
关键词:AI安全, 人工智能伦理, AI智能体, 3D生成, 代码模型, AI风险评估, Gemini 2.5 Pro视频理解, AssetGen 2.0 3D生成, Seed-Coder代码模型, AgentOps智能体运维
🔥 聚焦
AI 安全风险引关注,专家呼吁借鉴核安全经验进行风险评估: 国际社会对人工智能潜在风险的担忧日益加剧,有专家(如Max Tegmark)呼吁AI公司在发布危险的AI系统前,应效仿罗伯特·奥本海默首次核试验时的安全计算方法,对人工智能可能失控的概率(康普顿常数)进行严格评估。此举旨在形成行业共识,推动建立全球AI安全机制,防止超级智能可能带来的灾难性后果。 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

新任教皇方济各(化名Leo XIV)高度关注AI带来的社会变革: 新当选的教皇方济各(据称为Leo XIV)已将人工智能确定为人类面临的主要挑战之一。他选择“Leo”作为名号,部分原因在于AI驱动的新社会问题和工业革命,这呼应了历史上教皇Leo XIII对第一次工业革命的回应。教皇强调AI对维护“人类尊严、正义和劳动”构成挑战,并计划在未来发布关于AI伦理的重要文件,显示出宗教领袖对AI技术伦理和社会影响的深度关切。 (来源: Reddit r/artificial, AymericRoucher, AravSrinivas, Reddit r/ArtificialInteligence)

谷歌发布76页AI智能体白皮书,阐述AgentOps及未来应用: 谷歌发布了一份长达76页的AI智能体白皮书,详细阐述了智能体的构建、评估和应用。白皮书强调了智能体运维(AgentOps)的重要性,作为生成式AI运维的分支,AgentOps关注智能体高效运行所需的工具管理、核心提示设置、记忆功能和任务分解等。白皮书还探讨了多智能体协作架构,其中不同智能体扮演规划、检索、执行和评估等角色,共同完成复杂任务,并展望了智能体在企业中辅助员工和自动化后台任务的应用前景,如NotebookLM企业版和Agentspace。 (来源: WeChat)

Meta推出AssetGen 2.0:文本/图像生成高质量3D素材: Meta发布了其最新的3D基础AI模型AssetGen 2.0,该模型能够根据文本和图像提示创建高质量的3D资产。AssetGen 2.0包含两个子模型:一个用于生成3D网格,采用单阶段3D扩散模型以提高细节和保真度;另一个TextureGen模型用于生成纹理,并引入了增强视图一致性、纹理修复和更高纹理分辨率的方法。该技术目前已在Meta内部用于创建3D世界,并计划于今年晚些时候向Horizon创作者推广。 (来源: Reddit r/artificial)

🎯 动向
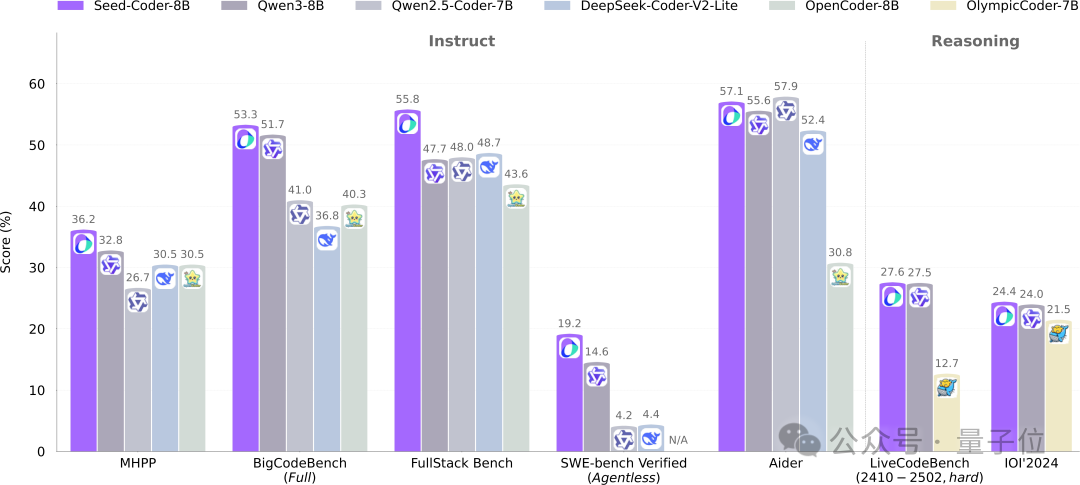
字节Seed开源8B代码模型Seed-Coder,采用模型管理数据新范式: 字节跳动Seed团队首次开源了其8B规模的代码模型Seed-Coder,包含Base、Instruct和Reasoning三个版本。该模型在多个代码生成基准测试中表现优异,特别是在HumanEval和MBPP上超越了Qwen3等模型。Seed-Coder的核心创新在于提出“模型中心”的数据处理方式,利用LLM自身生成和筛选高质量代码训练数据,包括文件级代码、仓库级代码、Commit数据和代码相关网络数据,总训练数据量达6T tokens。此举旨在降低人工参与,提升代码模型能力。 (来源: WeChat)
Gemini 2.5 Pro在视频理解上取得突破,实现音视频与代码原生融合: 谷歌最新的Gemini 2.5 Pro和Flash模型在视频理解能力上取得显著进展,Gemini 2.5 Pro在多个关键视频理解基准测试中达到SOTA水平,甚至超越了GPT 4.1。Gemini 2.5系列模型首次实现了音视频信息与代码等其他数据格式的原生无缝结合,能够将视频直接转换为互动应用(如学习App)、根据视频生成p5.js动画、以及精确检索和描述视频片段,展现了强大的时间推理能力。这些功能已在Google AI Studio、Gemini API和Vertex AI中可用。 (来源: WeChat)

ModelScope开源统一图像模型Nexus-Gen,对标GPT-4o图像能力: ModelScope团队推出了Nexus-Gen,一个能够同时处理图像理解、生成和编辑的统一多模态模型,旨在媲美GPT-4o的图像处理能力。该模型采用token → transformer → diffusion → pixels的技术路线,融合了MLLM的文本建模与Diffusion模型的图像渲染能力。为解决自回归预测连续图像Embedding时的误差累计问题,团队提出了预填充自回归策略。Nexus-Gen在约25M的图文数据上训练,包括ModelScope社区最新开源的ImagePulse编辑数据集。 (来源: WeChat)

Cursor 0.50版本发布,简化定价并增强多项代码编辑功能: AI代码编辑器Cursor发布了0.50版本,带来了重大更新。定价模式简化为基于请求的模式,Max模式支持所有顶级AI模型并采用基于token的定价。功能增强包括:新的Tab模型支持跨文件建议和代码重构;后台代理(预览版)支持并行运行多个代理并在远程环境执行任务;代码库上下文允许通过@folders添加整个代码库;优化了内联编辑UI,新增全文件编辑和发送至代理功能;长文件编辑引入搜索替换工具;支持多根工作区处理多个代码库;聊天功能增强,支持导出为Markdown和复制。 (来源: op7418)
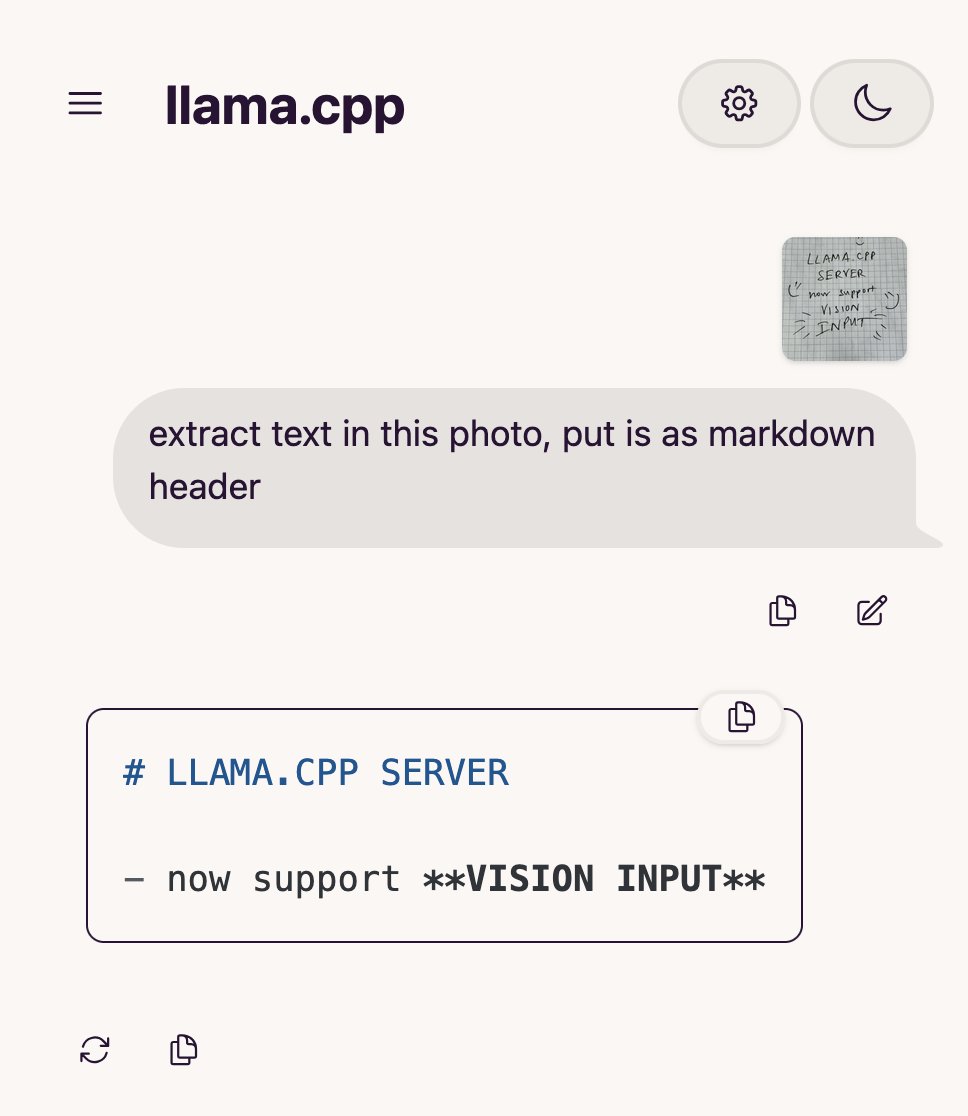
llama.cpp 新增视觉语言模型 (VLM) 支持,可构建完整视觉RAG流程: 开源项目llama.cpp宣布已支持视觉语言模型(VLM),用户现在可以通过llama.cpp服务器和Web UI使用视觉功能。这一更新意味着可以在llama.cpp上加载支持多LoRA的同一基础模型以及嵌入模型,从而能够构建完整的视觉检索增强生成(Vision RAG)流程。此举进一步扩展了llama.cpp在本地运行大型语言模型的能力,使其能够处理多模态任务。 (来源: mervenoyann, mervenoyann)
腾讯发布HunyuanCustom:基于混元Video的定制化视频生成架构: 腾讯在Hugging Face上发布了HunyuanCustom,这是一个专为定制化视频生成设计的多模态驱动架构。该工作建立在HunyuanVideo的基础之上,特别强调在生成视频时保持主体的一致性,同时支持图像、音频、视频和文本等多种条件的输入,为用户提供了更灵活和个性化的视频创作能力。 (来源: _akhaliq)
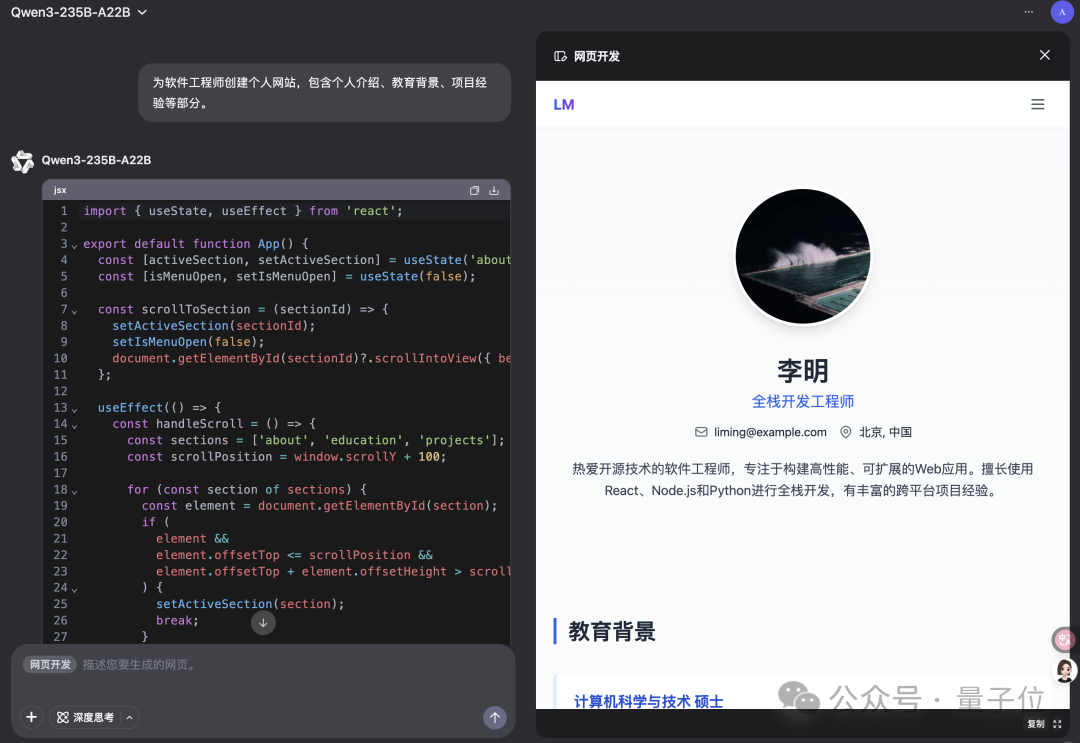
Qwen Chat新增“网页开发”模式,一句话生成React网页应用: 阿里巴巴Qwen Chat推出“网页开发”(Web Dev)模式,用户仅需一句话指令即可生成包含HTML、CSS和JavaScript的网页应用,底层使用React框架和Tailwind CSS。该功能能够快速创建个人网站、复刻现有网页界面(如Twitter、GitHub)或根据描述构建特定表单和动画。用户可以选择不同Qwen模型并结合“深度思考”模式提升网页质量。此功能旨在简化前端开发流程,快速搭建应用原型。 (来源: WeChat)
宇树科技回应Go1机器狗安全漏洞,强调后续产品已升级: 宇树科技针对其已停产约两年的Go1机器狗系列存在“后门漏洞”的传闻作出回应,承认该问题为安全漏洞。攻击者可利用第三方云隧道服务的管理密钥修改用户设备数据、获取摄像头画面及系统权限。宇树科技表示,后续机器人系列采用了更安全的升级版本,不受此漏洞影响。该事件引发了对智能机器人供应链安全和数据隐私的担忧,尤其是在人形机器人商业化元年的背景下,行业面临技术攻关、成本控制和商业化路径探索等多重挑战。 (来源: 36氪)

Claude Code 现支持引用其他 .MD 文件,优化指令组织: Anthropic 的 Claude Code 更新了其功能,版本 0.2.107 允许 CLAUDE.md 文件导入其他 Markdown 文件。用户可以通过在主 CLAUDE.md 文件中添加 [u/path/to/file].md 的方式,在启动时加载额外的文件内容。这一改进使得用户可以更好地组织和管理 Claude 的指令,提高了大型项目中指令配置的可靠性和模块化程度,解决了以往依赖分散文件可能导致的混乱问题。 (来源: Reddit r/ClaudeAI)

美国版权局对AI预训练采取更强硬立场,削弱“合理使用”辩护: 美国版权局最新发布的报告对AI模型预训练阶段使用受版权保护材料的问题采取了更为强硬的立场。报告指出,由于AI实验室现在声称其模型能够与权利持有人竞争(例如生成与原创作品相似的内容),这削弱了他们在版权侵权诉讼中以“合理使用”(fair use)为自己辩护的力度。这一转变可能对AI模型的训练数据来源和合规性产生重大影响。 (来源: Dorialexander)

英伟达发布RTX Pro 5000专业显卡,搭载48GB GDDR7显存: 英伟达推出了新款专业级桌面GPU RTX Pro 5000,基于Blackwell架构。该显卡配备48GB GDDR7显存,显存带宽高达1344 GB/s,功耗为300W。虽然官方称其为“廉价”的48GB Blackwell显卡,但预计售价仍较高(有评论提及4000美元级别),主要面向专业工作站用户,为AI模型训练、大型3D渲染等任务提供强大算力支持。 (来源: Reddit r/LocalLLaMA)

🧰 工具
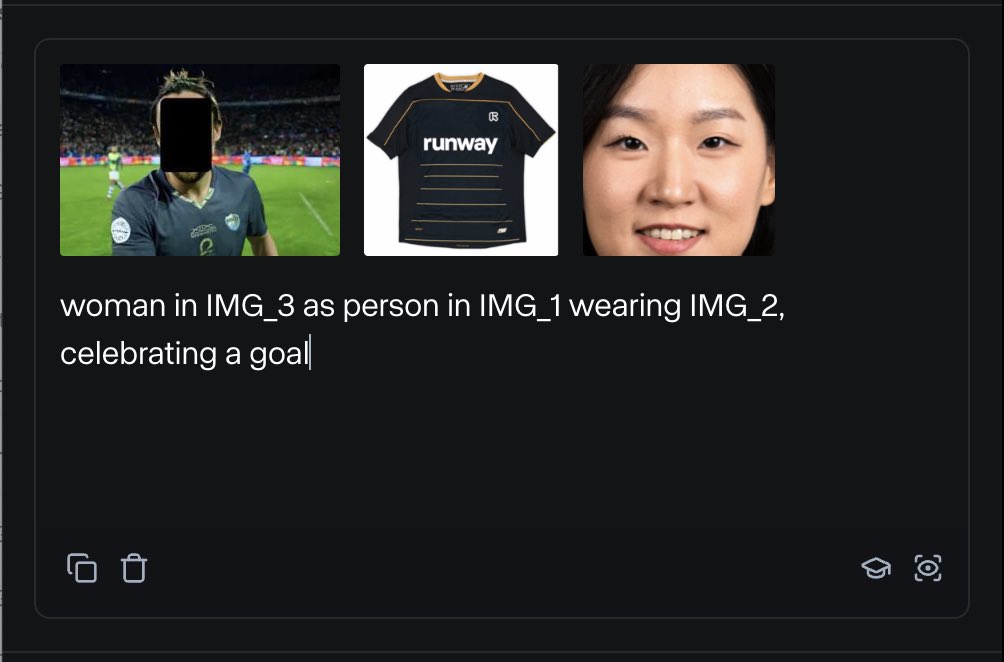
RunwayML推出References功能,可混合多种参考素材生成内容: RunwayML 的新功能 “References” 允许用户将不同的参考素材(如图像、风格)作为“原料”进行混合,并能根据这些“原料”的任意组合生成新的视觉内容。该功能被视为一个近乎实时的创作机器,能够帮助用户快速实现各种创意想法,极大地扩展了AI在视觉内容创作方面的灵活性和可能性。 (来源: c_valenzuelab)
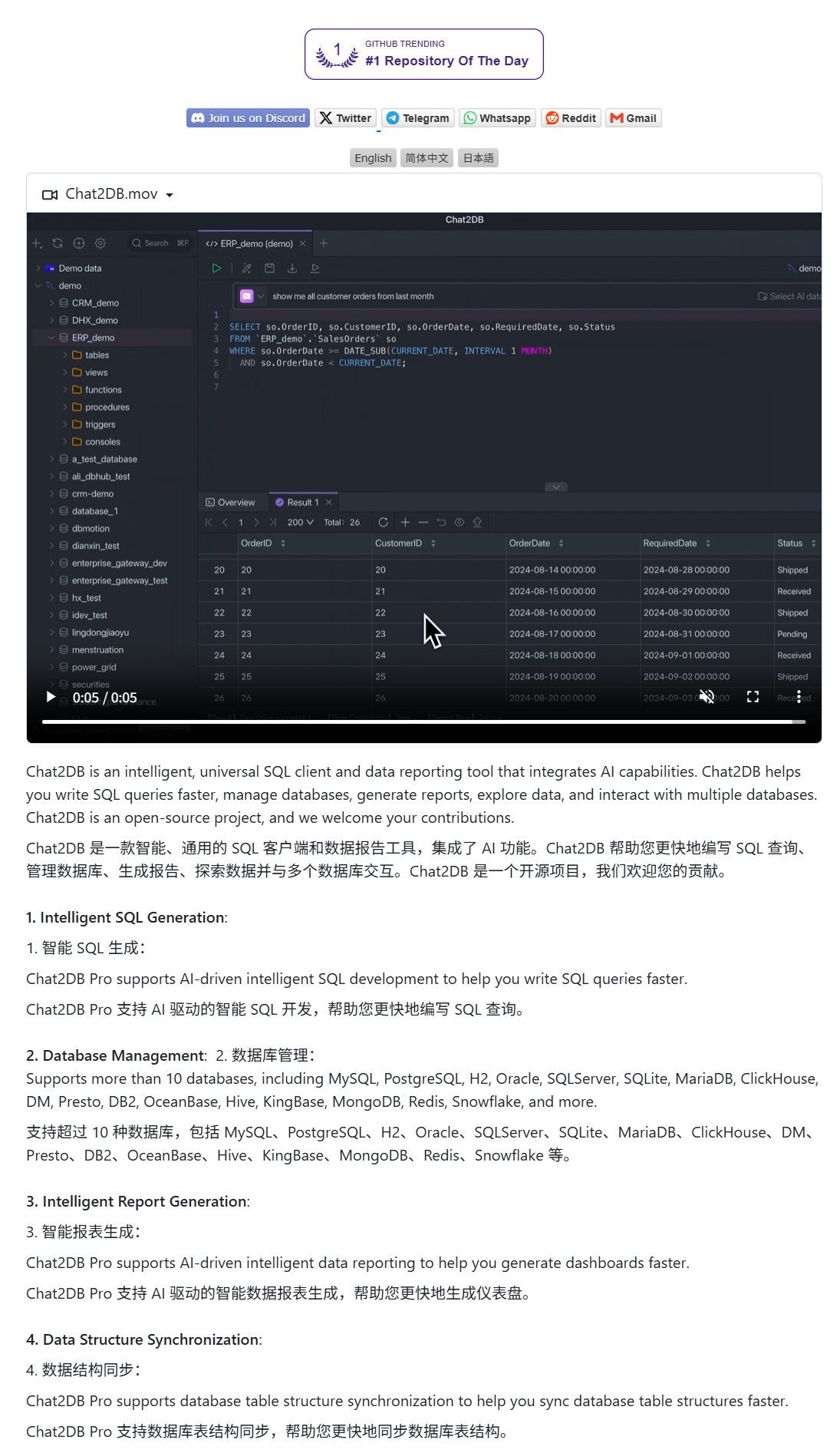
Chat2DB:自然语言操作数据库的AI客户端: Chat2DB是一款AI驱动的数据库客户端工具,允许用户通过自然语言与数据库进行交互。例如,用户可以提问“本月消费最多的客户是谁?”,Chat2DB能够利用AI理解问题,并根据数据库的表结构自动生成相应的SQL查询语句并执行查询,返回结果。这大大降低了数据库操作的技术门槛,使非技术人员也能方便地进行数据查询和分析。该项目已在GitHub开源。 (来源: karminski3)
Qwen 3 8B模型展现出色代码能力,可生成HTML键盘: Qwen 3 8B模型(Q6_K量化版)尽管参数量较小,但在代码生成方面表现出色。用户通过两个简短的提示,成功让该模型生成了一个可玩的HTML键盘代码。这显示了小型化模型在特定任务上也能达到较高实用性的潜力,尤其对于资源有限的本地部署场景具有吸引力。 (来源: Reddit r/LocalLLaMA)
Ollama Chat:类Claude界面的本地LLM聊天工具: Ollama Chat 是一款为本地大语言模型设计的Web聊天界面,其UI风格和用户体验借鉴了Anthropic的Claude。该工具支持文本文件上传、对话历史记录和系统提示词设置,旨在提供一个易于使用且美观的本地LLM交互方案。项目已在GitHub开源,方便用户自行部署和使用。 (来源: Reddit r/LocalLLaMA)
AI生成个性化卡片(生日/母亲节)的提示词技巧: 用户分享了使用AI生成个性化卡片(如生日卡、母亲节卡)的提示词技巧。关键在于明确卡片主题(如母亲节、生日)、风格(如女性风格、儿童风格)、收件人(如妈妈、Sandy、Jimmy)、年龄(如30岁、6岁)以及祝福语的具体内容或温馨甜美的基调。通过组合这些元素,可以引导AI生成符合需求的卡片设计。 (来源: dotey)

📚 学习
谷歌发布提示工程白皮书,指导用户如何有效提问: 谷歌发布了一份关于提示工程的白皮书(可通过Kaggle访问),旨在教用户如何更有效地向AI模型提问。教程内容清晰,详细介绍了如何明确输出要求、约束输出范围以及如何使用变量等技巧,帮助用户提升与大语言模型交互的效率和效果,从而获得更精准、更有用的回答。 (来源: karminski3)

港科广团队提出MultiGO:分层高斯建模实现单图生成3D纹理人体: 香港科技大学(广州)团队提出名为MultiGO的创新框架,通过分层高斯建模从单张图像重建带有纹理的3D人体模型。该方法将人体分解为骨骼、关节、皱纹等不同精度层级,逐级细化。核心技术采用高斯溅射点作为3D基元,并设计了骨架增强、关节增强和皱纹优化模块。该研究成果已入选CVPR 2025,为单图3D人体重建提供了新思路,代码即将开源。 (来源: WeChat)

清华、复旦、港科大联合发布RM-BENCH:首个奖励模型评估基准: 针对当前大语言模型奖励模型评估中存在的“形式大于内容”及风格偏见问题,清华大学、复旦大学和香港科技大学的研究团队联合发布了首个系统性的奖励模型评测基准RM-BENCH。该基准涵盖聊天、代码、数学和安全四大领域,通过评估模型对细微内容差异的敏感度和对风格偏差的鲁棒性,旨在建立更可靠的“内容裁判”新标准。研究发现现有奖励模型在数学和代码领域表现不佳,且普遍存在风格偏差。该成果已被ICLR 2025 Oral接收。 (来源: WeChat)

天大与腾讯开源COME方案:5行代码提升TTA鲁棒性,解决模型崩溃: 天津大学与腾讯合作提出COME (Conservatively Minimizing Entropy) 方法,旨在解决测试时自适应 (TTA) 过程中因熵最小化 (EM) 导致的模型过度自信和崩溃问题。COME通过引入主观逻辑显式建模预测不确定性,并采用自适应Logit约束(冻结Logit范数)间接控制不确定性,从而实现保守的熵最小化。该方法无需修改模型架构,仅需少量代码即可嵌入现有TTA方法,在ImageNet-C等数据集上显著提升模型鲁棒性和准确率,同时计算开销极小。论文已被ICLR 2025接收,代码已开源。 (来源: WeChat)
华为与信工所提出DEER:思维链“动态提前退出”机制提升LLM推理效率与精度: 华为联合中科院信工所提出了DEER(Dynamic Early Exit in Reasoning)机制,旨在解决大语言模型在长思维链(Long CoT)推理中可能出现的过度思考问题。DEER通过监控推理转换点、诱导试验性答案并评估其置信度,动态判断是否提前终止思考并生成结论。实验表明,在DeepSeek系列等推理LLM上,DEER无需额外训练即可平均减少31%-43%的思维链生成长度,同时将准确率提高1.7%-5.7%。 (来源: WeChat)

中科院等提出R1-Reward:通过稳定强化学习训练多模态奖励模型: 中科院、清华、快手和南京大学的研究团队提出了R1-Reward,一种通过稳定的强化学习算法StableReinforce训练多模态奖励模型(MRM)的方法,旨在提升其长时推理能力。StableReinforce改进了PPO等现有RL算法在训练MRM时可能遇到的不稳定性问题,通过Pre-Clip策略、优势过滤器和新颖的一致性奖励机制(引入裁判模型检查分析与答案的一致性)来稳定训练过程。实验表明,R1-Reward在多个MRM基准上性能优于SOTA模型,且通过推理时多次采样投票可进一步提升性能。 (来源: WeChat)
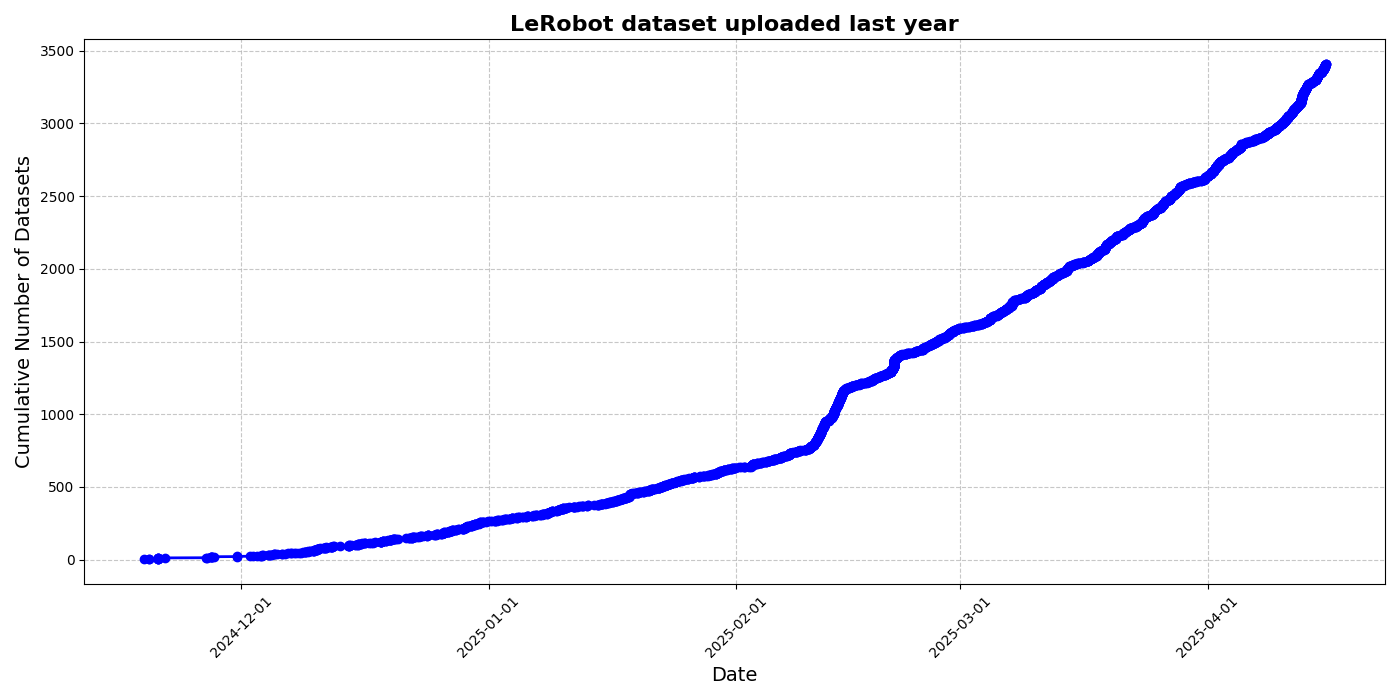
HuggingFace发布LeRobot社区数据集倡议,推动机器人“ImageNet时刻”: HuggingFace发起LeRobot社区数据集项目,旨在构建机器人领域的“ImageNet”,通过社区贡献推动通用机器人技术发展。文章强调了数据多样性对机器人泛化能力的重要性,并指出现有机器人数据集多源于受限的学术环境。LeRobot通过简化数据采集、上传流程及降低硬件成本,鼓励用户分享不同机器人(如So100、Koch机械臂)在多样任务(如下棋、操作抽屉)中的数据。同时,文章提出了数据质量标准和最佳实践清单,以应对数据标注不一致、特征映射模糊等挑战,促进高质量、多样化机器人数据集的建设。 (来源: HuggingFace Blog, LoubnaBenAllal1)
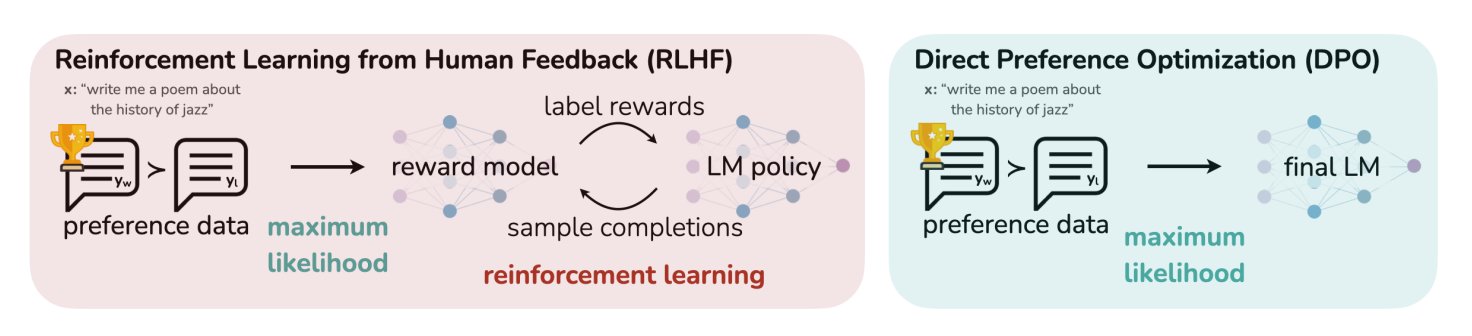
HuggingFace博文总结LLM的11种对齐与优化算法: TheTuringPost分享了一篇HuggingFace上的文章,其中总结了11种用于大型语言模型(LLM)的对齐和优化算法。这些算法包括PPO(近端策略优化)、DPO(直接偏好优化)、GRPO(组相对策略优化)、SFT(监督微调)、RLHF(人类反馈强化学习)以及SPIN(自玩微调)等。文章提供了这些算法的链接和更多信息,为研究者和开发者提供了LLM优化方法的概览。 (来源: TheTuringPost)
UC Berkeley分享CS280研究生计算机视觉课程材料: 加州大学伯克利分校的Angjoo Kanazawa和Jitendra Malik教授分享了他们本学期教授的研究生计算机视觉课程CS280的全部讲座材料。他们认为这套结合了经典与现代计算机视觉内容的材料效果良好,并将其公开,供学习者参考。 (来源: NandoDF)
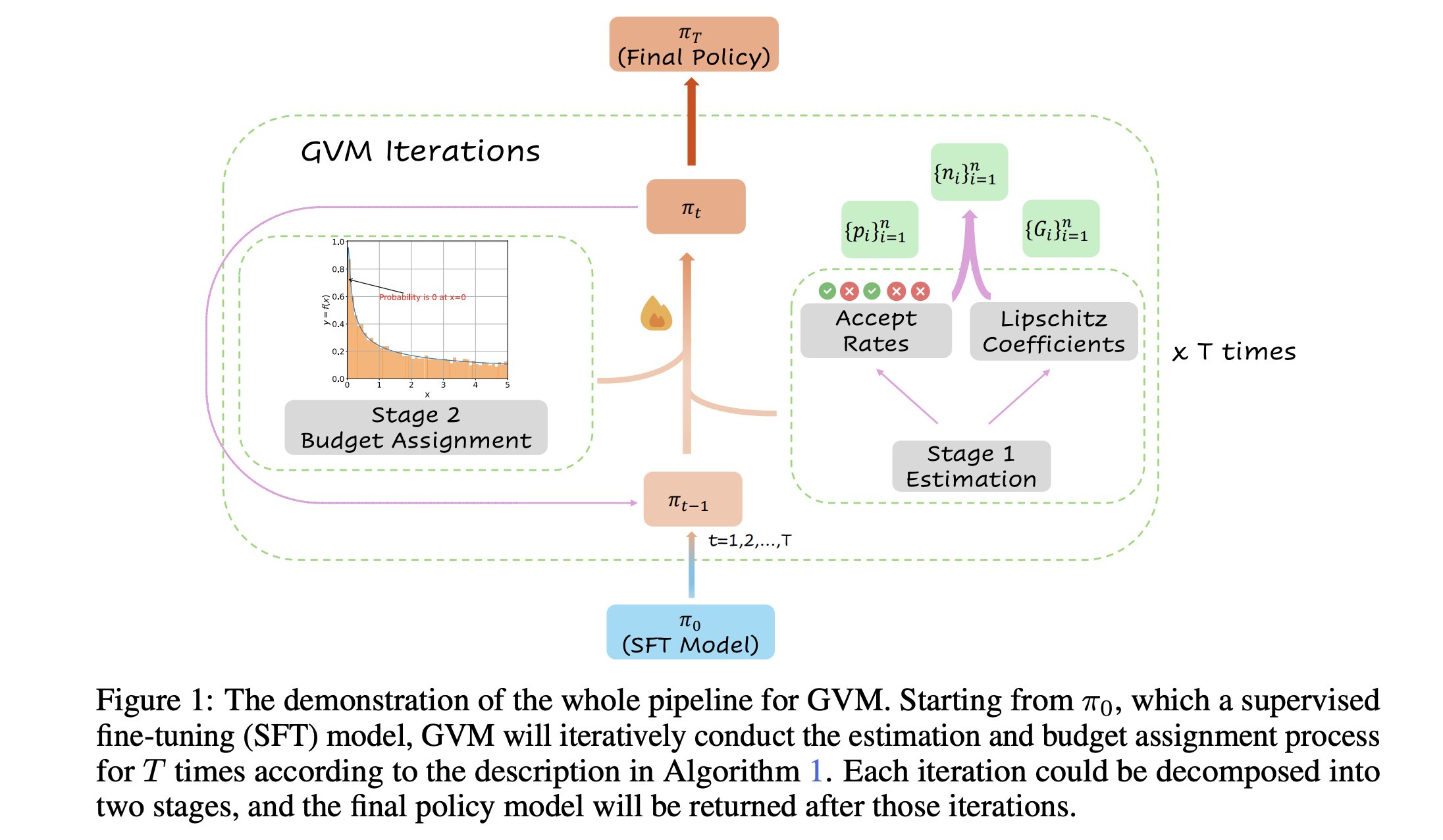
GVM-RAFT:优化思维链推理器的动态采样框架: 一篇新论文介绍了GVM-RAFT框架,该框架通过为每个提示动态调整采样策略来优化思维链(chain-of-thought)推理器,旨在最小化梯度方差。据称,这种方法在数学推理任务上实现了2-4倍的加速,并提升了准确性。 (来源: _akhaliq)
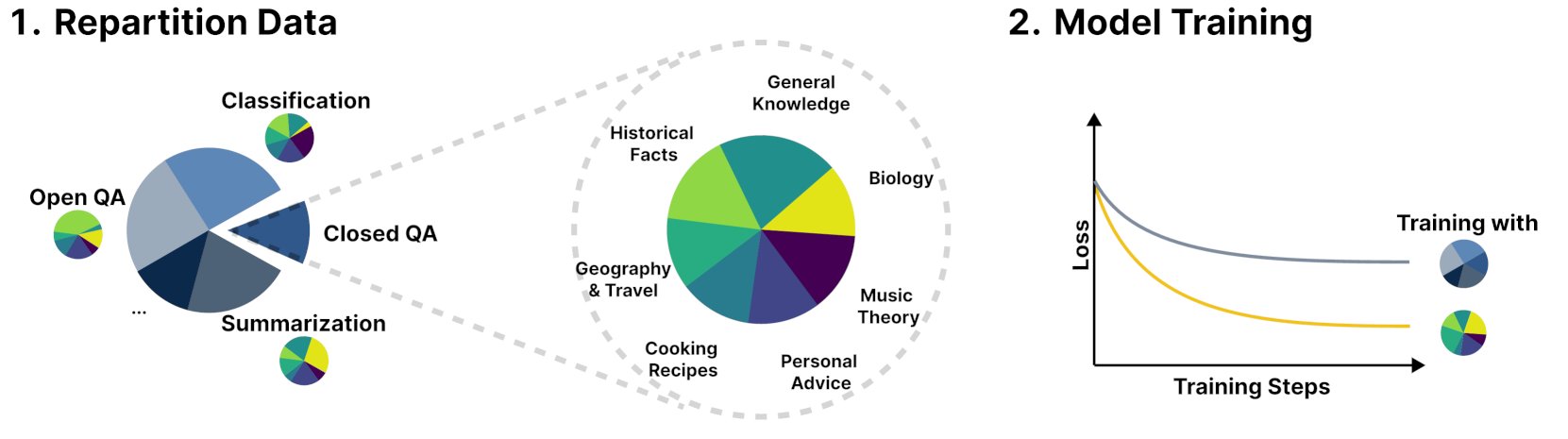
新框架R&B通过动态平衡训练数据提升语言模型性能: 一篇名为R&B的新研究提出了一种新框架,通过动态平衡语言模型的训练数据,仅增加0.01%的额外计算量即可提升模型性能。这种方法旨在优化数据利用效率,以较小的成本换取模型表现的改善。 (来源: _akhaliq)
论文探讨AI安全新视角:将社会与技术进步视为缝补被褥: 一篇在arXiv上发表的新论文《Societal and technological progress as sewing an ever-growing, ever-changing, patchy, and polychrome quilt》提出了一种新的AI安全观,主张将AI安全的核心聚焦于防止分歧升级为冲突。该论文将社会和技术的进步比作缝制一块不断扩大、变化、充满补丁和色彩斑斓的被褥,强调了在复杂系统中维护稳定与合作的重要性。 (来源: jachiam0)
论文探讨自回归语言模型中的适应性计算: 讨论提及深度学习中适应性计算的趣味性,并列举了相关技术发展:PonderNet (DeepMind, 2021) 作为早期整合神经网络和循环的工具;扩散模型通过多次前向传播进行计算;以及近期的推理型语言模型通过生成任意数量的token实现类似效果。这反映了模型在计算资源分配和使用上的灵活性和动态性趋势。 (来源: jxmnop)
论文探讨“坏数据”如何催生“好模型”: 一篇哈佛大学2025年的论文《When Bad Data Leads to Good Models》(arXiv:2505.04741) 探讨了在某些情况下,看似质量不高的数据(如包含4chan内容的预训练数据)反而可能有助于模型对齐和隐藏其“能量水平”(power level),使其表现更优。这引发了关于数据质量、模型对齐以及模型行为真实性的讨论。 (来源: teortaxesTex)

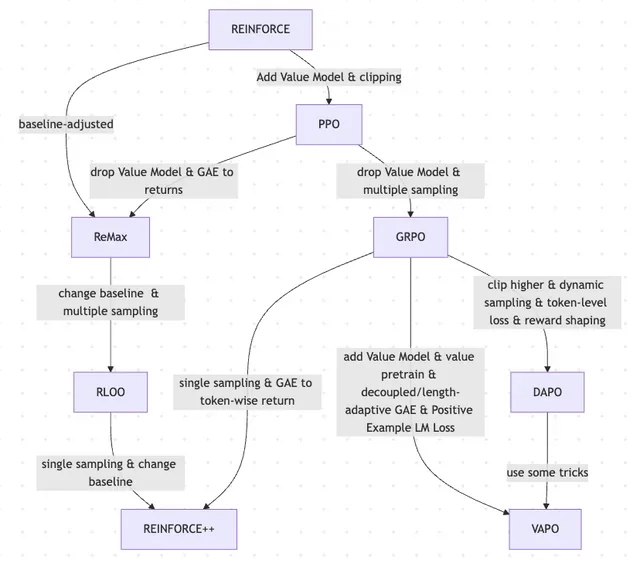
论文探讨RLHF及其变体的演进,从REINFORCE到VAPO: 一篇研究文章总结了用于微调大型语言模型(LLMs)的强化学习(RL)方法的演变历程。文章追溯了从经典的PPO和REINFORCE算法开始,到GRPO、ReMax、RLOO、DAPO和VAPO等近期方法的演变,分析了其中价值模型的舍弃、采样策略的改变、基线的调整以及奖励塑造和token级损失等技巧的应用。该研究旨在清晰展示RLHF及其变体在LLM对齐领域的研究图景。 (来源: Reddit r/MachineLearning)
论文“Absolute Zero”:AI在无人类数据情况下进行强化自学习推理: 一篇名为“Absolute Zero: Reinforced Self-Play Reasoning with Zero Data” (arXiv:2505.03335) 的白皮书探讨了训练逻辑AI的新方法。研究人员在不使用人类标记数据集的情况下训练逻辑AI模型,模型能自行生成推理任务、解决问题并通过代码执行验证解决方案。这引发了关于AI能否在完全没有先验知识(如数学、物理、语言)的原始环境中,从零开始发明符号表示、定义逻辑结构、发展数字系统并构建因果模型的讨论,以及这种“异类智能”的潜力和风险。 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial)
复旦大学智能人机交互实验室招收2026级硕博生: 复旦大学计算机科学技术学院的智能人机交互实验室正在招收2026级夏令营/推免的硕士和博士研究生。实验室由尚笠教授领导,研究方向包括可穿戴AGI (MemX智能眼镜与LLM结合)、开源具身智能、模型压缩(从大到小)以及机器学习系统(如ML编译优化、AI处理器)。实验室致力于探索以人为中心的智能,融合大模型与智能可穿戴、具身智能系统的人机交互新范式。 (来源: WeChat)

💼 商业
10家估值超10亿美元、员工少于50人的AI初创公司概览: Business Insider盘点了10家估值超过10亿美元但员工人数不足50人的AI初创公司。其中包括Safe Superintelligence(估值320亿美元,20名员工)、OG Labs(估值20亿美元,40名员工)、Magic(估值15.8亿美元,20名员工)、Sakana AI(估值15亿美元,28名员工)等。这些公司展示了AI领域以小团队撬动高估值的潜力,反映了技术和创新在资本市场的高价值。 (来源: hardmaru)
傅利叶智能深化康养场景,与上海国际医学中心合作打造具身智能康复基地: 具身智能独角兽傅利叶在其首届具身智能生态峰会上宣布,将与上海国际医学中心合作,共同推动具身智能机器人在康复医疗场景的应用,包括标准建设、方案共创和科研攻关,并打造国内首个具身智能康复示范基地。傅利叶创始人顾捷提出未来十年核心战略为“立足康养、聚焦交互、服务于人”,强调医疗康复是其根基。公司自2015年成立以来,从康复机器人逐步扩展到通用人形机器人GR-1及GRx系列,已累计出货数百台。 (来源: 36氪)
Meta被曝招募前五角大楼官员,或加强军事领域布局: 据福布斯报道,Meta公司正在招募前五角大楼官员,此举可能意味着该公司正计划加强其在军事技术或国防相关领域的业务。这一动向引发了关于大型科技公司参与军事应用的讨论和关注。 (来源: Reddit r/artificial)

🌟 社区
Andrej Karpathy提出LLM学习缺少重要范式“系统提示学习”引热议: Andrej Karpathy认为当前LLM学习缺少一个重要范式,他称之为“系统提示学习”。他指出,预训练是为了知识,微调(监督/强化学习)是为了习惯性行为,两者都涉及参数改变,但大量的人类交互和反馈似乎并未充分利用。他将其比作给《Memento》主角一个记事本,用于存储全局问题解决知识和策略。此观点引发广泛讨论,有人认为这与DSPy的理念相近,或涉及记忆/优化、持续学习问题,并探讨了如何在Langgraph中实现类似机制。 (来源: lateinteraction, hwchase17, nrehiew_, tokenbender, lateinteraction, lateinteraction)
AI公司要求求职者勿用AI写求职申请引热议: Anthropic等AI公司要求求职者在撰写求职申请(如简历)时不应使用AI工具,这一规定引发了社区讨论。有招聘方表示,收到的AI生成的简历“文字垃圾”现象严重,即使是资深人士也可能因此失去重点。但也有求职者认为,AI能帮助他们更好地针对职位要求优化简历,突出技能,提高可读性。讨论也延伸到LinkedIn等平台充斥AI生成内容的现象,以及是否应采用视频等其他方式评估求职者。 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

AI生成内容的“可识别性”引发讨论,用户认为易被察觉: 社区讨论指出,由AI(尤其是ChatGPT)生成的内容很容易被识别出来,不仅仅是因为特定的标点符号(如em dashes)或句式(如“That’s not x; that’s y.”),更在于其特有的“节奏感”和“平淡感”。一旦识别出AI痕迹,内容会显得不真实、缺乏个性。有用户表示在邮件、社交媒体帖子甚至视频游戏中都遇到了此类情况,认为直接使用AI生成全部内容会导致内容乏味和不真诚,建议用户应将AI作为工具进行修改和个性化。 (来源: Reddit r/ChatGPT)
AI发展呈现“蜜月期-反弹期”循环,反映人类对真实性的偏好: 有观点认为,新型生成式AI模型(文本、图像、音乐等)的出现往往伴随着一个“蜜月期”,人们为其能力感到惊艳。但很快,当人们开始识别出AI生成的“套路”或“痕迹”后,便会产生反弹,从赞扬转向怀疑,甚至认为其“没有灵魂”。这种快速学习识别AI作品并倾向于有瑕疵的人类创作的现象,可能意味着AI更多是作为辅助工具,而非完全取代人类创作者,因为人们重视作品背后的故事、作者意图和真实性。 (来源: Reddit r/ArtificialInteligence)
Anthropic内部AI代码生成率超70%,引发对AI自迭代的联想: Anthropic的Mike Krieger透露,公司内部超过70%的拉取请求(pull requests)现在由AI生成。这一数据引发了社区讨论,有人联想到机器自我编辑和改进的场景,类似于科幻作品中的情节。同时,也有人对这一数据的真实性和具体含义(例如这些PR的复杂程度)表示疑问。 (来源: Reddit r/ClaudeAI)

英伟达CEO黄仁勋强调全员拥抱AI智能体,AI将重塑开发者角色: 英伟达CEO黄仁勋表示,公司将全员配备AI助手,AI智能体将嵌入日常开发,优化代码、发现漏洞、加速原型设计。他认为未来每个人都将指挥多个AI助手,生产力将呈指数级增长。Meta CEO扎克伯格、微软CEO纳德拉等人也持类似观点,认为AI将完成大部分代码工作,开发者角色将转变为“指挥AI”和“定义需求”。这一趋势预示着软件开发周期将发生巨变,AI编程工具如GitHub Copilot、Cursor等将普及。 (来源: WeChat)

讨论:ML研究者每年阅读1000-2000篇论文是否可行?: 社区中有讨论提到,顶尖的机器学习研究者每年可能会阅读近2000篇论文。对此,有评论认为,论文阅读数量本身只是一个代理指标,真正重要的是从大量信息中筛选信号、提取有效信息并正确应用的能力。能够跟上领域内的亮点和趋势,并在需要时深入研究特定内容,这种信息过滤能力是本世纪的关键技能。 (来源: torchcompiled)
讨论:购买GPU vs. 租用GPU进行模型训练/微调: 机器学习实践者在选择GPU资源时面临购买或租用的抉择。有经验者建议采用混合策略:本地配置一块性能尚可的消费级GPU用于小型实验,而对于大规模训练任务则租用云GPU。选择取决于模型复杂度、数据量和预算。云GPU在ML Ops组织方面有优势,但同价位下T4等常见云GPU性能可能不如高端消费卡(如3090/4090),不过云端可提供A100/H100等拥有更大显存的顶级GPU。 (来源: Reddit r/MachineLearning)
💡 其他
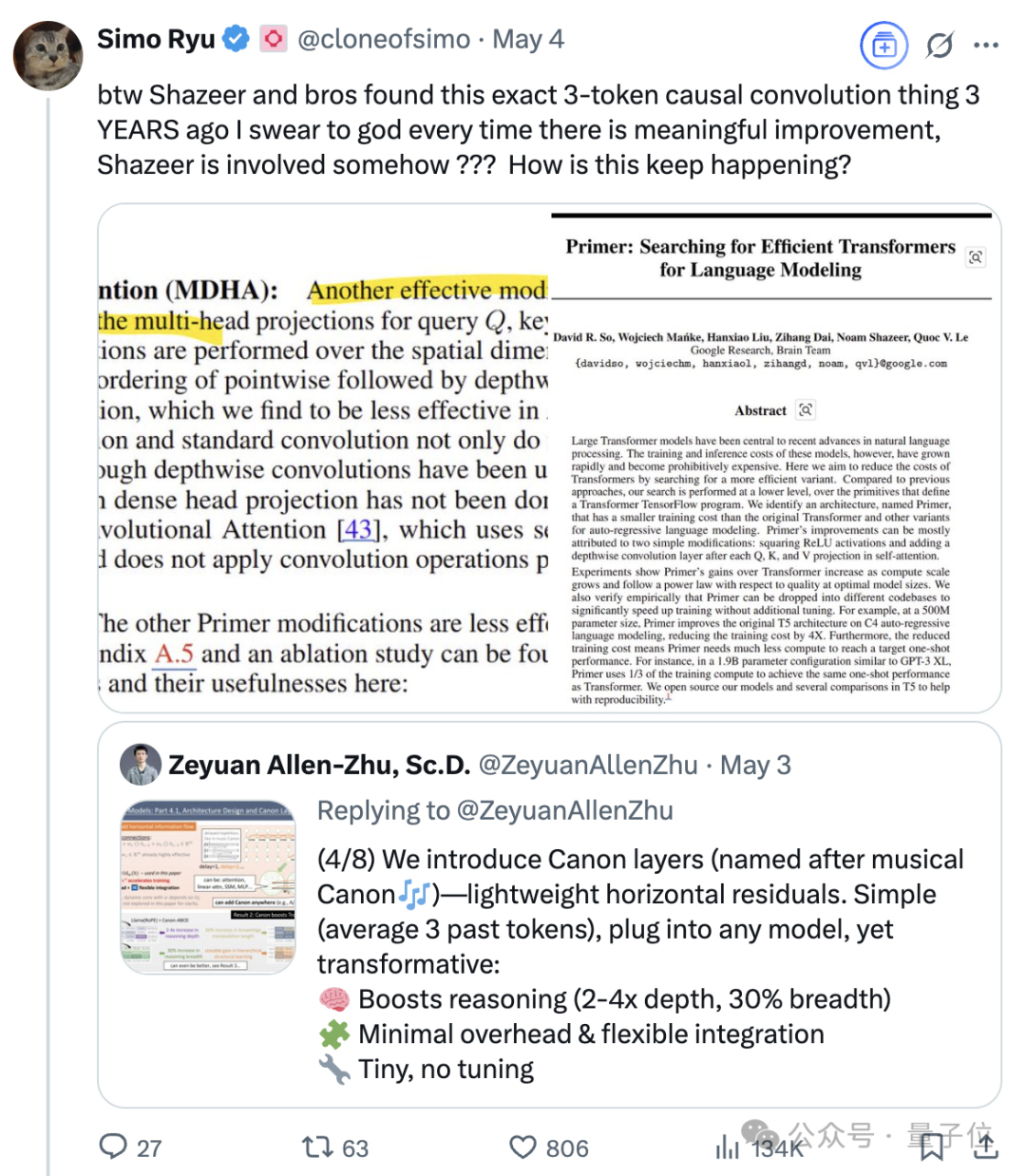
Transformer八子之一Noam Shazeer的持续影响力: Noam Shazeer,作为Transformer架构论文《Attention Is All You Need》的八位作者之一,其贡献被广泛认为是最大的。他的影响力远不止于此,还包括早期将稀疏门控专家混合(MoE)引入语言模型的研究、Adafactor优化器、多查询注意力(MQA)以及Transformer中的门控线性层(GLU)等。这些工作奠定了当前主流大语言模型架构的基础,使得Shazeer被认为是AI领域持续定义技术范式的关键人物。他曾离开谷歌创办Character.AI,后又随公司被收购回归谷歌,联合领导Gemini项目。 (来源: WeChat)
科技巨头面临AI引发的“中年危机”: 文章分析指出,包括谷歌、苹果、Meta、特斯拉在内的“科技七巨头”正面临人工智能带来的颠覆性挑战,陷入“中年危机”。谷歌的搜索业务受到AI直接问答模式的威胁,苹果在AI创新上进展缓慢,Meta试图将AI融入社交但Llama 4表现未达预期,特斯拉则面临销量和股价下滑的压力。这些昔日的行业领导者,如同《创新者的窘境》中的案例,需要应对AI带来的新市场和新模式的冲击,否则可能成为AI时代的“诺基亚”。 (来源: WeChat)

谷歌AI在模拟医疗对话中表现优于人类医生: 研究表明,一个经过训练用于进行医疗访谈的AI系统,在与模拟患者对话和根据病史列出可能诊断方面,其表现匹配甚至超过了人类医生。研究人员认为,这种AI系统有潜力帮助实现医疗服务的普及化和民主化。 (来源: Reddit r/ArtificialInteligence)
