
关键词:AI智能体, 大型语言模型, Gemini 2.5 Pro, 英伟达AI超算, 微软Build大会, 科研智能体, 推理能力评估, AI编程, Coding Agent自主修复bug, Microsoft Discovery科研平台, NVLink Fusion技术, CloudMatrix 384超节点, EdgeInfinite算法
🔥 聚焦
AI智能体重新定义开发与科研范式: 微软Build大会发布系列AI智能体工具,包括自主修复bug、维护代码的Coding Agent,以及能生成想法、模拟结果并自主学习的科研智能体平台Microsoft Discovery。同时,OpenAI首席产品官Kevin Weil及Anthropic CEO Dario Amodei均表示AI已具备高级编程能力,预示初级程序员岗位或被取代,开发者角色将向“AI引导者”转变。这些进展标志着AI智能体正从辅助工具进化为能在复杂项目中独立运作的核心力量,将深刻变革软件开发和科学研究的流程与效率 (来源: GitHub Trending, X)
大型语言模型推理能力面临新挑战与评估: 近期多项研究和讨论揭示了大型语言模型在复杂推理任务中的局限性。哈佛大学等机构的研究指出,思维链(CoT)有时可能导致模型在遵循指令方面准确率下降,因其过度关注内容规划而忽略简单约束。同时,现实世界物理任务(如零件加工)和复杂的视觉空间推理(如立方体堆叠问题)也暴露出顶级AI模型(包括o3、Gemini 2.5 Pro)的不足。为更准确评估模型能力,EMMA、SPOT等新基准被提出,旨在检测AI在多模态融合、科学验证等方面的真实水平,推动模型向更鲁棒和可靠的推理进化 (来源: HuggingFace Daily Papers, 量子位)
谷歌AI全方位发力,Gemini 2.5 Pro表现强劲: 谷歌在AI领域展现全面攻势,其Gemini 2.5 Pro模型在多个基准测试(如LMSYS Chatbot Arena)中表现出色,特别是在长上下文和视频理解方面达到顶尖水平,并在WebDev Arena超越前代版本。Google Cloud Next ‘25大会上,谷歌发布了包括Gemini 2.5 Flash、Imagen 3、Veo 2、Vertex AI Agent Development Kit(ADK)及Agent2Agent(A2A)协议在内的200余项更新,彰显其将AI融入云平台各个层级并推动企业规模化部署的决心。Google Labs也在持续孵化AI原生创新产品,如NotebookLM等,显示出强大的产品创新与迭代能力 (来源: Google, GoogleDeepMind)
英伟达发布桌面级AI超算及企业级AI工厂方案: 英伟达在Computex大会上发布多款重磅新品,包括搭载GB300超级芯片的个人AI计算机DGX Station,拥有高达784GB统一内存,支持运行1T参数大模型;以及面向企业的RTX PRO Server,可加速AI智能体、物理AI、科学计算等多种应用。同时,英伟达推出半定制化NVLink Fusion技术和NVIDIA AI数据平台,并宣布与迪士尼等合作开发物理AI引擎Newton。这些举措表明英伟达正从芯片公司向AI基础设施公司转型,旨在构建从桌面到数据中心的完整AI生态 (来源: nvidia, 量子位)

🎯 动向
Kimi.ai发布长文本思考模型kimi-thinking-preview: Kimi.ai推出了其最新的长文本思考模型kimi-thinking-preview,现已在platform.moonshot.ai上线。该模型据称拥有出色的多模态和推理能力,新用户注册可获得5美元代金券试用。社区评论建议由第三方对该模型进行评估,并提及Kimi此前已通过专用思考模型在livecodebench上取得领先 (来源: X)
Red Hat推出llm-d:基于Kubernetes的分布式推理框架: 为解决LLM推理速度慢、成本高和扩展难的问题,Red Hat推出了llm-d,一个Kubernetes原生的分布式推理框架。该框架利用vLLM、智能调度和解耦计算来优化LLM推理。llm-d构建于vLLM(高性能LLM推理引擎)、Kubernetes(容器编排标准)和Inference Gateway (IGW)(通过Gateway API扩展实现智能路由)三大开源基础之上,旨在提升LLM推理的效率和可扩展性 (来源: X, X)
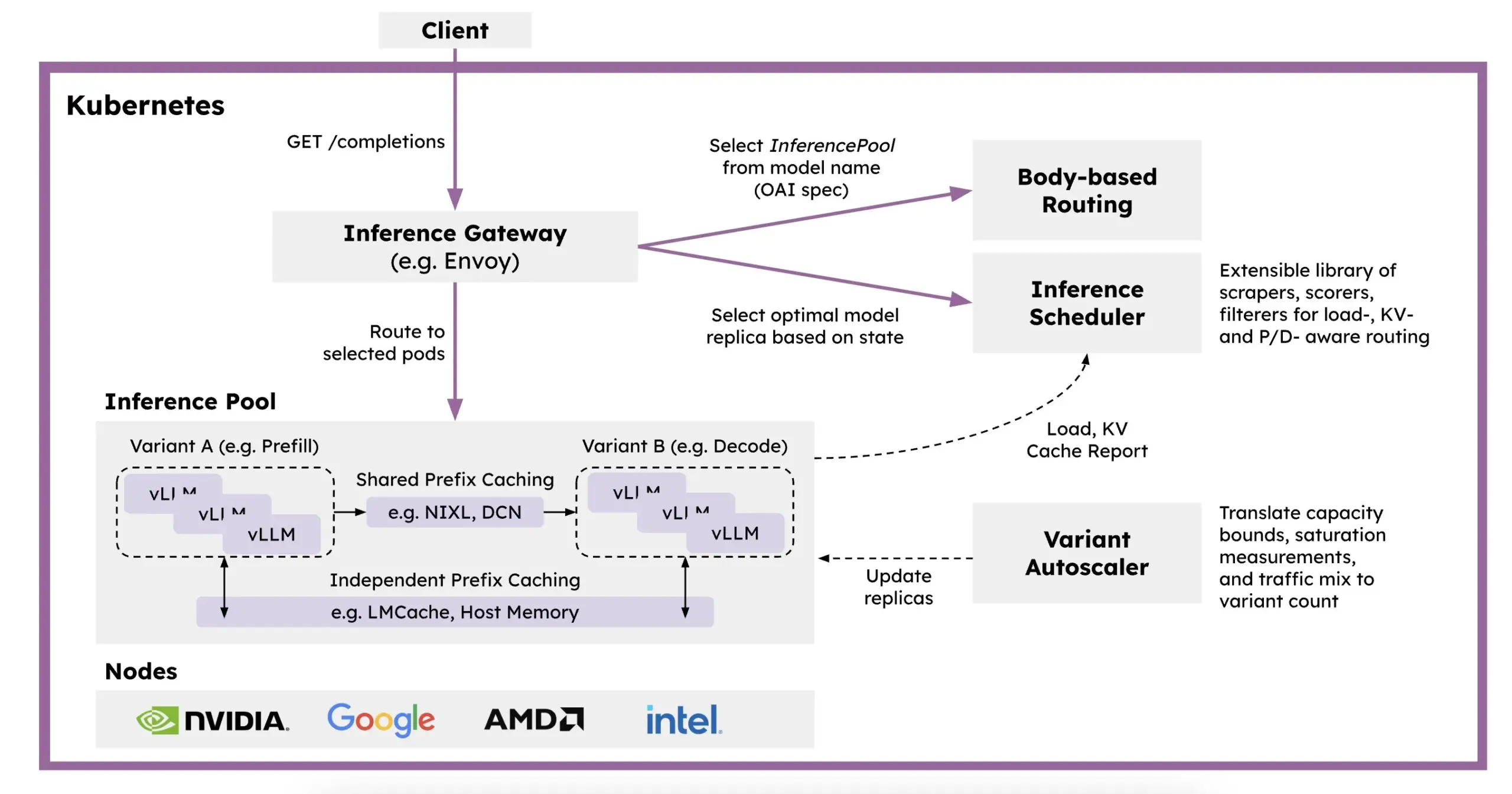
Meta AI发布OMol25数据集,包含超1亿分子构象体: Meta AI在HuggingFace上发布了OMol25数据集,包含超过1亿个分子构象体,涵盖83种元素和多样化的化学环境。该数据集旨在训练能够达到DFT(密度泛函理论)级别精度,同时大幅降低计算成本的机器学习模型。这将有助于加速药物发现、先进材料设计和清洁能源解决方案等领域的研究与应用 (来源: X)
Gemini 2.5 Pro在NotebookLM德国区iOS应用商店上线: 谷歌的NotebookLM应用(集成Gemini 2.5 Pro)已在德国地区的iOS App Store上架,此前在欧盟区iOS版本仅通过TestFlight提供。同时,Android版本似乎已更广泛可用。NotebookLM旨在帮助用户理解和处理长文档、笔记等内容 (来源: X)
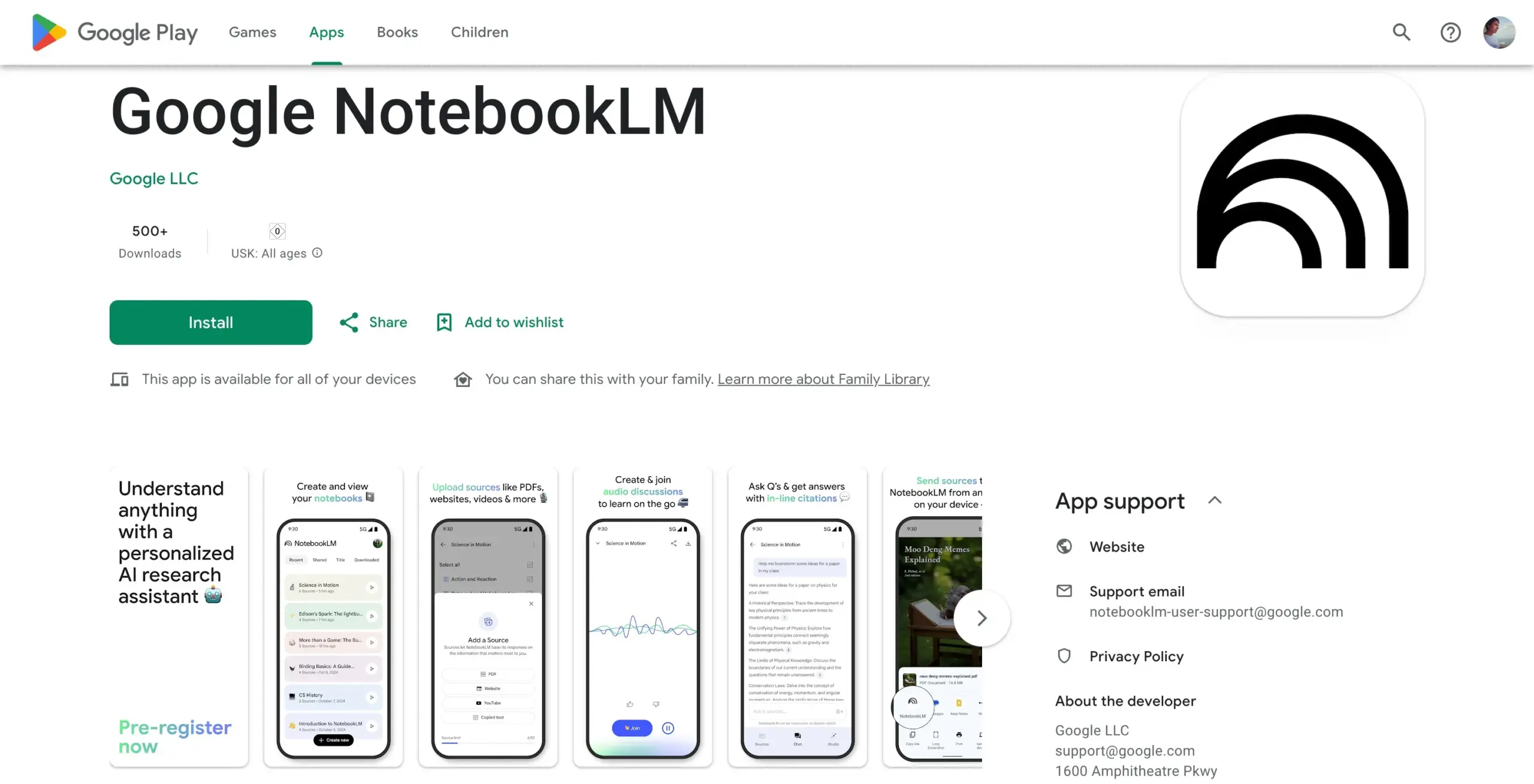
字节跳动AI研究活跃,近期发布多篇论文: 字节跳动旗下SEED团队在过去两个月内已发表至少13篇AI相关研究论文,涉及领域包括模型合并、强化学习触发的自适应思维链(AdaCoT)、通过潜在表征优化推理(LatentSeek)等。这些研究展示了字节跳动在提升大型语言模型效率、推理能力和训练方法上的持续投入和探索 (来源: X, X)
AI驱动下一代锌电池实现99.8%效率和4300小时运行时间: 通过人工智能优化,新一代锌电池实现了99.8%的库伦效率和长达4300小时的运行时间。这项技术突破展示了AI在材料科学和能源存储领域的应用潜力,有望推动更高效、更持久的电池技术发展,对于可再生能源存储和便携式电子设备具有重要意义 (来源: X)

Perplexity推出AI智能浏览器Comet进行早期测试: Perplexity已开始向早期测试者推出其具有智能体功能的网页浏览器Comet。这款浏览器预计将提供一种全新的“氛围浏览”(vibe browsing)体验,可能结合了Perplexity强大的AI搜索和信息整合能力,为用户带来更智能、更个性化的网络浏览方式 (来源: X)
英特尔发布高性价比Arc Pro B系列显卡,主打大显存: 英特尔推出Arc Pro B50(16GB显存,299美元)和专为AI工作站设计的Arc Pro B60(24GB显存,单卡500美元)显卡。B60在AI推理测试中表现优于英伟达RTX A1000,且更大显存使其在运行大模型时更具优势。Project Battlematrix工作站采用至强处理器,最多可配8个B60 GPU(192GB总显存),支持700亿+参数模型。此举被视为英特尔在AI硬件市场寻求性价比突破的策略 (来源: 量子位)

华为云推出CloudMatrix 384超节点,提升AI算力: 华为云发布CloudMatrix 384超节点,采用全对等互联架构,可将384张AI加速卡互联形成超级云服务器,提供高达300Pflops算力,旨在解决AI训练和推理中的通信效率、内存墙和可靠性挑战。该架构特别强调对MoE模型的亲和性、以网强算、以存强算等特性,已应用于支持DeepSeek-R1等大模型的推理服务 (来源: 量子位)

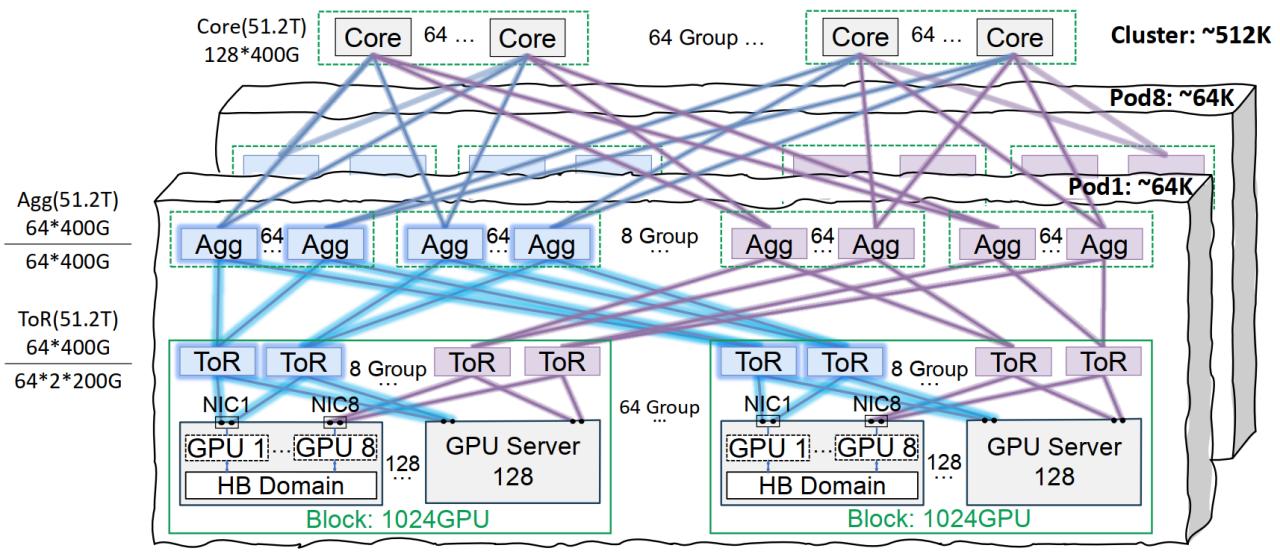
腾讯云星脉网络基础设施优化大模型训练: 腾讯云推出星脉高性能网络基础设施方案,专为大规模AI模型训练和推理设计。该方案通过同轨互联架构(支持单Pod 6.4万GPU、全集群51.2万GPU组网)、优化的电源管理与冷却方案以及智能监控系统,解决传统数据中心在网络、部署密度和故障定位方面的痛点。星脉已支持腾讯混元等自研业务,并为DeepSeek的DeepEP通信框架提供了性能优化 (来源: 量子位)
Stability AI发布SV4D2.0模型,或预示其在视频生成领域回归: Stability AI在Hugging Face上发布了名为sv4d2.0的模型,引发社区关注。虽然具体细节不多,但此举可能意味着Stability AI在视频生成或相关3D/4D领域有新的技术进展或产品迭代,暗示其在经历调整后可能重回AI生成领域前沿 (来源: X)
Meta AI发布Adjoint Sampling学习算法: Meta AI提出了一种新的学习算法Adjoint Sampling,用于训练基于标量奖励的生成模型。该算法基于FAIR开发的理论基础,具有高度可扩展性,有望成为未来可扩展采样方法研究的基础。相关研究论文、模型、代码和基准已发布 (来源: X)
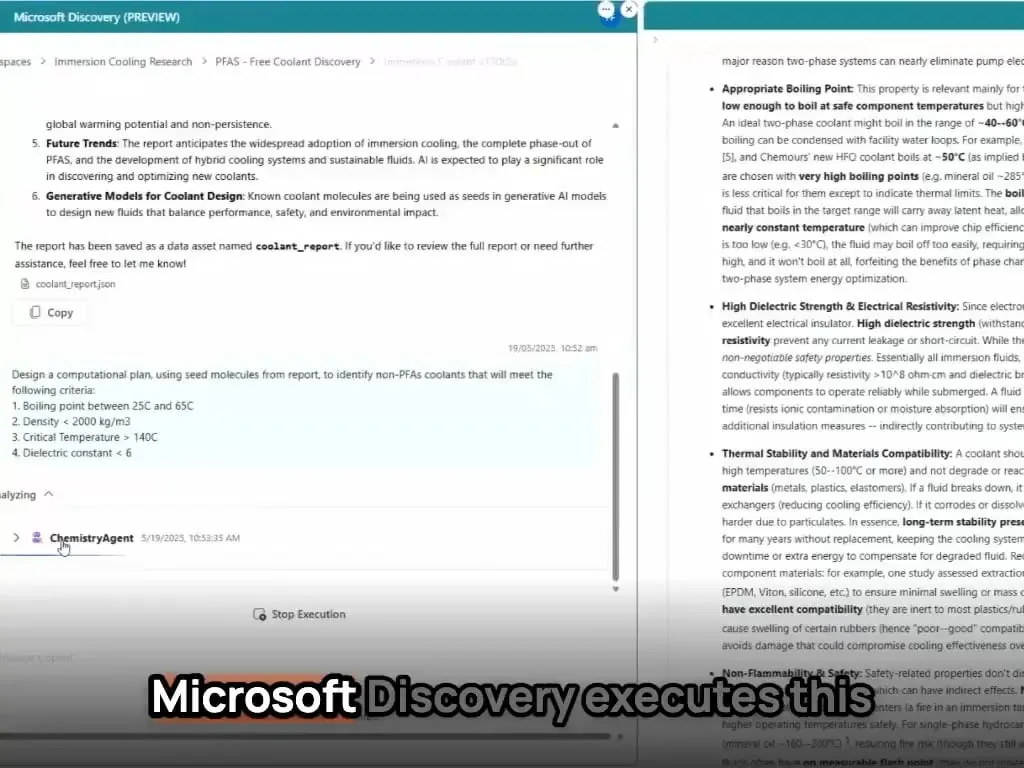
微软AI智能体在数小时内完成新材料发现与合成: 微软展示了其AI智能体在科学研发中的强大能力。这些智能体能够扫描科学文献、制定计划、编写代码、运行模拟,并在数小时内完成通常需要数年研发的新型数据中心冷却剂的发现。更进一步,团队成功合成了AI设计的新型冷却剂,并在实际主板上进行了演示,显示了AI在加速材料科学等领域自主发现和创造的巨大潜力 (来源: Reddit r/artificial)
智源研究院发布三款BGE系列向量模型,专注代码与多模态检索: 智源研究院联合高校推出了BGE-Code-v1(代码向量模型)、BGE-VL-v1.5(通用多模态向量模型)和BGE-VL-Screenshot(视觉化文档向量模型)。这些模型在CoIR、Code-RAG、MMEB、MVRB等基准测试中表现优异,BGE-Code-v1基于Qwen2.5-Coder-1.5B,BGE-VL-v1.5基于LLaVA-1.6,BGE-VL-Screenshot基于Qwen2.5-VL-3B-Instruct,旨在提升代码检索、图文理解和复杂视觉文档检索的性能,已全面开源 (来源: WeChat)
华为OmniPlacement技术优化MoE模型推理,DeepSeek-V3延迟理论降低10%: 针对混合专家(MoE)模型中专家网络负载不均衡(“热专家”与“冷专家”)导致推理性能受限的问题,华为团队提出OmniPlacement技术。该技术通过专家重排、层间冗余部署和近实时动态调度,在DeepSeek-V3等模型上理论可降低约10%的推理延迟并提升约10%的吞吐量。该方案近期将全面开源 (来源: WeChat)

vivo发布EdgeInfinite算法,实现手机端128K长文本高效处理: vivo AI研究院在ACL 2025发表研究,推出EdgeInfinite算法,专为端侧设备设计,通过可训练的门控记忆模块和记忆压缩/解压缩技术,在Transformer架构中高效处理超长文本。该算法在BlueLM-3B模型上测试,能在10GB GPU内存设备上处理128K tokens,并在LongBench多项任务上表现优异,显著降低首词出词时间与内存占用 (来源: WeChat)

🧰 工具
LlamaParse更新,增强文档解析能力: LlamaParse发布了多项更新,提升了其作为AI智能体驱动的文档解析工具的性能。新功能包括支持Gemini 2.5 Pro、GPT-4.1,增加了偏斜检测和置信度分数。此外,还引入了代码片段按钮,方便用户将解析配置直接复制到代码库中,并增加了用例预设和在渲染/原始Markdown间切换导出的功能 (来源: X)
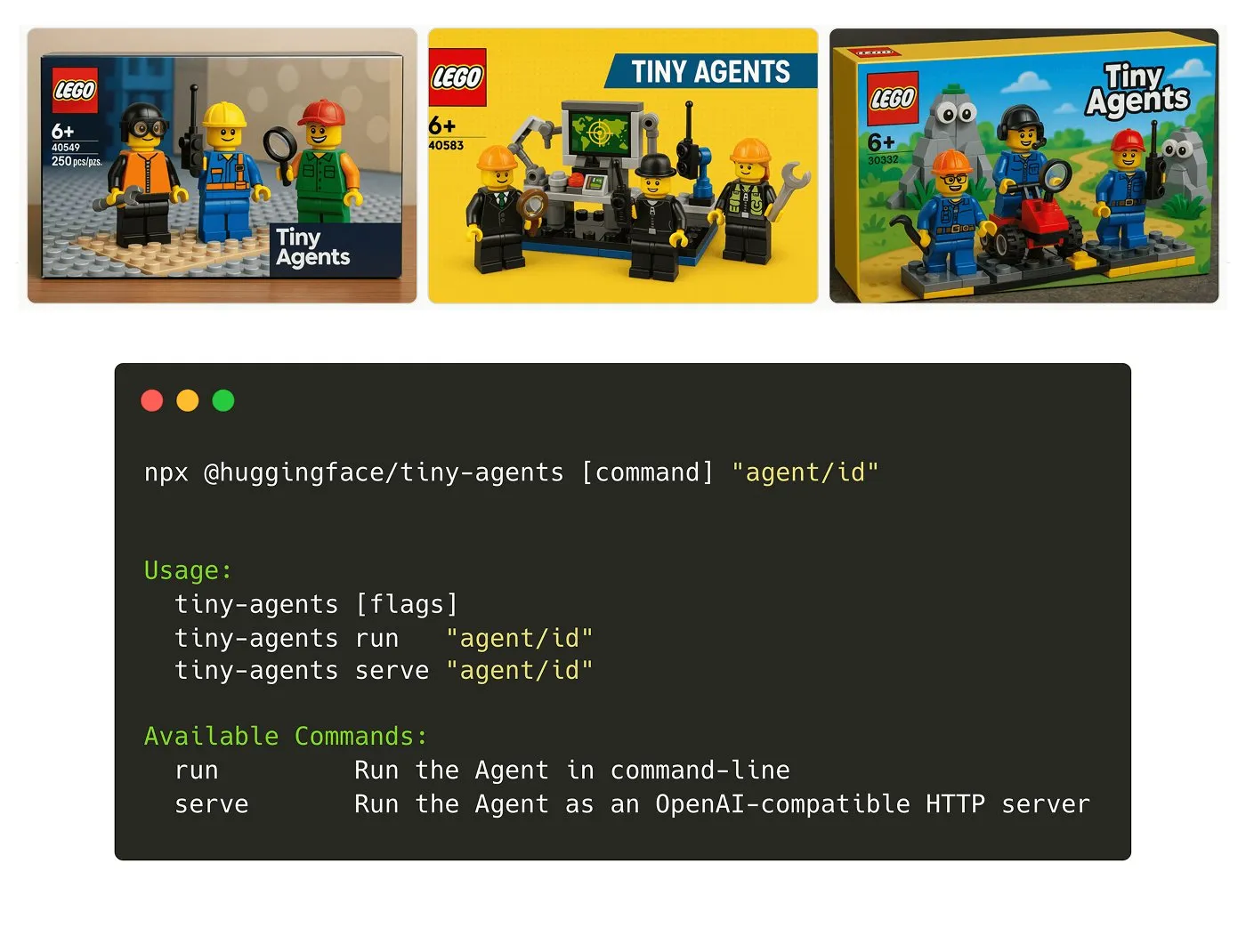
Hugging Face推出Tiny Agents NPM包: Julien Chaumond发布了Tiny Agents,一个轻量级、可组合的智能体NPM包。它基于Hugging Face的Inference Client和MCP(Model Component Protocol)堆栈构建,旨在方便开发者快速上手和构建小型智能体应用。官方提供了入门教程 (来源: X)
LangGraph平台新增MCP支持,简化智能体集成: LangGraph平台现在支持MCP(Model Component Protocol),每个部署在平台上的智能体都会自动暴露一个MCP端点。这意味着用户可以利用这些智能体作为工具,在任何支持MCP可流式HTTP的客户端中使用,无需编写自定义代码或配置额外基础设施,简化了智能体之间的集成和互操作 (来源: X)

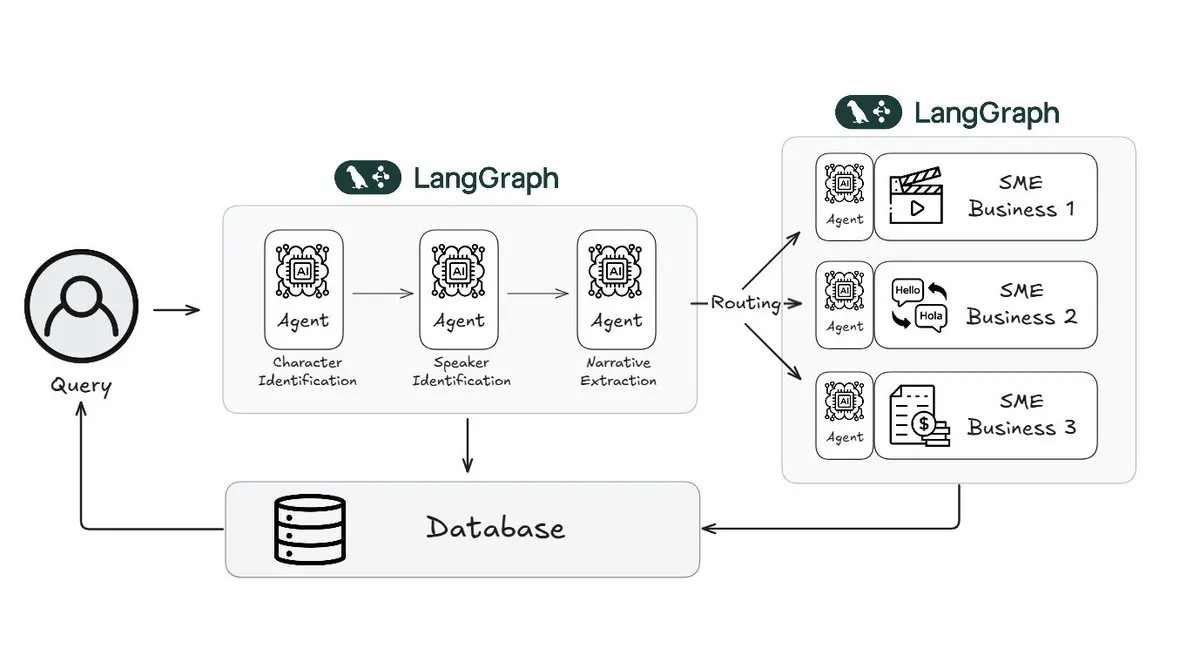
Webtoon利用LangGraph将故事审查工作量减少70%: 数字漫画领导者Webtoon构建了Webtoon Comprehension AI (WCAI),使用LangGraph自动化处理其海量内容库的叙事理解。WCAI通过智能多模态智能体取代了人工浏览,能够进行角色和发言人识别、情节和基调提取以及自然语言洞察查询,使其营销、翻译和推荐团队的工作量减少了70%,并提升了创作力 (来源: X)
OpenMemory MCP实现AI工具间持久私有记忆共享: Mem0项目推出了OpenMemory MCP服务器,旨在为AI应用提供跨平台、跨会话的持久化私有记忆。用户可在本地部署,通过MCP协议将OpenMemory连接到Cursor等客户端工具,实现记忆的添加、搜索、列出和删除。该工具通过仪表盘提供记忆管理功能,有望增强AI智能体的个性化和上下文理解能力 (来源: WeChat)

妙多AI 2.0发布,定位界面设计AI助手: 妙多AI 2.0作为界面设计领域的AI助手发布,旨在与用户协作完成设计任务。新版本通过AI魔法框增强交互,支持对话式编辑和迭代设计方案,能根据预设风格或用户输入(长文本、草图、参考图)生成多版界面,并兼容主流设计系统。此外,还提供图文处理、设计咨询和快捷指令(自然语言转API调用)等功能。妙多AI支持MCP协议,优化设计稿数据供大模型读取,以生成高还原度前端代码 (来源: 量子位)

llmbasedos:基于MCP的开源可启动AI操作系统概念验证: 开发者iluxu在微软发布“USB-C for AI apps”概念(基于MCP)前三天,开源了llmbasedos项目。该项目是一个可从USB或虚拟机快速启动的AI操作系统,通过FastAPI网关以JSON-RPC与小型Python守护进程通信,允许用户脚本通过简单的cap.json配置被ChatGPT/Claude/VS Code等调用。默认使用离线llama.cpp,也可切换至GPT-4o或Claude 3,旨在推动开放的AI应用连接标准 (来源: Reddit r/LocalLLaMA)
📚 学习
知识蒸馏(KD)为何有效?新研究提供简洁解释: Kyunghyun Cho等人对知识蒸馏(KD)的有效性提出了一种简洁的解释。他们假设,使用来自教师模型的低熵近似采样,会导致学生模型具有更高的精确度但召回率较低。由于自回归语言模型本质上是无限级联的混合分布,他们通过SmolLM验证了这一假设。该研究认为,当前的评估方法可能过于侧重精确度,而忽略了召回率的损失,这关系到大规模通用模型可能遗漏的内容和用户群体 (来源: X)

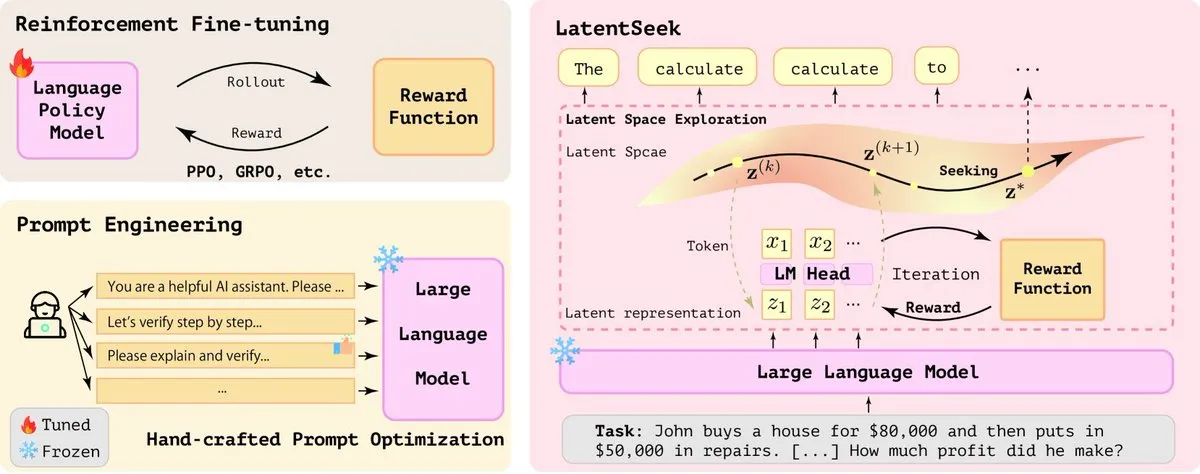
LatentSeek:通过潜在空间策略梯度优化提升LLM推理能力: 一篇名为《Seek in the Dark》的论文提出LatentSeek,一种在测试时通过潜在空间中的实例级策略梯度来增强大型语言模型(LLM)推理能力的新范式。该方法无需训练、数据或奖励模型,旨在通过优化潜在表征来改进模型的推理过程。这种训练无关的方法在提升LLM复杂推理任务性能方面显示出潜力 (来源: X)
微软提出CoML:语言模型的链式模型学习: 微软研究院提出了一种新的学习范式“链式模型学习”(Chain-of-Model Learning, CoML)。该方法将隐藏状态的因果关系以链式结构融入每层网络,旨在提高模型训练的扩展效率和部署时的推理灵活性。其核心概念“链式表征”(CoR)将每层的隐藏状态分解为多个子表征链,后续链可以访问前面所有链的输入表征,从而允许模型通过增加链来渐进扩展,并能通过选择不同数量的链来提供多种规模的子模型进行弹性推理。基于此原理设计的CoLM(链式语言模型)及其变体CoLM-Air(引入KV共享机制)展示了与标准Transformer相当的性能,并带来了渐进扩展和弹性推理的优势 (来源: X, HuggingFace Daily Papers)

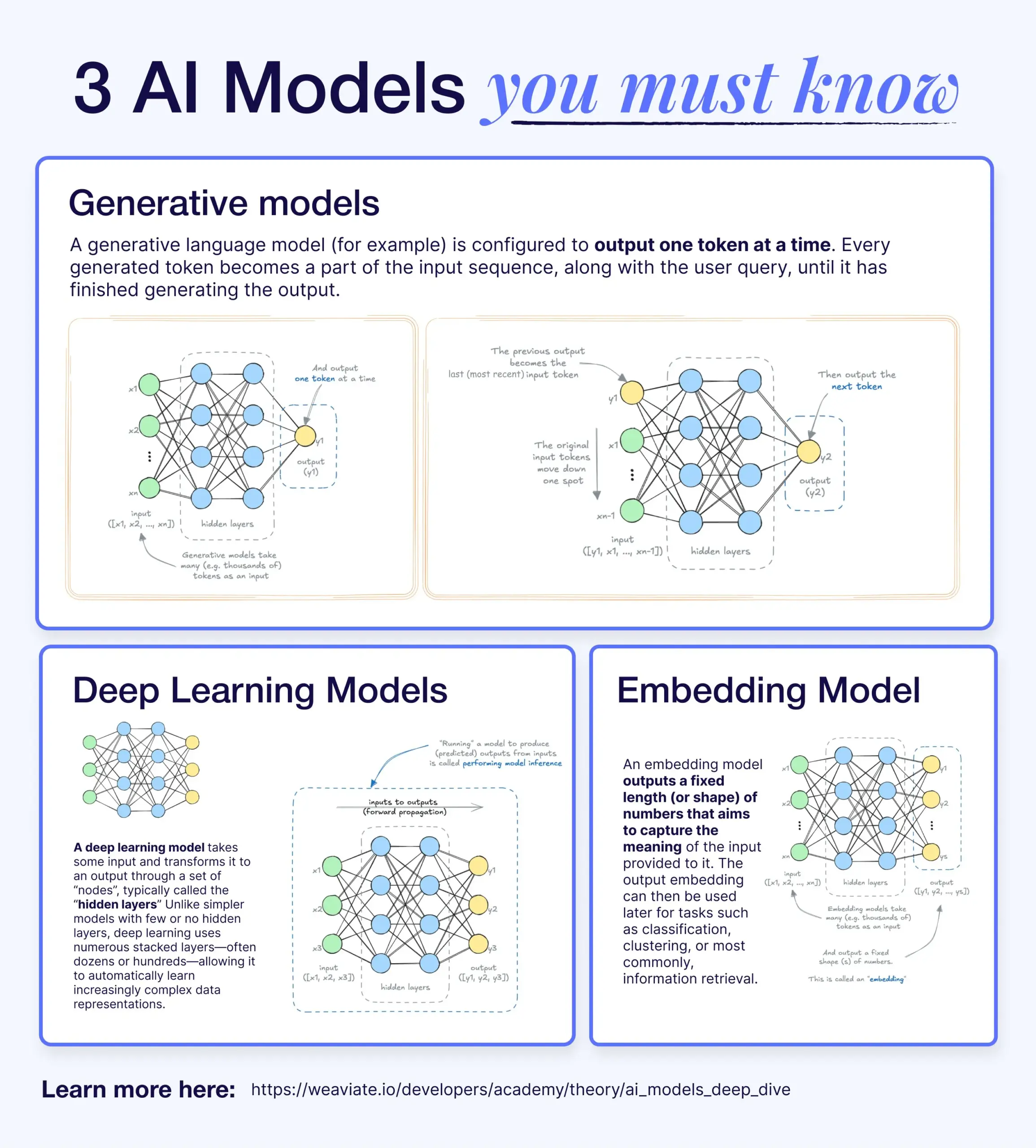
深度学习、生成模型与嵌入模型的区别与联系: 一篇科普文章解释了深度学习模型、生成模型和嵌入模型之间的关系。深度学习模型是基础架构,通过多层神经网络处理数值输入输出。生成模型是深度学习模型的一种,专门用于创建与其训练数据相似的新内容(如GPT、DALL-E)。嵌入模型也是深度学习模型的一种,用于将数据(文本、图像等)转换为捕捉语义信息的数值向量表示,常用于相似性搜索和RAG系统。在许多AI系统中,这些模型协同工作,例如RAG系统利用嵌入模型进行检索,再由生成模型生成回复 (来源: X)
DSPy提出AI系统投入哲学: DSPy分享了其关于AI系统投入的哲学,强调应将精力投入到AI系统的三个基础层:数据、模型和算法。他们认为,通过提供可组合的顶层模块(Prompts, Demonstrations, Optimizers, Metrics, Tools, Agents, Reasoning Modules),开发者可以快速迭代这三个基础层,从而构建更强大的AI系统 (来源: X)
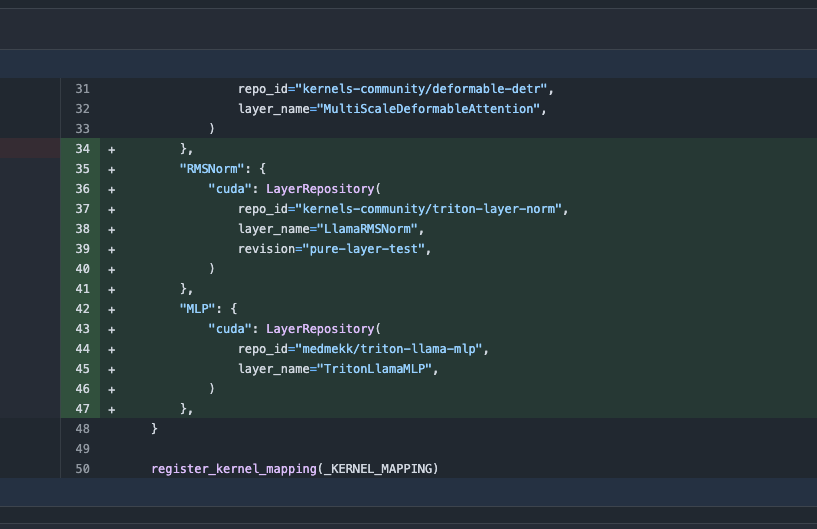
Transformers库更新,自动切换优化内核提升性能: 最新版本的Hugging Face Transformers库实现了在硬件允许时自动切换到优化内核的功能。该更新集成了kernels库,针对Llama等流行模型,利用Hugging Face Hub上最受欢迎的社区内核,旨在提升模型在兼容硬件上的运行效率和性能 (来源: X)
ARC-AGI-2基准发布,挑战前沿AI推理系统: François Chollet等人发布了关于ARC-AGI-2基准的论文,详细介绍了其设计原则、挑战性、人类表现分析以及当前模型的性能。该基准旨在评估AI的抽象推理能力,人类能够解决100%的任务,而当前前沿AI模型的得分低于5%,显示出在高级抽象推理方面AI与人类之间仍存在巨大差距 (来源: X)

陶哲轩发布GitHub Copilot辅助证明函数极限教程: 数学家陶哲轩发布视频教程,演示如何使用GitHub Copilot辅助证明函数极限问题,包括求和、求差、求积定理。他强调,虽然Copilot能快速生成代码框架和提示已有库函数,但在复杂数学细节、特殊情况处理及创造性解决方案上仍需大量人工干预和调整,有时结合纸笔推导再进行形式化验证可能更高效 (来源: 36氪)
PhyT2V框架利用LLM提升文生视频物理一致性: 匹兹堡大学研究团队提出PhyT2V框架,通过大型语言模型引导的链式推理(CoT)和迭代自我修正机制,优化文本提示,以增强现有文本到视频(T2V)模型生成内容的物理真实感。该方法无需模型重训练,通过分析已生成视频与提示的语义不匹配,并结合物理规则进行提示修正,旨在提高T2V模型在处理分布外(OOD)场景时的物理一致性。实验表明,PhyT2V能显著提升CogVideoX、OpenSora等模型在VideoPhy、PhyGenBench等基准上的表现 (来源: WeChat)

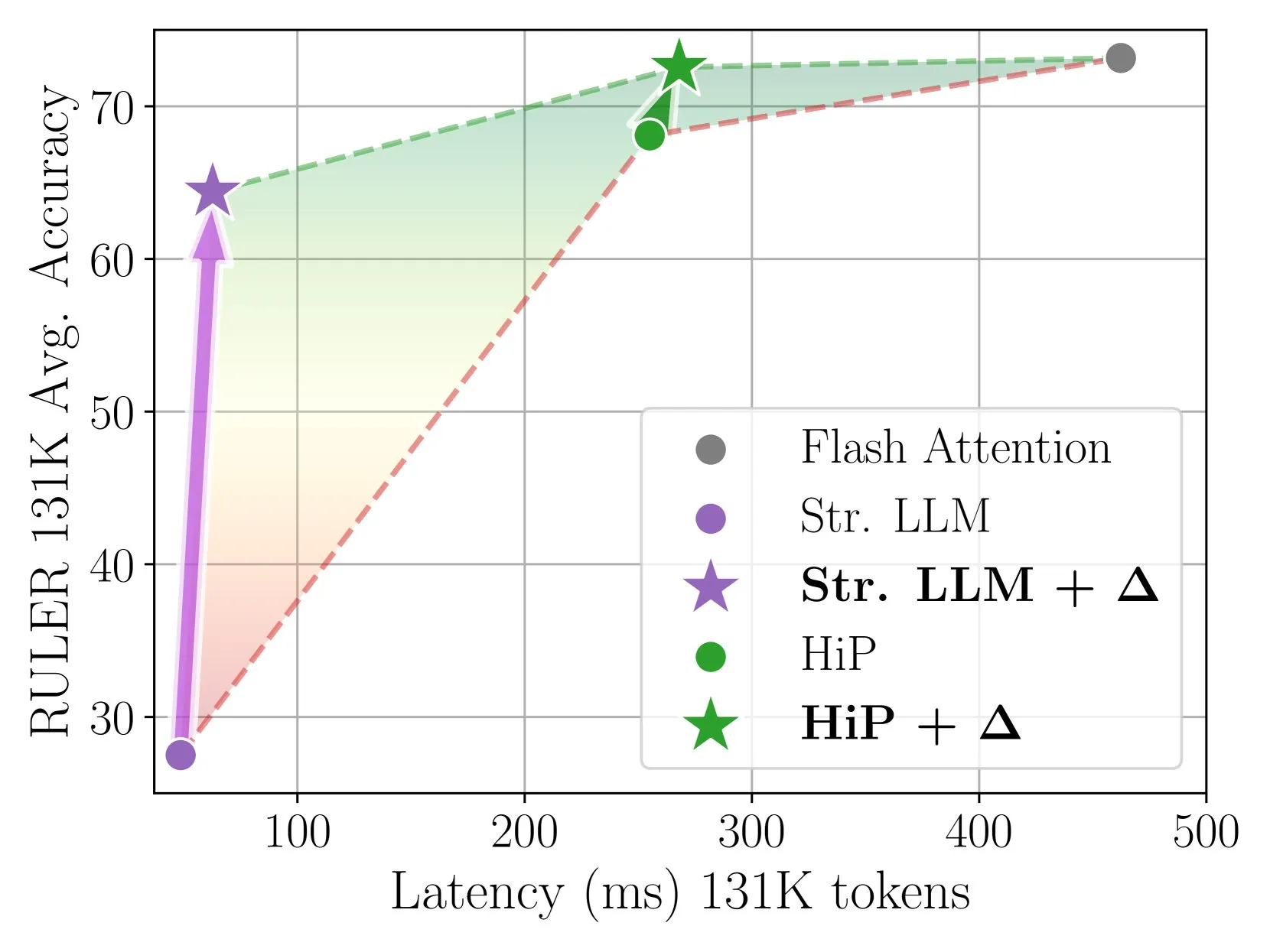
Delta Attention通过增量校正实现快速准确的稀疏注意力推理: 该研究发现稀疏注意力计算会导致注意力输出的分布偏移,从而降低模型性能。Delta Attention通过校正这种分布偏移,使稀疏注意力的输出分布更接近全量注意力,从而在保持高稀疏度(约98.5%)的同时,显著提升性能,恢复了滑窗注意力(带sink token)在RULER基准上88%的全量注意力准确率,且计算开销小。在处理1M token预填充时,比Flash Attention 2快32倍 (来源: HuggingFace Daily Papers)
Thinkless框架使LLM学习何时进行CoT推理: 为解决大型语言模型(LLM)在所有查询中均使用复杂思维链(CoT)推理导致的计算效率低下问题,研究者提出Thinkless框架。该框架通过强化学习训练LLM,使其能根据任务复杂度和自身能力自适应选择短式或长式推理。核心算法DeGRPO将学习目标分解为控制令牌损失(决定推理模式)和响应损失(提高答案准确性),从而稳定训练过程。实验表明,Thinkless能在Minerva Algebra等基准上减少50%-90%的长链思考使用,显著提升推理效率 (来源: HuggingFace Daily Papers)
CPGD算法提升基于规则的语言模型强化学习稳定性: 针对现有基于规则的强化学习方法(如GRPO, REINFORCE++, RLOO)在训练语言模型时可能出现的训练不稳定问题,研究者提出CPGD(带策略漂移的裁剪策略梯度优化)算法。CPGD通过引入基于KL散度的策略漂移约束来动态正则化策略更新,并利用对数比率裁剪机制防止过度策略更新。理论和实证分析表明,CPGD能缓解不稳定性,并在保持训练稳定性的同时显著提高性能 (来源: HuggingFace Daily Papers)
神经符号查询编译器QCompiler提升RAG系统复杂查询处理能力: 为解决检索增强生成(RAG)系统在处理具有嵌套结构和依赖关系的复杂查询时,尤其是在资源受限情况下难以精确识别搜索意图的问题,QCompiler框架被提出。该框架受语言学语法规则和编译器设计启发,首先设计了最小且充分的BNF语法G[q]来形式化复杂查询,然后通过查询表达式转换器、词法语法解析器和递归下降处理器将查询编译为抽象语法树(AST)执行。叶节点的子查询原子性确保了更精确的文档检索和响应生成 (来源: HuggingFace Daily Papers)
Jedi数据集与OSWorld-G基准推动计算机使用场景的GUI元素定位研究: 为解决图形用户界面(GUI)定位(将自然语言指令映射到GUI操作)的瓶颈,研究者发布了OSWorld-G基准(564个细粒度标注样本,覆盖文本匹配、元素识别、布局理解和精确操作)和大规模合成数据集Jedi(400万样本)。在Jedi上训练的多尺度模型在ScreenSpot-v2、ScreenSpot-Pro和OSWorld-G上均优于现有方法,并能提升通用基础模型在复杂计算机任务(OSWorld)中的智能体能力,从5%提升至27% (来源: HuggingFace Daily Papers)
分段思维链推理(Fractured CoT)提升LLM推理效率与性能: 为解决CoT推理带来的高token成本问题,研究者发现截断CoT(在完成前停止推理直接生成答案)通常能达到与完整CoT相当的性能,但token消耗显著减少。基于此,提出Fractured Sampling统一推理策略,通过调整推理轨迹数量、每个轨迹的最终解数量以及推理痕迹截断深度这三个维度,在多个推理基准和模型规模上实现了更优的准确性-成本权衡,为更高效可扩展的LLM推理铺平道路 (来源: HuggingFace Daily Papers)
通过LLM上下文条件化和PWP提示进行化学公式多模态验证: 研究者探索了结构化LLM上下文条件化,并结合持久工作流提示(PWP)原则,以调整LLM在推理时的行为,旨在提高其在精确验证任务(如化学公式)中的可靠性,特别是在处理包含图像的复杂科学文档时。该方法仅使用标准聊天界面(Gemini 2.5 Pro, ChatGPT Plus o3),无需API或模型修改。初步实验表明,此方法改进了文本错误识别,并帮助Gemini 2.5 Pro识别了人工审核忽略的图像公式错误 (来源: HuggingFace Daily Papers)
利用PWP、元提示和元推理实现AI驱动的学术同行评审: 研究者提出持久工作流提示(PWP)方法,通过标准LLM聊天界面实现对科学手稿的批判性同行评审。PWP采用分层模块化架构(Markdown结构化)定义详细分析工作流,通过元提示和元推理系统性编码专家评审流程(包括隐性知识)。PWP引导LLM进行系统性多模态评估,如区分主张与证据、整合文本/图片/图表分析、执行量化可行性检查等,在测试案例中成功识别了方法论缺陷 (来源: HuggingFace Daily Papers)
SPOT基准评估AI自动验证科学研究的能力: 为评估大型语言模型(LLM)作为“AI联席科学家”在自动化验证学术稿件方面的能力,研究者推出了SPOT基准。该基准包含83篇已发表论文及91处足以导致勘误或撤稿的错误,并经过原作者和人工标注者交叉验证。实验结果显示,即便是最先进的LLM(如o3),在SPOT上的召回率也不超过21.1%,精确率低于6.1%,且模型置信度低,多次运行结果不一致,表明当前LLM在可靠的学术验证方面与实际需求存在巨大差距 (来源: HuggingFace Daily Papers)
ExTrans通过样本增强强化学习实现多语言深度推理翻译: 为提升机器翻译中大型推理模型(LRM)的能力,特别是在多语言场景,研究者提出ExTrans。该方法设计了一种新的奖励建模方法,通过比较策略翻译模型与强LRM(如DeepSeek-R1-671B)的翻译结果来量化奖励。实验表明,以Qwen2.5-7B-Instruct为骨干训练的模型在文学翻译上达到SOTA,并优于OpenAI-o1和DeepSeeK-R1。通过轻量级奖励建模,该方法能将单向翻译能力有效迁移至11种语言的90个翻译方向 (来源: HuggingFace Daily Papers)
可训练稀疏注意力VSA加速视频扩散模型: 为解决视频扩散Transformer(DiT)中3D全注意力机制的二次复杂度问题,研究者提出VSA(可训练稀疏注意力)。VSA通过轻量级粗略阶段将token汇集到区块并识别关键token,然后在这些区块内进行细粒度token级注意力计算。VSA是可端到端训练的单一可微内核,无需后处理分析,并保持了FlashAttention3 MFU的85%。实验表明,VSA在不降低扩散损失的情况下,将训练FLOPS降低2.53倍,并将开源Wan-2.1模型的注意力时间加速6倍,端到端生成时间从31秒降至18秒 (来源: HuggingFace Daily Papers)
SoftCoT++:通过软性思维链推理实现测试时扩展: 为增强在连续潜在空间中进行推理的SoftCoT方法的探索能力,研究者提出SoftCoT++。该方法通过多种专用初始令牌扰动潜在思路,并应用对比学习来促进软性思路表征的多样性,从而将SoftCoT扩展到测试时扩展(TTS)范式。实验表明,SoftCoT++显著提升了SoftCoT的性能,并优于带自洽性扩展的SoftCoT,且与传统扩展技术(如自洽性)兼容性强 (来源: HuggingFace Daily Papers)
MTVCrafter:用于开放世界人体图像动画的4D运动标记化: 为解决现有方法依赖2D姿态图像导致泛化能力有限的问题,MTVCrafter提出直接对原始3D运动序列(4D运动)进行建模。其核心是4DMoT(4D运动标记器),将3D运动序列量化为4D运动标记,提供更鲁棒的时空线索。然后,通过独特运动注意力和4D位置编码设计的MV-DiT(运动感知视频DiT)有效利用这些标记作为上下文,在复杂3D世界中实现人体图像动画。实验表明,MTVCrafter在FID-VID上达到6.98,显著优于SOTA,并能很好地泛化到不同风格和场景的多种角色 (来源: HuggingFace Daily Papers)
QVGen:推动量化视频生成模型的极限: 为解决视频扩散模型(DM)计算和内存需求大的问题,QVGen提出了一种专为极低比特量化(如4比特及以下)设计的新型量化感知训练(QAT)框架。通过理论分析,研究者发现降低梯度范数对QAT收敛至关重要,并引入辅助模块(Phi)减轻大的量化误差。为消除Phi的推理开销,提出秩衰减策略,通过SVD和基于秩的正则化逐步消除Phi。实验表明,QVGen在4比特设置下首次达到与全精度相当的质量,并显著优于现有方法 (来源: HuggingFace Daily Papers)
ViPlan:用于视觉规划的符号谓词与视觉语言模型基准: 为弥合VLM驱动的符号规划与直接VLM规划方法在比较上的差距,ViPlan被提出作为首个开源视觉规划基准。ViPlan包含视觉版Blocksworld和模拟家居机器人环境两大领域中一系列难度递增的任务。通过对9个开源VLM家族及部分闭源模型的基准测试发现,符号规划在Blocksworld中(精确图像定位关键)表现更优,而直接VLM规划在家居机器人任务中(常识知识和错误恢复能力重要)更佳。研究还表明,CoT提示对多数模型和方法无显著益处,暗示当前VLM视觉推理能力仍有不足 (来源: HuggingFace Daily Papers)
从原始呼喊到语法:合作觅食环境中的语言演化研究: 为探究语言的起源和演化,研究者在多智能体觅食游戏中模拟早期人类合作场景。通过端到端深度强化学习,智能体从零开始学习行动和沟通策略。研究发现,智能体发展出的沟通协议展现了自然语言的标志性特征:任意性、可互换性、位移性、文化传播和组合性。该框架为研究在部分可观察、时间推理和合作目标驱动的具身多智能体环境中语言如何演化提供了平台 (来源: HuggingFace Daily Papers)
Tiny QA Benchmark++:超轻量级多语言合成数据集生成与LLM持续评估的冒烟测试: Tiny QA Benchmark++ (TQB++) 是一个超轻量级、多语言的冒烟测试套件,旨在为LLM流水线提供单元测试式的安全网,可在数秒内以极低成本运行。TQB++包含一个52项的英文黄金集,并提供一个基于LiteLLM的微型合成数据生成器(pypi包),用户可生成自定义语言、领域或难度的小型测试包。项目已提供10种语言的预制包,并支持OpenAI-Evals、LangChain等工具,方便集成到CI/CD流程中,用于快速检测提示模板错误、分词器漂移和微调副作用 (来源: HuggingFace Daily Papers)
HelpSteer3-Preference:跨多任务和语言的开放人类标注偏好数据集: 为满足高质量、多样化开放偏好数据的需求,NVIDIA发布了HelpSteer3-Preference数据集。该数据集包含超过40,000个人类标注的偏好样本,遵循CC-BY-4.0许可,涵盖STEM、编码和多语言场景等LLM真实应用。使用此数据集训练的奖励模型(RM)在RM-Bench(82.4%)和JudgeBench(73.7%)上均取得SOTA性能,较之前最佳结果提升约10%。该数据集也可用于训练生成式RM,并通过RLHF对齐策略模型 (来源: HuggingFace Daily Papers)
SEED-GRPO:用于不确定性感知策略优化的语义熵增强GRPO: 为解决GRPO在策略更新时未考虑LLM对输入提示不确定性的问题,研究者提出SEED-GRPO。该方法通过语义熵明确衡量LLM对输入提示的不确定性(即多个生成答案的语义多样性),并以此调节策略更新的幅度。这种不确定性感知训练机制允许对高不确定性问题进行更保守的更新,同时保持对置信问题的原始学习信号。实验表明,SEED-GRPO在五个数学推理基准上均取得SOTA性能 (来源: HuggingFace Daily Papers)
从计算机使用中创建通用用户模型(GUM): 研究者提出了一种通用用户模型(GUM)架构,通过观察用户与计算机的任何交互(如设备截图)来学习用户知识和偏好,并构建置信度加权的命题。GUM能够从未结构化的多模态观察中推断新命题,检索相关命题作为上下文,并持续修正现有命题。该架构旨在增强聊天助手、管理操作系统通知,并使交互式智能体能跨应用适应用户偏好。实验表明,GUM能做出校准且准确的用户推断,基于GUM的助手能主动识别并执行用户未明确请求的有用操作 (来源: HuggingFace Daily Papers)
DataExpert-io/data-engineer-handbook: GitHub上的热门项目,提供了一个全面的数据工程学习资源库,包括2024年入门路线图、为期6周的免费YouTube训练营材料、项目案例、面试技巧、推荐书籍、社区和时事通讯列表。其中,推荐书籍包括《Fundamentals of Data Engineering》、《Designing Data-Intensive Applications》和《Designing Machine Learning Systems》。该手册还列出了数据工程各个领域的公司,如Mage(编排)、Databricks(数据湖)、Snowflake(数据仓库)、dbt(数据质量)、LangChain(LLM应用库)等,并提供了知名公司的数据工程博客和重要白皮书链接 (来源: GitHub Trending)
💼 商业
Cohere与SAP合作,将企业级AI智能体引入全球业务: Cohere宣布与SAP合作,将其企业级AI智能体技术嵌入SAP Business Suite,为全球企业提供安全且可扩展的AI能力。Cohere的前沿模型也将登陆SAP AI Core,使企业能够在金融、医疗等领域利用其多语言、特定领域的AI模型(Command, Embed, Rerank),旨在加速企业AI应用并释放实际商业价值 (来源: X, X)
xAI寻求利用政府数据,拓展企业和政府业务: 据The Information报道,Elon Musk的xAI公司计划利用政府机构的数据来开发模型和应用,并将其销售给政府客户。这一举措可能成为xAI商业化战略的重要组成部分,但也引发了关于数据使用和潜在偏见的讨论 (来源: X)
Weaviate与AWS深化全球合作,加速生成式AI计划: 向量数据库公司Weaviate宣布加强与AWS的全球合作,旨在共同加速生成式AI项目。此次合作将聚焦于为全球开发者提供更快的速度、更大的规模和更优的开发者体验,推动生成式AI技术的应用和发展 (来源: X)

🌟 社区
AI编程智能体崛起,引发程序员职业前景讨论: 微软、OpenAI等公司纷纷推出或强化AI编程智能体(Coding Agents),如GitHub Copilot Coding Agent、OpenAI Codex等,它们能够自主完成编码、修复bug、代码维护等任务。Anthropic CEO Dario Amodei预测AI可能在短期内编写大部分甚至全部代码,OpenAI CPO Kevin Weil也认为AI将从初级工程师成长为架构师。这引发了社区对程序员职业未来的广泛讨论:部分人担忧初级岗位将被取代,AI将自动化大量编程工作;另一些人则认为AI将提升程序员效率,使其专注于更高层次的架构设计和创新,角色转变为“AI引导者”。整体趋势表明,学习与AI高效协作将成为程序员的核心技能 (来源: X, X, 36氪, 36氪)
AI Agent概念与标准讨论激烈,MCP协议受关注: 随着AI Agent应用的兴起(如Manus、Genspark Super Agent、Fellou.ai),社区对Agent的定义、能力等级和开发范式展开热议。知名风投BVP提出了Agent从L0到L6的七大等级划分。同时,模型上下文协议(MCP)作为实现AI应用间互操作性的关键技术受到关注,Anthropic、OpenAI、Google等国外大厂已支持或计划支持MCP,国内如阿里云、腾讯云也开始围绕MCP构建本土化Agent开发平台。开发者iluxu甚至在微软提出“USB-C for AI apps”概念前开源了相似的llmbasedos项目,旨在推动开放的Agent连接标准 (来源: X, X, WeChat, Reddit r/LocalLLaMA)
LLM在特定推理任务上表现不佳,引发对其能力边界的探讨: 社区热议LLM在某些看似简单的物理或视觉空间推理任务中集体“翻车”的现象,例如一个关于堆叠立方体以形成更大立方体的问题,即使是o3、Gemini 2.5 Pro等顶级模型也给出错误答案。同时,一篇评估文章指出,在零件制造等基本物理任务上,LLM(包括o3)表现不如经验丰富的工人,主要原因在于视觉能力不足和物理推理错误,以及缺乏真实世界的隐性知识。这些案例引发了对LLM真实理解能力、幻觉问题(如o3在推理时幻觉率上升)以及当前Benchmark有效性的讨论,强调了AI在特定领域知识和复杂推理方面仍有很大提升空间 (来源: 量子位, 36氪)

中美科技竞争与AI发展策略引关注: 英伟达CEO黄仁勋在采访中谈及芯片管制、AI工厂和企业实用主义,其观点被解读为对当前中美科技竞争格局的深刻洞察。有评论认为,美国试图通过限制中国获取高端AI资源来维持领先地位,但这可能导致双输局面,减缓全球AI发展。黄仁勋则似乎认为,真正的竞争是长期的,美国应全面领先(芯片、工厂、基础设施、模型、应用),而非仅仅寻求短期相对优势,否则可能错失AI时代的发展机遇,最终在综合国力竞争中落后 (来源: X)
ChatGPT等AI工具在心理健康辅助方面的应用与讨论: Reddit社区用户分享使用ChatGPT等AI工具进行心理健康支持的经验,认为其在两次专业治疗之间能提供帮助,尤其是在梳理和表达复杂情绪方面。用户通过向AI提问或让AI就自身感受提问,来更好地理解情绪来源并制定改善计划。评论中,有用户(包括自称治疗师的)认为AI在某些情况下甚至优于部分人类治疗师,尤其对于那些难以获得专业帮助或对人类治疗师存在信任障碍的个体。但也有用户提醒,AI不能完全替代专业治疗,且应注意个人数据隐私问题 (来源: Reddit r/ChatGPT)
💡 其他
“启智杯”算法大赛启动,聚焦三大AI前沿方向: 启元实验室发起“启智杯”算法大赛,总奖金池75万元。大赛设置三大赛道:“卫星遥感图像鲁棒实例分割”、“面向嵌入式平台的无人机对地目标检测”以及“面向多模态大模型的对抗”,旨在推动鲁棒感知、轻量化部署和对抗防御等AI核心技术的创新与应用落地。赛事面向国内研究机构、企事业单位开放 (来源: WeChat)

芝加哥太阳报AI生成内容出错,推荐不存在书籍和专家: 《芝加哥太阳报》在其一期夏季活动推荐中,部分内容疑似由AI生成,其中包含了对实际存在的作者创作的虚构书籍的推荐,以及引用了似乎并不存在的“专家”观点。例如,将Min Jin Lee的《Nightshade Market》和Rebecca Makkai的《Boiling Point》列为推荐读物,但这些书并不存在。此事件引发了对新闻媒体使用AI生成内容时准确性和审查机制的担忧 (来源: Reddit r/artificial)
关于AI是否构成“作弊”的讨论: 社区探讨了在工作和学习中使用AI工具(如ChatGPT、Claude)的界限。普遍观点认为,在无明确规则禁止的情况下(如大学作业),使用AI工具提高效率、完成重复性任务或辅助思考并非“作弊”,而是类似使用计算器或搜索引擎。关键在于使用者是否理解AI的输出、能否对其进行有效调整和验证,以及是否诚实声明AI的辅助作用(尤其在学术场景)。然而,如果完全依赖AI生成内容且不加甄别地声称是原创,则可能涉及学术不端或影响个人技能发展 (来源: Reddit r/ArtificialInteligence)