
关键词:AI编程智能体, Codex, AlphaEvolve, AI推理范式, MoE模型, AI芯片, AI教育, AI短剧, OpenAI Codex-1模型, 谷歌DeepMind AlphaEvolve, 字节跳动Seed1.5-VL, Qwen ParScale技术, 英伟达GB300系统
🔥 聚焦
OpenAI发布云端AI编程智能体Codex,由新模型codex-1驱动: OpenAI推出云端AI编程智能体Codex,基于为软件工程优化的o3特调版本codex-1。Codex能在云端沙盒安全并行处理多任务,与GitHub集成可直接调用代码库,实现快速构建模块、解答代码库问题、修复漏洞、提交PR及自动测试验证。过去数天或数小时的任务,Codex可在30分钟内完成。该工具已向ChatGPT Pro、Enterprise和Team用户开放,旨在成为开发者的“10x工程师”,重塑软件开发流程。 (来源: 36氪)
谷歌DeepMind推出AlphaEvolve,AI自主进化实现数学和算法突破: 谷歌DeepMind的AI系统AlphaEvolve通过自我进化和训练大语言模型,在多个数学和科学领域取得突破。它改进了4×4矩阵乘法算法(56年来首次),优化了六边形填充问题(16年来首次),并推进了“接吻数问题”。AlphaEvolve能自主优化算法,甚至找到了加速Gemini模型训练的方法,并已应用于优化谷歌内部计算基础设施,节省了0.7%的计算资源。这标志着AI不仅能解决问题,还能发现新知识,有望颠覆科研范式,实现AI创造科学。 (来源: 36氪)
奥特曼红杉AI峰会演讲:AI将在三年内进入现实世界,重塑生活与工作: OpenAI CEO奥特曼在红杉AI峰会上预测,2025年AI智能体将实用化(尤其编码领域),2026年AI将推动重大科学发现,2027年机器人将进入物理世界创造价值。他回顾了OpenAI从早期探索到ChatGPT诞生的历程,并提出未来AI产品将是“核心AI订阅”服务,能容纳个人全部人生经历,成为智能默认接口。OpenAI将专注于核心模型和应用场景,并保持“小团队、大责任”的组织效率。 (来源: 36氪)
英伟达Computex演讲:个人AI计算机投产,推下一代GB300系统,拟建台湾AI超算: 英伟达CEO黄仁勋在Computex 2025上宣布,个人AI计算机DGX Spark已全面投产,数周内上市;下一代AI系统GB300(配备72颗Blackwell Ultra GPU和36颗Grace CPU)将于Q3推出。英伟达将联合台积电、富士康在台建立AI超算中心。同时发布Blackwell RTX Pro 6000工作站系列和Grace Blackwell Ultra Superchip,并计划7月开源Newton物理引擎用于机器人训练。黄仁勋强调AI将无处不在,重申其革命性影响。 (来源: 36氪)

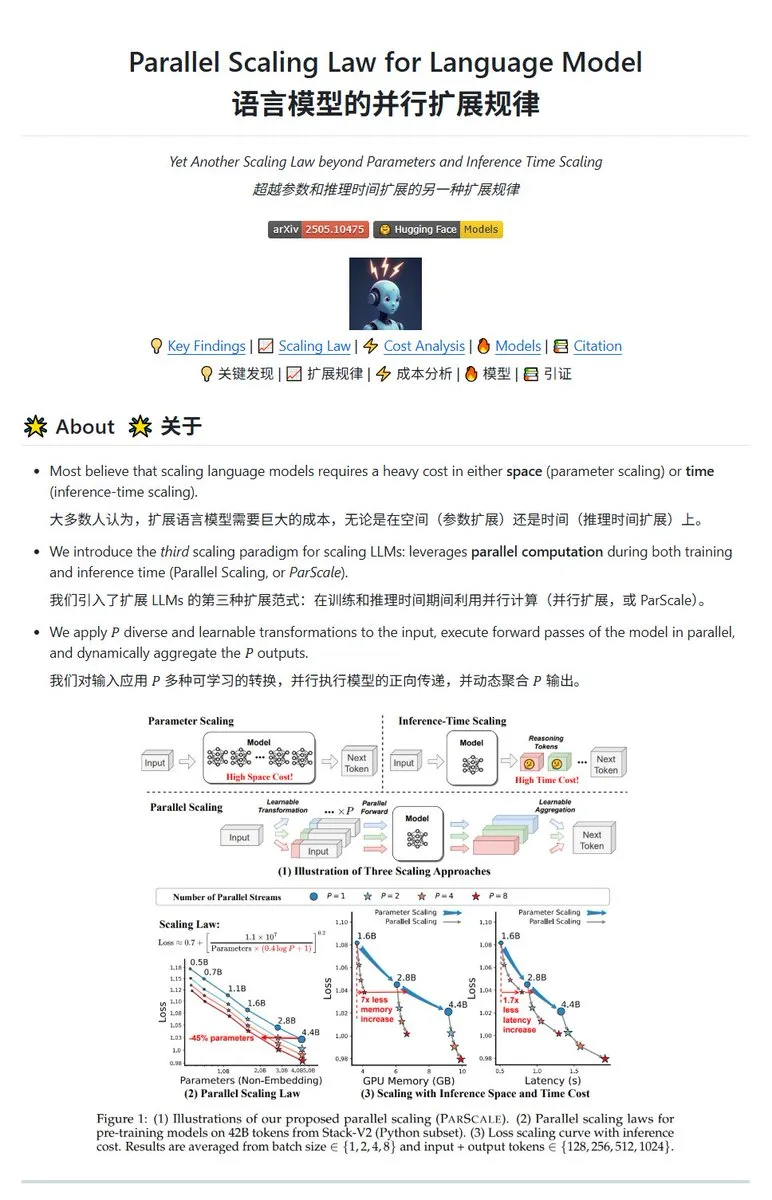
Qwen发布ParScale并行缩放技术,小模型可达大模型效果: Qwen团队推出ParScale技术,通过并行推理提升模型能力。该方法使用n个并行流进行推理,每个流采用可学习的差异化变换处理输入,最后通过动态聚合机制合并结果。研究表明,P个并行流的效果近似于将模型参数量增加O(log P)倍,例如30B模型通过8个并行流可达42.5B模型的效果。此技术有望在不显著增加显存占用的情况下提升模型性能,或通过增加并行度来缩小现有模型规模,但可能以增加计算需求和降低推理速度为代价。 (来源: karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
🎯 动向
Poe报告:OpenAI与谷歌领跑AI竞赛,Anthropic显颓势: Poe最新使用报告(2025年1-5月)显示,AI市场格局剧变。文本生成领域GPT-4o(35.8%)领先,Gemini 2.5 Pro在推理能力上(31.5%)登顶。图像生成由Imagen3、GPT-Image-1和Flux系列主导。视频生成领域Kling-2.0-Master异军突起,Runway份额大幅下降。智能体方面,o3表现最佳。报告指出,推理能力成为关键战场,Anthropic的Claude市场份额有所下滑,而DeepSeek R1用户占比也从高峰回落。企业需关注模型在复杂任务上的准确性和可靠性,并灵活选择AI模型。 (来源: 36氪)

Meta旗舰AI模型Behemoth(Llama 4)发布推迟,或引发AI战略调整: 据报道,Meta原计划4月发布的2万亿参数大模型Behemoth(Llama 4)因性能未达预期已推迟至秋季或更晚。该模型使用30T多模态token在32K GPU上预训练,旨在与OpenAI、谷歌等抗衡。开发困境引发内部对Llama 4团队表现的失望,并可能导致AI产品团队调整。同时,Llama 1初始团队14人中已有11人离职。Meta高管否认了“80%团队辞职”的传言,强调离职者主要来自Llama 1论文团队。此事件加剧了外界对Meta在AI竞赛中是否陷入瓶颈的担忧。 (来源: 36氪)

字节跳动与谷歌DeepMind发布新MoE模型研究,聚焦效率与生产系统应用: 字节跳动论文《MegaScale-MoE: Large-Scale Communication-Efficient Training of Mixture-of-Experts Models in Production》介绍了一种专为高效训练大规模MoE模型设计的生产系统,通过在算子层面将通信与计算重叠,实现了1.88倍于Megatron-LM的效率提升,并已部署于其数据中心训练产品模型(如Internal-352B,32专家,top-3)。谷歌DeepMind发布AlphaEvolve,通过AI自我进化和训练LLM,在数学和算法领域取得突破,例如改进4×4矩阵乘法和六边形填充问题,显示AI在科学发现上的潜力。 (来源: teortaxesTex, 36氪)

OpenAI探讨AI推理范式,强调其对性能提升的关键作用: OpenAI研究员Noam Brown指出,AI发展已从预训练范式(通过海量数据预测下一个词)进入推理范式。预训练成本高昂,而推理范式通过增加模型“思考”时间(推理计算量)来提升答案质量,即使训练成本不变。例如,o系列模型在数学竞赛(AIME)和博士级科学问题(GPQA)上,通过更长的推理时间获得了远超GPT-4o的准确率。OpenAI首席经济学家Ronnie Chatterji则讨论了AI对企业格局的重塑,认为关键在于企业如何整合AI增强或取代人类角色,以及AI技术如何嵌入价值链。 (来源: 36氪)

谷歌CEO皮查伊回应“谷歌已死论”,强调AI驱动的搜索进化与基础设施优势: 谷歌CEO桑达尔·皮查伊在专访中回应了关于“谷歌搜索被AI取代”的担忧,表示谷歌正通过“AI概览”和“AI模式”等功能,将搜索从响应式查询转变为预测性、个性化的智能助手。他强调谷歌在AI基础设施(自研TPU、大规模数据中心)和模型效率上的长期投入是核心优势,能以高性价比提供先进模型。皮查伊认为AI是“全场景技术平台”,将重塑搜索、YouTube、Cloud等核心业务,并催生新形态。他还提及中国AI(如DeepSeek)的竞争力不容忽视,并指出电力将是AI发展的关键瓶颈。 (来源: 36氪)

AI在教育领域的应用初创公司盘点: 文章盘点了13家在2025年值得关注的AI教育初创公司,它们通过个性化学习路径、智能辅导系统、自动评分和沉浸式内容创建等方式改变教学。例如,Merlyn是声控AI助手,减轻教师行政负担;Brisk Teaching是Chrome扩展,简化教学任务;Edexia是AI评分平台,学习教师风格;Storytailor结合书目疗法与AI创作个性化故事;Brainly提供AI增强的作业辅导。这些公司展示了AI在教育领域的广泛应用潜力,从提高效率到实现个性化学习和教育公平。 (来源: 36氪)
AI短剧面临技术与商业化挑战,制作效果与预期存差距: 尽管AI工具有望降低短剧制作成本、缩短周期,但从业者发现AI短剧在主体一致性、口型同步、镜头语言自然度等方面存在显著技术难题,导致许多作品更像“PPT式短剧”。AI难以理解超现实创意,限制了奇幻、科幻题材的发挥。目前AI技术更适合制作短片而非完整短剧,商业化前景不明。大型影视公司如博纳影业、华策集团凭借资源优势更有可能突围,而多数小型创作者面临试错成本高、技术迭代快导致作品迅速过时等问题。 (来源: 36氪)
MSI推出集成NVIDIA GB10超级芯片的AI PC,含6144 CUDA核心和128GB LPDDR5X内存: MSI展示了其EdgeExpert MS-C931 S,一款搭载NVIDIA GB10超级芯片的AI PC。该芯片确认拥有6144个CUDA核心和128GB LPDDR5X内存。这是继ASUS、Dell和Lenovo之后,又一家推出基于NVIDIA DGX Spark架构的个人AI计算机的厂商。此类产品的推出标志着高性能AI计算能力正逐步向个人和边缘设备普及,但也有评论指出其定价可能使其难以与Mac Mini等产品竞争。 (来源: Reddit r/LocalLLaMA)
Qwen3-30B在VLLM上实现高吞吐量,适用于数据集管理: Qwen3-30B-A3B模型在VLLM框架和RTX 3090s显卡上展现出色的推理速度(5K t/s预填充,1K t/s生成),使其非常适合用于数据集过滤和管理等任务。尽管相较于QwQ可能略有回归,但其速度优势使其在数据处理方面更为实用。目前存在的主要问题是训练速度极慢,但Hugging Face Transformers库中已有PR尝试解决此问题,未来有望基于Qwen3-30B推出改进数据集的RpR模型。 (来源: Reddit r/LocalLLaMA)
B站开源动画视频生成模型Index-AniSora,支持多种二次元风格: B站推出了专为二次元视频生成的开源模型Index-AniSora,基于其AniSora技术框架(已被IJCAI25接收)。该模型能将漫画一键生成动画,支持番剧、国创、漫改、VTuber等多种风格。AniSora系统通过构建千万级高质量文本-视频对数据集,开发统一扩散生成框架并引入时空掩码机制,实现对角色口型、动作的精细控制。同时,B站设计了面向动画视频的评估基准和基于VLM优化的自动化评估系统。开源内容将包括AniSoraV1.0(基于CogVideoX-5B)、AniSoraV2.0(基于Wan2.1-14B,支持华为910B训练)及相关数据集构建和评估工具。 (来源: WeChat)

字节跳动发布视觉语言模型Seed1.5-VL,多模态任务表现优异: 字节跳动推出了由532M参数视觉编码器和20B活动参数的混合专家(MoE)LLM组成的视觉语言模型Seed1.5-VL。该模型在60个公共基准测试中的38个上达到了SOTA性能,并在GUI控制和游戏玩法等以代理为中心的任务上超越了OpenAI CUA和Claude 3.7等领先系统,展现了强大的多模态理解与推理能力。 (来源: WeChat)
Nous Research推出Psyche Network,实现40B参数LLM分布式预训练: Nous Research发布Psyche Network,一个基于DeepSeek V3 MLA架构的去中心化训练网络,首次测试即对400亿参数大语言模型进行预训练。该网络利用DisTrO优化器和自定义点对点网络堆栈,整合全球分布式GPU算力,允许个人和小团体在单个H/DGX上训练,并在3090 GPU上运行。此举旨在打破科技巨头的算力垄断,使大规模模型训练更易于获取。 (来源: 量子位)

🧰 工具
Sim Studio:开源AI智能体工作流构建器: Sim Studio是一个开源的、轻量级的AI智能体工作流构建平台,提供直观的界面,用户可以快速构建和部署连接各种工具的LLM应用。支持云托管版本和自托管(推荐Docker环境,支持本地模型如Ollama)。其技术栈包括Next.js、Bun、PostgreSQL、Drizzle ORM、Better Auth、Shadcn UI、Tailwind CSS、Zustand、ReactFlow和Turborepo。 (来源: GitHub Trending)

Cherry Studio:功能全面的开源LLM前端桌面应用受关注: Cherry Studio是一款开源LLM前端桌面应用,集成了RAG、网页搜索、本地模型(通过Ollama, LM Studio连接)及云模型(如Gemini, ChatGPT)访问等多种功能。用户反馈其MCP(多控制协议)支持和管理优于Open WebUI和LibreChat,且易于安装设置。应用还支持直接连接Obsidian知识库。尽管一些用户对其来源表示担忧,但其全面的功能集使其成为一个有吸引力的选择。 (来源: Reddit r/LocalLLaMA)

MLX-LM-LoRA:为MLX模型添加LoRA并支持多种训练方法: 开源项目mlx-lm-lora使得用户可以为Apple MLX框架下的模型集成LoRA(Low-Rank Adaptation)模块。该项目不仅支持LoRA的添加,还内置了ORPO、DPO、CPO、GRPO等多种对齐训练方法,方便用户根据自己的需求微调模型,生成定制化的LoRA模块,并将其应用于偏好的MLX模型中。 (来源: karminski3)
DeepDrone:基于Qwen的AI控制无人机项目开源: 一位开发者基于Qwen大模型创建了名为DeepDrone的AI控制无人机项目,并在HuggingFace和GitHub上开源。该项目展示了将大型语言模型应用于无人机自主控制的潜力,引发了关于AI在自动化和潜在军事应用方面的讨论。 (来源: karminski3)
Qwen Web Dev:一键提示生成并部署网站: 阿里巴巴Qwen团队宣布其Qwen Web Dev工具得到增强,用户仅需通过一个提示(prompt)即可生成一个网站,并能一键部署。该工具旨在降低网页开发门槛,让用户能更便捷地将创意转化为实际可访问的网站,并与世界分享。 (来源: Alibaba_Qwen, huybery)
SuperGo.AI:集成八种LLM模型的单一界面工具: AI爱好者开发了一款名为SuperGo.AI的工具,它在一个界面中集成了八个不同角色的LLM(如AI超级大脑、AI想象力、AI道德、AI宇宙等)。这些AI角色可以相互感知和互动,用户可以选择“创意”、“科学”和“混合”模式以获得混合响应。该工具旨在提供新颖的多AI协作体验,目前无付费墙。 (来源: Reddit r/artificial)
Kokoro-JS:实现无限量本地文本转语音(TTS): Kokoro-JS是一个100%本地运行、100%开源的文本转语音工具,通过在浏览器端下载一个约300MB的AI模型来实现。用户输入的文本不会发送到任何服务器,保证了隐私和离线可用性。该工具旨在提供无限制的TTS功能。 (来源: Reddit r/LocalLLaMA)
📚 学习
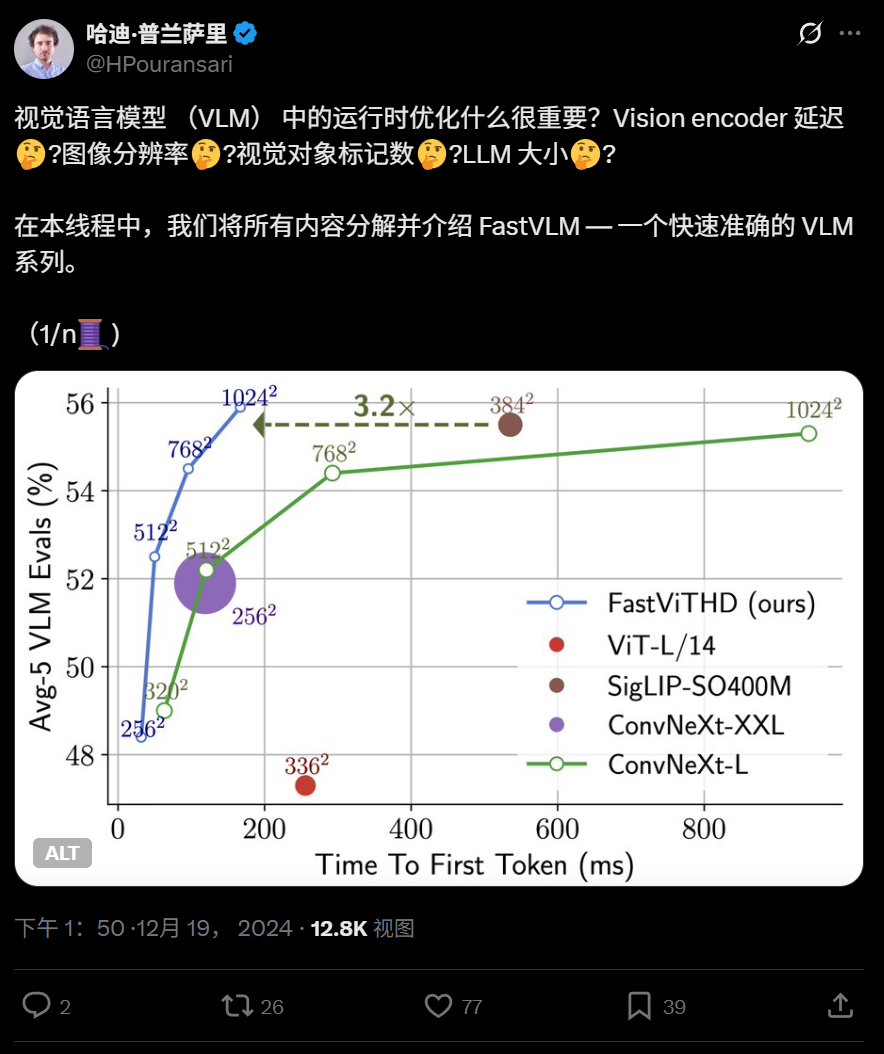
苹果开源高效视觉语言模型FastVLM,优化端侧运行: 苹果公司开源了FastVLM,一款专为在iPhone等设备上高效运行而设计的视觉语言模型。FastVLM引入新型混合视觉编码器FastViTHD,结合卷积层与Transformer模块,并采用多尺度池化和下采样技术,显著减少处理图像所需的视觉token数量(比传统ViT少16倍),首个token输出速度提升85倍。该模型兼容主流LLM,并已提供基于MLX框架的iOS/macOS演示应用,适合边缘设备和实时图文任务。 (来源: WeChat)
哈工大与宾大提出PointKAN,基于KAN改进3D点云分析: 哈尔滨工业大学(深圳)与宾夕法尼亚大学的研究团队推出PointKAN,一种基于Kolmogorov-Arnold Networks (KANs) 的3D感知新架构。PointKAN通过可学习激活函数替代传统MLP中的固定激活函数,增强了学习复杂几何特征的能力。其包含几何仿射模块和并行局部特征提取模块。团队还提出了PointKAN-elite版本,采用Efficient-KANs结构,使用有理函数作基函数并分组共享参数,显著降低了参数量和计算复杂度,同时在分类、部分分割及小样本学习任务上表现出SOTA性能。 (来源: 量子位)

匹兹堡大学提出PhyT2V框架,提升AI生成视频的物理真实性: 匹兹堡大学智能系统实验室研发了PhyT2V框架,旨在提高文本到视频(T2V)模型生成内容的物理一致性。该方法无需重训练模型或大规模外部数据,通过大型语言模型(LLM)引导的链式推理(CoT)和迭代自我修正机制,对文本提示进行多轮物理规则分析与优化。PhyT2V能够识别物理规则、语义不匹配,并生成修正提示,从而增强主流T2V模型(如CogVideoX, OpenSora)在现实物理场景(固体、流体、重力等)中的泛化能力,尤其在分布外场景下效果显著,物理常识(PC)和语义遵守度(SA)指标最高提升2.3倍。 (来源: WeChat)
LLM最新研究速递:多模态、测试时对齐、Agent、RAG优化等: 一周LLM研究进展包括:1. 华盛顿大学提出QALIGN,一种无需修改模型或访问logits的测试时对齐方法,通过MCMC在文本生成中实现更优对齐。2. UCLA预训练Clinical ModernBERT,将生物医学领域编码器上下文长度扩展至8192 token。3. Skoltech提出基于外部信息(实体流行度、问题类型)的轻量级LLM独立自适应RAG检索方法。4. PSU定义LLM多Agent系统自动化故障归因问题,并开发评估数据集与方法。5. 复旦大学提出多维约束框架与自动化指令生成流程,提升LLM指令遵循能力。6. a-m-team开源AM-Thinking-v1 (32B),数学编码能力媲美DeepSeek-R1-671B。7. 小米推出MiMo-7B,通过优化预训练和后训练,在推理任务上表现优异。8. MiniMax提出MiniMax-Speech自回归TTS模型,支持32种语言零样本音色克隆。9. 字节跳动构建Seed1.5-VL视觉语言模型,在多模态任务和代理中心任务上表现突出。10. 全球首个32B参数语言模型INTELLECT-2实现分布式强化学习训练,提出PRIME-RL框架。 (来源: WeChat)
AAAI 2025研讨会关注神经推理、数学发现及AI加速科学工程: AAAI 2025的研讨会重点讨论了AI在科学领域的应用。其中,“神经推理与数学发现”研讨会强调黑盒神经网络可用于提出数学猜想和生成新几何图形,但也指出其无法达到符号级逻辑推理,并提倡跨学科方法。另一“AI加速科学与工程”研讨会(第四届,主题为AI生物科学)则聚焦于治疗设计的基础模型、药物发现的生成模型、实验室闭环抗体设计、基因组学中的深度学习以及生物应用中的因果推断等议题,并探讨了生成模型在生物科学中的挑战与机遇。 (来源: aihub.org)

谷歌与Anthropic在AI可解释性研究上现分歧,机制可解释性面临挑战: AI的“黑箱”特性导致其在许多关键领域应用受限。谷歌DeepMind近期宣布降低“机制可解释性”(mechanistic interpretability)研究的优先级,认为通过稀疏自编码器(SAE)等方法逆向工程AI内部机制面临诸多问题,如缺乏客观参照、概念覆盖不全、特征扭曲等,且现有SAE技术未能在关键任务中识别出所需“概念”。而Anthropic CEO Dario Amodei则主张加强该领域研究,并对未来5-10年实现“AI的核磁共振成像”表示乐观。这场争论凸显了理解和控制AI行为的深层挑战。 (来源: 36氪)

北大/阶跃/曦智提出InfiniteHBD:新一代GPU高带宽域架构降本增效: 针对现有高带宽域(HBD)架构在可扩展性、成本和容错性上的限制,北京大学、阶跃星辰和曦智科技团队提出InfiniteHBD架构。该架构以光交换模组(OCSTrx)为中心,通过在光电转换模组中嵌入低成本光交换(OCS)能力,实现数据中心规模的动态可重配置K-Hop Ring拓扑和节点级故障隔离。InfiniteHBD的单位成本仅为NVL-72的31%,GPU浪费率近乎零,MFU(模型FLOPs利用率)相比NVIDIA DGX最高提升3.37倍,为大规模大模型训练提供了更优的解决方案。论文已被SIGCOMM 2025接收。 (来源: WeChat)

OceanBase发布PowerRAG,全面拥抱AI,构建Data×AI一体化数据底座: OceanBase在开发者大会上发布了面向AI的应用产品PowerRAG,旨在提供开箱即用的RAG开发能力,打通数据、平台、接口与应用层。CTO杨传辉详解了OceanBase的AI战略:构建Data×AI能力,从一体化数据库向一体化数据底座演进。OceanBase将增强向量能力、提升融合检索、实现企业知识存储动态更新、深度整合模型后训练与微调,并已适配Dify、FastGPT等主流Agent平台及MCP协议。其向量性能在VectorDBBench测试中表现领先,并通过BQ量化算法大幅降低内存需求。 (来源: WeChat)

💼 商业
上海国投系基金投资芯耀辉、燧原科技、壁仞科技等AI芯片公司: 上海国有资本投资有限公司(上海国投)近期与三家半导体公司芯耀辉、燧原科技、壁仞科技签署投资协议,此前其先导AI母基金已领投壁仞科技IPO前融资。上海国投表示将积极布局基础模型、算力芯片、具身智能等赛道。芯耀辉专注于半导体IP,特别是Chiplet技术,其创始人曾克强曾任新思科技中国区副总。燧原科技和壁仞科技均为GPU芯片设计公司。此举显示上海国投在AI产业链上游,特别是算力芯片领域的重点布局。 (来源: 36氪)
Sakana AI与三菱UFJ银行达成全面合作伙伴关系,开发银行专用AI: 日本AI初创公司Sakana AI宣布与三菱UFJ银行(MUFG)签订为期多年的合作伙伴协议。Sakana AI将为MUFG开发专门针对银行业务的AI代理,旨在推动银行业务的变革和AI的实际应用。同时,Sakana AI的联合创始人兼COO伊藤錬将担任MUFG的顾问,协助该行实施AI战略。此合作标志着Sakana AI将先进AI技术应用于解决日本金融行业具体课题的重要一步。 (来源: SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs, SakanaAILabs)

零一万物联创谷雪梅离职创业,公司业务重心转向B端: 零一万物联合创始人、负责模型预训练和C端产品的谷雪梅已于数月前离职,近期正筹备创业。零一万物确认此事并感谢其贡献。自2025年以来,零一万物业务重心已从AI ToC应用和模型API转向数字人、模型定制与部署等B端场景。其C端产品如国内版办公工具“万知”因用户量不及预期已停止运营,海外角色扮演产品Mona商业化亦不理想。此前,联合创始人戴宗宏也已离职创业。 (来源: 36氪)

🌟 社区
AI论文AIGC检测引争议,准确性受质疑,学生毕业受影响: 今年许多高校引入AIGC检测作为毕业论文审核环节,旨在防止学生滥用AI写作。然而,该举措引发广泛争议。学生反映,自己撰写的内容常被误判为AI生成,而AI辅助修改后疑似度反而上升。甚至有测试显示《滕王阁序》AI生成疑似度高达99.2%。AIGC检测工具本身也由AI驱动,其原理是分析文本语言特征与AI写作模式对比,但准确性堪忧,OpenAI早期工具准确率仅26%。这种不确定性不仅给学生带来困扰和额外花费(不同检测网站结果各异,降重服务收费),也引发了对AI工具本质的反思:AI模仿人类写作,再用AI检测人类文章是否像AI,本身存在逻辑悖论。 (来源: 36氪)

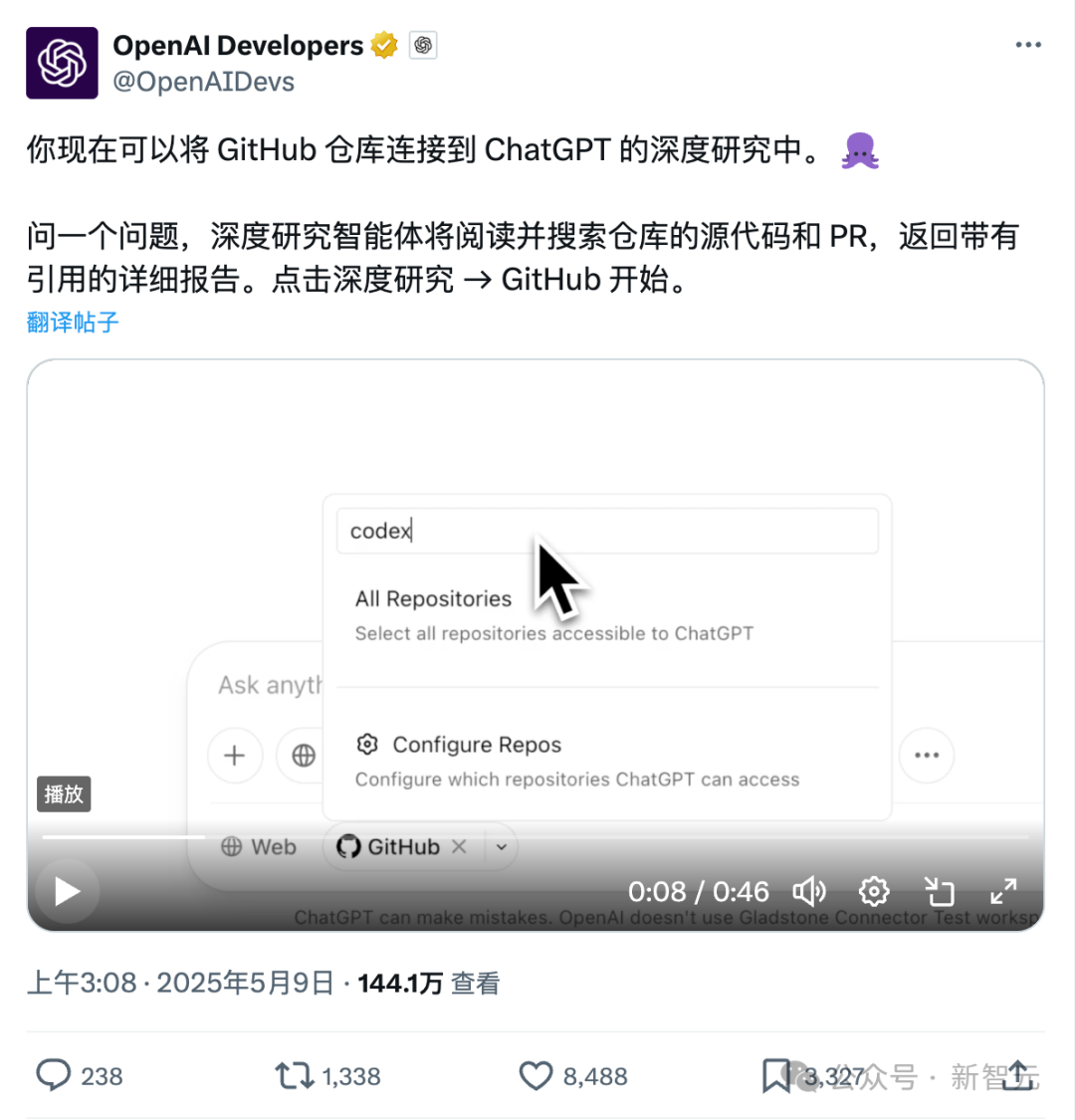
ChatGPT直连Github新功能:深度研究代码库与专业文档: ChatGPT近期上线的Deep Research功能新增了直连Github仓库的能力,用户可授权ChatGPT访问其公开或私有仓库,进行深度代码分析、功能架构总结、技术栈识别、代码质量评估及项目适用性分析等。此功能不仅限于代码,用户可上传PDF、Word等各类文档至Github仓库,利用ChatGPT进行特定领域资料的深度研究,相当于实现了限定范围的RAG+MCP组合。该功能目前向Plus用户开放,通过限定研究范围,有望提升研究报告的专业性和准确性,减少幻觉。 (来源: 36氪)
AI Agent市场竞争加剧,Manus全面开放注册,字节百度等大厂入局: 被称为“全能Agent”的Manus于5月12日宣布全面开放注册,用户无需等待即可获得使用份额。同时,市场传闻Manus正以15亿美元估值进行新一轮融资。自3月发布以来,Manus引发了Agent类项目热潮,但也面临流量下滑和竞品涌现的挑战。字节跳动推出Coze Space,百度上线“秒哒”和“心响”,设计Agent Lovart也开启测试。Agent市场正从早期概念验证转向产品功能、商业模式和用户增长的全方位竞争。 (来源: 36氪)
AI辅助编码改变开发者工作流,提高生产力但需警惕过度依赖: Reddit用户分享了AI代码助手如何显著改变其编码体验,尤其在处理大型遗留项目和理解复杂代码方面。AI工具能逐行解释代码、提供建议、高亮潜在问题、总结文件、查找片段和生成注释,如同拥有全天候专家指导。评论指出,AI能完成重复性编码、提高效率、引导新方法、添加注释,甚至帮助开发者完成超出其能力范围的任务,将数天工作缩短至数小时。然而,这也引发了关于开发者技能演变和对AI工具依赖性的思考。 (来源: Reddit r/artificial)
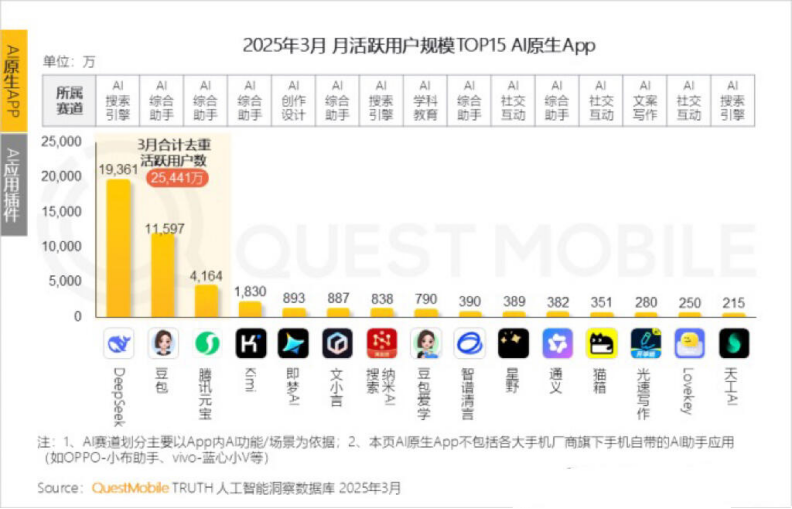
Kimi月活用户下滑,月之暗面寻求垂类突破与社交化转型: 月之暗面旗下Kimi Chat在QuestMobile数据中月活从去年10月的3600万降至今年3月的1820万,排名滑落至第四。为提升用户留存,Kimi正从通用大模型向垂类领域拓展,如与财新传媒合作提升财经内容搜索质量,布局AI医疗搜索,并引入B站视频内容。同时,Kimi在小红书发起打卡挑战,试图通过社交平台触达更多C端用户。其用户界面也向多模态、类豆包和社区化方向调整。面对DeepSeek等竞争者及大厂纷纷入局AI应用,Kimi的技术领先定位受到冲击,商业化压力增大,正积极寻找新的增长点。 (来源: 36氪)
关于AI是否应以第一人称自称的讨论: Reddit用户发起讨论,认为ChatGPT等LLM以“我”或“你”来自称和称呼用户可能不妥,因其本质是“物”而非“人”,建议其使用第三人称如“ChatGPT会帮助您…”以避免给予用户其是人格化存在的印象,从而引发潜在的危险或伦理问题。评论中,有人认为第三人称反而暗示了自我意识,也有人觉得第三人称听起来愚蠢且令人不适。该讨论反映了用户对AI身份定位和人机交互方式的思考。 (来源: Reddit r/ArtificialInteligence)
💡 其他
MIT紧急撤稿一篇广受关注的AI论文,指数据和研究真实性存疑: 麻省理工学院(MIT)撤回了其经济系博士生艾丹·托纳-罗杰斯撰写的论文《人工智能、科学发现与产品创新》。该论文曾因提出AI工具能显著提升顶尖科学家创新效率,但可能加剧科研“贫富差距”并降低普通科研人员幸福感而备受关注,并获诺奖得主等知名教授赞赏。MIT声明称,在收到研究诚信举报并进行内部调查后,对论文数据来源、可靠性、有效性及研究真实性失去信心,已要求arXiv和《经济学季刊》下架该文。作者已离开MIT,相关教授也发声明撇清关系。据称作者在调查期间购买假域名冒充大公司邮件,被识破并遭起诉。 (来源: 36氪)

AI生成图片被用于网络诈骗,引发用户警惕: Reddit用户分享了在Facebook等社交媒体上出现的利用AI生成的人物图片进行商品推广的案例,这些图片中的人物和场景往往存在不合逻辑之处(如模特进出方式诡异的箱子、背景中出现不相关人物等),但角色形象一致性较高。评论者指出,这类AI生成内容已被用于诈骗,提醒用户警惕。Pleasant Green等博主也制作过视频揭露此类骗局。 (来源: Reddit r/ChatGPT)
AI生成图片风格模仿与提取提示词探讨: 用户讨论了如何让AI模型(如DALL-E 3)模仿特定艺术风格(如皮克斯风格结合Designer Toy风格的萨尔瓦多·达利)创作人物画像,并分享了详细的提示词,强调了人物特征、背景、光影及核心概念(如影子作为精神投射)。此外,还有用户提供了用于从图片中提取风格参数并输出为JSON格式的提示词模板,旨在帮助用户反向工程图片风格,尽管精准还原仍有难度。 (来源: dotey, dotey)
