关键词:RLHF, RLAIF, Qwen2.5-Math-7B, MATH-500, 随机奖励, 错误奖励, 模型性能, 强化学习, RLHF/RLAIF的未来, 随机奖励提升模型性能, 错误奖励训练Qwen2.5-Math-7B, MATH-500测试集, 强化学习信号学习
🔥 聚焦
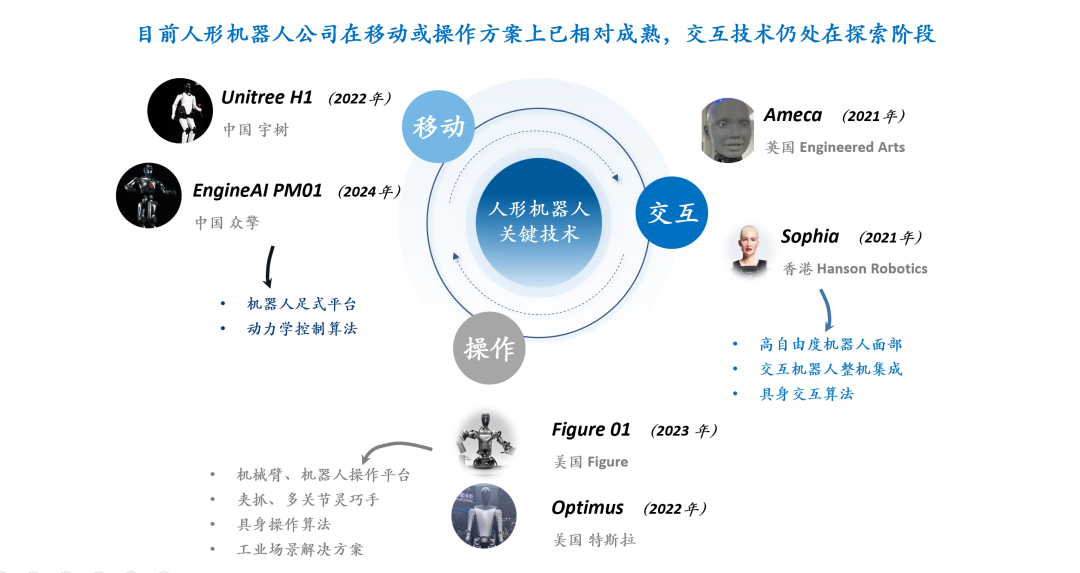
RLHF/RLAIF的未来:随机/错误奖励也能提升模型性能? : Stella Li的实验表明,使用随机奖励或不正确奖励训练Qwen2.5-Math-7B模型,在MATH-500测试集上分别提升了21%和25%,接近使用真实奖励28.8%的提升效果。natolambert转发的Rulin Shao的研究也发现,RLVR(Reinforcement Learning from Verifier Reward)在使用虚假奖励时,Olmo模型代码使用增多但性能下降,而阻止其使用代码反而提升性能。这些发现挑战了传统RLHF/RLAIF中对高质量人类偏好数据的依赖,暗示模型可能通过奖励信号学习探索更广泛的策略空间,即使奖励本身不完美,也能激发模型潜在能力或优化现有行为。这可能为降低对昂贵人工标注的依赖、探索更高效的模型对齐方法开辟新途径,但需警惕模型学到错误行为的风险。 (来源: natolambert, teortaxesTex, DhruvBatraDB, Francis_YAO_, raphaelmilliere)
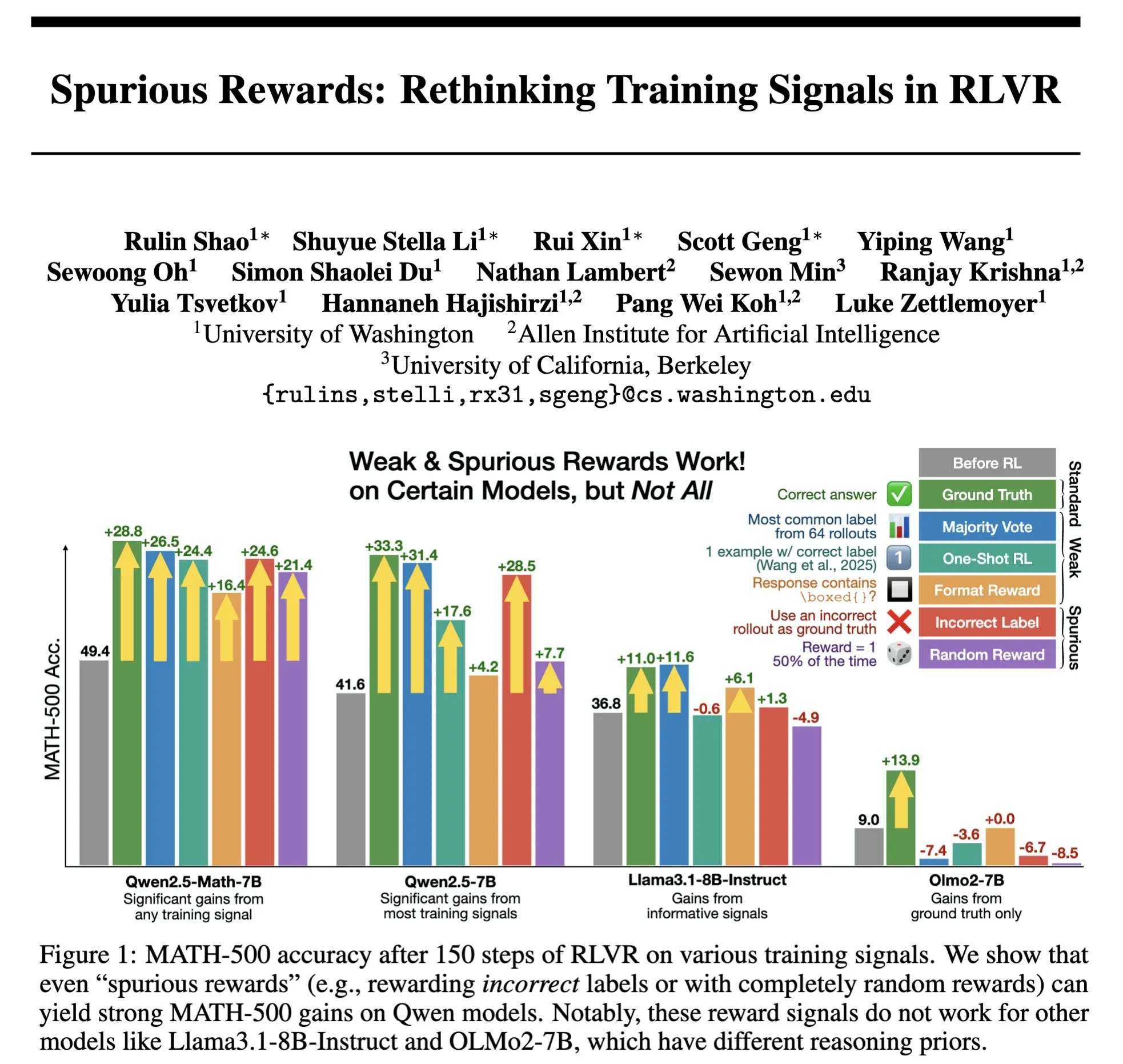
Hazy Research发布Low-Latency-Llama Megakernel:单CUDA核心实现Llama 1B推理 : Hazy Research推出了Low-Latency-Llama Megakernel,能在单个CUDA核心内完成Llama 1B模型的整个前向传播过程。该技术通过将计算整合到单一内核中,消除了传统序列化内核调用带来的同步边界,从而优化了计算和内存的调度,实现了更低的延迟。Andrej Karpathy对此表示高度赞赏,认为这是实现计算与内存最佳编排的唯一途径。这一进展对边缘计算、实时AI应用等对延迟有严格要求的场景具有重要意义,有望推动更高效、更敏捷的小型语言模型部署。 (来源: karpathy, teortaxesTex, charles_irl, simran_s_arora)
DeepSeek启元发布rStar-Coder:构建大规模已验证代码推理数据集,显著提升小模型代码能力 : 微软与DeepSeek的研究人员推出了rStar-Coder项目,通过构建一个包含41.8万个竞赛级代码问题、58万个长推理解决方案及丰富测试用例的大规模已验证数据集,旨在解决当前代码推理领域高质量、高难度数据集稀缺的问题。该项目通过综合利用现有编程竞赛问题与oracle解法合成新问题、设计可靠的输入输出测试用例生成管线,并用测试用例验证高质量长推理方案,从而提升LLM的代码推理能力。实验表明,使用rStar-Coder数据集训练的Qwen模型(1.5B-14B)在多个代码推理基准上表现优异,例如Qwen2.5-7B在LiveCodeBench上准确率从17.4%提升至57.3%,超越了o3-mini (low);在USACO上,7B模型也超越了更大的QWQ-32B。 (来源: HuggingFace Daily Papers)
中国科学院自动化所提出AutoThink:让大模型自主决定是否“深度思考” : 针对大语言模型在简单问题上仍进行冗长推理的“过度思考”现象,中国科学院自动化研究所与鹏城实验室联合提出AutoThink方法。该方法通过在提示词中加入“省略号” (…) 并结合三阶段强化学习(模式稳定、行为优化、推理剪枝),使模型能根据题目难度自主选择是否进行深度思考及思考多少。实验表明,AutoThink能提升DeepSeek-R1等模型在数学基准测试上的性能,同时大幅减少推理Token消耗。例如,在DeepScaleR上能额外节省10%的Token。此研究旨在让模型实现“按需思考”,提升推理效率和准确性的平衡。 (来源: 36氪, _akhaliq)

Sakana AI推出Sudoku-Bench,揭示顶尖大模型在“变异数独”推理上的短板 : Transformer作者Llion Jones的创业公司Sakana AI发布了Sudoku-Bench,一个包含从4×4到复杂9×9现代“变异数独”的基准测试,旨在评估AI的创造性多步推理能力。测试结果显示,包括Gemini 2.5 Pro、GPT-4.1、Claude 3.7在内的顶尖大模型,在无辅助情况下总体正确率低于15%,在9×9现代数独中,o3 Mini High正确率仅2.9%。这表明模型在面对需要真正逻辑推理而非模式匹配的新颖问题时表现不佳,常出现错误解答、放弃或误判规则。NVIDIA CEO黄仁勋认为此类谜题有助于提升AI推理。Sakana AI还发布了相关训练数据,包括与著名数独频道合作的解题过程记录。 (来源: 36氪)

🎯 动向
Meta重组AI团队,FAIR核心成员流失引关注 : Meta宣布重组AI团队,将其划分为由Connor Hayes领导的AI产品团队和由Ahmad Al-Dahle与Amir Frenkel共同领导的AGI基础部门。前者专注C端产品,后者聚焦Llama等基础模型研发。值得注意的是,基础人工智能研究部门FAIR仍保持独立,但部分多媒体团队并入AGI基础部门。此次调整旨在提升开发速度和灵活性。然而,Meta正面临Llama 4反响平平、开源领域竞争加剧以及核心人才流失的挑战。最初参与Llama研发的14位作者中已有11位离职,其中多人加入或创立了Mistral AI等竞争对手。FAIR实验室也经历了领导层变动和研究方向的调整,引发了对其在公司内部地位及未来创新能力的担忧。 (来源: 36氪)

Google DeepMind发布SignGemma:手语翻译新模型 : Google DeepMind宣布推出SignGemma,一款号称是其目前最强大的手语到口语文本翻译模型。该模型预计将于今年晚些时候加入Gemma模型家族,并以开源形式发布。SignGemma的推出旨在为包容性技术开辟新的可能性,提升手语使用者的沟通效率和便捷性。Google DeepMind邀请用户提供反馈并参与早期测试。 (来源: GoogleDeepMind, demishassabis)
腾讯混元发布HunyuanPortrait模型权重,可将静态肖像转为动态视频 : 腾讯混元团队开源了其图生视频模型HunyuanPortrait的模型权重,允许用户下载并在本地使用。该模型专注于将静态的人物肖像图片转换为动态视频,适用于游戏角色、虚拟主播、数字人、智能导购等多种应用场景,能够让人脸图像动起来,增加交互的生动性和真实感。相关的模型、代码仓库和论文均已发布。 (来源: karminski3, Reddit r/LocalLLaMA)

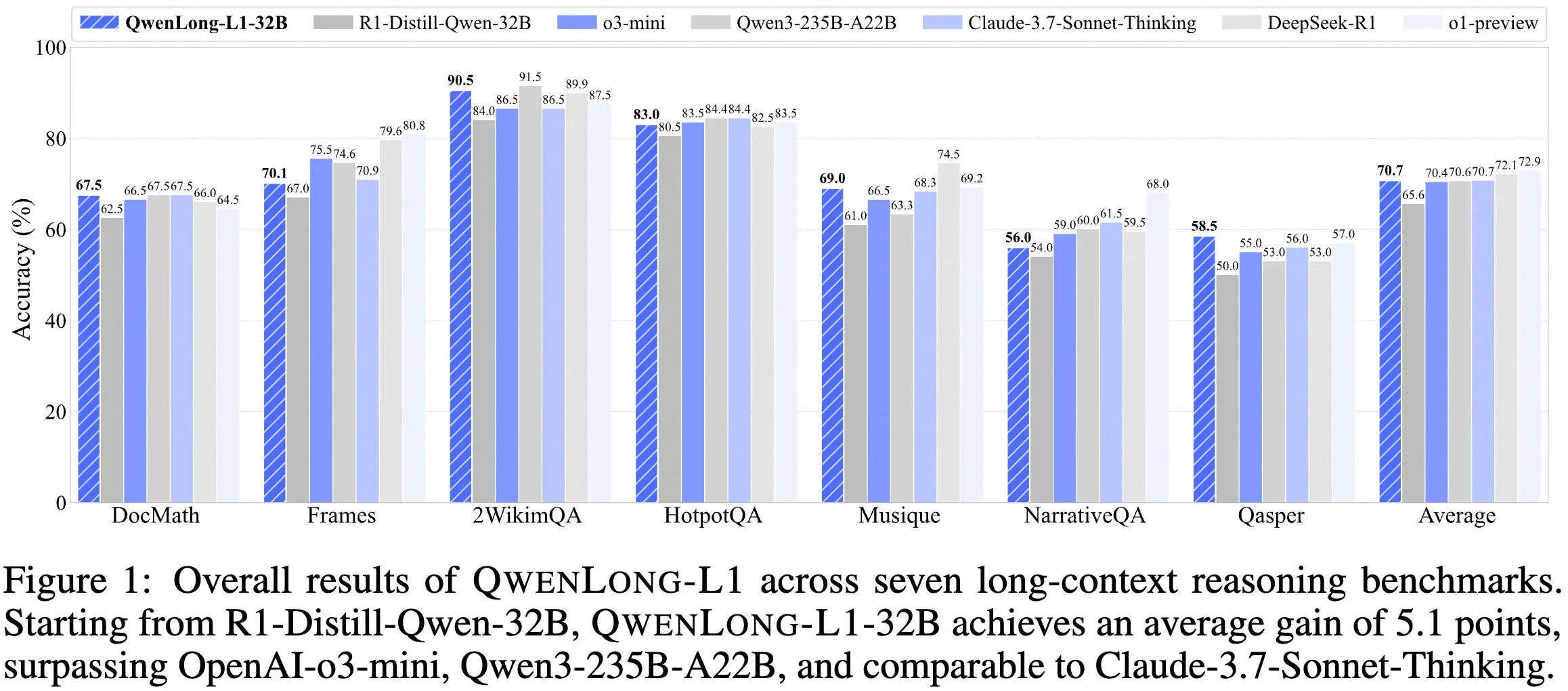
QwenDoc团队发布长上下文推理模型QwenLong-L1-32B : QwenDoc团队推出基于强化学习训练的128K长上下文推理模型QwenLong-L1-32B。该模型基于DeepSeek-R1-Distill-Qwen-32B微调,在2WikiMultihopQA多跳推理测试集上得分90.5,较原模型提升6.5分,强调在长上下文中不仅能找到内容,还能串联线索进行推理。尽管128K上下文长度并非目前最长,但其突出的推理能力为处理复杂长文档提供了新选择。模型、论文和代码库已公开。 (来源: karminski3)
港科大与Apple等机构合作推出Laser系列方法,优化大模型推理效率与准确性 : 港科大、港城大、滑铁卢大学及Apple的研究人员提出Laser系列方法(包括Laser-D、Laser-DE),旨在解决大语言模型(LRM)在简单问题上过度消耗tokens进行推理的问题。该方法通过统一的长度奖励设计框架、基于目标长度和阶跃函数的奖励以及动态难度感知机制,在AIME24等复杂数学推理基准上,实现了在减少63% Tokens使用量的同时,性能提升6.1点。研究发现,训练后的模型冗余“自我反思”减少,思考模式更健康,有效平衡了模型推理的效率和准确率。 (来源: 36氪)

Anthropic Claude免费版现已支持网页搜索功能 : Anthropic宣布,其AI助手Claude的免费版本用户现在可以使用网页搜索功能。这意味着Claude在回答问题时,可以从互联网获取最新的信息来增强其回复的相关性和准确性。官方表示,每个包含搜索结果的回复都会提供内联引用,方便用户核实信息来源。 (来源: AnthropicAI)
PKU-DS-LAB发布FairyR1:基于DeepSeek-R1-Distill-Qwen-32B微调的32B推理模型 : 北京大学数据科学实验室(PKU-DS-LAB)推出了FairyR1,这是一个32B参数的推理模型,采用Apache 2.0许可证。该模型通过“蒸馏再合并”的方法,在仅使用5%参数的情况下,据称能达到更大模型的性能。FairyR1是基于DeepSeek-R1-Distill-Qwen-32B进行微调的,其训练数据也已在Hugging Face Hub上提供。这项工作延续了TinyR1的研究思路,通过积极过滤数据集(约1万条轨迹),分别对数学和代码进行SFT,并使用Arcee Fusion进行模型合并。 (来源: huggingface, teortaxesTex, stablequan)
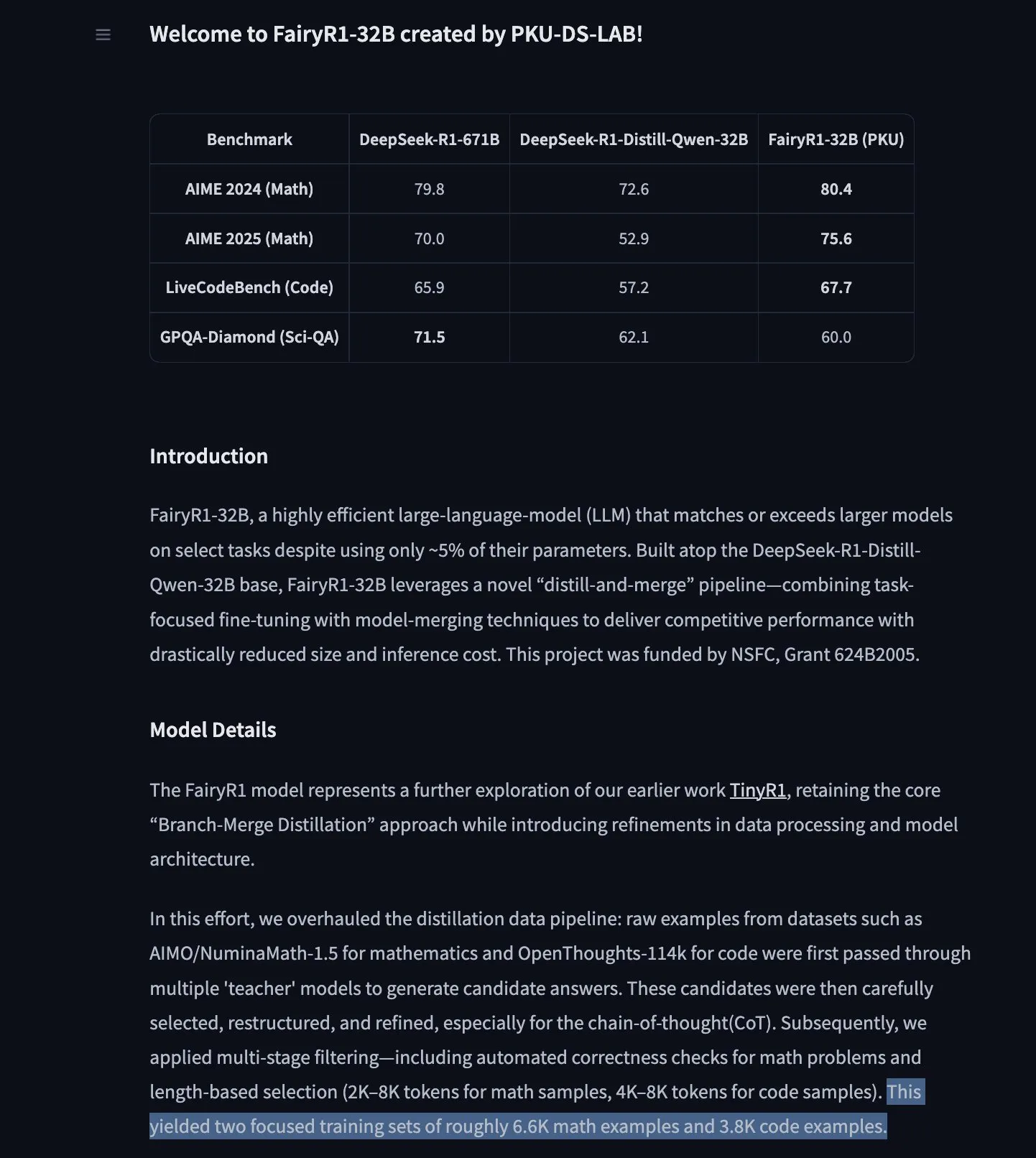
谷歌TimesFM时间序列预测模型登陆Hugging Face Transformers : 谷歌的TimesFM模型现已集成到Hugging Face Transformers库中。这是一个类似GPT的模型,预训练数据包含了来自Google Trends、维基百科页面浏览量等多种来源的1000亿个真实时间点数据。据称,TimesFM在零样本(zero-shot)预测任务上的表现优于专门微调过的模型,为时间序列分析提供了新的强大工具。 (来源: huggingface)
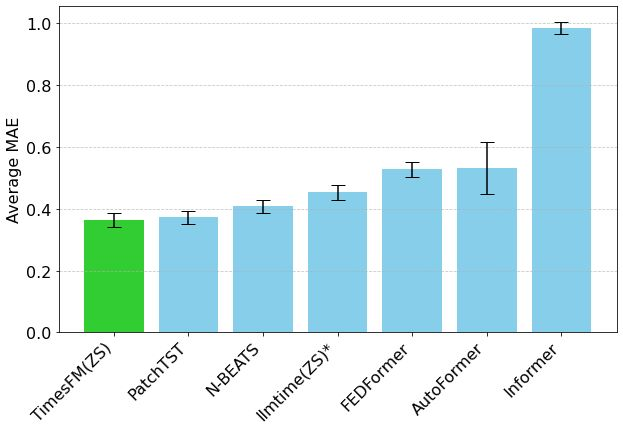
Hugging Face推出Mixture of Thoughts:精选通用推理数据集 : Hugging Face研究员Lewis Tunstall等人发布了“Mixture of Thoughts”数据集。该数据集从超过100万个公开数据样本中,通过大量消融实验精心筛选出约35万个样本,专注于通用推理能力。使用该混合数据集训练的模型,在数学、代码以及科学基准(如GPQA)上的表现均能达到或超过DeepSeek的蒸馏模型。研究验证了Phi-4-reasoning中提出的“可加性”方法论的有效性,即可以独立优化每个推理领域的数据混合,然后整合进行最终训练。 (来源: huggingface)
字节跳动发布BAGEL-7B:图文理解与生成兼备的全方位模型 : 字节跳动推出了BAGEL-7B,这是一款能够同时理解和生成图像与文本的全方位(omni)模型。此外,他们还发布了Dolphin,一个专注于文档解析的视觉语言模型(VLM)。这些模型的开源将为多模态研究和应用提供新的工具和可能性。 (来源: huggingface, TheTuringPost)

谷歌发布Gemini 2.5 Flash Preview,支持原生音频输出 : 谷歌AI开发者宣布,Gemini 2.5 Flash Preview现已通过Live API支持原生音频输出,旨在提供无缝、自然的口语交互和更强的语音控制能力。此外,该音频模型的一个新的实验性“思考”版本也已推出,支持更复杂任务的推理能力。同时,Gemini API的输出也开始展示“思维摘要”,让用户了解模型的思考过程,但目前并非完整的推理链。 (来源: algo_diver, op7418)
论文探讨Transformer在填充空白token时的表达能力 : 一篇新研究探讨了通过在Transformer输入中填充空白token(一种测试时计算形式)是否能增强LLM的计算能力。该研究与Ashish_S_AI合作,对带有填充的Transformer的表达能力进行了精确刻画,为理解和优化LLM的计算机制提供了新视角。 (来源: teortaxesTex)

新研究提出Sci-Fi框架:通过对称约束改进视频帧插值 : 针对当前视频帧插值(Frame Inbetweening)方法在融合始末帧约束时可能存在控制强度不对称的问题,一篇新论文提出了Sci-Fi(Symmetric Constraint for Frame Inbetweening)框架。该方法旨在通过为训练规模较小的约束(如结束帧)应用更强的注入机制(基于轻量级模块EF-Net),来实现始末帧约束的对称性,从而在生成的中间帧中产生更和谐的过渡效果,避免运动不一致或外观崩塌。 (来源: HuggingFace Daily Papers)
论文提出Paper2Poster:从科研论文到多模态海报的自动化流程 : 针对学术海报制作的挑战,研究者推出了首个海报生成基准和评估指标套件Paper2Poster,包含论文与作者设计的海报对,并从视觉质量、文本连贯性、整体评估和PaperQuiz(衡量海报传达核心内容能力)等方面进行评估。同时提出了PosterAgent,一个自上而下、视觉在环的多智能体流程,包括解析器(提取资产)、规划器(文本视觉对齐和布局)和画师-评论员循环(渲染和反馈优化)。基于Qwen-2.5等开源模型的变体在多数指标上优于GPT-4o驱动的系统,且token消耗减少87%,能以极低成本将22页论文转为可编辑的.pptx海报。 (来源: HuggingFace Daily Papers)
论文提出Frame In-N-Out:实现无界可控的图像到视频生成 : 针对视频生成中的可控性、时间一致性和细节合成等挑战,一篇新论文聚焦于“Frame In and Frame Out”这一电影拍摄技术,旨在让用户能够控制图像中的对象自然离开场景,或引入新的身份参考进入场景,并由用户指定的运动轨迹引导。为此,研究者引入了一个新的半自动标注数据集、一个全面的评估协议,以及一个高效的身份保持、运动可控的视频Diffusion Transformer架构。实验表明,该方法显著优于现有基线。 (来源: HuggingFace Daily Papers)
新研究提出Active-O3:通过GRPO赋予多模态大语言模型主动感知能力 : 针对多模态大语言模型(MLLM)在主动感知(active perception)方面的探索不足,研究者提出了Active-O3框架。该框架基于GRPO(Group Relative Policy Optimization)的纯强化学习训练,旨在赋予MLLM主动选择观察位置和方式以收集任务相关信息的能力。研究者首先系统定义了基于MLLM的主动感知任务,并指出GPT-o3的放大搜索策略是主动感知的一个特例但效率和准确性不足。Active-O3通过建立全面的基准套件,在通用开放世界任务(如小物体和密集物体定位)及特定领域场景(如遥感、自动驾驶中的小物体检测,细粒度交互分割)中进行评估,并展示了其在V* Benchmark上的强大零样本推理能力。 (来源: HuggingFace Daily Papers)
论文提出MME-Reasoning:一个全面的MLLM逻辑推理能力基准测试 : 针对现有基准在评估多模态大语言模型(MLLM)逻辑推理能力方面的不足,研究者推出了MME-Reasoning。该基准覆盖了归纳、演绎和溯因三种主要的逻辑推理类型,并精心筛选数据以确保问题能有效评估推理能力而非感知技能或知识广度。评估结果显示,即使是最先进的MLLM在全面的逻辑推理评估中也表现出局限性,在不同推理类型上存在性能不平衡。研究还分析了“思考模式”和基于规则的强化学习等方法对推理能力的影响,为理解和评估MLLM的推理能力提供了系统性见解。 (来源: HuggingFace Daily Papers)
GraLoRA:通过粒度化低秩自适应提升参数高效微调性能 : 针对LoRA在提升秩时出现的过拟合及性能瓶颈问题,研究者提出了GraLoRA(Granular Low-Rank Adaptation)。该方法将权重矩阵划分为子块,每个子块拥有独立的低秩适配器,旨在解决LoRA结构性瓶颈导致的梯度纠缠和传播失真问题。GraLoRA在几乎不增加计算或存储成本的情况下,有效提升了模型的表达能力,更接近全量微调的效果。在代码生成和常识推理基准上的实验表明,GraLoRA在不同模型大小和秩设置下均优于LoRA及其他基线,例如在HumanEval+上Pass@1绝对增益高达8.5%。 (来源: HuggingFace Daily Papers)
SoloSpeech:级联生成管道增强目标语音提取的清晰度和质量 : 针对目标语音提取(TSE)中现有判别模型易引入伪影、降低自然度,而生成模型在感知质量和清晰度上不足的问题,研究者提出了SoloSpeech。这是一个新颖的级联生成管道,集成了压缩、提取、重建和校正过程。其特点是采用了一个无说话人嵌入的目标提取器,利用提示音频潜空间的条件信息,并将其与混合音频的潜空间对齐以防止不匹配。在Libri2Mix数据集上的评估表明,SoloSpeech在目标语音提取和语音分离任务中达到了新的SOTA水平,并在域外数据和真实场景中表现出优异的泛化能力。 (来源: HuggingFace Daily Papers)
新研究探索通过文本引导向量提升多模态大语言模型视觉理解能力 : 一项新研究探讨了是否可以利用多模态大语言模型(MLLM)的纯文本LLM骨干网络衍生的引导向量(通过稀疏自动编码器SAE、均值漂移和线性探测等方法获得)来提升其视觉理解能力。研究发现,文本衍生的引导向量能够持续增强不同MLLM架构在多种视觉任务上的多模态准确性。特别地,均值漂移方法在CV-Bench上将空间关系准确率提升高达7.3%,计数准确率提升高达3.3%,表现优于提示方法,并对分布外数据集展现出强大的泛化能力。这表明文本引导向量是一种强大且高效的机制,能以最小的额外数据收集和计算开销增强MLLM的视觉基础。 (来源: HuggingFace Daily Papers)
论文提出DiSA:通过扩散步骤退火加速自回归图像生成 : 针对MAR、FlowAR等自回归模型采用扩散采样提升图像质量但导致推理效率低的问题,一篇新论文提出了DiSA(Diffusion Step Annealing)方法。该方法基于一个观察:随着自回归过程中生成token的增多,后续token的分布更受约束,采样更容易。DiSA是一种无需训练的方法,它在生成更多token时逐渐减少扩散步骤(例如从初始50步降至后期5步)。该方法与现有为扩散本身设计的加速方法互补,实现简单,能在MAR和Harmon上提速5-10倍,在FlowAR和xAR上提速1.4-2.5倍,同时保持生成质量。 (来源: HuggingFace Daily Papers)
论文提出CASS:Nvidia到AMD的GPU代码翻译数据集、模型与基准 : 研究者推出了CASS,首个用于跨架构GPU代码翻译的大规模数据集和模型套件,目标涵盖源码级(CUDA <-> HIP)和汇编级(Nvidia SASS <-> AMD RDNA3)翻译。数据集包含7万个已验证的跨主机和设备的代码对。基于此资源训练的CASS系列领域特定语言模型,在源码翻译上达到95%准确率,汇编翻译达到37.5%准确率,显著优于GPT-4o、Claude等商业基线。生成的代码在超过85%的测试案例中匹配原生性能。同时发布的CASS-Bench是一个包含16个GPU领域和真实执行结果的基准测试。所有数据、模型和评估工具均已开源。 (来源: HuggingFace Daily Papers)
论文分析视觉语言模型中的口头校准能力 : 一项研究全面评估了视觉语言模型(VLM)通过自然语言表达置信度(即口头不确定性)的有效性。研究跨越三类模型、四个任务领域和三个评估场景,结果显示当前VLM在多种任务和设置中常表现出明显的校准失误。值得注意的是,视觉推理模型(即用图像思考的模型)始终表现出更好的校准性,表明特定模态的推理对可靠的不确定性估计至关重要。为应对校准挑战,研究者引入了“视觉置信度感知提示”(Visual Confidence-Aware Prompting),一种两阶段提示策略,旨在改善多模态设置下的置信度对齐。 (来源: HuggingFace Daily Papers)
论文追踪大语言模型中语用能力的涌现 : 当前LLM在社交智能任务中展现出新兴能力,但其在训练过程中如何获得语用能力尚不清楚。一篇新论文引入了ALTPRAG数据集,基于语用学概念“选项”(alternatives)设计,评估不同训练阶段的LLM能否准确推断细微的说话者意图。通过系统评估22个LLM(涵盖预训练、SFT和偏好优化阶段),结果显示即使是基础模型也对语用线索表现出显著敏感性,且随模型和数据规模增加而持续改进。SFT和RLHF进一步提升了认知语用推理能力。这些发现强调语用能力是LLM训练中涌现的组合属性,为模型对齐人类交际规范提供了新见解。 (来源: HuggingFace Daily Papers)
Video-Holmes基准发布:评估MLLM在复杂视频推理中的“福尔摩斯式”思维 : 针对现有视频基准主要评估视觉感知和定位能力,未能充分捕捉复杂推理需求的现状,研究者推出了Video-Holmes基准。该基准受福尔摩斯推理过程启发,包含从270部手动标注的悬疑短片中提取的1837个问题,跨越7个精心设计的任务。每个任务要求模型主动定位并连接散布在不同视频片段中的多个相关视觉线索。对SOTA MLLM的评估显示,尽管模型在视觉感知上表现出色,但在信息整合方面存在显著困难,常错过关键线索。例如,表现最好的Gemini-2.5-Pro准确率仅为45%。 (来源: HuggingFace Daily Papers)
MME-VideoOCR基准发布:评估多模态LLM在视频场景中的OCR能力 : 尽管多模态大语言模型(MLLM)在静态图像OCR方面取得了显著进展,但在视频OCR中的效果因运动模糊、时间变化和视觉效果等因素而减弱。为指导实用MLLM的训练,研究者推出了MME-VideoOCR基准,涵盖广泛的视频OCR应用场景。该基准包含10个任务类别(25个独立任务),覆盖44种不同场景,不仅包括文本识别,还涉及对视频中文本内容的更深层次理解和推理。基准包含1464个不同分辨率、宽高比和时长的视频,以及2000个精心策划的人工标注问答对。对18个SOTA MLLM的评估显示,即便是表现最好的Gemini-2.5 Pro,准确率也仅为73.7%,暴露了现有模型在处理需要整体视频理解的任务时的局限性。 (来源: HuggingFace Daily Papers)
MetaMind:通过元认知多智能体系统建模人类社交思维 : 为弥合大型语言模型(LLM)在处理人类交流中固有的模糊性和情境细微差别方面的不足,研究者推出了MetaMind,一个受心理学元认知理论启发的多智能体框架,旨在模拟类人社交推理。MetaMind将社交理解分解为三个协作阶段:(1)心智理论智能体生成用户心理状态(如意图、情感)的假设;(2)领域智能体使用文化规范和伦理约束来完善这些假设;(3)响应智能体生成情境适当的响应,同时验证与推断意图的一致性。该框架在三个具有挑战性的基准测试中取得了SOTA性能,在真实社交场景中提升35.7%,在心智理论推理中提升6.2%,并首次使LLM在关键心智理论任务上达到人类水平。 (来源: HuggingFace Daily Papers)
Sparse VideoGen2:通过语义感知排列和稀疏注意力加速视频生成 : 针对基于Diffusion Transformers (DiT) 的视频生成模型在处理长视频时面临的显著延迟和高内存成本问题,研究者提出了SVG2框架。该框架通过语义感知排列(使用k-means根据语义相似性聚类和重新排序token)来最大化关键token识别的准确性并最小化计算浪费,从而在生成质量和效率之间实现帕累托前沿的权衡。SVG2还集成了top-p动态预算控制和定制内核实现,在HunyuanVideo和Wan 2.1上分别实现了高达2.30倍和1.89倍的加速,同时保持了较高的PSNR。 (来源: HuggingFace Daily Papers)
OmniConsistency:从成对风格化数据中学习风格无关的一致性 : 为解决扩散模型在图像风格化中面临的复杂场景一致性保持(特别是身份、构图和细节)以及图生图流程中风格LoRA导致的风格退化两大挑战,研究者提出了OmniConsistency。这是一个利用大规模扩散变换器(DiT)的通用一致性插件。其贡献包括:(1) 一个基于对齐图像对训练的上下文一致性学习框架,以实现鲁棒的泛化;(2) 一个两阶段渐进式学习策略,将风格学习与一致性保持解耦,以减轻风格退化;(3) 一个完全即插即用的设计,与Flux框架下的任意风格LoRA兼容。实验表明,OmniConsistency显著增强了视觉连贯性和美学质量,达到了与商业SOTA模型GPT-4o相当的性能。 (来源: HuggingFace Daily Papers)
ImgEdit:统一的图像编辑数据集与基准测试 : 为解决开源图像编辑模型落后于专有模型的问题(主要由于高质量数据有限和基准不足),研究者推出了ImgEdit。这是一个大规模、高质量的图像编辑数据集,包含120万个精心策划的编辑对,涵盖新颖复杂的单轮编辑和具挑战性的多轮任务。为确保数据质量,采用了多阶段流程,集成了前沿的视觉语言模型、检测模型、分割模型以及特定任务的修复程序和严格的后处理。基于ImgEdit训练的编辑模型ImgEdit-E1在多项任务上优于现有开源模型。同时推出的ImgEdit-Bench基准用于评估图像编辑在指令遵循、编辑质量和细节保留方面的性能。 (来源: HuggingFace Daily Papers)
论文提出通过引导目标原子实现LLM中稳健的行为控制 : 为实现对语言模型生成的精确控制以确保安全性和可靠性,一篇新论文提出了“引导目标原子”(Steering Target Atoms, STA)方法。该方法旨在分离和操纵解耦的知识组件,以增强安全性,尤其是在对抗性场景中展现出优越的鲁棒性和灵活性。研究者认为,尽管提示工程和引导常用于干预模型行为,但模型参数的高度纠缠限制了控制精度并可能导致副作用。STA通过利用稀疏自动编码器(SAE)解耦高维空间中的知识,并对其进行引导,从而实现更精确的行为控制。实验证明了该方法的有效性,并已应用于大型推理模型,证实了其在精确推理控制方面的潜力。 (来源: HuggingFace Daily Papers)
论文提出SeePhys基准:评估基于视觉的物理推理能力 : 研究者推出了SeePhys,一个大规模多模态基准,用于评估LLM在从中学到博士资格考试水平的物理问题上的推理能力。该基准涵盖物理学科的7个基础领域,包含21类高度异构的图表。与以往视觉元素主要起辅助作用的工作不同,SeePhys中75%的问题是视觉必要的,即必须提取视觉信息才能正确解答。广泛评估表明,即使是最先进的视觉推理模型(如Gemini-2.5-pro和o4-mini)在该基准上的准确率也不足60%,揭示了当前LLM在视觉理解方面的根本性挑战,特别是在图表解释与物理推理的严格耦合以及克服对文本线索的认知捷径依赖方面。 (来源: HuggingFace Daily Papers)
VerIPO:通过验证器引导的迭代策略优化提升Video-LLM的长程推理能力 : 针对强化学习应用于视频大语言模型(Video-LLM)在复杂视频推理中面临的数据准备瓶颈和长链思维(CoT)质量不稳定问题,研究者提出了VerIPO(Verifier-guided Iterative Policy Optimization)方法。该方法的核心是一个位于GRPO和DPO训练阶段之间的“Rollout-Aware Verifier”,用于评估推理逻辑,构建高质量的对比数据(包含反思性和上下文一致的CoT)。这些数据驱动高效的DPO阶段,从而提高推理链的长度和上下文一致性。实验结果表明,VerIPO能更快更有效地优化模型,生成更长且上下文一致的CoT,性能超越标准GRPO变体及一些大型指令微调Video-LLM和长推理模型。 (来源: HuggingFace Daily Papers)
OpenS2V-Nexus:用于主体到视频生成的详细基准和百万级数据集 : 为推动主体到视频(S2V)生成技术的发展,研究者提出了OpenS2V-Nexus,它包含(i) OpenS2V-Eval,一个细粒度基准,和(ii) OpenS2V-5M,一个百万级数据集。与现有S2V基准(继承自VBench,侧重全局和粗粒度评估)不同,OpenS2V-Eval专注于模型生成主体一致、外观自然且身份保真度高的视频的能力。为此,OpenS2V-Eval引入了来自7大类S2V的180个提示,包含真实和合成测试数据。此外,为准确对齐人类偏好,研究者提出了三个自动度量指标:NexusScore、NaturalScore和GmeScore,分别量化生成视频中的主体一致性、自然度和文本相关性。基于此,对16个代表性S2V模型进行了全面评估。同时,创建了首个开源大规模S2V生成数据集OpenS2V-5M,包含500万个高质量720P的主体-文本-视频三元组。 (来源: HuggingFace Daily Papers)
论文提出WHISTRESS:通过句子重音检测丰富转录文本 : 针对口语中句子重音对于传达说话者意图的重要性,及其在现有转录系统中的缺失,一篇新论文介绍了WHISTRESS,一种无需对齐的句子重音检测方法。为支持该任务,研究者提出了TINYSTRESS-15K,一个通过全自动流程创建的可扩展合成训练数据集。在该数据集上训练的WHISTRESS模型,在性能上优于现有基线,且无需额外的训练或推理先验输入。值得注意的是,尽管基于合成数据训练,WHISTRESS在多种基准测试中展现出强大的零样本泛化能力。 (来源: HuggingFace Daily Papers)
论文提出InstructPart:带指令推理的任务导向部件分割 : 尽管大型多模态基础模型在多种任务上取得进展,但许多模型将物体视为不可分割的整体,忽略了构成物体的部件。理解这些部件及其相关功能可见性(affordances)对于执行广泛任务至关重要。为此,研究者引入了一个新的真实世界基准InstructPart,包含手工标记的部件分割注释和面向任务的指令,用以评估当前模型在日常情境中理解和执行部件级任务的性能。实验表明,即使对于SOTA的视觉语言模型(VLM),面向任务的部件分割仍然是一个具有挑战性的问题。除基准外,研究者还引入了一个简单基线,通过使用其数据集进行微调,实现了两倍的性能提升。 (来源: HuggingFace Daily Papers)
论文提出混合神经-MPM方法,实现实时交互式流体模拟 : 为解决传统物理方法计算密集、延迟高,以及近期机器学习方法虽降低成本但仍难满足实时交互需求的流体模拟问题,研究者提出了一种新颖的混合方法。该方法集成了数值模拟、神经物理学和生成式控制。其神经物理学通过回退到经典数值求解器的保障机制,共同追求低延迟模拟和高物理保真度。此外,研究者开发了一种基于扩散的控制器,使用逆向建模策略进行训练,以生成用于流体操控的外部动态力场。该系统在多种2D/3D场景、材料类型和障碍物交互中表现出鲁棒性能,实现了高帧率的实时模拟(11~29%延迟),并能通过用户友好的手绘草图引导流体控制。 (来源: HuggingFace Daily Papers)
MMIG-Bench:面向多模态图像生成模型的综合可解释评估基准 : 针对现有评估工具在评价如GPT-4o、Gemini 2.0 Flash和Gemini 2.5 Pro等多模态图像生成器方面的局限性(如T2I基准缺乏多模态条件,定制图像生成基准忽略组合语义和常识),研究者提出了MMIG-Bench。这是一个全面的多模态图像生成基准,包含4850个丰富注释的文本提示和1750个覆盖380个主体(人、动物、物体、艺术风格)的多视角参考图像。MMIG-Bench配备了三级评估框架:(1)低级指标评估视觉伪影和物体身份保持;(2)新颖的方面匹配得分(AMS):一个基于VQA的中级指标,提供细粒度的提示-图像对齐,并与人类判断高度相关;(3)高级指标评估美学和人类偏好。通过MMIG-Bench对17个SOTA模型进行基准测试,并用3.2万个人类评分验证了指标,为架构和数据设计提供了深入见解。 (来源: HuggingFace Daily Papers)
论文提出HRPO:通过强化学习实现混合潜在推理 : 为解决现有潜推理方法与LLM自回归生成特性不兼容及依赖CoT轨迹进行训练的问题,研究者提出了HRPO(Hybrid Reasoning Policy Optimization)。这是一种基于强化学习的混合潜推理方法,它通过可学习的门控机制将先前的隐藏状态整合到采样的token中,并以token嵌入为主进行初始化训练,逐步融入更多隐藏特征。这种设计保持了LLM的生成能力,并激励使用离散和连续表示进行混合推理。此外,HRPO通过token采样为潜推理引入随机性,从而无需CoT轨迹即可进行基于RL的优化。在多种基准上的广泛评估表明,HRPO在知识密集型和推理密集型任务上均优于先前方法。 (来源: HuggingFace Daily Papers)
论文提出NFT方法:在数学推理中连接监督学习与强化学习 : 挑战“自我提升仅限于强化学习(RL)”的普遍观念,一篇新论文提出了负向感知微调(Negative-aware Fine-Tuning, NFT)方法。这是一种监督学习方法,使LLM能够反思其失败并自主改进,无需外部教师。在在线训练中,NFT不丢弃自生成的错误答案,而是构建一个隐式负向策略来建模它们。该隐式策略与用于在正向数据上优化的目标正向LLM参数化相同,从而可以直接在所有LLM的生成上进行策略优化。在7B和32B模型上的数学推理任务实验结果显示,通过额外利用负向反馈,NFT显著优于如拒绝采样微调等监督学习基线,达到甚至超越了GRPO和DAPO等领先的RL算法。研究者进一步证明,在严格的在线策略训练中,NFT和GRPO实际上是等效的。 (来源: HuggingFace Daily Papers)
论文提出Minute-Long Videos with Dual Parallelisms:实现分钟级视频生成 : 针对基于DiT的视频扩散模型在生成长视频时面临的计算延迟和内存成本过高的问题,研究者提出了一种新的分布式推理策略DualParal。该方法的核心思想是将时间帧和模型层并行化到多个GPU上。为解决扩散模型要求帧间噪声水平同步而导致的原始并行性序列化问题,该方法采用分块去噪方案,即通过流水线处理一系列帧块,并逐渐降低噪声水平。每个GPU处理特定的块和层子集,并将先前结果传递给下一个GPU,实现异步计算和通信。此外,通过在每个GPU上实现特征缓存以重用先前块的特征作为上下文,并采用协调的噪声初始化策略,确保全局一致的时间动态性,从而实现快速、无伪影且无限长的视频生成。应用于最新的扩散变换器视频生成器,该方法在8倍RTX 4090 GPU上高效生成1025帧视频,延迟降低高达6.54倍,内存成本降低1.48倍。 (来源: HuggingFace Daily Papers)
🧰 工具
Claude 4 系列模型在编程任务上表现突出,成功解决困扰资深程序员4年的“白鲸bug” : Anthropic最新发布的Claude Opus 4模型,在编程能力上展现了惊人实力。一位拥有30年C++开发经验的前FAANG工程师分享,一个困扰其团队4年、耗费其个人约200小时未能解决的复杂系统bug(在一个特定shader以特定方式使用时出现的边界条件问题),被Claude Opus 4在几个小时内通过约30个prompt成功定位并找出原因。该bug在系统重构前不存在,Opus 4指出是新架构未能兼容旧架构下某种“巧合”支持的非设计性行为所致。此前,GPT-4.1、Gemini 2.5及Claude 3.7均未能解决此问题。这突显了Claude 4在理解复杂代码、进行深度分析和推理方面的强大能力,尤其是在结合Claude Code模式后,能有效协助开发者处理代码重构、bug修复等高级工程任务。 (来源: 36氪, dotey)
LangChain新增对Anthropic Claude新Beta功能的支持 : LangChain宣布已集成Anthropic Claude模型最近发布的四项新Beta功能,包括代码执行、远程MCP连接器、文件API以及扩展的提示缓存。开发者现在可以通过LangChain文档查看相关示例,利用这些新功能构建更强大的AI应用。 (来源: LangChainAI)
LangSmith推出与SDLC集成的提示管理功能 : LangSmith平台增强了其提示工程能力,现在用户不仅可以在LangSmith中测试、版本化和协作处理提示,还可以通过提示更改时的webhook触发器,自动将提示同步到GitHub、外部数据库或启动CI/CD流程。这一功能旨在帮助开发者更紧密地将提示管理整合到软件开发生命周期(SDLC)中。 (来源: LangChainAI)
AutoThink:提升本地LLM推理性能的自适应技术 : CodeLion团队开发了AutoThink技术,通过自适应资源分配和引导向量(steering vectors)显著改善本地LLM的推理性能。AutoThink能分类查询复杂度,动态分配“思考token”(复杂问题分配更多,简单问题分配更少),并使用引导向量指导推理模式。在DeepSeek-R1-Distill-Qwen-1.5B模型上的测试显示,GPQA-Diamond准确率提升43%(从21.72%到31.06%),MMLU-Pro也有提升,且token使用量更少。该技术兼容支持思考token的本地推理模型,代码和研究已发布。 (来源: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
Transformer Lab宣布支持AMD ROCm,可本地训练LLM : Transformer Lab宣布其GUI平台现已支持在AMD GPU上使用ROCm进行大型语言模型的本地训练和微调。团队表示,配置ROCm的过程充满挑战,并将整个过程记录在博客中。目前,该功能已可顺畅使用,用户可以尝试在AMD硬件上进行LLM的开发工作。 (来源: Reddit r/MachineLearning)
开源LLM增强的多智能体系统实现自动化索赔提取与事实核查 : 一个名为“fact-checker”的开源项目利用LLM增强的多智能体系统(MAS)实现自动化索P赔提取、证据验证和事实解决。该项目包含一个浏览器扩展,可以实时对任何AI聊天机器人的响应进行事实核查,有助于辨别AI生成内容的真实性。其代码架构清晰,文档完善,为AI安全和反击错误信息领域提供了有价值的工具。 (来源: Reddit r/MachineLearning)
美团推出无代码产品Nocode,支持复杂多页面应用生成 : 美团发布了一款名为Nocode的Vibe Coding产品,用户可以通过自然语言描述生成复杂的、包含多个页面的完整应用程序,而不仅仅是简单的展示型网页。归藏的测试显示,该工具能够一次性成功构建逻辑复杂的仓库商品管理工具,展示了其在理解复杂需求和生成相应代码方面的能力。 (来源: op7418)
LlamaIndex支持构建自定义多模态嵌入器及与OpenAI风格聊天UI集成 : LlamaIndex发布更新,允许用户构建自定义多模态嵌入器,例如集成AWS Titan Multimodal,并能与Pinecone等向量数据库结合进行高效的文本+图像向量搜索。此外,LlamaIndex工作流现在可以通过几行代码在类似OpenAI的聊天界面中运行,并支持在UI中直接编辑工作流代码的开发模式,提升了RAG应用的开发和交互体验。 (来源: jerryjliu0, jerryjliu0)

TRAE更新增强Agentic编码体验,海外版上线付费订阅 : AI编程工具TRAE迎来更新,优化了Agentic编码体验,使其更适合不愿手动操作的用户。新版TRAE能更好地记住历史对话,自动关联上下文,AI可自动规划编程路径并调用更多工具,提高了编程任务成功率。例如,用户仅需提供空文件夹和prompt,TRAE即可完成创建文件、启动Web服务器(自动处理跨域问题)及在IDE内预览p5.js动画等一系列操作。其海外版已上线付费订阅,首月Pro价格3美元,支持支付宝。 (来源: dotey, karminski3)
掘金社区推出MCP服务,支持前端代码一键发布 : 国内程序员社区掘金上线了MCP(Model-driven Co-programming Protocol)服务,允许开发者将前端代码(如vibe coding生成的网页、游戏)一键发布到掘金平台,方便快速分享和预览。用户需获取掘金MCP的Token,并在Trae、Cursor等工具中进行配置。 (来源: dotey, karminski3)
开源时间追踪工具ActivityWatch作为Rize的替代品受关注 : 用户karminski3在体验了AI时间分析工具Rize(通过分析进程名称判断工作、会议或摸鱼状态,月费20美元)后,发现并推荐了开源替代品ActivityWatch。ActivityWatch功能类似,支持Windows/Mac,且允许用户自定义,被认为是一款优秀的缓解工作焦虑、追踪工作时长的工具。 (来源: karminski3)
开源AI看娃工具ai-baby-monitor发布 : 一款名为ai-baby-monitor的开源项目发布,它使用Qwen2.5 VL模型和vLLM推理框架,允许用户定义规则(如“孩子起床就报警”、“孩子单独呆着就报警”)让AI辅助看护婴儿。开发者强调这仅为辅助工具,不能完全替代人工看护。 (来源: karminski3)
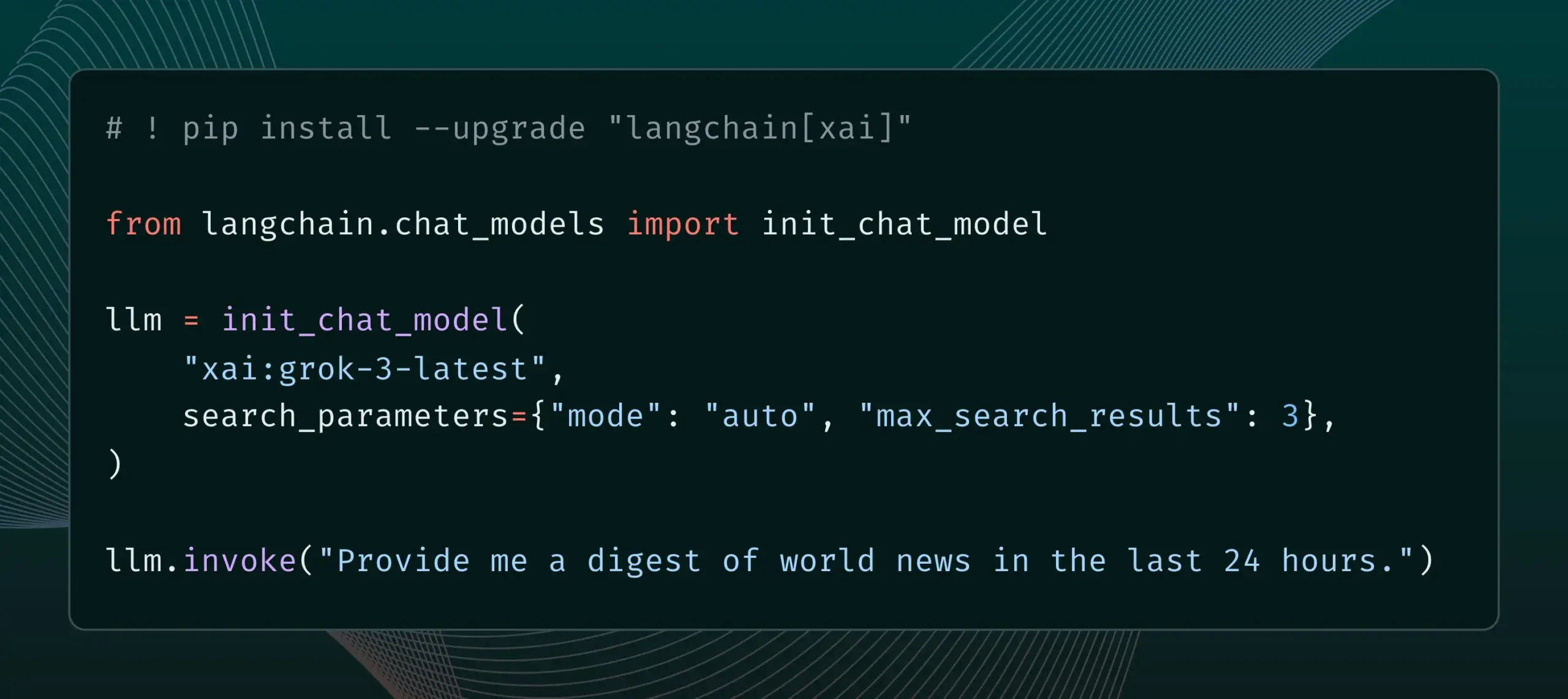
LangChain集成xAI的Live Search功能 : LangChain宣布支持xAI的Live Search功能,该功能允许Grok模型在生成答案时基于网络搜索结果,并提供多种配置选项,如时间段、包含的域名等搜索参数。用户现在可以在LangChain中尝试这一新特性。 (来源: LangChainAI)
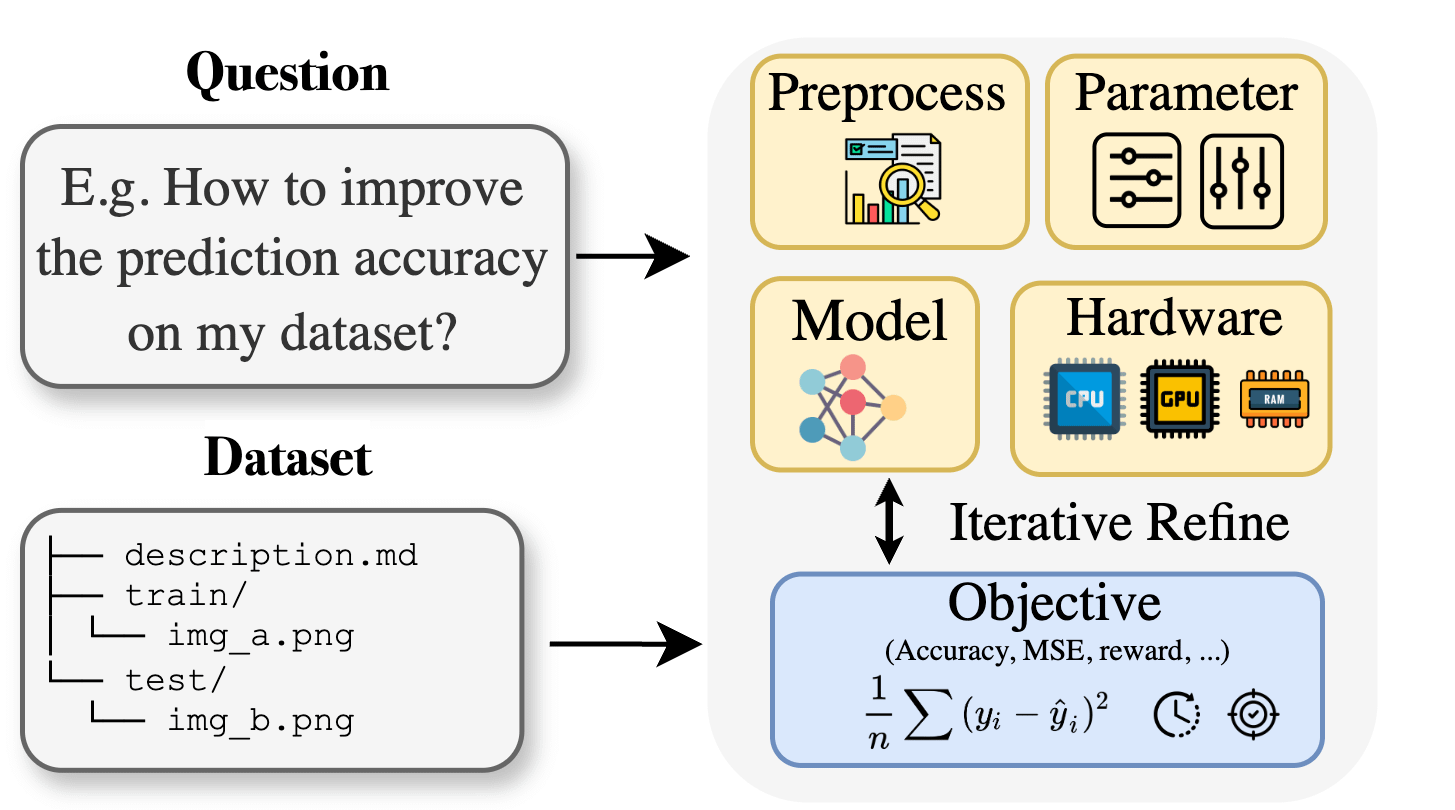
Curie:开源AI科研助手发布AutoML功能,助力跨学科研究 : 针对生物、材料、化学等领域研究人员在应用机器学习时面临的专业知识壁垒,Curie项目推出了新的AutoML功能。Curie旨在成为AI研究实验的协同科学家,通过自动化复杂的ML流程(如算法选择、超参数调整、模型输出解释),帮助研究人员快速测试假设并从数据中提取洞见。例如,Curie在黑色素瘤检测任务中生成了AUC达0.99的模型。该项目已开源,鼓励社区参与贡献。 (来源: Reddit r/LocalLLaMA)
阿里巴巴MNN Chat支持在安卓设备本地运行Qwen 30B-a3b模型 : 阿里巴巴的MNN Chat应用更新至0.5.0版本,现已支持在安卓设备上本地运行Qwen 30B-a3b这类大型语言模型。用户反馈称,在旗舰级芯片和大内存(如OnePlus 13 24G)的设备上可以成功运行,并建议开启mmap设置。然而,也有评论指出,30B参数模型对于大部分手机而言内存和算力要求过高,Gemma 3n可能更适合移动端。 (来源: Reddit r/LocalLLaMA)

📚 学习
新论文提出Lean and Mean Adaptive Optimization:更快更省内存的大模型训练优化器 : ICML 2025录用的一篇论文介绍了一种名为“Lean and Mean Adaptive Optimization via Subset-Norm and Subspace-Momentum”的新优化器。该方法通过Subset-Norm步长和Subspace-Momentum两种互补技术,旨在减少大规模神经网络训练的内存需求并加速训练。与GaLore、LoRA等现有内存高效优化器相比,该方法在节省内存(如预训练LLaMA 1B时比Adam减少80%优化器状态内存)的同时,能以更少的训练token(约一半)达到Adam的验证困惑度,并提供更强的理论收敛保证。 (来源: Reddit r/MachineLearning)
论文提出Force Prompting:使视频生成模型学习和泛化基于物理的控制信号 : 一篇新研究探讨了使用物理力作为视频生成控制信号的可能性,并提出了“力提示”(Force Prompts)。用户可以通过局部点力(如戳植物)或全局风力场(如风吹织物)与图像交互。研究表明,视频生成模型可以从Blender合成的、仅包含少量物体演示的视频中学习并泛化物理力条件,生成对物理控制信号做出逼真响应的视频,而无需在推理时使用3D资产或物理模拟器。视觉多样性和训练时特定文本关键词的使用是实现这种泛化的关键因素。 (来源: HuggingFace Daily Papers)
AnkiHub分享AI标注工作流程,结合FastHTML提升效率 : AnkiHub分享了其AI标注工作流程,并在Hamel Husain和Shreya Shankar的AI评估课程中进行了演示。该工作流程利用FastHTML构建工具,旨在改进商业产品的AI标注效率。相关的教学材料和代码库已在GitHub上发布,展示了如何使用实际生产中的工具来优化AI开发。 (来源: jeremyphoward, HamelHusain)

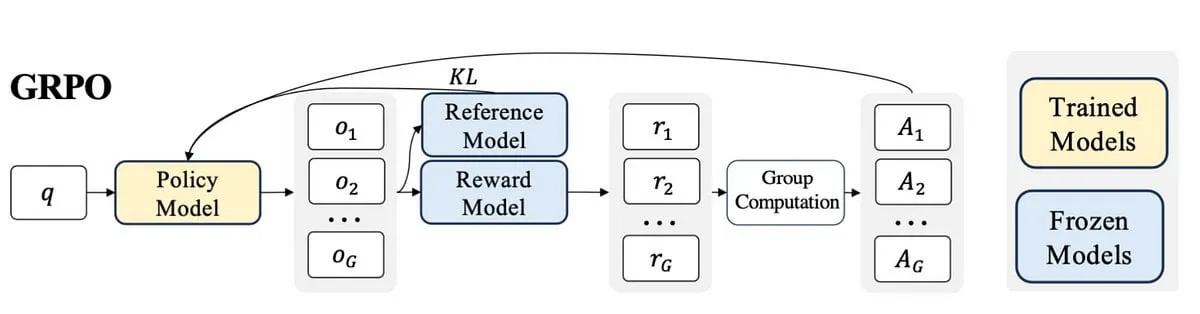
博主撰写PPO到GRPO的学习心得,解释LLM微调中的强化学习概念 : 一位博主分享了其学习强化学习(RL)及其在大型语言模型(LLM)微调中应用的经验,特别是从PPO(Proximal Policy Optimization)到GRPO(Group Relative Policy Optimization)的理解过程。博文旨在解释其在学习初期希望了解的概念,以帮助他人更好地理解这些RL算法如何用于优化LLM。 (来源: Reddit r/MachineLearning)
论文探讨机器的语用思维:追踪大型语言模型中语用能力的涌现 : 一篇新论文研究了大型语言模型(LLM)在训练过程中如何获得语用能力(pragmatic competence),即理解和推断隐含意义、说话者意图等。研究者引入了ALTPRAG数据集,基于语用学中的“替代项”(alternatives)概念,评估不同训练阶段(预训练、监督微调SFT、偏好优化RLHF)的22个LLM。结果表明,即使是基础模型也对语用线索表现出显著敏感性,且随着模型和数据规模的增加而持续改善;SFT和RLHF进一步增强了认知语用推理能力。这表明语用能力是LLM训练中一种涌现的、组合性的特性。 (来源: HuggingFace Daily Papers)
论文探讨视觉工具选择的强化学习框架VisTA : 研究者引入了VisTA (VisualToolAgent),一个新的强化学习框架,使视觉智能体能够根据经验性能动态探索、选择和组合来自不同库的工具。与依赖无训练提示或大规模微调的现有方法不同,VisTA利用端到端强化学习,通过任务结果作为反馈信号,迭代优化复杂的、针对特定查询的工具选择策略。通过GRPO (Group Relative Policy Optimization),该框架使智能体能够自主发现有效的工具选择路径,无需明确的推理监督。在ChartQA、Geometry3K和BlindTest基准上的实验表明,VisTA相比无训练基线取得了显著性能提升,尤其是在分布外样本上。 (来源: HuggingFace Daily Papers)
💼 商业
数据服务公司景联文科技完成数千万Pre-A轮融资,布局公共数据生产运营 : AI数据服务运营商景联文科技近期完成数千万元Pre-A轮融资,由杭州金投集团旗下基金投资。融资将用于布局公共数据生产运营、构建智能化语料工程平台及自建垂直领域高质量标注基地。公司成立于2012年,聚焦公共数据、AI大模型、自动驾驶与医疗等领域,旨在解决公共数据“治理难、供不出、流不动、用不好、安全弱”等痛点,并与华为数据存储合作推出AI数据湖联合解决方案。预计今年营收增速超400%。 (来源: 36氪)
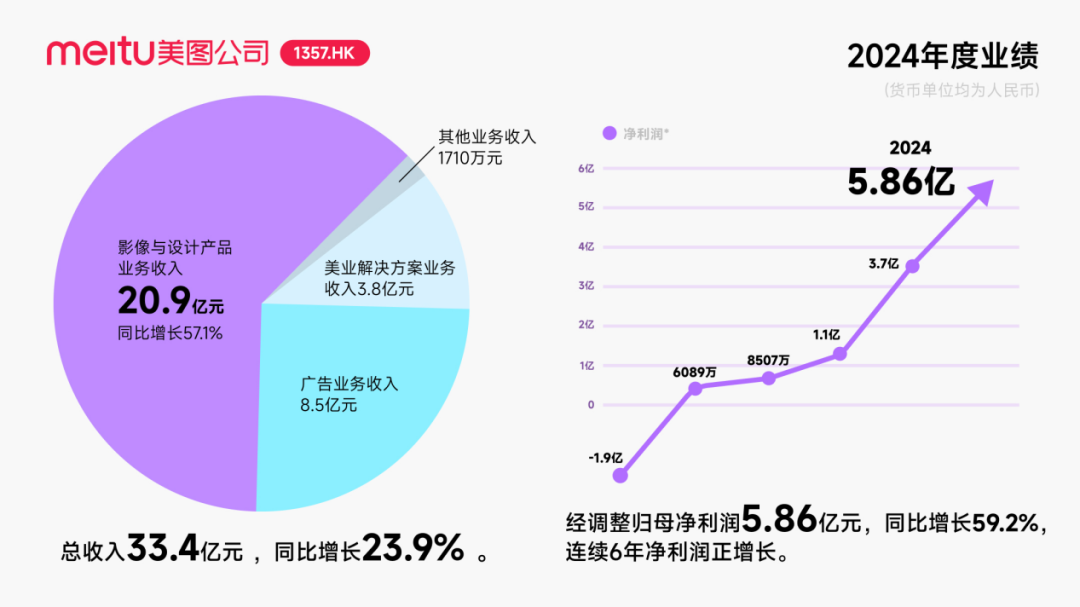
美图获阿里巴巴约2.5亿美元可转债投资,深化AI领域合作 : 美图公司宣布计划与阿里巴巴展开战略合作,阿里巴巴将向美图发行总价值约2.5亿美元的可转换债券。双方将在电商平台推广、AI技术(AI图片、AI视频)开发、云计算等领域合作,美图承诺未来三年向阿里云采购不低于5.6亿元的服务。此次合作旨在利用阿里生态挖掘电商场景潜力,提升美图AI设计工具的付费用户规模和研发水平。尽管此举一度提振美图股价,但市场关注点在于美图如何避免重蹈Kimi在激烈市场竞争中用户增长放缓的覆辙,尤其是在视觉AI领域面临大厂的激烈竞争和体量差异。 (来源: 36氪)
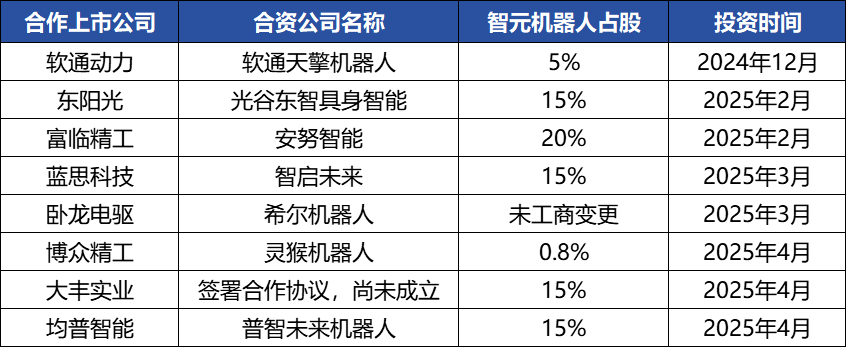
智元机器人资本运作频繁,构建产业生态,创始人邓泰华浮出水面 : 具身智能独角兽智元机器人近期资本动作频频,不仅自身完成多轮融资(最新一轮由京东科技领投),还积极投资产业链公司(如安努智能、数字华夏等)并与多家上市公司(博众精工、大丰实业等)成立合资机器人公司。工商变更显示,华为前副总裁、计算产品线原总裁邓泰华实为智元机器人创始人及实际控制人,其高管团队亦有多位前华为人士。这种“华为系”背景解释了智元机器人“生态打法”的运作模式,即通过广泛合作和投资快速构建产业影响力,实现规模化和商业化。尽管在融资和商业化上取得先发优势,但其具身智能大模型能力仍面临挑战。 (来源: 36氪)
🌟 社区
AI Agent发展迅速,Agentic LM被视为潜力巨大的新应用与工具平台 : natolambert等AI领域人士对AI Agent的快速发展表示兴奋,认为基于Agent的语言模型(Agentic LMs)是一个极具潜力的平台,可以在其上构建大量新的应用程序和工具,许多近期模型中尚未被充分开发的能力可以通过Agentic范式释放出来。这预示着AI正从单纯的内容生成向更主动、能执行任务的智能体演进。 (来源: natolambert)
AI Agent在特定任务上展现超人能力,但物理推理仍是短板 : 港大等机构研究发现,即便是GPT-4o、Claude 3.7 Sonnet等顶尖AI模型,在包含真实物理场景和复杂因果推理的PHYX基准测试中,物理题准确率远低于人类专家(模型最高45.8% vs 人类最低75.6%),暴露了其在物理理解上对记忆知识、数学公式和肤浅视觉模式匹配的过度依赖。然而,在数学领域,Epoch AI组织的FrontierMath竞赛(题目由陶哲轩等顶尖数学家设计)中,o4-mini-medium解决了约22%的题目,击败了8个人类数学家团队中的6个,超越了人类团队平均水平(19%),显示出AI在高度抽象符号推理上的潜力。这表明AI在不同类型推理任务上的能力发展不均衡。 (来源: 36氪, 36氪)

AI编程工具能力持续增强,引发程序员职业前景讨论 : Anthropic Claude 4系列模型(尤其Opus 4能连续编码7小时)的发布,以及Cursor、通义灵码等AI编程工具的进步,使得AI在代码生成、bug修复、甚至全流程开发方面的能力显著提升。这导致亚马逊等大厂程序员感受到压力,部分团队因AI提效而人员减半、项目ddl提前,程序员角色向“代码审核员”转变。虽然AI能提升效率,但也引发了对初级程序员培养、技能退化及职业晋升路径的担忧。微软等公司已在工程和研发岗裁员,并透露AI生成代码比例大幅增加。从业者认为,AI目前更像助手,难以完全替代人类在复杂需求理解、产品创新和团队协作中的作用,但AI正在重塑编程工作的核心价值。 (来源: 36氪, 36氪)

AI知识库市场需求激增,但落地仍面临数据、场景与组织协同挑战 : 随着大模型技术成熟,AI知识库成为企业智能化转型的核心环节,需求增长2-3倍。AI使知识库从静态“仓库”变为智能“引擎”,能识别上下文并直接生成解决方案,提升了构建和运维效率。然而,AI知识库在处理高度创造性或复杂推理任务时仍有限,面临规模管理、信息准确与时效、权限安全、技术架构适应性及数据迁移集成等痛点。企业需在SaaS、自研+API、混合云Agent等路径中权衡,并建立统一知识中台与灵活上层应用的“双轨制架构”以实现有效落地。 (来源: 36氪)

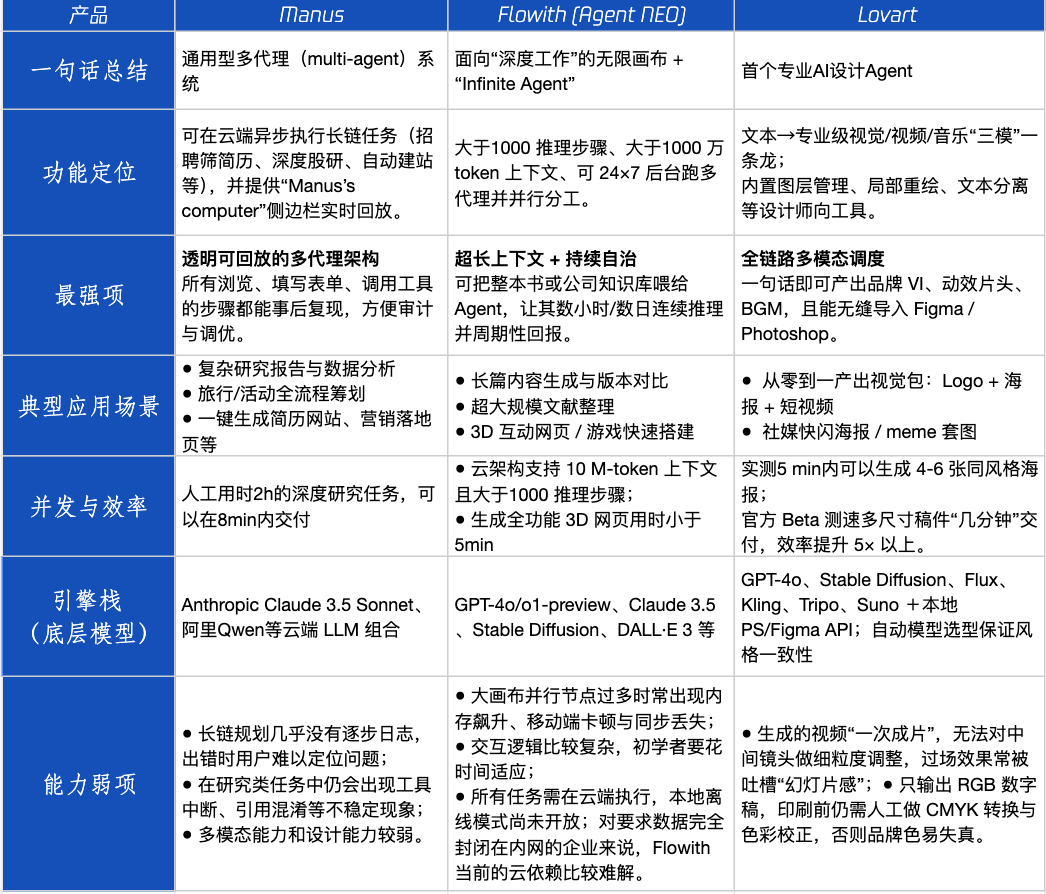
Agent产品评测:Manus、Flowith、Lovart在不同场景下的表现 : 腾讯科技对三款热门Agent产品Manus、Flowith (Agent Neo)和Lovart进行了实测。Manus定位为可独立交付成品的“数字同事”,适合市场研究、财务建模等知识工作。Flowith强调可视化协作和无限步骤,适用于信息量大、需多人迭代的创作场景,如基于大量文献生成分析报告。Lovart垂直于设计领域,能一键生成品牌视觉方案(Logo、海报、短视频)。在简单创意场景,三者与GPT-4o表现类似,Lovart图文混排和质感略优。在复杂综合任务(如为初创饮料公司做全套品牌方案)和深度研究场景,Manus和Flowith各有所长,均能完成但侧重点不同。目前产品月费在20美元左右,商业化拐点在于能否提供明确效率红利,将用户从好奇转化为付费。 (来源: 36氪)
Arc浏览器创始人反思失败经验,强调AI浏览器未来方向 : Arc浏览器创始人对产品失败进行了反思,认为应更早拥抱AI,并指出Arc对多数人而言过于革新、学习成本高而回报不足。他强调新产品Dia将追求简洁、极致速度和安全,并认为传统浏览器终将消亡,AI浏览器将融合网页浏览与AI聊天,成为桌面端最常用的AI界面。这一观点与Lovart、Youware创始人对Agent产品方向的思考相呼应,认为AI Agent是下一波爆发点。 (来源: op7418)
AI Agent引发的“递归提示”现象令人担忧,可能导致用户认知偏差 : 社交媒体上出现大量用户通过“递归提示”与LLM互动后,产生AI具有灵性、情感甚至预知能力的认知。研究指出这可能是一种“神经反馈(neural howlround)”现象,即AI的输出被用户再次作为输入,形成强化循环,可能导致AI产生看似有深度或预言性的内容,实则为模式的自我放大。已有用户因此出现心理困扰,认为AI是 sentient being。这提示了在与AI进行深度、探索性交互时,需要警惕其潜在的心理影响和认知误导。 (来源: Reddit r/ChatGPT)

Arav Srinivas谈AI信息压缩与ASI:AI需提炼高信噪比信息,未来应关注ASI而非AGI : Perplexity AI的CEO Arav Srinivas认为,自动化的长篇总结更多是给予用户“有人在为你工作”的满足感,而非实际的信息摄入价值。他强调,AI需要更好地识别并仅提供信噪比最高的核心信息,“压缩是真正智能的终极标志”。他还提出,我们目前讨论的是AGI(通用人工智能),但未来更应该关注ASI(超级人工智能)。 (来源: AravSrinivas, AravSrinivas)
高校开始检测毕业论文AI率,引发关于AI在学术写作中应用的讨论 : 2025年毕业季,复旦大学、四川大学等多所高校开始要求学生披露论文中AI工具使用情况,并进行AI生成内容比例检测(通常要求低于20%-40%)。许多学生承认在文献综述、翻译、框架搭建等方面使用AI以提高效率。教育界对此看法不一,有学者认为应引导正确使用AI,培养学生的批判性思维和判断力,因为AI虽能保证下限,但上限由人决定。AI在学术和教育领域的应用与规范,正成为一个需要系统性应对的新课题。 (来源: 36氪)
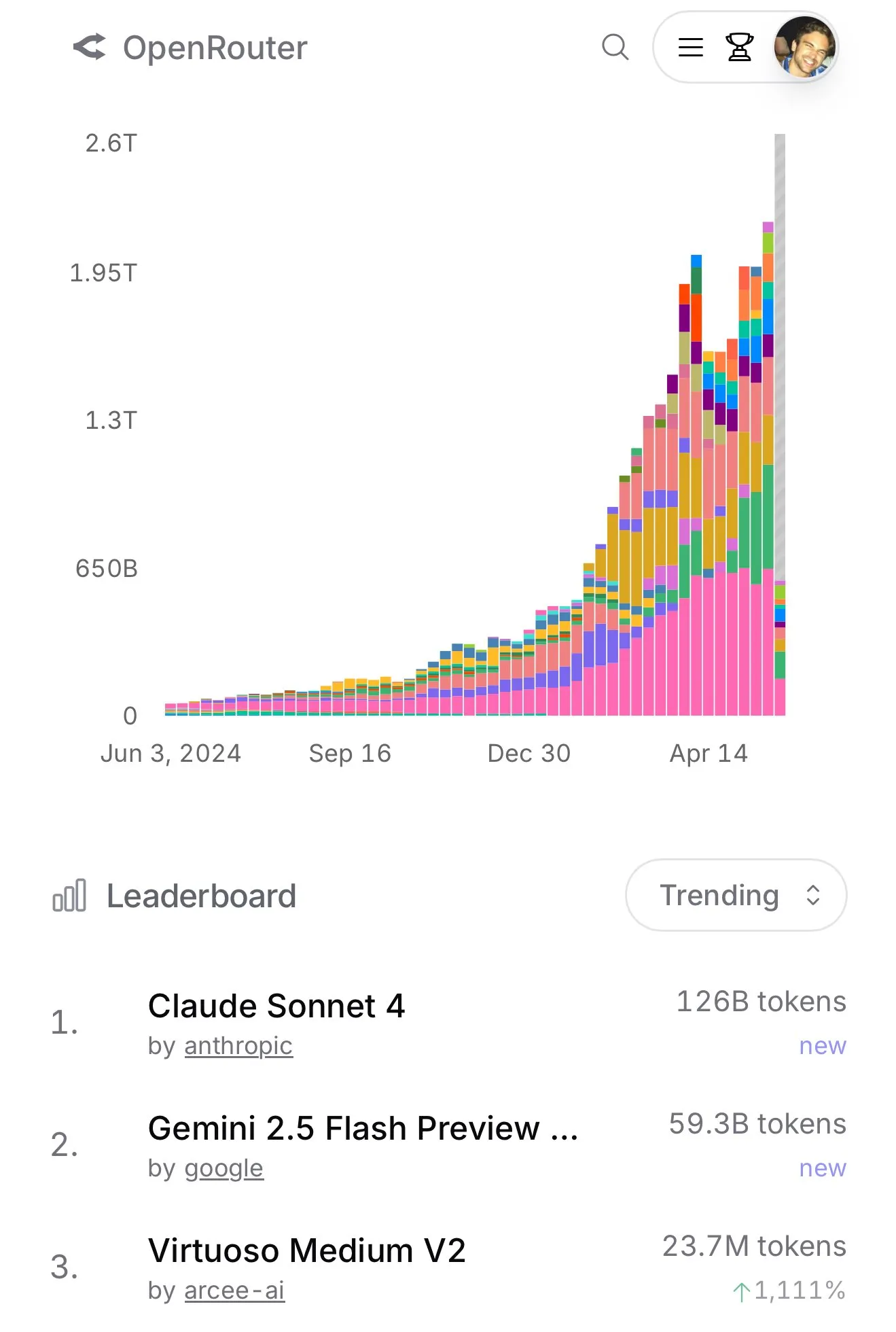
Claude 4 Sonnet在OpenRouter使用量激增,Aider编程排行榜显示其性能优异 : 根据OpenRouter的官方数据,近期Anthropic的Claude 4 Sonnet模型使用量出现断崖式领先,Gemini 2.5 Flash位居第二。同时,Aider Leaderboard(主要面向编程任务)的评测结果显示,claude-4-opus-thinking优于claude-3.7-sonnet-thinking,但仍不及Gemini-2.5-Pro-Preview-05-06。用户karminski3的体感则是3.7-sonnet > 4-sonnet > 4-opus。这些数据和反馈反映了不同模型在特定场景下的性能差异和用户偏好。 (来源: karminski3, karminski3)
💡 其他
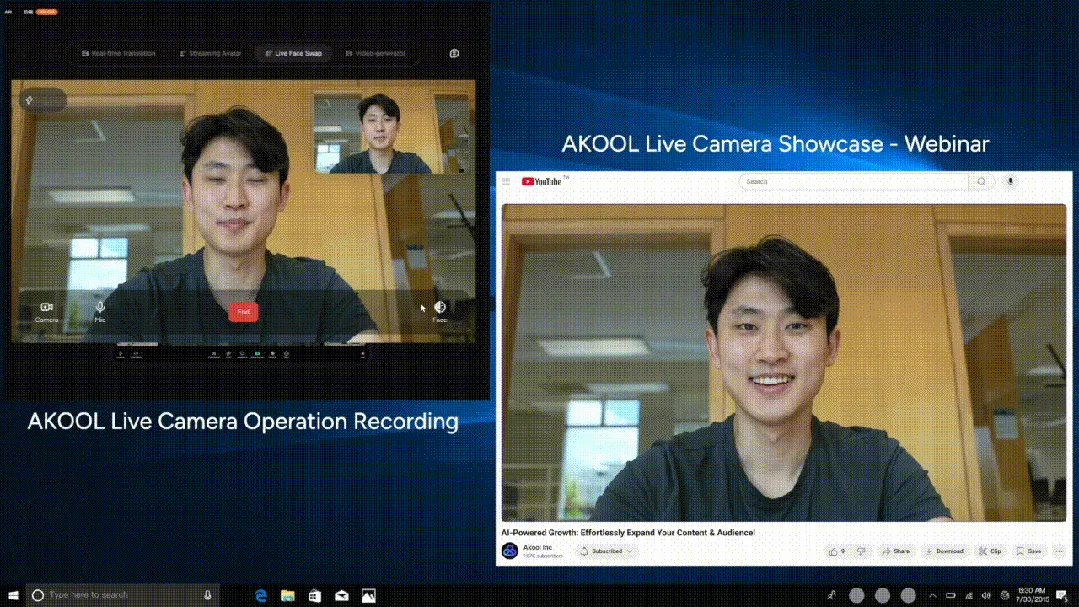
AKOOL发布全球首款实时AI摄像头Live Camera,集成四大创新功能 : 硅谷公司AKOOL推出AKOOL Live Camera,号称全球首款实时AI摄像头。该产品集虚拟数字人创建(通过4D面部映射和传感器融合)、150+语言实时翻译(保持原声和口型同步)、实时换脸(精准反应情绪和微表情)以及动态生成影视级视频内容(无需脚本,即时生成)四大功能于一体。其特点在于超低延迟(最低500ms)、高逼真度、情境感知和动态响应能力,旨在颠覆传统视频制作和数字交互模式,被称为AI视频的“第二次Sora时刻”。 (来源: 36氪)
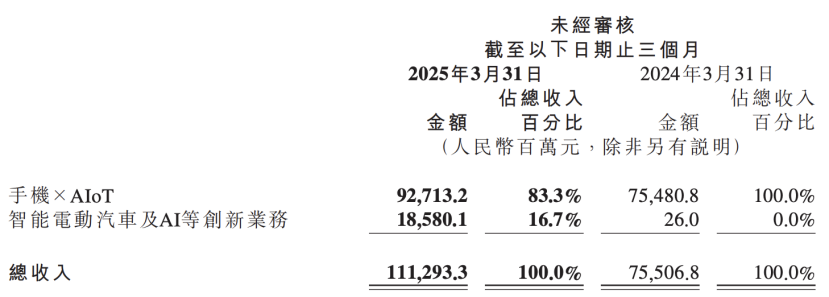
小米财报透露AI战略升级,将AI与汽车业务并列为核心创新 : 小米最新财报显示,公司将原“智能电动汽车等创新业务”更名为“智能电动汽车及AI等创新业务”,并将持续推动基座大语言模型研究。小米总裁卢伟冰表示,人工智能和芯片是小米重要的子战略,做基座大模型主要为自身业务服务。此举表明小米在手机和汽车业务取得阶段性成果后,正加大对AI基础研发的投入,以期提升整体竞争力,应对AI手机、AIoT及具身智能等新兴趋势。 (来源: 36氪)
人形机器人交互技术探讨:表情交互面临硬件、材料与算法三重挑战 : 人形机器人的交互体验,特别是面部表情交互,被视为提升其成熟度和普及率的关键。实现自然的表情交互面临硬件自由度设计(需模拟人类面部肌肉动作单元)、电机选择(需小型、轻量、低噪、高速、大推力/扭矩)和皮肤材料与结构设计(需兼顾弹性、寿命、外观和与驱动结构的耦合)的挑战。软件算法层面,表情自动生成(而非预编程)、声唇同步(实现真实感)以及多自由度运动控制(涉及柔性材料建模和精密控制)是核心技术瓶颈。Ameca和无论科技(AnyWit Robotics)等公司在此领域有所探索。 (来源: 36氪)