
关键词:OpenAI, HealthBench, Meta AI, Dynamic Byte Latent Transformer, 微软研究院, ARTIST框架, Sakana AI, 持续思考机器, 医疗AI性能评估, 8B参数动态字节潜在Transformer模型, 强化学习提升LLM推理, CTM神经网络架构, Qwen3官方量化模型
🔥 聚焦
OpenAI发布HealthBench评估医疗AI性能: OpenAI推出了HealthBench,一个旨在衡量大型语言模型在医疗场景中性能和安全性的新基准。该基准由250多名全球医生参与开发,包含5000个真实医疗对话和48562条独特的医生撰写评估标准,覆盖急诊、全球健康等多种情境及准确性、指令遵循等行为维度。测试显示,o3模型准确率达60%,而GPT-4.1 nano在成本降低25倍的情况下表现优于GPT-4o,显示了AI在医疗领域的巨大潜力与性能成本效益的快速进步。 (来源: OpenAI)
Meta发布8B参数动态字节潜在Transformer模型 (Dynamic Byte Latent Transformer): Meta AI宣布开源其8B参数的动态字节潜在Transformer模型权重。该模型提出了一种替代传统分词方法的新方案,旨在重新定义语言模型效率和可靠性的标准。通过这种新的分词方式,有望为语言模型领域带来突破性进展,提升模型处理文本的效率和效果。研究论文和代码已可供下载。 (来源: AIatMeta)
微软研究院推出ARTIST框架,结合强化学习提升LLM推理与工具使用能力: 微软研究院介绍了ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers)框架。该框架融合了自主推理、强化学习和动态工具使用,使大型语言模型能自主决定何时、如何以及使用何种工具进行多步推理,并能学习稳健策略而无需步骤级监督。ARTIST在数学和函数调用等挑战性基准测试中表现优于GPT-4o等顶尖模型,提升高达22%,为通用化和可解释性问题解决设定了新标准。 (来源: MarkTechPost)

Sakana AI发布持续思考机器 (Continuous Thought Machines, CTM): Sakana AI推出了名为“持续思考机器” (CTM)的新型神经网络架构。CTM的核心思想是将神经活动的动态时间过程作为其计算的核心组成部分,允许模型沿内部生成的“思考步骤”时间线进行操作,迭代构建和完善其表示,即使是静态数据也能进行。该架构在ImageNet分类、2D迷宫导航、排序、奇偶校验计算和强化学习等多种任务上展示了其自适应计算、改进的可解释性和生物学合理性。 (来源: Sakana AI)

🎯 动向
阿里巴巴Qwen团队发布Qwen3官方量化模型: 阿里巴巴Qwen团队正式发布了Qwen3的量化模型。用户现在可以通过Ollama、LM Studio、SGLang和vLLM等平台部署Qwen3,并支持GGUF、AWQ、GPTQ等多种格式,方便本地部署。相关模型已在Hugging Face和ModelScope上线。此次发布旨在降低高性能大模型的使用门槛,推动其在更广泛场景中的应用。 (来源: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI发布协作推理框架Collaborative Reasoner: Meta AI推出了Collaborative Reasoner,一个旨在改进语言模型协作推理能力的框架。该框架致力于开发能够与人类及其他智能体合作的社交智能体,通过提升模型的协作和推理能力,为更复杂的人机交互和多智能体系统铺平道路。相关研究论文和代码已开放下载,鼓励社区探索和应用。 (来源: AIatMeta)
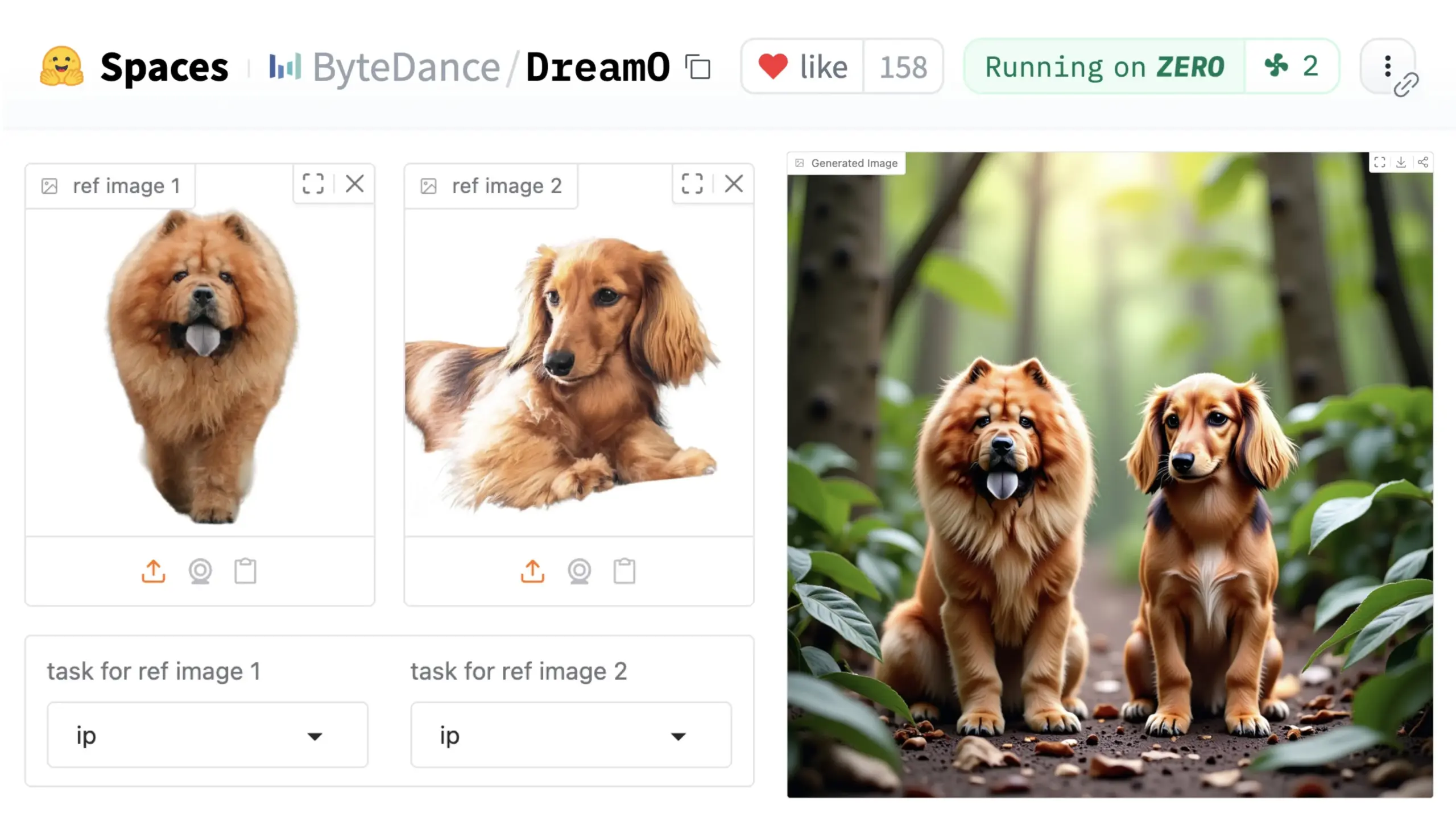
字节跳动推出通用图像定制框架DreamO: 字节跳动发布了名为DreamO的统一图像定制框架。该框架基于预训练的DiT(Diffusion Transformer)模型,能够实现对图像中人物、风格、背景等多种元素的广义定制,包括身份替换、风格迁移、主体变换和虚拟试穿等功能。用户可以在Hugging Face上体验Demo。这一进展展示了单一模型在多样化图像编辑任务中的潜力。 (来源: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA开放Nemotron模型数据管理流程Nemotron-CC: NVIDIA宣布开放其用于Nemotron模型的数据管理流程Nemotron-CC,并尽可能多地公开Nemotron训练和后期训练数据。Nemotron-CC流程现已加入NeMo Curator GitHub仓库,可以大规模处理文本、图像和视频数据。NVIDIA强调高质量预训练数据集对大型语言模型准确性的重要性,并认为数据是加速计算的基础组成部分。 (来源: ctnzr & NandoDF)

腾讯混元-Turbos模型在LMArena竞技场排名第八: 腾讯最新的混元-Turbos模型在LMArena(前身为lmsys.org)的基准测试中总体排名第八,风格控制排名第十三,表现接近Deepseek-R1。该模型在硬核、编码、数学等主要类别中均进入前十,相较于其二月份的版本有显著提升。WizardLM_AI等社区成员对其表现表示祝贺。 (来源: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References展示通用创作工具潜力: Runway的Gen-4 References模型被定位为一个通用创作工具,能够支持近乎无限的工作流程和应用。社区用户持续发现其新的使用案例,显示出其作为通用模型的强大适应性,能够根据用户的创意进行调整,而非让用户去适应模型的限制。这反映了AI在媒体创作领域从特定任务向通用能力的演进趋势。 (来源: c_valenzuelab & c_valenzuelab)

字节跳动Seed-1.5-VL-thinking模型在视觉语言模型基准测试中领先: 字节跳动发布了Seed-1.5-VL-thinking模型,该模型在60个视觉语言模型(VLM)基准测试中的38个上取得了SOTA(state-of-the-art)的成绩。据称,该模型在130万H800 GPU小时上进行了训练,显示了其强大的多模态理解和推理能力。 (来源: teortaxesTex)
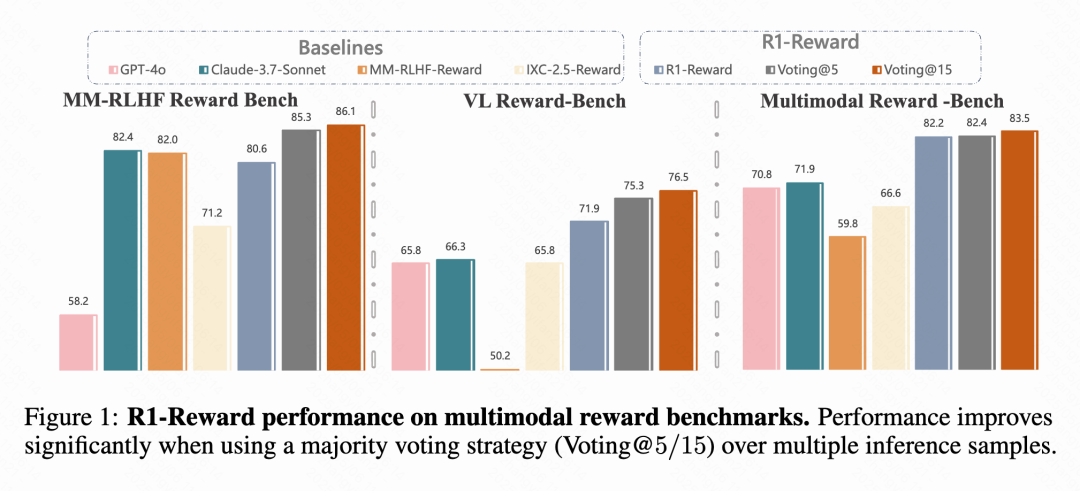
快手与中科院等提出多模态奖励模型R1-Reward: 快手、中科院、清华和南大的研究团队提出了R1-Reward,一种新的多模态奖励模型(MRM),通过改进的强化学习算法StableReinforce进行训练。该模型旨在解决现有RL算法在训练MRM时遇到的不稳定性问题,引入了Pre-Clip、优势过滤器和一致性奖励等机制。实验表明,R1-Reward在多个MRM基准上比SOTA模型提升5%-15%,并在快手的短视频、电商等业务场景中成功应用。 (来源: WeChat & WeChat)
南洋理工等提出WorldMem,用记忆机制实现长时序一致世界生成: 南洋理工大学S-Lab、北京大学与上海AI Lab的研究者提出了世界生成模型WorldMem。该模型通过引入记忆机制,解决了现有视频生成模型在长时序下缺乏一致性的问题。WorldMem在Minecraft数据集上训练,支持多样化场景探索和动态变化,并在真实数据集上验证了其可行性,能够在视角和位置变化后保持良好的几何一致性,并建模时间一致性。 (来源: WeChat)

快手可灵团队提出CineMaster,3D感知可控电影级视频生成框架: 快手可灵研究团队在SIGGRAPH 2025上发表论文,介绍了CineMaster框架。这是一个电影级文本到视频生成框架,允许用户通过交互式工作流,在3D空间中布置场景、设定目标与相机运动,实现对视频内容的精细控制。CineMaster通过语义布局ControlNet和Camera Adapter分别集成物体运动和相机运动控制,并设计了从任意视频中提取3D控制信号的数据构建流程。 (来源: WeChat)

🧰 工具
Comet-ml发布开源LLM评估框架Opik: Comet-ml在GitHub上开源了Opik,一个用于调试、评估和监控LLM应用、RAG系统和Agent工作流的框架。Opik提供全面的追踪、自动化评估和生产就绪的仪表盘,支持本地安装或通过Comet.com作为托管解决方案。它集成了OpenAI、LangChain、LlamaIndex等多种流行框架,并提供LLM即评判者(LLM-as-a-judge)指标用于幻觉检测、内容审核和RAG评估。 (来源: GitHub Trending)
LovartAI推出首款设计智能体Lovart,强调理解上下文: LovartAI发布了其首款设计智能体Lovart的Beta版。用户反馈称,与其它AI设计工具相比,Lovart能更好地理解上下文,甚至“像在读心”。该工具允许人与AI在同一画布上协作,将提示词即时转化为视觉效果,可用于品牌Logo和VI设计等。 (来源: karminski3)
CMU朱俊彦团队推出LEGOGPT,文本生成3D乐高模型: CMU朱俊彦团队开发了LEGOGPT,一个能根据文本提示生成物理稳定且可搭建的3D乐高模型的大型语言模型。该模型将乐高设计问题表述为自回归文本生成任务,通过预测下一个积木的尺寸和位置来构建结构,并在训练和推理中强制执行物理感知组装约束,确保生成设计的稳定性和可搭建性。团队还发布了包含47000多种乐高结构的StableText2Lego数据集。 (来源: WeChat)

MNN聊天应用支持Qwen 2.5 Omni 3B和7B模型: 阿里巴巴的MNN(Mobile Neural Network)聊天应用现已支持Qwen 2.5 Omni 3B和7B模型。这意味着用户可以在移动端体验到更强大的本地化语言模型服务。MNN是一个轻量级的深度学习推理引擎,专注于移动端和嵌入式设备的优化。 (来源: Reddit r/LocalLLaMA)

FutureHouse平台为科学家提供超级智能AI研究工具: 非营利组织FutureHouse发布了FutureHouse平台,这是一个基于Web和API的AI智能体套件,旨在加速科学发现。该平台提供了一系列超级智能的AI研究工具,帮助科学家进行数据分析、模拟实验和知识发现,推动科研范式的变革。 (来源: dl_weekly)
Cartesia推出Pro Voice Cloning,轻松构建自定义语音模型: Cartesia发布了其微调产品Pro Voice Cloning。用户可以上传自己的语音数据,轻松构建自定义语音模型,用于创建个人化身、AI智能体或语音库。该产品支持在2小时内完成训练和服务部署,并提供完全自助式的产品体验,旨在实现规模化应用。 (来源: krandiash)

中科院计算所提出MCA-Ctrl,实现图像精准定制化: 中国科学院计算技术研究所研究团队提出了一种无需微调的通用图像定制方法MCA-Ctrl(Multi-party Collaborative Attention Control)。该方法通过多主体协同注意力控制,利用扩散模型内部知识,结合条件图像/文本提示与主体图像内容,实现对特定主体的主题替换、生成和添加。MCA-Ctrl通过自注意力局部查询和全局注入机制,确保了布局一致性和特定对象外观替换与背景对齐。 (来源: WeChat)
📚 学习
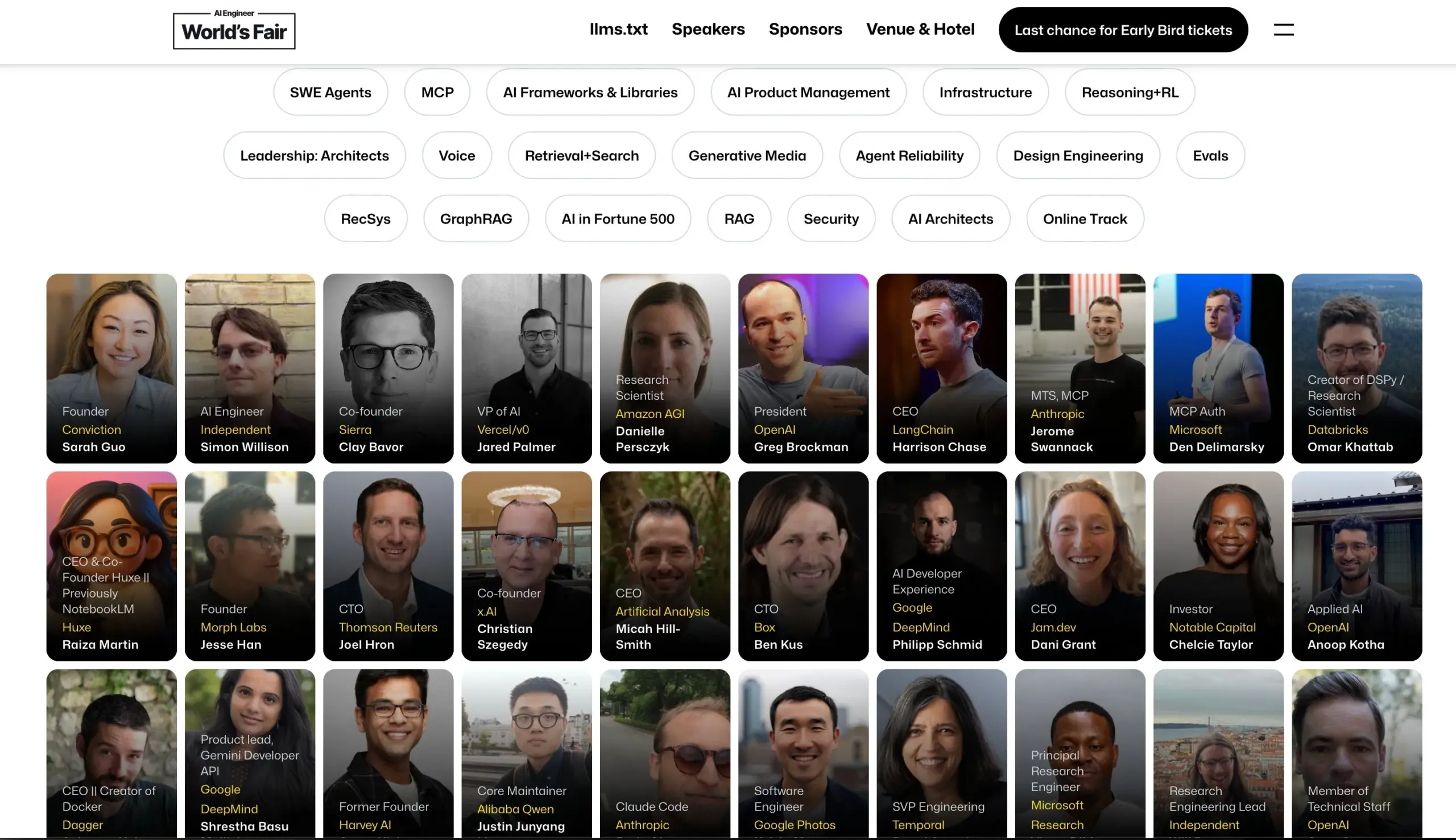
AI Engineer大会公布演讲嘉宾阵容: AI Engineer大会公布了其演讲嘉宾阵容,包括来自OpenAI、Anthropic、LangChainAI、Google等公司的顶尖AI工程师和研究员。大会将涵盖MCP、LLM RecSys、Agent Reliability、GraphRAG等20个细分领域,并首次设立CTO和VP领导力议程。 (来源: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face发布视觉语言模型(VLM)最新进展博客: Hugging Face发布了一篇关于视觉语言模型(VLM)最新进展的综合博客文章。内容涵盖GUI智能体、智能体VLM、全能模型、多模态RAG、视频LM、小型模型等多个方面,总结了过去一年VLM领域的新趋势、突破、对齐和基准测试等。 (来源: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

微软Azure举办构建无服务器AI聊天应用在线研讨会: Yohan Lasorsa宣布将举办一场关于使用Azure构建无服务器AI聊天应用的在线研讨会。会议将探讨Azure Functions、静态Web应用和Cosmos DB,以及如何结合LangChainAI JS使用RAG(检索增强生成)技术。 (来源: Hacubu & hwchase17)
Weaviate播客探讨LLM即评判者系统与Verdict库: Weaviate播客第121期邀请Haize Labs联合创始人Leonard Tang,深入探讨了LLM即评判者(LLM-as-Judge)/奖励模型系统的演变。讨论内容包括评估的用户体验、对比评估、评判者集成、辩论评判者、策划评估集和对抗性测试等,并重点介绍了Haize Labs的新库Verdict,一个用于指定和执行复合LLM即评判者系统的声明式框架。 (来源: bobvanluijt & Reddit r/deeplearning)

陶哲轩发布YouTube视频,演示AI辅助数学形式化证明: 菲尔兹奖得主陶哲轩在其YouTube频道首秀,演示了如何利用GitHub Copilot和Lean证明助手等AI工具,在33分钟内半自动形式化一个原本需要人类数学家写满一页纸的数学证明(Magma方程E1689蕴含E2)。他强调这种方法适用于技术性强、概念性弱的证明,能将数学家从繁琐事务中解放出来。同时,他开发的轻量级Python证明助手也更新至2.0版本,增强了对渐进估计和命题逻辑的处理。 (来源: WeChat & 量子位)

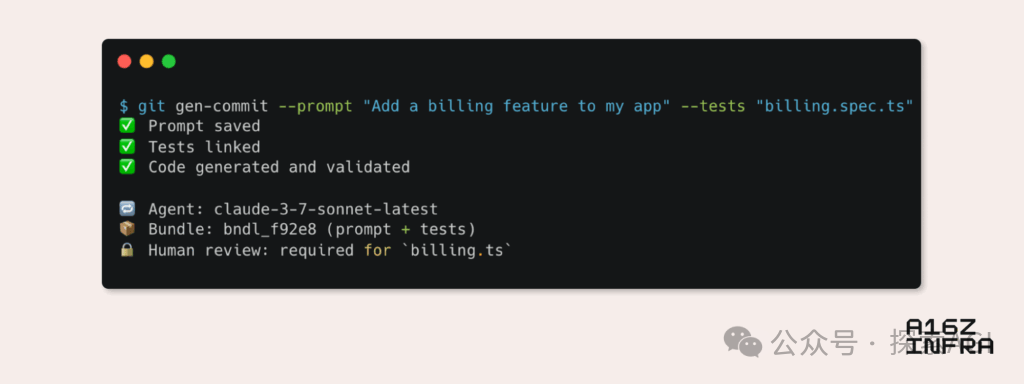
a16z分析AI时代新兴开发者模式九大趋势: Andreessen Horowitz (a16z)发布博客,分析了AI时代新兴的九大开发者模式趋势。其中包括:AI原生Git(版本控制转向Prompt和测试用例)、Vibe Coding(意图驱动编程取代模板)、AI Agent的密钥管理新范式、AI驱动的交互式监控仪表盘、文档演变为AI可交互知识库、从LLM视角看应用(通过无障碍API交互)、异步执行Agent的兴起、MCP(Model-Tool Communication Protocol)协议的潜力以及Agent对基础组件的需求。这些趋势预示着软件构建方式的深刻变革。 (来源: WeChat)
💼 商业
Google Labs推出AI Futures Fund支持AI初创企业: Google Labs宣布启动AI Futures Fund项目,旨在与初创企业合作共同构建AI技术的未来。该基金将为入选的初创企业提供早期访问Google DeepMind模型的机会以及云积分等资源,以帮助其加速发展。 (来源: GoogleDeepMind & JeffDean & Google & demishassabis)
传Perplexity正洽谈新一轮5亿美元融资,估值达140亿美元: 据报道,AI搜索引擎公司Perplexity正在洽谈新一轮5亿美元的融资,估值可能达到140亿美元。这距离其上一轮融资(估值90亿美元)仅过去六个月,显示出资本市场对AI搜索赛道的高度关注和对Perplexity发展前景的认可。 (来源: Dorialexander)

传OpenAI同意以约30亿美元收购Windsurf: 据彭博社报道,OpenAI已同意以约30亿美元的价格收购初创公司Windsurf。此次收购的具体细节和Windsurf的业务方向尚未公开,但此举可能意味着OpenAI在进一步扩展其技术能力或市场版图。 (来源: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 社区
AI的真实风险:无限满足带来的“模拟陷阱”: Amjad Masad等人的讨论指出,AI的真正危险并非科幻电影中的杀手机器人,而是它能无限满足人类欲望,创造一个“无限快乐机器”。这种AI可能导致人类沉溺于模拟的奋斗与意义,最终“消失”在模拟世界中,为费米悖论提供了一种可能的解释——文明并非消亡,而是进入了数字极乐。 (来源: amasad)
AI Agent将重塑编程与科研: Replit的CEO Amjad Masad预测,未来一两年内AI Agent将能不间断工作数天,甚至数年,以解决复杂的科学问题。他认为Agent将成为一种新的编程方式,能够像人类一样投入数天时间解决一个问题,这预示着AI在自动化复杂任务和加速科学发现方面的巨大潜力。 (来源: TheTuringPost & amasad & TheTuringPost)
John Carmack探讨AI在优化代码库方面的潜力: 传奇程序员John Carmack认为,AI不仅能生成大量代码,更有潜力帮助美化和重构现有代码库。他设想AI作为一个勤奋的团队成员,持续审查代码并提出改进建议,甚至可以通过客观实验来定义“AI友好”的编码风格指南。他期待看到OpenBSD这类对代码质量要求极高的团队如何接纳AI成员。 (来源: ID_AA_Carmack)
“Vibe Coding”引发热议:AI辅助编程的利与弊: 社区讨论指出,尽管“Vibe Coding”(通过自然语言指令让AI生成代码原型)能够快速搭建演示级应用,但若要部署和扩展,仍需专业开发者从头构建。工程化产品不仅是写代码,还涉及架构、CI/CD、微服务等复杂问题,AI目前难以完全胜任。Vibe Coding适合快速原型验证,但构建真实解决方案仍需工程思维和经验。 (来源: Reddit r/ClaudeAI)
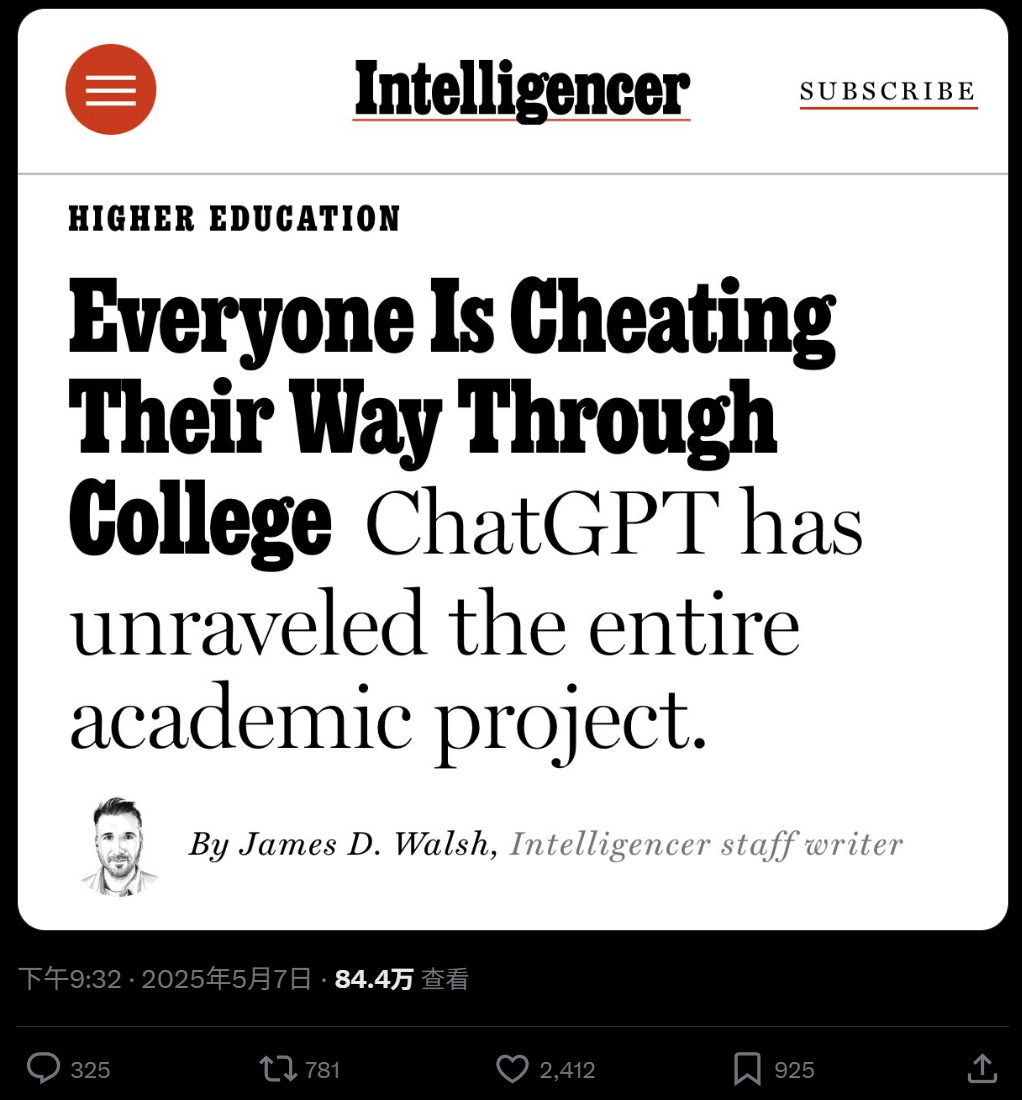
AI在大学教育中的广泛应用与作弊担忧: 《纽约杂志》报道揭示了AI工具(如ChatGPT)在北美大学中被广泛用于完成作业和论文的现象。学生们利用AI进行笔记、学习、研究乃至直接生成作业内容,引发了关于学术诚信、教育质量和学生批判性思维能力下降的担忧。教育工作者尝试调整教学和评估方式,但AI检测工具的有效性存疑,使得AI作弊难以根除。 (来源: WeChat)
💡 其他
Cohere探讨政府AI应用从试点到生产的挑战: Cohere指出,多数政府AI项目仍停留在试点阶段。要实现从试点到实际生产应用的跨越,政府机构需要可信赖的工具、明确的成果导向、高效的基础设施以及合适的合作伙伴。文章探讨了政府机构如何通过安全高效的AI实现从实验到实际应用的转变。 (来源: cohere)

Mustafa Suleyman:大语言模型规模越大越易于控制: Inflection AI的联合创始人Mustafa Suleyman认为,与普遍的担忧相反,大型语言模型(LLM)的规模越大,实际上越容易控制。他指出,几代之前的模型更难引导、风格化和塑造,而规模的扩大有助于提升模型的可控性,而非削弱。 (来源: mustafasuleyman)
AI伦理讨论:AI造成伤害或偏见的责任归属: 一则Reddit帖子引发讨论:当AI系统(如医疗诊断AI)因训练数据偏差(如主要基于浅色皮肤图像训练,导致对深色皮肤患者误诊)造成伤害时,责任应由谁承担?这涉及到AI开发者、部署机构、监管方等多方责任界定问题,是AI伦理和法律框架亟待解决的关键议题。 (来源: Reddit r/ArtificialInteligence)