
关键词:Gemini 2.5 Pro, Veo 3, AI视频生成, OpenAI, Jony Ive, Claude 4 Opus, AI智能体, 多模态模型, Deep Think模式, 视频生成模型, AI推理能力, AI硬件设计, 软件工程优化
🔥 聚焦
谷歌发布Gemini 2.5 Pro Deep Think与Veo 3,推动AI推理与视频生成新高度: 在Google I/O大会上,谷歌推出了Gemini 2.5 Pro的Deep Think模式,该模式专为解决复杂问题设计,在USAMO等数学竞赛难题上表现优异,展示了AI在高级推理方面的重大进展,例如通过多步推理和尝试不同证明方法(如反证法、罗尔定理)解决复杂代数问题。同时,谷歌发布的视频生成模型Veo 3,凭借其逼真的场景、可控的角色一致性、声音合成及多样的编辑功能(如场景变换、参考图生成、风格迁移、首尾帧指定、局部编辑等),在AI视频生成领域树立了新的标杆,引发广泛关注
OpenAI斥资65亿美元收购Jony Ive公司,共创AI驱动新一代计算机: OpenAI宣布与苹果前首席设计师Jony Ive合作,并收购其公司,旨在共同打造AI驱动的新一代计算机。此举标志着OpenAI向硬件领域拓展,并试图将AI能力深度集成到计算设备中,可能重塑人机交互方式。Jony Ive以其在苹果期间的卓越设计闻名,他的加入预示着新设备可能在设计和用户体验上有重大突破,挑战现有计算设备形态 (来源: op7418, TheRundownAI, BorisMPower)
Anthropic开发者大会召开在即,Claude 4 Opus或将发布,聚焦软件工程能力: Anthropic即将召开其首次开发者大会,社区普遍猜测新一代模型Claude 4(包括Sonnet 4和Opus 4)可能在此次大会上发布。有迹象表明Claude Sonnet 3.7 API已出现类似Claude 4的行为,如无需“思考步骤”的快速工具使用。Anthropic似乎正集中精力攻克软件工程难题,与OpenAI和谷歌追求“全能模型”的路径有所不同。TIME杂志也间接证实了Claude 4 Opus的发布,进一步提升了市场对Anthropic在AI编码和复杂任务处理能力上的期待 (来源: op7418, mathemagic1an, cto_junior, scaling01, Reddit r/ClaudeAI)
OpenAI与谷歌的AI生态战略差异:组装战舰与改造帝国: OpenAI和谷歌正分别通过“集齐生态”和“改造生态”两条不同路径,争夺未来AI平台的“主操作系统”地位。OpenAI通过收购硬件(io)、数据库(Rockset)、工具链(Windsurf)和协作工具(Multi)等,从无到有地组装全栈AI能力。而谷歌则选择将其Gemini模型深度嵌入现有产品(搜索、安卓、Docs、YouTube等),并改造底层系统,实现AI原生化。两者策略虽异,但目标一致,均指向构建AI时代的终极平台 (来源: dotey)
🎯 动向
微软揭示“智能体网络”愿景,强调AI智能体将成为下一代工作核心: 微软CEO Satya Nadella在Build 2025大会及访谈中阐述了公司对“智能体网络(agentic web)”的愿景。他认为未来AI智能体将成为商业和M365生态的一等公民,甚至可能催生“AI智能体管理员”等新职业。当95%的代码由AI生成时,人类的角色将转向管理和编排这些智能体。微软正通过Azure AI Foundry、Copilot Studio及NLWeb等开放协议,构建开放的智能体生态系统,并将Teams打造成多智能体协作中心 (来源: rowancheung, TheTuringPost)
MMaDA:统一文本推理、多模态理解与图像生成的多模态扩散语言模型发布: 研究者推出了MMaDA(Multimodal Large Diffusion Language Models),这是一种新型多模态扩散基础模型,通过混合长思维链(Mixed Long-CoT)和统一强化学习算法UniGRPO,实现了文本推理、多模态理解和图像生成能力的统一。MMaDA-8B在多模态理解方面超越了Show-o和SEED-X,在文生图方面优于SDXL和Janus,模型和代码已在Hugging Face开源 (来源: _akhaliq, arankomatsuzaki, andrew_n_carr, Reddit r/LocalLLaMA)

dKV-Cache:为扩散语言模型设计缓存机制,大幅提升推理速度: 针对扩散语言模型(DLMs)推理速度慢的问题,研究者提出dKV-Cache机制。该方法借鉴自回归模型中的KV-Cache,通过延迟和条件化缓存策略,为DLMs的去噪过程设计键值缓存。实验表明,dKV-Cache能实现2-10倍的推理加速,显著缩小了DLMs与自回归模型在速度上的差距,甚至在长序列上提升性能,且可无训练地应用于现有DLM (来源: NandoDF, HuggingFace Daily Papers)

Imagen4在细节还原上表现出色,接近图像生成终局: Imagen4模型在根据复杂文本提示生成图像方面展现了强大的细节还原能力。例如,在生成包含25个具体细节(如特定颜色、物体、位置、光照和氛围)的图像时,Imagen4成功还原了其中的23个。这种高保真度和对复杂指令的精确理解,表明文生图技术正逼近能够完美再现用户想象的“终局”水平 (来源: cloneofsimo)

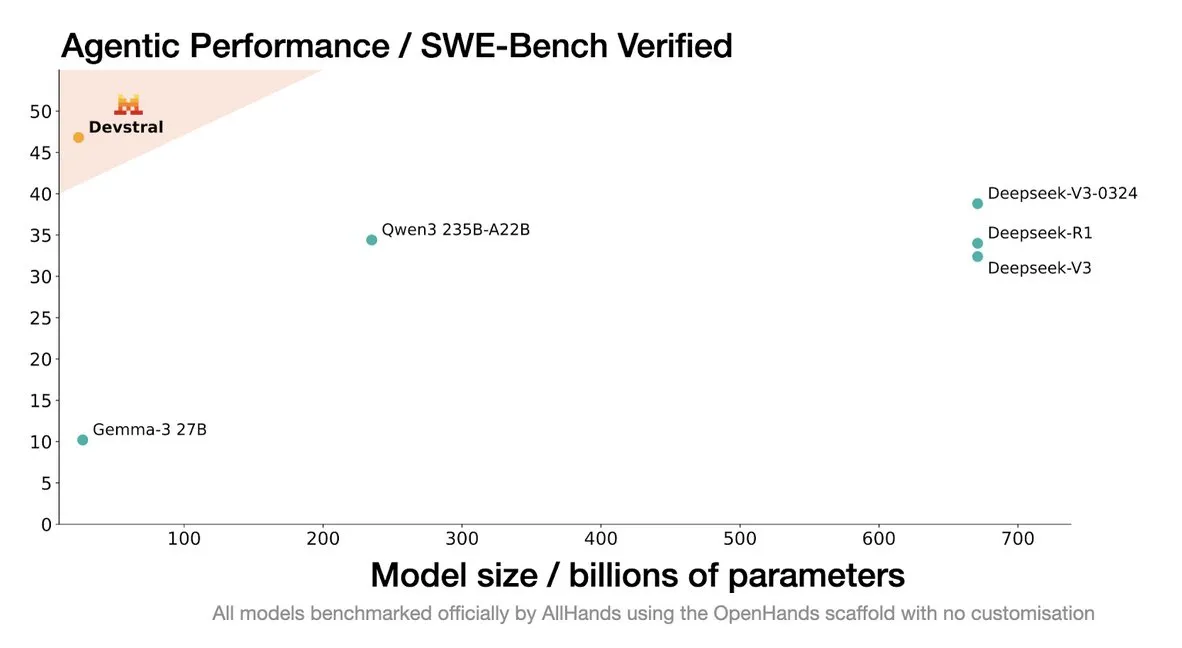
Mistral发布Devstral模型,专为编码智能体设计: Mistral AI推出了Devstral,这是一款专为编码智能体设计的开源模型,并与allhands_ai合作开发。其4位DWQ量化版本已在Hugging Face上线(mlx-community/Devstral-Small-2505-4bit-DWQ),可在M2 Ultra等设备上流畅运行,显示出在代码生成和理解方面的优化潜力 (来源: awnihannun, clefourrier, GuillaumeLample)
字节跳动发布Gemini级多模态模型训练报告,采用集成Transformer架构: 字节跳动公开了一份长达37页的报告,详细介绍了其训练类Gemini原生多模态模型的方法。其中最引人注目的是“集成Transformer”(Integrated Transformer)架构,该架构使用相同的骨干网络同时作为类GPT的自回归模型和类DiT的扩散模型,展示了其在多模态统一建模方面的探索 (来源: NandoDF)

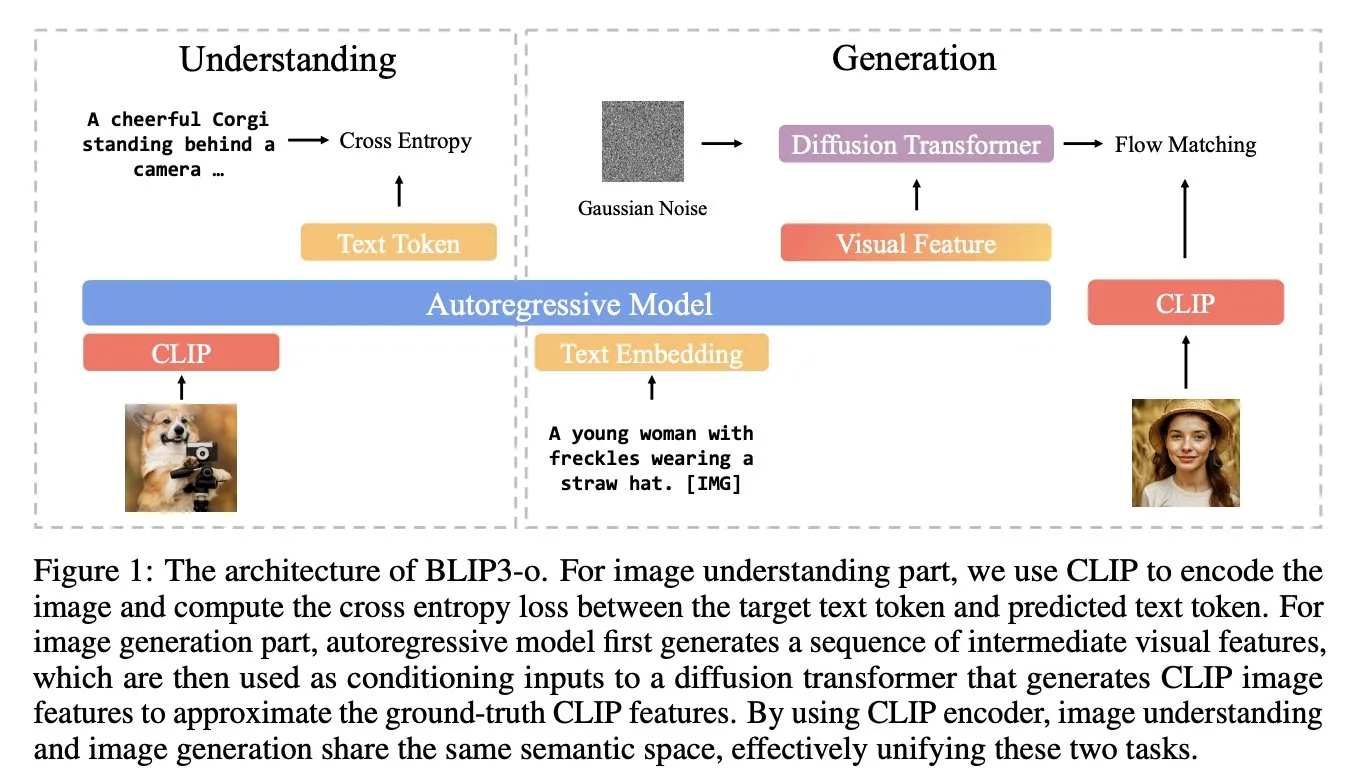
BLIP3-o:Salesforce推出全开源统一多模态模型系列,解锁GPT-4o级图像生成能力: Salesforce研究团队发布了BLIP3-o系列模型,这是一组完全开源的统一多模态模型,旨在尝试解锁类似GPT-4o的图像生成能力。该项目不仅开源了模型,还公开了包含2500万数据的预训练数据集,推动多模态研究的开放性 (来源: arankomatsuzaki)
谷歌推出Gemma 3n E4B预览版,专为低资源设备设计的多模态模型: 谷歌在Hugging Face上发布了Gemma 3n E4B-it-litert-preview模型。该模型设计用于处理文本、图像、视频和音频输入,并生成文本输出,当前版本支持文本和视觉输入。Gemma 3n采用新颖的Matformer架构,允许嵌套多个模型并有效激活2B或4B参数,专为在低资源设备上高效运行而优化。模型基于约11万亿token的多模态数据训练,知识截至2024年6月 (来源: Tim_Dettmers, Reddit r/LocalLLaMA)
研究揭示大模型中的语言特定知识(LSK)现象: 一项新研究探讨了语言模型中存在的“语言特定知识”(Language Specific Knowledge, LSK)现象,即模型在处理某些主题或领域时,在特定非英语语言中的表现可能优于英语。研究发现,通过在特定语言(甚至是低资源语言)中进行思维链推理,模型性能可以得到提升。这表明文化特定文本在相应语言中更丰富,使得特定知识可能只存在于“专家”语言中。研究者设计了LSKExtractor方法来衡量和利用这种LSK,在多个模型和数据集上平均准确率相对提高了10% (来源: HuggingFace Daily Papers)
DeepMind Veo 3视频生成效果惊艳,细节逼真引发关注: Google DeepMind的视频生成模型Veo 3展示了强大的视频生成能力,包括场景变换、参考图驱动、风格迁移、角色一致性、首尾帧指定、视频缩放、对象添加和动作控制等。其生成视频的逼真度和对复杂指令的理解能力,让用户感叹AI视频生成技术的飞速发展,甚至有用户用其制作了效果媲美专业制作的广告片
Moondream视觉语言模型推出4位量化版,显著降低显存并提升速度: Moondream视觉语言模型(VLM)发布了4位量化版本,实现了显存占用减少42%,推理速度提升34%,同时保持了99.4%的准确率。这一优化使得这款功能强大的小型VLM在物体检测等任务上更易于部署和使用,受到了开发者的欢迎 (来源: Sentdex, vikhyatk)
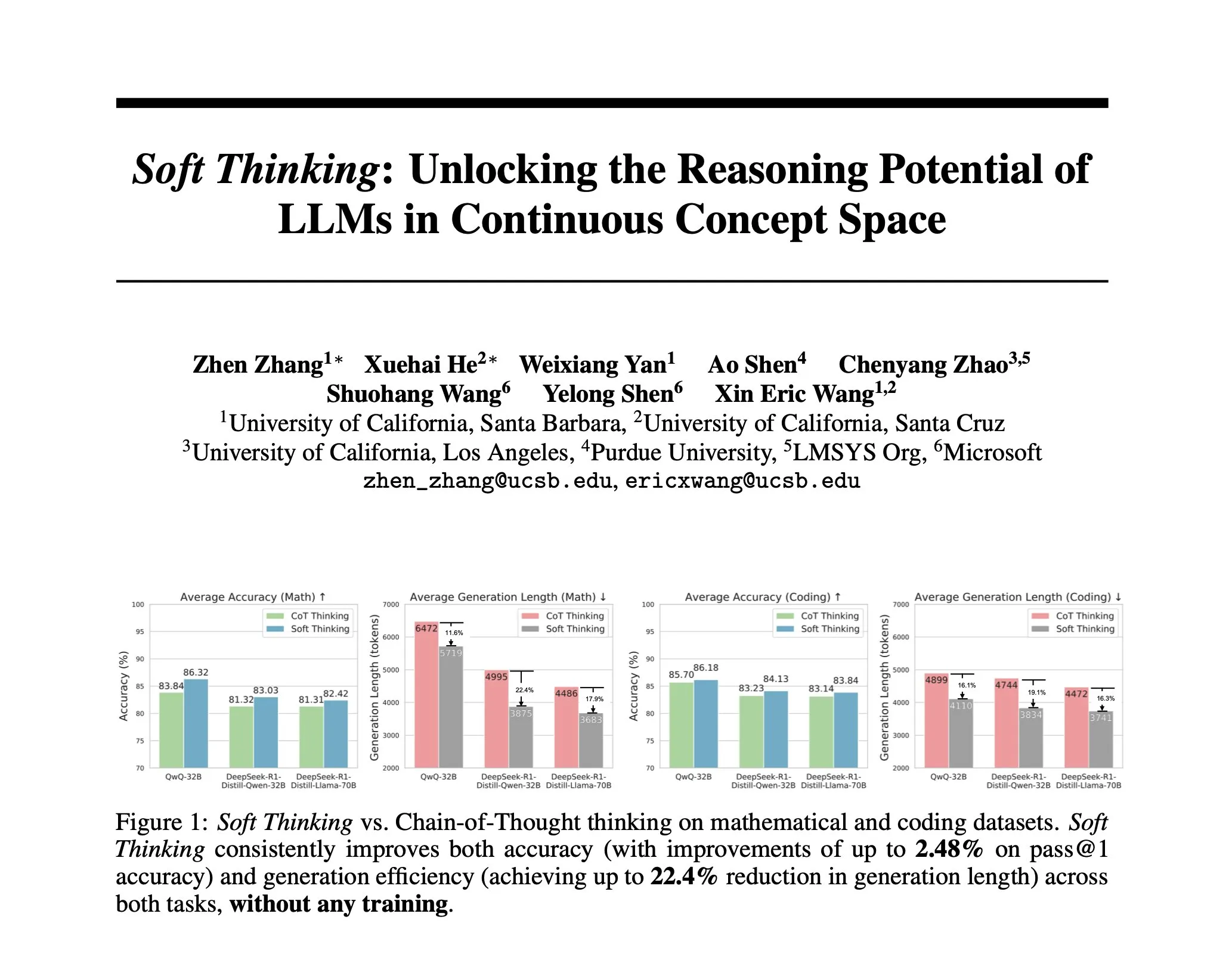
研究提出Soft Thinking:模拟人类“软”推理的无训练方法: 为了让AI推理更接近人类的流畅思维,不受离散token限制,研究者提出了Soft Thinking方法。该方法无需额外训练,通过生成连续的、抽象的概念token,这些token通过概率加权的嵌入混合来平滑融合多种含义,从而实现更丰富的表示和对不同推理路径的无缝探索。实验表明,该方法在数学和代码基准测试中准确率提升高达2.48% (pass@1),同时token使用量减少高达22.4% (来源: arankomatsuzaki)
IA-T2I框架:利用互联网增强文生图模型处理不确定知识的能力: 针对现有文生图模型在处理包含不确定知识(如新近事件、稀有概念)的文本提示时的不足,IA-T2I(Internet-Augmented Text-to-Image Generation)框架被提出。该框架通过主动检索模块判断是否需要参考图像,利用分层图像选择模块从搜索引擎返回结果中挑选最合适的图像来增强T2I模型,并通过自反思机制持续评估和优化生成图像。在专门构建的Img-Ref-T2I数据集上,IA-T2I表现优于GPT-4o约30%(人类评估) (来源: HuggingFace Daily Papers)
MoI (Mixture of Inputs) 提升自回归生成质量与推理能力: 为解决标准自回归生成过程中丢弃token分布信息的问题,研究者提出Mixture of Inputs (MoI) 方法。该方法无需额外训练,在生成一个token后,将生成的离散token与先前丢弃的token分布混合构造新的输入。通过贝叶斯估计,将token分布视为先验,采样token视为观测,用连续后验期望替换传统one-hot向量作为新模型输入。MoI在数学推理、代码生成和博士级问答任务上,持续提升了Qwen-32B、Nemotron-Super-49B等多个模型的性能 (来源: HuggingFace Daily Papers)
ConvSearch-R1:通过强化学习优化对话式搜索中的查询重写: 为解决对话式搜索中上下文依赖查询的歧义、省略和指代问题,ConvSearch-R1框架被提出。该框架首次采用自驱动方法,通过强化学习直接利用检索信号优化查询重写,完全消除了对外部重写监督(如人工标注或大模型)的依赖。其两阶段方法包括自驱动策略预热和基于检索引导的强化学习(采用等级激励奖励机制)。实验表明,ConvSearch-R1在TopiOCQA和QReCC数据集上显著优于先前SOTA方法 (来源: HuggingFace Daily Papers)
ASRR框架实现大语言模型高效自适应推理: 针对大型推理模型(LRMs)在简单任务上因冗余推理导致计算开销过大的问题,研究者提出了自适应自恢复推理(Adaptive Self-Recovery Reasoning, ASRR)框架。该框架通过揭示模型的“内部自恢复机制”(在答案生成中隐式补充推理),抑制不必要的推理,并引入准确率感知的长度奖励调节,根据问题难度自适应分配推理精力。实验表明,ASRR能在性能损失极小的情况下,大幅减少推理预算并提升安全基准上的无害率 (来源: HuggingFace Daily Papers)
MoT (Mixture-of-Thought) 框架提升逻辑推理能力: 受人类利用多种推理模态(自然语言、代码、符号逻辑)解决逻辑问题的启发,研究者提出Mixture-of-Thought (MoT) 框架。MoT使LLM能够跨三种互补模态进行推理,包括新引入的真值表符号模态。通过两阶段设计(自进化MoT训练和MoT推理),MoT在FOLIO和ProofWriter等逻辑推理基准上显著优于单模态思维链方法,平均准确率提升高达11.7% (来源: HuggingFace Daily Papers)
RL Tango:通过强化学习共同训练生成器与验证器以增强语言推理: 为解决现有LLM强化学习方法中验证器(奖励模型)固定或监督微调带来的奖励破解和泛化差问题,RL Tango框架被提出。该框架通过强化学习交错地同时训练LLM生成器和生成式的、过程级的LLM验证器。验证器仅基于结果级验证正确性奖励进行训练,无需过程级标注,从而与生成器形成有效互促。实验表明,Tango的生成器和验证器在7B/8B规模模型中均达到SOTA水平 (来源: HuggingFace Daily Papers)
pPE:先验提示工程助力强化细调(RFT): 研究探讨了先验提示工程(prior prompt engineering, pPE)在强化细调(RFT)中的作用。与推理时提示工程(iPE)不同,pPE在训练阶段将指令(如逐步推理)前置于查询,以引导语言模型内化特定行为。实验将五种iPE策略(推理、规划、代码推理、知识回忆、空示例利用)转化为pPE方法,应用于Qwen2.5-7B。结果显示,所有pPE训练模型均优于iPE对应模型,其中空示例pPE在AIME2024和GPQA-Diamond等基准上提升最大,揭示了pPE作为RFT中一个未被充分研究的有效手段 (来源: HuggingFace Daily Papers)
BiasLens:无需人工测试集的LLM偏见评估框架: 为解决现有LLM偏见评估方法依赖人工构建标签数据且覆盖有限的问题,BiasLens框架被提出。该框架从模型向量空间结构出发,结合概念激活向量(CAVs)和稀疏自动编码器(SAEs)提取可解释概念表示,通过衡量目标概念与参考概念间表示相似性的变化来量化偏见。BiasLens在无标签数据情况下与传统偏见评估指标显示强一致性(Spearman相关性r > 0.85),并能揭示难以用现有方法检测的偏见形式 (来源: HuggingFace Daily Papers)
HumaniBench:以人为本的大型多模态模型评估框架: 针对当前LMM在公平、道德、同理心等人本标准上表现不足的问题,HumaniBench被提出。这是一个包含32K真实世界图文问答对的全面基准,通过GPT-4o辅助标注并经专家验证。HumaniBench评估公平性、道德、理解、推理、语言包容性、同理心和鲁棒性七项人本AI原则,覆盖七大多样化任务。对15个SOTA LMM的测试显示,闭源模型普遍领先,但鲁棒性和视觉定位仍是弱点 (来源: HuggingFace Daily Papers)
AJailBench:首个大型音频语言模型越狱攻击综合基准: 为系统评估大型音频语言模型(LAMs)在越狱攻击下的安全性,AJailBench被提出。该基准首先构建了包含1495个对抗性音频提示的AJailBench-Base数据集,覆盖10个违规类别。基于此数据集的评估显示,现有SOTA LAMs均未表现出一致的鲁棒性。为模拟更真实的攻击,研究者开发了音频扰动工具包(APT),通过贝叶斯优化搜索微妙且高效的扰动,生成了扩展数据集AJailBench-APT。研究表明,微小且语义保留的扰动即可显著降低LAMs的安全性能 (来源: HuggingFace Daily Papers)
WebNovelBench:评估LLM长篇小说创作能力的基准: 为解决LLM长篇叙事能力评估的挑战,WebNovelBench被提出。该基准利用超4000部中文网络小说数据集,将评估设定为大纲到故事的生成任务。通过LLM即评判者的方法,从八个叙事质量维度进行自动评估,并使用主成分分析聚合得分,与人类作品进行百分位排名比较。实验有效区分了人类杰作、流行网络小说和LLM生成内容,并对24个SOTA LLM进行了综合分析 (来源: HuggingFace Daily Papers)
MultiHal:面向LLM幻觉评估的多语言知识图谱落地数据集: 为弥补现有幻觉评估基准在知识图谱路径和多语言性方面的不足,MultiHal被提出。这是一个基于知识图谱的多语言、多跳基准,专为生成文本评估而设计。团队从开放域知识图谱中挖掘了14万条路径,并筛选出2.59万条高质量路径。基线评估显示,在多语言和多模型上,知识图谱增强的RAG(KG-RAG)相比普通问答,在语义相似性得分上绝对提升约0.12至0.36点,展示了知识图谱集成的潜力 (来源: HuggingFace Daily Papers)
Llama-SMoP:基于稀疏混合投影器的LLM音视频语音识别方法: 为解决LLM在音视频语音识别(AVSR)中计算成本高的问题,Llama-SMoP被提出。这是一种高效的多模态LLM,采用稀疏混合投影器(SMoP)模块,通过稀疏门控的混合专家(MoE)投影器,在不增加推理成本的情况下扩展模型容量。实验表明,采用模态特定路由和专家的Llama-SMoP DEDR配置,在ASR、VSR和AVSR任务上均取得优异性能,并在专家激活、可扩展性和噪声鲁棒性方面表现良好 (来源: HuggingFace Daily Papers)
VPRL:基于强化学习的纯视觉规划框架,性能超越文本推理: 剑桥大学、伦敦大学学院和谷歌的研究团队提出了VPRL(Visual Planning with Reinforcement Learning),一种纯粹依靠图像序列进行推理的新范式。该框架利用群组相对策略优化(GRPO)对大型视觉模型进行后训练,通过视觉状态转换计算奖励信号并验证环境约束。在FrozenLake、Maze和MiniBehavior等视觉导航任务中,VPRL的准确率高达80.6%,显著优于基于文本的推理方法(如Gemini 2.5 Pro的43.7%),且在复杂任务和鲁棒性方面表现更佳,证明了视觉规划的优越性 (来源: 量子位)

英伟达公布未来五年AI技术路线图,转型AI基础设施公司: 英伟达CEO黄仁勋在COMPUTEX 2025上宣布公司定位调整为AI基础设施公司,并公布了未来五年技术路线图。他强调AI基础设施将如同电力或互联网一样无处不在,英伟达正致力于建造AI时代的“工厂”。为支持转型,英伟达将扩大供应链“朋友圈”,与台积电等深化合作,并计划在中国台湾地区建立办事处(NVIDIA Constellation)和首台巨型AI超级计算机 (来源: 36氪)

谷歌重启AI眼镜项目,发布Android XR平台及第三方设备: 谷歌在I/O 2025大会上宣布重启AI/AR眼镜项目,发布了专为XR设备开发的Android XR平台,并展示了基于该平台的两款第三方设备:三星的Project Moohan(对标Vision Pro)和Xreal的Project Aura。谷歌旨在复制Android在智能手机领域的成功,打造XR设备的“安卓时刻”,布局未来环境计算和空间计算平台。结合升级的Gemini 2.5 Pro多模态大模型和Project Astra智能体助理技术,新一代AI/AR眼镜将在语音理解、实时翻译、情境感知和复杂任务执行方面实现颠覆性体验 (来源: 36氪)

ARC-AGI-2挑战赛原则更新,强调多步上下文推理: 新发布的ARC-AGI-2论文更新了该挑战赛的设计原则。新原则要求解决任务需具备多规则、多步骤和上下文推理能力。网格更大,包含更多对象,并编码多个交互概念。任务具有新颖性且不可重用,以限制记忆。该设计有意抵制暴力程序合成。人类解决者平均每任务需2.7分钟,而顶级系统(如OpenAI o3-medium)得分仅约3%,所有任务均需明确的认知努力 (来源: TheTuringPost, clefourrier)
Skywork推出超级智能体,旨在将8小时工作缩短至8分钟: Skywork发布了其AI工作空间智能体——Skywork Super Agents,宣称能够将用户8小时的工作量压缩到8分钟内完成。该产品定位为AI工作空间智能体的开创者,具体功能和实现方式有待进一步观察 (来源: _akhaliq)
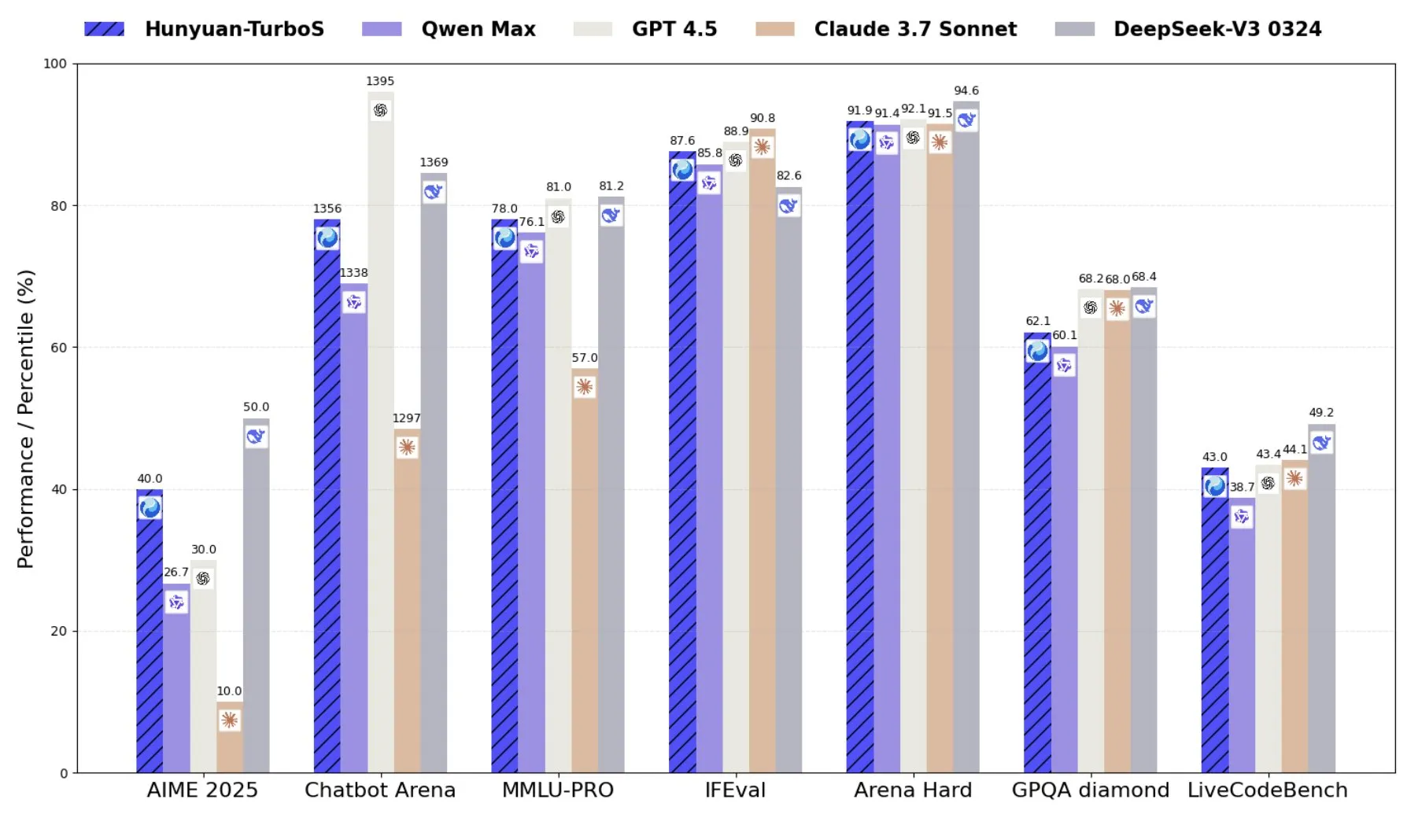
腾讯推出混元-TurboS,结合Transformer与Mamba的混合专家模型: 腾讯发布了Hunyuan-TurboS模型,该模型采用Transformer与Mamba的混合专家(MoE)架构,拥有560亿激活参数,并在16万亿token上进行训练。Hunyuan-TurboS能够动态切换快速响应和深度“思考”模式,在LMSYS Chatbot Arena上总体排名前七 (来源: tri_dao)
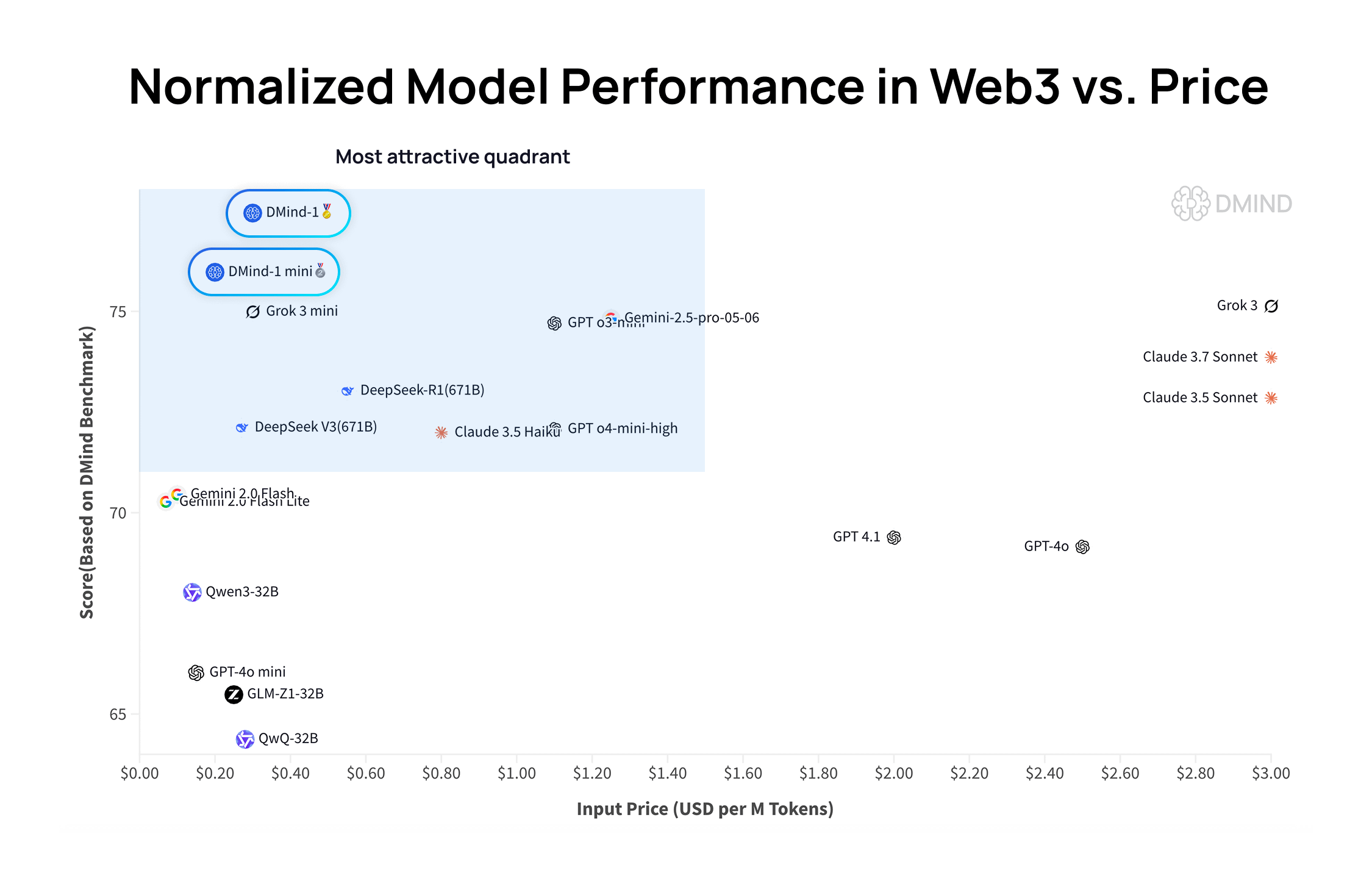
DMind-1:专为Web3场景设计的开源大语言模型: DMind AI发布了DMind-1,一款针对Web3场景优化的开源大语言模型。DMind-1 (32B) 基于Qwen3-32B微调,使用了大量Web3特定知识,旨在平衡AI+Web3应用的性能与成本。在Web3基准评估中,DMind-1表现优于主流通用LLM,且token成本仅为其10%左右。同时发布的DMind-1-mini (14B) 保留了DMind-1超过95%的性能,并在延迟和计算效率上更优 (来源: _akhaliq)
LightOn发布Reason-ModernColBERT,小参数模型在推理密集型检索任务中表现优异: LightOn推出了Reason-ModernColBERT,这是一款仅有1.49亿参数的晚期交互模型。在流行的BRIGHT基准测试(专注于推理密集型检索)中,该模型表现出色,超越了参数量大45倍的模型,并在多个领域达到SOTA水平。这一成果再次证明了晚期交互模型在特定任务上的高效性 (来源: lateinteraction, jeremyphoward, Dorialexander, huggingface)

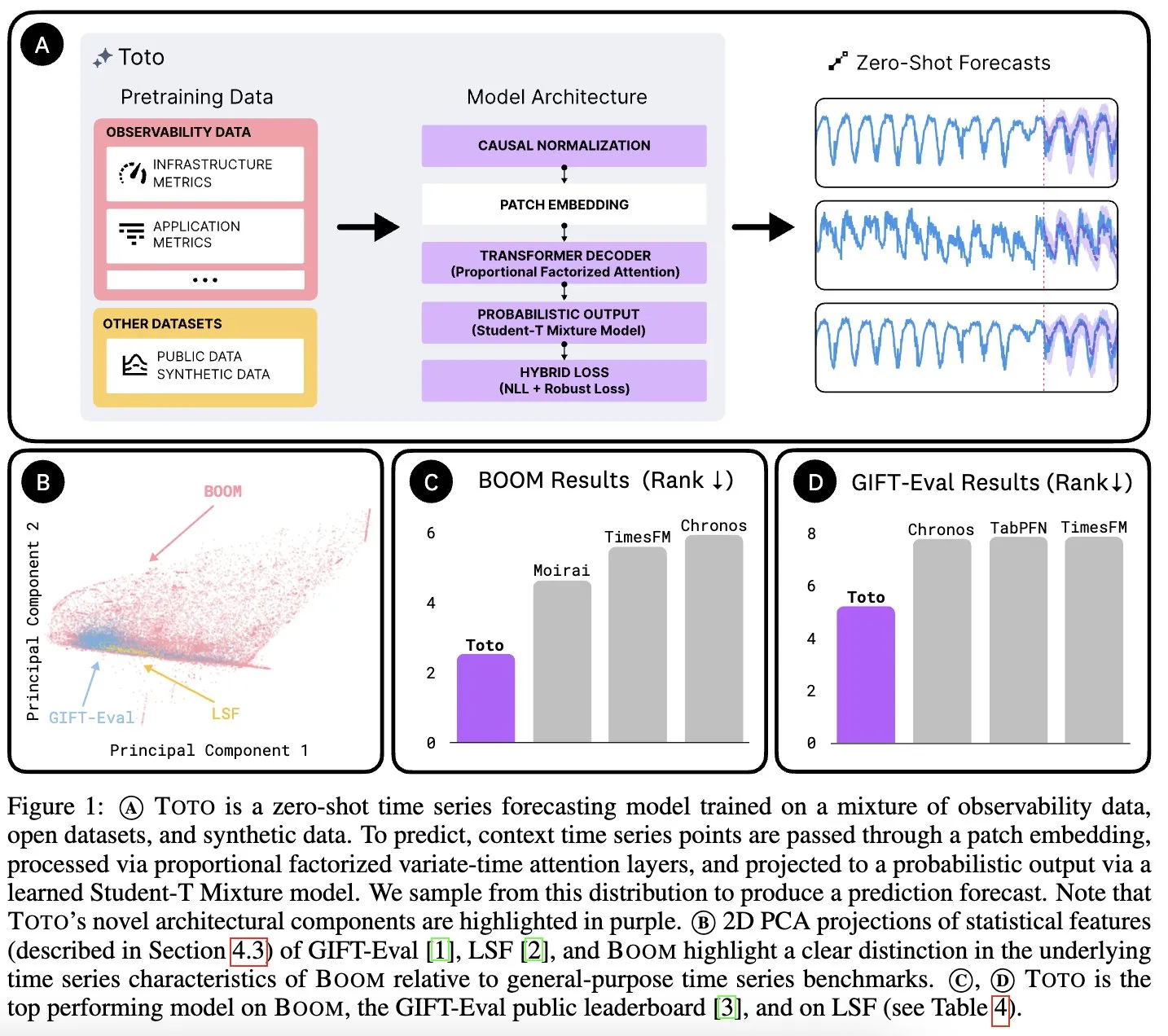
Datadog AI Research发布时间序列基础模型Toto和观测指标基准BOOM: Datadog AI Research推出了Toto,一个新的时间序列基础模型,并在相关基准测试中大幅领先现有SOTA模型。同时发布的还有BOOM,这是目前最大的可观测性指标基准。两者均采用Apache 2.0许可证开源,旨在推动时间序列分析和可观测性领域的研究与应用 (来源: jefrankle, ClementDelangue)
TII发布Falcon-H1系列混合Transformer-SSM模型: 阿联酋技术创新研究所(TII)发布了Falcon-H1系列模型,这是一组结合了Transformer注意力机制和Mamba2状态空间模型(SSM)头的混合架构语言模型。该系列模型参数规模从0.5B到34B不等,支持高达256K的上下文长度,并在多项基准测试中表现优于或媲美Qwen3-32B、Llama4-Scout等顶级Transformer模型,尤其在多语言(原生支持18种)和效率方面展现优势。模型已集成到vLLM、Hugging Face Transformers和llama.cpp (来源: Reddit r/LocalLLaMA)

MIT研究:AI无需人类干预即可学习视觉与声音的关联: MIT的研究人员展示了一种AI系统,它能够自主学习视觉信息和相应声音之间的联系,而无需人类的明确指导或标记数据。这种能力对于开发更全面的多模态AI系统至关重要,使其能够更像人类一样理解和感知世界 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

阿联酋推出大型阿拉伯语AI模型,加速海湾地区AI竞赛: 阿联酋发布了一款大型阿拉伯语AI模型,标志着其在人工智能领域的进一步投入,并加剧了海湾地区国家在AI技术发展方面的竞争。此举旨在提升阿拉伯语在AI领域的影响力,并满足本地化AI应用的需求 (来源: Reddit r/artificial)
粉笔科技发布垂域大模型,定义“AI+教育”新范式: 粉笔科技在腾讯云AI产业应用峰会上展示了其在职业教育领域的自研垂域大模型。该模型已应用于面试点评、AI刷题系统班等产品,覆盖“教、学、练、评、测”全链条。通过AI老师等形式,旨在实现从“千人一面”到“千人千面”的个性化教学,并计划推出搭载自研大模型的AI硬件产品,推动教育智能化变革 (来源: 量子位)

北森酷学院发布新一代AI Learning平台,引入五大AI Agent: 北森控股在收购酷学院后,推出了基于AI大模型的新一代学习平台AI Learning。该平台在原有eLearning基础上增加了AI做课助手、AI学习助手、AI陪练、AI领导力教练和AI考试助手五个智能体,旨在通过Agent实时对话、技能训练、个性化学习和AI一站式做课与考试,颠覆传统企业学习模式 (来源: 量子位)

小马智行Q1财报:Robotaxi服务收入同比暴涨8倍,年底将部署千辆无人车: 小马智行公布2025年第一季度财报,总营收1.02亿元,同比增长12%。其中,核心的Robotaxi服务收入达1230万元,同比大涨200.3%,乘客车费收入更是同比暴涨8倍。公司计划于第二季度开始量产第七代Robotaxi,并于年底前部署1000辆车,力争达到单车盈亏平衡点。小马智行还宣布与腾讯云和Uber达成合作,将分别通过微信和Uber平台拓展国内及中东市场 (来源: 量子位)

OpenAI CPO Kevin Weil:ChatGPT将转型为行动助手,模型成本已是GPT-4的500倍: OpenAI首席产品官Kevin Weil表示,ChatGPT的定位将从回答问题转向为用户执行任务,通过穿插使用工具(如浏览网页、编程、连接内部知识源)成为AI行动助手。他透露,当前模型的成本已是初代GPT-4的500倍,但OpenAI致力于通过硬件提升和算法改进来提高效率、降低API价格。他认为AI Agent将快速发展,从初级工程师水平在一年内成长为架构师水平 (来源: 量子位)

🧰 工具
FlowiseAI:可视化构建AI智能体: FlowiseAI是一个开源项目,允许用户通过可视化界面构建AI智能体和LLM应用。它支持拖拽组件、连接不同的LLM、工具和数据源,简化了AI应用的开发流程。用户可以通过npm安装或Docker部署Flowise,快速搭建和测试自己的AI流程 (来源: GitHub Trending)

Hugging Face JS库发布,简化与Hub API及推理服务的交互: Hugging Face推出了一系列JavaScript库(@huggingface/inference, @huggingface/hub, @huggingface/mcp-client等),旨在方便开发者通过JS/TS与Hugging Face Hub API和推理服务进行交互。这些库支持创建仓库、上传文件、调用10万+模型的推理(包括聊天补全、文生图等)、使用MCP客户端构建智能体等功能,并支持多种推理提供商 (来源: GitHub Trending)

Jan AI本地运行环境更新为Apache 2.0许可证,降低企业使用门槛: Jan AI是一款支持本地运行LLM的开源工具,近日将其许可证从AGPL更改为更宽松的Apache 2.0。此举旨在方便企业和团队在组织内部署和使用Jan,无需担心AGPL带来的合规性问题,可以自由分叉、修改和发布,从而推动Jan在实际生产环境中的大规模采用 (来源: reach_vb, Reddit r/LocalLLaMA)
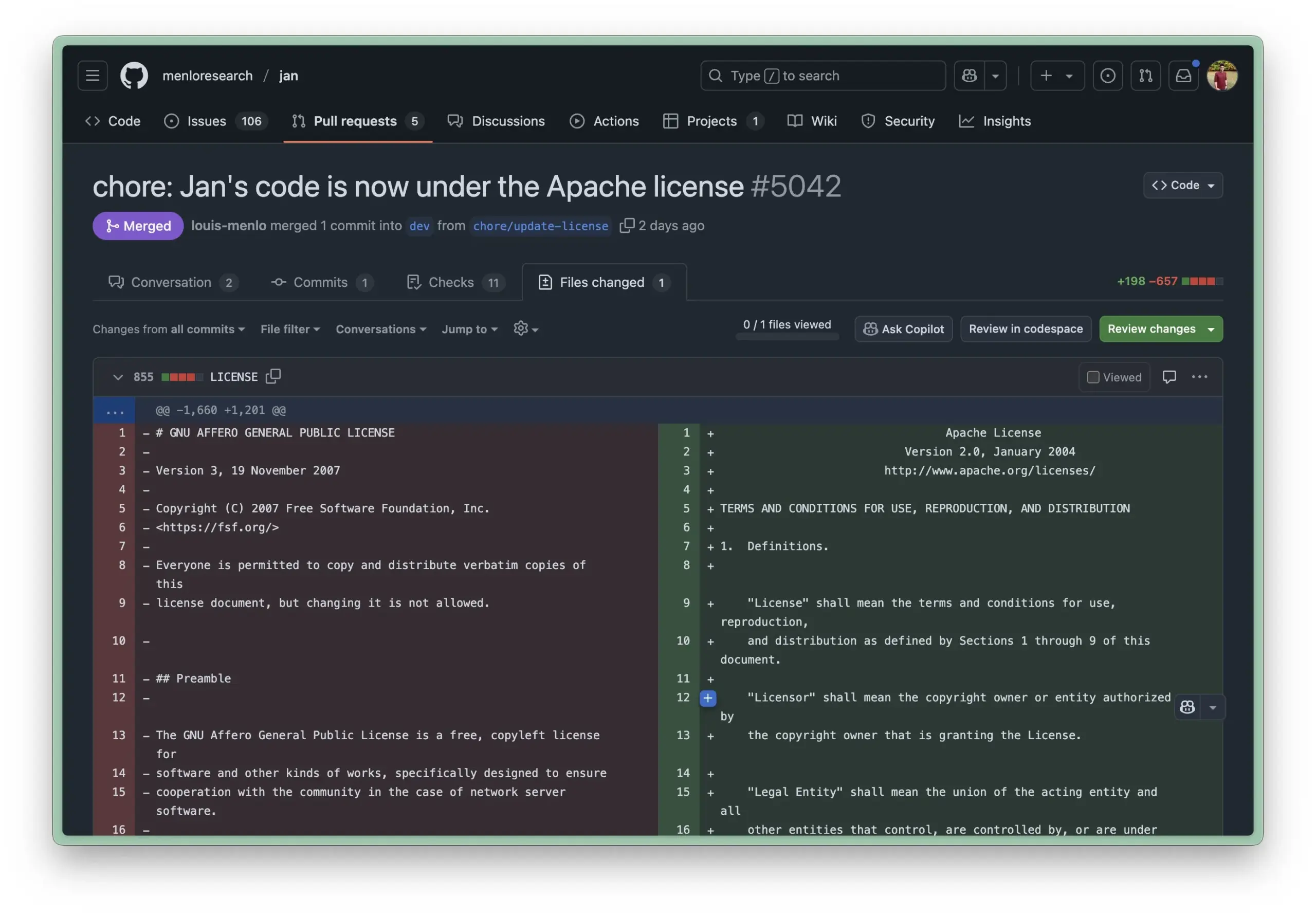
Obsidian推出Bases核心插件,实现笔记数据库化管理: 知识管理软件Obsidian更新了其核心插件Bases,允许用户将笔记集转化为强大的数据库。通过Bases,用户可以创建自定义表格视图,可视化并交互式操作知识库中的数据,支持通过属性筛选笔记,并创建公式派生动态属性,适用于项目管理、旅行计划、阅读清单等多种场景。该功能目前已向早期用户开放 (来源: op7418)
Hugging Face推出Tiny Agents,简化本地模型控制浏览器与文件操作: Hugging Face在其MCP课程中介绍了Tiny Agents,这是一个易于上手的浏览器控制设置框架。用户通过命令行、JSON配置和提示定义,即可让本地运行的LLM(通过OpenAI兼容服务器)控制浏览器(如Playwright)或本地文件系统,无需直接调用API,为llama.cpp等本地模型的智能体应用提供了便利 (来源: Reddit r/LocalLLaMA)

开发者开源AI简历优化应用,基于LangChain与Ollama: 一位开发者构建并开源了一款AI驱动的简历优化应用。用户上传当前简历和目标职位描述后,应用会尝试调整简历中的关键词,使其更符合招聘需求。该项目后端使用LangChain,结合BM25稀疏检索和稠密模型进行混合检索,语言模型通过Ollama在本地运行,前端使用React。项目目前处于概念验证阶段,代码已在GitHub开源 (来源: Reddit r/deeplearning)
Lovable应用构建工具增强图片处理能力: AI应用构建工具Lovable宣布改进了其图片处理功能。用户现在可以向聊天上传图片,并指示Lovable在应用中使用这些图片素材,提升了在AI辅助下构建包含视觉元素应用的用户体验 (来源: op7418)
Helios:首个尝试用AI加速政府工作的平台: Joe Scheidler推出了Helios,一个旨在利用AI提升政府工作效率的平台,被形容为“政府版的Cursor”。该平台是首批明确针对政府部门,试图通过AI技术优化其工作流程和效率的尝试之一,具体功能和应用场景有待进一步观察 (来源: timsoret)
📚 学习
浙江大学发布《大模型基础》教材,系统讲解LLM知识并持续更新: 浙江大学LLM团队开源了《大模型基础》教材,旨在为对大语言模型感兴趣的读者提供系统性的基础知识和前沿技术介绍。该书内容包括传统语言模型、LLM架构演化、Prompt工程、参数高效微调、模型编辑、检索增强生成等,并将进行月度更新。每章配备相关Paper List以追踪最新进展。完整PDF及分章节内容已在GitHub发布 (来源: GitHub Trending)

Hugging Face提供10门免费AI课程,覆盖各层次多领域知识: Hugging Face汇总了其平台提供的10门免费AI课程,内容涵盖从入门到高级的各类热门AI主题,包括自然语言处理、深度学习、强化学习、音频处理、多模态等。这些课程为不同水平的学习者提供了系统学习AI知识的宝贵资源,进一步推动了AI知识的普及和开源社区的发展 (来源: huggingface, reach_vb, _akhaliq)

斯坦福大学分享Marin 8B模型训练经验与教训: 斯坦福大学Percy Liang团队公开了他们从零开始训练Marin 8B模型(并在多项基准上超越Llama 3.1 8B基础模型)的详细回顾。这份诚实的记录包含了团队在研发过程中的所有发现和犯过的错误,为社区提供了宝贵的LLM真实构建经验,强调了科研过程中试错和迭代的重要性 (来源: stanfordnlp, YejinChoinka, hrishioa)
DeepLearning.AI与Predibase合作推出强化细调(RFT)LLM课程: Andrew Ng的DeepLearning.AI与Predibase合作,推出了一门关于使用GRPO(Group Relative Policy Optimization)进行强化细调(RFT)以提升LLM性能的免费短期课程。课程由Predibase联合创始人兼CTO Travis Addair等人主讲,旨在帮助学习者掌握如何利用强化学习,仅用少量标注数据即可将小型开源LLM转化为针对特定用例的推理引擎 (来源: DeepLearningAI)
Hugging Face论文页面新增AI生成摘要功能: Hugging Face在其论文展示页面引入了新功能,为每篇论文提供由AI生成的单句摘要。该摘要旨在简洁明了地概括论文核心内容,帮助用户快速筛选和理解研究文献,提升了学术资源的可访问性和使用效率。此功能由开源LLM驱动,体现了“AI赋能AI研究”的理念 (来源: _akhaliq, _akhaliq, _akhaliq, _akhaliq, huggingface)

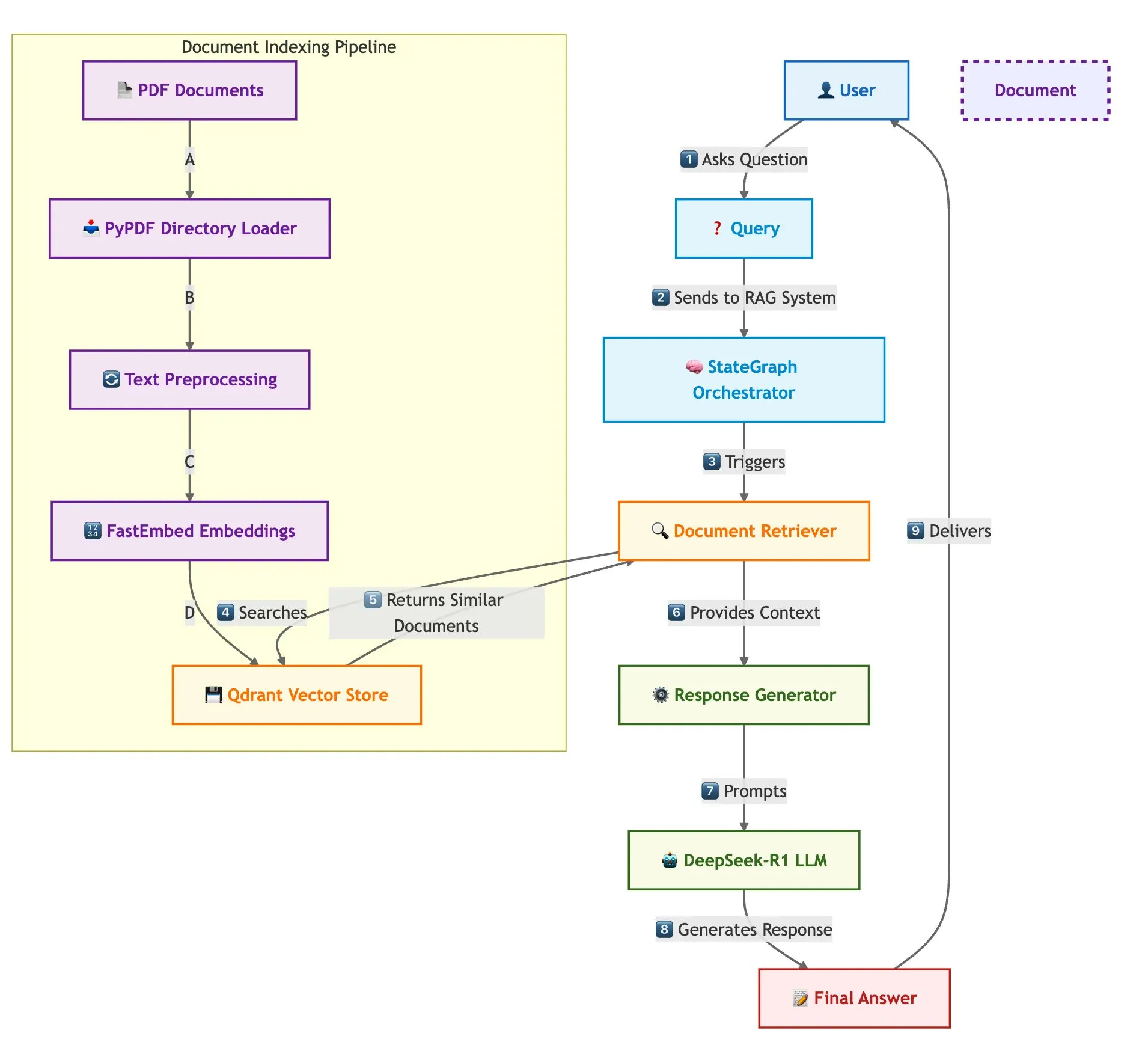
Qdrant、SambaNova等联合展示快速多文档RAG系统构建方案: 一篇技术博客介绍了如何使用Qdrant向量数据库、SambaNova、DeepSeek-R1和LangGraph构建高速、内存高效的多文档检索增强生成(RAG)系统。该方案通过二元量化实现32倍内存节省,利用DeepSeek-R1进行快速、集中的LLM响应,并借助LangGraph进行模块化编排,适用于大规模多文档处理场景 (来源: qdrant_engine)
LangChain Interrupt 2025峰会回顾(普通话版)发布: LangChain Interrupt 2025峰会的普通话版回顾已发布。此次峰会吸引了全球800多人参与,分享了关于AI智能体构建的经验和未来展望,并宣布了LangGraph Platform、LangGraph Studio v2等多款产品,探讨了智能体工程、AI可观测性等主题 (来源: hwchase17)
Andi Marafioti发布nanoVLM教程,逐步详解纯PyTorch训练视觉语言模型: Andi Marafioti发布了一篇新的博客教程,名为nanoVLM,详细介绍了如何使用纯PyTorch从头开始训练自己的视觉语言模型(VLM)。教程内容易于理解和上手,旨在帮助初学者快速掌握VLM的训练过程 (来源: LoubnaBenAllal1)

Ferenc Huszár解读连续时间马尔可夫链及其在扩散语言模型中的应用: 深度学习研究者Ferenc Huszár发表博文,深入浅出地解释了连续时间马尔可夫链(CTMCs)背后的直觉,这是诸如Mercury和Gemini Diffusion等扩散语言模型(DLMs)的关键组成部分。文章探讨了马尔可夫链的不同视角及其与点过程的联系,为理解DLM的理论基础提供了有价值的参考 (来源: fhuszar)
💼 商业
“人工AI”公司Builder.ai宣告破产,曾融资近5亿美元: 曾宣称用AI颠覆软件开发、估值一度达10亿美元的英国公司Builder.ai(原Engineer.ai)本周宣布破产清算。该公司曾被曝其AI平台大量功能实为印度工程师手动完成。尽管获得了微软、软银DeepCore等知名机构近5亿美元融资,但因技术真实性存疑、财务管理混乱及创始人法律纠纷等问题,最终资金耗尽,并拖欠微软3000万美元、亚马逊8500万美元云服务费 (来源: 36氪)

LMArena.ai (原LMSys) 获1亿美元种子轮融资,从Gradio应用走向商业化: 最初作为一个基于Gradio的学术项目LMSys(用于LLM竞技和评估)的LMArena.ai宣布获得1亿美元种子轮融资,由a16z和加州大学投资公司领投。此轮融资将支持LMArena继续其在可靠AI方面的研究和平台运营,标志着一个成功的开源学术项目向商业化运作的转变。这也凸显了Gradio等快速原型工具在孵化有影响力AI项目方面的潜力 (来源: ClementDelangue, _akhaliq, clefourrier)
AI人才争夺战白热化,OpenAI、谷歌等千万年薪抢人: 硅谷AI领域的人才争夺已进入白热化阶段,顶尖研究人员(IC)成为OpenAI、谷歌、xAI等巨头争抢的核心资源,年薪加股权激励普遍超过千万美元。例如,OpenAI为挽留有意加入SSI的资深研究员开出200万美元奖金及超2000万美元股权;谷歌DeepMind也为顶级人才提供年薪2000万美元的待遇。这种激烈竞争源于少数核心人才对大型语言模型发展的巨大贡献,他们的去留可能直接影响AI模型的成败 (来源: 36氪)
🌟 社区
Sora中文能力似乎有所提升,但模型局限性仍存: 社交媒体用户观察到OpenAI的视频生成模型Sora在处理中文文本方面似乎有进步,能够生成包含中文字符的场景。然而,用户也指出模型仍有其局限性,生成的内容并非完美,接受这种不完美可能是当前阶段与AI模型互动的一种常态 (来源: dotey)

Gemini推出深度报告“考试”功能,助力知识复用与学习闭环: 谷歌Gemini上线了一项新功能,用户在阅读深度报告后,Gemini能直接出题进行测试。该功能旨在检验用户对内容的真实理解程度,并构建“学→考→补→再学”的AI原生学习闭环,强调AI时代学习的核心在于知识的复用能力而非阅读量 (来源: dotey)
ChatGPT记忆功能引发用户对控制权的担忧: ChatGPT新上线的“从聊天中学习记忆”功能,允许模型记住用户过去的对话信息以便在后续交互中提供更个性化的回应。然而,一些高级用户对此表示担忧,认为这改变了与模型互动的方式,他们更倾向于完全控制模型的输入内容,不希望模型在他们不知情或无法精确控制的情况下使用历史信息 (来源: random_walker)
AI Agent发展迅速,未来工作模式或将改变: 社区热议AI Agent的快速发展及其对未来工作模式的潜在影响。观点认为,AI Agent正从简单的问答工具向能够独立完成复杂任务(如编码、研究、客户支持)的“虚拟员工”转变。OpenAI CPO Kevin Weil预计AI Agent的能力将迅速提升,从初级工程师水平在一年内成长为架构师水平。微软也提出了“智能体网络”的构想,预示着未来工作可能围绕管理和编排AI智能体展开 (来源: rowancheung, 量子位)
AI在医疗诊断领域潜力巨大,但引发医生职业忧虑: AI在医疗诊断方面展现出惊人能力,例如有研究称o1-preview模型在医疗推理和诊断任务上表现出超人能力,AI几秒钟内检测肺炎的案例也引发关注。这使得AI辅助诊断成为热门话题,但也让部分从业20年的医生担忧其职业前景,甚至开玩笑称要去麦当劳工作。社区讨论认为AI更应被视为辅助医生提高效率和准确性的工具,而非完全替代 (来源: paul_cal, Reddit r/ArtificialInteligence)
新闻出版商指责谷歌AI搜索模式为“盗窃”: 新闻媒体联盟等出版商对谷歌新的AI搜索模式表示强烈不满,称其为“盗窃”。他们认为谷歌AI直接从新闻内容中提取信息并整合到搜索结果中,绕过了新闻网站,损害了出版商的流量和广告收入,引发了关于AI时代内容版权和合理使用的激烈讨论 (来源: Reddit r/artificial)
DeepSeek模型在中国被用于传统占卜,引发AI应用边界讨论: 有用户发现,DeepSeek模型在中国的大量流量来自于用户将其用于易经占卜等传统算命活动。这一现象引发了关于AI应用边界和文化适应性的讨论,也间接反映了用户对AI能力的多样化探索和需求 (来源: menhguin, cto_junior)

💡 其他
Figure公司人形机器人在宝马生产线完成20小时连续轮班: 人形机器人公司Figure宣布,其机器人在宝马X3生产线上成功完成了20小时的连续轮班工作。此前,该机器人已进行了数周的10小时轮班测试。Figure称,这是全球首次由人形机器人在汽车产线完成如此长时间的连续作业,展示了其在工业自动化领域的潜力 (来源: adcock_brett, TheRundownAI)
Agentic AI 与 GenAI 的区别与联系: 社区讨论了Agentic AI(智能体AI)与Generative AI(生成式AI)的概念。生成式AI主要指能创造新内容(文本、图像、代码等)的AI,而智能体AI则更强调自主性、目标导向和与环境交互行动的能力。智能体AI通常会利用生成式AI作为其核心能力之一,去理解、规划并执行任务,是AI向更高级自主智能发展的重要方向 (来源: Ronald_vanLoon, Ronald_vanLoon)

AI在科学研究中的应用被低估,存在“粉饰结果”现象: 社区讨论指出,AI在科学研究中的应用潜力巨大但可能被低估,同时存在研究者为了发表而“粉饰”AI实验结果的现象。例如,在偏微分方程(PDEs)等领域,AI的实际表现可能不如论文中所呈现的那样出色。这提示科研社区需要更严谨和透明地评估AI在科学发现中的真实作用和局限性 (来源: clefourrier)