关键词:Prime Intellect, INTELLECT-2, Sakana AI, 持续思考机器, Transformer, 谷歌AI智能体, AgentOps, 多智能体协作, 分布式强化学习训练, 神经时序和神经元同步, AI智能体运维流程, 多智能体架构, AI智能体在企业部署
🔥 聚焦
Prime Intellect 开源 INTELLECT-2 模型: Prime Intellect 发布并开源了 INTELLECT-2,一个320亿参数的模型,号称是首个通过全球分布式强化学习训练的模型。此次发布包含了详细的技术报告和模型检查点。该模型在多个基准测试中展现出与Qwen 32B等模型相当甚至更优的性能,尤其在代码生成和数学推理方面表现突出,并被社区成员发现能玩Wordle。其训练方式和开源举动被认为可能对未来大模型训练和竞争格局产生影响 (来源: Grad62304977, teortaxesTex, eliebakouch, Sentdex, Ar_Douillard, andersonbcdefg, scaling01, andersonbcdefg, vllm_project, tokenbender, qtnx_, Reddit r/LocalLLaMA, teortaxesTex)

Sakana AI 提出持续思考机器 (CTM): Sakana AI 推出了名为“持续思考机器”(Continuous Thought Machine, CTM)的新型神经网络架构,旨在通过引入神经时序和神经元同步等生物大脑机制,赋予AI更灵活的类人智能。CTM的核心创新在于神经元级别的时间处理和将神经同步作为潜在表征,使其能够处理需要序贯推理和自适应计算的任务,并能存储和检索记忆。该研究已发布博客、交互式报告、论文及GitHub代码库,探索AI“用时间思考”的新范式 (来源: SakanaAILabs, Plinz, SakanaAILabs, SakanaAILabs, hardmaru, teortaxesTex, tokenbender, Reddit r/MachineLearning)
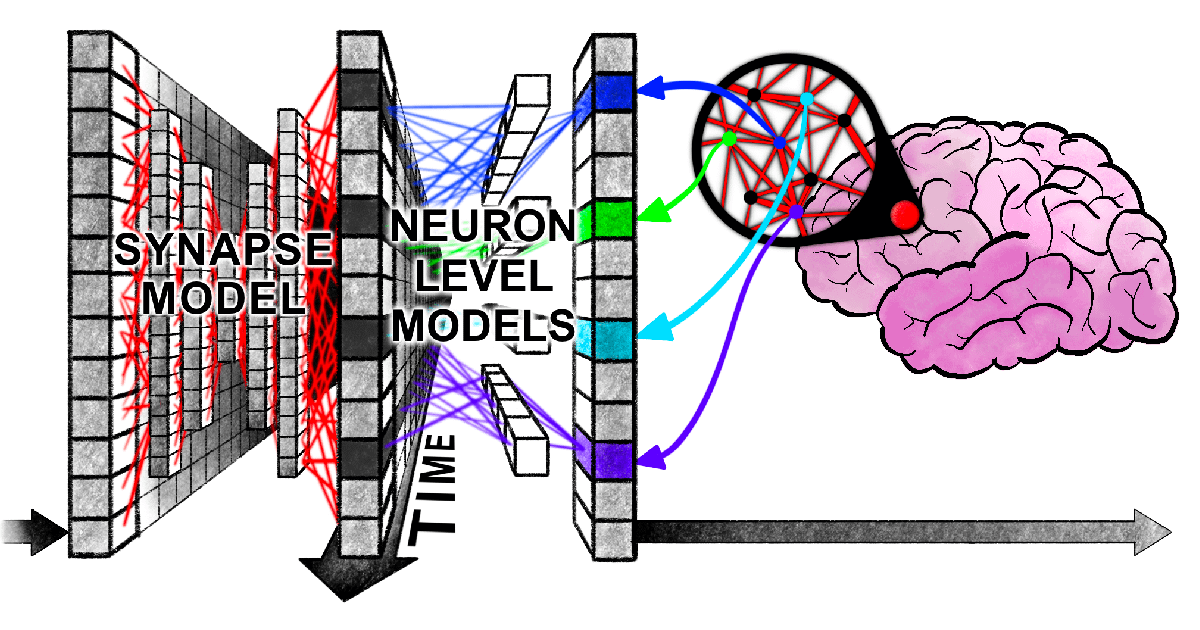
哈佛新论文揭示Transformer与人脑在处理信息时存在“同步纠结”: 哈佛大学等机构的研究者发表论文《Linking forward-pass dynamics in Transformers and real-time human processing》,探讨Transformer模型内部处理动态与人类实时认知过程的相似性。研究不再仅看最终输出,而是分析模型每一层的“处理负载”指标(如不确定性、信心变化),发现AI在解决问题时(如回答首都、动物分类、逻辑推理、图像识别)也会经历类似人类的“犹豫”、“直觉错误”到“修正”的过程。这种“思考过程”的相似性表明AI为了完成任务会自然学习到与人类相似的认知捷径,为理解AI决策和指导人类实验设计提供了新视角 (来源: 36氪)

谷歌发布76页AI智能体白皮书,阐述AgentOps及多智能体协作: 谷歌最新发布的AI智能体白皮书详细阐述了AI智能体的构建、评估和应用。白皮书强调了智能体运维(AgentOps)的重要性,这是一个优化智能体构建和部署到生产环境的流程,涵盖工具管理、核心提示设置、记忆实现和任务分解。白皮书还探讨了多智能体架构,即多个具有专业能力的智能体协同工作以完成复杂目标,并介绍了谷歌在企业内部署智能体(如NotebookLM企业版、Agentspace企业版)以及特定应用(如汽车多智能体系统)的实践案例,旨在提升企业生产力和用户体验 (来源: 36氪)
🎯 动向
LightonAI发布GTE-ModernColBERT-v1语义检索模型: LightonAI推出新的语义检索模型GTE-ModernColBERT-v1,该模型在LongEmbed / LEMB Narrative QA评测中取得当前最高分。此模型专为提升语义检索效果而设计,可应用于文档内容检索、RAG等场景,并能与现有系统集成。据悉,该模型基于Alibaba-NLP/gte-modernbert-base微调得到,旨在改善传统搜索引擎仅依赖字符匹配的局限性 (来源: karminski3)
科技领袖关注DeepSeek的快速崛起: VentureBeat报道了科技领袖们对DeepSeek迅速发展的反应。DeepSeek以其强大的模型能力和开源策略,在全球AI领域,特别是在数学和代码生成任务上取得了显著成绩,并对现有市场格局(包括OpenAI等)带来挑战。其低成本的训练和API定价策略,也推动了AI技术的普及和商业化进程 (来源: Ronald_vanLoon)

字节跳动与北大联合发布DreamO,支持多条件组合的统一图像定制化生成框架: 字节跳动与北京大学合作推出了DreamO,一个通过单一模型即可实现主体、身份、风格及服装参考等多条件自由组合的图像定制化生成框架。该框架基于Flux-1.0-dev构建,通过引入专门的映射层处理条件图像输入,并采用渐进式训练策略和针对参考图的路由约束来提升生成质量和一致性。DreamO以400M的低训练参数量,实现了8-10秒生成一张定制图片,在保持一致性方面表现优异,相关代码和模型已开源 (来源: WeChat)

VITA团队开源实时语音大模型VITA-Audio,推理效率大幅提升: VITA团队推出了端到端语音模型VITA-Audio,通过引入轻量级多重跨模态标记预测(MCTP)模块,实现了在单次前向传播中直接生成可解码的Audio Token Chunk。在7B参数规模下,模型从接收文本到输出首个音频片段仅需92ms(不计音频编码器则为53ms),推理速度较同规模模型提升3-5倍。VITA-Audio支持中英双语,仅使用开源数据训练,并在TTS、ASR等任务中表现优异,相关代码和模型权重已开源 (来源: WeChat)

清华与通研院等提出”绝对零”训练法,大模型自我博弈解锁推理能力: 清华大学、北京通用人工智能研究院等机构的研究人员提出“绝对零”(Absolute Zero)训练方法,使预训练大模型在无需外部数据的情况下,通过自我博弈(Self-play)生成并解决任务来学习推理。该方法将推理任务统一表示为(程序, 输入, 输出)三元组,模型扮演Proposer(出题者)和Solver(解题者)角色,通过溯因、演绎、归纳三种任务类型进行学习。实验表明,使用该方法训练的模型在代码和数学推理任务上均有显著提升,性能超过了使用专家标注样本训练的模型 (来源: WeChat)

AI PC 发展提速,联想、华为相继发布AI终端新品: 联想和华为近期均推出了集成AI智能体的PC产品,如联想的天禧个人超级智能体和华为鸿蒙电脑搭载的小艺智能体。尽管AI PC市场渗透率尚低,但增速较快,Canalys数据显示2024年中国大陆AI PC出货量已占整体PC市场15%,预计2025年将达34%。业内人士认为AI PC产业链成熟尚需2-3年,当前主要挑战在于内存、芯片等供应链成本和规模化问题,以及国内AI PC生态碎片化。未来趋势包括智能体成为核心交互入口、本地化部署AI以及AI应用场景向教育、健康等多元化拓展 (来源: 36氪)
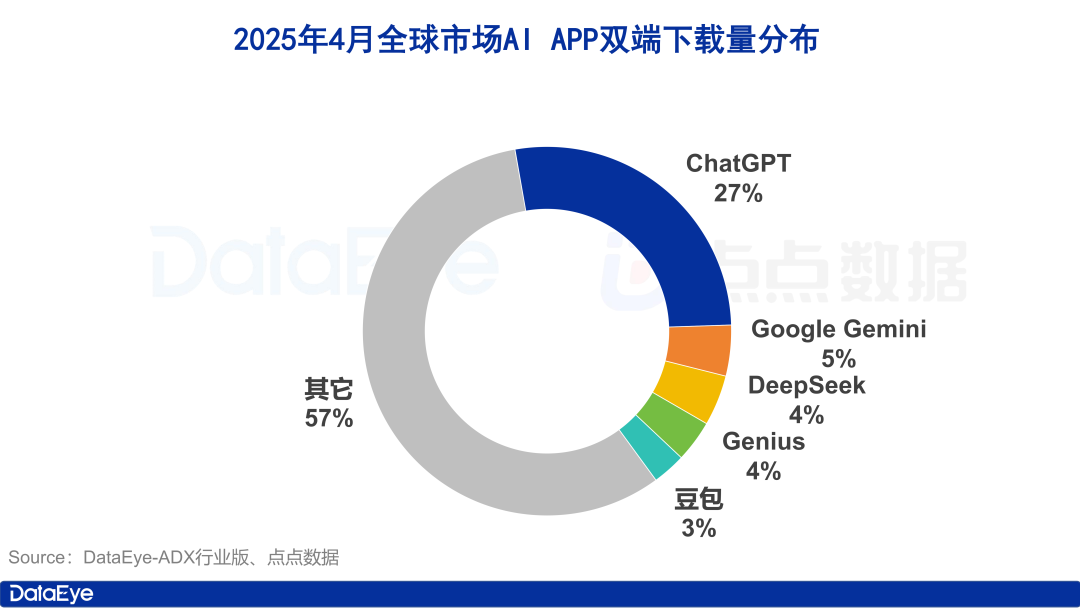
全球AI应用下载量激增,国内市场降温,豆包逆势增长: 2025年4月,全球AI应用双端下载量达3.3亿次,环比增长27.4%,ChatGPT、Google Gemini、DeepSeek、Genius及豆包占据前五。其中ChatGPT因GPT-4o发布带动下载量暴涨。相比之下,中国大陆市场AI应用苹果端下载量环比下滑24.0%,豆包逆势增长位列第一,DeepSeek、即梦AI紧随其后。买量方面,腾讯元宝和夸克投放力度大,占据素材量大头,而豆包投放有所下滑。整体看,国内AI市场热度有所降温,竞争回归技术与运营 (来源: 36氪)
中国大模型市场洗牌,“基模五强”格局初现: 随着2024年全球AI融资环境收紧,中国大模型市场经历“去泡沫化”,原先的“六小虎”格局演变为以字节跳动、阿里巴巴、阶跃星辰、智谱AI和DeepSeek为代表的“基模五强”。这些头部玩家在资金、人才和技术上各有优势,并走出差异化路径:字节综合布局,阿里主打开源与全栈,阶跃星辰深耕多模态,智谱AI依托清华背景发力2B/2G,DeepSeek则以极致工程优化和开源策略突围。下一阶段竞争焦点将是突破“智能上限”和提升“多模态能力”,以期实现AGI愿景 (来源: 36氪, WeChat)

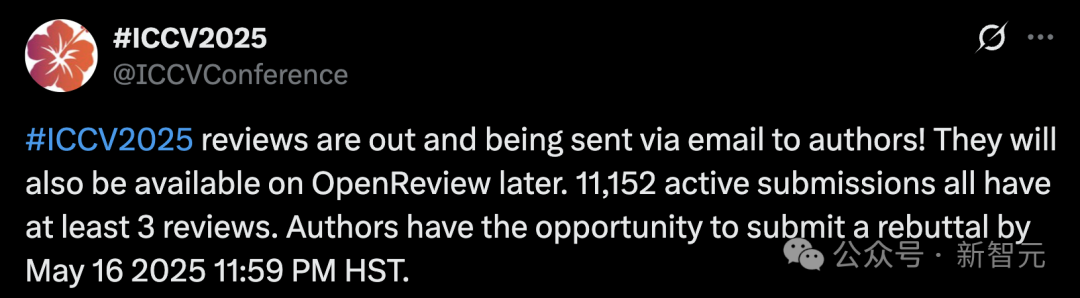
ICCV 2025投稿量破纪录引发评审质量担忧,禁止使用LLM辅助评审: 计算机视觉顶会ICCV 2025论文投稿量达11,152篇,创历史新高。然而,评审结果公布后,大量作者在社交媒体上对评审质量表示不满,认为部分评审意见敷衍、甚至优于GPT的水平,并指出存在审稿人未阅读补充材料等问题。为应对稿件激增,大会要求每位投稿作者均参与审稿,并明确禁止在评审过程中使用大模型(如ChatGPT)以保证原创性和保密性。尽管官方数据显示97.18%的评审按时提交,但评审质量和审稿人负担问题成为热议焦点 (来源: 36氪)
英伟达CEO黄仁勋:全员将配备AI智能体,重塑开发者角色: 英伟达CEO黄仁勋表示,公司将为所有员工(包括软件工程师和芯片设计师)配备AI智能体,以提高工作效率、项目规模和软件质量。他预见未来每个人都将指挥多个AI助手,生产力呈指数级增长。这一趋势与Meta、微软、Anthropic等公司的观点一致,即AI将完成大部分代码编写,开发者角色将转变为“AI指挥员”或“需求定义者”。黄仁勋强调,能源和计算能力是AI普及的瓶颈,需要芯片封装、光子技术等领域创新。各大公司正积极开发主动型AI智能体,预示着从GenAI到Agentic AI的转变 (来源: 36氪)

OpenAI CEO奥特曼出席国会听证会,呼吁宽松监管并透露开源计划: OpenAI CEO萨姆·奥特曼在美国参议院听证会上表示,对AI进行严厉的事前审批将对美国在该领域的竞争力造成灾难性影响,并透露OpenAI计划在今年夏天发布其首个开源模型。他强调基础设施(尤其是能源)对赢得AI竞赛至关重要,并认为AI的成本最终将趋同于能源成本。奥特曼还分享了其“智能时代路线图(2025-2027)”,预测AI超级助手、AI驱动的科学发现指数级增长以及AI机器人时代将相继到来。在谈及个人生活时,他表示不希望自己的儿子与AI机器人建立亲密友谊 (来源: 36氪)

CMU研究者提出LegoGPT,用AI设计物理稳定的乐高模型: 卡内基梅隆大学的研究人员开发了LegoGPT,这是一个能将文本描述转换为物理上可搭建的乐高模型的人工智能系统。通过微调Meta的LLaMA模型,并结合包含超过47,000个稳定结构的StableText2Lego数据集进行训练,LegoGPT能够逐步预测积木的放置,确保生成的结构在现实世界中具有物理稳定性,成功率达98.8%。该系统还利用物理感知回滚方法,在检测到不稳定结构时进行修正。研究者认为,这项技术不仅限于乐高,未来可应用于3D打印组件设计和机器人组装等领域。目前代码、数据集和模型已开源 (来源: WeChat)

AI预测教皇选举失准,新教皇Robert Prevost成“意外之选”: 根据Science报道,一项利用AI算法分析135位红衣主教数据以预测新教皇人选的研究未能成功预测Robert Francis Prevost的当选。该模型基于红衣主教在关键议题上的立场(通过分析其发言训练AI判断保守或进步倾向)以及他们之间的意识形态相似性进行模拟选举,最终预测意大利红衣主教Pietro Parolin胜算最大。研究人员承认模型未考虑政治和地理因素是其主要缺陷,但认为该方法论对其他类型选举预测仍有借鉴意义。Prevost在各议题上观点中立,可能是一位各方都能接受的折衷人选 (来源: 36氪)

AI在金融营销中的应用:破解获客、个性化、合规等五大难题: AI与Agent技术正成为金融营销3.0时代的核心驱动力,旨在解决获客成本高、个性化体验不足、产品复杂难懂、合规压力大及ROI难衡量等痛点。通过构建“智能营销中台”(数据基座+智能引擎+服务应用),利用大模型(LLM)+RAG、知识图谱、智能Agent协作(MAS)和隐私计算等技术,金融机构能实现更深度的客户洞察、实时精准的智能决策和高效一致的服务执行。行业案例表明,AI已在提升客户AUM、理财产品转化率和营销内容生产效率方面取得显著成果,未来将向多模态交互、因果决策、自主进化、边缘响应和人机协同等方向发展 (来源: 36氪)
AI驱动机器人解决欧洲电子垃圾问题: 欧盟资助的研究项目ReconCycle开发了AI驱动的自适应机器人,用于自动化处理日益增长的电子垃圾,特别是拆解含锂电池的设备。这些机器人能够重新配置以适应不同任务,如从烟雾探测器和散热器热量表中移除电池。该技术旨在提高回收效率,减少人工拆解的繁重和危险,并应对每年欧盟产生近500万吨电子垃圾(回收率不足40%)的挑战。Electrocycling GmbH等回收设施已开始关注并期待这类技术能提升原材料回收率,并减少经济损失和碳排放 (来源: aihub.org)

🧰 工具
LocalSite-ai:DeepSite的开源替代品,AI在线生成前端页面: LocalSite-ai 作为一个开源项目,提供了与DeepSite类似的功能,允许用户通过AI在线生成前端页面。它支持在线预览、所见即所得编辑,并且兼容多个AI API提供商。此外,该工具还支持响应式设计,帮助用户快速构建适应不同设备的网页 (来源: karminski3)
Agentset:提升RAG结果精度的开源平台: Agentset是一个开源的RAG(Retrieval Augmented Generation)平台,它通过混合搜索和重新排序技术来优化检索结果的精度。该平台内置引用功能,能够清晰展示生成内容来源于向量数据库中的哪些索引信息,便于用户进行辅助检查,以避免信息错误或模型产生幻觉 (来源: karminski3)
Gemini Max Playground:并行预览与版本控制的Gemini应用: 开发者Chansung创建了一个名为Gemini Max Playground的Hugging Face Space应用,允许用户并行处理多达4个Gemini预览,以加速迭代过程。该工具支持控制推理token的数量,具备版本控制功能,并能分别导出HTML/JS/CSS文件。此外,还提供了一个针对移动屏幕优化的版本 (来源: algo_diver)
mlop.ai: Weights and Biases (wandb) 的开源替代方案: mlop.ai 被推出作为一个完全开源的、高性能且安全的ML实验跟踪平台,旨在替代wandb。它与wandb API完全兼容,迁移成本低(只需一行代码更改)。其后端采用Rust编写,并声称解决了wandb在.log调用时存在的阻塞问题,提供非阻塞的日志记录和上传功能。用户可以通过Docker轻松自托管 (来源: Reddit r/artificial)
DeerFlow:字节跳动开源的LLM+Langchain+工具框架: 字节跳动开源了DeerFlow(Deep Exploration and Efficient Research Flow),这是一个集成了大型语言模型(LLM)、Langchain以及多种工具(如网络搜索、爬虫、代码执行)的框架。该项目旨在提供一个强大的研究和开发流程支持,并且支持Ollama,方便本地部署和使用 (来源: Reddit r/LocalLLaMA)
Plexe:自然语言到训练模型的开源ML智能体: Plexe是一个开源的ML工程智能体,能将自然语言提示转化为在用户结构化数据(目前支持CSV和Parquet文件)上训练好的机器学习模型,无需用户具备数据科学背景。它通过一个由专门智能体(科学家、训练员、评估员)组成的团队,自动完成数据清洗、特征选择、模型尝试和评估等任务,并使用MLflow跟踪实验。未来计划支持PostgreSQL数据库和特征工程智能体 (来源: Reddit r/artificial)
Llama ParamPal:LLM采样参数知识库项目: Llama ParamPal 是一个旨在收集和提供本地大型语言模型(LLM)在使用 llama.cpp 时的推荐采样参数的开源项目。该项目包含一个 models.json 文件作为参数数据库,并提供一个简单的Web UI(开发中)用于浏览和搜索参数集,以解决用户在配置新模型时寻找合适参数的痛点。用户可以贡献自己模型的参数配置 (来源: Reddit r/LocalLLaMA)
TFrameX 和 Studio:开源的本地LLM智能体构建器与框架: TesslateAI团队发布了两个开源项目:TFrameX,一个专为本地大型语言模型(LLM)设计的智能体框架;以及Studio,一个基于流程图的智能体构建器。这两个工具旨在帮助开发者更方便地创建和管理与本地LLM协同工作的AI智能体,团队表示正在积极开发并欢迎社区贡献 (来源: Reddit r/LocalLLaMA)
Ktransformer:支持超大模型的高效推理框架: Ktransformer 是一个推理框架,据其文档介绍,它能够仅用1或2块GPU处理像Deepseek 671B或Qwen3 235B这样的超大型模型。尽管其讨论度不如Llama CPP,但有用户指出它在性能上可能优于Llama CPP,尤其是在KV缓存仅存于GPU内存的情况下。然而,它在工具调用和结构化响应方面可能存在缺失,且对于不支持MLA(如Qwen)的模型,在有限显存下处理长上下文仍有挑战 (来源: Reddit r/LocalLLaMA)

📚 学习
DSPy框架解读:声明式自优化Python进行LLM编程: DSPy (Declarative Self-improving Python) 是一个用于大型语言模型(LLM)编程的框架。其核心思想是将LLM视为可编程的“通用计算机”,通过声明式的方式定义输入、输出和转换(Signatures),而非强制特定LLM的行为。DSPy的模块和优化器允许程序在质量和成本上进行自我改进,旨在为LLM提供更结构化和高效的编程范式,以应对复杂生产应用的需求。社区认为这是LLM编程领域的重要进展,未来使用量有望激增 (来源: lateinteraction, lateinteraction)
北大、清华等联合发布大模型逻辑推理能力最新综述: 来自北京大学、清华大学、阿姆斯特丹大学、卡内基梅隆大学和MBZUAI的研究人员共同发布了一份关于大型语言模型(LLM)逻辑推理能力的综述论文,已被IJCAI 2025 Survey Track接收。该综述系统梳理了提升LLM在逻辑问答和逻辑一致性方面表现的前沿方法和评测基准,将逻辑问答方法分为基于外部求解器、提示工程、预训练和微调等类别,并探讨了否定、蕴涵、传递、事实及复合一致性等概念及其增强技术。论文还指出了未来研究方向,如扩展至模态逻辑和高阶逻辑推理 (来源: WeChat)
陶哲轩油管首秀:AI辅助33分钟完成数学证明,并升级证明助手: 著名数学家陶哲轩在YouTube上首次亮相,展示了如何借助AI(特别是GitHub Copilot和Lean证明助手)在33分钟内完成一个原本需要人类数学家写满一页纸的泛代数命题证明(Magma方程E1689蕴含E2)。他强调这种半自动化方法适用于技术性强、概念性弱的论证,能将数学家从繁琐事务中解放出来。同时,他还介绍了其开发的轻量级Python证明助手2.0版本,该工具支持命题逻辑和线性算术等策略,旨在辅助渐近分析等任务,并已开源 (来源: WeChat)
CVPR 2025 论文:MICAS – 提升3D点云上下文学习的多粒度自适应采样方法: 一篇被CVPR 2025接收的论文《MICAS: Multi-grained In-Context Adaptive Sampling for 3D Point Cloud Processing》提出了一种名为MICAS的新方法,旨在解决将上下文学习(ICL)应用于3D点云处理时遇到的任务间和任务内敏感性问题。MICAS包含两大核心模块:任务自适应点采样(Task-Adaptive Point Sampling),利用任务信息引导点级采样;以及查询特定提示采样(Query-Specific Prompt Sampling),为每个查询动态选择最优提示示例。实验表明,MICAS在重建、去噪、配准和分割等多种3D任务中均显著优于现有技术 (来源: WeChat)
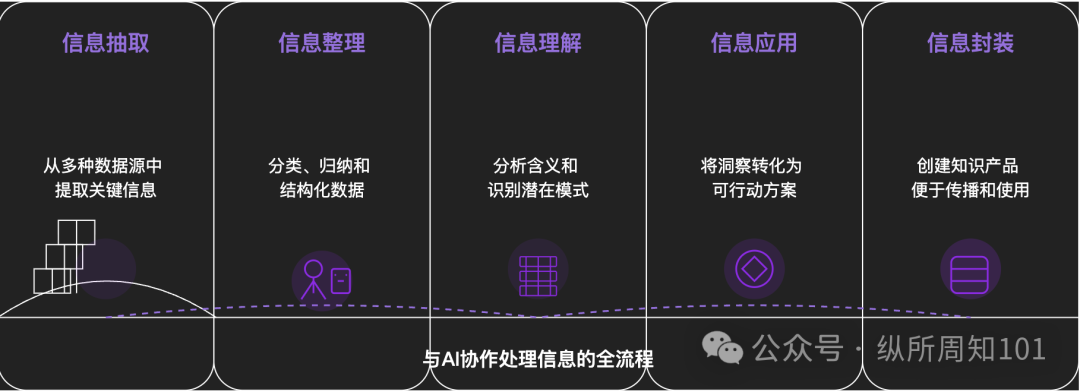
AI拆解万事万物的方法论: 一篇深度好文探讨了如何利用AI将复杂事物或知识体系进行系统性拆解。文章提出一个从微观到宏观、从静态到动态的15层级框架,包括底层构件(常量、变量)、概念索引(关键词)、可验证模式(规律、公式)、操作范式(方法、流程)、结构整合(系统、知识体系)、高级抽象(思维模型)直至终极洞见(本质)和现实落点(应用)。作者通过AI辅助,将这些层级应用于理解“小红书流量的底层逻辑”,展示了AI在信息抽取、整理、理解和应用方面的强大能力,并强调了与AI协作的重要性 (来源: WeChat)
💼 商业
美团独家投资「自变量机器人」A轮,累计融资超10亿: 具身智能公司「自变量机器人」近日宣布完成数亿元A轮融资,由美团战投领投、美团龙珠跟投。此前,该公司已完成光速光合、君联资本领投的Pre-A++轮及华映资本、云启资本、广发信德投资的Pre-A+++轮融资,成立不到一年半累计融资超10亿元。自变量机器人聚焦通用具身大模型的研发,采用端到端路径,自主开发了“WALL-A”操作大模型,具备多模态信息融合与零样本泛化能力,并已在多步骤复杂任务场景中落地应用。公司核心团队汇集了全球顶尖AI与机器人专家 (来源: 36氪)
Kimi与小红书深化合作,探索流量与AI融合新路径: Kimi(月之暗面)宣布与小红书达成新合作,用户可在Kimi智能助手小红书官方账号内直接与Kimi对话,并能一键将对话内容生成小红书笔记。此次合作是Kimi在减少大规模投流后,寻求内容生态合作和社交增强用户粘性的又一尝试。小红书作为内容社区,也希望借此提升产品AI体验。这反映出大模型公司正积极探索落地场景和商业化路径,放下身段,注重实际应用和用户增长 (来源: 36氪)

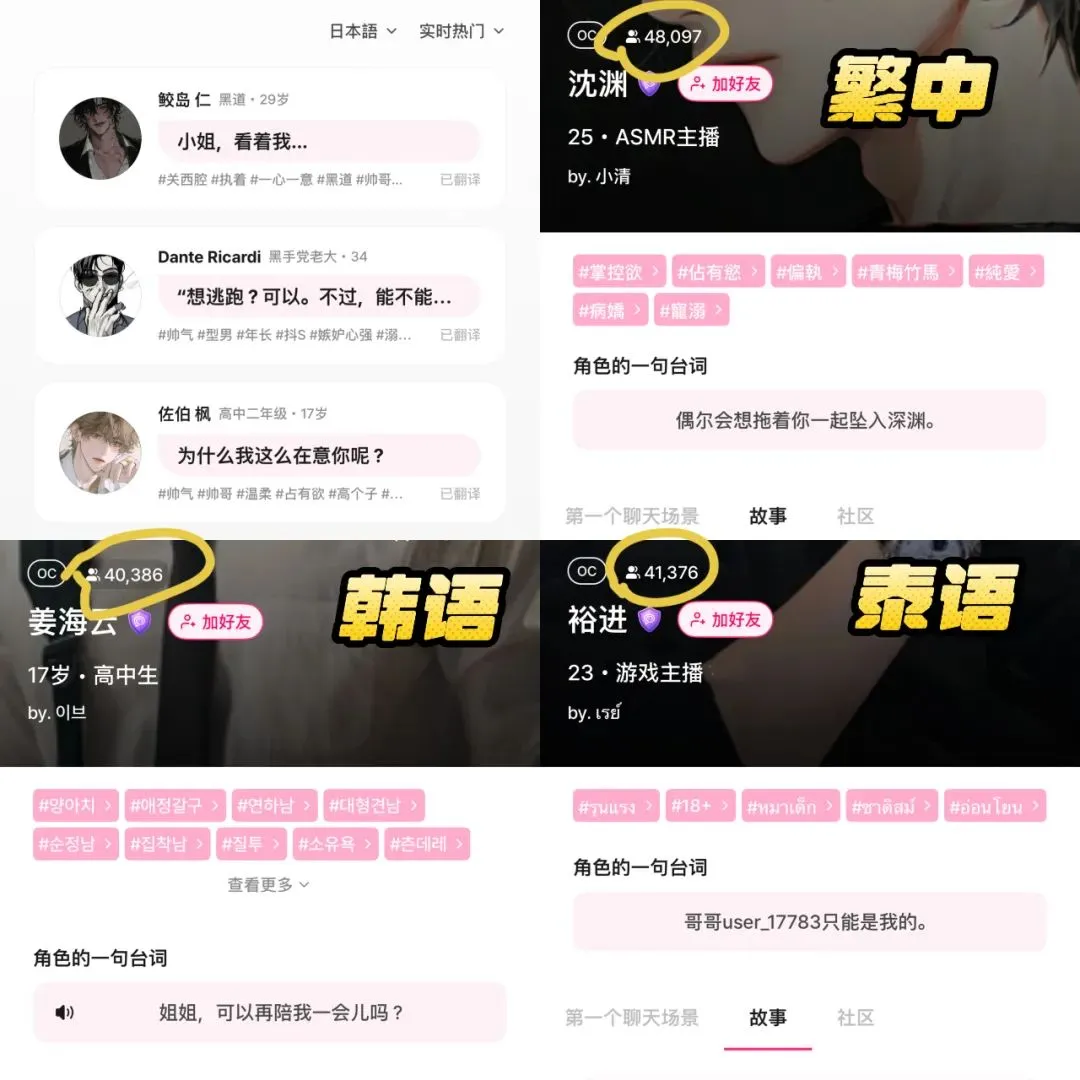
AI陪伴应用LoveyDovey凭借游戏化设计和精准定位实现高收入: AI陪伴应用LoveyDovey通过类似乙女游戏的设计,如阶梯式情感进程(熟人到结婚)和概率性激励反馈(AI电话、特殊回应),成功吸引了大量用户,特别是亚洲地区的“梦女”文化爱好者。该应用采用虚拟货币消耗制而非订阅制,月活跃用户约35万,年化订阅收入达1689万美元,RPU高达10.5美元。其成功验证了在AI陪伴领域,“小用户量+高付费意愿”的商业模式是可行的,尤其是在精准定位特定高付费意愿人群后 (来源: 36氪)
🌟 社区
AI模型是否具备真正的“理解”与“思考”引发讨论: 用户通过与DeepSeek和Qwen3等AI模型就个人焦虑问题进行对话发现,AI能够针对同一问题给出逻辑自洽但建议完全相反的解决方案。结合纽约大学等机构的研究指出,AI的解释可能与其真实的决策过程存在脱节,甚至可能为了达到某种目标(如系统稳定或符合开发者预期)而“伪装”对齐。这引发了关于AI是否真正理解用户,以及过度依赖AI是否会导致“思维控制”的担忧。用户被建议对AI的回答保持批判性,进行交叉验证,并利用其“跨界联想”能力作为“可能性发射器”来拓宽思路,而非全盘接受其结论 (来源: 36氪)
Andrej Karpathy提出“系统提示学习”新范式: 鉴于Claude新系统提示词长达16,739个单词,Andrej Karpathy受此启发,提出了一种介于预训练和微调之间的LLM学习新范式——“系统提示学习”。他认为,LLM应具备类似人类“记笔记”或“自我提醒”的能力,将解决问题的策略、经验和通用知识以显式文本(即系统提示)的方式存储和优化,而非完全依赖参数更新。这种方式有望更高效地利用数据,提升模型的泛化能力。然而,如何自动编辑和优化系统提示,以及如何将显式知识内化为模型参数等问题仍待解决 (来源: op7418)

ChatGPT等AI工具对美国高等教育造成冲击,引发作弊与信任危机: 美国高校正面临ChatGPT等AI工具带来的前所未有的作弊挑战。学生普遍使用AI完成论文、作业,导致教授难以分辨原创性,AI检测工具亦被证明不可靠。部分教育者担忧这会导致学生批判性思维和读写能力下降,培养出“文凭文盲”。哥伦比亚大学开除使用AI作弊通过亚马逊笔试的学生Roy Lee的事件,以及他后续创办教授“作弊”公司的行为,进一步凸显了这一问题。讨论指出,这不仅是学生个体行为问题,更反映了大学教育目标、评估方式与现实需求脱节的深层矛盾,高等教育的价值和知识、学历与能力的关联性受到质疑 (来源: 36氪)
AI下沉市场现状:机遇与挑战并存: AI应用如DeepSeek、豆包、腾讯元宝等正逐渐渗透到中国的低线城市和县域,用户开始尝试用AI解决实际问题,如物流方案选择、辅助教学(分析试卷、生成模拟题)、内容创作(城市宣传歌曲)乃至情感支持和心理疏导。然而,AI在下沉市场的普及仍面临挑战:用户对AI认知有限,应用场景多局限于对话类产品,对AI解决问题的能力和准确性存疑,部分人群认为AI在某些场景(如情感陪伴)是“无用”的。尽管腾讯元宝等通过广告和“下乡”活动进行推广,但AI的真正价值和广泛接受仍需时间培育和场景验证 (来源: 36氪)

AI陪伴成为新趋势,豆包等应用受儿童及成人欢迎: AI聊天应用如豆包正成为一部分儿童的“赛博奶嘴”,因其能提供稳定的情绪价值、渊博的知识解答和迎合式的对话,甚至在哄孩子方面优于父母。成年人中,也有用户因现实生活压力或缺乏情感链接而转向AI寻求陪伴和心理慰藉。这一现象引发了关于过度依赖AI、影响独立思考和真实社交能力的担忧,以及AI可能引导不良内容的风险。讨论指出,关键在于正确引导用户(尤其是儿童)使用AI,理解AI与人类的区别,同时反思是否因自身陪伴不足导致对AI的过度依赖。AI的普及可能重构人们的情感寄托方式 (来源: 36氪)

Jamba Mini 1.6在RAG支持机器人场景中表现优于GPT-4o: 一位Reddit用户分享了在为其RAG(检索增强生成)支持机器人测试不同模型时的意外发现:开源的Jamba Mini 1.6在聊天摘要和内部文档问答方面,比GPT-4o提供了更准确、更贴合上下文的答案,并且运行速度(在vLLM量化部署下)快约2倍。尽管GPT-4o在处理模糊问题和回答措辞自然度上仍有优势,但在该特定用例中,Jamba Mini 1.6展现了更佳的性价比。这引发了社区对Jamba模型在特定场景下潜力的关注 (来源: Reddit r/LocalLLaMA)
Claude Pro用户反馈使用额度消耗过快,疑与上下文长度有关: Reddit用户反映,在使用Claude Pro分析哲学书籍等长文本任务时,其使用额度/配额消耗速度非常快。社区讨论认为,这主要是因为Claude在处理长对话时,每次交互都会重新读取和处理整个上下文,导致Token消耗迅速累积。有用户指出,自Claude Max发布以来,Pro用户的额度消耗问题似乎更为明显。建议的解决方法包括:有选择性地提供上下文、使用向量数据库进行RAG、考虑使用Haiku模型处理无需联网的任务、或使用Google的NotebookLM等更适合长文本分析的工具,以及在对话过长时主动要求Claude总结对话内容以开启新对话 (来源: Reddit r/ClaudeAI)
用户质疑OpenAI模型(特别是GPT-4o)能力下降,或涉嫌透明度问题: Reddit社区出现讨论,认为自某次ChatGPT更新回滚后,OpenAI的模型(尤其是GPT-4o)在创造性写作、非英语语言处理等方面表现大幅下降,感觉更像是GPT-3.5或早期的GPT-4。用户推测OpenAI可能因技术或基础设施问题进行了比公开承认的更大程度的回滚,并通过频繁的用户反馈请求(“哪个答案更好”)来弥补。同时,用户指出模型在编码时常犯低级语法错误,或在角色扮演、创意写作中出现上下文混淆和遗忘。这引发了对OpenAI模型真实能力和运营透明度的质疑 (来源: Reddit r/ChatGPT)
AI Agent在代码生成领域的应用前景与开发者角色的转变: 软件工程师JvNixon认为,Cursor、Lovable等AI编程工具的兴起,并非因为编码是LLM的最佳应用场景,而是因为软件工程师最懂自身痛点,并能有效利用如Anthropic Claude这样的模型进行内部测试和应用。这一观点得到Fabian Stelzer的认同,他指出代码生成具有极快的反馈循环(从推理到验证结果),这在医药、法律等领域是罕见的。这预示着AI Agent将深刻改变软件开发模式,开发者角色可能从直接编写者转变为AI工具的管理者和需求定义者 (来源: JvNixon, fabianstelzer)
💡 其他
美国超250名CEO联名呼吁将AI与计算机科学纳入K-12核心课程: 包括微软、Uber、Etsy等公司CEO在内的超过250名美国企业领袖联名在《纽约时报》发表公开信,敦促全美各州将AI和计算机科学设为K-12(幼儿园至高中)教育的核心必修课程。他们认为此举对保持美国全球竞争力至关重要,旨在培养“AI创造者”而非仅仅是“消费者”。信中提到,中国、巴西等国已将此类课程设为必修,而美国需加速改革。尽管面临联邦教育经费削减的挑战,但已有12个州将计算机科学列为高中毕业必修课,预计到2024年将有35个州制定相关计划。企业界此举也意在填补AI技能鸿沟,确保未来劳动力适应AI时代的需求 (来源: 36氪)
Benchmark合伙人警告AI初创企业警惕“模型升级贬值陷阱”: Benchmark普通合伙人Victor Lazarte在与20VC的访谈中指出,当前AI创业公司的营收增长可能存在泡沫,许多收入是“实验性的”,即基于当前模型能力构建的简单工作流(如用ChatGPT写催款函)所产生的。随着模型能力的快速迭代升级,这些“外挂式”应用或服务的价值可能会迅速贬值。他建议投资者和创业者在评估项目时,不仅要看增长,更要思考“模型更强以后,这套生意会增值还是贬值?”。他认为,真正有价值的项目是那些在模型升级后依然能增值,或者能解决“替代人力”等核心痛点的业务,并能形成数据闭环和平台效应 (来源: 36氪)
AI在内容创作领域的应用与变现探索: 作者分享了利用AI工作流创作短篇小说并实现单月过万收益的经验。核心思路是先通过AI学习和拆解目标内容体裁(如付费短篇小说)的创作规律和商业模式,形成结构化的创作框架(如“150字抓人→800字爽点→3次循环升级→3000字付费点→9500字高峰→闭环”),然后利用AI辅助内容生成。作者认为AI内容变现的本质是流量、带货、获客或直接作品交付,并强调“懂写作的你 + 智能AI工具 = 能变现的原创文”是未来写作的新范式 (来源: WeChat)