
关键词:AlphaEvolve, Gemini, 进化算法, AI智能体, 算法优化, 矩阵乘法, Borg数据中心, 4×4复数矩阵乘法优化, Google DeepMind算法发现, AI自动化算法设计, Gemini 2.0 Pro应用, Borg资源调度优化
🔥 聚焦
谷歌DeepMind推出AlphaEvolve:基于Gemini的进化算法编码智能体,在数学和计算机科学领域实现突破: 谷歌DeepMind发布了AlphaEvolve,一个利用Gemini 2.0 Pro大型语言模型,通过进化算法自动发现和优化算法代码的智能体。AlphaEvolve能够从人类提供的初始代码和评估指标出发,自主生成、评估和改进候选方案。该系统在50多个数学问题上表现出色,约75%案例重现已知解,20%案例发现更优解。值得注意的是,AlphaEvolve将4×4复数矩阵乘法的计算次数从49次减少到48次,刷新了尘封56年的记录。此外,它还优化了谷歌内部Borg数据中心的调度算法,回收了0.7%的全球计算资源,并改进了下一代TPU芯片的设计,使Gemini训练时间缩短1%。这一成果展示了AI在自动化算法发现和科学创新方面的巨大潜力,尽管目前主要处理可自动评估的问题,但其在药物发现等应用科学领域的应用前景广阔。
英伟达Computex 2025发布多项AI进展,黄仁勋强调Agentic AI与Physical AI愿景: 英伟达CEO黄仁勋在Computex 2025发表主旨演讲,强调AI正从“单次响应”向“思考型、推理型”的Agentic AI(智能体AI)和理解物理世界的Physical AI(物理AI)演进。为支持此趋势,英伟达发布了扩展版Blackwell平台(Blackwell Ultra AI),并宣布Grace Blackwell GB300系统全面投产,其推理性能较前代提升1.5倍。黄仁勋还预览了下一代AI超级芯片Rubin Ultra,性能为GB300的14倍。为推动AI基础设施建设,英伟达推出NVLink Fusion技术,并联合台积电、富士康等在中国台湾建立AI超级计算机。此外,英伟达更新了类人机器人基础模型Isaac GR00T N1.5,提升了其环境适应和任务执行能力,并计划开源与DeepMind、Disney Research合作开发的物理引擎Newton。 (来源: AI 前线, 量子位, Reddit r/artificial)
OpenAI Codex团队AMA透露GPT-5及未来产品整合计划: OpenAI Codex团队在Reddit举行“有问必答”(AMA)活动,研究副总裁Jerry Tworek透露,下一代基础模型GPT-5的目标是提升现有模型能力并减少模型切换的需要,计划将Codex、Operator(任务执行智能体)、Deep Research(深度研究工具)和Memory(记忆功能)等现有工具整合,形成一个统一的AI助手体验。团队成员还分享了Codex的开发初衷(源于内部对模型利用不足的思考)、内部使用Codex带来的约3倍编程效率提升,以及对未来软件工程的展望——高效可靠地将需求转化为可运行软件。Codex目前主要利用加载到容器运行时的信息,未来可能结合RAG技术获取最新知识。OpenAI也在探索灵活的定价方案,并计划为Plus/Pro用户提供免费API积分供Codex CLI使用。 (来源: 36氪)
VS Code宣布开源GitHub Copilot Chat扩展,计划打造开源AI代码编辑平台: Visual Studio Code团队宣布计划将VS Code发展为一个开源的AI编辑器,秉持开放、协作和社区驱动的核心原则。作为此计划的一部分,GitHub Copilot Chat扩展已在GitHub上以MIT许可证开源。未来,VS Code计划逐步将这些AI功能集成到编辑器的核心中,旨在构建一个完全开源、由社区驱动的AI代码编辑平台,以提升开发效率、透明度和安全性。这一举措被认为是微软在开源领域的重要一步,可能对AI辅助编程工具的生态产生深远影响。 (来源: dotey, jeremyphoward)
华为昇腾与DeepSeek合作,MoE模型推理性能超越英伟达Hopper: 华为昇腾宣布其CloudMatrix 384超节点和Atlas 800I A2推理服务器在部署DeepSeek V3/R1等超大规模MoE模型时,推理性能取得重大突破,在特定条件下超越英伟达Hopper架构。CloudMatrix 384超节点在50ms时延下单卡Decode吞吐量突破1920 Tokens/s,而Atlas 800I A2在100ms时延下单卡吞吐量达到808 Tokens/s。华为将此归功于“以数学补物理”的策略,通过算法和系统优化弥补硬件工艺局限。相关技术报告已发布,核心代码也将于一个月内开源。优化措施包括针对MoE模型的专家并行解决方案、PD分离部署、vLLM框架适配、A8W8C16量化策略,以及FlashComm通信方案、层内并行转换、FusionSpec投机推理引擎和MLA/MoE算子硬件亲和性优化等。 (来源: 量子位, WeChat)
🎯 动向
苹果开源高效视觉语言模型FastVLM,优化端侧AI体验: 苹果公司开源了FastVLM(Fast Vision Language Model),一款专为在iPhone等边缘设备上高效运行而设计的视觉语言模型。FastVLM通过引入新型混合视觉编码器FastViTHD,结合卷积层与Transformer模块,并采用多尺度池化和下采样技术,显著减少了图像处理所需的视觉token数量(比传统ViT少16倍)。这使得模型在保持高精度的同时,首个token输出速度(TTFT)相比同类模型提升高达85倍。FastVLM兼容主流LLM并易于适配iOS/Mac生态,提供0.5B、1.5B、7B三种参数版本,适用于图像描述、问答、分析等多种实时图文任务。 (来源: WeChat)
Meta发布KernelLLM 8B模型,在特定基准测试中超越GPT-4o: Meta在Hugging Face上发布了KernelLLM 8B模型。据称,在KernelBench-Triton Level 1基准测试中,该80亿参数模型在单次推理性能上超过了GPT-4o和DeepSeek V3等更大规模的模型。在多次推理的情况下,KernelLLM的性能也优于DeepSeek R1。这一发布引起了AI社区的关注,被认为是中小型模型在特定任务上展现出强大竞争力的又一例证。 (来源: ClementDelangue, huggingface, mervenoyann, HuggingFace Daily Papers)
Mistral Medium 3模型在Arena表现强劲,技术领域尤为突出: Mistral AI新推出的Mistral Medium 3模型在lmarena.ai的社区评估中表现出色,整体聊天能力排名第11位,较Mistral Large有显著提升(Elo分数增加90点)。该模型在技术领域表现尤为突出,数学能力排名第5,复杂提示词与编码能力排名第7,WebDev Arena中排名第9。社区评论认为其在技术领域的表现接近GPT-4.1级别,而成本可能更具竞争力,类似于GPT-4.1 mini的定价。用户可在Mistral官方聊天界面免费试用该模型。 (来源: hkproj, qtnx_, lmarena_ai)
Hugging Face Datasets新增直接查看聊天对话功能: Hugging Face Datasets平台进行了一项重要更新,用户现在可以直接在数据集中阅读聊天对话内容。这项功能被社区成员(如Caleb、Maxime Labonne)认为是解决数据质量问题的一大步,因为直接查阅原始对话数据有助于更好地理解数据、进行数据清洗和提升模型训练效果。此前,查看具体对话内容可能需要额外的代码或工具,新功能简化了这一流程,提升了数据工作的便捷性和透明度。 (来源: eliebakouch, _lewtun, _akhaliq, maximelabonne, ClementDelangue, huggingface, code_star)
MLX LM与Hugging Face Hub集成,简化Mac本地模型运行: MLX LM现已直接集成到Hugging Face Hub,Mac用户可以更便捷地在Apple Silicon设备上本地运行超过4400个LLM。用户只需在Hugging Face Hub上兼容模型的页面点击“Use this model”,即可快速在终端运行模型,无需复杂的云端配置或等待。此外,还可以直接从模型页面启动与OpenAI兼容的服务器。这一集成旨在降低本地运行模型的门槛,提升开发和实验效率。 (来源: awnihannun, ClementDelangue, huggingface, reach_vb)
英伟达开源物理AI推理模型Cosmos-Reason1-7B: 英伟达在Hugging Face上开源了其Physical AI模型系列中的Cosmos-Reason1-7B。该模型旨在理解物理世界常识并生成相应的具身决策。这标志着英伟达在推动物理世界与AI结合方面迈出了新的一步,为机器人、自动驾驶等需要与物理环境交互的应用提供了新的工具和研究基础。 (来源: reach_vb)
百度视频生成模型Steamer-I2V登顶VBench图生视频榜单: 百度的视频生成模型Steamer-I2V在权威视频生成评测榜单VBench的图生视频(I2V)类别中排名第一,总分达到89.38%,超越了OpenAI Sora和谷歌Imagen Video等知名模型。Steamer-I2V的技术优势包括像素级画面精准控制、大师级运镜、高达1080P的电影级高清画质和动态美学,以及基于亿级中文多模态数据库的精准中文语义理解。这一成绩显示了百度在多模态生成领域的实力,也是其构建AI内容生态系统战略的一部分。 (来源: 36氪)

LLM在读取钟表和日历等时间任务上表现不佳: 爱丁堡大学等机构的研究者发现,尽管大型语言模型(LLM)及多模态大语言模型(MLLM)在多种任务上表现出色,但在看似简单的时间读取任务(如识别指针式时钟时间和理解日历日期)上准确率堪忧。研究构建了ClockQA和CalendarQA两个定制测试集,结果显示AI系统读取时钟的准确率仅为38.7%,判断日历日期的准确率仅为26.3%。即使是Gemini-2.0和GPT-o1等先进模型也存在明显困难,尤其在处理罗马数字、风格化指针或复杂日期计算(如闰年、特定天数是周几)时。研究者认为,这暴露了当前模型在空间推理、结构化布局解析以及对非常见模式泛化能力上的不足。 (来源: 36氪, WeChat)

微软在Build大会上宣布将Grok模型引入Azure AI Foundry: 在微软Build 2025开发者大会上,微软宣布xAI公司的Grok模型将加入其Azure AI Foundry模型系列。用户可以在Azure Foundry和GitHub上免费试用Grok-3和Grok-3-mini,直至六月初。此举意味着Azure AI Foundry将进一步扩展其支持的第三方模型范围,未来用户可以通过统一的预留吞吐量使用来自OpenAI、xAI、DeepSeek、Meta、Mistral AI、Black Forest Labs等多个厂商的模型。 (来源: TheTuringPost, xai)
苹果据报计划允许欧盟iPhone用户更换Siri为第三方语音助手: 据Mark Gurman报道,苹果公司正计划首次允许欧盟地区的iPhone用户将Siri替换为第三方的语音助手。这一举措可能是为了应对欧盟日益严格的数字市场监管要求,旨在增强平台的开放性和用户选择权。如果该计划得以实施,将对语音助手市场格局产生重要影响,为其他语音助手提供了进入苹果生态系统的机会。 (来源: zacharynado)

Meta发布Open Molecules 2025数据集和UMA模型,加速分子与材料发现: Meta AI发布了Open Molecules 2025 (OMol25) 和Meta通用原子模型 (UMA)。OMol25是目前规模最大、最多样化的高精度量子化学计算数据集,包含生物分子、金属配合物和电解质等。UMA是一个基于超过300亿个原子训练的机器学习原子间势模型,旨在提供更准确的分子行为预测。这些工具的开源旨在加速分子和材料科学的发现与创新。 (来源: AIatMeta)
Hugging Face Datasets新增Parquet文件增量编辑功能: Hugging Face Datasets 宣布其底层依赖库 PyArrow 的夜间版本现已支持对 Parquet 文件进行增量编辑,而无需完全重写文件。这一新功能将极大提升大规模数据集操作的效率,特别是在需要频繁更新或修改部分数据时,可以显著减少时间和计算资源的消耗。此举有望改善开发者在处理和维护大型AI训练数据集时的体验。 (来源: huggingface)
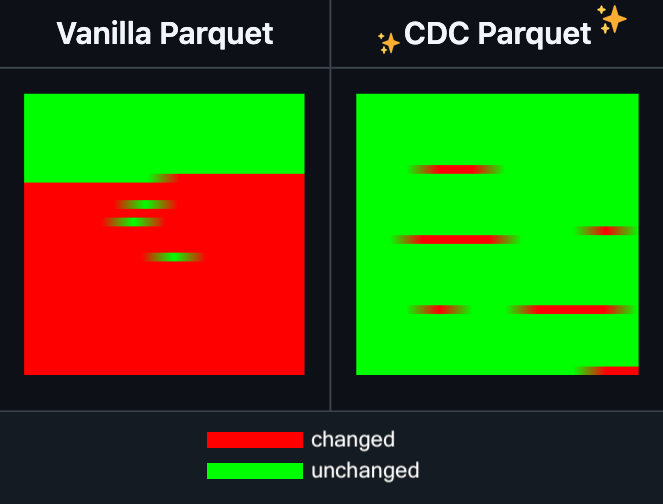
LangGraph新增节点级缓存功能,提升工作流效率: LangGraph宣布其开源版本新增节点/任务缓存功能。该功能旨在通过避免重复计算来加速工作流程,尤其适用于包含通用部分或需要频繁调试的智能体(Agent)工作流。用户可以在命令式API或图形API中使用缓存,从而更快地迭代和优化其AI应用。这是LangGraph本周开源发布系列更新的第一项。 (来源: hwchase17)

Sakana AI推出新型AI架构“持续思考机器”(CTM) : 东京AI初创公司Sakana AI发布了一种名为“持续思考机器”(Continuous Thought Machines, CTM)的新型AI模型架构。CTM旨在让模型能够像人脑一样,在更少指导的情况下进行推理。这一新架构可能为解决当前AI模型在复杂推理和自主学习方面面临的挑战提供新的思路。 (来源: dl_weekly)
微软与英伟达深化RTX AI PC合作,TensorRT登陆Windows ML: 在微软Build和台北国际电脑展(COMPUTEX)期间,英伟达与微软宣布进一步推进RTX AI PC的开发合作。英伟达的TensorRT推理优化库已被重新设计并集成到微软新的推理堆栈Windows ML中。此举旨在简化AI应用的开发流程,并充分发挥RTX GPU在PC端AI任务中的峰值性能,推动AI在个人计算设备上的普及和应用。 (来源: nvidia)
B站开源动画视频生成模型Index-AniSora,多项指标达SOTA: B站宣布开源其自研的动画视频生成模型Index-AniSora,该模型在IJCAI 2025上发表。AniSora专为二次元视频生成设计,支持番剧、国创、漫改等多种风格,能够实现视频局部区域引导、时序引导(如首帧/尾帧引导、关键帧插值)等精细控制。项目开源内容包括基于CogVideoX-5B的AniSoraV1.0和基于Wan2.1-14B的AniSoraV2.0的训练推理代码、训练数据集构建工具、动画专用Benchmark系统及基于人类偏好强化学习优化的AniSoraV1.0_RL模型。 (来源: WeChat)

腾讯混元开源首个多模态统一CoT奖励模型UnifiedReward-Think: 腾讯混元联合上海AI Lab、复旦大学等机构提出UnifiedReward-Think,这是首个具备长链式推理(CoT)能力的统一多模态奖励模型。该模型旨在让奖励模型在评估复杂视觉生成与理解任务时“学会思考”,从而提升评估准确性、跨任务泛化能力和推理可解释性。项目已全面开源,包括模型、数据集、训练脚本和评测工具。 (来源: WeChat)
阿里巴巴开源视频生成与编辑模型通义万相Wan2.1-VACE: 阿里巴巴正式开源了其视频生成与编辑模型通义万相Wan2.1-VACE。该模型具备文生视频、图像参考视频生成、视频重绘、视频局部编辑、视频背景延展以及视频时长延展等多种功能。此次开源了1.3B和14B两个版本,其中1.3B版本可在消费级显卡上运行,旨在降低AIGC视频创作的门槛。 (来源: WeChat)
字节跳动发布视觉语言模型Seed1.5-VL,多项基准测试领先: 字节跳动构建了视觉语言模型Seed1.5-VL,由532M参数的视觉编码器和20B活动参数的混合专家(MoE)LLM组成。尽管架构相对紧凑,但在60个公共基准测试中,有38个达到SOTA性能,并在GUI控制和游戏玩法等以代理为中心的任务上超越了OpenAI CUA和Claude 3.7等模型,展现了强大的多模态推理能力。 (来源: WeChat)
MiniMax推出自回归TTS模型MiniMax-Speech,支持32种语言零样本声音克隆: MiniMax提出基于Transformer的自回归文本转语音(TTS)模型MiniMax-Speech。该模型能从参考音频中提取音色特征无需转录,实现零样本方式生成与参考音色一致且富有表现力的语音,并支持单样本声音克隆。通过Flow-VAE技术提升了合成音频质量,支持32种语言。该模型在客观声音克隆指标上达到SOTA水平,并在公共TTS Arena排行榜上位居榜首,还可扩展应用于声音情感控制、文本转声音及专业声音克隆等。 (来源: WeChat)
OuteTTS 1.0 (0.6B) 发布,支持14种语言的Apache 2.0开源TTS模型: OuteAI发布了OuteTTS-1.0-0.6B,这是一款基于Qwen-3 0.6B构建的轻量级文本转语音(TTS)模型。该模型采用Apache 2.0许可证,支持包括中、英、日、韩在内的14种语言。其Python推理库OuteTTS v0.4.2更新支持EXL2异步批量推理、vLLM实验性批量推理以及Llama.cpp服务器的连续批处理和外部URL模型推理。在单NVIDIA L40S GPU上的基准测试显示,vLLM OuteTTS-1.0-0.6B FP8在批量大小为32时RTF(实时因子)可达0.05。模型权重(ST, GGUF, EXL2, FP8)已在Hugging Face上提供。 (来源: Reddit r/LocalLLaMA)

Hugging Face与微软Azure深化合作,超万款开源模型登陆Azure AI Foundry: 在微软Build大会上,CEO萨提亚·纳德拉宣布与Hugging Face扩大合作。目前已有超过11000个最受欢迎的开源模型通过Hugging Face在Azure AI Foundry上提供,方便用户轻松部署。此举进一步丰富了Azure的AI生态,为开发者提供了更多模型选择和更便捷的开发体验。 (来源: ClementDelangue, _akhaliq)

英特尔发布Arc Pro B50/B60系列GPU,主打AI与工作站市场,24GB版本约500美元: 英特尔在Computex上发布了新款Arc Pro B系列专业显卡,包括Arc Pro B50(16GB显存,约299美元)和Arc Pro B60(24GB显存,约500美元)。其中,双B60 GPU组成的48GB显存版本“Project Battlematrix”工作站方案也一同亮相,预计售价低于1000美元。这些产品旨在为AI计算和专业工作站提供高性价比的解决方案,特别是高显存配置对本地运行大型语言模型具有吸引力。新品预计于今年Q3上市,初期通过OEM厂商提供,Q4可能推出DIY版本。 (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

🧰 工具
Moondream Station发布Linux版本,简化本地Moondream运行: Moondream Station是一款旨在简化在本地设备上运行Moondream(一种视觉语言模型)的工具,现已宣布支持Linux操作系统。这意味着Linux用户可以更方便地部署和使用Moondream模型进行多模态AI实验和应用开发。 (来源: vikhyatk)
Flowith发布无限智能体NEO,支持无限步骤、上下文和工具调用: AI应用公司Flowith发布了其最新的智能体产品NEO,号称是全球首个支持无限步骤、无限上下文和无限工具调用的智能体。该智能体设计用于在云端长时间运行,具备超越基准的智能水平,并且宣称零成本、无限制。这一发布可能代表了AI智能体在处理复杂长期任务和整合外部能力方面的一个新进展。 (来源: _akhaliq, op7418)

Kapa AI利用Weaviate构建可交互技术文档问答工具“Ask AI”: Kapa AI开发了一款名为“Ask AI”的智能小部件,允许用户通过自然语言对话的方式查询技术文档、博客、教程、GitHub issues和论坛等整个技术知识库。为实现高效的语义搜索和知识检索,Kapa AI采用了Weaviate向量数据库,看重其内置的混合搜索能力、Docker兼容性以及多租户特性,以支持快速增长的用户和数据规模。 (来源: bobvanluijt)

开发者利用Gemini Flash快速构建截图转HTML的MVP工具: 开发者Daniel Huynh利用Google AI的Gemini Flash模型,在一个周末内构建了一个MVP(最小可行产品)工具,可以将设计稿、竞品或灵感截图快速转换为HTML代码。该工具已在Hugging Face Spaces上免费提供试用,展示了多模态模型在前端开发辅助方面的潜力。 (来源: osanseviero, _akhaliq)
Azure AI Foundry Agent Service正式可用,集成LlamaIndex: 微软宣布Azure AI Foundry Agent Service已正式发布(GA),并提供对LlamaIndex的一流支持。该服务旨在帮助企业客户构建客户支持助手、流程自动化机器人、多智能体系统以及与企业数据和工具安全集成的解决方案,进一步推动企业级AI智能体的开发和应用。 (来源: jerryjliu0)
tinygrad:一个介于PyTorch和micrograd之间的极简深度学习框架: tinygrad是一个以简单性为核心设计理念的深度学习框架,旨在成为最容易添加新加速器的框架,支持推理和训练。它支持LLaMA和Stable Diffusion等模型,并采用惰性求值(lazy evaluation)来融合操作并优化性能。tinygrad支持GPU (OpenCL)、CPU (C代码)、LLVM、Metal、CUDA等多种加速器。其代码简洁,核心功能由少量代码实现,方便开发者理解和扩展。 (来源: GitHub Trending)
纳米AI搜索推出“超级搜索”功能,整合多模型与MCP工具箱: 纳米AI搜索(bot.n.cn)新增“超级搜索”功能,旨在提供更深度的信息获取和处理能力。该功能集成了国内外上百款大模型,并可按需自动切换;内置MCP万能工具箱,支持数千种AI工具,能处理网页、图片、视频、PDF等多种格式文件,并进行代码生成、数据分析等。同时结合公域搜索与本地知识库私域搜索,提供更全面的结果,并内置文生图、文生视频能力。用户体验显示,该功能能将搜索结果整理成包含图表的详细报告和精美网页,适用于行研、购物比价、知识梳理等多种场景。 (来源: WeChat)
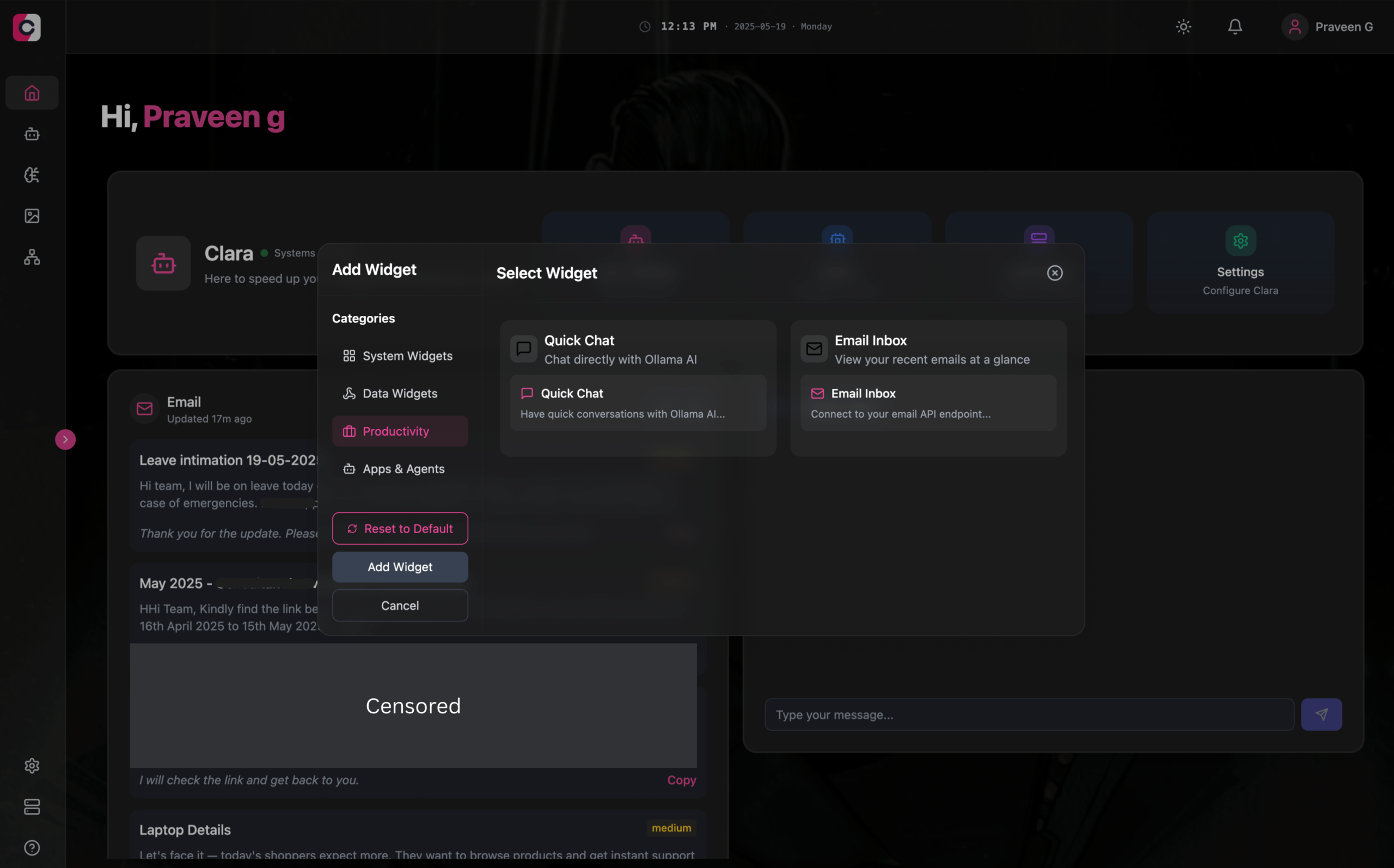
Clara:模块化离线AI工作空间,集成LLM、Agent、自动化与图像生成: 开发者推出名为Clara的开源项目,旨在打造一个完全离线、模块化的AI工作空间。用户可以在仪表盘上以小部件形式组织本地LLM聊天(支持RAG、图像、文档、代码执行,兼容Ollama及OpenAI类API)、创建带记忆和逻辑的Agent、通过原生N8N集成运行自动化流程(提供1000+免费模板)、以及使用Stable Diffusion(ComfyUI)本地生成图像。Clara提供Mac、Windows、Linux版本,旨在解决用户在多个AI工具间频繁切换的问题,实现一站式AI操作。 (来源: Reddit r/LocalLLaMA)
AI Playlist Curator:利用LLM个性化整理YouTube播放列表的Python工具: 一位开发者创建了名为AI Playlist Curator的Python项目,旨在帮助用户自动整理其庞大且无序的YouTube播放列表。该工具利用LLM,根据用户偏好将歌曲分类并创建个性化的子播放列表,支持处理任何已保存的播放列表和喜欢的歌曲。项目已在GitHub上开源,开发者希望能获得社区反馈以进一步改进。 (来源: Reddit r/MachineLearning)
OpenAI Codex编程助手登陆ChatGPT iOS应用: OpenAI宣布其编程助手Codex现已集成到ChatGPT的iOS应用程序中。用户可以在移动设备上启动新编程任务、查看代码差异、请求修改,甚至推送拉取请求(PR)。该功能还支持通过锁屏实时活动跟踪Codex的进展,方便用户在不同设备间无缝切换工作。 (来源: openai)
Kollektiv:利用MCP协议解决LLM聊天上下文重复粘贴问题的工具: 开发者推出Kollektiv工具,旨在解决用户在与LLM(如Claude)聊天时需要反复复制粘贴大量上下文(如研究论文、SDK文档、个人笔记、书籍内容)的问题。Kollektiv允许用户一次性上传这些文档源,并通过MCP(Model Control Protocol)服务器从任何兼容的IDE或MCP客户端(如Cursor, Windsurf, PyCharm等)中按需调用。MCP服务器负责用户认证、数据隔离和按需流式传输数据到聊天界面。该工具目前不建议用于敏感或机密材料。 (来源: Reddit r/ClaudeAI)
📚 学习
谷歌DeepMind发布AlphaEvolve技术报告,揭示其算法发现能力: 谷歌DeepMind发布了关于其AI系统AlphaEvolve的技术报告。AlphaEvolve是一个基于Gemini的编码智能体,能够通过进化算法设计和优化算法。报告详细介绍了AlphaEvolve如何通过结构化反馈循环自主生成、评估和改进候选算法方案,从而在多个数学和计算科学问题上取得突破,包括刷新4×4复数矩阵乘法算法的记录。该报告为理解AI在自动化科学发现和算法创新方面的潜力提供了重要参考。
DeepLearning.AI推出“构建AI浏览器代理”课程: DeepLearning.AI上线了一门名为“Building AI Browser Agents”的新课程。该课程由AGI公司的联合创始人Div Garg和Naman Agarwal讲授,旨在帮助学习者掌握构建能够与浏览器交互的AI智能体(Agent)的技术。课程内容可能涵盖网页自动化、信息提取、用户界面交互等AI在浏览器环境中的应用。 (来源: DeepLearningAI)
Qwen3技术报告发布: 阿里巴巴发布了其最新一代大语言模型Qwen3的技术报告。该报告详细介绍了Qwen3的模型架构、训练方法、性能评估以及在各项基准测试中的表现。Qwen3系列模型旨在提供更强的语言理解、生成和多模态处理能力,其技术报告的发布为研究者和开发者提供了深入了解该模型技术细节的机会。 (来源: _akhaliq)

论文研讨:多视角搜索与数据管理提升逐步定理证明 (MPS-Prover): 一篇新论文介绍了MPS-Prover,一个新颖的逐步自动化定理证明(ATP)系统。该系统通过高效的训练后数据管理策略(剪枝约40%冗余数据而不牺牲性能)和多视角树搜索机制(集成学习的评论家模型与启发式规则)来克服现有逐步证明器中搜索指导有偏的问题。实验表明,MPS-Prover在miniF2F和ProofNet等多个基准上达到SOTA性能,生成的证明更短、更多样。 (来源: HuggingFace Daily Papers)
论文研讨:视觉规划——仅用图像进行思考 (Visual Planning): 一篇新论文提出“视觉规划”范式,使模型能够完全通过视觉表征(图像序列)进行规划,而非依赖文本。研究者认为,在涉及空间和几何信息的任务中,语言可能并非最自然的推理媒介。他们引入了通过强化学习的视觉规划框架VPRL,并使用GRPO对大型视觉模型进行训练后优化,在FrozenLake、Maze和MiniBehavior等视觉导航任务中取得了显著改进,表现优于纯文本推理的规划变体。 (来源: HuggingFace Daily Papers)
论文研讨:扩展推理能提升大语言模型的事实性 (Scaling Reasoning can Improve Factuality): 一项研究探讨了扩展大型语言模型(LLM)的推理过程是否能提升其在复杂开放域问答(QA)中的事实准确性。研究者从QwQ-32B和DeepSeek-R1-671B等模型中提取推理轨迹,并对多种Qwen2.5系列模型进行微调,同时将知识图谱路径融入推理轨迹。实验表明,在单次运行中,较小的推理模型相比原始指令微调模型在事实准确性上有明显提升。增加测试时计算和token预算,事实准确性可稳定提升2-8%。 (来源: HuggingFace Daily Papers)
论文研讨:Mergenetic——简单的进化模型合并库: 一篇新论文介绍了Mergenetic,一个用于进化模型合并的开源库。模型合并允许将现有模型的能力组合成新模型,无需额外训练。Mergenetic支持轻松组合合并方法和进化算法,并结合轻量级适应度评估器以降低评估成本。实验证明,Mergenetic在多种任务和语言上使用适度硬件即可产生有竞争力的结果。 (来源: HuggingFace Daily Papers)
论文研讨:群体思维——多并发推理智能体在Token级协作 (Group Think): 一篇新论文提出“群体思维”(Group Think)——让单个LLM充当多个并发推理智能体(思考者)。这些智能体共享对彼此部分生成进展的可见性,在Token级别动态适应彼此的推理轨迹,从而减少冗余推理、提高质量并降低延迟。该方法适用于本地GPU上的边缘推理,实验证明其在使用未经专门训练的开源LLM时也能改善延迟。 (来源: HuggingFace Daily Papers)
论文研讨:人类在策略游戏中期望LLM对手展现理性和合作 (Humans expect rationality and cooperation from LLM opponents): 一项首次进行的受控货币激励实验室实验研究了人类在多人P-beauty竞赛中对抗其他人类与LLM时的行为差异。结果显示,人类在对抗LLM时选择的数字显著更低,主要因为“零”纳什均衡选择的普遍性增加。这种转变主要由具有高策略推理能力的受试者驱动,他们认为LLM具备更强的推理能力和合作倾向。 (来源: HuggingFace Daily Papers)
论文研讨:通过双头优化从视觉语言模型进行简单的半监督知识蒸馏 (Dual-Head Optimization for KD): 一篇新论文提出DHO(Dual-Head Optimization),一个简单有效的知识蒸馏(KD)框架,用于在半监督设置下将知识从视觉语言模型(VLM)迁移到紧凑的任务特定模型。DHO引入独立学习标记数据和教师预测的双预测头,并在推理时线性组合其输出,从而缓解监督信号和蒸馏信号间的梯度冲突。实验表明,DHO在多个领域和细粒度数据集上均优于单头KD基线,在ImageNet上达到SOTA。 (来源: HuggingFace Daily Papers)
论文研讨:GuardReasoner-VL——通过强化推理保护VLM: 为增强视觉语言模型(VLM)的安全性,一篇新论文引入了基于推理的VLM防护模型GuardReasoner-VL。核心思想是通过在线强化学习(RL)激励防护模型在做出审核决策前进行审慎推理。研究者构建了包含123K样本和631K推理步骤的推理语料库GuardReasoner-VLTrain,并通过监督微调(SFT)冷启动模型的推理能力,再通过在线RL进一步增强。实验表明,该模型(3B/7B版本已开源)性能优越,在平均F1分数上比次优模型高出19.27%。 (来源: HuggingFace Daily Papers)
论文研讨:多Token预测需要寄存器 (Multi-Token Prediction Needs Registers): 一篇新论文提出MuToR,一种简单有效的多Token预测方法,通过在输入序列中交错插入可学习的寄存器Token来预测未来目标。与现有方法相比,MuToR参数增加可忽略,无需架构更改,兼容现有预训练模型,并与下一Token预训练目标保持一致,特别适合监督微调。该方法在语言和视觉领域的生成任务中展示了有效性和通用性。 (来源: HuggingFace Daily Papers)
论文研讨:MMLongBench——有效彻底的长上下文视觉语言模型基准测试: 针对长上下文视觉语言模型(LCVLM)的评估需求,一篇新论文引入了MMLongBench,这是首个覆盖多种长上下文视觉语言任务的基准。MMLongBench包含13331个样本,涵盖视觉RAG、多样本ICL等五类任务,并提供多种图像类型。所有样本均以8K-128K Token的五种标准化输入长度提供。通过对46个闭源和开源LCVLM的基准测试,研究发现单一任务性能不能代表整体长上下文能力,当前模型仍有很大改进空间,且推理能力强的模型往往长上下文性能更好。 (来源: HuggingFace Daily Papers)
论文研讨:MatTools——材料科学工具的大语言模型基准测试: 一篇新论文提出了MatTools基准,用于评估大型语言模型(LLM)通过生成和安全执行基于物理的计算材料科学软件包代码来回答材料科学问题的能力。MatTools包含一个材料模拟工具问答(QA)基准(基于pymatgen,含69225个QA对)和一个真实世界工具使用基准(含49个任务,138个子任务)。对多种LLM的评估揭示:通用模型优于专业模型;AI更懂AI;简单方法更有效。 (来源: HuggingFace Daily Papers)
论文研讨:一种通用共生水印框架,平衡LLM水印的鲁棒性、文本质量和安全性: 针对现有大型语言模型(LLM)水印方案在鲁棒性、文本质量和安全性之间存在的权衡问题,一篇新论文提出了一种通用的共生水印框架。该框架集成了基于logits和基于采样的方法,并设计了串行、并行和混合三种策略。混合框架利用Token熵和语义熵自适应嵌入水印,旨在优化各方面性能。实验表明,该方法优于现有基线并达到SOTA水平。 (来源: HuggingFace Daily Papers)
论文研讨:CheXGenBench——合成胸片的保真度、隐私和效用统一基准: 一篇新论文介绍了CheXGenBench,一个用于评估合成胸片生成的多方面框架,同时评估保真度、隐私风险和临床效用。该框架包含标准化的数据分区和统一的评估协议(超过20个量化指标),分析了11种领先文本到图像架构的生成质量、潜在隐私漏洞和下游临床适用性。研究发现现有评估协议在评估生成保真度方面存在不足。团队同时发布了高质量合成数据集SynthCheX-75K。 (来源: HuggingFace Daily Papers)
经典教材《泛函分析》作者Peter Lax逝世,享年99岁: 应用数学巨匠、首位获得阿贝尔奖的应用数学家Peter Lax逝世,享年99岁。Lax以其编著的经典教材《泛函分析》闻名,并在偏微分方程、流体力学、数值计算等领域做出奠基性贡献,如Lax等价定理、Lax-Friedrichs和Lax-Wendroff方法等。他也是最早将计算机技术应用于数学分析的先驱之一,其工作深刻影响了计算机时代的数学发展。 (来源: 量子位)

前OpenAI华人VP翁荔万字长文《Why We Think》,探讨测试时计算与思维链: 前OpenAI华人副总裁翁荔(Lilian Weng)发表万字长文《Why We Think》,深入探讨了“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought, CoT)等技术如何显著提升大型语言模型的性能和智能水平。文章类比人类思考的“快思慢想”双系统理论,指出让模型在输出前进行更多“思考”(如通过智能解码、CoT推理、潜变量建模等)能够突破当前能力瓶颈。文中详细梳理了基于Token的思考、并行采样与顺序修订、强化学习与外部工具整合、思维忠实性及连续空间思维等多个研究方向的进展和挑战。 (来源: 量子位)

哈工大与宾大联合推出PointKAN,基于KANs的点云分析新SOTA: 哈尔滨工业大学(深圳)与宾夕法尼亚大学的研究团队推出了PointKAN,一种基于Kolmogorov-Arnold Networks (KANs) 的3D点云分析解决方案。该方法通过几何仿射模块和并行局部特征提取模块,并利用可学习激活函数替代传统MLP中的固定激活函数,以更有效地捕捉点云的复杂几何特征。同时,团队提出了Efficient-KANs结构,通过有理函数替代B样条函数并进行组内参数共享,显著降低了参数量和计算开销。实验表明,PointKAN及其轻量版PointKAN-elite在分类、部分分割和小样本学习等任务上均取得了SOTA或有竞争力的表现。 (来源: WeChat)

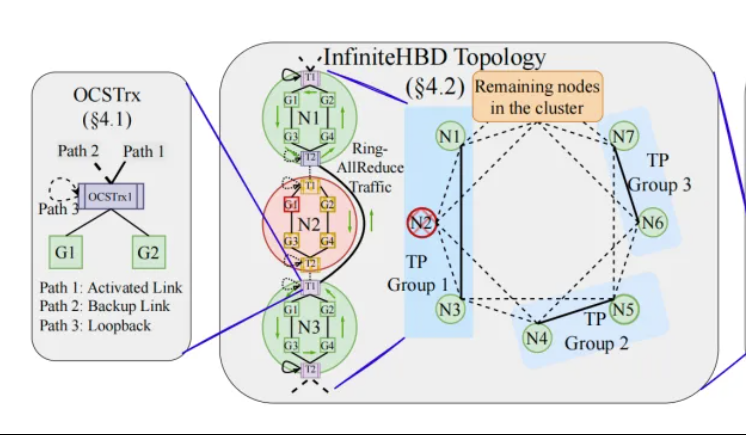
北大/阶跃/曦智提出InfiniteHBD:新一代高带宽GPU互联架构,降低大模型训练成本: 北京大学、阶跃星辰和曦智科技的研究团队针对当前大模型分布式训练中高带宽域(HBD)架构的局限性,提出了InfiniteHBD方案。该架构以嵌入了光路交换(OCS)能力的光电转换模组为核心,实现了动态可重构的点对多点连接,具备节点级故障隔离和低资源碎片化能力。研究表明,InfiniteHBD的单位成本仅为NVIDIA NVL-72的31%,GPU浪费率接近零,MFU(模型FLOPs利用率)相比NVIDIA DGX最高可提升3.37倍。该研究已被SIGCOMM 2025接收。 (来源: WeChat, 量子位)
ICML 2025论文速递:OmniAudio从360°视频生成空间音频: 一项将在ICML 2025发表的研究提出了OmniAudio框架,能够直接从360°全景视频生成具有方向感的一阶环绕声(FOA)空间音频。该研究首先构建了大规模360°视频与空间音频配对数据集Sphere360。OmniAudio采用两阶段训练:首先进行自监督的从粗到细流匹配预训练,利用大规模非空间音频数据学习通用音频特征;然后结合双分支视频编码器(提取全局和局部视觉特征)进行有监督微调。实验结果显示,OmniAudio在客观和主观评估指标上均显著优于现有基线模型。 (来源: WeChat)

华为Selftok:基于反向扩散的自回归视觉分词器,统一多模态生成: 华为盘古多模态生成团队提出Selftok技术,一种创新的视觉Token化方案,通过反向扩散过程将自回归先验融入视觉Token,使像素流转化为严格遵循因果律的离散序列,旨在解决现有空间Token方案与自回归(AR)范式冲突的问题。Selftok Tokenizer采用双流编码器(图像分支继承SD3 VAE,文本分支为可学习连续向量组)和带重激活机制的量化器。实验表明,Selftok在ImageNet重建指标上达到SOTA,基于昇腾AI和MindSpeed框架训练的Selftok dAR-VLM在GenEval等文生图基准上超越GPT-4o。该工作入选CVPR 2025最佳论文候选。 (来源: WeChat)
颜水成团队领衔发布General-Level评估框架与General-Bench基准,为多模态通才模型分级: 由新加坡国立大学颜水成教授、南洋理工大学张含望教授等领衔,十所顶尖高校联合发布了针对多模态通才模型的评估框架General-Level和大规模基准数据集General-Bench。该框架借鉴自动驾驶分级思路,设立五个等级(Level 1-5)来评估多模态大语言模型(MLLM)的通用性和性能,核心评估标准为“协同泛化效应”(Synergy),考察模型在任务间、理解与生成范式间、以及跨模态间的知识迁移与增强能力。General-Bench包含超700项任务和32万样本,对100多个现有MLLM的评测显示,多数模型处于L2-L3水平,尚无模型达到L5。 (来源: WeChat)

💼 商业
Sakana AI与三菱日联银行 (MUFG) 达成多年期合作伙伴关系: 日本AI初创公司Sakana AI宣布与日本最大的银行三菱日联银行 (MUFG Bank) 签署了多年的全面合作伙伴协议。Sakana AI将为MUFG银行提供敏捷且强大的AI技术,旨在助力这家拥有百年历史的银行在快速发展的AI领域保持竞争力。此项合作预计将帮助Sakana AI在一年内实现盈利。 (来源: SakanaAILabs, SakanaAILabs)

Cohere与戴尔合作,将其安全智能体平台Cohere North引入戴尔本地化企业AI解决方案: AI公司Cohere宣布与戴尔科技集团(Dell Technologies)达成合作,共同加速安全的、具备智能体能力的企业AI解决方案。戴尔将成为首个向企业提供Cohere安全智能体平台Cohere North的本地化(on-premises)部署方案的提供商。这一合作对于处理敏感数据、有严格合规要求的行业尤为关键,使得企业可以在自己的数据中心内部署和运行Cohere的先进AI智能体技术。 (来源: sarahookr)

Mistral AI与MGX、Bpifrance合作,在法国建设欧洲最大AI园区: Mistral AI宣布与阿布扎比支持的科技投资公司MGX以及法国国家投资银行Bpifrance合作,共同在法国巴黎地区建设欧洲最大的AI园区。该园区将整合数据中心、高性能计算资源、教育和研究设施。英伟达也将参与其中,提供技术支持。此举旨在推动欧洲AI生态系统的发展,并提升法国在全球AI领域的战略地位。 (来源: arthurmensch, arthurmensch)
🌟 社区
AI从业者中ADHD患病率引关注,或超20-30%: 社交媒体上出现关于AI领域从业人员中注意力缺陷多动障碍(ADHD)患病率的讨论。有用户观察到,该领域似乎吸引了许多具有神经多样性特征的人才。Minh Nhat Nguyen评论认为,AI行业中可能有超过20-30%的人患有ADHD。这一现象可能与AI研究和开发工作对高度专注、快速迭代和创造性思维的需求有关,这些特质有时与ADHD的某些表现相吻合。 (来源: Dorialexander)
AI时代技能贬值引深思,系统重构而非工具掌握是关键: 一篇深度分析文章指出,AI时代真正的危机并非“会不会用AI工具”,而是技能本身的贬值以及整个工作系统的重构。文章通过马奇诺防线、集装箱化、打字员被文字处理器取代等例子,论证了仅仅学习使用新工具无法保证领先,关键在于理解AI如何改变工作的结构、流程和组织逻辑。当系统被重写,原有高价值技能可能迅速边缘化。生产力的提升未必带来个体价值的提升,因为价值会流向控制新系统协调层的主体。文章驳斥了“学会AI就能领先”、“AI让我干更多活所以更有价值”、“工作岗位不变只是方式变了”等八大流行谬论,强调需要从系统层面思考自身定位和价值。 (来源: 36氪)
谷歌前CEO施密特:非人类智能崛起将重塑全球格局,需警惕AI风险与挑战: 谷歌前CEO埃里克·施密特在专访中警告,社会对“非人类智能”的颠覆性潜力认知严重不足。他认为AI已从语言生成迈向战略决策,能独立完成复杂任务。施密特强调了AI带来的三大核心挑战:能源与算力瓶颈(美国需新增90吉瓦电力)、公开数据已近枯竭(下一阶段需AI生成数据)、以及如何让AI超越人类既有知识创造“新知”。他还指出了三大风险:AI递归自我改进失控、获得武器控制权、未经授权的自我复制。他认为,在中美AI竞争加剧的背景下,开源AI的快速扩散可能带来安全风险,甚至引发类似“核威慑”的“先发制人”局面。施密特呼吁立即展开全球AI治理对话,并强调在系统设计初就应内嵌对人类自由的保护。 (来源: 36氪)

GitHub CEO反驳“编程无用论”,强调人类程序员在AI时代依然重要: 针对英伟达CEO黄仁勋等人提出的“未来不再需要学习编程”的观点,GitHub CEO托马斯·多姆克在采访中表示反对。他认为2025年将是编程智能体(SWE Agent)之年,但人类程序员的角色依然关键。多姆克强调,AI应作为增强开发者能力的助手,而非完全取代。他构想未来软件开发将演变为人与AI协作的模式,开发者如同“智能体乐队指挥”,负责分配任务和审核成果。GitHub CPO马里奥·罗德里格斯也表示,公司致力于用Copilot增强个人能力。他们认为,随着AI发展,理解如何编程和重编程能够代表人类思考和行动的机器至关重要,放弃学习代码等于放弃在智能体未来的话语权。 (来源: 36氪, 量子位)

AI生成低质漏洞报告泛滥,curl创始人引入过滤机制抵制“AI垃圾”: curl项目创始人Daniel Stenberg表示,由于收到大量由AI生成的低质量、无效漏洞报告,已不堪其扰,这些报告浪费了维护人员大量时间,形同DDoS攻击。为此,HackerOne上提交curl相关安全报告时,新增了询问是否使用AI的复选框。若回答为是,则需提供额外证据证明漏洞真实性,否则报告者可能被封禁。Stenberg称项目从未收到过有效的AI生成bug报告。Python开发者Seth Larson也曾表达类似担忧,认为此类报告给维护者带来困惑、压力和沮丧,加剧了开源项目的倦怠问题。社区讨论认为,AI生成报告的泛滥反映了信息过载和部分人试图利用漏洞赏金机制的问题,甚至有高层管理者被误导认为AI可替代资深程序员。 (来源: WeChat)

AI辅助编程引热议:效率提升显著,但人类开发者角色依然关键: 一位有数十年编程经验的开发者分享了被AI(可能是Codex或类似工具)在几分钟内解决困扰数小时的bug并优化代码的经历,感叹AI如同“永不疲倦的超能队友”。这一经历引发社区讨论。多数人认同AI在代码生成、bug修复、信息总结方面的强大能力,能显著提升效率。然而,也有开发者指出AI目前仍会犯错,尤其在复杂逻辑、边界条件和创造性解决方案上不及人类,且其输出需要有经验的开发者审查和批判性评估。微软CEO纳德拉亦强调AI是赋能工具,软件开发已离不开AI,但人类的雄心和能动性依然重要。讨论普遍认为,AI将改变编程方式,开发者需适应与AI协作的新范式,专注于更高层次的架构设计和问题定义。 (来源: Reddit r/ChatGPT, WeChat)
AI Agent Manus开放注册但定价高昂,面临国内外巨头竞争,中文版上线存疑: AI Agent平台Manus在经历邀请码热炒后正式开放注册,但目前仅面向海外用户,未提供中文版。用户反馈其采用积分消耗制,免费积分(注册送1000,每日300)仅够完成简单任务,复杂任务(如制作网页版数独游戏)需付费购买积分,平均1美元100积分,价格偏高。业内人士分析,Manus依赖第三方大模型(如海外版用Claude)导致成本较高,且云端沙盒运行也增加开销。中文版迟迟未上线可能与国内模型备案、用户付费习惯及市场竞争有关。字节跳动的Coze、百度的“心响”APP等国内外产品已形成竞争。Manus虽获新融资,但其“轻模型、重应用”模式的护城河面临考验。 (来源: 36氪)
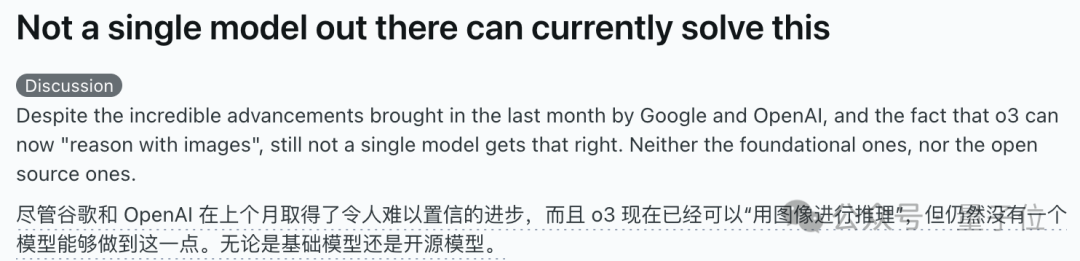
AI模型在“补全立方体”视觉推理题上集体翻车,引发对其真实理解能力的讨论: 一道要求计算补全一个不完整立方体所需小立方块数量的视觉推理题,难倒了包括OpenAI o3、Google Gemini 2.5 Pro、DeepSeek、Qwen3在内的多个主流AI模型。各模型给出的答案不一,主要原因在于对最终大立方体规格(如3x3x3、4x4x4、5x5x5)的理解不同。即使通过提示引导,模型也难以一次性正确解答。有网友指出,问题本身表述可能存在歧义,人类也会对此感到困惑。这一现象引发了关于AI模型是真正理解问题还是仅依赖模式匹配的讨论,凸显了当前AI在复杂空间推理和视觉理解方面的局限性。 (来源: 36氪)
用户讨论LLM在指令遵循与推理中的“过思考”问题: 社交媒体及论文讨论指出,大型语言模型(LLM)在使用链式思考(CoT)等推理过程时,有时会“思考过度”,反而导致无法准确遵循简单指令。例如,在被要求写特定字数或重复特定短语时,CoT可能使模型更关注任务的整体内容而忽略这些基本约束,或引入额外的解释性内容。研究者提出了“约束注意力”指标来量化此现象,并测试了情境学习、自我反思、自选择推理和分类器选择推理等缓解策略。这表明,并非所有任务都适合CoT,简单指令可能需要更直接的执行方式。 (来源: menhguin, omarsar0)

AI经济学反思:廉价认知劳动打破传统经济模型,价值分配面临重塑: 一篇引发讨论的观点认为,AI的崛起正使认知劳动(如报告撰写、数据分析、代码编写)变得极其廉价,这从根本上挑战了以“人类智能稀缺且昂贵”为核心假设的经典经济学模型。当AI能以近乎零边际成本完成大量知识工作时,生产力可能飙升,但单任务价值将暴跌,专业化优势被侵蚀。价值分配将不再简单依据效率或产出,而是取决于谁控制了新的稀缺资源(如数据、平台、AI模型本身)。这类似于历史上技术变革(如快时尚之于服装业、流媒体之于音乐业)中,效率提升的红利并未完全流向劳动者,而是被系统协调者获取。文章警示,AI不仅自动化任务,更在商品化“思考”,这可能是现代经济史上最具颠覆性的力量。 (来源: Reddit r/artificial)
AI时代企业战略:避免“智能公司”陷阱,需重构而非优化旧流程: 许多企业在采纳AI时,倾向于将其作为优化现有流程、降本增效的工具,陷入“更聪明地做同样的事”的“智能公司”陷阱。然而,真正的变革并非让旧流程更智能,而是思考这些流程是否还有存在的必要,并构建全新的、AI原生的系统和商业模式。技术不会简单适应旧系统,而是会重塑系统。企业应避免在即将被AI淘汰的流程上投入过多资源进行优化,而应着眼于定义新规则,从根本上改变决策方式、协调机制和组织架构。 (来源: 36氪)
💡 其他
LangChain纽约线下交流活动: LangChain宣布将于5月22日(星期四)在纽约与Tabs和TavilyAI共同举办线下交流活动。活动内容包括炉边谈话、产品演示以及与其他构建者的交流环节。 (来源: hwchase17, LangChainAI)

全球AI大会东京站将于6月举办: 一场名为“全球AI大会·东京站”的活动计划于6月7日至8日在日本东京举行。届时将有众多知名的AI开发者、艺术家、投资人等参与。对AI领域感兴趣并计划前往日本的人士可以关注相关报名信息。 (来源: op7418)

AI服务架构范式正从“模型即服务”向“Agent即服务”迁移: 随着AI技术发展,AI服务架构正经历从“模型即服务”(MaaS)向“Agent即服务”(AaaS)的深刻跃迁。AI Agent以其目标驱动、环境感知、自主决策和学习能力,超越了传统AI模型被动执行指令的模式。它们能够独立思考、拆解任务、规划路径,并调用外部工具完成复杂目标。这一转变促使产业链从底层基础设施(算力、数据)、核心算法与大模型,到中间层Agent组件与平台,再到终端产品应用(通用型、垂直行业、嵌入式Agent)的全面发展。中国AI Agent企业如HeyGen、来也科技、波形智能等也积极出海,探索海外市场。尽管面临算力成本高昂、供给不足等挑战,但通过算法优化、专用芯片、边缘计算等方案,AI Agent的潜力正不断被释放。 (来源: 36氪)