
关键词:DeepSeek-R1-0528, AI智能体, 多模态模型, 开源AI, 强化学习, 图像编辑, 大语言模型, AI基准测试, DeepSeek-R1-0528-Qwen3-8B, Circuit Tracer工具, Darwin Gödel Machine, FLUX.1 Kontext, Agentic Retrieval
🔥 聚焦
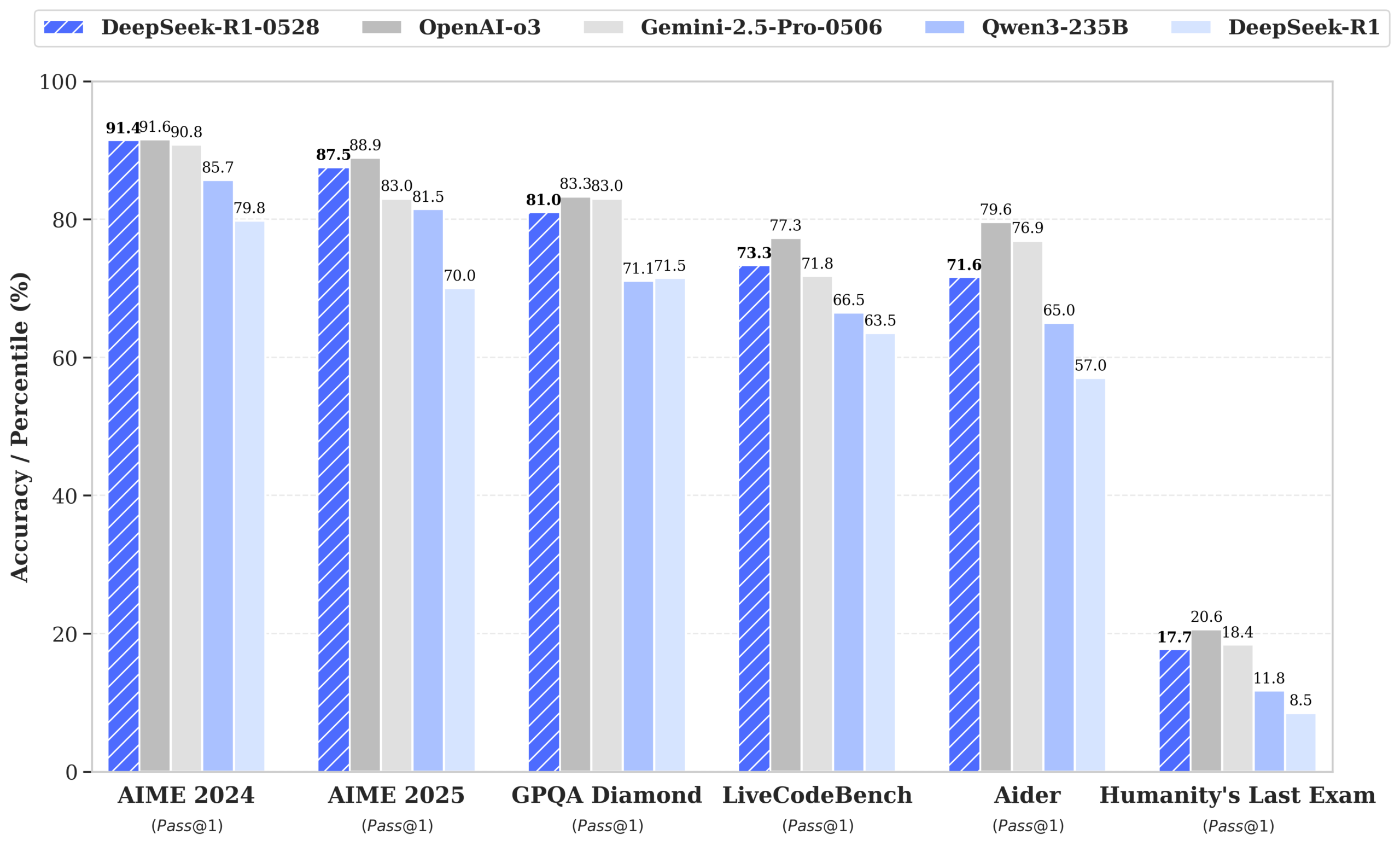
DeepSeek发布R1-0528模型,性能逼近GPT-4o和Gemini 2.5 Pro,登顶开源榜首: DeepSeek-R1-0528在数学、编程和通用逻辑推理等多个基准测试中表现出色,尤其在AIME 2025测试中准确率从70%提升至87.5%。新版本显著降低了幻觉率(约45-50%),增强了前端代码生成能力,并支持JSON输出和函数调用。同时,DeepSeek基于Qwen3-8B Base微调发布了DeepSeek-R1-0528-Qwen3-8B,在AIME 2024上性能仅次于R1-0528,超越Qwen3-235B。此次更新巩固了DeepSeek作为全球第二大AI实验室和开源领导者的地位。 (来源: ClementDelangue, dotey, huggingface, NandoDF, andrew_n_carr, Francis_YAO_, scaling01, karminski3, teortaxesTex, tokenbender, dotey)
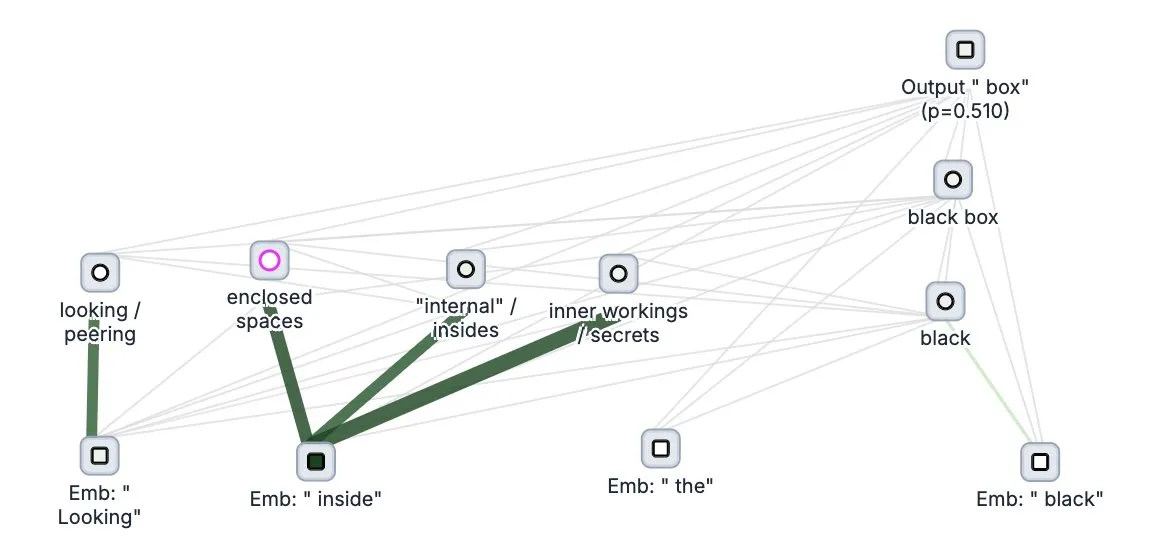
Anthropic开源大模型“思维追踪”工具Circuit Tracer: Anthropic公司开源了其大模型可解释性研究工具Circuit Tracer,允许研究人员生成和交互式探索“归因图谱”,以理解大语言模型(LLM)的内部“思考”过程和决策机制。这一工具旨在帮助研究者更深入地探究LLM的内部运作,例如模型如何利用特定特征来预测下一个token。用户可以在Neuronpedia上尝试该工具,输入句子即可获得模型特征使用情况的电路图。 (来源: scaling01, mlpowered, rishdotblog, menhguin, NeelNanda5, akbirkhan, riemannzeta, andersonbcdefg, algo_diver, Reddit r/ClaudeAI)
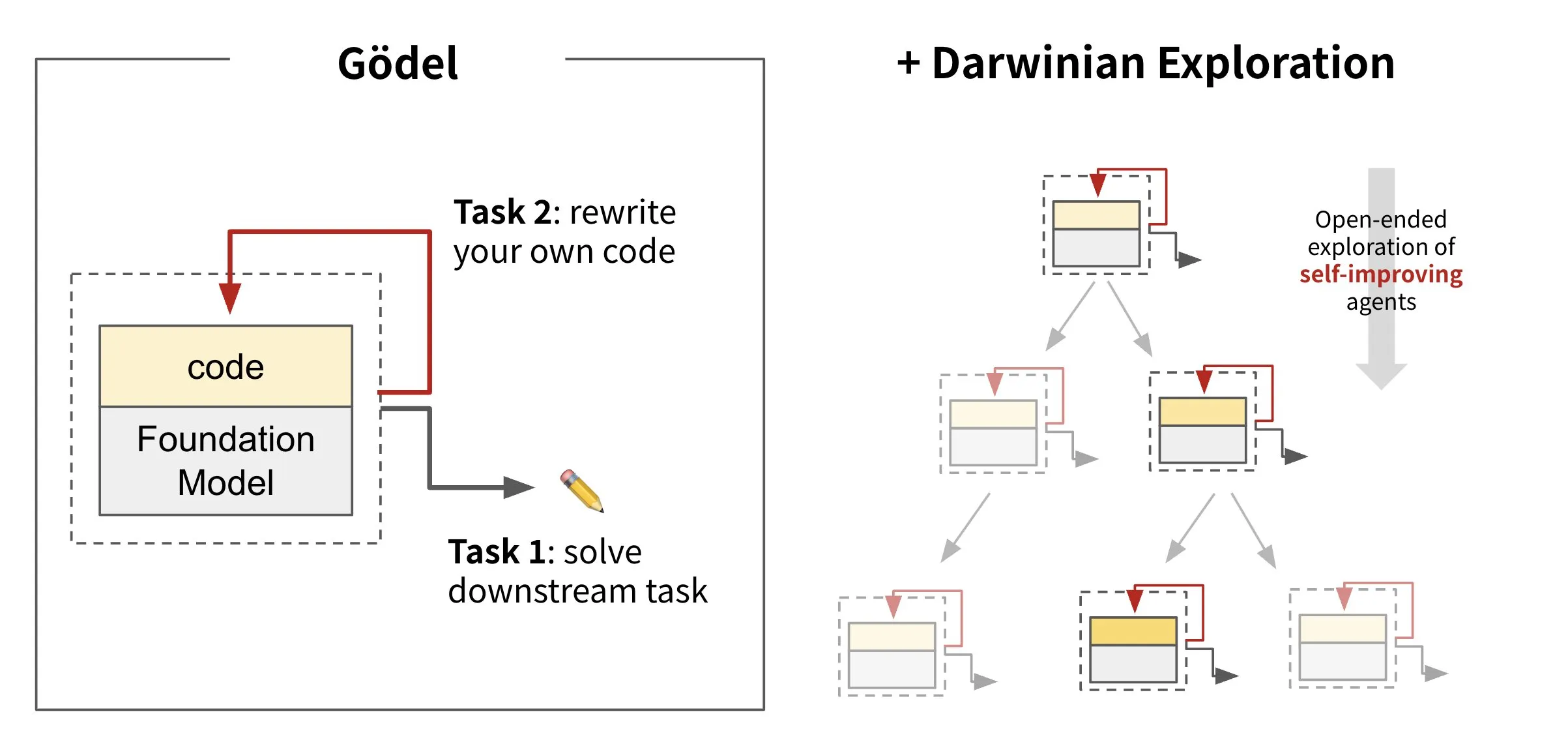
Sakana AI发布自进化智能体框架Darwin Gödel Machine (DGM): Sakana AI推出了Darwin Gödel Machine (DGM),这是一个能够通过重写自身代码进行自我改进的AI智能体框架。DGM受进化理论启发,维护一个不断扩展的智能体变体谱系,以开放式探索自我改进智能体的设计空间。该框架旨在使AI系统能够像人类一样随时间学习和进化自身能力。在SWE-bench上,DGM将性能从20.0%提升至50.0%;在Polyglot上,成功率从14.2%提升至30.7%。 (来源: SakanaAILabs, teortaxesTex, Reddit r/MachineLearning)
Black Forest Labs发布图像编辑模型FLUX.1 Kontext,支持文本与图像混合输入: Black Forest Labs推出了新一代图像编辑模型FLUX.1 Kontext,采用流匹配架构,能够同时接受文本和图像作为输入,实现上下文感知的图像生成和编辑。该模型在角色一致性、局部编辑、风格参考和交互速度方面表现出色,例如在1024×1024分辨率下生成图像仅需3-5秒。Replicate的测试表明其编辑效果优于GPT-4o-Image且成本更低。Kontext提供Pro和Max版本,并计划推出开源的Dev版本。 (来源: TomLikesRobots, two_dukes, cloneofsimo, robrombach, bfirsh, timudk, scaling01, KREA AI)

🎯 动向
谷歌DeepMind发布多模态医疗模型MedGemma: Google DeepMind推出了MedGemma,这是一款功能强大的开放模型,专为多模态医疗文本和图像理解而设计。该模型作为Health AI Developer Foundations的一部分提供,旨在提升AI在医疗领域的应用能力,特别是在结合文本和医学影像(如X光片)进行综合分析方面。 (来源: GoogleDeepMind)
Perplexity AI推出Perplexity Labs,赋能复杂任务处理: Perplexity AI发布了新功能Perplexity Labs,专为处理更复杂的任务而设计,旨在为用户提供类似整个研究团队的分析和构建能力。用户可以通过Labs构建分析报告、演示文稿和动态仪表盘等。该功能目前已向所有Pro用户开放,并展示了其在科学研究、市场分析和迷你应用(如游戏、仪表盘)创建方面的潜力。 (来源: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)
腾讯混元与腾讯音乐联合推出HunyuanVideo-Avatar,照片可生成逼真歌唱视频: 腾讯混元与腾讯音乐联手发布了HunyuanVideo-Avatar模型,该模型能将用户上传的照片和音频结合,自动检测场景上下文和情感,生成具有逼真口型同步和动态视觉效果的讲话或唱歌视频。该技术支持多种风格,并已开源。 (来源: huggingface, thursdai_pod)
Apache Spark 4.0.0 正式发布,增强SQL、Spark Connect及多语言支持: Apache Spark 4.0.0版本正式发布,带来了SQL功能的显著增强,Spark Connect的改进使得应用程序运行更为便捷,并增加了对新语言的支持。此次更新共解决了超过5100个问题,有超过390位贡献者参与。 (来源: matei_zaharia, lateinteraction)

Kling 2.1视频模型发布,集成OpenArt支持角色一致性: Kling AI发布了其视频模型Kling 2.1,并与OpenArt合作,支持在AI视频故事叙述中实现角色一致性。Kling 2.1提升了提示词对齐、视频生成速度、相机运动的清晰度,并号称拥有最佳的文本到视频效果。新版本支持720p(标准)和1080p(专业)输出,目前图像到视频功能已上线,文本到视频功能即将推出。 (来源: Kling_ai, NandoDF)
Hume发布EVI 3语音模型,可理解并生成任何人类声音: Hume推出了其最新的语音语言模型EVI 3,旨在实现通用语音智能。EVI 3能够理解和生成任何人类的声音,而不仅仅是少数特定说话者,从而提供更广泛的表达能力和对语调、节奏、音色及说话风格的更深理解。该技术旨在让每个人都能拥有一个通过声音识别的、独特的、可信赖的AI。 (来源: AlanCowen, AlanCowen, _akhaliq)
Alibaba发布WebDancer,探索自主信息搜寻智能体: 阿里巴巴推出了WebDancer项目,旨在研究和开发能够自主进行信息搜寻的AI智能体。该项目关注如何使AI智能体更有效地在网络环境中导航、理解信息并完成复杂的信息获取任务。 (来源: _akhaliq)
MiniMax开源V-Triune框架及Orsta模型,统一视觉RL推理与感知任务: AI公司MiniMax开源了其视觉强化学习统一框架V-Triune及基于此框架的Orsta模型系列(7B至32B)。该框架通过三层组件设计和动态交并比(IoU)奖励机制,首次使VLM能在单个后训练流程中联合学习视觉推理和感知任务,在MEGA-Bench Core基准测试中性能提升显著。 (来源: 量子位)

上海AI实验室等发布图像编辑新基准RISEBench,考验模型深层推理: 上海人工智能实验室联合多所高校发布了名为RISEBench的新图像编辑评测基准,包含360个人类专家设计的高难度案例,覆盖时间、因果、空间、逻辑四种核心推理类型。测试结果显示,即便是GPT-4o-Image也仅能完成28.9%的任务,暴露了当前多模态模型在复杂指令理解和视觉编辑方面的不足。 (来源: 36氪)

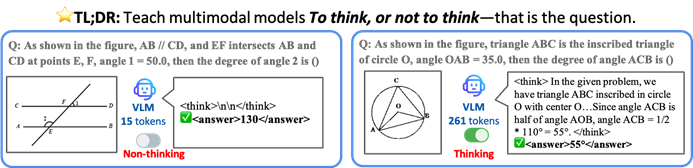
港中大等提出TON框架,让AI模型选择性思考以提升效率与准确率: 香港中文大学与新加坡国立大学Show Lab的研究者提出了TON(Think Or Not)框架,使视觉语言模型(VLM)能自主判断是否需要显式推理。该框架通过“思想丢弃”和强化学习,让模型对简单问题直接作答,对复杂问题进行详细推理,从而在不牺牲准确率的前提下,平均推理输出长度最多减少90%,部分任务准确率甚至提升17%。 (来源: 36氪)
微软Copilot集成Instacart,实现AI辅助生鲜购物: 微软AI负责人Mustafa Suleyman宣布,Copilot现已集成Instacart服务,用户可以通过Copilot应用无缝完成从菜谱生成、购物清单创建到生鲜杂货送货上门的整个流程。这标志着AI助手在日常生活服务领域的进一步拓展。 (来源: mustafasuleyman)
🧰 工具
LlamaIndex推出BundesGPT源码及create-llama工具,简化AI应用构建: LlamaIndex的Jerry Liu宣布提供BundesGPT的源代码,并推广其开源工具create-llama。该工具基于LlamaIndex,旨在帮助开发者轻松构建和集成企业数据与AI代理,其新的eject-mode使得创建如BundesGPT这样完全可定制的AI界面变得非常简单。此举旨在支持德国为每位公民提供免费ChatGPT Plus订阅的潜在计划。 (来源: jerryjliu0)
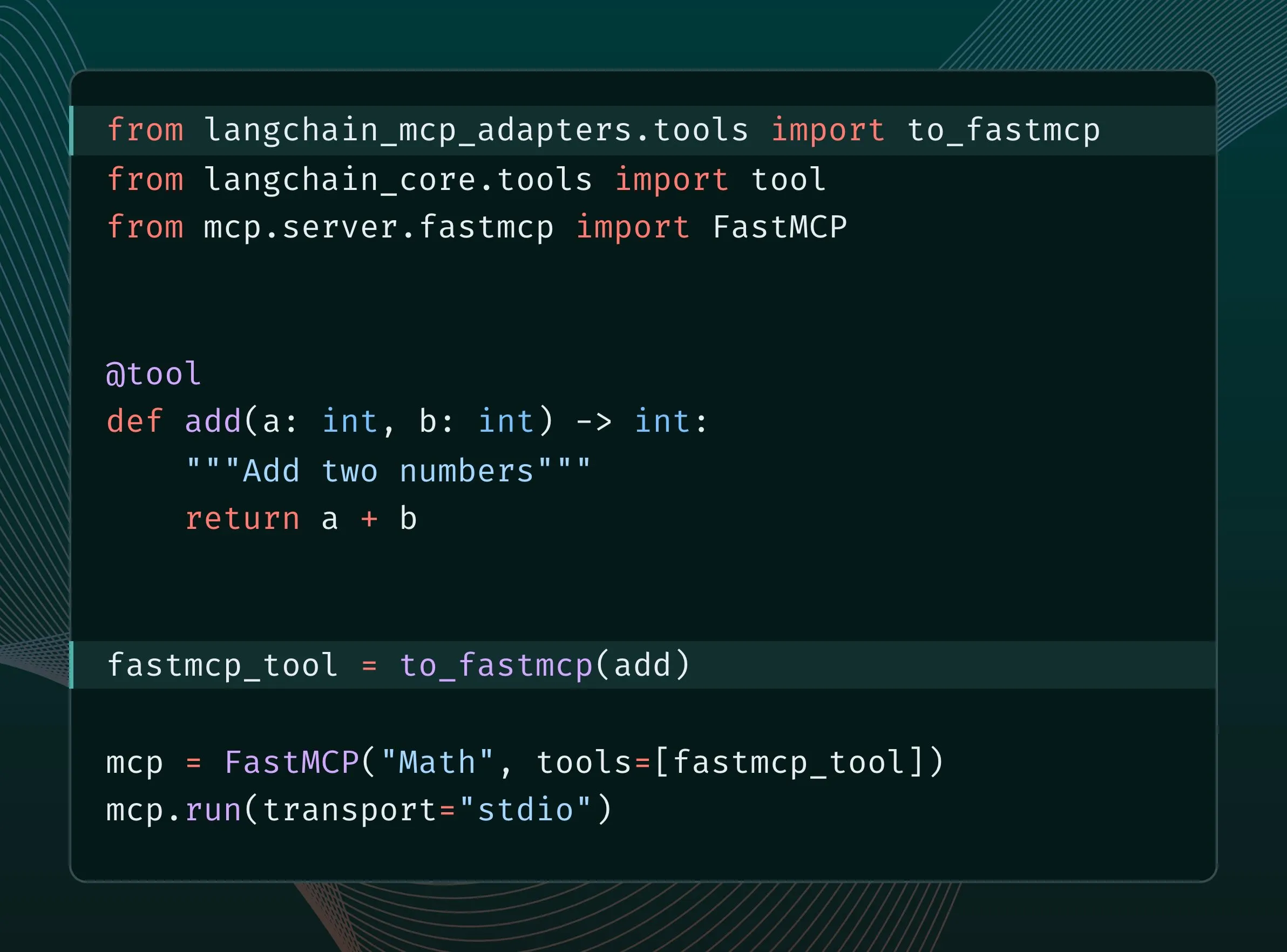
LangChain工具可转换为MCP工具并集成至FastMCP服务器: LangChain用户现在可以将LangChain工具转换为MCP(Model Component Protocol)工具,并直接添加到FastMCP服务器中。通过安装langchain-mcp-adapters库,开发者可以更便捷地在MCP生态系统中使用LangChain的工具集,促进了不同AI框架间的互操作性。 (来源: LangChainAI, hwchase17)
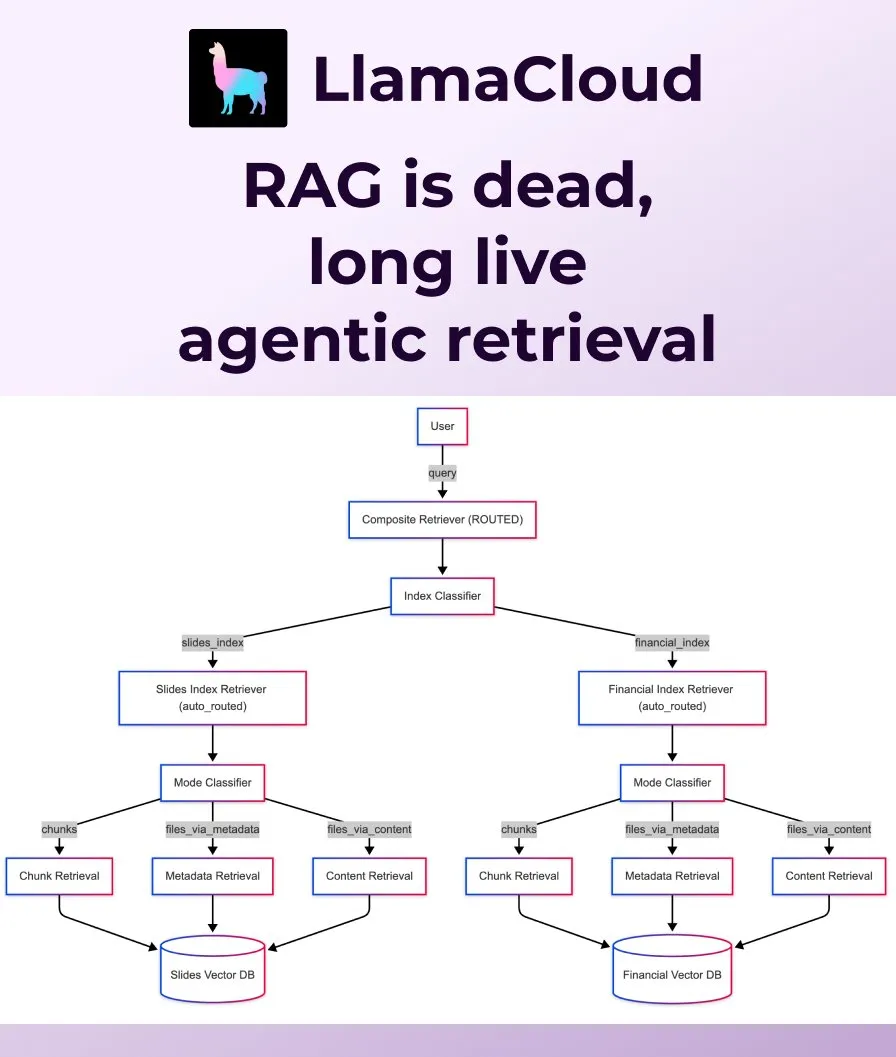
LlamaIndex发布Agentic Retrieval,取代传统RAG: LlamaIndex认为传统朴素的RAG(检索增强生成)已不足以满足现代应用需求,并推出了Agentic Retrieval。该方案内置于LlamaCloud,允许智能体根据问题内容动态地从单个或多个知识库(如Sharepoint, Box, GDrive, S3)中检索整个文件或特定数据块,实现更智能、更灵活的上下文获取。 (来源: jerryjliu0, jerryjliu0)
Ollama支持运行Osmosis-Structure-0.6B模型,用于非结构化数据转换: 用户现在可以通过Ollama运行Osmosis-Structure-0.6B模型。这是一个极小的模型,能够将任何非结构化数据转换为指定的格式(例如JSON Schema),可与任何模型配合使用,特别适用于需要结构化输出的推理任务。 (来源: ollama)
CrewAI更新Gemini文档,简化入门流程: CrewAI团队更新了其关于Google Gemini API的文档,旨在帮助用户更轻松地开始使用Gemini模型构建AI智能体。新的文档可能包含更清晰的指引、示例代码或最佳实践。 (来源: _philschmid)
Requesty推出Smart Routing功能,自动为OpenWebUI选择最佳LLM: Requesty发布Smart Routing功能,可无缝集成OpenWebUI,根据用户提示的任务类型自动选择最佳LLM(如GPT-4o, Claude, Gemini)。用户只需使用smart/task作为模型ID,系统即可在约65毫秒内对提示进行分类,并基于成本、速度和质量路由到最合适的模型。该功能旨在简化模型选择,提升用户体验。 (来源: Reddit r/OpenWebUI)
EvoAgentX:首个AI智能体自进化开源框架发布: 英国格拉斯哥大学研究团队发布了EvoAgentX,这是全球首个AI智能体自进化开源框架。它支持一键搭建工作流,并引入“自进化”机制,使多智能体系统能根据环境与目标变化持续优化结构与性能,旨在推动AI多智能体系统从“人工调试”迈向“自主进化”。实验表明,在多跳问答、代码生成和数学推理任务中,性能平均提升8%-13%。 (来源: 36氪)

📚 学习
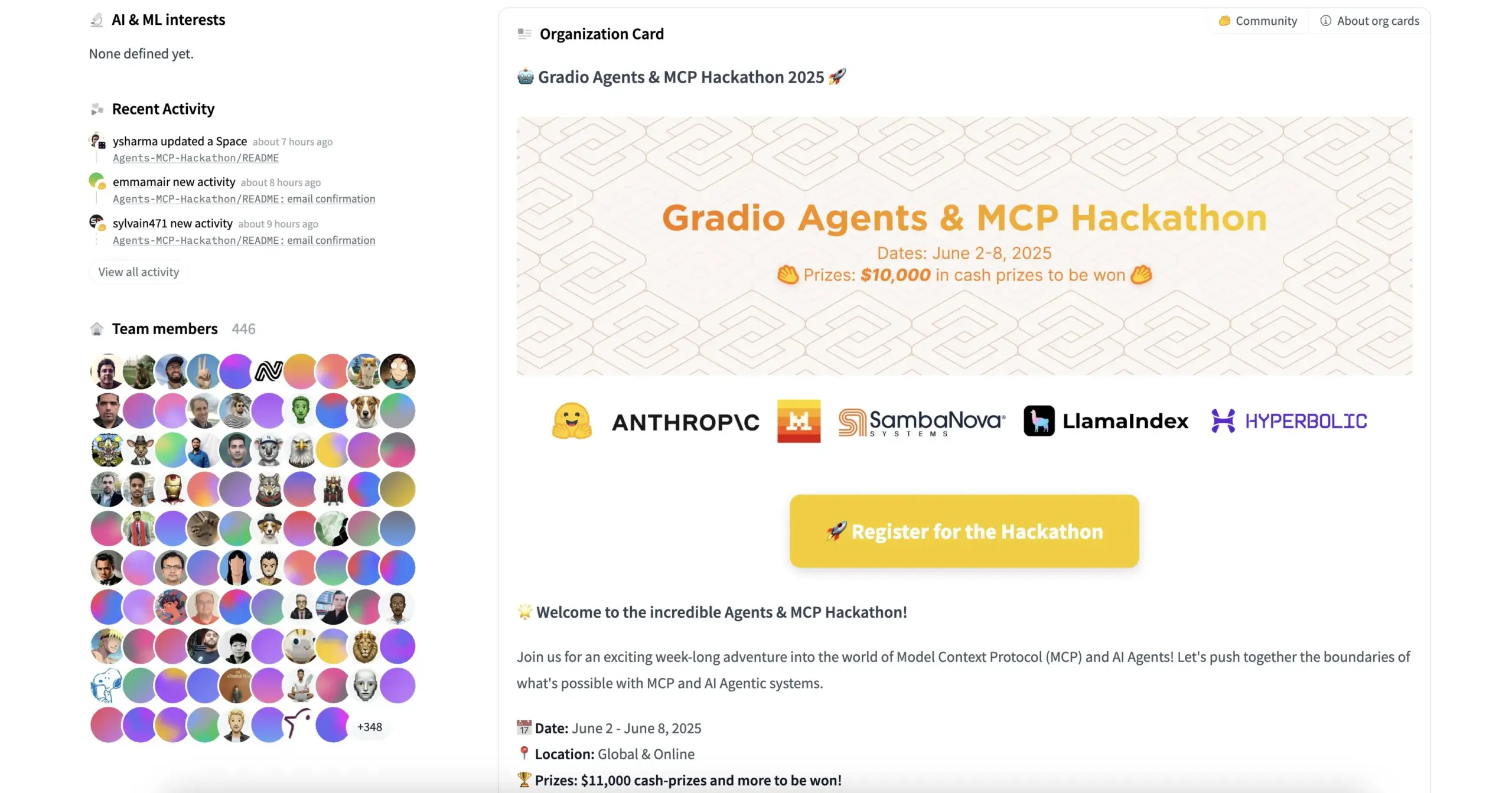
HuggingFace与Gradio等联合举办Agents & MCP Hackathon,提供丰厚奖金与API额度: HuggingFace、Gradio、Anthropic、SambaNovaAI、MistralAI和LlamaIndex等机构将联合举办Gradio Agents & MCP Hackathon(6月2-8日)。活动提供总计11000美元奖金,并为早期报名者提供Hyperbolic、Anthropic、Mistral、SambaNova的免费API额度。Modal Labs更是承诺为所有参与者提供价值250美元的GPU额度,总计超过30万美元。 (来源: huggingface, _akhaliq, ben_burtenshaw, charles_irl)
LangChain分享摩根大通利用多智能体系统进行投资研究的实践: 摩根大通的David Odomirok和Zheng Xue分享了他们如何构建名为”Ask David”的多智能体AI系统。该系统旨在为数千种金融产品自动化投资研究流程,展示了多智能体架构在复杂金融分析中的应用潜力。 (来源: LangChainAI, hwchase17)
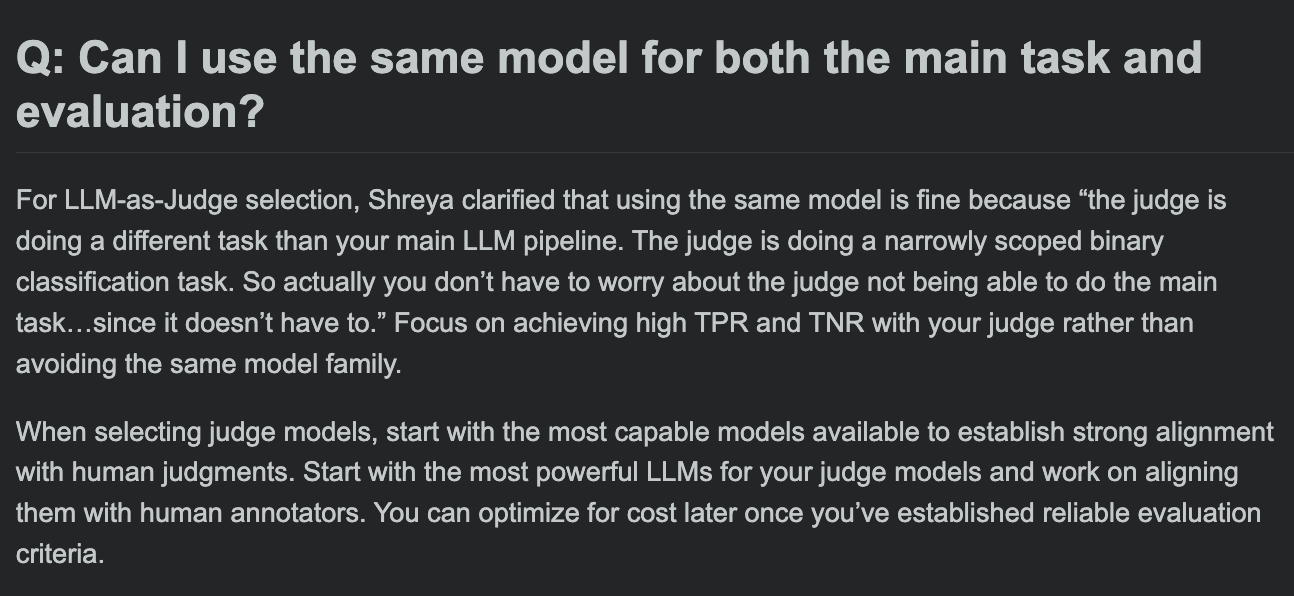
Hamel Husain分享LLM评估课程FAQ,探讨评估模型与主任务模型是否可相同: 在其LLM评估课程的问答环节中,Hamel Husain探讨了一个常见问题:是否可以使用相同的模型进行主要任务处理和任务评估。这一讨论有助于开发者理解模型评估中的潜在偏差和最佳实践。 (来源: HamelHusain, HamelHusain)
The Rundown AI推出个性化AI教育平台: The Rundown AI宣布启动全球首个个性化AI教育平台,提供针对不同行业、技能水平和日常工作流程的定制化培训、用例和实时研讨会。平台内容包括16个科技垂直领域的行业特定AI证书课程、300多个真实世界AI用例、专家研讨会以及AI工具折扣等。 (来源: TheRundownAI, rowancheung)
Common Crawl发布2025年3-5月主机和域名级别网络图谱: Common Crawl 公布了其最新的主机和域名级别网络图谱数据,覆盖2025年3月、4月和5月。这些数据对于研究网络结构、训练语言模型以及进行大规模网络分析具有重要价值。 (来源: CommonCrawl)
Bill Chambers发起“20 Days of DSPyOSS”学习活动: 为帮助社区更好地理解DSPyOSS的功能和使用方法,Bill Chambers发起了为期20天的DSPyOSS学习活动。每天将发布一个DSPy代码片段及其解释,旨在帮助用户从入门到精通该框架。 (来源: lateinteraction)
DeepLearning.AI发布The Batch周报,Andrew Ng探讨削减科研经费风险: 最新一期The Batch周报中,Andrew Ng讨论了削减科研经费对国家竞争力和安全的潜在风险。周报还涵盖了Claude 4模型在编码基准测试中的表现、谷歌I/O的AI发布、DeepSeek的低成本训练方法以及GPT-4o可能使用受版权保护书籍进行训练等热点。 (来源: DeepLearningAI)
谷歌DeepMind为英国大学生免费提供Gemini 2.5 Pro和NotebookLM: 谷歌DeepMind宣布为英国大学生提供其最先进模型(包括Gemini 2.5 Pro和NotebookLM)的免费访问权限,为期15个月。此举旨在支持学生在研究、写作和备考等方面的学习,并提供2TB的免费存储空间。 (来源: demishassabis)
AI论文解读:Prot2Token统一蛋白质建模框架: 论文《Prot2Token: A Unified Framework for Protein Modeling via Next-Token Prediction》介绍了一个统一的蛋白质建模框架Prot2Token,它将蛋白质序列属性、残基特征到蛋白质间相互作用等多种预测任务转化为标准的下一token预测格式。该框架采用自回归解码器,利用预训练蛋白质编码器的嵌入和可学习的任务token进行多任务学习,旨在提高效率并加速生物学发现。 (来源: HuggingFace Daily Papers)
AI论文解读:企业系统领域特定检索的硬负例挖掘: 论文《Hard Negative Mining for Domain-Specific Retrieval in Enterprise Systems》提出了一种针对企业特定领域数据的可扩展硬负例挖掘框架。该方法动态选择语义上具有挑战性但上下文不相关的文档,以增强部署的重排模型性能,在云服务领域的企业语料库上实验证明,MRR@3和MRR@10分别提升了15%和19%。 (来源: HuggingFace Daily Papers)
AI论文解读:FS-DAG,少样本富视觉文档理解图网络: 论文《FS-DAG: Few Shot Domain Adapting Graph Networks for Visually Rich Document Understanding》提出FS-DAG模型架构,用于在少样本情况下进行富视觉文档理解。该模型利用领域特定和语言/视觉特定骨干网络,在模块化框架内以最少数据适应不同文档类型,并在信息提取任务的实验中显示出比SOTA方法更快的收敛速度和性能。 (来源: HuggingFace Daily Papers)
AI论文解读:FastTD3,简单快速的人形机器人强化学习控制: 论文《FastTD3: Simple, Fast, and Capable Reinforcement Learning for Humanoid Control》介绍了一种名为FastTD3的强化学习算法,它通过并行模拟、大批量更新、分布式评论器和精心调整的超参数,显著加速了人形机器人在HumanoidBench、IsaacLab和MuJoCo Playground等流行套件中的训练速度。 (来源: HuggingFace Daily Papers, pabbeel, cloneofsimo, jachiam0)
AI论文解读:HLIP,面向3D医学影像的可扩展语言-图像预训练: 论文《Towards Scalable Language-Image Pre-training for 3D Medical Imaging》介绍了一种名为HLIP(Hierarchical attention for Language-Image Pre-training)的可扩展3D医学影像预训练框架。HLIP采用轻量级分层注意力机制,能够直接在未整理的临床数据集上进行训练,并在多个基准测试中取得了SOTA性能。 (来源: HuggingFace Daily Papers)
AI论文解读:PENGUIN,LLM个性化安全基准与规划式智能体方法: 论文《Personalized Safety in LLMs: A Benchmark and A Planning-Based Agent Approach》引入了个性化安全概念,并提出了PENGUIN基准(包含7个敏感领域的14000个场景)和RAISE框架(一个免训练、两阶段智能体,能策略性获取用户特定背景信息)。研究表明个性化信息能显著提高安全评分,RAISE能在低交互成本下提升安全性。 (来源: HuggingFace Daily Papers)
AI论文解读:通过回合级信用分配强化LLM智能体的多轮推理: 论文《Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Credit Assignment》研究了如何通过强化学习增强LLM智能体的推理能力,特别是在多轮工具使用场景中。作者提出了一种细粒度的回合级优势估计策略,以实现更精确的信用分配,实验表明该方法能显著提升LLM智能体在复杂决策任务中的多轮推理能力。 (来源: HuggingFace Daily Papers)
AI论文解读:PISCES,大语言模型中参数内概念的精确擦除: 论文《Precise In-Parameter Concept Erasure in Large Language Models》提出了PISCES框架,用于通过直接编辑参数空间中编码概念的方向来精确擦除模型参数中的整个概念。该方法使用解缠结器分解MLP向量,识别与目标概念相关的特征并从模型参数中移除,实验显示其在擦除效果、特异性和鲁棒性方面均优于现有方法。 (来源: HuggingFace Daily Papers)
AI论文解读:DORI,细粒度多轴感知任务评估MLLM方向理解: 论文《Right Side Up? Disentangling Orientation Understanding in MLLMs with Fine-grained Multi-axis Perception Tasks》引入了DORI基准,旨在评估多模态大语言模型(MLLM)对物体方向的理解能力。DORI包含正面定位、旋转变换、相对方向关系和规范方向理解四个维度,测试了15个SOTA MLLM,发现即使最佳模型在精细方向判断上也存在显著局限。 (来源: HuggingFace Daily Papers)
AI论文解读:LLM能否从真实世界文本中推断因果关系?: 论文《Can Large Language Models Infer Causal Relationships from Real-World Text?》探讨了LLM从真实世界文本中推断因果关系的能力。研究者开发了一个源自真实学术文献的基准,包含不同长度、复杂性和领域的文本。实验表明,即使是SOTA的LLM在此任务上也面临显著挑战,最佳模型F1得分仅0.477,揭示了其在处理隐含信息、区分相关因素和连接分散信息方面的困难。 (来源: HuggingFace Daily Papers)
AI论文解读:IQBench,用人类IQ测试评估视觉语言模型“智能”程度: 论文《IQBench: How “Smart’’ Are Vision-Language Models? A Study with Human IQ Tests》推出了IQBench,一个旨在通过标准化视觉IQ测试评估视觉语言模型(VLM)流体智能的新基准。该基准以视觉为中心,包含500个人工收集和注释的视觉IQ问题,评估模型的解释、解决问题的模式以及最终预测的准确性。实验显示,o4-mini、Gemini-2.5-Flash和Claude-3.7-Sonnet表现较好,但所有模型在3D空间和字谜推理任务上均存在困难。 (来源: HuggingFace Daily Papers)
AI论文解读:PixelThink,迈向高效的像素链推理: 论文《PixelThink: Towards Efficient Chain-of-Pixel Reasoning》提出PixelThink方案,通过整合外部估计的任务难度和内部测量的模型不确定性,在强化学习范式内调节推理生成。该模型学会根据场景复杂性和预测置信度压缩推理长度。同时引入ReasonSeg-Diff基准进行评估,实验表明该方法提高了推理效率和整体分割性能。 (来源: HuggingFace Daily Papers)
AI论文解读:多智能体辩论作为测试时扩展的再探讨: 论文《Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness》将多智能体辩论(MAD)概念化为一种测试时计算扩展技术,并系统研究了其在不同条件下(任务难度、模型规模、智能体多样性)相对于自智能体方法的有效性。研究发现,对于数学推理,MAD优势有限,但在问题难度增加或模型能力降低时更有效;对于安全任务,MAD的协作优化可能增加脆弱性,但多样化配置有助于减少攻击成功率。 (来源: HuggingFace Daily Papers)
AI论文解读:VF-Eval,评估MLLM生成AIGC视频反馈能力: 论文《VF-Eval: Evaluating Multimodal LLMs for Generating Feedback on AIGC Videos》提出了新基准VF-Eval,用于评估多模态大语言模型(MLLM)在解读AI生成内容(AIGC)视频方面的能力。VF-Eval包含连贯性验证、错误感知、错误类型检测和推理评估四个任务。对13个前沿MLLM的评估显示,即使是表现最好的GPT-4.1也难以在所有任务上保持良好性能。 (来源: HuggingFace Daily Papers)
AI论文解读:SafeScientist,LLM智能体实现风险感知的科学发现: 论文《SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents》介绍了一个名为SafeScientist的AI科学家框架,旨在增强AI驱动科学探索中的安全性和伦理责任。该框架能主动拒绝不当或高风险任务,并通过提示监控、智能体协作监控、工具使用监控和伦理审查员组件等多重防御机制强调研究过程的安全性。同时提出了SciSafetyBench基准进行评估。 (来源: HuggingFace Daily Papers)
AI论文解读:CXReasonBench,评估胸部X光结构化诊断推理的基准: 论文《CXReasonBench: A Benchmark for Evaluating Structured Diagnostic Reasoning in Chest X-rays》介绍了CheXStruct流程和CXReasonBench基准,用于评估大型视觉语言模型(LVLM)在胸部X光诊断中是否能执行临床上有效的推理步骤。该基准包含18988个QA对,覆盖12个诊断任务和1200个病例,支持多路径、多阶段评估,包括解剖区域选择和诊断测量的视觉定位。 (来源: HuggingFace Daily Papers)
AI论文解读:ZeroGUI,零人工成本自动化在线GUI学习: 论文《ZeroGUI: Automating Online GUI Learning at Zero Human Cost》提出了ZeroGUI,一个可扩展的在线学习框架,用于零人工成本地自动化GUI智能体训练。ZeroGUI集成了基于VLM的自动任务生成、自动奖励估计和两阶段在线强化学习,以持续与GUI环境交互并从中学习。 (来源: HuggingFace Daily Papers)
AI论文解读:Spatial-MLLM,提升MLLM视觉空间智能: 论文《Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence》提出了Spatial-MLLM框架,用于从纯2D观察中进行基于视觉的空间推理。该框架采用双编码器架构(一个语义视觉编码器和一个空间编码器),并结合空间感知帧采样策略,在多个真实世界数据集上实现了SOTA性能。 (来源: HuggingFace Daily Papers)
AI论文解读:TrustVLM,判断视觉语言模型预测是否可信: 论文《To Trust Or Not To Trust Your Vision-Language Model’s Prediction》引入了TrustVLM,一个免训练框架,旨在评估视觉语言模型(VLM)预测的可信度。该方法利用图像嵌入空间中的概念表征差异,提出新的置信度评分函数以改进误分类检测,并在17个不同数据集上展示了SOTA性能。 (来源: HuggingFace Daily Papers)
AI论文解读:MAGREF,基于掩码引导的多参考视频生成: 论文《MAGREF: Masked Guidance for Any-Reference Video Generation》提出了MAGREF,一个统一的多参考视频生成框架。它引入掩码引导机制,通过区域感知动态掩码和像素级通道连接,实现了在多样化参考图像和文本提示条件下,连贯的多主体视频合成,并在多主体视频基准上超越了现有开源和商业基线。 (来源: HuggingFace Daily Papers)
AI论文解读:ATLAS,学习在测试时优化上下文记忆: 论文《ATLAS: Learning to Optimally Memorize the Context at Test Time》提出ATLAS,一个高容量的长期记忆模块,通过根据当前和过去token优化记忆来学习记忆上下文,克服了长期记忆模型的在线更新特性。基于此,作者提出了DeepTransformers架构家族,实验显示ATLAS在语言建模、常识推理、召回密集型和长上下文理解任务上超越了Transformers和近期线性循环模型。 (来源: HuggingFace Daily Papers)
AI论文解读:Satori-SWE,样本高效的进化式测试时扩展软件工程方法: 论文《Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering》提出了EvoScale方法,将代码生成视为进化过程,通过迭代优化输出来提高小模型在软件工程任务(如SWE-Bench)上的性能。Satori-SWE-32B模型通过此方法,在使用少量样本的情况下,表现达到或超过了参数量超100B的模型。 (来源: HuggingFace Daily Papers)
AI论文解读:OPO,具有最优奖励基线的策略上强化学习: 论文《On-Policy RL with Optimal Reward Baseline》提出了OPO算法,一种新的简化强化学习算法,旨在解决当前RL算法在训练LLM时面临的训练不稳定和计算效率低下问题。OPO强调精确的策略上训练,并引入理论上最小化梯度方差的最优奖励基线,实验表明其在数学推理基准上具有优越性能和训练稳定性。 (来源: HuggingFace Daily Papers)
AI论文解读:SWE-bench Goes Live! 实时更新的软件工程基准: 论文《SWE-bench Goes Live!》介绍了SWE-bench-Live,一个旨在克服现有SWE-bench局限性的实时可更新基准。新版本包含1319个源自2024年以来真实GitHub问题的任务,覆盖93个仓库,并配备自动化管理流程,以实现可扩展性和持续更新,从而提供更严格、抗污染的LLM和智能体评估。 (来源: HuggingFace Daily Papers, _akhaliq)
AI论文解读:ToMAP,基于心智理论训练具有对手意识的LLM说服者: 论文《ToMAP: Training Opponent-Aware LLM Persuaders with Theory of Mind》介绍了一种名为ToMAP的新方法,通过整合两个心智理论模块来构建更灵活的说服智能体,增强其对对手心理状态的意识和分析。实验表明,仅3B参数的ToMAP说服者在多个说服对象模型和语料库中表现优于GPT-4o等大型基线。 (来源: HuggingFace Daily Papers)
AI论文解读:LLM能否欺骗CLIP?通过文本更新评估预训练多模态表示的对抗性组合性: 论文《Can LLMs Deceive CLIP? Benchmarking Adversarial Compositionality of Pre-trained Multimodal Representation via Text Updates》引入了多模态对抗性组合性(MAC)基准,利用LLM生成欺骗性文本样本以利用CLIP等预训练多模态表示的组合性漏洞。研究提出一种自训练方法,通过促进多样性的过滤进行拒绝采样微调,以增强攻击成功率和样本多样性。 (来源: HuggingFace Daily Papers)
AI论文解读:喧嚣奖励在学习推理中的作用——登顶之路比顶峰更能雕琢智慧: 论文《The Climb Carves Wisdom Deeper Than the Summit: On the Noisy Rewards in Learning to Reason》研究了奖励噪声对LLM通过强化学习进行推理后训练的影响。研究发现LLM对大量奖励噪声表现出强大鲁棒性,即使仅奖励关键推理短语的出现(不验证答案正确性),模型也能达到与严格验证和准确奖励训练的模型相当的性能。 (来源: HuggingFace Daily Papers)
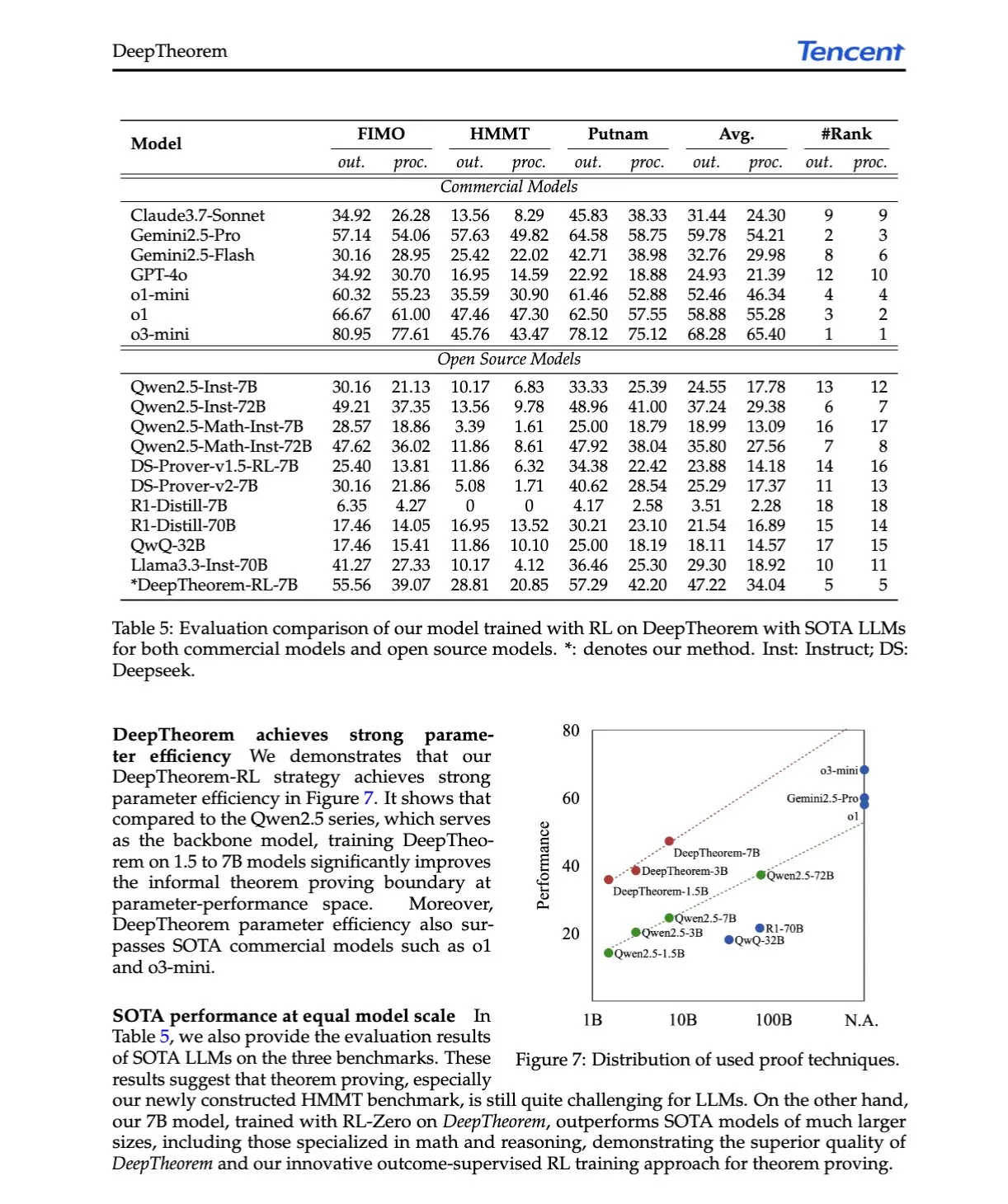
AI论文解读:DeepTheorem,通过自然语言和强化学习推进LLM定理证明: 论文《DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning》提出了DeepTheorem,一个利用自然语言增强LLM数学推理的非形式化定理证明框架。该框架包含一个大规模基准数据集(12.1万个IMO级别非形式化定理和证明)和一种专为非形式化定理证明设计的RL策略(RL-Zero)。 (来源: HuggingFace Daily Papers, teortaxesTex)
AI论文解读:D-AR,通过自回归模型实现扩散: 论文《D-AR: Diffusion via Autoregressive Models》提出D-AR新范式,将图像扩散过程重塑为标准自回归的下一token预测过程。通过设计的tokenizer将图像转换为离散token序列,不同位置的token可解码为像素空间中不同的扩散去噪步骤。该方法在ImageNet上使用775M Llama骨干网络和256个离散token达到2.09 FID。 (来源: HuggingFace Daily Papers)
AI论文解读:Table-R1,表格推理的推理时扩展: 论文《Table-R1: Inference-Time Scaling for Table Reasoning》首次探讨了表格推理任务中的推理时扩展。研究者开发并评估了两种后训练策略:从前沿模型推理轨迹中蒸馏(Table-R1-SFT)和使用可验证奖励的强化学习(Table-R1-Zero)。Table-R1-Zero(7B参数)在多种表格推理任务上达到或超过GPT-4.1和DeepSeek-R1的性能。 (来源: HuggingFace Daily Papers)
AI论文解读:Muddit,统一离散扩散模型实现超越文本到图像的生成: 论文《Muddit: Liberating Generation Beyond Text-to-Image with a Unified Discrete Diffusion Model》介绍Muddit,一个统一的离散扩散Transformer模型,支持文本和图像模态的快速并行生成。Muddit整合了预训练文本到图像骨干网络的强大视觉先验和轻量级文本解码器,在质量和效率上均具竞争力。 (来源: HuggingFace Daily Papers)
AI论文解读:VideoReasonBench,MLLM能否执行以视觉为中心的复杂视频推理?: 论文《VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?》引入VideoReasonBench,一个旨在评估以视觉为中心的复杂视频推理能力的基准。该基准包含对细粒度操作序列的视频,问题评估回忆、推断和预测能力。实验显示,多数SOTA MLLM在此基准上表现不佳,而思维增强的Gemini-2.5-Pro表现突出。 (来源: HuggingFace Daily Papers, OriolVinyalsML)
AI论文解读:GeoDrive,具有精确动作控制的3D几何感知驾驶世界模型: 论文《GeoDrive: 3D Geometry-Informed Driving World Model with Precise Action Control》提出GeoDrive,将鲁棒的3D几何条件明确整合到驾驶世界模型中,以增强空间理解和动作可控性。该方法通过动态编辑模块在训练中增强渲染效果,实验证明其在动作准确性和3D空间感知方面优于现有模型。 (来源: HuggingFace Daily Papers)
AI论文解读:通过动态低置信度掩码实现自适应无分类器引导: 论文《Adaptive Classifier-Free Guidance via Dynamic Low-Confidence Masking》提出A-CFG方法,通过利用模型的瞬时预测置信度来定制无分类器引导(CFG)的无条件输入。A-CFG在迭代(掩码)扩散语言模型的每一步识别低置信度token并临时重新掩码,从而创建动态、局部化的无条件输入,使CFG的校正影响更精确。 (来源: HuggingFace Daily Papers)
AI论文解读:PatientSim,用于真实医患交互的角色驱动模拟器: 论文《PatientSim: A Persona-Driven Simulator for Realistic Doctor-Patient Interactions》介绍了PatientSim,一个基于MIMIC数据集临床概况和四轴角色(个性、语言熟练度、病史回忆水平、认知混乱水平)生成真实多样患者角色的模拟器。旨在为训练或评估医生LLM提供现实的患者交互系统。 (来源: HuggingFace Daily Papers)
AI论文解读:LoRAShop,通过校正流Transformer实现免训练多概念图像生成与编辑: 论文《LoRAShop: Training-Free Multi-Concept Image Generation and Editing with Rectified Flow Transformers》介绍了首个使用LoRA模型进行多概念图像编辑的框架LoRAShop。该框架利用Flux风格扩散Transformer内部特征交互模式,为每个概念导出解耦的潜在掩码,并仅在概念区域内混合LoRA权重,实现多主体或风格的无缝集成。 (来源: HuggingFace Daily Papers)
AI论文解读:AnySplat,从无约束视图进行前馈3D高斯溅射: 论文《AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views》介绍AnySplat,一个用于从未校准图像集合进行新视角合成的前馈网络。与传统神经渲染流程不同,AnySplat通过单次前向传播即可预测3D高斯基元(编码场景几何与外观)以及每个输入图像的相机内外参,无需姿态标注,并支持实时新视角合成。 (来源: HuggingFace Daily Papers)
AI论文解读:ZeroSep,零训练实现音频中的万物分离: 论文《ZeroSep: Separate Anything in Audio with Zero Training》发现,仅通过预训练的文本引导音频扩散模型,在特定配置下即可实现零样本声源分离。ZeroSep方法通过将混合音频反转到扩散模型的潜在空间,并使用文本条件引导去噪过程来恢复单个声源,无需任何特定任务训练或微调。 (来源: HuggingFace Daily Papers)
AI论文解读:单样本熵最小化研究: 论文《One-shot Entropy Minimization》通过训练13440个大语言模型发现,熵最小化仅需单个无标签数据和10步优化,即可达到甚至超过使用数千数据和精心设计奖励的规则型强化学习所能取得的性能改进。这一结果可能促使对LLM后训练范式的重新思考。 (来源: HuggingFace Daily Papers)
AI论文解读:ChartLens,图表中的细粒度视觉归因: 论文《ChartLens: Fine-grained Visual Attribution in Charts》针对MLLM在图表理解中易产生幻觉的问题,引入了图表后验视觉归因任务,并提出ChartLens算法。该算法使用分割技术识别图表对象,并通过标记集提示与MLLM进行细粒度视觉归因。同时发布了ChartVA-Eval基准,包含金融、政策、经济等领域图表的细粒度归因标注。 (来源: HuggingFace Daily Papers)
AI论文解读:从图视角探索大语言模型中知识的结构模式: 论文《A Graph Perspective to Probe Structural Patterns of Knowledge in Large Language Models》从图的视角研究LLM中知识的结构模式。研究量化了LLM在三元组和实体层面的知识,分析其与节点度等图结构属性的关系,并揭示了知识同质性(拓扑相近的实体知识水平相似)。基于此开发了图机器学习模型来估计实体知识,并用于知识检查。 (来源: HuggingFace Daily Papers)
💼 商业
具身智能公司Lumos Robotics半年融资近2亿,与中远海运等达成合作: 前追觅高管喻超创立的具身智能机器人公司Lumos Robotics(鹿明机器人)宣布完成天使++轮融资,投资方包括复星锐正、德马科技和吴中金控,半年来累计融资近2亿元。公司聚焦家庭场景,产品包括LUS、MOS系列人形机器人及核心零部件,已推出全尺寸人形机器人LUS,并与德马科技、中远海运等达成战略合作,加速具身智能在物流及智能制造等场景的商业化。 (来源: 36氪)

Snorkel AI完成1亿美元D轮融资,推出AI智能体评估与专家数据服务: 数据中心AI公司Snorkel AI宣布完成由Valor Equity Partners领投的1亿美元D轮融资,总融资额达到2.35亿美元。同时,公司推出了Snorkel Evaluate(数据中心智能体AI评估平台)和Expert Data-as-a-Service(专家数据即服务),旨在帮助企业构建和部署更可靠、更专业的AI智能体。 (来源: realDanFu, percyliang, tri_dao, krandiash)
美国能源部宣布与戴尔、英伟达合作开发下一代超级计算机“Doudna”: 美国能源部宣布与戴尔公司签订合同,为劳伦斯伯克利国家实验室开发名为“Doudna”的下一代旗舰超级计算机NERSC-10。该系统将由英伟达下一代Vera Rubin平台提供支持,预计2026年投入使用,性能将是现有旗舰Perlmutter的10倍以上,旨在支持大规模高性能计算和AI工作负载,助力美国赢得全球AI主导权竞赛。 (来源: 36氪, nvidia)

🌟 社区
DeepSeek R1-0528引发热议,性能、幻觉、工具调用成焦点: DeepSeek R1-0528的发布在社区引起广泛讨论。多数观点认为其在数学、编程和通用逻辑推理方面有显著提升,接近甚至超越部分闭源模型。新版本在降低幻觉率方面取得进展,并增加了对JSON输出和函数调用的支持。同时,其蒸馏的Qwen3-8B版本也因其在小模型上的优异数学性能受到关注。社区普遍认为DeepSeek巩固了其在开源领域的领导地位,并期待R2版本的发布。 (来源: ClementDelangue, dotey, scaling01, awnihannun, karminski3, teortaxesTex, scaling01, karminski3, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI图像编辑模型FLUX.1 Kontext受关注,强调上下文理解与角色一致性: Black Forest Labs发布的FLUX.1 Kontext图像编辑模型因其能够同时处理文本和图像输入,并保持角色一致性而受到社区关注。用户反馈其在图像编辑、风格迁移和文本叠加等任务上表现优异,尤其在多轮编辑中能较好地保留主体特征。Replicate等平台已上线该模型,并提供了详细的测试报告和使用技巧。 (来源: TomLikesRobots, two_dukes, robrombach, timudk, robrombach, cloneofsimo, robrombach, robrombach)

AI智能体将显著改变搜索和广告模式: Perplexity AI CEO Arav Srinivas认为,随着AI智能体代用户执行搜索,谷歌等搜索引擎的人类查询量将大幅下降,这将导致广告CPM/CPC降低,广告支出可能流向社交媒体或AI平台。用户将不再需要频繁进行关键词搜索,而是由AI助手主动推送信息。 (来源: AravSrinivas)
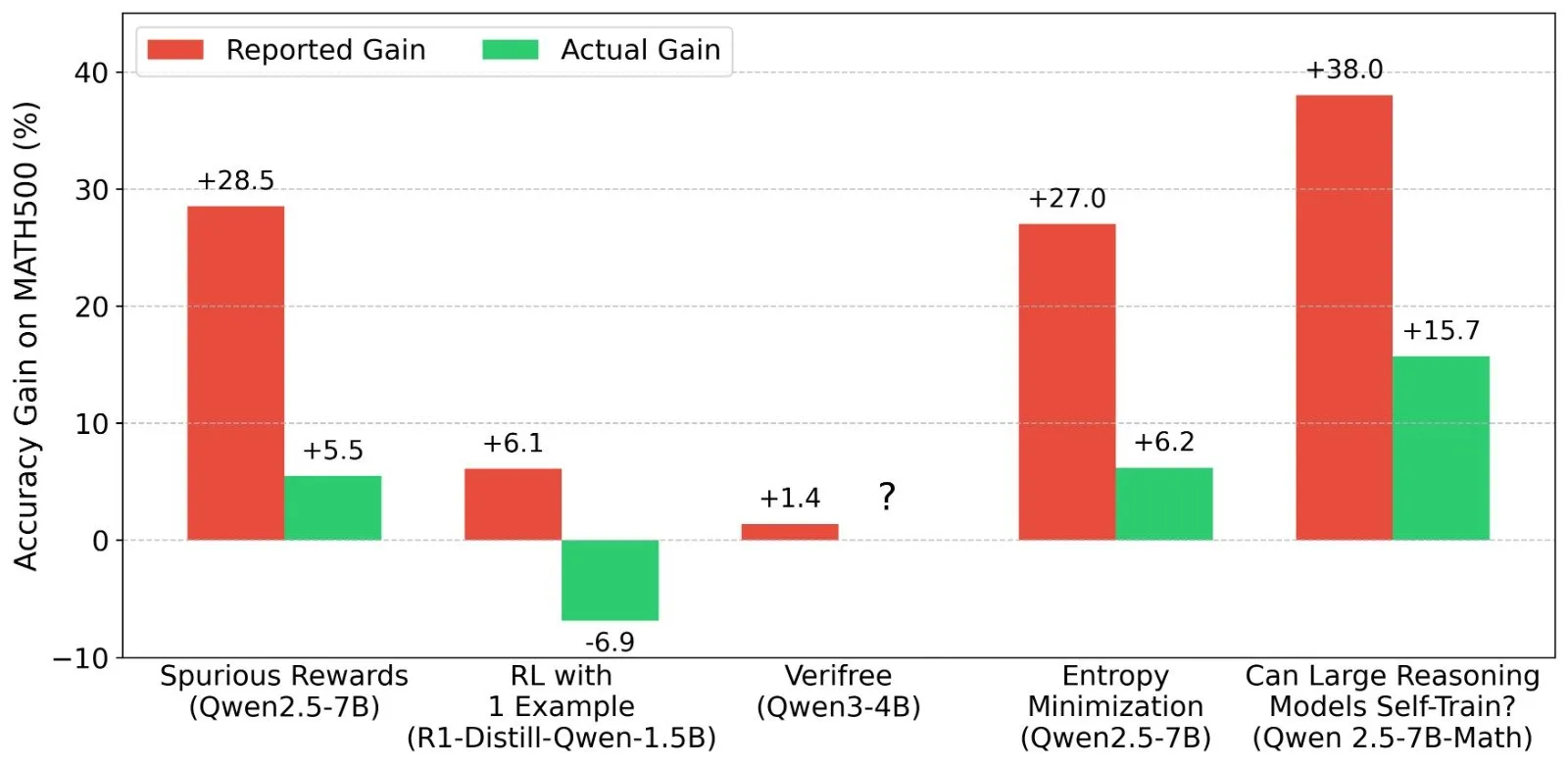
关于LLM强化学习(RL)结果的讨论:奖励信号与模型能力的真实性: Shashwat Goel等研究者对近期LLM RL研究中模型在没有真实奖励信号下仍能提升性能的现象提出疑问,指出部分研究可能低估了预训练模型的基线能力或存在其他混淆因素。讨论引发了对Qwen等模型在RL中表现的深入分析,以及对RLVR(可验证奖励强化学习)有效性的思考,强调了在评估RL效果时需要更严格的基线和prompt优化。 (来源: menhguin, AndrewLampinen, lateinteraction, madiator, vikhyatk, matei_zaharia, hrishioa, iScienceLuvr)
“Vibe Coding”引发讨论,强调安全默认值和技术债务风险: “Vibe coding”(氛围编程,指更多依赖直觉和快速迭代而非严格规范的编程方式)成为社区讨论热点。Replit CEO Amjad Masad认为这种方式赋能了新开发者,但平台必须提供安全的默认配置。同时,Pedro Domingos评论称“氛围编程是技术债务的哥斯拉”,暗示其可能带来的长期维护问题。Semafor报道了Lovable因RLS策略配置不当导致的安全漏洞,进一步引发对该编程方式安全性的关注。 (来源: alexalbert__, amasad, pmddomingos, gfodor)
AI在软件工程中的作用:效率提升与人类程序员的不可替代性: Redis之父Salvatore Sanfilippo分享经验称,尽管AI(如Gemini 2.5 Pro)在编程辅助、代码审查和思路验证方面有价值,但人类程序员在创造性问题解决、打破常规思维方面仍远超AI。社区讨论进一步指出,AI目前更像“智能橡皮鸭”,能辅助思考,但其建议需谨慎评估,且过度依赖可能削弱开发者的核心能力。Mitchell Hashimoto也分享了LLM帮助他快速定位Clang编译问题的案例,节省了大量时间。 (来源: mitchellh, 36氪)
AI是否会大规模取代工作岗位引发持续关注: Anthropic CEO Dario Amodei预测AI可能导致一半入门级办公室职位消失,而Mark Cuban则认为AI将创造新公司和新岗位。社区对此讨论激烈,有观点认为客服、初级文案、部分开发等工作已受影响,但AI在创意、复杂决策和需要高度人际互动的领域尚难取代人类。普遍共识是AI将改变工作性质,人类需适应并提升与AI协作的能力。 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ArtificialInteligence)
AI Agent(智能体)成为下一代交互入口,引发大厂竞逐: 微软、谷歌、OpenAI、阿里、腾讯、百度、酷开等国内外科技公司纷纷布局AI Agent。智能体能深度思考、自主规划、决策并执行复杂任务,被视为继搜索引擎、App之后的下一代交互入口。目前已形成三股主要力量:以OpenAI、百度为代表的技术生态构建者;以微软、阿里云为代表的垂直场景企业服务商;以及以华为、酷开为代表的软硬件终端厂商。 (来源: 36氪)

💡 其他
中国AI出海加速,从产品输出转向生态构建: 《中国AI的跨洋生长》报告指出,中国AI企业出海已进入规模化快车道,76%集中在应用层面。出海路径从早期工具型应用,发展到中期结合技术优势输出行业解决方案,现阶段则着重于技术生态出海,推动技术标准与开源协作。AI出海呈现“由近及远”的梯度渗透,并面临本地化、合规伦理及品牌营销等挑战。 (来源: 36氪)

美国能源部将AI竞赛喻为“新曼哈顿计划”,强调美国将获胜: 美国能源部在宣布下一代超级计算机“Doudna”时,将AI的发展竞争称为“我们这个时代的曼哈atan计划”,并宣称美国将在这场竞赛中获胜。此番言论引发社区关于大国科技竞争、AI伦理及国际合作的讨论。 (来源: gfodor, teortaxesTex, andrew_n_carr, npew, jpt401)
AI在内容创作领域的进步引发关于“真实性”和“创意”的思考: 社区讨论了AI在时尚设计、漫画创作、视频生成等领域的应用。一方面,AI能够快速生成多样化的内容,甚至将几年前的漫画作品具象化为视频;另一方面,这些生成内容有时显得怪异或缺乏深度。这引发了关于AI生成内容是否“更好”、以及人类创意在AI时代将扮演何种角色的思考。 (来源: Reddit r/ChatGPT, Reddit r/artificial)
