
关键词:AlphaEvolve, Claude Sonnet, AI监管, GPT-4.1, Meta FAIR, Seed1.5-VL, Qwen3, Phi-4-reasoning, Gemini驱动的编码智能体, 矩阵乘法算法优化, 数据中心效率优化, 多语言多模态模型, 去中心化AI训练网络
🔥 聚焦
谷歌DeepMind发布AlphaEvolve:Gemini驱动的编码智能体,革新算法发现: 谷歌DeepMind推出AlphaEvolve,一个由Gemini驱动的AI编码智能体,旨在通过结合大型语言模型的创造力与自动化评估器来发现和优化复杂算法。AlphaEvolve已成功设计出更快的矩阵乘法算法,解决了如Erdős最小重叠问题和接吻数问题等开放数学难题,并在谷歌内部用于优化数据中心效率(平均回收0.7%的计算资源)、芯片设计和加速Gemini自身训练,展现了AI在科学发现和工程优化方面的巨大潜力。 (来源: GoogleDeepMind, DeepLearning.AI Blog)
Anthropic即将发布Claude Sonnet与Opus新模型,强化推理与工具调用能力: 据The Information报道,Anthropic计划在未来几周内推出Claude Sonnet和Claude Opus的新版本。新模型的核心特性是能在“思考模式”和“工具使用模式”间灵活切换,当使用外部工具(如应用程序、数据库)解决问题遇阻时,模型能主动返回“推理模式”反思并自我纠正。在代码生成方面,新模型能自动测试生成的代码,若发现错误则会暂停、思考并修正。这一“思考—行动—反思”的闭环有望显著提升模型解决复杂问题的能力与可靠性。 (来源: steph_palazzolo, dotey)

美国共和党议员提议10年内禁止联邦及州层面AI监管,引发激烈讨论: 美国共和党议员在预算协调法案中加入条款,提议在未来十年内禁止联邦和州政府对人工智能模型、系统或自动化决策系统进行监管,并计划拨款5亿美元支持AI商业化及在联邦政府IT系统中的应用。此举被部分科技界人士视为保护AI创新、防止法规扼杀的积极信号,但也引发了对DeepFake泛滥、数据隐私失控、AI伦理及环境影响等潜在风险的担忧。该提案若通过,将对现有及未来的AI立法产生重大影响。 (来源: Reddit r/ArtificialInteligence, Yoshua_Bengio)

OpenAI发布GPT-4.1模型并上线安全评估中心,强调编码与指令遵循能力: OpenAI宣布,应用户要求,GPT-4.1模型即日起在ChatGPT中可用(Plus、Pro、Team用户,企业版和教育版稍后)。GPT-4.1专为编码任务和指令遵循优化,速度更快,可作为o3和o4-mini的日常编码替代品。同时,GPT-4.1 mini将替代所有用户当前使用的GPT-4o mini。此外,OpenAI推出了安全评估中心(Safety Evaluations Hub),用于公开其模型的安全测试结果及指标,并会定期更新,以提高安全性沟通的透明度。 (来源: openai, michpokrass)
Meta FAIR发布多项AI科研成果,聚焦分子发现与原子建模: Meta AI(FAIR)宣布了在分子特性预测、语言处理和神经科学领域的最新开源版本。其中包括Open Molecules 2025 (OMol25),一个用于大型原子系统模拟的分子发现数据集;Universal Model for Atoms (UMA),一个可广泛应用于材料和分子原子相互作用建模的机器学习原子间势模型;以及Adjoint Sampling,一种基于标量奖励训练生成模型的可扩展算法。此外,FAIR与罗斯柴尔德基金会医院合作研究揭示了人类与LLM在语言发展上的显著相似性。 (来源: AIatMeta)
🎯 动向
字节跳动发布Seed1.5-VL视觉语言大模型,20B激活参数性能卓越: 字节跳动推出了其视觉-语言多模态大模型Seed1.5-VL,该模型在仅有20B激活参数的情况下,展现出与Gemini 2.5 Pro相当的性能,并在60项公开评测基准中的38项取得SOTA。Seed1.5-VL增强了通用多模态理解和推理能力,特别在视觉定位、推理、视频理解和多模态智能体方面表现突出。模型已在火山引擎开放API,推理输入价格为0.003元/千tokens,输出为0.009元/千tokens。 (来源: 机器之心)

Qwen3技术报告揭秘:融合思考与非思考模式,大模型蒸馏小模型: 阿里巴巴发布Qwen3系列模型技术报告,包含0.6B至235B参数的8款模型。核心创新在于双重工作模式,模型能根据任务复杂性自动切换“思考模式”(复杂推理)和“非思考模式”(快速应答),通过“思考预算”参数动态分配计算资源。训练采用三阶段预训练(通用知识、推理增强、长文本)和四阶段后训练(长思维链冷启动、推理强化学习、思维模式融合、通用强化学习)。同时采用“大带小”数据蒸馏策略,利用教师模型(如235B)输出训练学生模型(如30B),实现知识迁移。 (来源: 36氪)

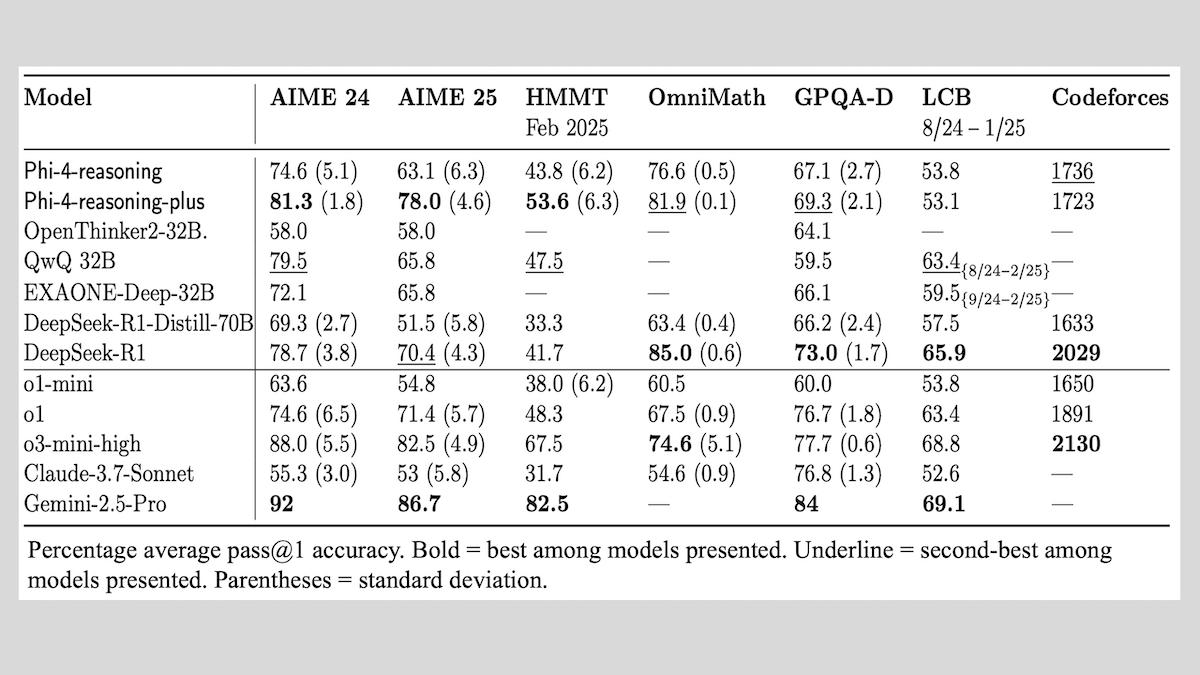
微软发布Phi-4-reasoning系列模型,分享推理模型训练经验: 微软推出了Phi-4-reasoning、Phi-4-reasoning-plus(均为14B参数)和Phi-4-mini-reasoning(3.8B参数)三款模型,并公开了其训练方法与经验。这些模型通过对预训练模型的微调,专注于提升数学推理等能力。例如,Phi-4-reasoning-plus通过强化学习在数学问题上表现优异,Phi-4-mini-reasoning则分阶段进行SFT和RL微调。报告分享了小模型训练中可能出现的不稳定性及应对策略,以及大模型RL训练中关于数据选择和奖励函数设计的考量。模型权重已在Hugging Face开放,遵循MIT许可。 (来源: DeepLearning.AI Blog)
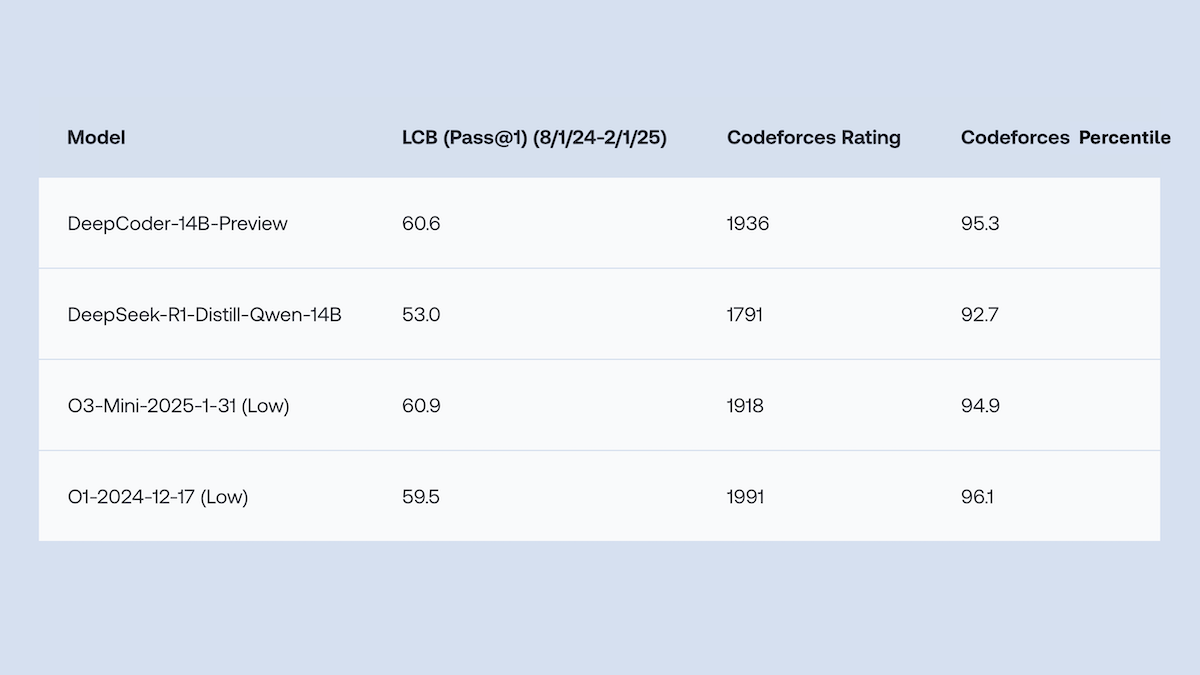
Together.AI与Agentica开源DeepCoder-14B-Preview,代码生成性能媲美o1: Together.AI和Agentica团队发布了DeepCoder-14B-Preview,一个14B参数的代码生成模型,其性能在多个编码基准上与DeepSeek-R1及OpenAI o1等更大模型相当。该模型通过对DeepSeek-R1-Distilled-Qwen-14B进行微调,采用了简化的强化学习方法(结合GRPO和DAPO的优化),并改进了RL库Verl的并行处理能力,显著缩短了训练时间。模型权重、代码、数据集及训练日志均以MIT许可证开源。 (来源: DeepLearning.AI Blog)
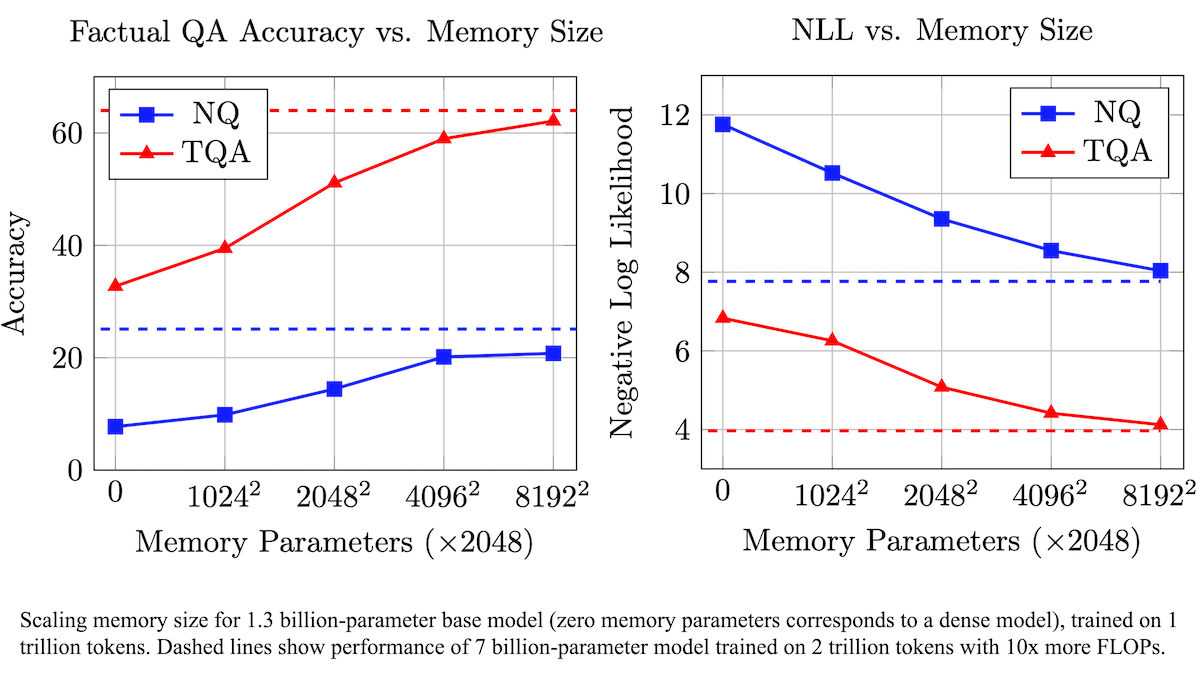
Meta提出可训练记忆层增强LLM事实准确性,降低计算需求: Meta的研究人员通过为Transformer架构增加可训练的记忆层,提升了大型语言模型在事实回忆方面的准确性,同时无需显著增加计算量。该方法通过学习键和对应值来存储信息,并采用将键分解为两个半键的策略,有效解决了大规模键检索时的计算瓶颈。实验表明,配备记忆层的8B参数模型在多个问答数据集上表现优于无记忆层的同类模型,显示出在预训练数据和计算量需求上的优势。 (来源: DeepLearning.AI Blog)
阿里巴巴开源Wan2.1系列视频基础模型,支持文本/图像到视频生成及编辑: 阿里巴巴发布了Wan2.1,一套全面的开源视频基础模型套件,包括1.3B和14B参数版本,采用Apache 2.0许可证。Wan2.1在文本到视频、图像到视频、视频编辑、文本到图像以及视频到音频等多种任务上表现出色,并特别支持中英文文本的视觉生成。其T2V-1.3B模型仅需8.19GB显存,可在消费级GPU上运行,4分钟内可生成5秒480P视频。配套的Wan-VAE能高效编解码1080P视频,保留时序信息。 (来源: _akhaliq, Reddit r/LocalLLaMA)

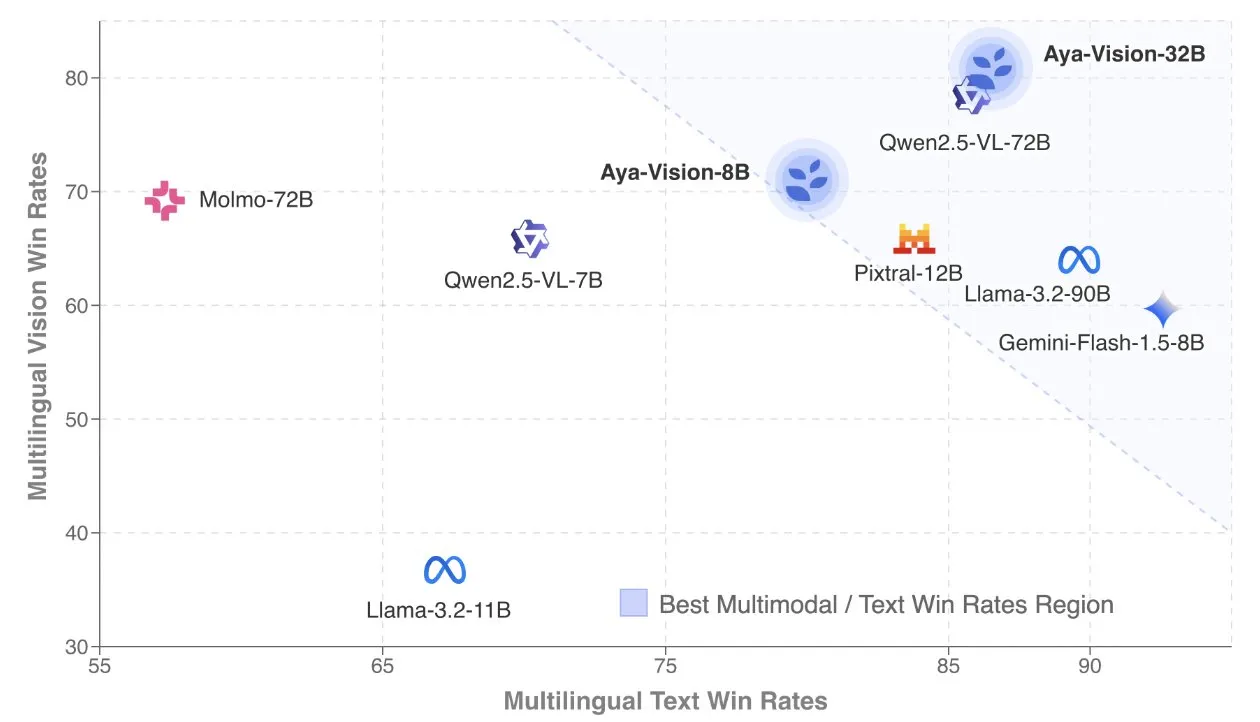
Cohere发布Aya Vision技术报告,专注多语言多模态模型: Cohere Labs公开了Aya Vision技术报告,详细介绍了其构建SOTA多语言多模态模型的配方。Aya Vision模型旨在统一23种语言在多模态和文本任务中的能力。报告探讨了合成多语言数据框架、架构设计、训练方法、跨模态模型合并以及在开放式、多语言生成任务上的全面评估。其8B模型在性能上优于Pixtral-12B等更大模型,而32B模型效率更高,超越了Llama3.2-90B等两倍以上大小的模型。 (来源: sarahookr, Cohere Labs)
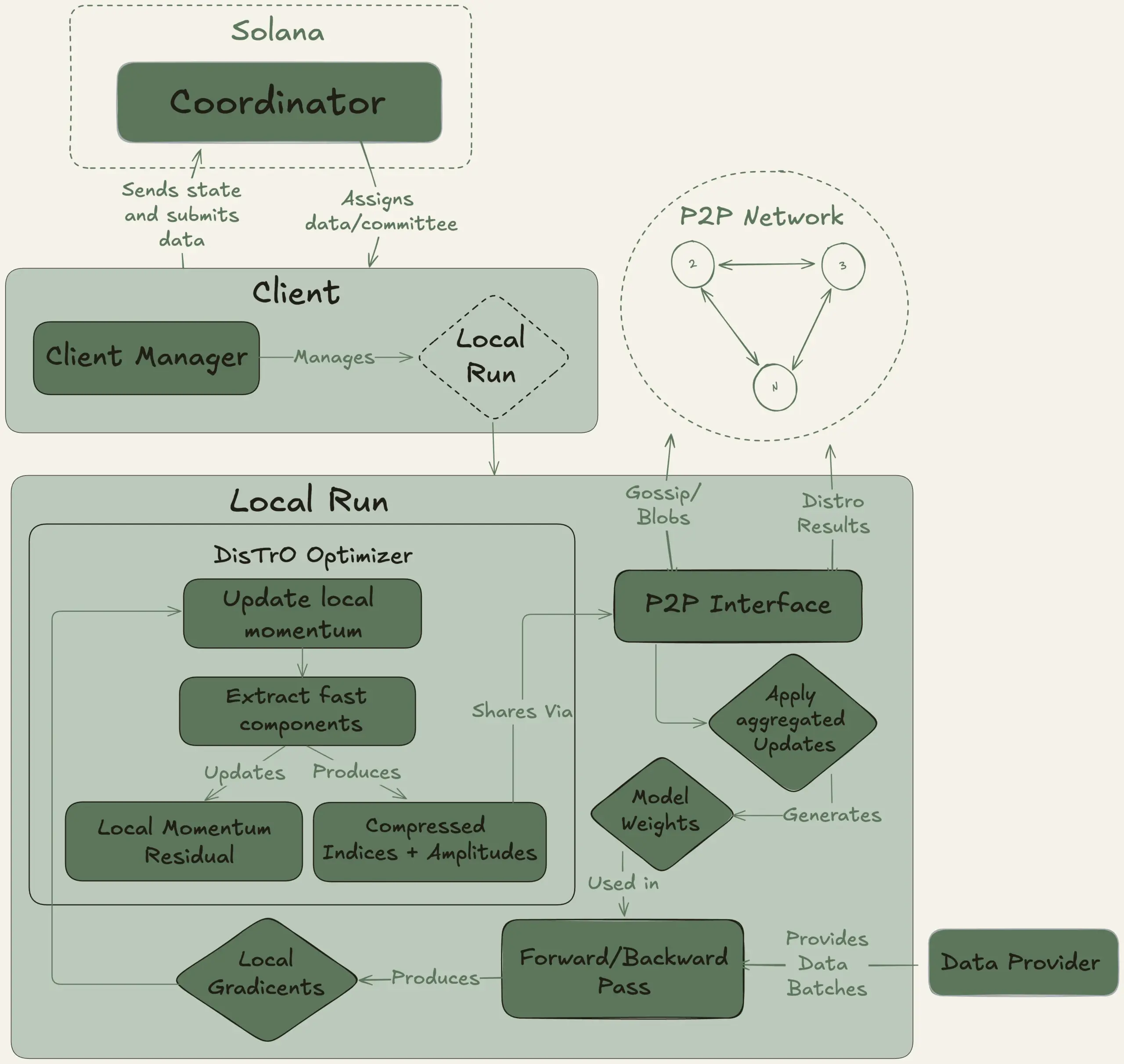
Nous Research启动Psyche项目,旨在去中心化训练40B参数大模型: Nous Research宣布启动Psyche网络,一个去中心化AI训练网络,旨在集合全球算力共同训练强大的AI模型,使个人和小型社区也能参与大规模模型开发。其测试网已开始预训练一个40B参数的LLM,采用MLA架构,数据集包含FineWeb (14T)、部分FineWeb-2 (4T)及The Stack v2 (1T),总计约20T tokens。该模型训练完成后,所有检查点(包括未退火和退火版本)及数据集将开源。 (来源: eliebakouch, Teknium1)
Stability AI发布开源Stable Audio Open Small模型,专注于快速文本到音频生成: Stability AI在Hugging Face上发布了Stable Audio Open Small模型,这是一款专为快速文本到音频生成而设计的模型,并采用了对抗性后训练技术。该模型旨在提供一个高效、开源的音频生成解决方案。 (来源: _akhaliq)
谷歌Gemini Advanced集成GitHub,强化编码辅助能力: 谷歌宣布Gemini Advanced现已连接GitHub,进一步提升其作为编码助手的能力。用户可以直接连接公共或私有GitHub仓库,利用Gemini生成或修改函数、解释复杂代码、针对代码库提问、进行调试等操作。通过在提示栏点击“+”按钮并选择“导入代码”,粘贴GitHub URL即可开始使用。 (来源: algo_diver)
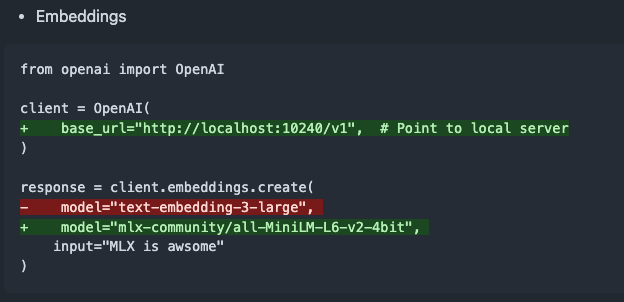
mlx-omni-server v0.4.0发布,新增embeddings服务和更多TTS模型: mlx-omni-server更新至v0.4.0版本,引入了新的/v1/embeddings服务,通过mlx-embeddings简化了嵌入生成。同时,集成了更多TTS模型(如kokoro, bark),并升级了mlx-lm以支持如qwen3等新模型。 (来源: awnihannun)
Together Chat新增PDF文件处理功能: Together Chat宣布支持PDF文件上传和处理。当前版本主要解析PDF中的文本内容并传递给模型进行处理,未来计划推出v2版本,增加OCR功能以读取PDF中的图像内容。 (来源: togethercompute)
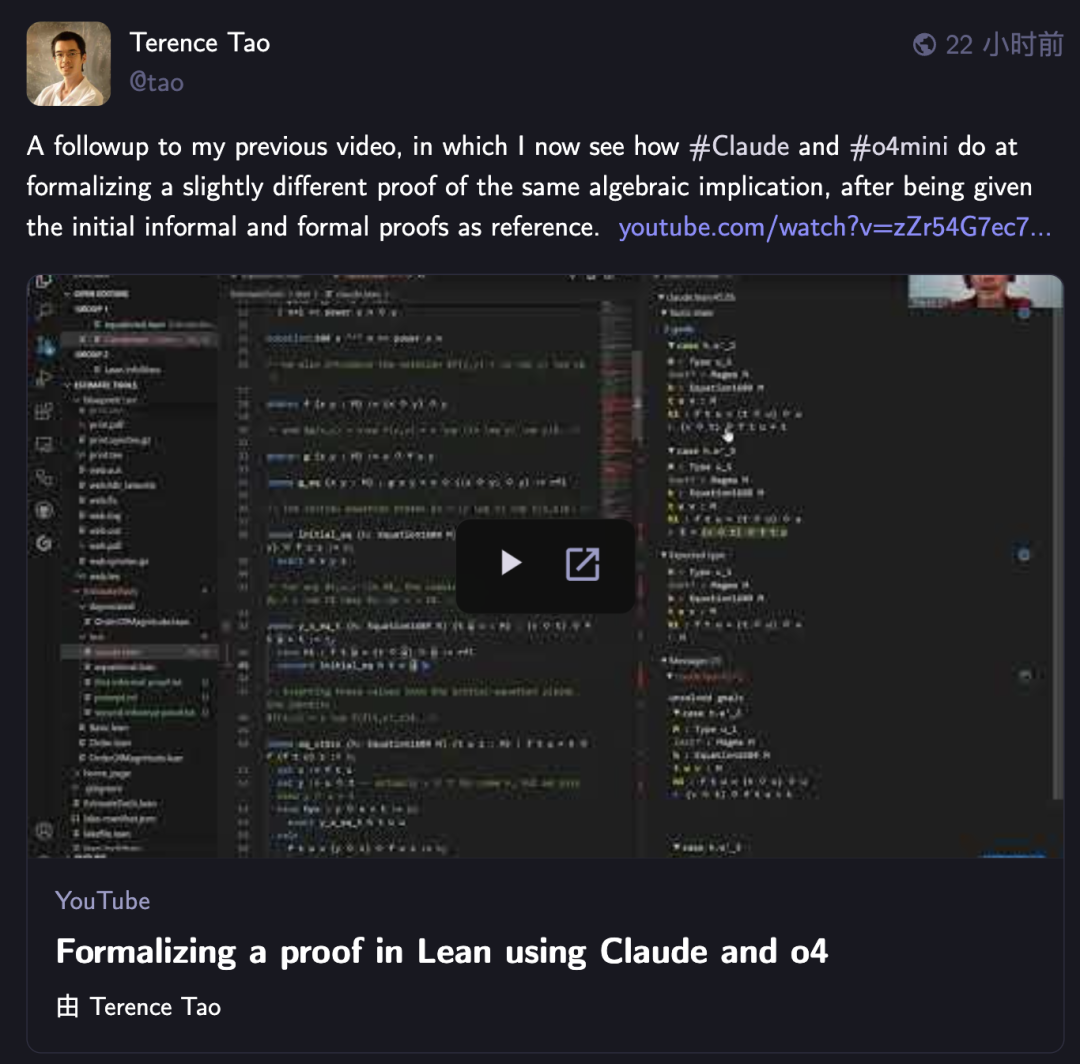
陶哲轩再用AI挑战数学形式化证明,Claude表现优于o4-mini: 数学家陶哲轩在其YouTube系列视频中,测试了AI在Lean证明助手形式化代数蕴含证明的能力。实验中,Claude能在约20分钟内完成任务,尽管在编译过程中暴露出对Lean中自然数从0开始的规则理解偏差和对称性处理问题,但通过人工干预得以修正。相比之下,o4-mini表现更为谨慎,能识别幂函数定义问题,但在关键证明步骤选择放弃,未能完成任务。陶哲轩总结,过度依赖自动化可能削弱对证明整体结构的把握,最佳自动化水平应在0%到100%之间,保留人为干预以深化理解。 (来源: 36氪)
奥特曼访谈:OpenAI的终极目标是打造核心AI订阅服务: OpenAI CEO萨姆·奥特曼在红杉资本AI Ascent 2025活动中表示,OpenAI的“柏拉图式理想”是开发一个AI操作系统,成为用户的核心AI订阅服务。他设想未来的AI模型将能处理用户一生的数据(万亿级上下文标记),实现深度个性化推理。奥特曼承认这尚处“PPT阶段”,但强调公司以灵活性和适应性为荣。他还谈到AI语音交互的潜力、2025年将是AI代理大放异彩的一年,并认为编码将是驱动模型运作和API调用的核心。 (来源: 36氪, 量子位)

Karminski3分享Qwen3-30B社区修改版,激活专家数翻倍: 开发者社区对Qwen3模型进行了修改,推出了Qwen3-30B-A6B-16-Extreme版本。通过修改模型参数,将激活专家数量从A3B增加到A6B,据称能带来轻微的质量提升,但生成速度会相应变慢。用户也可以通过修改llama.cpp的运行参数 --override-kv http://qwen3moe.expert_used_count=int:24 来实现类似效果,或反向操作减少Qwen3-235B-A22B的激活量以提速。 (来源: karminski3)

🧰 工具
OpenMemory MCP发布:本地运行的共享记忆系统,打通多款AI工具: mem0ai团队推出了OpenMemory MCP,一个基于开放模型上下文协议(MCP)构建的私有内存服务器。它支持100%本地运行,旨在解决当前AI工具(如Cursor, Claude Desktop, Windsurf, Cline)间上下文信息不共享、会话结束即丢失记忆的问题。用户数据存储在本地,确保隐私安全。OpenMemory MCP提供标准化的记忆操作API(增删查改),并设有集中式仪表板供用户管理记忆和客户端访问权限,通过Docker简化部署。 (来源: 36氪, AI进修生)

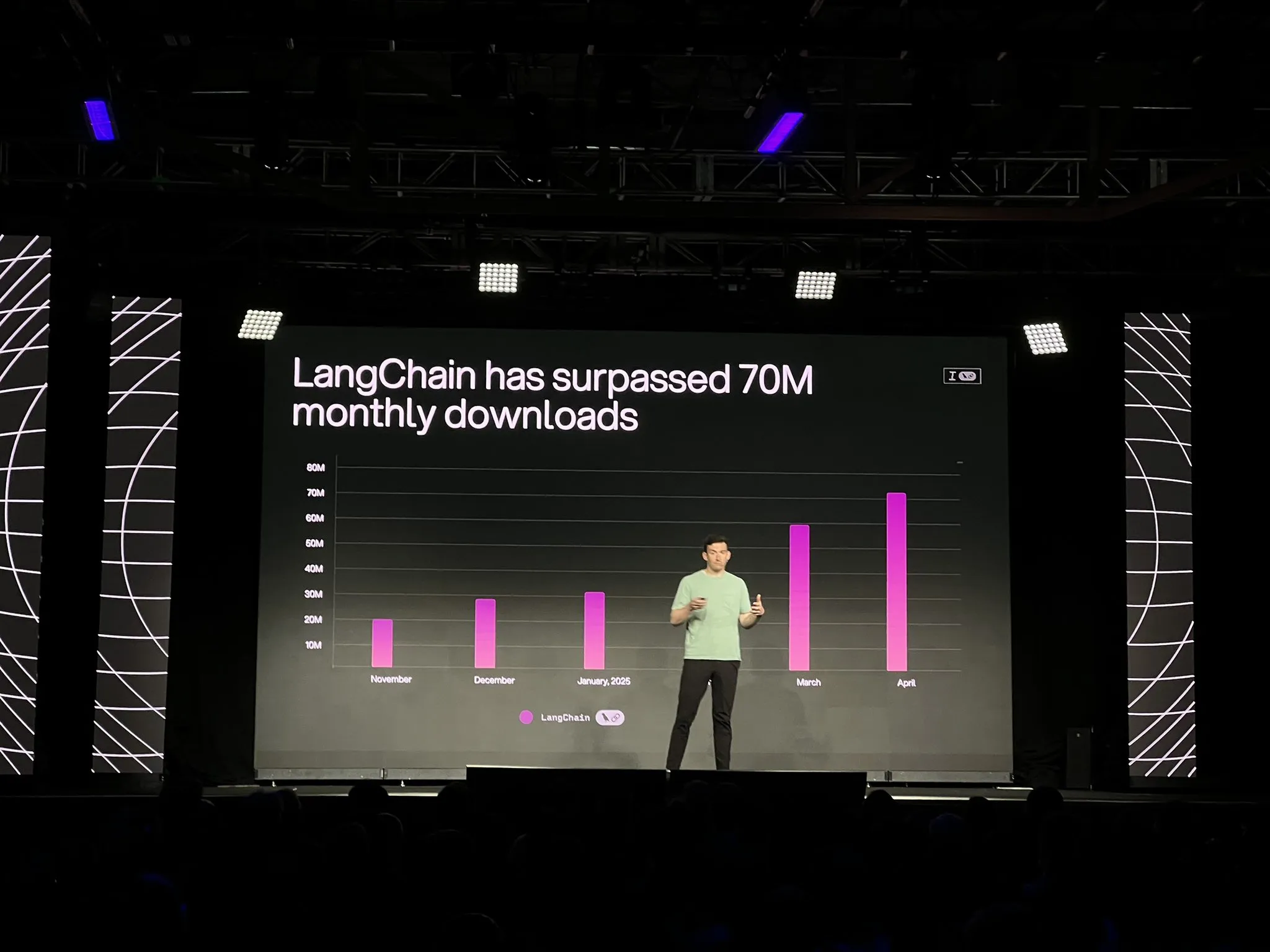
LangChain推出LangGraph平台正式版及多项更新,强化AI智能体开发与可观测性: LangChain在Interrupt大会上宣布其LangGraph平台正式通用可用(GA),该平台专为构建和管理长时运行、有状态的AI智能体工作流设计,支持一键部署、水平扩展及内存、人机交互(HIL)、对话历史等API。同时发布的LangGraph Studio V2,作为智能体IDE,支持本地运行、直接编辑配置、集成Playground,并能拉取生产环境追踪数据进行本地调试。此外,LangChain还推出了开源无代码智能体构建平台Open Agent Platform (OAP),并增强了LangSmith在工具调用和轨迹方面的智能体可观测性。 (来源: LangChainAI, hwchase17)
PatronusAI发布Percival:能评估并修复其他AI智能体的AI智能体: PatronusAI推出了Percival,号称首个能够评估并自动修复其他AI智能体错误的AI智能体。Percival不仅能检测智能体追踪记录中的故障,还能提出修复建议。据称,在包含GAIA和SWE-Bench人为标注错误的TRAIL数据集上,Percival的性能比SOTA LLM高出2.9倍。其功能包括自动建议智能体提示词修复方案,捕获超过20种智能体故障类型(涵盖工具使用、规划协调、领域特定错误等),并将手动调试时间从数小时缩短至1分钟以内。 (来源: rebeccatqian, basetenco)
PyWxDump:微信信息获取与导出工具,支持AI训练: PyWxDump是一个Python工具,用于获取微信账号信息(昵称、账号、手机、邮箱、数据库密钥),解密数据库,本地查看聊天记录,并能将聊天记录导出为CSV、HTML等格式,可用于AI训练、自动回复等场景。该工具支持多账户信息获取及所有微信版本,并提供了网页版UI查看聊天记录。 (来源: GitHub Trending)

Airweave:让AI智能体能搜索任何应用的工具,兼容MCP协议: Airweave是一个旨在让AI智能体能够语义化搜索任何应用程序内容的工具。它兼容模型上下文协议(MCP),可以无缝连接各种应用、数据库或API,将其内容转化为智能体可用的知识。其主要功能包括数据同步、实体提取与转换、多租户架构、增量更新、语义搜索及版本控制等。 (来源: GitHub Trending)

讯飞发布搭载viaim AI大脑的新一代AI耳机iFLYBUDS Pro3与Air2: 未来智能发布了讯飞AI会议耳机iFLYBUDS Pro3和iFLYBUDS Air2,两款耳机均搭载了全新的viaim AI大脑。viaim是一个面向个人商务办公的AI智能体,整合了端到端智能感知处理、智能Agent协同推理、实时多模态能力和数据安全隐私保护四大核心模块。耳机支持便捷记录(通话、现场、音视频录音)、AI助理(自动生成标题摘要、针对性提问)、多语言翻译(32种语言,同传听译、面对面翻译、通话翻译)等功能,并提升了音质和佩戴舒适度。 (来源: WeChat)

KoboldCpp Smart Launcher发布:优化LLM性能的Tensor Offload自动调优工具: 一款名为KoboldCpp Smart Launcher的GUI和CLI工具发布,旨在帮助用户自动寻找本地运行LLM时KoboldCpp的最佳Tensor Offload策略。通过更细粒度地在CPU和GPU间分配张量(而非整个层),该工具据称可以在不增加VRAM需求的情况下,将生成速度提高一倍以上。例如,QwQ Merge在12GB VRAM GPU上速度从3.95 t/s提升至10.61 t/s。 (来源: Reddit r/LocalLLaMA)
OpenBMB开源AgentCPM-GUI:首个针对中文优化的设备端GUI智能体: OpenBMB团队开源了AgentCPM-GUI,这是首款专为中文应用优化的设备端GUI(图形用户界面)智能体。该智能体通过强化微调(RFT)增强了推理能力,采用了紧凑的动作空间设计,并具备高质量的GUI定位(grounding)能力,旨在提升在中文环境下操作各种应用的用户体验。 (来源: Reddit r/LocalLLaMA)
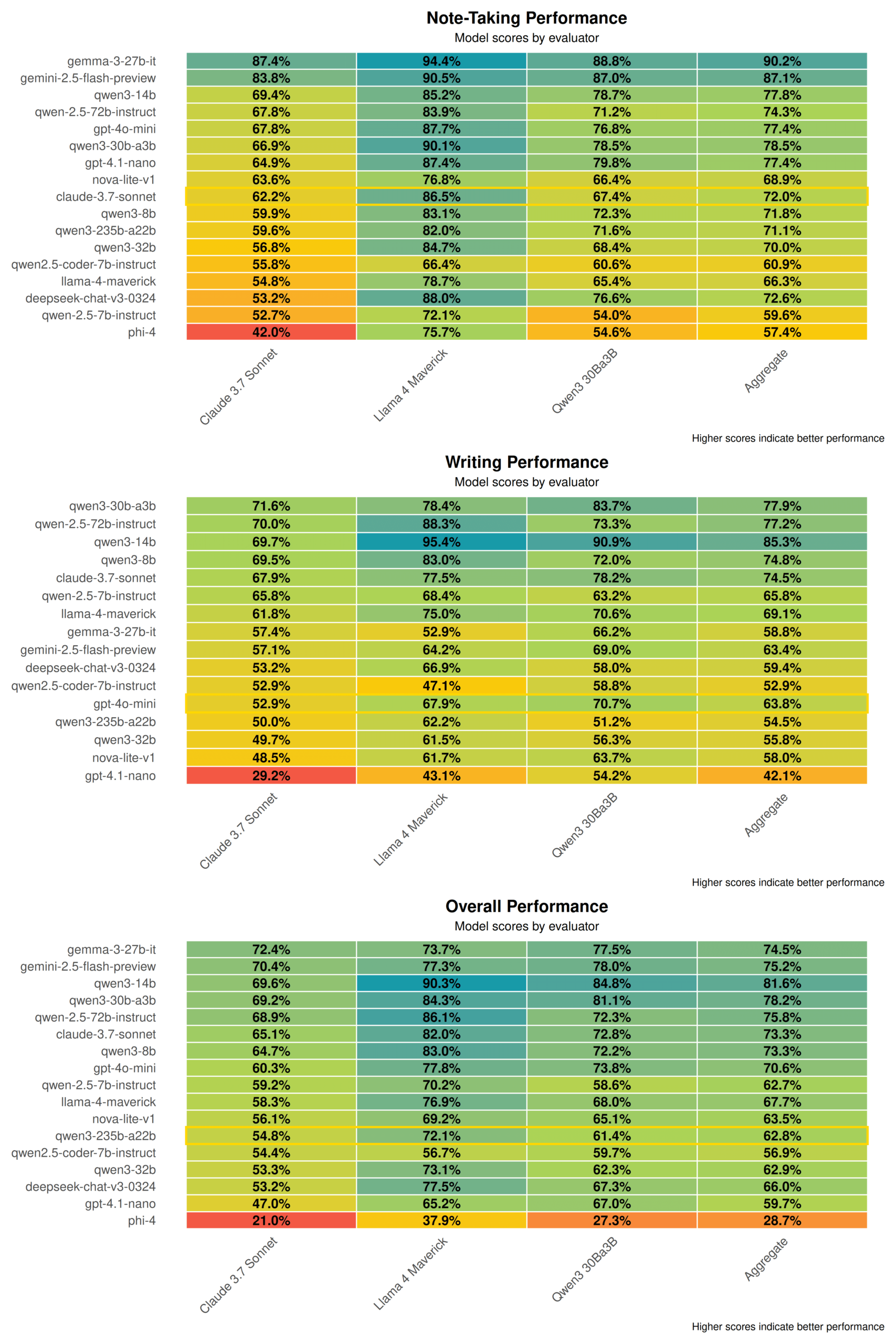
MAESTRO:本地优先的AI研究应用,支持多智能体协作与自定义LLM: MAESTRO (Multi-Agent Execution System & Tool-driven Research Orchestrator) 是一款新发布的AI驱动研究应用,强调本地控制和能力。它提供模块化框架,包括文档提取、强大的RAG流程和多智能体系统(规划、研究、反思、写作),可处理复杂研究问题。用户可通过Streamlit Web UI或CLI进行交互,使用自己的文档集和选择的本地或API LLM。 (来源: Reddit r/LocalLLaMA)
Contextual AI推出专为RAG优化的文档解析器: Contextual AI发布了一款新的文档解析器,专为检索增强生成(RAG)系统设计。该工具旨在通过结合视觉、OCR和视觉语言模型,提供高准确度的复杂非结构化文档解析,能够保留文档层级结构,处理表格、图表和图形等复杂模态,并提供边界框和置信度以便用户审计,从而减少RAG系统因解析失败导致的上下文缺失和幻觉。 (来源: douwekiela)
Gradio新增ImageEditor撤销/重做功能: Gradio的ImageEditor组件现已增加撤销(undo)和重做(redo)按钮,为用户提供了类似专业付费应用的Python图像编辑功能,增强了交互性和易用性。 (来源: _akhaliq)
RunwayML推出References新功能,支持零样本材质、服装、地点和姿势测试: RunwayML的References功能得到更新,用户可以使用传统3D材质球预览图作为输入,将其材质应用到任意物体上,实现零样本的材质迁移和可视化。此外,新功能还支持对服装、地点和角色姿势进行零样本测试,扩展了创意生成和快速原型设计的可能性。 (来源: c_valenzuelab, c_valenzuelab)

秘塔AI推出“今天学点啥”功能,AI辅助结构化学习: 秘塔AI上线“今天学点啥”新功能,旨在将AI从信息检索和文档处理的助手角色,转变为能够主动引导和教学的“AI老师”。用户上传或搜索资料后,该功能可自动生成系统化、结构化的视频课程及PPT讲解,帮助用户梳理知识点,并支持根据用户水平选择不同讲解深度(初学者/专家)和风格(讲故事/暴躁老哥等)。此外,还支持中途提问和课后测试。 (来源: WeChat)

📚 学习
吴恩达与Anthropic合作推出新课程:使用MCP构建富上下文AI应用: 吴恩达的DeepLearning.AI与Anthropic合作推出新课程“MCP: Build Rich-Context AI Apps with Anthropic”,由Anthropic技术教育主管Elie Schoppik授课。课程聚焦模型上下文协议(MCP),一个旨在标准化LLM访问外部工具、数据和提示的开放协议。学员将学习MCP的核心架构,创建MCP兼容聊天机器人,构建和部署MCP服务器,并将其连接到Claude驱动的应用及其他第三方服务器,以简化富上下文AI应用的开发。 (来源: AndrewYNg, DeepLearningAI)
FlashInfer:MLSys 2025最佳论文,高效可定制的LLM推理注意力引擎: 由华盛顿大学叶子豪(Zihao Ye)、英伟达、OctoAI陈天奇等人合作的FlashInfer项目荣获MLSys 2025最佳论文奖。FlashInfer是一个为LLM推理服务优化设计的高效可定制注意力引擎,通过优化内存访问(采用块稀疏格式和可组合格式处理KV缓存)、提供基于JIT编译的灵活注意力计算模板以及引入负载均衡的任务调度机制,显著提升了LLM推理性能,已集成到vLLM、SGLang等项目中。 (来源: 机器之心)
ICML 2025论文:从数据操作视角为图提示(Graph Prompting)提供理论分析: 香港中文大学王群中、孙相国博士和程鸿教授在ICML 2025发表论文,首次从“数据操作”视角为图提示的有效性提供了系统性理论框架。研究引入“桥接图”概念,证明图提示机制在理论上等价于对输入图数据进行某种操作,使其能被预训练模型正确处理以适应新任务。论文推导了误差上界,分析了误差来源与可控性,并对误差分布进行了建模,为图提示的设计和应用提供了理论基础。 (来源: WeChat)
ICML 2025论文:通过Token级编辑合成文本数据以避免模型崩溃: 上海交通大学等机构的研究团队在ICML 2025发表论文,探讨了合成数据导致“模型崩溃”的问题,并提出一种名为“Token-Level Editing”的数据生成策略。该方法通过在真实数据上对模型“过度自信”的Token进行微编辑替换,而非完全生成新文本,旨在构建结构更稳定、泛化性更强的半合成数据。理论分析表明,此方法能有效约束测试误差,避免模型性能随迭代轮次增长而崩溃。实验在预训练、持续预训练和监督微调阶段均验证了该方法的有效性。 (来源: WeChat)

ICML 2025论文:OmniAudio,从360°全景视频生成3D空间音频: OmniAudio团队在ICML 2025展示了一项从360°全景视频直接生成一阶环绕声(FOA)空间音频的技术。为解决数据稀缺问题,团队构建了大规模360V2SA数据集Sphere360(超10万片段,288小时)。OmniAudio采用两阶段训练:自监督的coarse-to-fine流匹配预训练,先用普通立体声音频转伪FOA训练,再用真实FOA精调;然后结合双分支视频编码器进行有监督微调,提取全局和局部视角特征,生成高保真、方向准确的空间音频。 (来源: 量子位)

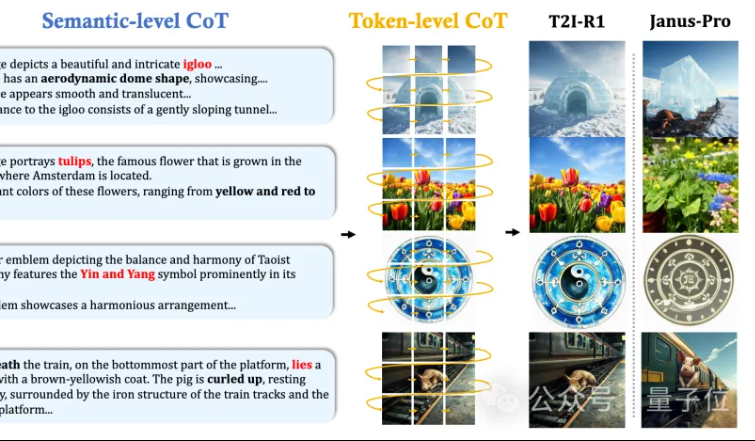
港中文MMLab提出T2I-R1:为文生图引入双层级CoT推理与强化学习: 香港中文大学MMLab团队发布T2I-R1,首个基于强化学习的推理增强文生图模型。该模型创新性地提出双层级思维链(CoT)推理框架:Semantic-CoT(文本推理,规划图像全局结构)和Token-CoT(图像Token逐块生成,专注底层细节)。通过BiCoT-GRPO强化学习方法,在一个统一LMM(Janus-Pro)中协同优化这两个CoT层次,无需额外模型。奖励模型采用多个视觉专家模型集成,确保评估的可靠性并防止过拟合。实验表明,T2I-R1能更好地理解用户意图,生成更符合期望的图像,并在T2I-CompBench和WISE基准上显著优于基线模型。 (来源: 量子位, WeChat)
OpenAI发布轻量级语言模型评估库simple-evals: OpenAI开源了simple-evals,一个用于评估语言模型的轻量级库,旨在透明化其最新模型发布的准确性数据。该库强调零样本、思维链(chain-of-thought)的评估设置,并提供了在MMLU、MATH、GPQA等多个基准上的详细模型表现对比,包括OpenAI自家模型(如o3, o4-mini, GPT-4.1, GPT-4o)以及其他主要模型(如Claude 3.5, Llama 3.1, Grok 2, Gemini 1.5)。 (来源: GitHub Trending)
LLM Engineer’s Handbook韩文版发布: Maxime Labonne的《LLM工程师手册》现已推出韩文版,由Woocheol Cho翻译。该手册的俄文、中文、波兰文等更多语言版本也即将发布,为全球LLM开发者提供学习资源。 (来源: maximelabonne)

ICML 2025音频机器学习研讨会ML4Audio宣布举办: 备受欢迎的音频机器学习研讨会(ML for Audio)将在温哥华举行的ICML 2025期间回归,具体时间为7月19日(星期六)。研讨会将邀请Dan Ellis, Albert Gu, Jesse Engel, Laura Laurenti和Pratyusha Rakshit等知名学者进行演讲。论文提交截止日期为5月23日。 (来源: sedielem)
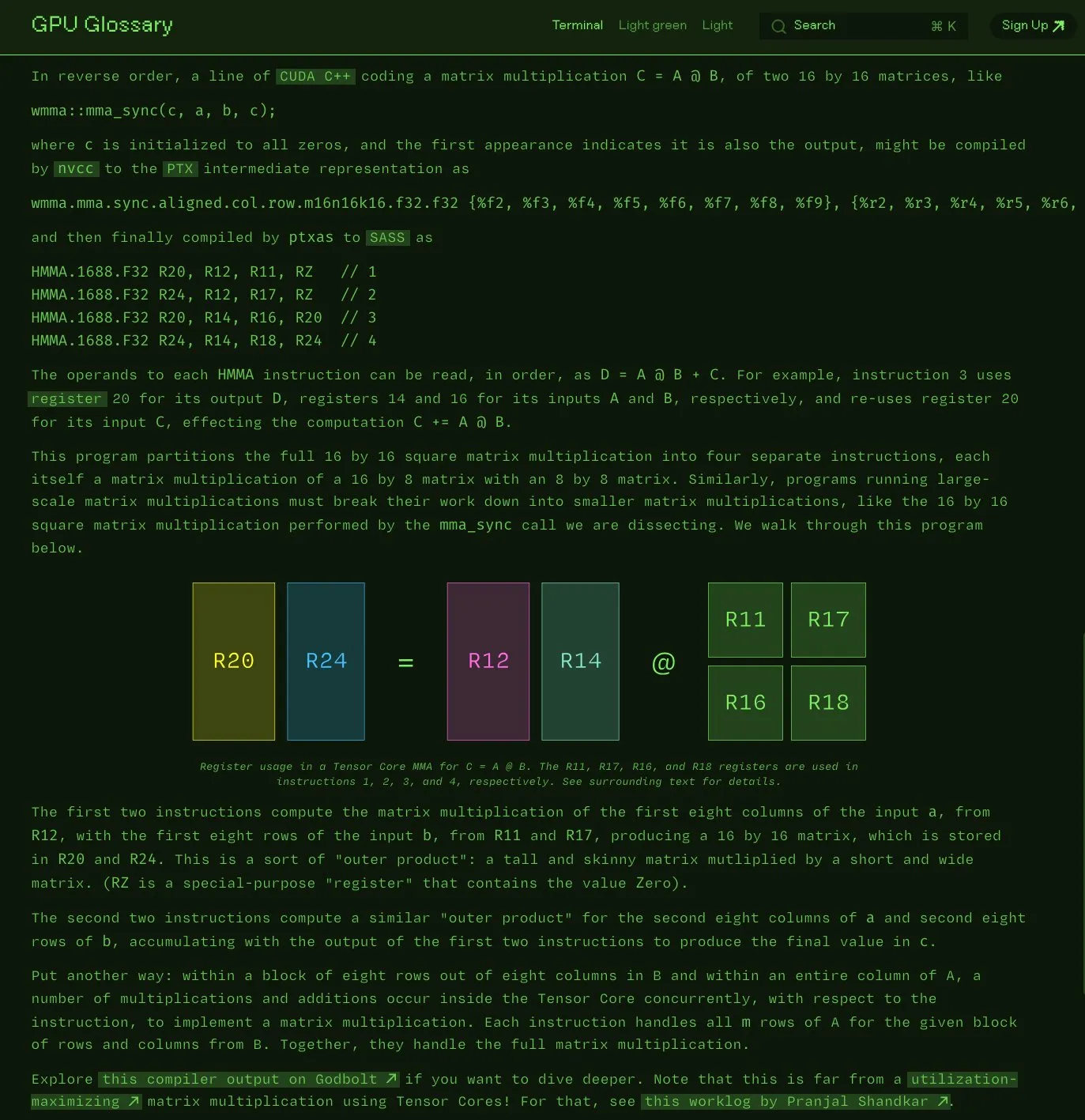
Charles Frye开源GPU术语表: Charles Frye宣布其编写的GPU术语表(GPU Glossary)现已开源。该术语表旨在帮助理解GPU硬件和编程相关概念,最近更新了关于Tensor Core执行简单矩阵乘加(mma)操作的SASS指令分解。项目托管在GitHub上,并列出了一些待完成的任务。 (来源: charles_irl)
OpenAI发布GPT-4.1提示工程指南,强调结构化与清晰指令: OpenAI推出了一份针对GPT-4.1的提示工程指南,旨在帮助用户更有效地构建提示,尤其适用于需要结构化输出、推理、工具使用和基于智能体的应用。指南强调了明确角色与目标、提供清晰指令(包括语气、格式、边界)、可选的子指令、分步推理/规划、精确定义输出格式以及使用示例的重要性,并提供了一些实用技巧如突出关键指令、使用Markdown或XML结构化输入等。 (来源: Reddit r/MachineLearning)

Kaggle与Hugging Face深化合作,简化模型调用与发现: Kaggle宣布与Hugging Face加强合作,用户现在可以直接在Kaggle Notebooks中启动Hugging Face模型,发现相关的公开代码示例,并在两个平台间无缝探索。这一集成旨在扩大模型的可访问性,让Kaggle用户更便捷地利用Hugging Face生态中的模型资源。 (来源: huggingface)
FedRAG:用于RAG系统微调的开源框架,支持联邦学习: Vector Institute研究员推出FedRAG,一个旨在简化检索增强生成(RAG)系统微调的开源框架。该框架不仅支持典型的中心化训练,还特别引入了联邦学习架构,以适应在分布式数据集上训练的需求。FedRAG与PyTorch和Hugging Face生态兼容,支持使用Qdrant作为知识库存储,并可桥接到LlamaIndex。 (来源: nerdai)

💼 商业
Cursor母公司Anysphere两年内ARR达2亿美元,估值飙升至90亿美元: 年仅25岁的MIT辍学生Michael Truell领导的Anysphere公司,凭借其AI代码编辑器Cursor,在未进行市场推广的情况下,两年内实现了2亿美元的年经常性收入(ARR),公司估值迅速达到90亿美元。Cursor通过将AI深度融入开发流程,重塑了软件开发范式,专注于服务个人开发者,获得了全球开发者的广泛认可和口碑传播。Thrive Capital领投了其最新一轮融资。 (来源: 36氪)

Databricks宣布收购Serverless Postgres公司Neon: Databricks已同意收购以开发者为中心的Serverless Postgres公司Neon。Neon以其新颖的数据库架构著称,提供速度、弹性扩展以及分支与分叉功能,这些特性对开发者和AI智能体均具吸引力。此次收购旨在共同为开发者和AI智能体打造一个开放的、Serverless的数据库基础。 (来源: jefrankle, matei_zaharia)
AI金融服务初创公司Samaya AI完成4350万美元融资: Samaya AI宣布获得由NEA领投的4350万美元融资,用于构建面向金融服务的专家AI智能体,旨在规模化变革知识工作。该公司成立于2022年,专注于为复杂金融工作流打造专用AI解决方案。其基于自研LLM的专家AI智能体已在摩根士丹利等顶级机构的数千名用户中使用,应用于尽职调查、经济建模和决策支持等场景,强调精确性、透明度和无幻觉。 (来源: maithra_raghu)
🌟 社区
AI是否会取代软件工程师?社区热议技能升级的必要性: 社交媒体上再次出现关于AI是否会取代软件工程师的讨论。普遍观点认为,AI不会完全取代软件工程师,因为软件开发远不止编码本身。然而,对于那些主要从事重复性编码工作、缺乏对系统整体理解的“代码猴子”(code monkeys),如果不能提升技能、深入理解系统架构和复杂问题解决,则面临较高的被AI辅助工具替代的风险。 (来源: cto_junior, cto_junior)
AI Agent的未来:机遇与挑战并存,行业领袖看好其潜力: OpenAI CEO奥特曼预测2025年将是AI Agent大展拳脚的一年,它们将更多地参与到实际工作中。刘志毅在其访谈中也强调,Agent正从被动工具向主动执行系统转变,其发展依赖基础模型的进步及与物理世界的交互能力。尽管目前Agent在响应速度、幻觉控制等方面仍有不足,但其自主执行任务、辅助大模型学习的能力被广泛看好,已在智能客服、金融投顾等领域开始应用。 (来源: 36氪, 量子位)

Perplexity AI与PayPal、Venmo达成合作,整合电商与旅行支付: Perplexity AI宣布将与PayPal和Venmo合作,在其平台的电商购物、旅行预订以及语音助手和即将推出的浏览器Comet中集成支付功能。此举旨在简化从浏览、搜索、选择到安全支付的整个商业流程,提升用户体验。 (来源: AravSrinivas, perplexity_ai)
关于AI模型评估的讨论:IFEval和ChartQA受关注,需警惕训练数据污染: 社区讨论中,IFEval因其简单而巧妙的设计被认为是优秀的指令遵循评估基准之一。与此同时,有用户指出ChartQA测试数据存在噪声、答案模糊及不一致等问题,可能需要被淘汰。Vikhyatk提醒,许多声称在基准测试上取得高准确率的模型可能存在训练数据污染问题而未被察觉。 (来源: clefourrier, vikhyatk)

AI生成内容版权与道德引关注:Audible计划使用AI旁白,AI生成人物用于网络交友引担忧: Audible宣布计划使用AI生成旁白来制作有声读物,旨在“将更多故事带给生活”,引发关于AI在创意产业应用的讨论。另一方面,Reddit上有用户发帖称其母亲在约会网站上与疑似AI生成的“真实男性”形象互动,担心其受骗。这凸显了AI生成内容在真实性、情感操纵和诈骗方面的潜在风险。 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

💡 其他
中国企业“星算”计划成功发射首批12颗太空计算卫星,开启天基算力新时代: 国星宇航牵头的“星算”计划成功将首批12颗计算卫星送入太空,组成全球首个太空计算星座。每颗卫星具备太空计算和互联能力,单星计算能力从T级提升至P级,首发星座在轨算力达5POPS,卫星间激光通信速度高达100Gbps。此举旨在构建天基智能计算基础设施,解决地面算力能源消耗大、散热难等问题,并支持深空探测数据的在轨实时处理,实现“天数天算”。未来计划发射2800颗卫星组建太空计算大网。 (来源: 量子位)

NVIDIA发布年度回顾,强调AI是新工业革命核心,智能即产品: NVIDIA在其年度回顾中指出,世界正进入一场新的工业革命,其核心产品是“智能”。NVIDIA致力于构建智能基础设施,将计算转变为推动各行各业发展的生成性力量。 (来源: nvidia)

NBA与快手Kling AI合作推出AI短片《库里儿时扣篮》: NBA与快手旗下类Sora文生视频大模型Kling AI合作,由AI TALK制作了一部名为《Childhood Curry’s Dunk》的AI短片。该片尝试使用Kling AI重现库里“穿越时空”的扣篮场景,为NBA季后赛助威,片中还有巴克利、奥尼尔和约基奇的特别客串。 (来源: TomLikesRobots)