
关键词:OpenAI, AI芯片, 大模型, 强化学习, AI基础设施, 多模态AI, 智能体, RAG, OpenAI国家级AI计划, 英伟达H20芯片出口管制, DeepSeek-R1推理优化, AI光学显微镜Meta-rLLS-VSIM, 字节跳动Seed-Coder代码大模型
🔥 聚焦
OpenAI推出「国家级AI」计划,助力全球AI基础设施建设: OpenAI启动「OpenAI for Countries」项目,作为其「星际之门」计划的一部分,旨在协助各国建立本地AI数据中心、定制化ChatGPT,并推动AI生态发展。CEO萨姆·奥特曼已实地考察位于德州Abilene的首个超级计算园区,该园区是耗资5000亿美元的「星际之门」计划的一部分,旨在打造全球最大的AI训练设施。此举标志着OpenAI将与多国政府合作,通过基础设施建设和技术共享,推动AI技术的全球普及与应用,首批计划与10个国家或地区合作 (来源: WeChat)

传特朗普政府拟废除AI芯片出口三级限制,或采用更简化的全球许可体系: 据外媒报道,特朗普政府计划撤销拜登时代末期制定的《人工智能扩散框架》(FAID),该框架原定对全球AI芯片出口实施三级分类限制。特朗普团队认为该框架过于繁琐且阻碍创新,倾向于用一个更简单的全球许可体系替代,并通过政府间协议执行。此举可能对英伟达等芯片制造商的全球市场策略产生影响,旨在巩固美国在AI领域的创新和主导地位 (来源: WeChat)

SGLang团队大幅优化DeepSeek-R1推理性能,吞吐量提升26倍: SGLang、英伟达等机构的联合团队通过对SGLang推理引擎的全面升级,在四个月内将DeepSeek-R1模型在H100 GPU上的推理性能提升了26倍。优化方案包括预填充与解码分离(PD分离)、大规模专家并行(EP)、DeepEP、DeepGEMM及专家并行负载均衡器(EPLB)等技术。在处理2000个token输入序列时,实现了每个节点每秒52.3k输入token和22.3k输出token的吞吐量,接近DeepSeek官方数据,并显著降低了本地部署成本 (来源: WeChat)

OpenAI科学家Dan Roberts:强化学习的扩展将推动AI发现新科学,或9年实现爱因斯坦级AGI: OpenAI研究科学家Dan Roberts在红杉资本AI Ascent上发表演讲,探讨了强化学习(RL)在未来AI模型构建中的核心作用。他认为,通过持续扩大RL的规模,AI模型不仅能提升在数学推理等任务上的表现,更能通过“测试时间计算”(即模型思考时间越长,表现越好)实现科学发现。他以爱因斯坦发现广义相对论为例,推测若AI能进行长达8年的计算和思考,或能在9年后达到类似爱因斯坦的科学突破水平。Roberts强调,未来的AI发展将更侧重于RL计算,甚至可能主导整个训练过程 (来源: WeChat)

🎯 动向
英伟达Jim Fan:机器人将通过「物理图灵测试」,模拟与生成式AI是关键: 英伟达机器人部门主管Jim Fan在红杉AI Ascent演讲中提出「物理图灵测试」概念,即人类无法分辨任务是由人还是机器人完成。他指出当前机器人数据获取成本高昂,模拟技术是关键,特别是结合生成式AI(如视频生成模型微调)来创造多样化、大规模的训练数据(“数字表亲”而非精确的“数字孪生”)。他预测,通过大规模模拟和视觉-语言-动作模型(如英伟达GR00T),未来物理API将无处不在,机器人将能完成复杂日常任务,与环境智能融为一体 (来源: WeChat)
字节跳动发布Seed-Coder系列代码大模型,8B版本表现优越: 字节跳动推出了Seed-Coder系列代码大模型,包括8B、14B等多个版本。其中,Seed-Coder-8B在SWE-bench、Multi-SWE-bench、IOI等多个代码能力评测基准上表现突出,据称优于Qwen3-8B和Qwen2.5-Coder-7B-Inst。该系列模型包含Base、Instruct和Reasoner版本,其核心理念是“让代码模型为自己策划数据”,在代码推理和软件工程能力方面有显著提升。模型已在Hugging Face和GitHub开源 (来源: Reddit r/LocalLLaMA, karminski3, teortaxesTex)
阿里开源ZeroSearch框架,利用LLM模拟搜索降低AI训练成本88%: 阿里巴巴研究人员发布了名为“ZeroSearch”的强化学习框架,该框架允许大语言模型(LLM)通过模拟搜索引擎进行高级搜索功能的开发,而无需在训练过程中调用昂贵的商业搜索引擎API(如谷歌)。实验表明,使用3B LLM作为模拟搜索引擎即可有效提升策略模型的搜索能力,14B参数的检索模块性能甚至超越谷歌搜索,同时API成本降低了88%。该技术已在GitHub和Hugging Face开源,支持Qwen-2.5、LLaMA-3.2等模型系列 (来源: WeChat)

Gemini API推出隐式缓存功能,可节省75%成本: 谷歌Gemini API最近为Gemini 2.5模型系列(Pro和Flash)启用了隐式缓存功能。当用户的请求命中缓存时,可自动节省高达75%的成本。同时,触发缓存的最低token要求也已降低,2.5 Flash模型降至1K token,2.5 Pro模型降至2K token。此举旨在降低开发者使用Gemini API的成本,并提升高频重复请求的效率 (来源: JeffDean)
清华大学研发AI光学显微镜Meta-rLLS-VSIM,体积分辨率提升15.4倍: 清华大学李栋课题组与戴琼海团队合作,提出元学习驱动的反射式晶格光片虚拟结构光照明显微镜(Meta-rLLS-VSIM)。该系统通过AI与光学交叉创新,将活细胞成像的横向分辨率提升至120nm,轴向分辨率提升至160nm,实现了近各向同性超分辨,体积分辨率较传统LLSM提升15.4倍。其核心技术包括利用DNN学习并拓展超分辨能力至多方向的“虚拟结构光照明”,以及通过镜面反射双视角信息融合与RL-DFN网络提升轴向分辨率。元学习策略的引入使得AI模型仅需3分钟即可完成自适应部署,极大降低了AI在生物实验中的应用门槛,为观测癌细胞分裂、胚胎发育等生命过程提供了强大工具 (来源: WeChat)

Qwen3系列大模型发布,持续引领开源社区: 阿里巴巴发布了Qwen3系列大型语言模型,参数规模从0.5B到235B不等,在多个基准测试中表现优异,其中多个小尺寸模型在同规模开源模型中达到SOTA水平。Qwen3系列支持多种语言,上下文长度最高可达128k tokens。由于其强大的性能和较低的部署成本(相较于DeepSeek-R1等),Qwen系列已在海外(尤其日本)被广泛采用作为AI开发基础,并衍生出大量垂类模型。Qwen3的发布进一步巩固了其在全球开源AI社区的领先地位,GitHub上一周内星标数破2万 (来源: dl_weekly, WeChat)

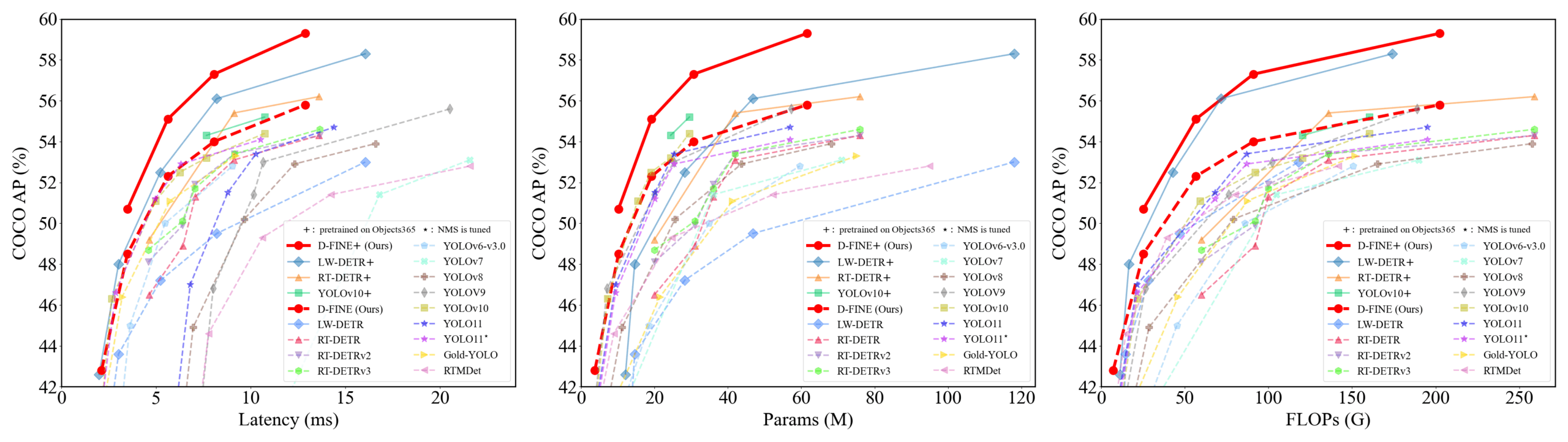
D-FINE:基于细粒度分布优化的实时目标检测器,性能优越: 研究者提出D-FINE,一种新型实时目标检测器,它将DETR中的边界框回归任务重新定义为细粒度分布优化(FDR),并引入全局最优定位自蒸馏(GO-LSD)策略。D-FINE在不增加额外推理和训练成本的情况下,实现了卓越的性能。例如,D-FINE-N在COCO val上达到42.8% AP,速度高达472 FPS (T4 GPU);D-FINE-X在Objects365+COCO预训练后,COCO val AP达到59.3%。该方法通过迭代优化概率分布来实现更精细的定位,并通过自蒸馏将最终层的定位知识传递给早期层 (来源: GitHub Trending)
Harmon模型协调视觉表征,统一多模态理解与生成: 南洋理工大学的研究者提出了Harmon模型,旨在通过共享MAR Encoder(Masked Autoencoder for Reconstruction)来统一多模态理解与生成任务。研究发现MAR Encoder在图像生成训练中能同时学习视觉语义,其Linear Probing结果远超VQGAN/VAE。Harmon框架利用MAR Encoder处理完整图像进行理解,并沿用MAR掩码建模范式进行图像生成,LLM在其中实现模态交互。实验表明,Harmon在多模态理解基准上接近Janus-Pro,在文生图美学基准MJHQ-30K和指令跟随基准GenEval上表现优异,甚至超越部分专家模型。该模型已开源 (来源: WeChat)

推行科技物流机器人实现商业闭环,通过「骑手影子系统」积累数据: 推行科技的物流机器人已在国内多个城市投入实际运营,通过与人类骑手协同工作,实现了单个机器人的盈亏平衡。其核心技术之一是「骑手影子系统」,通过采集真实骑手在复杂城市环境中的驾驶行为、环境感知及操作数据(如开关门、取放物品),为机器人提供海量、高质量的模仿学习与强化学习训练数据。目前该系统已积累数千万公里行驶数据和近百万条上肢轨迹数据。推行科技基于此训练了行为树VLA模型,使机器人能应对真实世界中的复杂情况,并计划拓展海外市场 (来源: WeChat)

快手推出KuaiMod框架,利用多模态大模型优化短视频生态: 快手提出了基于多模态大模型的短视频平台生态优化方案KuaiMod,旨在通过自动化内容质量判别改善用户体验。KuaiMod借鉴判例法思路,利用视觉语言模型(VLM)的链式推理分析劣质内容,并通过基于用户反馈的强化学习(RLUF)持续更新判别策略。该框架已在快手平台部署,有效降低用户举报率超20%。快手同时致力于打造能理解社区短视频的多模态大模型,从表征提取迈向深度语义理解,已在视频兴趣标签结构化、内容生成辅助等多个场景应用并取得成效 (来源: WeChat)

联想发布「天禧」个人超级智能体,迈向L3级智能: 联想在创新科技大会上推出「天禧」个人超级智能体,具备多模态感知与交互、基于个人知识库的认知与决策、以及复杂任务自主拆解与执行能力。天禧旨在通过AI随心窗、AI玲珑台、AI如影框等伴随式AUI界面,提供自然无缝的人机协作体验。它集成了包括DeepSeek-R1在内的多个行业顶级大模型,并采用端云混合部署架构,结合联想个人云1.0(搭载720亿参数大模型)提供强大算力与100G专属记忆空间。联想同时发布了企业级「乐享」和城市级超级智能体,展示其在AI领域的全面布局 (来源: WeChat)

新研究通过符号交互复杂度判断神经网络泛化性: 上海交通大学张拳石教授团队提出新理论,从神经网络内在的符号化交互表征复杂度角度分析其泛化性。研究发现,可泛化的交互(在训练和测试集均高频出现)在不同阶数(复杂度)上通常呈现衰减形分布(低阶交互为主),而不可泛化的交互(主要在训练集出现)则呈现纺锤形分布(中阶交互为主,正负效应易抵消)。该理论旨在通过分析模型等效的“与或交互逻辑”的分布模式,直接判断模型的泛化潜力,为理解和提升模型泛化性提供了新视角 (来源: WeChat)
🧰 工具
Llama.cpp全面兼容视觉语言模型 (VLM): Llama.cpp现已完全支持视觉语言模型(VLM),使开发者能够在设备端运行多模态应用。Hugging Face的Julien Chaumond等人分享了预量化模型,包括Google DeepMind的Gemma、Mistral AI的Pixtral、阿里巴巴的Qwen VL以及Hugging Face的SmolVLM,这些模型可直接使用。此更新得益于@ngxson和@ggml_org团队的贡献,为本地化、低延迟的多模态AI应用开启了新可能 (来源: ggerganov, ClementDelangue, cognitivecompai)
夸克AI超级框升级「深度搜索」,提升AI「搜商」: 夸克AI超级框近期升级,推出「深度搜索」功能,旨在提升AI的搜索商(搜商)。新功能强调AI在搜索前的主动思考和逻辑规划,能更好地理解用户复杂和个性化查询意图,分解问题并进行有条理的智能检索。在健康领域,夸克AI健康顾问“阿夸”会参考三甲医生观点和专业资料;学术领域则接入知网等权威信源。此外,夸克还具备强大的多模态处理能力,如图片分析、AI抠图、图像增强及风格转换。据悉,夸克未来还将发布具备Deep Research能力的深度搜索Pro版 (来源: WeChat)

LangChain推出多项集成与教程,强化RAG与智能体能力: LangChain近期发布了多个更新和教程:1. 社交媒体智能体UI教程:指导如何将LangChain社交媒体智能体转化为用户友好的Web应用,集成ExpressJS和AgentInbox UI,并支持Notion。2. 获奖RAG解决方案:展示了一个分析公司年报的RAG实现,支持PDF解析、多LLM和高级检索。3. 私有RAG聊天应用:教程演示如何使用LangChain和Reflex框架构建本地化、注重数据隐私的RAG聊天应用。4. Nimble Retriever集成:引入强大的Web数据检索器,为LangChain应用提供精准数据。5. Claude 3.7结构化输出指南:提供三种通过LangChain和AWS Bedrock实现Claude 3.7结构化输出的方法。6. 本地聊天RAG系统:开源项目展示了使用LangChain RAG流程和本地LLM(通过Ollama)构建的完全本地化的文档问答系统,确保数据隐私 (来源: LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI, LangChainAI)

Minion-agent:整合多框架能力的开源AI智能体框架: Minion-agent是一个新开源的AI智能体开发框架,旨在解决现有AI框架(如OpenAI、LangChain、Google AI、SmolaAgents)的碎片化问题。它提供统一接口,支持多框架能力调用、工具即服务(网页浏览、文件操作等)以及多智能体协作。项目展示了其在深度研究(自动收集文献生成报告)、价格比较(自动化市场调研)、创意生成(游戏代码生成)和技术动态追踪等场景的应用潜力,强调开源模式在灵活性和成本效益上的优势 (来源: WeChat)

RunwayML在多场景展现强大视频生成与编辑能力: 独立AI研究员Cristobal Valenzuela及其他用户展示了RunwayML在多种创意场景下的应用。包括利用其Frames、References及Gen-4功能,在保持风格和角色一致性的同时快速生成和可视化创意视觉;将伦勃朗的世界创作成RPG视频游戏;以及通过提供视觉参考实现新颖的单张图片室内设计视图合成。这些案例突显了RunwayML在可控视频生成、风格迁移和场景构建方面的进步 (来源: c_valenzuelab, c_valenzuelab, c_valenzuelab, c_valenzuelab)

Olympus:计算机视觉任务的通用任务路由器: Olympus是一个为计算机视觉任务设计的通用任务路由器。它旨在简化和统一不同视觉任务的处理流程,可能通过智能调度和分配计算资源或模型调用,来优化多任务计算机视觉系统的效率和性能。项目已在GitHub开源 (来源: dl_weekly)
Tracy Profiler:实时纳秒级混合帧与采样分析器: Tracy Profiler是一款针对游戏及其他应用的实时、纳秒级分辨率、支持远程遥测的混合式帧分析与采样分析工具。它支持CPU(C, C++, Lua, Python, Fortran及第三方绑定的Rust, Zig, C#等)、GPU(OpenGL, Vulkan, Direct3D, Metal, OpenCL)、内存分配、锁、上下文切换的性能分析,并能自动关联截图与捕获帧。该工具以其高精度和实时性,为开发者提供了强大的性能瓶颈定位与优化手段 (来源: GitHub Trending)

FieldStation42:复古广播电视模拟器: FieldStation42是一个Python项目,旨在模拟老式广播电视的观看体验。它能同时支持多个频道,自动插入广告和节目预告,并根据配置生成每周节目表。该模拟器能随机选择近期未播放的节目以保持新鲜感,支持设定节目播放日期范围(如季节性节目),并可配置电视台停播视频和无信号循环画面。项目还支持硬件连接(如树莓派Pico)来模拟换台操作,并提供预览/指南频道功能。其目标是当用户“打开电视”时,能播放符合该时段和频道的“真实”节目内容 (来源: GitHub Trending)

Tiny Corp推出基于USB3的AMD eGPU方案,支持Apple Silicon: Tiny Corp展示了通过USB3(具体为基于ASM2464PD主控的ADT-UT3G设备)连接AMD eGPU至Apple Silicon Mac的方案。该方案重写了驱动程序,旨在利用USB3的10Gbps带宽,并使用libusb,理论上也支持Linux或Windows。这为Apple Silicon用户扩展图形处理能力提供了新途径,尤其对本地运行大型AI模型等场景有潜在价值 (来源: Reddit r/LocalLLaMA)
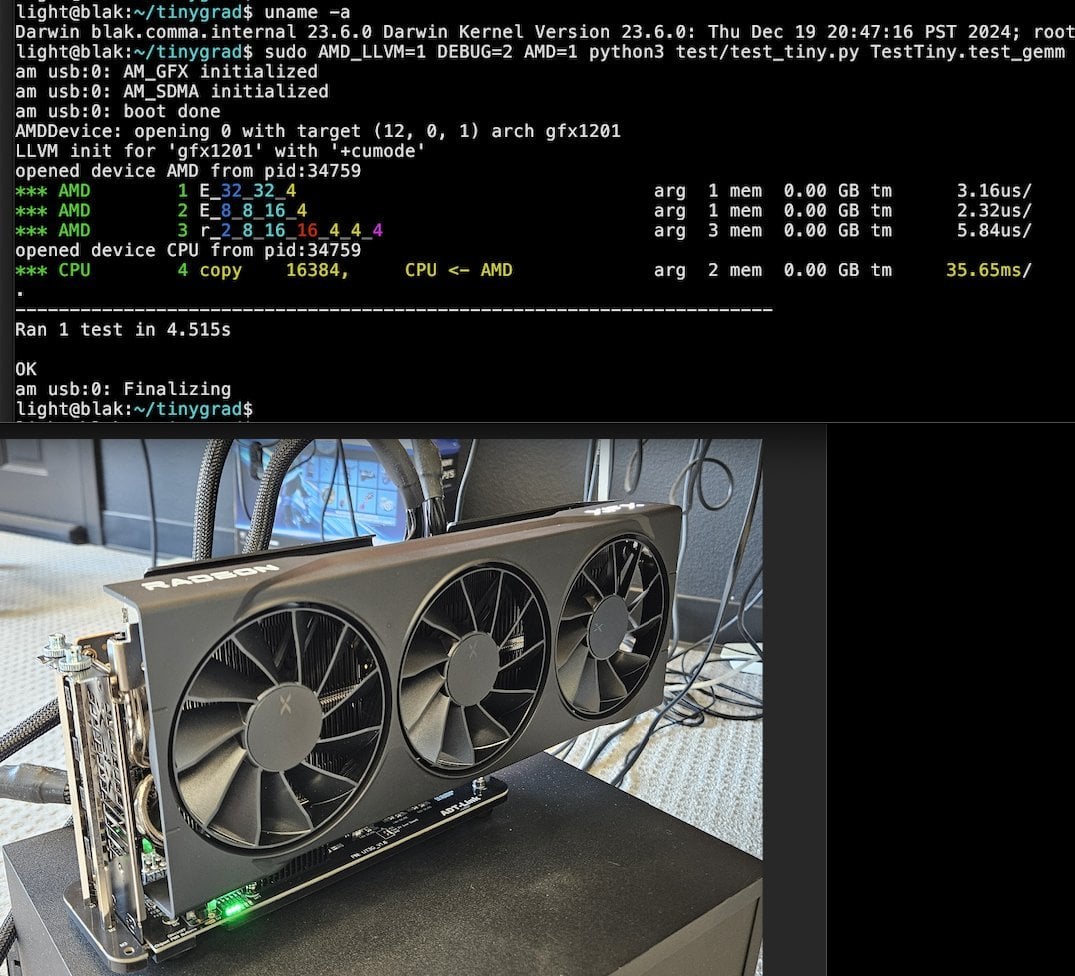
Llama.cpp-vulkan在AMD GPU上实现FlashAttention支持: Llama.cpp的Vulkan后端最近合并了FlashAttention的实现,这意味着在AMD GPU上使用llama.cpp-vulkan的用户现在可以利用FlashAttention技术。结合Q8 KV缓存量化,用户有望在保持或提升推理速度的同时,将上下文大小扩展一倍。这一更新对AMD GPU用户在本地运行大型语言模型是一个重要利好 (来源: Reddit r/LocalLLaMA)
Devseeker:轻量级AI编码助手,Aider和Claude Code的替代方案: Devseeker是一个新开源的轻量级AI编码代理项目,定位为Aider和Claude Code的替代品。它具备创建和编辑代码、管理代码文件和文件夹、短期代码记忆、代码审查、运行代码文件、计算token用量以及提供多种编码模式等功能。该项目旨在提供一个更易于本地部署和使用的AI辅助编程工具 (来源: Reddit r/ClaudeAI)
📚 学习
Panaversity推出Agentic AI学习项目,聚焦Dapr与OpenAI Agents SDK: Panaversity发起了「Learn Agentic AI」项目,旨在通过Dapr Agentic Cloud Ascent (DACA)设计模式和多种智能体原生云技术(包括OpenAI Agents SDK, Memory, MCP, A2A, Knowledge Graphs, Dapr, Rancher Desktop, Kubernetes)培养智能体与机器人AI工程师。该项目核心解决如何设计能处理千万级并发AI智能体的系统,并提供AI-201、AI-202、AI-301系列课程,覆盖从基础到大规模分布式AI智能体的学习路径。项目强调OpenAI Agents SDK因其简单易用、高控制性应成为主流开发框架 (来源: GitHub Trending)

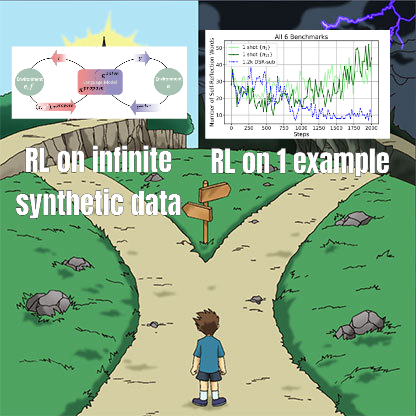
RL微调研究揭示数据管理与泛化能力的复杂关系: Minqi Jiang转发的论文讨论了强化学习(RL)微调中数据管理对模型泛化能力的影响。研究发现,无论是通过自博弈课程学习在“无限”编码任务上训练(Absolute Zero Reasoner),还是仅在单个MATH任务样本上重复训练(1-shot RLVR),7B规模的Qwen2.5系列模型在数学基准测试上均能实现约28%到40%的准确率提升。这揭示了一个悖论:极端的数据管理策略(无限数据 vs 单点数据)竟能产生相似的泛化改进。可能的解释包括RL主要引出预训练模型已有的能力、存在共享的“推理回路”以及预训练可能导致竞争性推理回路等。研究者认为,要突破“预训练天花板”,需持续收集和创造新任务与环境 (来源: menhguin)
Absolute Zero Reasoner:通过自博弈实现零数据推理能力提升: 一篇名为《Absolute Zero Reasoner》的论文提出,模型可以通过完全的自博弈(self-play)学习提出能最大化可学习性的任务,并通过解决这些任务来提升自身的推理能力,整个过程无需任何外部数据。该方法在数学和编码领域均优于其他“零样本”模型。这表明,AI系统或许可以通过内部生成和解决问题来持续进化其推理能力,为解决数据稀疏或标注成本高昂领域的AI应用提供了新思路 (来源: cognitivecompai, Reddit r/LocalLLaMA)

AI产品评估常见错误与最佳实践分享: Hamel Husain与Shreya Runwal分享了创建AI产品评估(evals)时常见的错误,并提供了避免这些错误的建议。关键点包括:基础模型基准不等于应用评估;通用评估无效,需针对具体应用;不要将标注和提示工程外包给非领域专家;应自建数据标注应用;LLM提示应具体化并基于错误分析;使用二元标签;重视数据审查;警惕对测试数据过拟合;进行在线测试。这些实践旨在帮助开发者构建更可靠、更能反映真实世界性能的AI产品评估体系 (来源: jeremyphoward, HamelHusain)
KV缓存优化新思路:通用可转移字典与信号处理重构: 威斯康星大学麦迪逊分校Dimitris Papailiopoulos团队提出一种减少KV缓存的新方法,通过使用一个通用的、可转移的字典结合传统的信号处理重构算法来实现。该方法在非推理模型上已达到SOTA(state-of-the-art)水平,并有望在推理模型上表现更佳。这项研究已获ICML接收,为解决大模型推理中KV缓存占用过高的问题提供了新的视角和技术路径 (来源: teortaxesTex, jeremyphoward, arohan, andersonbcdefg)

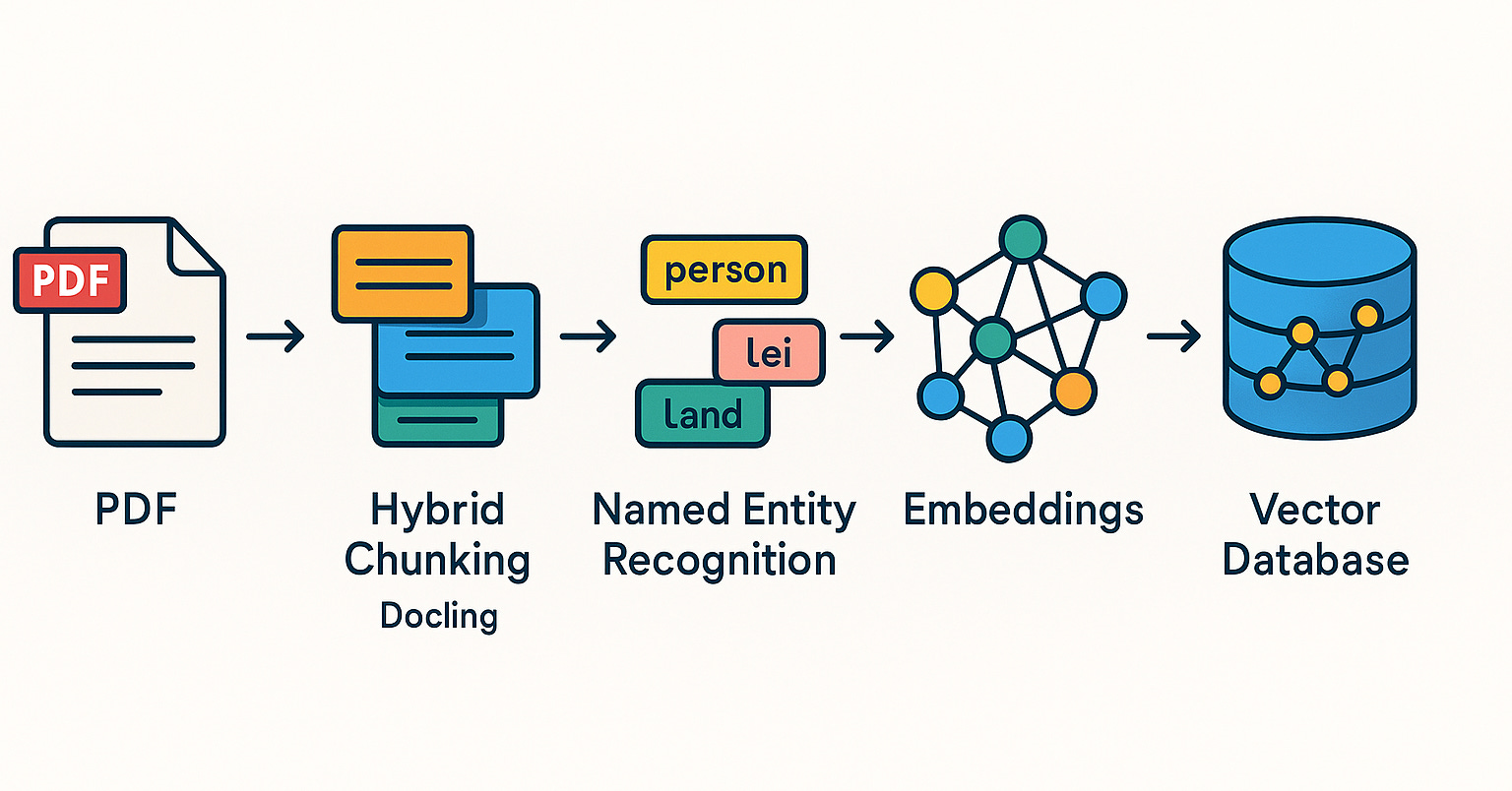
Qdrant在巴西社区推广RAG系统与混合搜索实践: Qdrant向量数据库在巴西社区日益受到关注。开发者Daniel Romero分享了两篇葡萄牙语文章,介绍了使用Qdrant、FastAPI和混合搜索构建RAG(检索增强生成)系统的实用方法。内容包括如何搭建混合搜索RAG系统,以及针对RAG的数据摄取策略,特别是混合分块(Hybrid Chunking)技术。这些分享有助于巴西开发者更好地利用Qdrant进行AI应用开发 (来源: qdrant_engine)
OpenAI学院推出K12教育提示工程专题系列: OpenAI学院发布了针对K-12教育工作者的提示工程(Prompt Engineering)学习系列“Mastering Your Prompts”。该系列旨在帮助教育者更好地理解和运用提示技巧,以便更有效地将AI工具(如ChatGPT)融入教学实践,提升教学效果和学生的学习体验。这表明AI辅助教育正逐渐向基础教育阶段渗透,并重视培养教育者的AI素养 (来源: dotey)
Yann LeCun分享其在新加坡国立大学的演讲内容: Yann LeCun分享了其于2025年4月27日在新加坡国立大学(NUS)所做的杰出讲座(Distinguished Lecture)的PDF文档。虽然未提供演讲的具体主题,但LeCun作为深度学习领域的先驱,其演讲通常涉及人工智能的前沿理论、未来趋势或对当前AI发展的深刻见解。该分享为关注AI研究的人士提供了直接获取其最新观点的途径 (来源: ylecun)
PyTorch与Mojo后端协作,简化新硬件与语言适配: PyTorch正致力于简化为新兴编程语言和硬件创建新后端的流程。在Mojo黑客松上,marksaroufim展示了PyTorch在这方面的努力,并提及了一个与Mojo团队合作开发的WIP(进行中)后端。这表明PyTorch生态系统正积极扩展其兼容性,以支持更多样化的AI开发环境和硬件加速选项,从而降低开发者在不同平台上部署和优化PyTorch模型的门槛 (来源: marksaroufim)
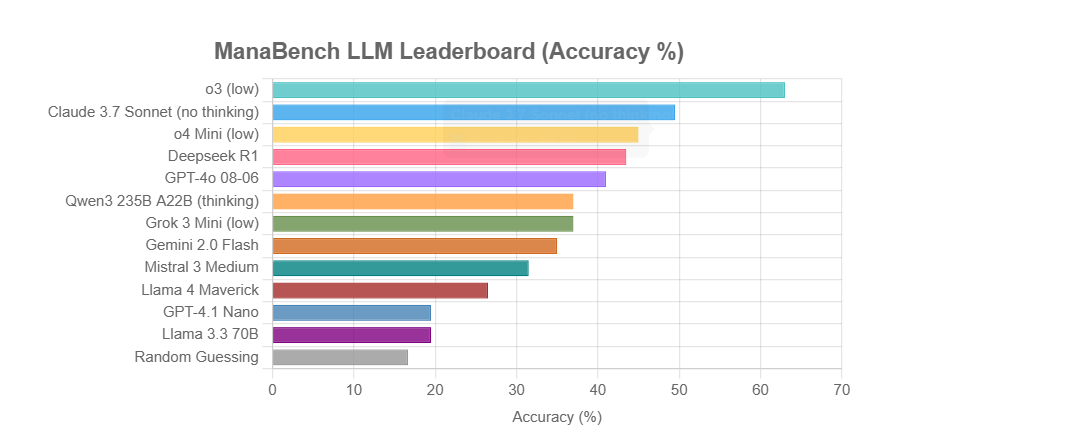
ManaBench:基于万智牌组牌的新型LLM推理能力基准: 一位开发者创建了名为ManaBench的新基准,通过让LLM在给定59张万智牌(MTG)的情况下,从六个选项中选择最合适的第60张牌,来测试其复杂系统推理能力。该基准强调战略推理、系统优化,且答案与人类专家设计一致,难以通过简单记忆破解。初步结果显示,Llama系列模型表现不及预期,而闭源模型如o3和Claude 3.7 Sonnet表现领先。该基准旨在更真实地评估LLM在需要复杂推理任务上的表现 (来源: Reddit r/LocalLLaMA)
讨论:AI是否会复兴或埋葬语义网的梦想?: 社交媒体上,用户Spencer提及除非是大型企业网站因ADA法案(美国残疾人法案)有显著风险敞口,否则语义网在大多数网站上更多是理论而非实践。Dorialexander回应称,感觉AI要么会复兴语义网的梦想,要么会将其永远埋葬。这反映了对AI在结构化数据理解和利用方面潜力的期待与担忧,AI可能通过自动理解和生成结构化信息来间接实现语义网的目标,但也可能因其自身的强大能力而使传统语义网技术变得不再那么重要 (来源: Dorialexander)
研究者探讨模型记忆与遗忘的伦理及架构: 一篇名为《Sticky Minds: The Ethics and Architectures of AI Memory and Forgetting》的论文草稿正在撰写中,探讨当模型开始“记忆过好”时,我们如何决定它们应该忘记什么,融合了神经架构与记忆伦理。这涉及到AI系统如何存储、检索和(选择性)遗忘信息,以及由此带来的伦理挑战和社会影响,对于构建负责任和可信的AI至关重要 (来源: Reddit r/artificial)
💼 商业
传英伟达将推出符合美国新出口管制要求的“再阉割版”H20芯片: 据路透社报道,英伟达计划在未来两个月内推出一款新的中国特供版H20 AI芯片,以符合美国最新的出口管制要求。这款芯片在原有H20(本身已是为中国市场定制的降级版)的基础上将进一步“阉割”,例如显存容量会显著减少。尽管性能再次降低,但据称下游用户或可通过修改模块配置进行一定程度的性能调整。目前,英伟达已收到价值180亿美元的H20订单 (来源: WeChat)

Databricks或以10亿美元收购开源数据库公司Neon,强化AI基础设施: 数据与AI公司Databricks据传正就收购开源PostgreSQL数据库引擎开发商Neon进行谈判,交易金额可能约10亿美元。Neon以其无服务器架构、存储与计算分离、以及对AI Agent和氛围编程的良好适配性为特点,允许按需付费使用,并能快速启动数据库实例,适合AI应用场景。此次收购若成功,将进一步增强Databricks在AI时代的基础设施层能力,为其提供一个现代化的、以AI为中心的数据库解决方案 (来源: WeChat)

OpenAI任命前Instacart CEO Fidji Simo为应用业务CEO,强化产品与商业化: OpenAI宣布任命前Instacart CEO及公司董事会成员Fidji Simo为新设立的“应用业务首席执行官”,与Sam Altman平级。Simo将全面负责OpenAI的产品,特别是ChatGPT等面向用户的应用,旨在推动产品优化、用户体验提升和商业化进程。此举标志着OpenAI战略重心从模型研发向产品平台化和市场拓展的重大转变,意图在AI应用层建立更强竞争力。Simo在Facebook和Instacart的丰富产品和商业化经验将助力OpenAI应对日益激烈的市场竞争 (来源: WeChat)

🌟 社区
JetBrains AI Assistant因体验不佳及评论管理引发用户不满: JetBrains的AI Assistant插件虽有超过2200万次下载,但在其市场上的评分仅为2.3分(满分5分),充斥大量1星差评。用户普遍反映其自动安装、运行缓慢、bug多、第三方模型支持不足、核心功能绑定云服务、文档缺失等问题。近期,JetBrains被指批量删除负面评论,虽官方解释为处理违规或已解决问题的内容,但仍引发用户对其控评和不重视用户反馈的质疑,部分用户选择重新发布差评并继续给予1星。此事加剧了用户对JetBrains AI产品策略的不满 (来源: WeChat)

用户热议AI营销智能体输出质量问题: 社交媒体用户omarsar0观察到,许多YouTube教程中展示的营销AI智能体,其生成的营销文案质量普遍较差,缺乏创意和风格。他认为,这反映出让LLM产出高质量、有吸引力内容的难度,并强调在构建AI智能体时,“品味”至关重要。他指出,当前许多AI智能体虽然工作流程复杂,但在产出真正具有商业价值的内容方面仍有不足,这为具备高品味、经验丰富且能设计良好评估体系的人才提供了机会 (来源: omarsar0)
AI辅助编码与“氛围编程”趋势引发讨论: Reddit上一篇关于Y Combinator讨论AI编码的视频引发热议。视频观点与发帖人(自称通过“氛围编程”创建了多个盈利项目)的经验高度吻合,核心观点包括:1. AI已能辅助构建复杂且可用的软件产品,甚至无需编写代码。2. 软件工程师对AI取代其工作的担忧与日俱增,但真正掌握AI辅助开发的人拥有“超能力”。3. 未来软件工程师的角色可能转变为善用AI工具的“智能体管理者”,AI将负责大部分代码编写。4. AI将催生大量针对细分市场的小众软件。讨论者认为,虽然AI编码潜力巨大,但仍需具备工程概念、数据库、架构等知识才能有效利用 (来源: Reddit r/ClaudeAI)

关于AI是否会“接管世界”及对就业影响的讨论持续: Reddit r/ArtificialInteligence板块的帖子反映了社区对AI未来影响的普遍焦虑和多样化观点。一些用户认为,对AI能力了解越深,对其超越人类并主导未来的担忧就越大,并指出前沿AI系统已展现出惊人能力。另一些用户则认为,对AGI的过分渲染导致了不切实际的期望,AI本质上是智能自动化工具,其影响将是渐进的,类似计算机和互联网。讨论也涉及到AI对就业的潜在冲击、财富分配以及监管的有效性,有观点认为历史表明技术进步往往加剧贫富分化,而AI可能通过消除大量工作岗位进一步集中财富。同时,也有人对AI在医疗、教育等领域的积极作用表示期待 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
用户体验:ChatGPT等AI工具如何影响思维与认知: 一些用户在社交平台和Reddit上分享了使用ChatGPT等AI工具带来的认知层面的积极影响。他们感觉AI不仅是信息获取或写作辅助工具,更像是一个能帮助他们理清思路、将潜意识中的想法清晰表达出来的“思维伙伴”或“镜子”。通过与AI对话,用户表示能更好地反思、挑战自身信念、发现思维模式,甚至感觉在“觉醒”,对生活和系统有更深刻的认识。这种体验表明,AI在某些情况下可能成为促进个人成长和自我探索的催化剂 (来源: Reddit r/ChatGPT)
💡 其他
第二届「兴智杯」全国人工智能创新应用大赛启动: 由中国信通院等单位联合主办的第二届「兴智杯」开幕,大赛以「兴智赋能,创新引领」为主题,设大模型创新、行业赋能、软硬件创新生态三大赛道及多个特色方向。赛事旨在推动AI技术创新、工程化落地和自主生态构建,覆盖工业、医疗、金融等近10个重点行业,并强调国产AI软硬件的应用。优胜项目将获资金、产业对接等支持 (来源: WeChat)

红杉资本AI Ascent分享:AI市场潜力巨大,应用层与智能体经济是未来: 红杉资本合伙人Pat Grady等在AI Ascent活动中分享了对AI市场的洞察。他们认为AI市场潜力远超云计算,但需警惕“氛围营收”(用户仅出于好奇尝试而非真实需求)。应用层被视为真正价值所在,创业公司应专注垂直领域和客户需求。AI在语音生成和编程领域已取得突破。未来展望“智能体经济”,AI智能体将能转移资源、进行交易,但面临持久身份、通信协议和安全等挑战。同时,AI将极大放大个体能力,催生“超级个体” (来源: WeChat)

讨论:AI时代大学机器学习课程内容与教学质量引关注: NYU教授Kyunghyun Cho对其研究生ML课程大纲的分享引发讨论,该课程强调SGD能解决的非LLM问题及经典论文阅读,获得哈佛CS教授等同行的认可,认为保留基础概念很重要。然而,有印度和美国学生抱怨其大学ML课程质量低下,过于抽象,充斥术语而缺乏深度解释,导致学生依赖自学和网络资源。这反映了AI/ML领域发展迅速与高校课程更新滞后之间的矛盾,以及打好数学和理论基础的重要性 (来源: WeChat)
