关键词:AI编程智能体, Codex, 语音大模型, AI Agent, OpenAI, MiniMax, 阿里巴巴, Qwen, Codex预览版, Speech-02语音模型, WorldPM研究, FastVLM视觉语言模型, FG-CLIP跨模态模型
🔥 聚焦
OpenAI发布AI编程智能体Codex预览版: OpenAI于5月16日深夜推出了基于云的软件工程智能体Codex的预览版。Codex由专为软件工程优化的o3变种模型codex-1驱动,能并行处理编程、代码库问答、Bug修复及提交拉取请求等任务。它在云端沙盒环境运行,预加载用户代码库,任务完成时间1-30分钟。目前已向ChatGPT Pro、Team和Enterprise用户开放,Plus和Edu用户即将上线。同时发布了轻量级模型codex-mini(基于o4-mini)用于Codex CLI,API定价输入1.5美元/百万token,输出6美元/百万token。 (来源: 36氪, 机器之心, op7418)
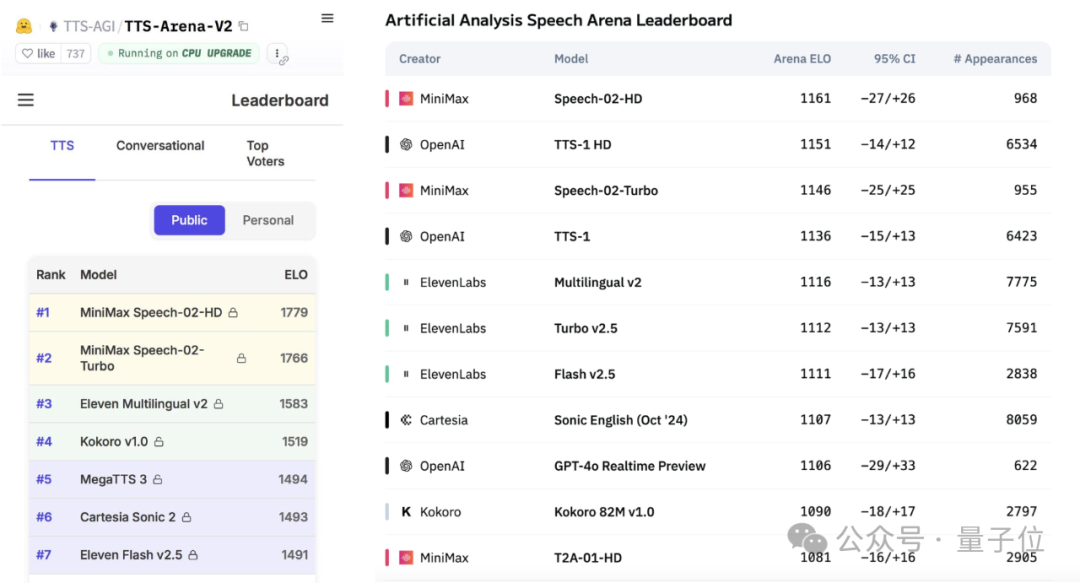
MiniMax发布Speech-02语音大模型,登顶全球测评榜: 国产AI公司MiniMax最新发布的文本转语音(TTS)大模型Speech-02-HD,在Artificial Analysis Speech Arena和Hugging Face TTS Arena V2两项全球权威语音基准测评中均获得第一名,超越了OpenAI和ElevenLabs。该模型具备超拟人、个性化和多样性特点,支持32种语言,最少10秒语音参考即可实现逼真音色复刻。此前大火的“AI吴彦祖”学英语应用即采用MiniMax技术。Speech-02的核心创新包括可学习说话者编码器和Flow-VAE流匹配模型,提升了音质和相似度。 (来源: 36氪, karminski3)
AI Agent引发市场关注,大厂加速布局: AI智能体(Agent)正成为AI领域的新焦点,Manus等通用型Agent平台开放注册引发热潮,其母公司Monica据称完成新一轮7500万美元融资,估值近5亿美元。百度(心响)、字节跳动(扣子空间)、阿里(心流)等大厂纷纷推出自家Agent产品或平台,争夺AI时代的入口。Agent能执行更复杂任务,如材料制作、网页设计、旅行规划等。目前通用Agent在跨应用操作和深度任务方面仍有不足,生态不完善、数据孤岛是主要挑战。MCP协议被视为解决互联互通的关键,但接入者尚少。B端垂直领域Agent因场景聚焦、易于定制,被认为更易率先实现商业化。 (来源: 36氪, 36氪)

阿里巴巴发布WorldPM研究,探索人类偏好建模的规模法则: 阿里巴巴Qwen团队发表论文《Modeling World Preference》,揭示人类偏好建模遵循规模法则(Scaling Laws),表明多样化的人类偏好可能共享统一的表示。研究使用包含1500万偏好对的StackExchange数据集,在1.5B至72B参数的Qwen2.5模型上进行实验。结果显示,偏好建模在客观和鲁棒性指标上随训练规模增加呈现对数损失减少;72B模型在某些挑战性任务上表现出涌现现象。该研究为偏好微调提供了有效基础,论文与模型(WorldPM-72B)均已开源。 (来源: Alibaba_Qwen)
🎯 动向
谷歌DeepMind与Anthropic在AI可解释性研究上现分歧: 谷歌DeepMind近期宣布不再将“机制可解释性”(mechanistic interpretability)作为研究重点,认为通过稀疏自编码器(SAE)等方法逆向工程AI内部运作的路径困难重重,且SAE存在固有缺陷。而Anthropic CEO Dario Amodei则主张加强该领域研究,并对未来5-10年实现“AI的核磁共振成像”表示乐观。AI的“黑箱”特性是许多风险的根源,机制可解释性旨在理解模型具体神经元和回路的功能,但十多年的研究成果有限,引发了关于研究路径的深刻反思。 (来源: WeChat)

Poe报告揭示AI模型市场格局变化,OpenAI与谷歌领跑: Poe最新AI模型使用报告显示,文本生成领域GPT-4o(35.8%)领先,推理领域Gemini 2.5 Pro(31.5%)登顶。图像生成由Imagen3、GPT-Image-1和Flux系列主导。视频生成Runway份额下降,快手Kling成黑马。智能体方面,OpenAI的o3在研究测试中表现优于Claude和Gemini。Anthropic的Claude市场份额有所下滑。报告指出,推理能力成为关键竞争点,企业需建立评估体系,灵活选用不同模型应对快速变化的市场。 (来源: WeChat)

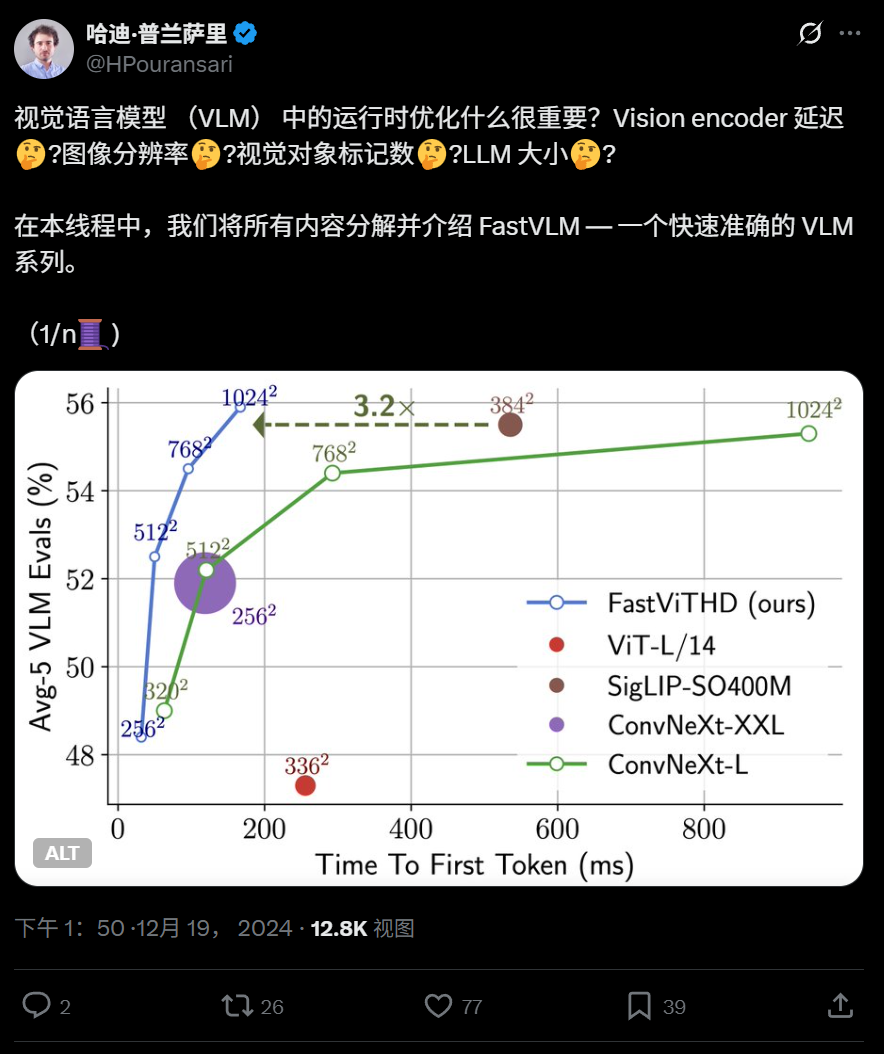
苹果开源高效视觉语言模型FastVLM,可在iPhone上运行: 苹果公司开源了FastVLM,一个专为在iPhone等端侧设备高效运行而设计的视觉语言模型。该模型通过新型混合视觉编码器FastViTHD(融合卷积层与Transformer模块,采用多尺度池化和下采样技术)显著减少了视觉token数量(比ViT少16倍),首个token输出速度相对同类模型提升85倍。FastVLM兼容主流LLM,并已发布0.5B、1.5B、7B参数版本,旨在提升端侧AI应用的图像理解速度和用户体验。 (来源: WeChat)
360发布新一代图文跨模态模型FG-CLIP,提升细粒度对齐能力: 360人工智能研究院研发了新一代图文跨模态模型FG-CLIP,旨在解决传统CLIP模型在图文细粒度理解上的不足。FG-CLIP采用两阶段训练策略:全局对比学习(整合多模态大模型生成的长描述)和局部对比学习(引入区域-文本标注数据和难细粒度负样本学习),从而实现对图像局部细节和文本细微属性差异的精准捕捉。该模型已在ICML 2025接收,并在Github和Huggingface开源,权重可商用。 (来源: WeChat)

谷歌推出LightLab,利用扩散模型精确控制图像光影: 谷歌研究团队发布了LightLab项目,该技术能够基于单张图像实现对光源的细粒度参数化控制。用户可以调整可见光源的强度、颜色,环境光的强度,并能将虚拟光源插入场景。LightLab通过在特制数据集(包含真实受控光照照片对和大规模合成渲染图像)上微调扩散模型实现,利用光的线性特性分离光源和环境光,合成大量不同光照变化的图像对进行训练。该模型能直接在图像空间模拟复杂照明效果,如间接照明、阴影和反射。 (来源: WeChat)

腾讯提出GRPO与RCS强化学习方法,提升意图检测泛化性: 腾讯PCG社交线研究团队提出采用分组相对策略优化(GRPO)算法结合基于奖励的课程采样策略(RCS)的强化学习方法,应用于意图识别任务。该方法显著提升了模型在未知意图上的泛化能力(在新意图和跨语言能力上提升高达47%),尤其在引入“思考(Thought)”后,复杂意图检测的泛化能力进一步增强。实验表明,RL训练的模型在泛化性上优于SFT模型,且无论基于预训练模型还是指令微调模型,GRPO训练后性能相近。 (来源: WeChat)

南洋理工等提出RAP框架,基于RAG提升高分辨率图像感知: 南洋理工大学陶大程教授团队等提出Retrieval-Augmented Perception (RAP),一种无需训练的基于RAG技术的高分辨率图像感知插件,旨在解决多模态大语言模型(MLLM)处理高分辨率图像时信息损失的问题。RAP通过检索与用户问题相关的图像块,并利用Spatial-Awareness Layout算法维持其相对位置关系,再通过Retrieved-Exploration Search (RE-Search)自适应选择保留的图像块数量K,有效降低输入图像分辨率同时保留关键视觉信息。实验表明,RAP在HR-Bench 4K和8K数据集上准确率分别提升高达21%和21.7%。该成果已被ICML 2025接收为Spotlight论文。 (来源: WeChat)

Qwen2.5-Omni-7B量化模型发布: 阿里巴巴Qwen团队发布了Qwen2.5-Omni-7B模型的量化版本,包括GPTQ和AWQ优化检查点。这些模型已在Hugging Face和ModelScope上线,旨在提供更高效、资源消耗更低的部署选项,同时保持其强大的多模态能力。 (来源: Alibaba_Qwen, karminski3, reach_vb)
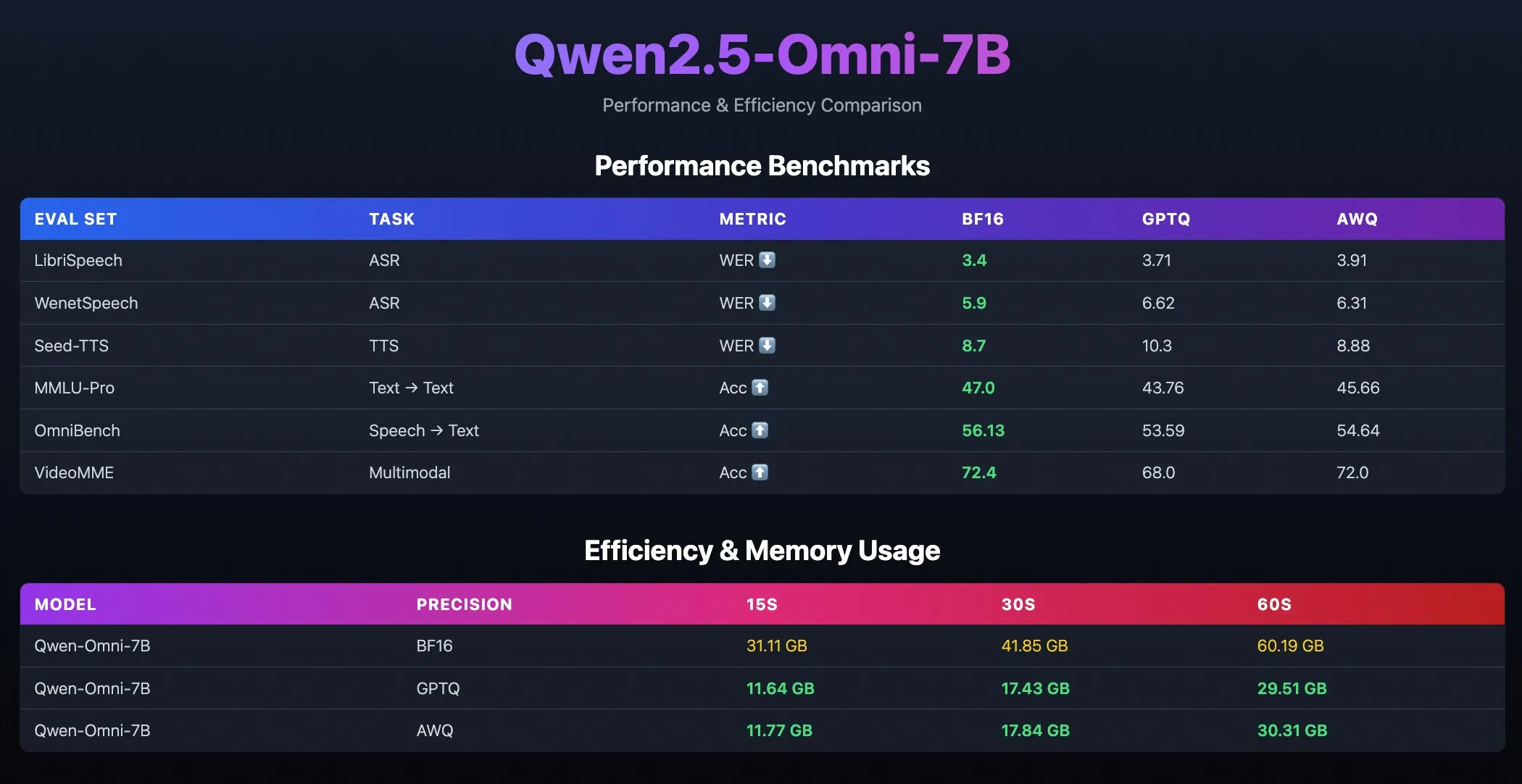
TII发布BitNet模型Falcon-E-1B/3B,大幅降低内存占用: 技术创新研究所(TII)推出了基于微软1-bit精度模型框架BitNet的新模型系列Falcon-Edge,包括Falcon-E-1B和Falcon-E-3B。据称,这些模型性能与Qwen3-1.7B相当,但内存占用仅为其1/4。TII同时发布了微调库onebitllms,支持用户在NVIDIA显卡上自行微调这些1-bit模型。 (来源: karminski3)
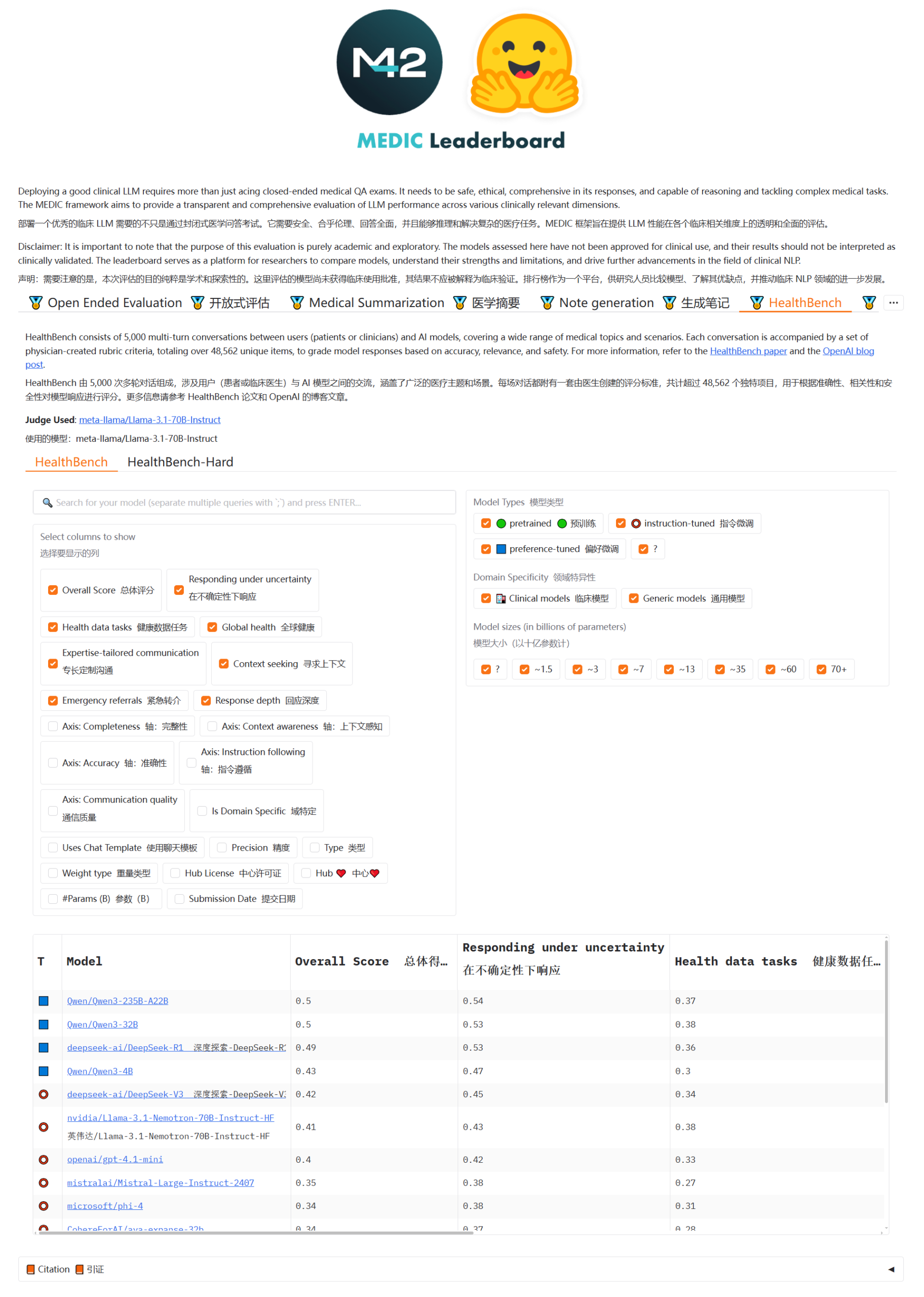
Qwen3与DeepSeek模型在MEDIC-Benchmark医疗问答排行榜领先: Qwen3模型在最新发布的MEDIC-Benchmark医疗问答排行榜上取得了第一和第二的成绩。此外,榜单前五名均由Qwen和DeepSeek系列模型占据,显示了这些国产大模型在专业医疗领域的强大问答能力。 (来源: karminski3)
浙大提出Rankformer:直接优化排序的Transformer推荐模型架构: 浙江大学团队提出了一种名为Rankformer的新型图Transformer推荐模型架构,其设计直接源于排序目标(如BPR损失函数)。Rankformer通过模拟梯度下降过程中的向量优化方向来设计独特的图Transformer机制,在前向传播中引导模型编码更优的排序表征。该模型利用全局注意力机制聚合信息,并声称通过数学变换与缓存优化将时空复杂度降至线性级别。该研究已被WWW 2025会议录用。 (来源: WeChat)
🧰 工具
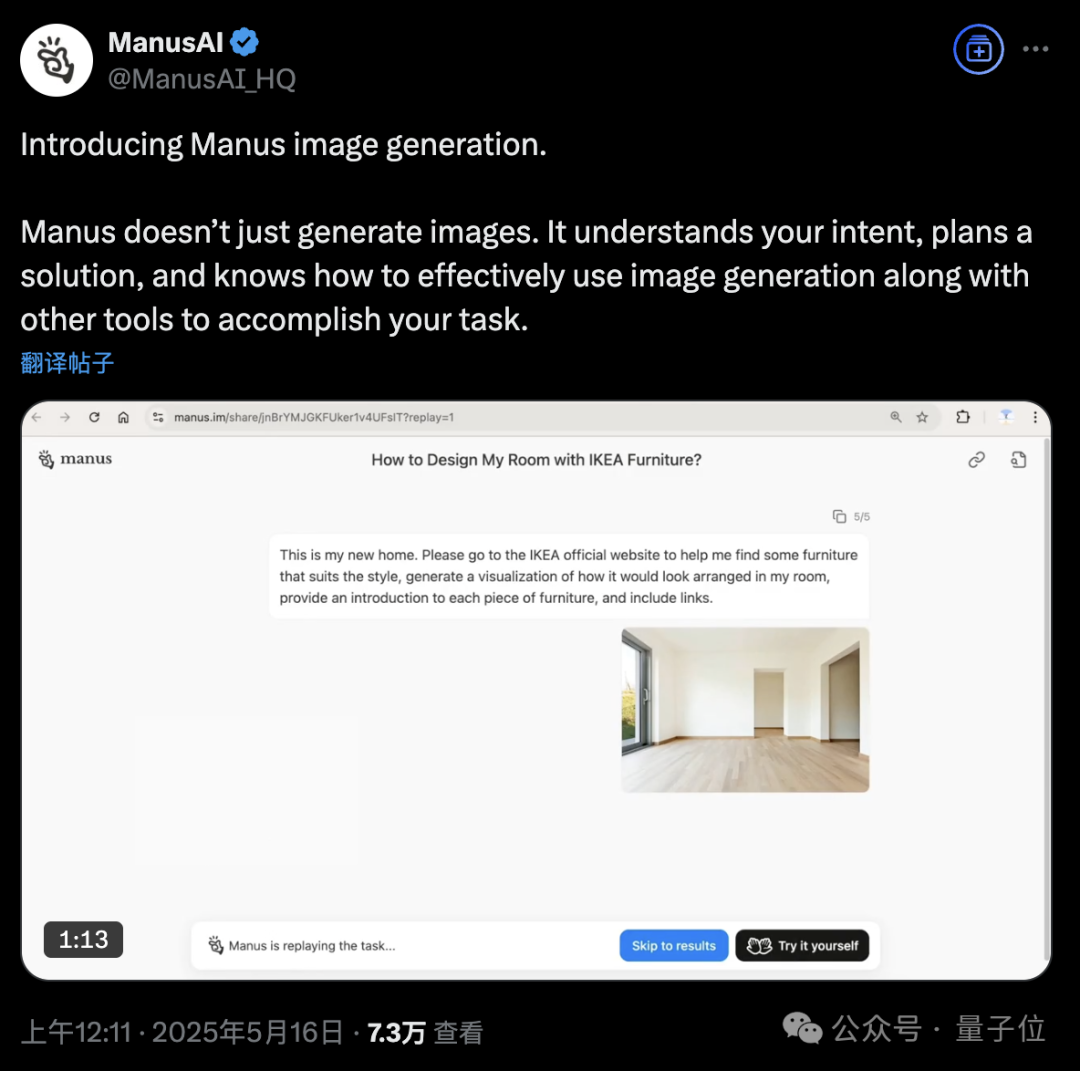
Manus AI Agent平台新增图像生成功能: AI Agent平台Manus宣布支持图像生成。与传统AI绘图工具不同,Manus能理解用户绘图目的,规划生成方案。例如,用户可上传房间照片,要求Manus从宜家官网寻找家具并生成可视化装修效果图,同时附上家具链接。Manus通过分析、搜索、筛选家具、撰写设计策略等步骤完成任务。该功能旨在将智能体工作流与图像生成深度结合。目前Manus已开放注册,赠送1000点数,每日额外赠送300点,并提供付费订阅计划。 (来源: 36氪, WeChat)
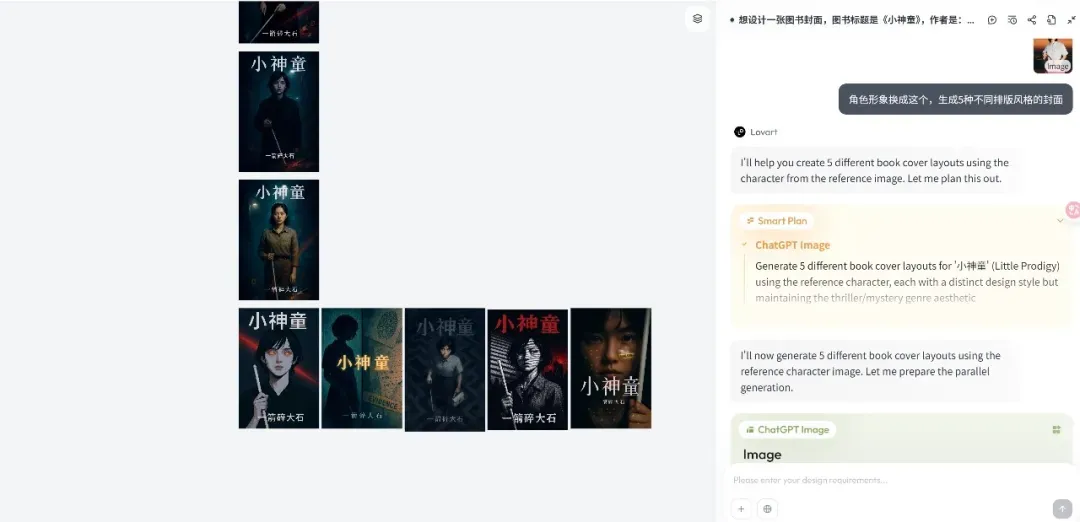
Lovart设计Agent平台发布,专注创意工作流: 新兴设计Agent平台Lovart在发布后迅速引起关注,其核心理念是将设计师的创作过程(涉及多模态)转化为Agent工作流。Lovart提供画布式交互界面,用户可通过对话指导AI完成设计任务,AI负责规划和执行。创始人陈冕认为AI图像产品已进入Agent驱动的3.0阶段,Lovart旨在成为设计师的“朋友”,将琐事交给AI,让设计师专注于创意。产品未来将整合3D建模、视频、音频能力,成为一个“创意团队”或“设计公司”。 (来源: 36氪)
OpenAI Codex CLI更新,集成o4-mini并提供免费API额度: OpenAI对其轻量级开源编码Agent Codex CLI进行了改进。新版本由codex-1的精简版o4-mini(命名为codex-mini)驱动,专为低延迟代码问答和编辑优化。用户现在可以使用ChatGPT账户登录Codex CLI,Plus和Pro用户可分别兑换5美元和50美元的免费API积分(有效期30天),用于体验codex-mini-latest模型。 (来源: openai, hwchung27, op7418)
DeepSeek开源数据处理框架Smallpond集成DuckDB对3FS的原生访问: DeepSeek开源的数据处理框架Smallpond,其内部使用了3FS(DeepSeek File System)和DuckDB。现在DuckDB通过hf3fs_usrbio插件支持以原生方式访问3FS,这将带来性能提升和开销减少。DuckDB本身也因其易用性受到好评,例如可以直接在查询语句中嵌入URL进行数据处理。 (来源: karminski3)

ComfyUI原生支持阿里Wan2.1-VACE视频模型: ComfyUI宣布原生支持阿里巴巴Wanxiang(@Alibaba_Wan)团队的视频生成模型Wan2.1-VACE 14B和1.3B版本。该模型为ComfyUI带来了集成的视频编辑能力,包括文本到视频、图像到视频、视频到视频(姿态和深度控制)、视频修复(inpainting)与外扩(outpainting)以及角色/物体参考等功能。 (来源: TomLikesRobots)
谷歌AI Studio集成Veo 2、Gemini 2.0及Imagen 3,提供统一生成媒体体验: 谷歌AI Studio推出了新的生成媒体体验,整合了视频模型Veo 2、Gemini 2.0的原生图像生成/编辑能力,以及最新的文生图模型Imagen 3。用户可以在AI Studio中免费试用这些模型,开发者也可以通过API进行构建。 (来源: op7418)
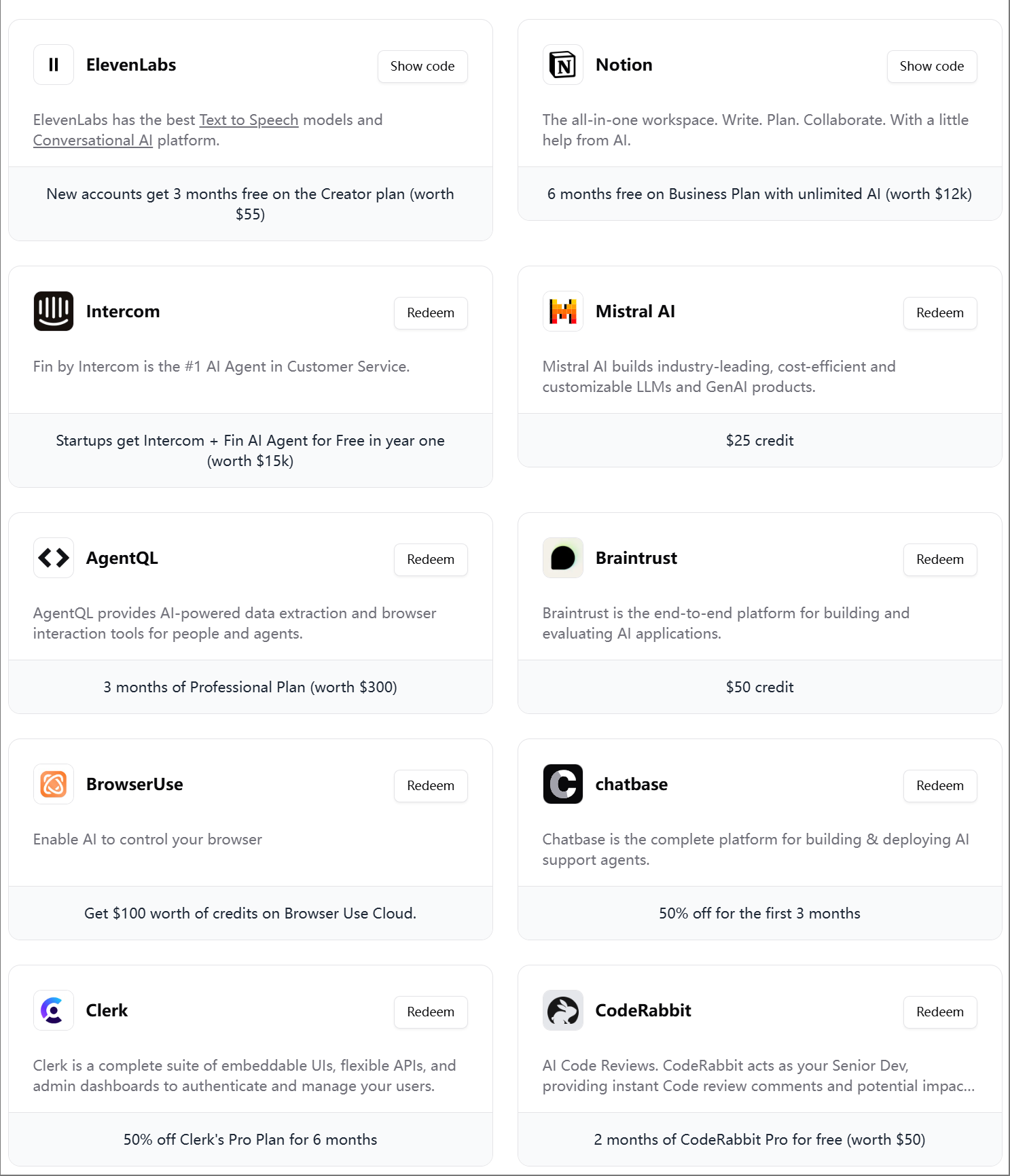
ElevenLabs推出第四期AI工程师大礼包: ElevenLabs发布了第四期面向AI开发者的AI工程师大礼包,内含多种工具和服务的会员及API额度,例如Modal Labs、Mistral AI、Notion、BrowserUse、Intercom、Hugging Face、CodeRabbit等,旨在帮助AI初创企业和开发者。 (来源: op7418)
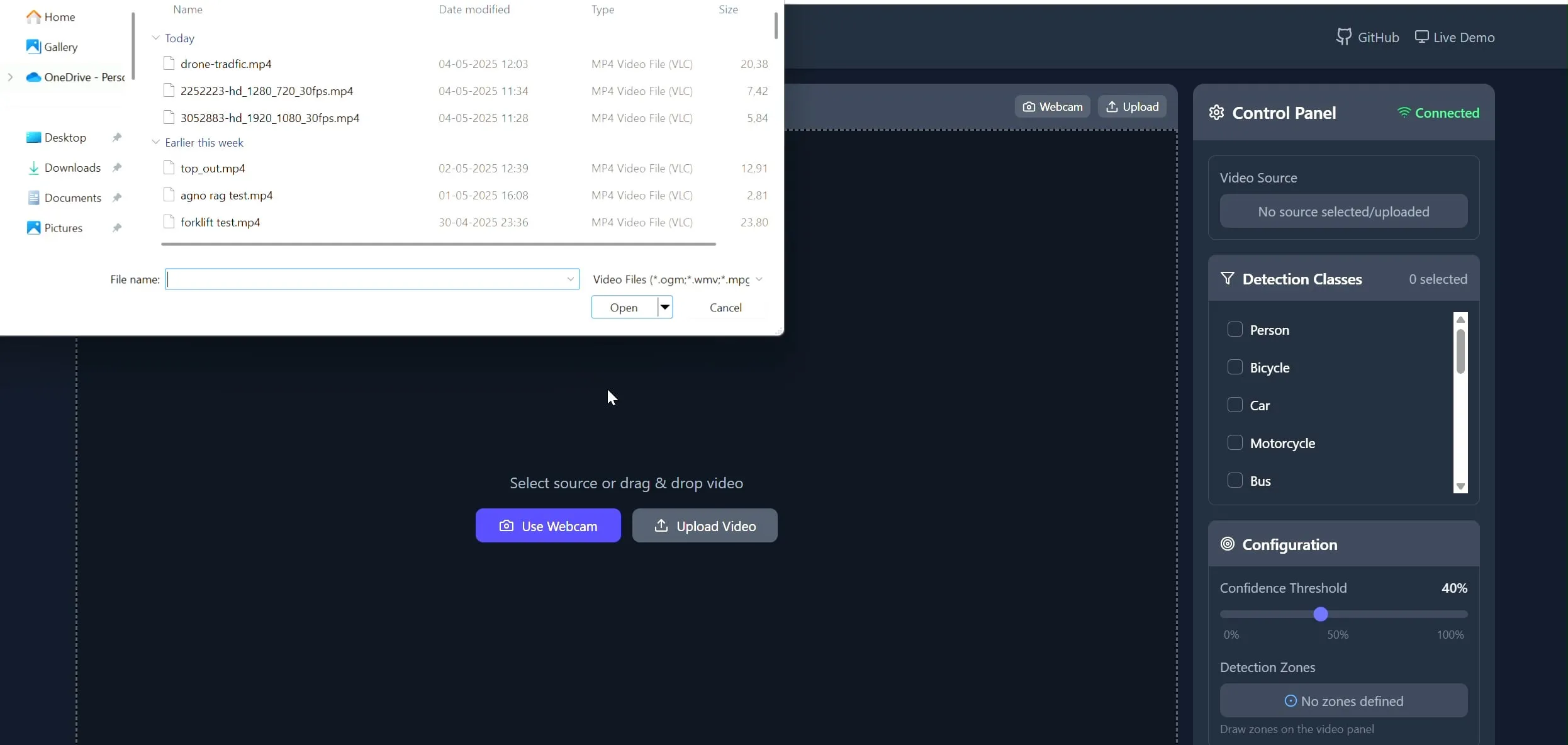
Polygon Zone App:用于CV任务的视频自定义多边形绘制工具: 开发者Pavan Kunchala创建了一个名为Polygon Zone App的工具,允许用户上传视频,在视频帧上交互式绘制自定义多边形区域(ROI),并可在这些区域内运行对象检测等计算机视觉分析。该工具旨在简化CV项目中定义ROI的繁琐过程,避免手动编辑JSON坐标。 (来源: Reddit r/deeplearning)
📚 学习
AI Evals课程吸引超300家公司参与: Hamel Husain开设的AI评估课程(bit.ly/evals-ai)已吸引超过300家公司参与,其中包括Adobe、Amazon、Google、Meta、Microsoft、NVIDIA、OpenAI等知名企业以及多所顶尖大学。这反映了业界对AI模型评估方法和实践的高度关注和需求。 (来源: HamelHusain)
Latent.Space发布ChatGPT Codex使用手册: Latent.Space推出了名为《ChatGPT Codex: The Missing Manual》的指南,详细介绍了如何高效使用OpenAI新发布的云端自主软件工程师ChatGPT Codex。该手册由Josh Ma和Alexander Embiricos编写,旨在帮助用户充分发挥Codex在代码库操作中的强大功能。 (来源: swyx)

Qdrant推出本地RAG应用教程: Qdrant Engine分享了一个由@maxedapps制作的教程,演示了如何使用Gemma 3、Ollama和Qdrant Engine从零开始构建一个100%本地运行的检索增强生成(RAG)应用程序。该教程时长2小时,提供了完整的代码和步骤,适合希望实践本地AI应用的开发者。 (来源: qdrant_engine)

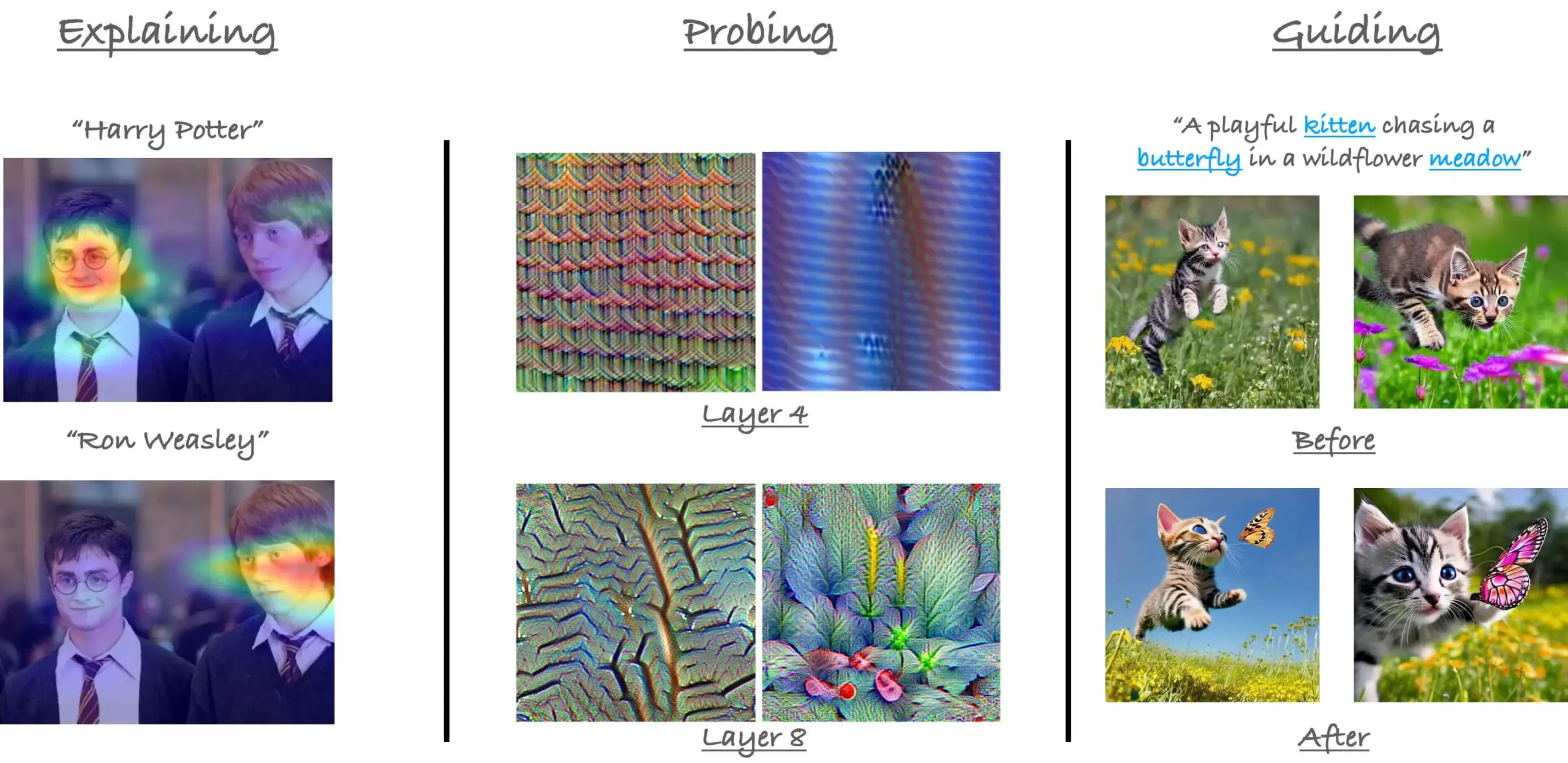
CVPR23 ViT中的注意力机制教程回顾: 研究员Sayak Paul回顾了其与Hila Chefer在CVPR 2023上关于Vision Transformer(ViT)中注意力机制的教程。该教程围绕“解释(explain)”、“探测(probe)”和“引导(guide)”三个主题展开,旨在帮助理解ViT内部的注意力运作方式。 (来源: RisingSayak)
Claude Code使用技巧分享:规划、规则与手动压缩: Reddit用户分享了深度使用Claude Code一周的经验,强调了规划、制定规则(通过CLAUDE.md文件)以及在达到自动压缩限制前手动运行/compact的重要性。这些技巧有助于提高生产力和输出质量,尤其是在处理大型特性或避免模型偏离轨道方面。用户提到,通过这些方法,Claude Code能够高效完成复杂任务。 (来源: Reddit r/ClaudeAI)
AIGCode创始人宿文访谈:坚持自研大模型,目标Autopilot“L5”级代码生成: AIGCode创始人宿文在访谈中表示,公司目标是做代码供给的基础设施,实现“L5”级别的Autopilot自动编程,让非程序员也能通过AI生成完整应用。他认为Coding是培育大模型的最佳场景,代码是高质量训练数据。AIGCode已训练出66B基础模型“锡月”,并推出AutoCoder产品。宿文强调,AI产品最终比拼的是“大脑”的聪明程度,预训练是技术源动力,即使成本高昂,自研模型对于实现AGI和构建产品核心竞争力至关重要。 (来源: WeChat)

💼 商业
京东智能体平台与应用算法团队招聘: 京东集团核心项目智能体平台和应用算法团队正在招聘大模型算法工程师及实习生,工作地点北京。主要技术方向包括LLM Agent、LLM Reasoning及LLM结合强化学习。招聘面向2026年毕业的硕博研究生(校招)、对标P5-P8的社招人士以及研究型实习生。团队注重技术驱动和实际问题解决,在顶级AI会议有论文发表。 (来源: WeChat)

AI优先策略在Klarna和Duolingo遇挑战,人机平衡受关注: 金融科技公司Klarna和语言学习应用Duolingo在推行“AI优先”策略后,面临消费者反馈和市场现实的压力。Klarna曾用AI替代数百客服岗位,但因服务质量下降现重新招聘人工客服。Duolingo因自动化角色引发用户不满,许多人认为语言学习核心应由人主导。这些案例表明,企业在AI转型中需平衡创新与人文关怀,技术虽重要,但用户信任仍需人来构建。 (来源: Reddit r/ArtificialInteligence)
Databricks传闻以10亿美元收购数据库初创公司Neon: 根据Reddit社区流传的AI新闻摘要,Databricks收购了数据库初创公司Neon,交易金额据称为10亿美元。此次收购可能旨在增强Databricks在数据管理和AI基础设施方面的能力。 (来源: Reddit r/ArtificialInteligence)
🌟 社区
OpenAI Codex发布引发热议,开发者期待与审慎并存: OpenAI发布编程智能体Codex后,社区反响热烈。许多开发者对Codex能自动完成PR创建、代码修复等任务表示兴奋,认为这将极大提高编程效率,甚至有人称其为“AGI时刻的感受”。Ryan Pream分享其使用Codex一天创建超过50个PR的经历。同时,也有用户指出Codex在任务拆分、测试用例添加等方面尚需改进,目前更适合专业人士使用。Yohei Nakajima分享了初步体验,认为其GitHub中心化设计合理,但学习曲线较陡。 (来源: kevinweil, gdb, itsclivetime, dotey, yoheinakajima, cto_junior)
Meta在AI开源领域的贡献获肯定,引发封闭与开放讨论: Hugging Face CEO Clement Delangue发文支持Meta,认为其在AI模型开源方面的贡献远超其他拥有更多资源的大厂和初创公司,不应受到过多指责。此观点得到部分用户认同,认为构建前沿AI模型极为困难,Meta的开放行为对领域发展至关重要。但也有观点(gabriberton)指出,开源意味着放弃知识优势,本质上闭源能获得更好结果。Dorialexander则对美国突然采纳“欧洲的应对方式”(指为Meta辩护)表示不解。 (来源: ClementDelangue, gabriberton, Dorialexander)
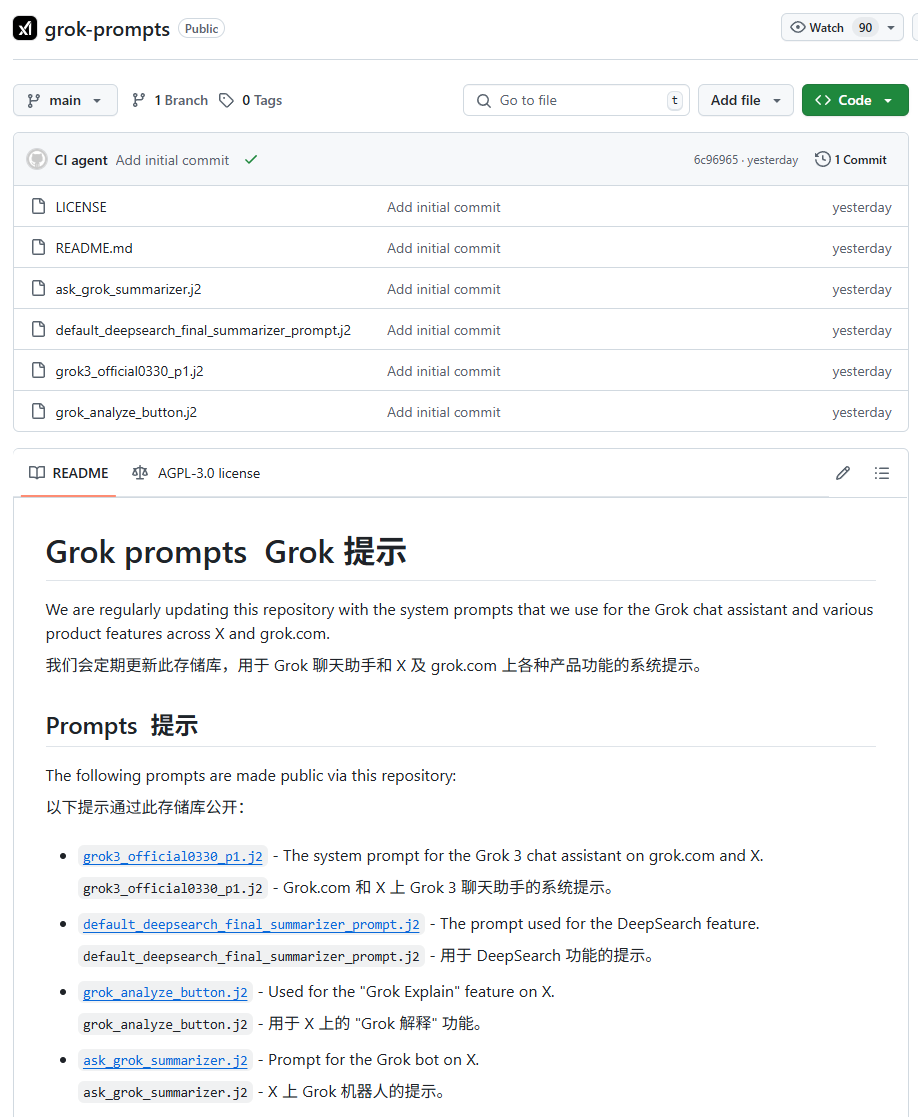
xAI Grok系统提示词泄露及不当内容合并事件引关注: xAI的Grok模型系统提示词被发现在GitHub上泄露,甚至包含了DeepSearch的系统提示词。更严重的是,有用户指出,一个包含“白人种族灭绝”等不当内容的PR在经过五人审查后被合并到主分支,随后虽被还原并删除历史,但该事件暴露了xAI在流程管理和运营安全方面的重大缺陷。此事引发社区对xAI内部流程和内容审核机制的广泛质疑和讨论。 (来源: karminski3, eliebakouch, colin_fraser, Reddit r/artificial)
AI Agent被认为是未来趋势,但挑战与期望并存: “2025年是Agent之年”的观点在社区中流传,引发对AI Agent未来发展的讨论。有观点认为,未来的工作模式将类似《星际争霸》或《帝国时代》,用户指挥大量微智能体完成任务。然而,也有用户指出当前Agent在任务拆解、理解复杂指令方面尚不成熟,需要使用者具备较强的规划能力。部分人对AI Agent在2025年能达到预期表示怀疑,认为可能从一个噱头转向另一个噱头,期待2026年能有实质性改变。 (来源: gdb, EdwardSun0909, op7418, eliza_luth, tokenbender)
AI在教育与就业领域的角色引发深刻讨论: Reddit社区出现关于AI发展对传统教育和就业模式冲击的讨论。有用户提问“现在上学还有什么意义?”,认为AI将使未来无人需要工作。对此,多数评论强调批判性思维、学习能力和社交技能的重要性,认为这些是AI无法替代的。学校不仅是知识传授的场所,更是学习如何学习、如何思考和与人互动的环境。即使在AI主导的世界,这些能力依然至关重要,甚至需要学习AI本身。另有讨论指出,不应将人的价值仅仅等同于其工作,AI的发展应促使我们思考超越职业的人类意义。 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI女友现象引发社会伦理及人口问题思考: 经济学人报道中国年轻人开始与AI谈恋爱、交朋友,引发网友热议。有评论将此现象比作“为了减少蚊子数量,向野外释放大量绝育的母蚊子”,暗示AI伴侣可能加剧低生育率问题,尽管AI伴侣能提供“永远懂你”的完美体验。这反映了AI技术在情感陪伴领域应用所带来的复杂社会影响和伦理考量。 (来源: dotey)
AI电话交流逼真度引人担忧,真假难辨成新挑战: Reddit用户分享了接到来自学习机构的电话,对方声音语调自然、应答流畅,几乎无法分辨是真人还是AI。直到对话几分钟后,因其回答过于完美无瑕才意识到是AI。这一经历引发了用户对AI语音技术发展速度的惊叹和一丝不安,担心未来难以辨别电话中的AI,尤其可能对老年人等群体造成诈骗风险。 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial)
💡 其他
MIT要求arXiv撤下一篇关于AI与科学发现的预印本论文引发争议: MIT要求arXiv撤下一篇由其博士生撰写的关于AI对材料科学创新影响的预印本论文,理由是对研究数据的来源、可靠性和有效性“没有信心”。该论文曾指出AI辅助研究员发现材料增加44%,专利申请增加39%。MIT此举引发讨论,有评论认为其做法有损学术自由,可能与研究结论(AI可能加剧顶尖研究者优势,降低普通研究者工作满意度)不符资助方期望有关;也有评论认为,在AI领域,研究成果的严谨性至关重要,应警惕预印本驱动的过度炒作。 (来源: Reddit r/ArtificialInteligence)
AI编码工具的普及对代码模块化和工程实践提出更高要求: E0M在推特上指出,初创公司的竞争优势越来越体现在工程师采用AI编码工具的速度和效率上。良好的模块化代码实践变得前所未有地重要,如果代码复杂度在现代编码Agent的处理范围内,则能实现快速迭代;反之,过于复杂的“意大利面条式代码”则可能拖慢进度,被采用AI的竞争对手超越。 (来源: E0M, E0M)
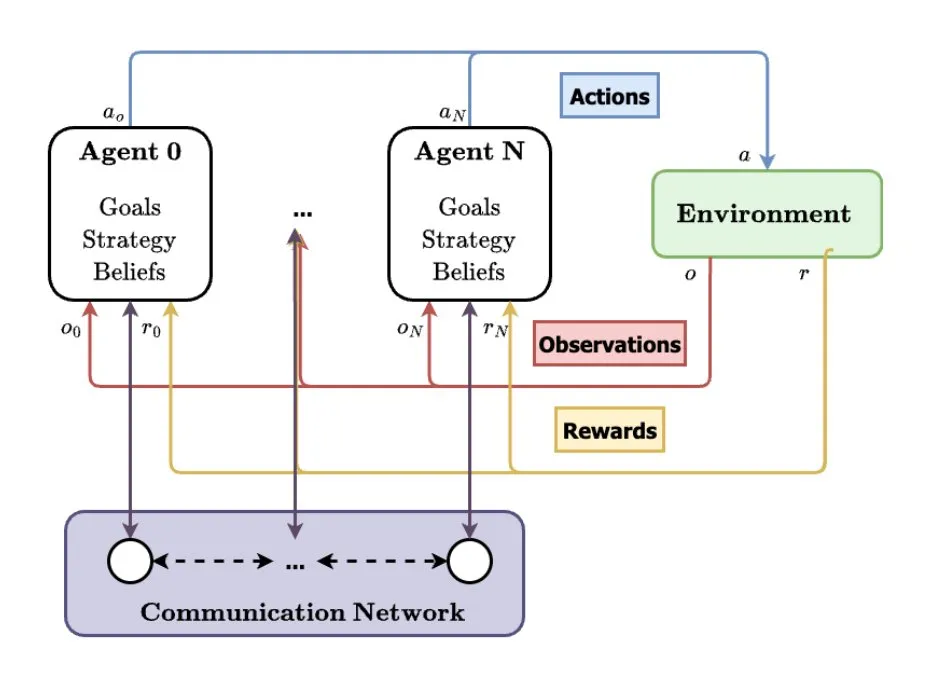
多智能体系统(MAS)被视为AI未来发展方向: TheTuringPost分析了多智能体系统(MAS)的兴起趋势,关键发展包括多智能体强化学习(MARL)、群体机器人技术、情境感知MAS(CA-MAS)以及大型语言模型(LLM)驱动的MAS。这些技术使得AI系统能够通过协作和竞争解决复杂问题,应用于灾难响应、环境监测、社会动力学模拟等领域,预示着集体智能的未来。 (来源: TheTuringPost)