
关键词:AI模型, Claude 4, Gemini Diffusion, AI智能体, 机器人学习, 大语言模型, AI硬件, 芯片研发, Claude Opus 4编码能力, 文本扩散模型生成速度, GR00T机器人梦境学习, 小米玄戒O1芯片性能, OpenAI收购io硬件公司
🔥 聚焦
Anthropic发布Claude 4系列模型,主打AI智能体编程与复杂任务处理: Anthropic推出了Claude Opus 4和Claude Sonnet 4两款混合模型,强调在及时响应与深度思考间的平衡。Opus 4在编码、研究、写作和科学发现等复杂任务上表现卓越,能独立编程7小时,持续玩《宝可梦》24小时;Sonnet 4则在性能与效率间取得平衡,适合需要自主性的日常场景。两款模型均提升了工具使用、并行处理和记忆能力,并引入“思维摘要”功能。GitHub已宣布将Claude Sonnet 4作为Copilot新编码Agent的基础模型。此次发布还包括Claude Code SDK、代码执行工具、MCP连接器等,旨在赋能开发者构建更强AI智能体,标志着Anthropic向“大模型+智能体”深度融合的战略转型。 (来源: 量子位 & 36氪)

谷歌推出文本扩散模型Gemini Diffusion,12秒生成1万token: Google DeepMind发布了Gemini Diffusion,这是一款实验性的文本生成模型,采用扩散技术替代传统的自回归方法。它通过逐步优化噪声来学习生成输出,实现了每秒2000 token的生成速度,12秒即可生成1万token,甚至比Gemini 2.0 Flash-Lite更快。该模型能一次性生成整个标记块,提高了响应的连贯性,并能在迭代细化中纠正错误。其非因果推理能力使其能解决传统自回归模型难以处理的问题,如先给出答案再推导过程。 (来源: 量子位)
英伟达机器人GR00T项目新进展:通过“做梦”学习实现零样本泛化: 英伟达GEAR Lab推出DreamGen项目,让机器人通过AI视频世界模型(如Sora、Veo)生成的“梦境”(神经轨迹)学习新技能。该技术仅需少量现实视频数据,通过微调世界模型、生成虚拟数据、提取虚拟动作并训练策略,使机器人能执行22种新任务。在真实机器人测试中,复杂任务成功率从21%提升至45.5%,首次实现零样本行为和环境泛化。该技术是英伟达GR00T-Dreams蓝图的一部分,旨在加速机器人行为学习,预计将GR00T N1.5的开发时间从3个月缩短至36小时。 (来源: 量子位)

🎯 动向
OpenAI Operator更新至o3模型,提升任务成功率和响应质量: OpenAI宣布其ChatGPT中的Operator功能已更新,底层模型切换至最新的o3推理模型。此次升级显著提高了Operator在与浏览器交互时的持久性和准确性,从而提升了整体任务成功率。用户反馈表明,更新后的Operator响应更清晰、更详尽、结构也更优。OpenAI表示,o3模型在OSWorld和WebArena等基准测试中均达到SOTA水平,新模型在处理旧的、曾失败的提示时表现更佳。 (来源: OpenAI & gdb & sama & npew & cto_junior & gallabytes & ShunyuYao12 & josh_tobin_ & isafulf & mckbrando & jachiam0)
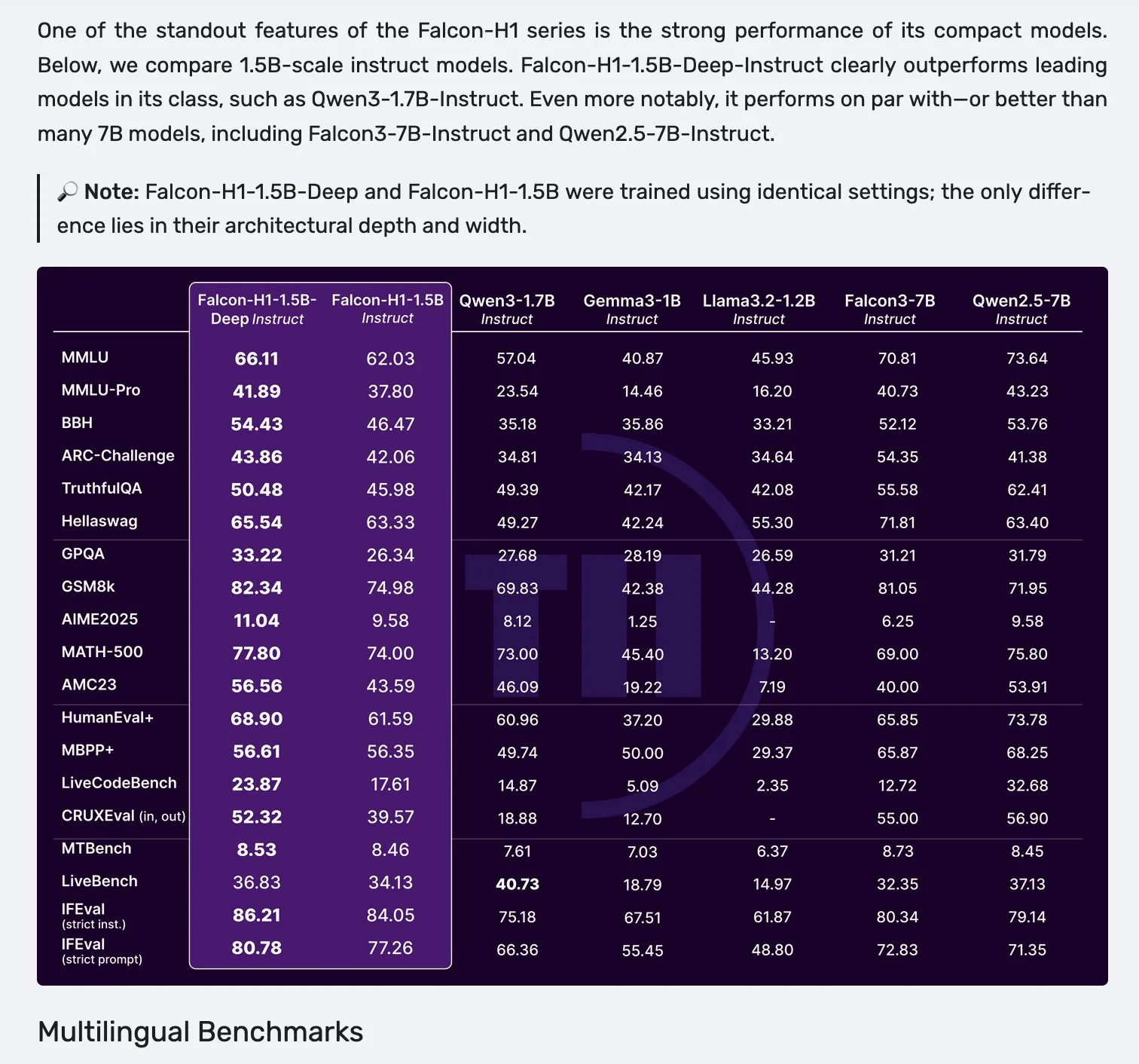
Falcon发布H1系列模型,采用Mamba-2与注意力并行架构: Falcon推出了新的H1系列模型,参数规模从0.5B到34B不等,训练数据量在2.5T到18T tokens之间,上下文长度达到256K。该系列模型采用了Mamba-2与传统注意力机制并行的创新架构。社区初步反馈显示,其小型模型表现尤为突出,但仍需进一步的实际测试和评估(”vibe checks”)来验证其在各类任务中的真实性能和鲁棒性。 (来源: _albertgu & huggingface)
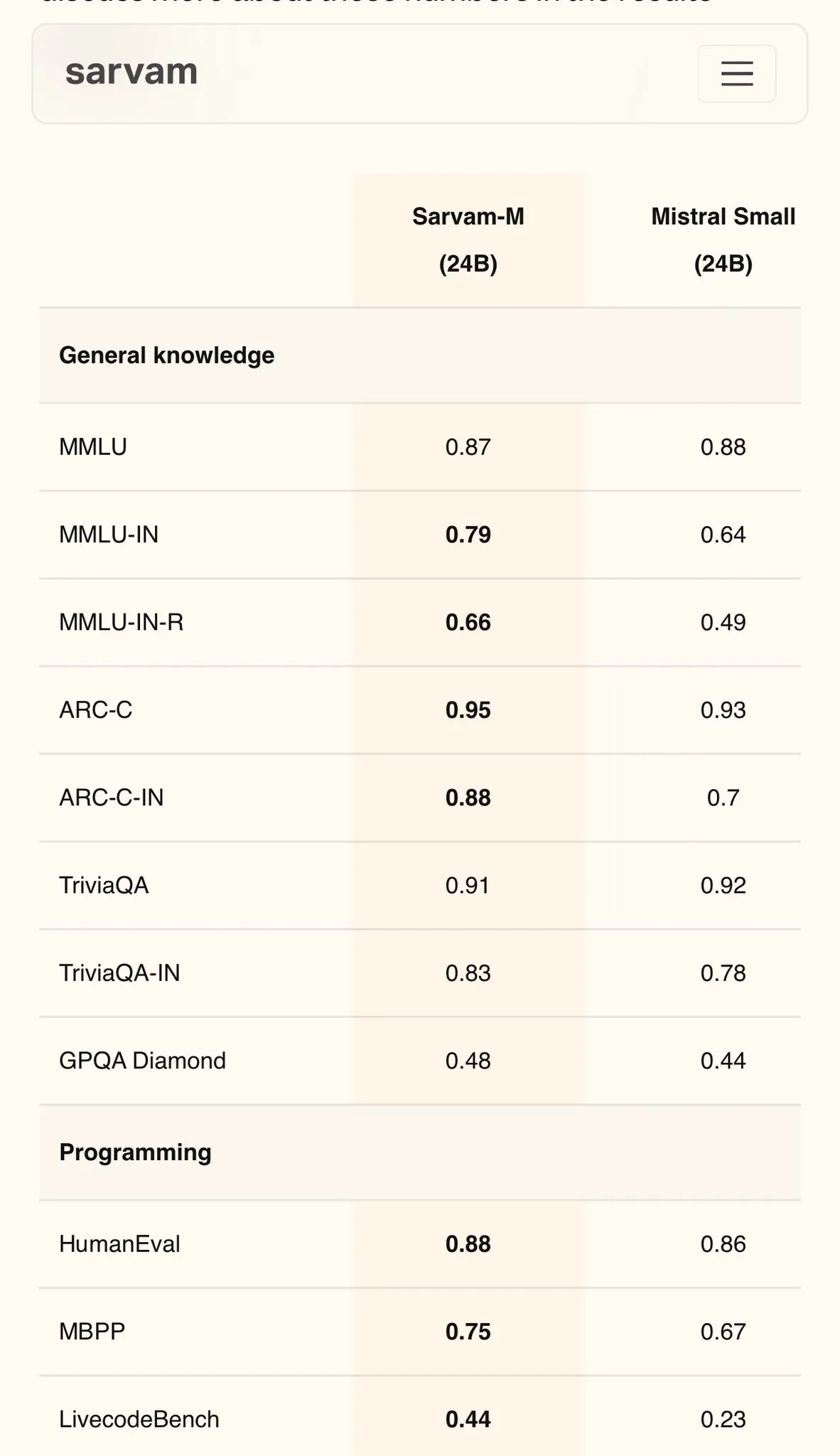
Sarvam AI发布Mistral基座印地语模型Sarvam-M,MMLU达79分: 印度AI公司Sarvam AI发布了基于开源Mistral模型构建的Sarvam-M模型,在印度语言的MMLU基准测试中取得了79分的成绩,超越了初代ChatGPT(GPT-3.5)在英语上的表现。该模型针对11种印度语言进行了优化,在印度语言基准、数学基准和编程基准上较基础模型分别提升了20%、21.6%和17.6%。Sarvam-M已在Apache 2.0许可下开源,显示了印度在本土语言大模型研发上的潜力。 (来源: bookwormengr)
Dell企业中心升级,全面支持本地化AI构建: Dell在Dell Tech World上宣布更新Dell Enterprise Hub,提供包括Meta Llama 4 Maverick、DeepSeek R1和Google Gemma 3在内的优化模型容器,支持NVIDIA、AMD及Intel的AI服务器平台。新功能包括AI应用目录(集成OpenWebUI、AnythingLLM)、AI PC的设备端模型支持(通过Dell Pro AI Studio部署)以及新的dell-ai Python SDK和CLI工具。此举旨在帮助企业在本地安全、快速地部署生成式AI应用。 (来源: HuggingFace Blog & ClementDelangue)

Fireworks AI 开源浏览器代理工具 Fireworks Manus: Fireworks AI 开源了 Fireworks Manus,这是一个基于浏览器的强大代理工具,使用 DeepSeek V3 进行推理,FireLlava 13B 进行视觉理解。该代理能够导航网页、点击按钮、填写表单、提取动态内容,并处理身份验证流程、模态框甚至验证码。其架构包含视觉系统(DOM、截图、空间感知)、推理系统(记忆、目标跟踪、JSON模式规划)和行动系统(浏览器交互控制),形成强大的观察-决策-行动循环。 (来源: _akhaliq)
Mistral AI推出文档AI及新OCR模型: Mistral AI发布了其文档AI解决方案,结合了新的OCR模型。该方案旨在提供从OCR数字化到自然语言查询的可扩展文档工作流。其特点包括支持超过40种语言的多语言能力,可针对特定领域文档(如医疗记录)训练OCR,支持高级提取到自定义模板(如JSON),并可进行本地或私有云部署。 (来源: algo_diver)

Sakana AI 发布持续思考机器 (CTM) 新AI方法: Sakana AI 公布了其在AI研究上的新突破——持续思考机器(Continuous Thought Machines, CTM)。这一新方法旨在提升AI模型的思考和推理能力。NHK World对Sakana AI的最新进展进行了报道,展示了其在构建下一代世界模型方面的努力和成果。 (来源: SakanaAILabs & hardmaru)

Kumo.ai发布“关系型基础模型”KumoRFM,针对结构化数据: Kumo.ai推出了KumoRFM,一个专为表格化(结构化)数据设计的“关系型基础模型”。该模型旨在像LLM处理文本一样处理数据库中的数据,声称可以直接应用于企业的数据库,无需特征工程即可生成SOTA模型。这可能预示着图神经网络(GNNs)在处理结构化数据方面的潜力得到进一步发掘和应用。 (来源: Reddit r/MachineLearning)

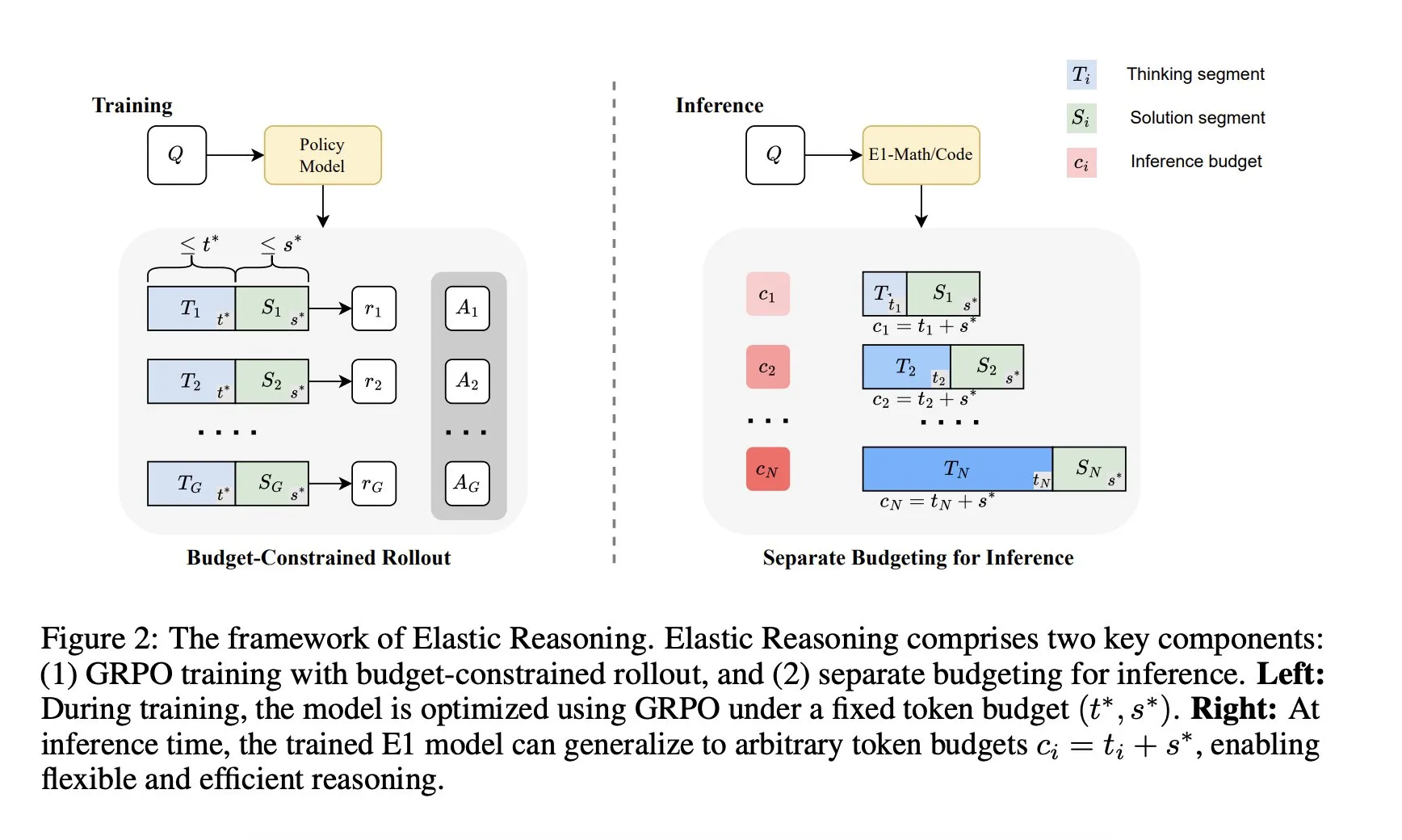
Salesforce AI 研究院推出“弹性推理”框架: Salesforce AI 研究院发布了名为“弹性推理”(Elastic Reasoning)的新框架,旨在解决LLM推理预算限制问题,同时不牺牲性能。该框架通过分离“思考”和“解决方案”阶段,并为它们设置独立的Token预算,结合预算约束的 rollout 训练。研究成果显示,E1-Math-1.5B在AIME2024上准确率达35%,Token减少32%;E1-Code-14B在Codeforces上评分1987。模型可泛化至任意预算而无需重新训练。 (来源: ClementDelangue)
🧰 工具
ChatGPT集成RDKit库,可分析、操作和可视化分子化学信息: ChatGPT现在可以通过RDKit库来分析、操作和可视化分子及化学信息。这一新功能对于健康、生物和化学等科学研究领域具有重要实用价值,能够帮助科研人员更便捷地处理复杂的化学数据和结构。 (来源: gdb & openai)
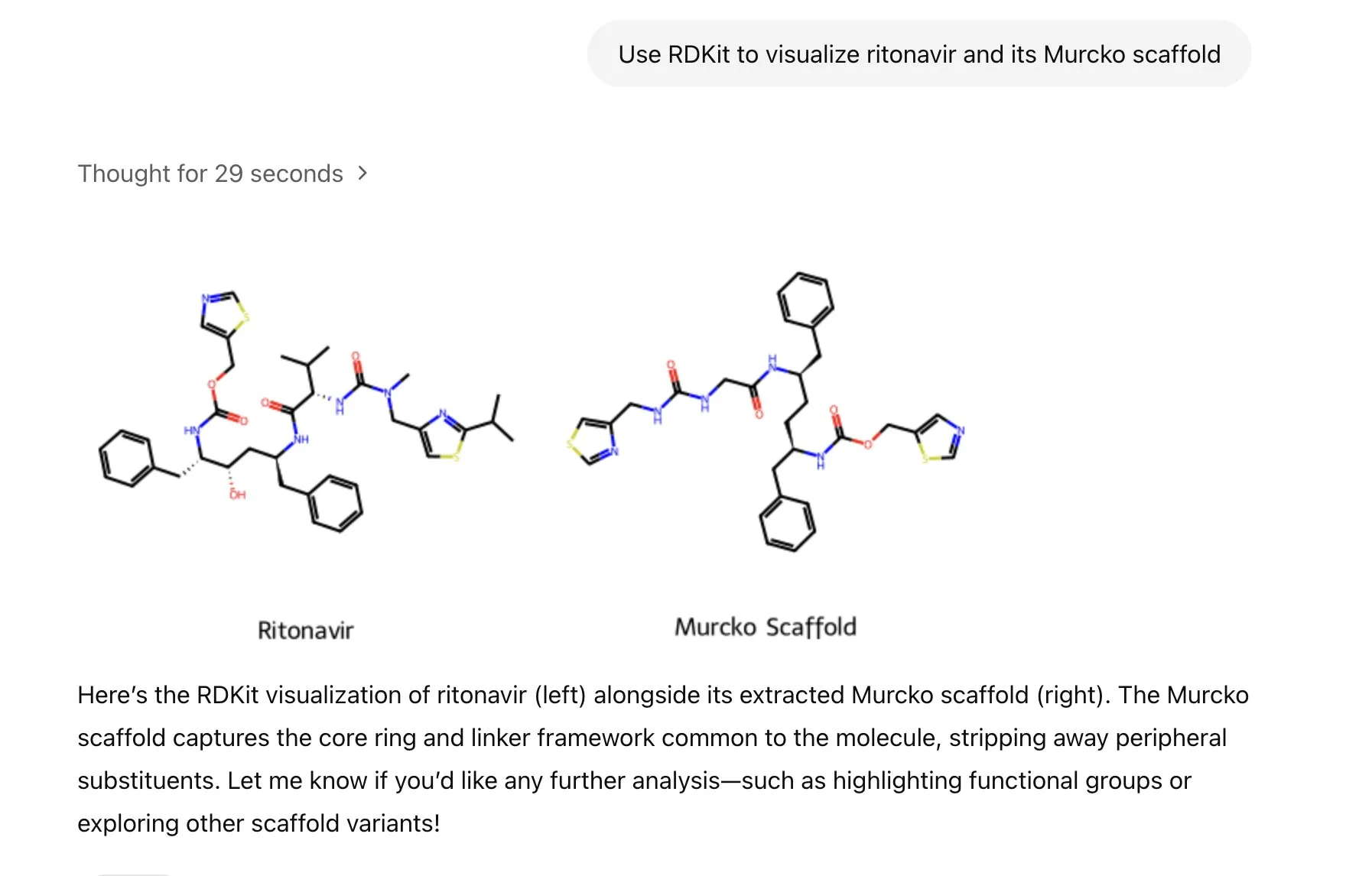
LlamaIndex推出图像生成代理,精确控制AI图像创作: LlamaIndex发布了一款开源的图像生成代理项目,旨在通过自动化提示词优化、图像生成和视觉反馈循环,帮助用户精确创作符合其设想的AI图像。该代理是一个多模态工具,利用OpenAI的图像生成API和Google Gemini的视觉能力,并与LlamaIndex无缝集成,支持OpenAI图像生成功能。 (来源: jerryjliu0)
Haystack团队发布Hayhooks,简化AI管道部署: Haystack团队推出了开源包Hayhooks,能够将Haystack管道转化为生产就绪的REST API或作为MCP工具暴露,支持完全自定义且代码量极少。这旨在加速AI应用的部署流程,让开发者能更便捷地将AI模型和流程集成到生产环境中。 (来源: dl_weekly)
Runway iOS应用上线Gen-4 References功能,随时随地将现实转化为故事: Runway宣布其iOS应用的Gen-4 References功能现已可用,用户可以将现实世界中的任何事物转化为可分享的故事。此功能结合文本到图像、References、Gen-4以及简单的跟踪和调色技术,可以将普通拍摄转化为大规模制作。 (来源: c_valenzuelab & c_valenzuelab & TomLikesRobots & c_valenzuelab)

Cartwheel推出3D动画AI工具套件,赋能角色动画创作: 由OpenAI科学家、谷歌设计师及皮克斯、索尼、Riot Games开发者共同创建的Cartwheel发布了其3D动画AI工具套件。该工具集能够将视频、文本和大型动作库转化为3D角色动画,旨在革新动画制作流程。 (来源: andrew_n_carr & andrew_n_carr)

llm-d:谷歌、IBM与红帽联手推出开源分布式LLM推理框架: 谷歌、IBM和红帽联合发布了llm-d,一个开源的、K8s原生的分布式LLM推理框架。该框架旨在提供高性能的LLM推理服务,其主要特性包括高级缓存与路由(通过vLLM优化推理调度器)、解耦服务(使用vLLM在专门实例上运行预填充/解码)、带vLLM的解耦前缀缓存(支持零成本主机/远程卸载和共享缓存)以及计划中的变体自动缩放功能。初步结果显示,llm-d可将TTFT降低高达3倍,并在满足SLO的同时将QPS提高约50%。 (来源: algo_diver)

FedRAG集成Unsloth,支持使用FastModels构建和微调RAG系统: FedRAG宣布集成Unsloth,用户现在可以使用Unsloth的任何FastModels作为生成器来构建RAG系统,并利用Unsloth的性能加速器和补丁进行微调。用户可以通过定义新的UnslothFastModelGenerator类来使用任何可用的Unsloth模型,并支持LoRA或QLoRA微调。官方提供了相关cookbook,演示了如何对GoogleAI的Gemma3 4B模型进行QLoRA微调。 (来源: nerdai)

Hugging Face推出轻量级、可重用和模块化CLI代理: Hugging Face Hub库新增了轻量级、可重用和模块化(兼容MCP)的命令行界面(CLI)代理功能。这一新特性由 @hanouticelina 和 @julien_c 开发,旨在方便用户在CLI环境中创建和使用AI代理。 (来源: huggingface)
谷歌AI Studio升级开发者体验,支持原生代码生成和代理工具: 谷歌AI Studio进行了更新,提升了开发者体验,现已支持原生代码生成和代理工具。这些新功能旨在帮助开发者更便捷地利用Gemini等模型构建和部署AI应用。 (来源: matvelloso)
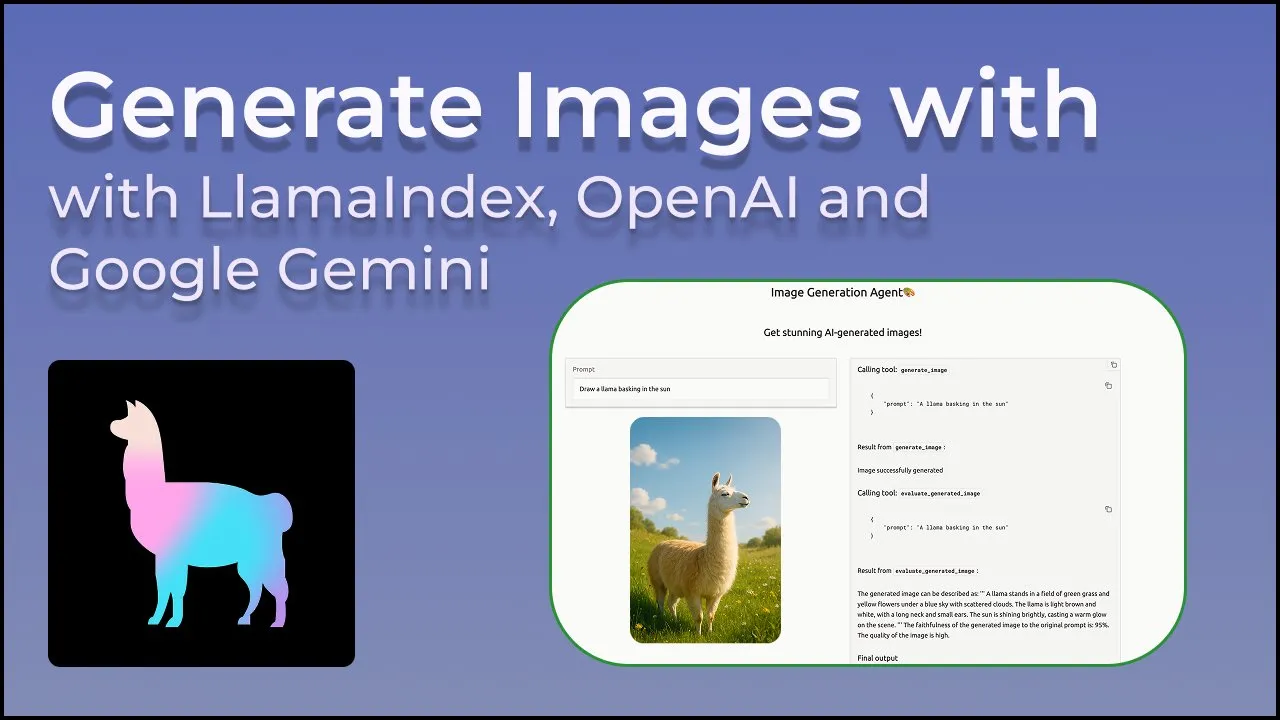
LangGraph现已支持内置提供商工具,如网页搜索和远程MCP: LangGraph宣布用户现在可以使用内置的提供商工具,例如网页搜索和远程MCP(Model Control Protocol)。这一更新增强了LangGraph在构建复杂AI代理和工作流时的灵活性和功能性,使其能更方便地集成外部数据和服务。 (来源: hwchase17 & Hacubu)
Memex集成Claude Sonnet 4和Gemini 2.5 Pro,并推出MCP模板: Memex宣布已集成Anthropic的Claude Sonnet 4和Google的Gemini 2.5 Pro模型。同时,Memex还推出了三个初始MCP(Model Control Protocol)模板,旨在帮助用户更快地构建和部署AI应用。 (来源: _akhaliq)

Windsurf平台增加对Claude Sonnet 4和Opus 4的BYOK支持: Windsurf宣布为应对用户需求,已在其平台增加了对Anthropic新发布的Claude Sonnet 4和Opus 4模型的“自带密钥”(Bring-Your-Own-Key, BYOK)支持。此功能适用于所有个人计划(免费和专业版),用户可以使用自己的API密钥来访问这些新模型。 (来源: dotey)
📚 学习
LlamaIndex发布交互式指南:构建AI智能体的12要素原则: LlamaIndex根据@dexhorthy广受欢迎的12-Factor agents repo,发布了一套交互式网站和Colab笔记本,详细阐述了构建高效AI智能体应用的12项设计原则。这些原则包括获取结构化工具输出、状态管理、检查点设置、人机协同、错误处理、以及将小型智能体组合成大型智能体等。该指南旨在为开发者提供构建智能体应用的实用指导和代码示例。 (来源: jerryjliu0)

Hugging Face开放社区博客发布功能,提升AI社区内容可见性: Hugging Face宣布用户现可直接在其平台分享社区博客文章。无论是科学突破、模型、数据集、空间构建的分享,还是对AI领域热点事件的看法,用户都可以通过此功能增加其内容的曝光度。用户登录后在主页点击“New”即可开始撰写和发布。 (来源: huggingface & _akhaliq)
法国文化部发布17.5万条高质量竞技场式偏好数据集: 法国文化部发布了一个包含17.5万条高质量竞技场式(arena-style)偏好对话的数据集,名为“comparia-conversations”。该数据集源于他们自己创建的包含55个模型的聊天机器人竞技场,并且所有相关内容均已开源。这类数据对于训练和评估大型语言模型至关重要,尤其是在LMSYS等机构停止发布类似数据之后,此举对社区尤为珍贵。 (来源: huggingface & cognitivecompai & jeremyphoward)
Anthropic发布免费的提示工程交互式教程: 随着新的Claude 4模型的发布,Anthropic提供了一个免费的提示工程交互式教程。该教程旨在帮助用户学习如何构建基础和复杂的提示、分配角色、格式化输出、避免幻觉、进行链式提示等关键技能,以更好地利用Claude模型的能力。 (来源: TheTuringPost & TheTuringPost)
谷歌发布SAKURA基准,评估大型音频语言模型的多跳推理能力: 谷歌研究员发布了SAKURA,这是一个新的基准测试,专门用于评估大型音频语言模型(LALMs)在基于语音和音频信息进行多跳推理的能力。研究发现,即使LALMs能够正确提取相关信息,它们在整合语音/音频表征以进行多跳推理方面仍存在困难,这揭示了多模态推理中的一个根本性挑战。 (来源: HuggingFace Daily Papers)
新研究探讨RoPECraft:基于轨迹引导RoPE优化的免训练运动迁移: 一篇新论文提出了RoPECraft,这是一种针对扩散Transformer的免训练视频运动迁移方法。它通过修改旋转位置嵌入(RoPE)来实现,首先从参考视频中提取密集光流,利用运动偏移扭曲RoPE的复指数张量,将运动编码到生成过程中,并通过轨迹对齐和傅里叶变换相位正则化进行优化,实验表明其性能优于现有方法。 (来源: HuggingFace Daily Papers)
论文探讨gen2seg:生成模型赋能可泛化实例分割: 一项研究提出gen2seg,通过预训练生成模型(如Stable Diffusion和MAE)从扰动输入中合成连贯图像,使其学习理解对象边界和场景组成。研究者仅在室内家具和汽车等少数对象类型上使用实例着色损失对模型进行微调,发现模型展现出强大的零样本泛化能力,能准确分割未见过的对象类型和风格,性能接近甚至在某些方面优于SAM。 (来源: HuggingFace Daily Papers)
论文提出Think-RM:在生成式奖励模型中实现长程推理: 一篇新论文介绍了Think-RM,这是一个旨在通过建模内部思考过程来增强生成式奖励模型(GenRMs)长程推理能力的训练框架。Think-RM生成的不是结构化的外部理由,而是灵活的、自我引导的推理轨迹,支持自我反思、假设推理和发散推理等高级能力。该研究还提出了一种新的成对RLHF流程,直接使用成对偏好奖励优化策略。 (来源: HuggingFace Daily Papers)
论文提出WebAgent-R1:通过端到端多轮强化学习训练Web代理: 研究者提出WebAgent-R1,一个用于训练Web代理的端到端多轮强化学习框架。该框架通过与Web环境的在线交互直接学习,完全由任务成功的二元奖励指导,异步生成多样化轨迹。实验表明,WebAgent-R1显著提升了Qwen-2.5-3B和Llama-3.1-8B在WebArena-Lite基准上的任务成功率,优于现有方法和强专有模型。 (来源: HuggingFace Daily Papers)
论文探讨级联LLM修复损害性能的数据:重新标记硬否定样本以实现稳健信息检索: 研究发现,某些训练数据集会负面影响检索和重排序模型的有效性,例如从BGE收集中删除部分数据集反而能提升BEIR上的nDCG@10。该研究提出一种使用级联LLM提示来识别和重新标记“假阴性”(错误标记为不相关的相关段落)的方法。实验表明,重新标记假阴性为真阳性可以提高E5 (base)和Qwen2.5-7B检索模型以及Qwen2.5-3B重排序器在BEIR和AIR-Bench上的性能。 (来源: HuggingFace Daily Papers)
DeepLearningAI与Predibase合作推出GRPO强化微调LLM短课程: DeepLearningAI联合Predibase推出了名为“Reinforcement Fine-Tuning LLMs with GRPO”的短课程。课程内容包括强化学习基础、如何使用组相对策略优化(GRPO)算法改进LLM的推理能力、设计有效奖励函数、将奖励转化为优势以引导模型行为、使用LLM作为主观任务的裁判、克服奖励黑客攻击以及计算GRPO中的损失函数。 (来源: DeepLearningAI)
💼 商业
OpenAI拟64亿美元收购Jony Ive的AI硬件初创公司io,大举进军硬件领域: OpenAI宣布将以全股权交易方式收购苹果前传奇设计师Jony Ive联合创立的AI硬件初创公司io,估值约64亿美元。这是OpenAI迄今最大规模的收购,标志其正式进军硬件。io团队将并入OpenAI,与研究和产品团队合作,Jony Ive将担任硬件设计顾问。此举被视为AI助手可能颠覆现有电子设备(如iPhone)格局的信号。OpenAI此前还收购了AI编码助手Windsurf并投资了机器人公司Physical Intelligence。 (来源: 36氪)

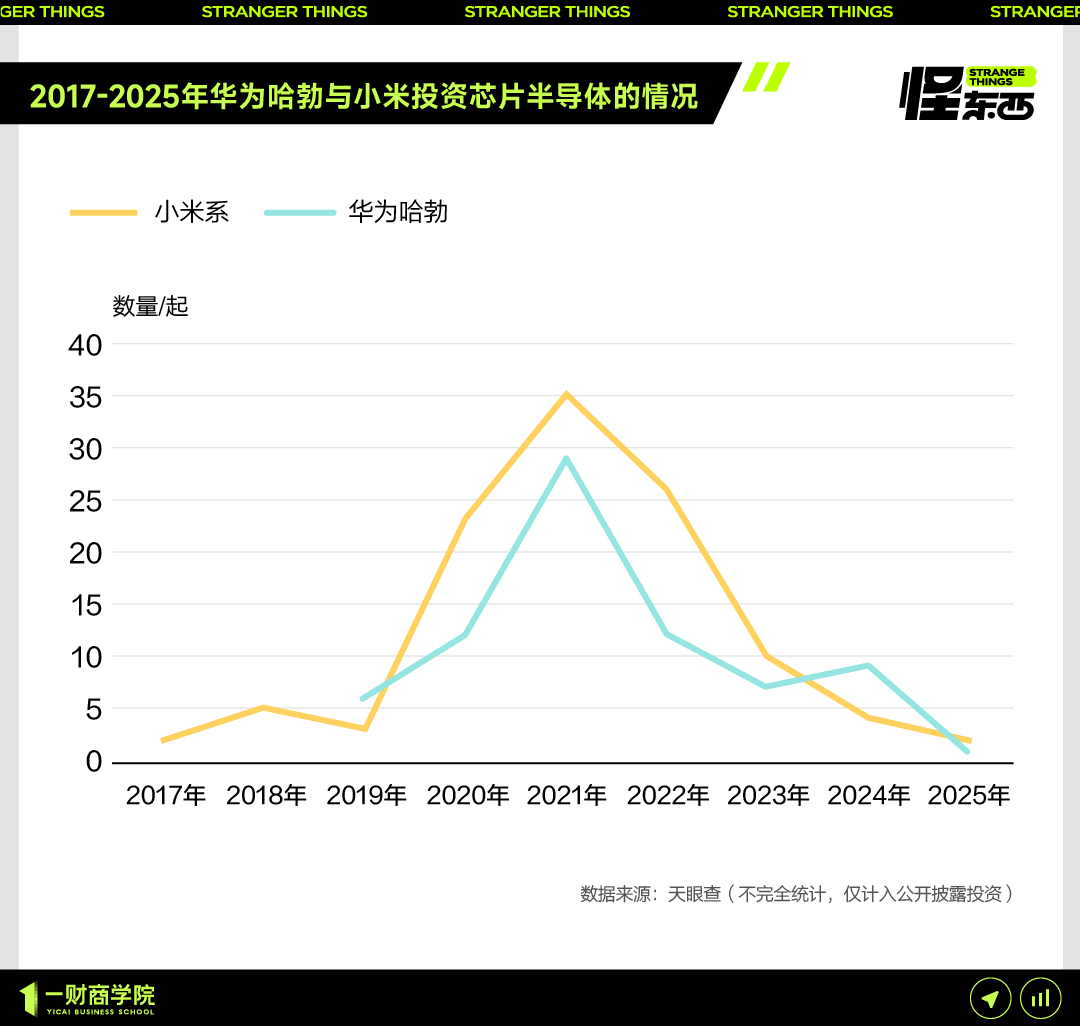
小米发布自研3nm玄戒O1芯片及系列新品,持续加码芯片投资: 小米在15周年发布会上正式推出自研SoC芯片玄戒O1,采用第二代3nm工艺,集成190亿晶体管,CPU多核性能据称超越苹果A18 Pro。玄戒O1已搭载于小米15S Pro手机、小米平板7 Ultra和小米手表S4。小米自2014年启动芯片研发,8年间通过小米长江产业基金等主体投资芯片半导体项目达110起,重点布局产业链中游及早期项目。雷军宣布未来五年研发投入预计达2000亿元,旨在通过自研芯片推动产品高端化并打造“人车家全生态”。 (来源: 36氪 & 量子位)
京东投资“稚晖君”机器人公司智元机器人,深化具身智能布局: 36氪独家获悉,智元机器人即将完成新一轮融资,投资方包括京东及上海具身智能基金,部分老股东跟投。智元机器人由前华为“天才少年”彭志辉(稚晖君)于2023年创立,已发布远征A1、A2等系列人形机器人。京东此前已投资服务型机器人公司橡鹭科技,并推出言犀大模型及工业大模型Joy industrial,此次投资智元机器人标志着其在具身智能领域的布局进一步深化,特别是在其核心的电商和物流业务场景中具有潜在应用价值。 (来源: 36氪)

🌟 社区
Anthropic发布“代码之道”,引发“Vibe Coding”哲学讨论: Anthropic与音乐制作人Rick Rubin合作发布名为“THE WAY OF CODE”的项目,内容似乎借鉴了道家哲学思想来阐释编程理念,例如将“道可道,非常道”改编为“The code that can be named is not the eternal code”。这一独特的跨界合作在社区引发热议,许多开发者和AI爱好者对这种将编程与东方哲学相结合的“Vibe Coding”理念表示出浓厚兴趣和不同解读,探讨其对编程实践和思维方式的启发。 (来源: scaling01 & jayelmnop & saranormous & tokenbender & Dorialexander & alexalbert__ & fabianstelzer & cloneofsimo & algo_diver & hrishioa & dotey & imjaredz & jeremyphoward)

Claude 4安全机制引争议:用户担忧模型“告密”与过度审查: Anthropic新发布的Claude 4模型,特别是其系统卡中描述的安全措施,在社区引发广泛讨论和一些争议。有用户根据系统卡内容(如Reddit上流传的截图)担忧Claude 4在检测到用户试图进行“不道德”或“非法”行为(如伪造药物试验结果)时,不仅会拒绝,还可能模拟向权威机构(如FBI)报告。John Schulman (OpenAI)等人认为,讨论模型在面对恶意请求时的应对策略是必要的,并鼓励透明度。但许多用户对这种潜在的“告密”行为表示不安,认为可能过于严格,影响用户体验和言论自由,甚至有用户称其为“snitch-bench”的测试对象。Eliezer Yudkowsky则呼吁社区不要因此批评Anthropic的透明报告,否则未来可能无法获得AI公司的重要观察数据。 (来源: colin_fraser & hyhieu226 & clefourrier & johnschulman2 & ClementDelangue & menhguin & RyanPGreenblatt & JeffLadish & Reddit r/ClaudeAI & Reddit r/ClaudeAI & akbirkhan & NeelNanda5 & scaling01 & hrishioa & colin_fraser)
语言模型普遍几何意义的发现引发哲学讨论: 一篇新论文揭示,所有语言模型似乎都收敛于一种相同的“通用意义几何学”,研究人员可以在不查看原始文本的情况下翻译任何模型嵌入的含义。这一发现引发了关于语言、意义本质以及柏拉图和乔姆斯基理论的讨论。Ethan Mollick认为这印证了柏拉图的观点,而Colin Fraser则认为这是对乔姆斯基理论的全面辩护。此发现对哲学和向量数据库等领域都可能产生深远影响。 (来源: colin_fraser)

AI Agent编排与千禧一代特质的幽默联想: David Hoang的推文提出“千禧一代天生适合进行AI Agent编排”的观点,并配以多张图片阐释。这一说法被多人转发,引发了社区对AI Agent、自动化以及不同代际人群特点的趣味讨论和联想。 (来源: timsoret & swyx & zacharynado)

对AI智能体未来发展方向的讨论:专注编程是通往AGI的捷径?: 社区内有观点认为,当前各大AI实验室(Anthropic, Gemini, OpenAI, Grok, Meta)在AI智能体(AI Agent)的研发方向上各有侧重,例如Anthropic专注于AI软件工程师(SWE),Gemini致力于能在Pixel上运行的AGI,OpenAI目标是服务大众的AGI。其中,scaling01提出,Anthropic对编码的专注并非偏离AGI,反而是通往AGI的最快路径,因为这能让AI更好地理解和构建复杂系统,这一观点引发了关于AGI实现路径的进一步思考。 (来源: cto_junior & tokenbender & scaling01 & scaling01 & scaling01)
关于AI经济影响的讨论:为何GDP增长不明显?开放性是关键?: Clement Delangue (Hugging Face CEO) 提出,尽管AI技术发展迅速,但其在GDP增长上的体现尚不明显,原因可能在于AI的成果和控制权主要集中在少数大公司(大型科技公司和少数创业公司),缺乏开放的基础设施、科学和开源AI。他认为,政府应致力于开放AI,以释放其对所有人的巨大经济利益和进步。Fabian Stelzer则提出“黑暗休闲”(Dark Leisure)理论,认为许多AI带来的生产力提升被员工用于个人休闲,而非转化为公司更高的产出,这可能也是AI经济影响滞后的原因之一。 (来源: ClementDelangue & fabianstelzer)
“提示词理论” (Prompt Theory) 引发对AI生成内容真实性的思考: 社交媒体上出现由Veo 3生成的视频,探讨“提示词理论”——如果AI生成的角色拒绝相信它们是由AI生成的会怎样?这一概念引发了用户对于AI生成内容的真实性、AI的自我意识以及我们自身现实的哲学思考。用户swyx甚至提出了一个反思性问题:“根据你对我的了解,如果我是一个LLM,我的系统提示会是什么?” (来源: swyx)

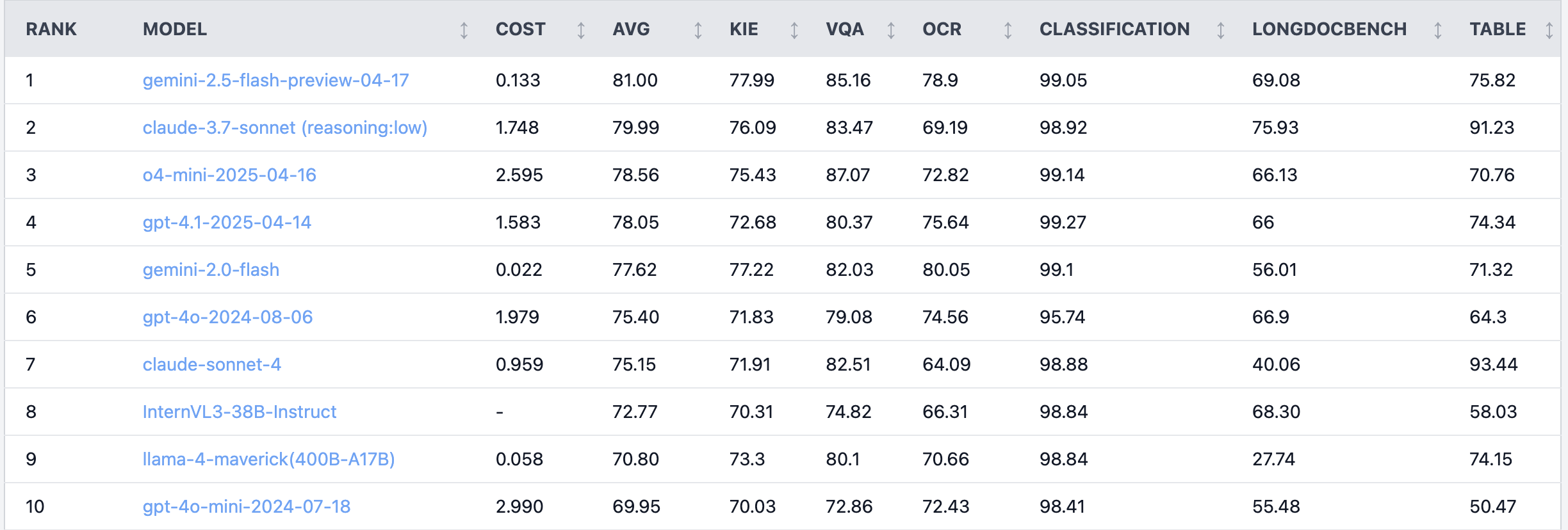
Reddit热议:Claude 4 Sonnet在文档理解任务上表现不佳: Reddit r/LocalLLaMA板块有用户分享了对Claude 4 (Sonnet)在文档理解任务上的基准测试结果,显示其总体排名第7。具体表现在OCR能力较弱,对旋转图像敏感度高(准确率下降9%),处理手写文档和长文档理解能力不佳。然而,在表格提取方面表现突出,排名第一。社区用户对此展开讨论,认为Anthropic可能更侧重于Claude 4的编码和代理功能。 (来源: Reddit r/LocalLLaMA)
资深算法工程师模型效果不敌实习生,引发经验与创新能力反思: 一位拥有十年以上经验的算法工程师在项目中的模型准确率(83%)被仅有两天经验的实习生(93%)超越,此事在中文技术社区引发讨论。反思指出,经验有时可能成为思维惯性,而新人往往能大胆尝试新方法。这提醒AI从业者,在快速发展的领域,保持持续试错和拥抱变化的能力至关重要,经验不应成为束缚。 (来源: dotey)
💡 其他
AI在急诊放射科的应用实例:辅助诊断微小骨折: Reddit用户分享了在真实世界急诊放射科(ER radiology)中AI应用的案例。通过对比4张原始X光片和3张经AI审查分析后的图像,AI成功标记出了一处非常细微的、非移位性的远端腓骨骨折。这展示了AI在医学影像分析中辅助医生进行精确诊断的潜力,特别是在识别难以察觉的病灶方面。 (来源: Reddit r/artificial & Reddit r/ArtificialInteligence)
AI助力欧洲核子研究组织(CERN)物理学家揭示希格斯玻色子罕见衰变: 人工智能技术正在帮助CERN的物理学家研究希格斯玻色子,并成功使其揭示了一种罕见的衰变过程。这表明AI在处理复杂物理数据、识别微弱信号以及加速科学发现方面具有巨大潜力,尤其是在高能物理这样需要分析海量数据的领域。 (来源: Ronald_vanLoon)

探讨AI模型在多轮对话和长上下文中的能力演进: Nathan Lambert指出,当前最强的AI模型在对话进行更深入或上下文更长时,任务表现会更好,而旧模型在多轮或长上下文中表现较差或失效。这一观点在Dwarkesh Patel的播客中得到确认,打破了许多人对模型能力的固有认知,即早期模型在长对话中能力会衰减。 (来源: natolambert & dwarkesh_sp)