
关键词:OpenAI Codex, AI软件开发, 多模态模型, AI语音生成, 数据筛选, Codex研究预览版, MiniMax Speech-02, BLIP3-o多模态模型, PreSelect数据筛选, SWE-1模型系列
🔥 聚焦
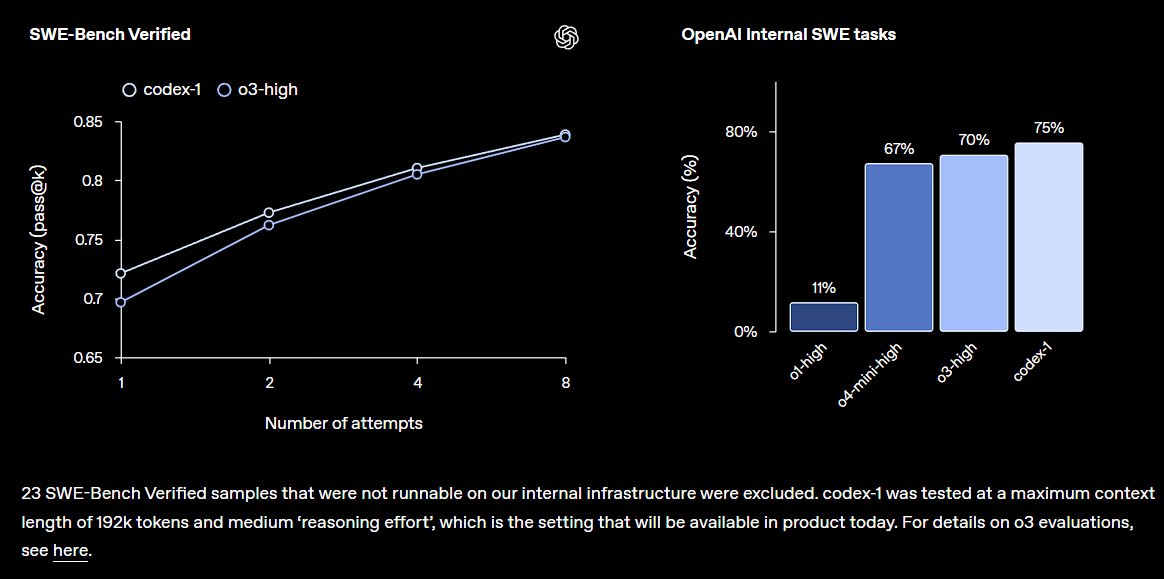
OpenAI发布Codex研究预览版,集成于ChatGPT: OpenAI推出Codex,一个云端软件工程智能体,能理解大型代码库、编写新功能、修复错误,并可并行处理多任务。Codex基于o3微调的codex-1模型,在SWE-bench上表现优异。该功能将逐步向ChatGPT Pro、Team和Enterprise用户开放,旨在大幅提升开发者生产力,预示着AI在软件开发领域将扮演更核心角色。社区对此反应积极,但也关注其实际效果和潜在bug (来源: OpenAI, OpenAI Developers, scaling01, dotey)
微软大规模裁员引发行业震动,AI驱动的组织变革加速: 微软宣布全球裁员约6000人,旨在简化管理层级并提高程序员比例,部分被裁员工不乏有25年工龄且贡献卓著的老将及TypeScript核心开发者。此次裁员被认为与AI技术提升效率、自动化部分工作任务有关,反映了科技巨头在AI时代控制成本、优化人力结构的趋势。事件引发了关于AI对就业市场冲击、企业忠诚度以及未来工作模式的广泛讨论 (来源: WeChat, NeelNanda5)
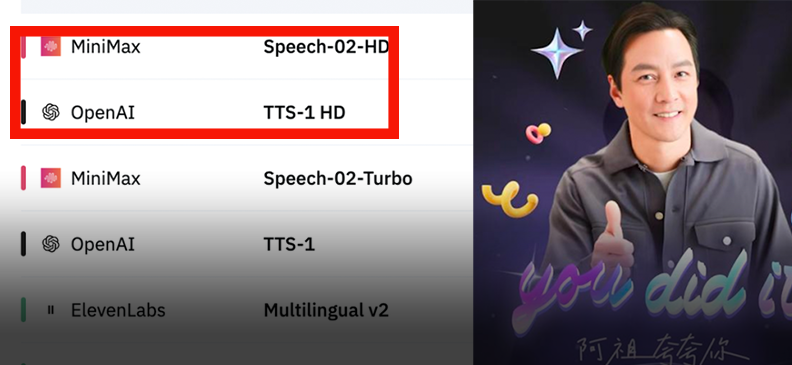
MiniMax发布Speech-02语音模型,登顶全球榜单: MiniMax推出新一代语音模型Speech-02,在Artificial Analysis Speech Arena和Hugging Face TTS Arena两大权威语音测评中均获得第一,超越OpenAI和ElevenLabs。该模型在超拟人、个性化音色定制(支持32种语言及口音、几秒参考即可复刻)和多样性方面表现突出,并创新性采用Flow-VAE技术提升克隆细节。其技术已应用于“AI阿祖”学英语、故宫AI向导等场景,显示国产大模型在AI语音生成领域的领先地位 (来源: WeChat, WeChat)
Salesforce等机构发布统一多模态模型BLIP3-o: Salesforce Research联合多所高校发布全开源统一多模态模型BLIP3-o,采用“先理解后生成”策略,结合自回归与扩散架构。模型创新使用CLIP特征与Flow Matching训练,显著提升生成图像的质量、多样性及提示对齐能力。BLIP3-o在多个基准测试中表现优异,并正拓展至图像编辑和视觉对话等复杂多模态任务,推动了多模态AI技术的发展 (来源: 36氪)

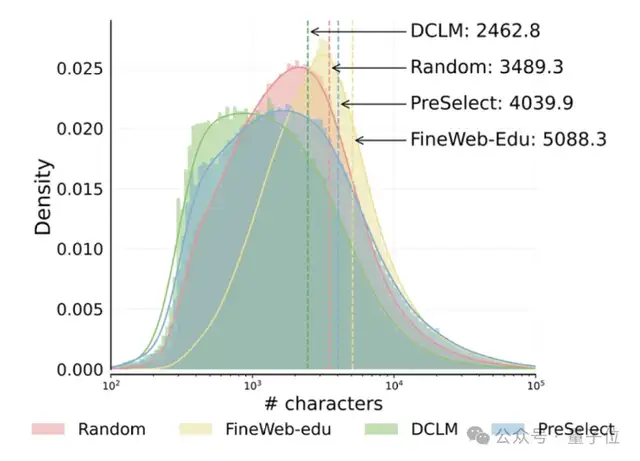
港科大与vivo提出PreSelect数据筛选方案,提升预训练效率10倍: 香港科技大学与vivo AI Lab合作提出轻量级高效数据选择方法PreSelect,已被ICML 2025接收。该方法通过“预测强度”指标量化数据对模型特定能力的贡献,利用fastText评分器筛选全量训练数据,能在减少10倍计算需求的同时,使模型效果平均提升3%。PreSelect旨在更客观、泛化地筛选高质量多样性数据,克服了传统规则或模型筛选方法的局限性 (来源: 量子位)
🎯 动向
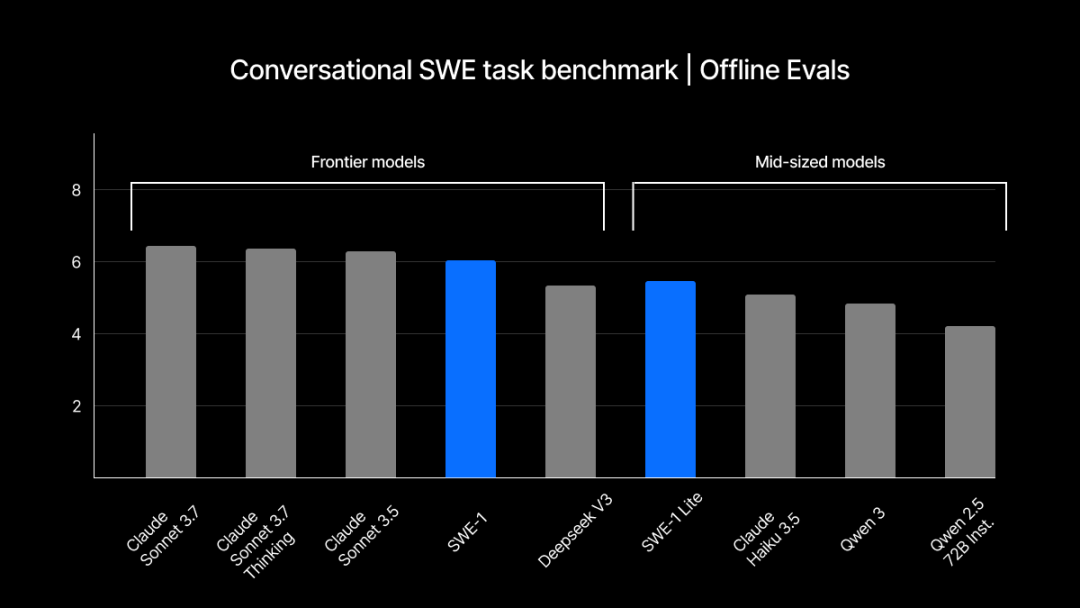
Windsurf发布自研SWE-1系列模型,优化软件工程流程: Windsurf推出首个专为软件工程优化的模型系列SWE-1,旨在将开发效率提升99%。该系列包括SWE-1(接近Claude 3.5 Sonnet的工具调用能力,成本更低)、SWE-1-lite(高质量,替代Cascade Base)和SWE-1-mini(小而快,用于低延迟场景)。其核心创新在于“流动感知”(Flow Awareness)系统,即AI与用户共享操作时间线,实现高效协作和对未完成状态的理解 (来源: WeChat, WeChat)
ChatGPT记忆机制被逆向工程,揭示三种记忆子系统: OpenAI为ChatGPT推出的“聊天历史记录”记忆功能被技术爱好者分析,揭示其可能包含当前对话历史、对话历史记录(基于摘要和内容检索)和用户洞察(基于多对话分析生成,带置信度)三个子系统。这些机制旨在提供更个性化和高效的交互体验,通过RAG和向量空间等技术实现。尽管官方称能提升用户体验,但社区反馈褒贬不一,部分用户报告功能不稳定或存在bug (来源: WeChat, 量子位)
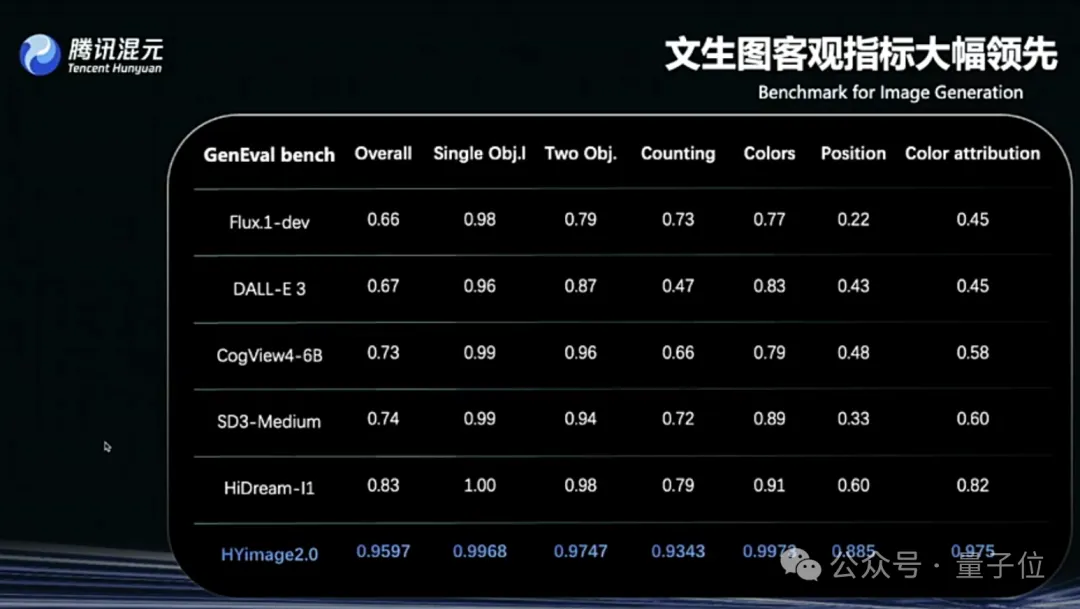
腾讯混元图像2.0发布,支持实时“边说边画”: 腾讯混元推出Hunyuan Image 2.0模型,实现了毫秒级响应的实时文生图功能,用户输入文本或语音描述时,图像会随之实时生成和调整。新模型还支持实时绘画板,用户手绘草图结合文字说明即可生成图像。模型在真实感、语义遵从(适配多模态大语言模型作为文本编码器)、图像编解码器压缩率方面有显著提升,并通过强化学习进行后训练优化 (来源: 量子位)
TII发布Falcon-Edge系列BitNet模型及onebitllms微调库: TII推出Falcon-Edge,一系列参数量为1B和3B的紧凑型语言模型,大小分别仅为600MB和900MB。这些模型采用BitNet架构,可在几乎不损失性能的情况下恢复至bfloat16。初步结果显示其性能优于其他小型模型,并与Qwen3-1.7B相当,但内存占用仅为其1/4。同时发布的onebitllms库专用于BitNet模型的微调 (来源: Reddit r/LocalLLaMA, winglian)

Ollama新引擎增强多模态支持: Ollama更新其引擎,为多模态模型提供原生支持,允许进行模型特定的优化并改进内存管理。用户可以通过LangChain集成尝试Llama 4、Gemma 3等多模态模型。谷歌AI开发者也发布了使用Ollama和Gemma 3进行函数调用的指南,以实现实时搜索等功能 (来源: LangChainAI, ollama)
Grok新增图像生成宽高比控制功能: xAI的Grok模型现在允许用户在生成图像时指定所需的宽高比,为图像创作提供了更大的灵活性和控制力 (来源: grok)
谷歌AI Studio更新,新增生成媒体页面和使用仪表盘: 谷歌的ai.studio平台进行了一系列更新,包括全新的着陆页设计、内置的使用情况仪表盘以及新的生成媒体(gen media)页面,预示着在即将到来的I/O大会上可能会有更多相关发布 (来源: matvelloso)
LatitudeGames发布新模型Harbinger-24B (New Wayfarer): LatitudeGames在Hugging Face上发布了名为Harbinger-24B的新模型,代号New Wayfarer。社区对此表示关注,并讨论为何不选择微调Qwen3 32B或Llama 4 Scout等其他模型 (来源: Reddit r/LocalLLaMA)

🧰 工具
Adopt AI获600万美元融资,旨在通过AI Agent重构软件交互: 初创公司Adopt AI获得600万美元种子轮融资,致力于通过Agent Builder和Agent Experience两大功能,让传统企业软件能以无代码方式快速集成自然语言交互能力。其技术能自动学习应用结构和API,生成可由自然语言调用的操作,并通过Pass-through架构保障数据安全,旨在提升软件采用率和效率,降低企业成本 (来源: WeChat)

字节跳动火山引擎推出迷你AI硬件Demo,支持高度DIY: 火山引擎发布了一款迷你AI硬件的Demo,并开源了其客户端/服务端代码。该硬件支持高度自由定制,可对接火山大模型、Coze智能体以及兼容OpenAI API的第三方大模型(如FastGPT)和多种TTS语音(包括MiniMax)。用户可以DIY实现与特定角色(如年轻周杰伦、何炅)对话,或打造AI语音客服等应用,提供了丰富的AI交互体验 (来源: WeChat)

Runway发布Gen-4 References API,赋能开发者构建图像生成应用: Runway将其广受欢迎的Gen-4 References图像生成模型通过API开放给开发者。该模型以其通用性和灵活性著称,能够基于参考图像生成新的、风格一致的图像。API的发布将使开发者能将这一强大的图像生成能力集成到自己的应用和工作流中 (来源: c_valenzuelab)

Zencoder推出编码优化AI智能体平台Zen Agents: AI初创公司Zencoder(正式名称为For Good AI Inc.)发布了名为Zen Agents的云平台,该平台用于创建针对编码任务优化的AI智能体,旨在提高软件开发的效率和质量 (来源: dl_weekly)
llmbasedos:基于MCP的极简Linux发行版,专为本地LLM优化: 一位开发者构建了llmbasedos,这是一个基于Arch Linux的最小化发行版,旨在将本地环境转变为LLM前端(如Claude Desktop, VS Code)的一等公民。它通过MCP(Model Context Protocol)协议暴露本地能力(文件、邮件、代理等),支持离线模式(含llama.cpp)或连接GPT-4o、Claude等云端模型,方便开发者快速添加新功能 (来源: Reddit r/LocalLLaMA)
PDF文件可运行LLM及Linux系统引关注: 技术爱好者Aiden Bai展示了在PDF文件中运行小型语言模型(如TinyStories, Pythia, TinyLLM)的项目“llm.pdf”,通过将模型编译成JavaScript并利用PDF对JS的支持实现。评论区更有人指出此前已有在PDF中运行Linux系统(通过RISC-V模拟器)的先例。这揭示了PDF作为动态内容容器的潜力,但也引发了关于安全性和实用性的讨论 (来源: WeChat)

OpenAI Codex CLI工具更新,支持ChatGPT登录及新mini模型: OpenAI开发者团队宣布Codex CLI工具迎来改进,包括支持通过ChatGPT账户登录以快速连接API组织,并新增了codex-mini模型,该模型专为低延迟的代码问答和编辑任务进行了优化 (来源: openai, dotey)
商汤大模型一体机获IDC推荐,支持日日新及DeepSeek等模型: IDC发布的《中国AI大模型一体机市场分析与品牌推荐,2025》报告中,商汤科技的大模型一体机入选。该一体机基于商汤大装置AI基础设施,搭载高性能算力芯片和推理加速引擎,支持商汤“日日新SenseNova V6”及DeepSeek等主流大模型,提供全链路自主可控解决方案,优化总体拥有成本(TCO),并已在医疗、金融等多个行业落地 (来源: 量子位)

开源工作流自动化工具n8n增加中文支持: 广受欢迎的开源工作流自动化工具n8n现已通过社区贡献的汉化包支持中文界面。用户可以下载对应版本的汉化文件,并通过简单的Docker配置修改,即可在n8n中使用中文操作,降低了国内用户的使用门槛 (来源: WeChat)

git-bug:嵌入Git的分布式离线优先Bug追踪器: git-bug是一个开源工具,它将问题、评论等作为对象嵌入到Git仓库中(而非普通文件),实现了分布式的、离线优先的Bug追踪。它支持与GitHub、GitLab等平台通过桥接同步问题,并提供CLI、TUI和Web界面 (来源: GitHub Trending)

PyLate集成PLAID索引,提升大规模数据集模型基准测试效率: Antoine Chaffin宣布PyLate(一个用于ColBERT模型的训练和推理生态系统)已合并PLAID索引。这一集成使得用户能够在其非常大规模的数据集上有效地对最佳模型进行基准测试,为在各种检索排行榜上取得SOTA提供了便利 (来源: lateinteraction, tonywu_71)

Neon:开源无服务器PostgreSQL数据库: Neon是一个开源的无服务器PostgreSQL替代方案,它通过分离存储和计算来实现自动扩展、代码式数据库分支和缩放到零的特性。该项目在GitHub上受到关注,为需要弹性、可扩展数据库解决方案的AI及其他应用开发者提供了新选择 (来源: GitHub Trending)

Unmute.sh:可定制提示和语音的新AI语音聊天工具: Unmute.sh是一个新推出的AI语音聊天工具,其特点是允许用户自定义提示(prompt)和选择不同的语音,为用户提供了更加个性化和灵活的语音交互体验 (来源: Reddit r/artificial)
📚 学习
全球首个多模态通才模型评估框架General-Level与基准General-Bench发布: 一项录用于ICML‘25 (Spotlight)的研究提出了全新的多模态大模型(MLLM)评测框架General-Level及配套数据集General-Bench。该框架引入五级段位体系,核心考察模型的“协同泛化效应”(Synergy),即知识在不同模态或任务间的迁移提升能力。General-Bench是目前规模最大、覆盖最广的MLLM评测基准,含700+任务、32万+测试数据,覆盖图像、视频、音频、3D及语言五大模态和29个领域。排行榜显示,GPT-4V等模型目前仅达Level-2(无协同),尚无模型达到Level-5(全模态完全协同) (来源: WeChat)

论文J1提出通过强化学习激励LLM-as-a-Judge进行思考: 一篇名为 “J1: Incentivizing Thinking in LLM-as-a-Judge via RL” 的新论文(arxiv:2505.10320)探讨了如何利用强化学习(RL)来激励作为评估者的大语言模型(LLM-as-a-Judge)进行更深层次的“思考”,而不是仅仅给出表面判断。这种方法可能提升LLM在评估复杂任务时的准确性和可靠性 (来源: jaseweston)

新框架TREQA利用LLM评估复杂文本翻译质量: 针对现有机器翻译(MT)指标在评估复杂文本方面存在的不足,研究者提出了TREQA框架。该框架通过使用大语言模型(LLM)生成关于源文本和翻译文本的问题,并比较对这些问题的回答,来评估翻译是否保留了关键信息。这一方法旨在更全面地衡量长文本翻译的质量 (来源: gneubig)

研究发现矩阵与其转置乘积的高效计算方法: Dmitry Rybin等人发现了一种计算矩阵与其转置乘积的更快算法(arxiv:2505.09814)。这一基础性突破对于数据分析、芯片设计、无线通信和LLM训练等多个领域具有深远影响,因为这类计算是这些领域中的常见操作。这再次证明了即使在成熟的计算线性代数领域,仍有改进空间 (来源: teortaxesTex, Ar_Douillard)

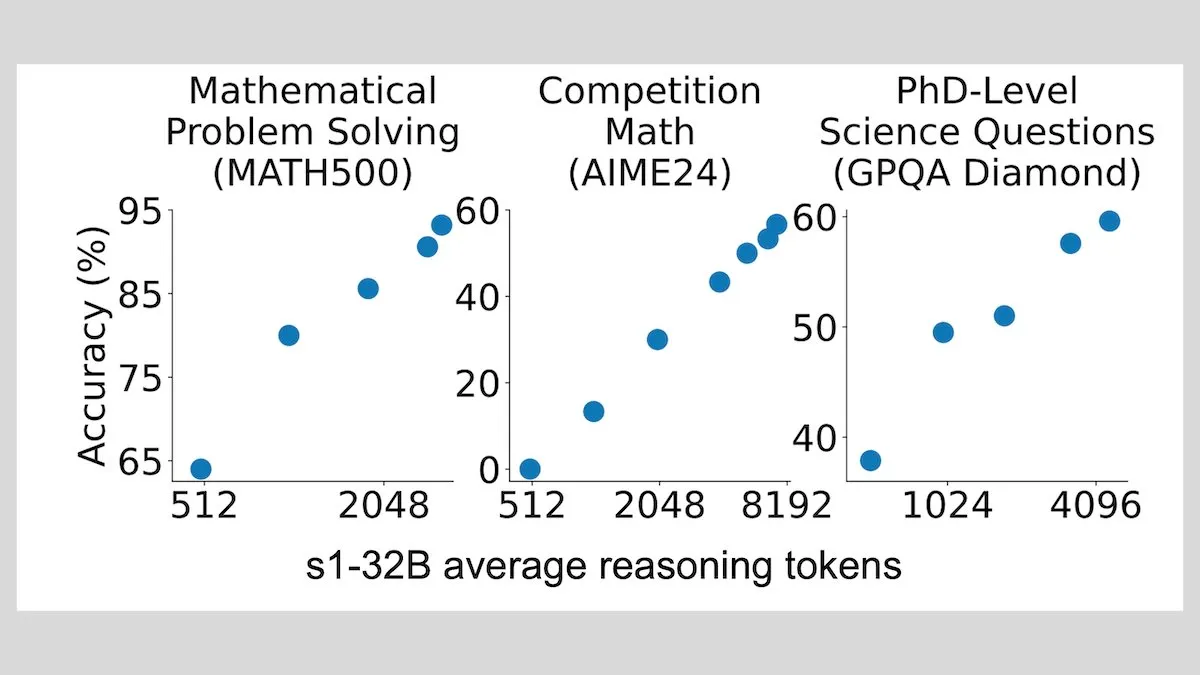
DeepLearningAI:少量样本微调可显著提升LLM推理能力: 研究显示,仅用1000个样本对大语言模型进行微调,即可显著提升其推理能力。其实验模型s1通过在推理时附加“Wait”一词来扩展推理过程,在AIME和MATH 500等基准测试中取得了良好性能。这种低资源方法表明,无需强化学习,用少量数据也能教授高级推理 (来源: DeepLearningAI)
Hugging Face推出免费MCP课程,助力构建丰富上下文AI应用: Hugging Face与Anthropic合作推出了名为“MCP: Build Rich-Context AI Apps with Anthropic”的免费课程。课程旨在帮助开发者理解MCP(Model Context Protocol)架构,学习如何构建和部署MCP服务器及兼容应用,从而简化AI应用与工具和数据源的集成。目前已有超过3000名学生注册 (来源: DeepLearningAI, huggingface, ClementDelangue)
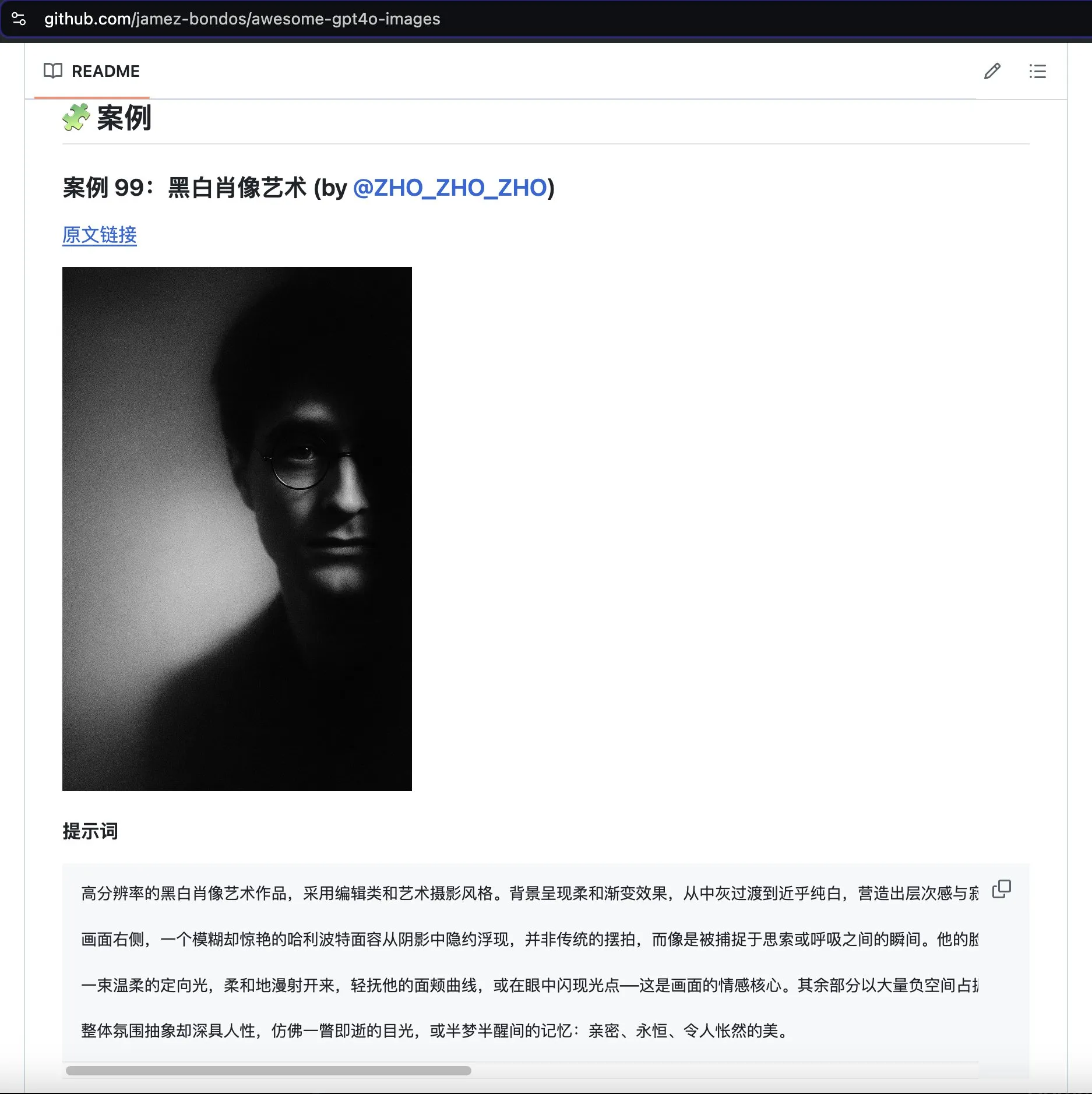
awesome-gpt4o-images项目收集GPT-4o图像生成精彩案例: Jamez Bondos创建的GitHub项目awesome-gpt4o-images在33天内获得了超过5700星标。该项目收集和展示了使用GPT-4o生成的优秀图像案例及提示词,目前已有近百个案例,并计划在整理和校验后持续更新,为AIGC社区提供了宝贵的创意资源 (来源: dotey)
Yann LeCun分享自监督学习(SSL)演讲: Yann LeCun分享了其关于自监督学习(SSL)的演讲内容。SSL作为一种重要的机器学习范式,旨在让模型从未标记数据中学习有效表征,对于减少对大规模标注数据的依赖、提升模型泛化能力具有重要意义 (来源: ylecun)
Hugging Face论文论坛成为AI论文筛选优质资源: Dwarkesh Patel推荐Hugging Face的论文论坛,认为它是筛选过去一个月最佳AI论文的绝佳资源。该平台为研究者提供了一个便捷的渠道来发现和讨论最新的AI研究进展 (来源: dwarkesh_sp, huggingface)
ACL 2025录用结果公布,阿里国际AIB团队多篇论文入选: 自然语言处理顶会ACL 2025公布录用结果,今年投稿量创历史新高,竞争激烈。阿里国际AI Business团队有多篇论文被收录,部分成果如Marco-o1 V2、Marco-Bench-IF和HD-NDEs(用于幻觉检测的神经微分方程)等获得高度评价并被收录为主会长文。这反映了阿里国际在AI领域的持续投入和人才培养初见成效 (来源: 量子位)

dstack发布分布式训练快速互连设置指南: dstack为在NVIDIA或AMD集群上进行分布式训练的用户提供了一份简明指南,介绍如何通过dstack设置快速互连。该指南旨在帮助用户在云端或本地扩展AI工作负载时优化网络性能 (来源: algo_diver)
AssemblyAI分享10个提升LLM提示技巧的视频: AssemblyAI通过YouTube视频分享了10个改进大型语言模型(LLM)提示(prompting)效果的技巧,旨在帮助用户更有效地与LLM交互以获得期望的输出 (来源: AssemblyAI)
LangGraph.js学习资源集合“awesome-langgraphjs”受关注: Brace创建并维护了一个名为“awesome-langgraphjs”的GitHub仓库,收集了使用LangGraph.js构建的开源项目和YouTube视频教程。该资源为想要学习和使用LangGraph.js构建从多智能体系统到全栈聊天应用等各类应用的开发者提供了便利 (来源: LangChainAI)
💼 商业
阿里AI战略转型显效,云业务与AI产品收入增长显著: 阿里巴巴2025年Q4财报显示,剔除特定业务后整体收入同比增长10%,云智能业务收入增长18%,其中AI相关产品收入连续7季度保持三位数同比增长。阿里将AI视为核心战略,计划未来三年投入超3800亿元升级云计算和AI基础设施。其开源的通义千问Qwen-3模型登顶多个全球榜单,衍生模型超10万个,显示其技术实力和开源生态的活力。阿里正加速AI在汽车、通信、金融等行业的落地 (来源: 36氪)
视频编辑应用Mojo被Dailymotion收购: 视频编辑应用Mojo (@mojo_video_app) 已被Dailymotion收购。Mojo的视频编辑技术将被整合到Dailymotion的社交应用和B2B产品中,双方旨在共同打造欧洲下一代社交视频平台 (来源: ClementDelangue)
Cohere收购Ottogrid,增强企业AI能力: AI公司Cohere宣布收购初创公司Ottogrid。此次收购预计将增强Cohere在企业级AI解决方案方面的能力,但具体交易细节和Ottogrid的技术方向未详细披露 (来源: aidangomez, nickfrosst)

🌟 社区
AI Agent引发工作方式变革讨论,未来或如即时战略游戏: Will Depue提出未来工作可能演变成类似《星际争霸》或《帝国时代》的模式,人类指挥约200个微型智能体处理任务、收集信息、设计系统等。Sam Altman转发认同。Fabian Stelzer则戏称这是“虫族爆兵式编码”(Zerg rush coded)。这种观点反映了社区对AI Agent将如何重塑工作流程和人机协作模式的畅想与讨论 (来源: willdepue, sama, fabianstelzer)
xAI的Grok机器人回复引发争议,提示词被指遭未授权修改: xAI承认其在X平台上的Grok响应机器人的提示词在5月14日凌晨被未经授权修改,导致其对某些事件(如涉及特朗普的事件)的分析显得异常或与主流信息不符。社区对此事高度关注,Clement Delangue等人呼吁Grok开源以增加透明度。Colin Fraser等用户通过对比Grok不同时间的回复,试图逆向工程其系统提示词的修改历史 (来源: ClementDelangue, menhguin, colin_fraser)

Meta Llama4团队传大量离职,引发社区对开源AI前景担忧: 社区消息指Meta的Llama4团队约80%成员(原14人团队离职11人)已经辞职,且其旗舰模型Behemoth发布推迟。此事引发广泛关注,Nat Lambert等业内人士对此表示惋惜。Scaling01评论称Meta可能需要新的Llama市场总监。TeortaxesTex等用户则担忧这对开源AI发展可能造成负面影响,甚至讨论中国是否会成为开源的最后希望 (来源: teortaxesTex, Dorialexander, scaling01)

AI在战争中的应用及伦理问题引关注: Reddit社区讨论AI在战争中的应用,指出其已用于监视和定位战斗人员,通过分析信息提供军事情报。讨论提及美国军方自1991年起便使用DART等AI工具。用户担忧AI武器化可能带来的致命风险及对人类的潜在威胁,并关注相关国际条约和措施的制定情况。OpenAI的使用指南中也移除了禁止军事用途的条款,引发进一步思考 (来源: Reddit r/ArtificialInteligence)
大型语言模型在CCPC编程竞赛中表现不佳,暴露当前局限性: 在第十届中国大学生程序设计竞赛(CCPC)决赛中,字节Seed-Thinking等多个知名大语言模型(包括o3/o4, Gemini 2.5 pro, DeepSeek R1)表现不佳,大多仅解出签到题或挂零。官方人员解释称模型纯自主尝试,未进行人工干预。社区分析认为,这暴露了当前大模型在解决高度创新和复杂算法问题上的短板,尤其在非Agentic(即无工具辅助执行和调试)模式下。与OpenAI o3在IOI竞赛中通过Agentic训练取得金牌形成对比 (来源: WeChat)

DSPy框架与“苦涩的教训”引发讨论,强调规范设计与自动化提示: DSPy相关的讨论强调,虽然AI的规模化发展(Scaling)可以绕过许多工程难题(“苦涩的教训”),但它不能替代对问题核心规范(需求与信息流)的仔细设计。然而,规模化可以提升定义问题的抽象层次。自动化提示(如prompt optimizers)被视为符合“苦涩的教训”的利用计算能力的方法,而人工提示则可能违背,因其注入了人类直觉而非让模型学习 (来源: lateinteraction, lateinteraction)
AI Agent在推理时进行自我检查/工具探索的计算成本受关注: Paul Calcraft提问关于在推理阶段投入大量计算资源(如200美元以上解决单个问题)用于AI Agent进行积极的自我检查、工具使用和探索性工作流的实践情况。他指出像Devin及其竞争者可能为公关演示这么做,但对于寻求新颖解决方案的场景(类似FunSearch但更少约束)则不明确 (来源: paul_cal)
AI辅助“氛围编程” (Vibe Coding) 引发讨论: GitHub Copilot等工具使得“氛围编程”(Vibe Coding,指更依赖直觉和AI辅助而非严格规划的编程方式)成为可能,甚至有16岁学生使用Copilot完成学校项目。社区对此现象看法不一,有人认为这是一种新的编程范式,也有人强调基础和规范的重要性 (来源: Reddit r/ArtificialInteligence, nrehiew_)
Hugging Face Transformers库启用新社区看板: Hugging Face为其核心库Transformers开设了新的社区看板,用于发布公告、新功能介绍、路线图更新,并欢迎用户就库使用或模型问题进行提问和讨论,旨在加强与开发者的互动和支持 (来源: TheZachMueller, ClementDelangue)
AI开发者呼吁顶级会议增设”Findings”论文轨道: 鉴于NeurIPS等顶级AI会议投稿量激增(如NeurIPS达25000篇),Dan Roy等人呼吁效仿ACL等会议设立”Findings”性质的论文轨道。这旨在为那些虽未达到主会标准但仍有价值的研究提供发表机会,减轻评审压力,并促进更广泛的学术交流。提议包括轻量级评审,聚焦提升论文清晰度等 (来源: AndrewLampinen)
💡 其他
AI驱动外骨骼助轮椅使用者站立行走: 一款AI驱动的外骨骼设备展示了其帮助轮椅使用者重新站立和行走的能力。这类技术融合了机器人技术、传感器和AI算法,通过感知用户意图并提供动力辅助,为行动不便人士带来了康复和生活质量改善的希望 (来源: Ronald_vanLoon)
利用AI将用户名称创意可视化: Reddit和X社区出现一股小热潮,用户纷纷使用AI图像生成工具(如ChatGPT内置的DALL-E 3)根据自己的社交媒体用户名创作概念图像,并分享这些充满想象力的作品,展示了AI在个性化创意表达方面的趣味应用 (来源: Reddit r/ChatGPT, Reddit r/ChatGPT)

亚马逊广告利用AI提升品牌出海营销效率: 亚马逊广告推出“世界公屏实验室”概念,展示其如何利用AI技术赋能中国品牌出海。通过Prime Video等媒体矩阵扩大品牌触达,利用AI创意工作室(如视频生成工具)降低内容制作门槛,并通过亚马逊DSP和Performance+等工具优化广告投放与转化。AI在其中扮演了从创意生成到效果衡量的全链路角色,旨在帮助品牌主,特别是中小企业,更高效地进行全球化品牌建设 (来源: 36氪)
