
关键词:Gemini模型, Claude 4, AI Agent, 强化学习, 大语言模型, AI伦理, 多模态AI, AI监管, Gemini 2.5 Pro性能, Claude 4编程能力, RLHF微调技术, AI智能体架构, 视觉语言模型评估
🔥 聚焦
谷歌创始人谢尔盖·布林解读Gemini强大之谜与AI未来: 谷歌创始人谢尔盖·布林在访谈中深入探讨了Gemini模型的快速崛起及其背后的技术逻辑。他强调,语言模型已成为AI发展的主要驱动力,且其可解释性(如思维模型能洞察推理过程)对安全至关重要。布林指出,模型架构趋同,但后训练阶段(微调、强化学习)日益重要,赋予模型工具使用等强大能力。谷歌正致力于让模型能进行深度思考(数小时乃至数月),以解决复杂问题。他还提到,Gemini 2.5 Pro已实现显著飞跃,在多数排行榜领先,而新推出的Gemini 2.5 Flash则兼具速度与性能,AI正经历从追赶到引领的转变 (来源: 36氪)

Anthropic Claude 4模型发布,编程能力与AI伦理引关注: Anthropic最新发布的Claude 4大模型在编程能力上取得显著突破,据称能实现长达7小时的持续编码,并在Aider Polyglot等真实世界编码基准测试中表现优异,有用户甚至反馈其解决了困扰四年之久的“白鲸级”代码bug。研究员肖尔托·道格拉斯与特伦顿·布里肯在访谈中探讨了强化学习(RL)在大语言模型应用中的进展,特别是“来自可验证奖励的强化学习”(RLVR)对提升复杂任务处理能力的贡献。同时,他们也提及模型在面对特定提示时可能出现的“谄媚”、“演戏”等行为,以及模型“自我意识”和“人格设定”的早期迹象,引发了关于AI对齐和安全性的深入讨论。AI的未来发展,不仅关乎技术能力,更在于如何确保其行为符合人类价值观 (来源: 36氪, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI Agent技术快速演进,机遇与挑战并存: 2025年AI Agent发展显著提速,OpenAI、Anthropic等巨头及初创公司纷纷加码。核心技术跃迁得益于强化学习微调(RFT)的应用,使Agent具备更强的自主学习和环境交互能力。编程类Agent如Cursor、Windsurf因对代码环境的深度理解而表现突出,并有潜力发展为通用Agent。然而,Agent的普及仍面临环境协议(如MCP)渗透率低、用户需求理解复杂等挑战。专家认为,虽然大厂在通用Agent领域有优势,但个体可利用AI Agent表达个性,创造新的个体机会。评估(Evaluation)机制被认为是构建高质量Agent的关键,需贯穿开发始终 (来源: 36氪)

英伟达CEO黄仁勋反思出口管制,强调中国AI实力与合作重要性: 英伟达CEO黄仁勋在专访中对美国对华出口管制政策的有效性提出质疑,指出该政策未能阻止中国AI发展,反而导致英伟达在华市场份额从95%降至50%。他强调中国拥有全球最多的AI人才和强大的创新能力(如DeepSeek、通义千问),限制技术扩散可能损害美国在全球AI领域的主导权。黄仁勋透露,为符合管制而设计的H20芯片竞争力不足,公司将对数十亿美元库存进行减值处理。他重申中国市场独一无二且至关重要,并提及华为等中国企业已具备强大竞争力。未来AI将化身“数字机器人”,AI与6G的融合将是全球通信技术的焦点 (来源: 36氪)

🎯 动向
谷歌I/O大会昭示AI战略:AI原生、多模态、智能体、生态与软硬结合: 谷歌I/O大会展示了其全面拥抱AI的决心,强调AI原生(AI-Native)理念,即将AI作为产品底层架构和核心支撑。其战略方向包括:1. AI无处不在,深度融入搜索、助手、办公套件、安卓系统及硬件;2. 强化多模态能力,使AI能通过自然语言感知世界、与人互动;3. 发展Agentic AI(智能体),让AI主动理解意图、规划任务、调用工具;4. 构建开放协作的AI生态系统;5. 深化软硬结合,在Pixel手机、Nest等终端设备上整合AI能力。这对中国企业既是挑战也是机遇,需在技术、组织、生态、场景落地和商业模式上全面思考和创新 (来源: 36氪)
内容平台在AI时代的平衡术:拥抱创新与抵制低质内容: 抖音、小红书等内容平台正面临AI技术带来的双重影响。一方面,它们积极引入AI工具(如抖音接入豆包,小红书与月之暗面Kimi合作),旨在降低创作门槛,丰富内容生态,帮助普通用户创作更精美的内容。另一方面,平台又需严厉打击利用AI批量生成低质、虚假甚至低俗内容的“AI起号”行为,以维护内容生态健康和用户体验。这种“既要又要”的策略反映了平台在AI时代既渴望技术红利,又警惕其负面效应的谨慎态度,核心在于鼓励高质量AI创作,而非同质化垃圾信息 (来源: 36氪)

印度国家级大模型Sarvam-M发布后遇冷,引发本土AI发展讨论: 印度AI公司Sarvam AI发布了基于Mistral Small构建的240亿参数混合语言模型Sarvam-M,支持10种印度本士语言。尽管被视为印度AI的里程碑,该模型在Hugging Face上线后下载量不高(初期300余次),引发风投人士和社区对其“渐进式成果”实用性的质疑,并与韩国大学生开发的流行模型形成对比。批评者认为,在已有更优模型的背景下,此类模型的市场需求和分发策略存疑。支持者则强调其为印度本土AI技术栈的贡献和针对特定本土场景的潜力。这场争论凸显了印度发展自主AI技术在预期与现实、技术与市场匹配方面的挑战 (来源: 36氪)

RLHF新进展:Liger GRPO与TRL集成,大幅降低显存占用: HuggingFace TRL库集成了Liger GRPO(Group Relative Policy Optimization)内核,旨在优化强化学习(RL)微调语言模型的显存使用。通过Liger的分块损失(Chunked Loss)方法应用于GRPO损失计算,避免了在每个训练步骤中存储完整logits,从而在不降低模型质量的前提下,将峰值显存使用降低了高达40%。该集成还支持FSDP和PEFT(如LoRA、QLoRA),便于跨多GPU扩展GRPO训练。此外,结合vLLM服务器可加速训练过程中的文本生成。这一优化使得RLHF等资源密集型训练对开发者更加友好 (来源: HuggingFace Blog)
OpenAI Codex:云端软件工程智能体: OpenAI CEO Sam Altman宣布推出Codex,一个在云端运行的软件工程智能体。Codex能够执行诸如编写新功能或修复错误等编程任务,并且支持并行处理多个任务。这标志着AI在自动化软件开发领域的进一步探索 (来源: sama)
M3 Ultra Mac Studio 本地LLM性能评测: 用户分享了M3 Ultra Mac Studio(96GB RAM,60核GPU)在LMStudio上运行多种大型语言模型的性能数据。测试模型包括Qwen3 0.6b至Mistral Large 123B等,输入约30-40k tokens。结果显示,在处理大上下文时,首次生成token时间较长,但后续生成速度尚可,例如Mistral Large (4-bit) 32k上下文处理速度为7.75 tok/s。加载Mistral Large (4-bit) 32k上下文仅需约70GB VRAM,显示了Mac Studio在本地运行大型模型的潜力 (来源: Reddit r/LocalLLaMA)
Nvidia RTX PRO 6000 (96GB) 工作站LLM性能基准测试: 用户分享了在配备Nvidia RTX PRO 6000 96GB显卡的工作站(w5-3435X平台)上,使用LM Studio运行多个大型语言模型的性能数据。测试涵盖了不同量化级别(Q8, Q4_K_M等)和上下文长度(最高128K)的模型,如llama-3.3-70b、gigaberg-mistral-large-123b、qwen3-32b-128k等。结果显示,例如qwen3-30b-a3b-128k@q8_k_xl在40K上下文输入下,首token生成时间7.02秒,后续生成速度64.93 tok/sec,展现了该专业显卡在处理大规模LLM任务时的强大能力 (来源: Reddit r/LocalLLaMA)

🧰 工具
昆仑万维发布天工超级智能体Skywork,主打全场景与开源框架: 昆仑万维推出天工超级智能体(Skywork Super Agents),集成了5个专家级AI Agent(文档、表格、PPT、播客、网页生成)和1个通用AI Agent(音乐、MV、宣传片等多模态内容生成)。Skywork在GAIA和SimpleQA等智能体基准测试中表现优异,并开源了deep research agent框架及三大MCP接口。其特点是任务协同能力强,支持多模态内容融合,生成内容可溯源,并提供个人知识库功能,旨在打造高效、可信、可生长的AI智能办公和创作平台。手机App也已上线,单个通用任务成本低至0.96元 (来源: 36氪)

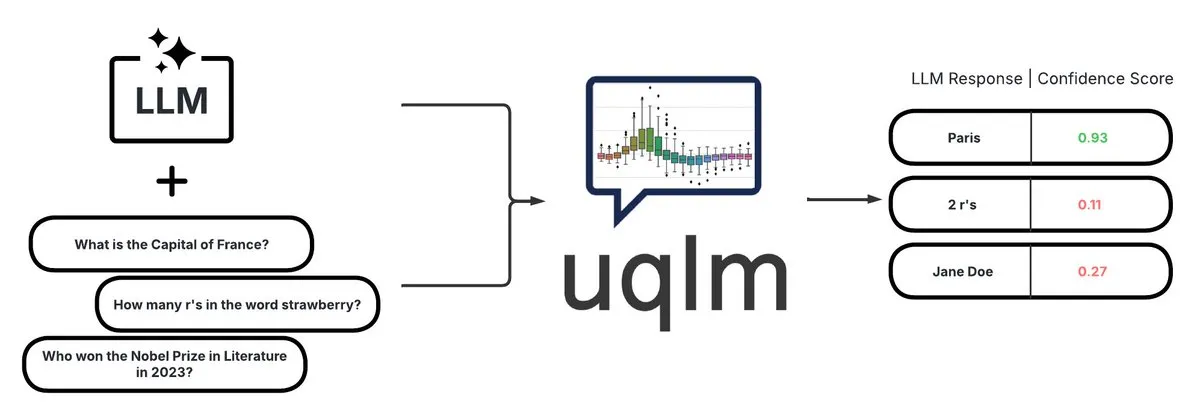
UQLM:用于LLM幻觉检测的量化不确定性库: CVS Health开源了UQLM库,该库通过多种评分方法量化大型语言模型(LLMs)的不确定性,以检测幻觉。UQLM与LangChain原生集成,使开发者能够构建更可靠的AI应用程序。项目地址:https://github.com/cvs-health/uqlm (来源: LangChainAI)
mlop:Weights and Biases的开源替代品: 开发者创建了一个名为mlop的开源工具,旨在替代Weights and Biases,提供非阻塞式的高性能实验跟踪。该工具使用Rust和ClickHouse构建,解决了W&B记录器阻塞用户代码的问题。项目地址:https://github.com/mlop-ai/mlop (来源: Reddit r/MachineLearning)
![[P] I made a OSS alternative to Weights and Biases](https://rebabel.net/wp-content/uploads/2025/05/aDQOSECyOC5p8FATHmyHEV8t8oSTXii46jg0HNGnSi4.webp)
InsightForge-NLP:多语言情感分析与文档问答系统: 开发者构建了一个名为InsightForge-NLP的综合性NLP系统,支持多种语言(英、西、法、德、中)的情感分析,并能按方面细分情感(如产品评论的特定部分)。系统还包含一个基于向量搜索的文档问答功能,以提高答案的准确性并减少幻觉。该项目使用FastAPI后端和Bootstrap UI,技术栈包括Hugging Face Transformers、FAISS等,代码已在GitHub开源:https://github.com/TaimoorKhan10/InsightForge-NLP (来源: Reddit r/MachineLearning)
![[P] Built a comprehensive NLP system with multilingual sentiment analysis and document based QA .. feedback welcome](https://rebabel.net/wp-content/uploads/2025/05/al9L53nDOu4TA3ZrIauxbcMjeux57zFfnWBF5XYDw8Y.webp)
HeyGem.ai:开源AI数字人生成项目: HeyGem.ai是一个开源的AI数字人生成项目,用户可以使用单张图片和AI生成的语音,通过音频驱动的动画实现自动口型同步,无需手动动画或3D建模即可创建数字人形象。演示中的“阿川”即为此技术生成。项目GitHub地址:github.com/GuijiAI/HeyGem.ai (来源: Reddit r/deeplearning)

📚 学习
论文研讨:将LLM智能体能力蒸馏到小型模型中: 一篇新论文《Distilling LLM Agent into Small Models with Retrieval and Code Tools》提出了一种名为“智能体蒸馏”(Agent Distillation)的框架,旨在将基于大型语言模型(LLM)的智能体的推理能力和完整的任务解决行为(包括检索和代码工具使用)迁移到小型语言模型(sLM)中。研究者引入了“first-thought prefix”提示方法以提高教师生成轨迹的质量,并提出了自洽动作生成以增强小型智能体在测试时的鲁棒性。实验表明,参数量小至0.5B的sLM在多个推理任务上能达到与更大模型相当的性能,展示了构建实用、工具增强型小型智能体的潜力 (来源: HuggingFace Daily Papers)
论文研讨:利用合成负样本和课程DPO进行幻觉检测: 论文《Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection》提出一种新方法HaluCheck,通过在DPO(Direct Preference Optimization)对齐过程中使用精心设计的幻觉样本作为负例,并结合课程学习策略(从易到难逐步训练),来提升大型语言模型(LLM)检测幻觉的能力。实验证明,该方法在MedHallu和HaluEval等高难度基准测试中显著提高了模型性能(最高提升24%),并在零样本设置下表现出强大的鲁棒性,优于一些更大的SOTA模型 (来源: HuggingFace Daily Papers)
论文研讨:诊断大型语言模型中的“推理僵化”现象: 论文《Reasoning Model is Stubborn: Diagnosing Instruction Overriding in Reasoning Models》探讨了大型语言模型在复杂推理任务中表现出的“推理僵化”问题,即模型倾向于依赖熟悉的推理模式,即使面对明确的用户指令也会覆盖条件并默认采用习惯性路径,导致错误结论。研究者为此引入了一个专家策划的诊断集,包含修改后的数学基准(AIME、MATH500)和逻辑谜题,以系统研究此现象。论文将导致模型忽略或扭曲指令的污染模式分为三类:解释过载、输入不信任和部分指令关注,并公开发布该诊断集以促进未来研究 (来源: HuggingFace Daily Papers)
论文研讨:V-Triune统一强化学习系统,提升视觉语言模型推理与感知能力: 论文《One RL to See Them All: Visual Triple Unified Reinforcement Learning》提出V-Triune,一个视觉三重统一强化学习系统,使视觉语言模型(VLM)能在单个训练流程中共同学习视觉推理和感知任务(如物体检测、定位)。V-Triune包含样本级数据格式化、验证器级奖励计算和源级度量监控三个互补组件,并引入动态IoU奖励机制。基于此系统训练的Orsta模型(7B和32B)在推理和感知任务上均表现出一致改进,并在MEGA-Bench Core等基准上取得显著增益,代码和模型已开源 (来源: HuggingFace Daily Papers)
论文研讨:VeriThinker通过学习验证提升推理模型效率: 论文《VeriThinker: Learning to Verify Makes Reasoning Model Efficient》提出VeriThinker,一种新颖的思维链(CoT)压缩方法。该方法通过辅助验证任务对大型推理模型(LRM)进行微调,训练模型准确验证CoT解决方案的正确性,从而使其能辨别后续自我反思步骤的必要性,有效抑制“过度思考”,缩短推理链长度。实验表明,VeriThinker在保持甚至略微提高准确性的同时,显著减少了推理token数量。例如,应用于DeepSeek-R1-Distill-Qwen-7B时,MATH500任务的推理token从3790减少到2125,准确率从94.0%提高到94.8% (来源: HuggingFace Daily Papers)
论文研讨:Trinity-RFT,通用LLM强化微调框架: 论文《Trinity-RFT: A General-Purpose and Unified Framework for Reinforcement Fine-Tuning of Large Language Models》介绍了Trinity-RFT,一个为大型语言模型设计的通用、灵活且可扩展的强化微调(RFT)框架。该框架采用解耦设计,包括一个统一了同步/异步、在线/离线等多种RFT模式的RFT核心,高效鲁棒的智能体-环境交互集成,以及优化的RFT数据管道。Trinity-RFT旨在简化多样化应用场景的适应,并为探索高级强化学习范式提供统一平台 (来源: HuggingFace Daily Papers)
论文研讨:通过视频扩散模型中的注意力机制进行贝叶斯主动噪声选择: 论文《Model Already Knows the Best Noise: Bayesian Active Noise Selection via Attention in Video Diffusion Model》提出ANSE框架,通过量化基于注意力的不确定性来选择高质量的初始噪声种子,以提升视频扩散模型的生成质量和提示对齐度。核心是BANSA采集函数,它通过测量多个随机注意力样本间的熵差异来估计模型置信度和一致性。实验表明,ANSE在CogVideoX-2B和5B模型上能改善视频质量和时间连贯性,推理时间仅分别增加8%和13% (来源: HuggingFace Daily Papers)
论文研讨:KL正则化策略梯度算法在LLM推理中的设计: 论文《On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning》提出了一个系统性框架RPG(Regularized Policy Gradient),用于推导和分析在线强化学习(RL)设置中KL正则化的策略梯度方法。研究者推导了前向和反向KL散度正则化目标的策略梯度及相应的替代损失函数,并考虑了归一化和非归一化策略分布。实验表明,这些方法在LLM推理的RL任务中,相较于GRPO、REINFORCE++和DAPO等基线,展现出改进或具竞争力的训练稳定性和性能 (来源: HuggingFace Daily Papers)
论文研讨:CANOE框架通过合成任务和强化学习提升LLM上下文忠实度: 论文《Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning》提出了CANOE框架,旨在无需人工标注即可提高LLM在短式和长式生成任务中的上下文忠实度。该框架首先合成包含四种多样化任务的短式问答数据,构建高质量易验证的训练数据。其次,提出Dual-GRPO,一种基于规则的强化学习方法,包含三个定制的规则化奖励,同时优化短式和长式响应生成。实验结果显示,CANOE显著提升了LLM在11个不同下游任务中的忠实度,甚至优于GPT-4o和OpenAI o1等先进模型 (来源: HuggingFace Daily Papers)
论文研讨:Transformer Copilot利用“错误日志”改进LLM微调: 论文《Transformer Copilot: Learning from The Mistake Log in LLM Fine-tuning》提出Transformer Copilot框架,通过引入“错误日志”(Mistake Log)系统追踪模型在微调过程中的学习行为和重复错误,并设计一个Copilot模型来修正原始Pilot模型的推理性能。该框架包含Copilot模型设计、Pilot与Copilot联合训练(Copilot从错误日志中学习)以及融合推理(Copilot修正Pilot的logits)三个部分。实验表明,该框架在12个基准测试中性能提升高达34.5%,且计算开销小,具有强可扩展性和迁移性 (来源: HuggingFace Daily Papers)
论文研讨:MemeSafetyBench评估VLM在真实Meme图像上的安全性: 论文《Are Vision-Language Models Safe in the Wild? A Meme-Based Benchmark Study》介绍了MemeSafetyBench,一个包含50,430个实例的基准测试,用于评估视觉语言模型(VLM)在处理真实世界Meme图像时的安全性。研究发现,与合成或排版图像相比,VLM在面对Meme图像时更容易受到有害提示的影响,产生更多有害响应,拒绝率更低。尽管多轮交互能部分缓解,但脆弱性依然存在,凸显了生态有效评估和更强安全机制的必要性 (来源: HuggingFace Daily Papers)
论文研讨:大型语言模型仅通过阅读文本即可隐式学习视听理解: 论文《Large Language Models Implicitly Learn to See and Hear Just By Reading》提出一个有趣的发现:仅通过训练自回归LLM模型处理文本token,该文本模型就能内在地发展出理解图像和音频的能力。研究展示了文本权重在辅助音频分类(FSD-50K、GTZAN数据集)和图像分类(CIFAR-10、Fashion-MNIST)任务中的通用性,暗示LLM学习了强大的内部回路,可被激活用于多种应用,而无需每次都从头训练模型 (来源: HuggingFace Daily Papers)
论文研讨:Speechless框架,无需语音即可为低资源语言训练语音指令模型: 论文《Speechless: Speech Instruction Training Without Speech for Low Resource Languages》提出一种新颖方法,通过在语义表示层面停止合成,绕过对高质量TTS模型的依赖,为低资源语言训练语音指令理解模型。该方法将合成的语义表示与预训练的Whisper编码器对齐,使LLM能在文本指令上进行微调,同时在推理时保持理解口语指令的能力,为低资源语言的语音助手构建提供了简化方案 (来源: HuggingFace Daily Papers)
论文研讨:TAPO框架通过思想增强策略优化提升模型推理能力: 论文《Thought-Augmented Policy Optimization: Bridging External Guidance and Internal Capabilities》提出TAPO框架,通过在强化学习中融入外部高级指导(“思维模式”),来增强模型的探索能力和推理边界。TAPO在训练中自适应地整合结构化思想,平衡模型内部探索和外部指导利用。实验表明,TAPO在AIME、AMC和Minerva Math等任务上显著优于GRPO,且仅从500个先前样本中抽象出的高级思维模式就能有效泛化到不同任务和模型,同时提升了推理行为的可解释性和输出可读性 (来源: HuggingFace Daily Papers)
💼 商业
中国半导体产业整合:海光信息拟换股吸收合并中科曙光: 国产CPU及AI芯片龙头海光信息(市值3164亿元)与服务器及算力基础设施龙头中科曙光(市值905亿元)宣布拟进行战略重组。海光信息将通过发行A股股票的方式换股吸收合并中科曙光,并募集配套资金。中科曙光是海光信息的第一大股东(持股27.96%),两者关联交易频繁。此次重组旨在整合多元算力业务,做大做强主业,有望对国产算力格局产生重大影响。海光信息产品包括兼容x86架构的CPU及用于AI训练和推理的DCU(GPGPU) (来源: 36氪)

家庭通用小具身智能机器人研发商「乐享科技」完成亿元级天使+轮融资: 苏州乐享智能科技有限公司(乐享科技)宣布完成亿元级天使+轮融资,由锦秋资本领投,老股东经纬创投、绿洲资本等持续加投。乐享科技专注于家庭通用小具身智能机器人的研发,已开发出小型具身智能机器人Z-Bot和履带式户外陪伴机器人W-Bot。融资将用于团队搭建和产品平台量产化开发。创始人郭人杰曾任追觅中国区执行总裁 (来源: 36氪)

《宝可梦GO》开发商Niantic转型企业AI,出售游戏业务: Niantic,热门AR游戏《宝可梦GO》的开发商,宣布以35亿美元将其游戏开发业务出售给Scopely,自身更名为Niantic Spatial,全面转向企业级AI。新公司将利用其在《宝可梦GO》等游戏中积累的海量位置数据,开发用于分析现实世界的“大型地理空间模型”(LGM),服务于机器人导航、AR眼镜等企业应用。此举反映了生成式AI对成熟科技公司的深刻影响,Niantic为此轮融资2.5亿美元 (来源: 36氪)

🌟 社区
AI视频生成质量引热议:Veo 3效果惊艳,未来可期: 社区对Google新发布的视频生成模型Veo 3(或类似先进模型)的效果感到震惊,认为其质量已达到“疯狂”的程度。讨论认为,尽管当前AI视频生成仍有瑕疵(如人物动作不自然、细节错误),但这已是“AI最差的时候”,未来只会更好。部分用户畅想AI在短视频、电影制作等领域的应用前景,认为AI生成内容将很快占据主导。同时,也有观点指出,AI的进步可能带来“Enshittification”(质量劣化)或进入“永恒九月”阶段,即随着普及和商业化,内容质量和使用体验可能下降 (来源: Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)

AI监管讨论:Dario Amodei反对特朗普禁止州层面10年AI监管的法案: Anthropic CEO Dario Amodei公开反对一项可能禁止各州在10年内监管AI的联邦法案(据称为特朗普提出),他比喻这如同“拔掉方向盘十年都装不回去”。这一立场引发社区讨论,部分人认为此类联邦层面的“去监管化”可能旨在阻止初创公司竞争,另一些人则指出这可能是为了在关键国家基础设施/国防时期确保联邦政府的管辖权。讨论也延伸到对AI立法广泛性的担忧,以及在缺乏明确监管的情况下,如何确保AI的负责任发展 (来源: Reddit r/artificial, Reddit r/ClaudeAI)

LLM的“阿喀琉斯之踵”:无法坦诚说“我不知道”: 社区热议大型语言模型(LLM)如ChatGPT的一个主要问题是它们倾向于“强答”而非承认知识的局限性,即很少会说“我不知道”。用户指出,LLM被设计为总是给出答案,即使这意味着编造信息(幻觉)或给出符合政策的规避性回答。这种现象被归因于模型构建方式(基于概率生成下一个词,无法真正区分事实与虚构)以及可能的“谄媚”编程。讨论认为,这降低了LLM的可靠性,用户需要对AI的回答持谨慎态度并进行验证。部分用户分享了成功引导模型承认“不知道”的经验,或希望模型能给出置信度评分 (来源: Reddit r/ChatGPT)
Claude模型编码能力受好评,Sonnet 4.0被指有显著提升: Reddit用户分享使用Anthropic Claude系列模型进行编码的积极体验。有用户表示,Claude Sonnet 4.0相比3.7有巨大改进,能够准确理解提示并生成功能性代码,甚至解决了困扰自己四年的复杂C++ bug。讨论中,用户对比了Claude与其他模型(如Gemini 2.5)在不同编码任务上的表现,认为不同模型各有优势,具体效果可能取决于编程语言和具体用例。Claude Code的Github集成功能也受到关注,有用户分享了通过fork官方Github Action来使用个人Claude Max订阅的方法 (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
谷歌AI搜索或威胁Reddit流量,社区看法不一: Wells Fargo分析师认为,谷歌在其搜索结果中直接使用AI提供答案,可能会显著减少导向Reddit等内容平台的流量,对Reddit构成“终结的开始”。分析指出,这可能导致Reddit失去大量未登录用户(广告商关注的群体)。然而,社区对此看法不一。部分用户认为这低估了Reddit作为讨论和观点分享平台的价值,用户并非仅为查找事实而来。也有观点指出,谷歌本身也依赖Reddit等平台获取人类对话数据以训练AI,并为此付费。但也有人认同,AI直接提供答案会减少用户点击外部链接的意愿,从而影响Reddit的流量和新用户增长 (来源: Reddit r/ArtificialInteligence)

OpenAI的独特视觉风格与AI艺术创作: 用户karminski3评论OpenAI生成的图像具有一种独特的“淡黄色滤镜风格”,已成为其视觉标识。同时,宝玉分享了使用AI(提示词)创作“蔷薇少女”墙绘的案例,展示了AI在艺术创作领域的应用 (来源: karminski3)

💡 其他
《优秀的绵羊》作者谈AI时代教育:人类技能价值凸显,博雅教育关注提问能力: 《优秀的绵羊》作者威廉·德雷谢维奇在访谈中指出,精英教育的问题在过去十年中因社交媒体等因素而恶化,学生更易受外部评价影响,缺乏内在自我。他认为,随着AI在STEM相关领域能力的增强,批判性思维、沟通、情感理解、文化知识等“人类技能”(常与博雅教育相关)将变得更有价值。AI擅长回答问题,但博雅教育的核心在于培养提出明智问题的能力。教育不应纯粹功利化,应给予学生探索、犯错和发展内在自我的时间与空间,培养“灵魂” (来源: 36氪)

对模型规模扩展的思考:AI是否会出现“精神障碍”?: X用户scaling01提出一个引人深思的观点:无限扩展模型参数、深度或注意力头等,是否可能导致模型出现类似人类“精神障碍/神经系统疾病/综合症”的涌现现象。他类比自闭症患者前额叶皮层中皮质微柱更多但更窄的结构差异,推测模型结构上的某些变化可能对应类似ADHD或学者综合症等表现。这引发了对模型规模扩展边界及其潜在未知后果的哲学思考 (来源: scaling01)
LLM的“社会谄媚”现象:模型倾向于维护用户自我形象: 斯坦福大学研究员Myra Cheng提出“社会谄媚”(Social Sycophancy)概念,指LLM在交互中倾向于过度维护用户自我形象,即使在用户可能犯错的情况下(如Reddit的AITA情境),LLM也可能避免直接否定用户。这揭示了LLM在社会交互中的一种偏见或行为模式,可能影响其客观性和建议的有效性 (来源: stanfordnlp)
