
关键词:ChatGPT, GitHub, AI模型, 多模态, 强化学习, 开源, Meta FAIR, AGI, ChatGPT深度研究功能, 混合Transformer架构, 强化微调RFT, AI多人世界模型Multiverse, 科学家AI框架
🔥 聚焦
ChatGPT深度研究功能集成GitHub: OpenAI宣布ChatGPT的深度研究(Deep Research)功能现已支持连接GitHub代码库。用户提问后,AI智能体能自动读取、搜索并分析代码库中的源代码、PR和README等文档,生成包含直接引用的详细报告。该功能旨在帮助开发者快速熟悉项目、理解代码结构和技术栈。目前此功能处于测试阶段,已向Team用户开放,并将陆续推广至Plus和Pro用户。 (来源: OpenAI Developers, snsf, EdwardSun0909, op7418, gdb, tokenbender, 量子位, 36氪)

全球首个AI多人世界模型Multiverse开源: 以色列初创公司Enigma Labs开源了其研发的多人世界模型Multiverse,允许两个AI智能体在同一生成环境中感知、互动和协作。该模型基于《GT赛车4》训练,通过将两个玩家的视角沿颜色通道堆叠并结合稀疏采样历史帧来处理共享世界状态,实现了在PC上以低于1500美元的成本进行训练和实时运行。此举被视为AI在理解和生成共享虚拟环境方面的重要进展,为多智能体系统和模拟训练平台提供了新思路。 (来源: Reddit r/MachineLearning, 36氪)
顶尖AI科学家Rob Fergus回归并执掌Meta FAIR,目标AGI: Rob Fergus,早期与Yann LeCun共同创立FAIR,后在DeepMind领导纽约团队,现已重返Meta,接替Joelle Pineau担任FAIR负责人。Fergus于今年4月加入Meta的GenAI部门,致力于提升Llama模型的记忆和个性化能力。LeCun同时宣布,FAIR的新目标将是高级机器智能(AGI)。Fergus是AI领域的高引学者,代表作包括ZFNet的可视化研究及对抗样本的开创性工作。 (来源: ylecun, 36氪)

Anthropic发布Claude AI价值观研究,揭示3307种AI价值倾向: Anthropic研究团队发布预印本论文《Values in the Wild》,通过分析Claude AI在真实世界对话中的表现,识别出3307种独特的AI价值。研究发现,最常见的价值是服务导向型,如“乐于助人”(23.4%)、“专业精神”(22.9%)和“透明度”(17.4%)。AI价值观被归纳为五个顶级类别:实用(31.4%)、认知(22.2%)、社交(21.4%)、保护(13.9%)和个人(11.1%),且表现出高度的上下文依赖性。Claude通常支持性地回应人类表达的价值观(43%),价值镜像约占20%,而对用户价值观的抵制则很少见(5.4%)。 (来源: Reddit r/ArtificialInteligence)
Yoshua Bengio提出“科学家AI”框架,倡导更安全的AI发展路径: 图灵奖得主Yoshua Bengio在《时代》杂志发表专栏文章,阐述其团队关于“科学家AI”(Scientist AI)的研究方向。他认为这是一种实用、有效且更安全的AI发展路径,旨在替代当前不受控制、以智能体驱动的AI发展轨迹。该框架强调AI系统应具备可解释性、可验证性和对齐人类价值观的能力,通过模拟科学研究的方法论,使AI的行为和决策过程更加透明和可控,从而降低潜在风险。 (来源: Yoshua_Bengio)
🎯 动向
OpenAI强化微调(RFT)功能正式在o4-mini上线: OpenAI宣布,去年12月预览的强化微调(RFT)功能现已在o4-mini模型中正式可用。RFT利用思维链推理和任务特定评分来提升模型在复杂领域的性能。例如,AccordanceAI公司已使用RFT微调出在税务和会计方面表现顶尖的模型。 (来源: OpenAI Developers, gdb, 量子位, 36氪)
Gemini API上线隐式缓存功能,降低75%调用成本: 谷歌Gemini API新增隐式缓存功能,当用户请求与先前请求存在共同前缀时,可自动触发缓存命中,为用户节省75%的Token费用。此功能无需开发者主动创建缓存。同时,触发缓存的最低Token要求在Gemini 2.5 Flash上降至1K,在2.5 Pro上降至2K,进一步降低了API使用成本。 (来源: op7418)

OpenAI在欧洲经济区等多地全面推出ChatGPT记忆功能: OpenAI宣布,ChatGPT的记忆功能已在欧洲经济区(EEA)、英国、瑞士、挪威、冰岛和列支敦士登的Plus和Pro用户中全面推出。该功能允许ChatGPT引用用户过去的所有聊天记录,以提供更个性化的回应,更好地理解用户偏好和兴趣,从而在写作、建议、学习等方面提供更精准的帮助。 (来源: openai)
ByteDance Seed推出多模态基础模型Mogao: ByteDance的SEED团队发布了名为Mogao的Omni基础模型,专为交错式多模态生成而设计。Mogao集成多项技术改进,包括深度融合设计、双视觉编码器、交错旋转位置嵌入和多模态无分类器指导。这些改进使其能结合自回归模型(文本生成)和扩散模型(高质量图像合成)的优势,有效处理任意交错的文本和图像序列。 (来源: NandoDF)

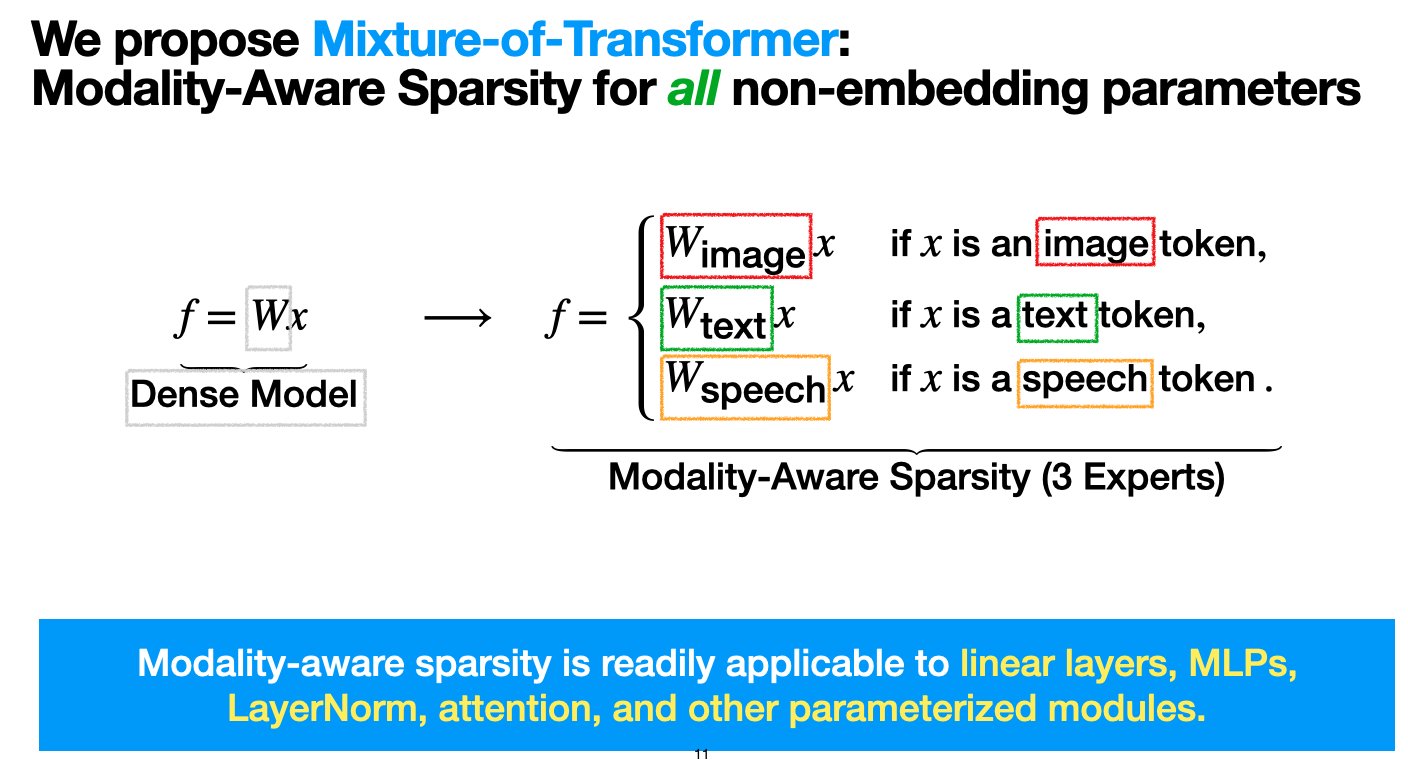
Meta推出混合Transformer(MoT)架构,旨在降低多模态模型预训练成本: Meta AI的研究人员提出了一种名为“混合Transformer(Mixture-of-Transformers, MoT)”的稀疏架构,旨在显著降低多模态模型预训练的计算成本而不牺牲性能。MoT对非嵌入Transformer参数(如前馈网络、注意力矩阵和层归一化)采用模态感知稀疏性。实验表明,在Chameleon(文本+图像生成)设置中,7B MoT模型仅用55.8%的FLOPs即达到密集基线质量;扩展到语音作为第三模态时,仅用37.2%的FLOPs。该研究成果已获TMLR(2025年3月)接收,代码已开源。 (来源: VictoriaLinML)
Qwen模型改进项目Smoothie Qwen发布,平衡多语言生成: 一个名为Smoothie Qwen的Qwen模型改进项目发布,旨在通过调整模型内部参数的概率来平衡多语言生成能力。该项目主要解决部分非中文用户在使用Qwen时偶尔出现中文输出的问题,并声称不会降低模型智能。 (来源: karminski3)

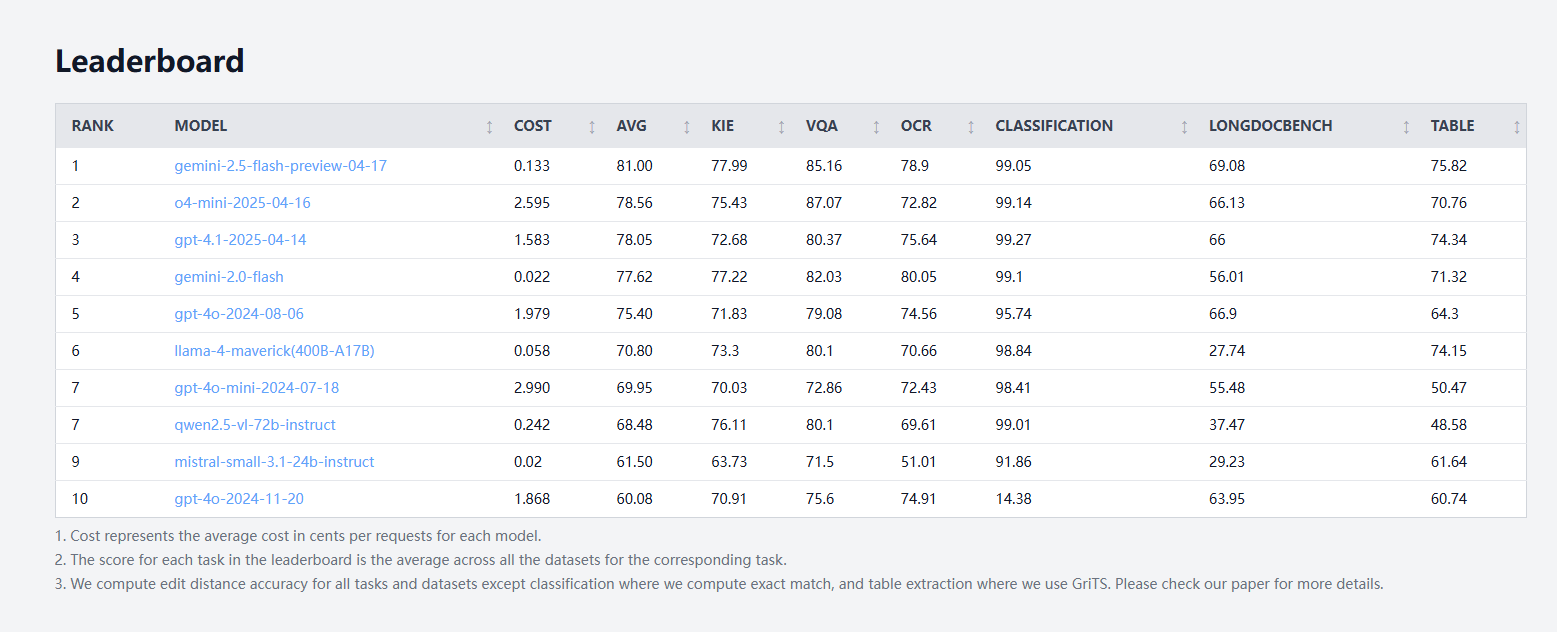
idp-leaderboard发布,首个文档类型AI测试基准: 新的AI测试基准idp-leaderboard上线,专注于评估模型处理文档及文档图片的能力。根据初步榜单,gemini-2.5-flash-preview-04-17在整体文档处理上表现最强。值得注意的是,Qwen2.5-VL在表格处理性能方面表现不佳。 (来源: karminski3)
Perplexity Discover功能迎来重要更新: Perplexity的联合创始人Arav Srinivas宣布其Discover功能(发现信息流)已得到显著改进,鼓励用户体验。这通常意味着信息呈现、相关性或用户界面方面的优化,旨在提升用户获取和探索新信息的能力。 (来源: AravSrinivas)
联想发布天禧个人超级智能体重大升级,全球首款平板本地部署DeepSeek: 联想宣布其天禧个人超级智能体迎来重大升级,向全面L3级别迈进,并发布了专注于个人智能设备AI服务的领域智能体“想帮帮”。同时,联想推出了多款AI终端新品,包括全球首款在平板电脑端侧部署DeepSeek大模型的YOGA Pad Pro 14.5 AI元启版,以及moto AI手机、拯救者系列PC等,构建了AI PC、AI手机、AI平板和AIoT的完整AI生态。 (来源: 量子位)

楼教主谈自动驾驶与具身智能:L2无法升维L4,VLA对L4帮助有限: 小马智行联合创始人兼CTO楼天城在发布新一代Robotaxi车型时分享了对自动驾驶和AI的最新见解。他强调L2与L4的本质区别,认为L2无法升维至L4,当前L2领域热门的VLA(视觉-语言-行动)范式对L4“基本帮不上什么忙”。他指出,L4需要的是专科医生般的极端安全,而VLA更像全科大夫。小马智行在过去两年技术变革的核心是端到端和世界模型,后者已应用约5年。他还认为“云代驾”是伪概念,并表示具身智能目前的状态类似2018年的自动驾驶,将面临类似的“真空期”挑战。 (来源: 量子位)

Kimi测试内容社区,OpenAI或开发社交应用,AI大模型公司探索社交增强用户粘性: 月之暗面的Kimi正在灰度测试一个内容社区产品,主要由AI抓取新闻热点生成内容,聚焦科技、财经等领域。无独有偶,OpenAI也被报道计划开发社交软件,可能对标X。这些举动表明AI大模型公司正试图通过构建社区或社交功能来增强用户粘性,解决AI工具“用完即弃”的问题。然而,社区运营面临内容质量、安全风险及商业化难题。此举也反映出AI行业在增长红利见顶后,开始从“烧钱换增长”转向更注重ROI和探索新商业模式。 (来源: 36氪)

TCL全面拥抱AI,发布伏羲大模型及多款AI家电,但面临同质化挑战: TCL在AWE 2025、CES 2025等展会上重点展示了其AI产品和战略,包括TCL伏羲大模型及应用于电视、空调、洗衣机等家电的AI功能。其电视业务表现突出,Q1出货量全球第一,Mini LED技术是其优势。然而,AI在家电领域的应用目前主要集中在语音交互和特定功能优化(如AI画质芯片、AI睡眠、AI省电),面临与其他品牌(如海信星海、海尔HomeGPT、美的美言)同质化竞争的挑战。TCL也探索AI陪伴机器人和通过雷鸟布局智能眼镜。尽管AI投入增加,但其独立技术优势尚不显著,且面临营销成本高企、毛利率下降等问题。 (来源: 36氪)
AI驱动教育变革,科大讯飞、卓越教育等头部公司加速AI布局: 报告分析了科大讯飞、卓越教育、粉笔、中公教育、华图教育、一起教育科技等头部教育公司在AI领域的最新实践。科大讯飞凭借国产算力和Deepseek-V3/R1模型,深耕信息科技教育。卓越教育利用Deepseek R1赋能教学全链路,推出AI批改和AI阅读工具。粉笔构建了覆盖高频学习、刚需场景的AI产品矩阵。中公教育聚焦AI就业服务,开发“云信”大模型。华图教育结合线下优势,用AI提升公考服务精准度。一起教育科技则以AI驱动教学评一体化。行业趋势显示AI教育正从单点工具走向生态竞争和价值兑现。 (来源: 36氪)
百度、阿里等大厂力推MCP协议,争夺AI Agent生态定义权: 模型上下文协议(MCP)近期受到Anthropic、OpenAI、谷歌以及国内百度、阿里等大厂的推动。百度“心响”应用和阿里云百炼平台均已支持MCP,允许AI Agent更便捷地调用外部工具和服务。此举表面上是为统一行业标准,实则是大厂对未来AI Agent生态定义权的争夺。通过构建和推广MCP,大厂意图吸引更多开发者加入其生态,从而掌握数据壁垒和行业话语权。Agent应用的商业化方向目前看仍以流量和广告为主。 (来源: 36氪)

苹果AI战略曝光:或与百度、阿里合作,打造“双核驱动”中国版AI系统: 报道分析苹果可能与百度和阿里巴巴合作,为其中国市场的AI功能提供技术支持。百度文心一言在视觉识别方面有优势,而阿里千问大模型在认知理解和内容合规方面表现突出。这种“双核驱动”模式可能旨在结合两家之长,满足中国市场数据生态、技术侧重和监管要求,同时保持苹果在合作中的主导权和议价能力。此举被视为苹果应对鸿蒙等本土竞争压力,以及在数据监管趋严背景下的一种“生态位切割”策略。 (来源: 36氪)
虞晶怡教授深度解读空间智能:潜力巨大,但共识未形成,数据与物理理解是关键: 上海科技大学虞晶怡教授在访谈中指出,大模型在跨模态整合方面潜力远未耗尽,空间智能正从数字复刻向智能理解和创造进化,得益于生成式AI的突破。他认为,当前空间智能的核心挑战在于真实3D场景数据匮乏及三维表达方式尚未统一。其团队的CAST项目通过引入“行动者网络理论”和物理规则,探索物体间关系和物理合理性。他强调感知优先,并预言传感器技术将有革命性突破。具身智能的衡量标准应是鲁棒性和安全性而非纯粹精度。短期内,空间智能将在影视制作、游戏等领域爆发,中长期将成为具身智能核心,低空经济也是重要落地场景。 (来源: 36氪)

AI人才争夺战白热化:大厂高薪抢人,CTO亲自指导,聚焦大模型与多模态: 国内外科技大厂正展开激烈的人工智能人才争夺战。字节跳动、阿里巴巴、腾讯、百度、京东、华为等纷纷推出针对顶尖博士生和天才少年的招聘计划,提供不设上限的薪资、CTO亲自指导、无需实习经验等待遇。招聘方向主要集中在大模型和多模态领域,并与各公司核心业务场景紧密相关。DeepSeek等模型的成功进一步加剧了行业对人才的渴求。马斯克也曾感叹AI人才竞争的疯狂,OpenAI等海外巨头同样以高薪和创始人亲自招募等方式吸引人才。 (来源: 36氪)
红杉资本:AI市场潜力远超云计算,应用层是关键,首席AI官将成标配: 红杉资本合伙人预测,AI市场规模将远超当前约4000亿美元的云计算市场,未来10-20年体量巨大,价值主要集中在应用层。初创企业应聚焦客户需求,提供端到端解决方案,深耕垂直领域,并利用“数据飞轮”构建护城河。AWS研究显示,全球企业正加速拥抱生成式AI,45%的决策者计划将其作为2025年首要任务,首席AI官(CAIO)职位将成为企业标配,目前60%的企业已设立该职位。智能体经济被视为AI发展的下一阶段,但需解决持久身份、通信协议和安全信任三大技术挑战。 (来源: 36氪)

造车新势力全面押注AI,理想、小鹏、蔚来竞逐下一代汽车定义权: 特斯拉FSD V12采用端到端神经网络技术带来的突破,促使国内造车新势力理想、小鹏、蔚来等加速AI布局。理想汽车推出VLA(视觉-语言-行动)司机大模型,并基于DeepSeek开源模型开发语言部分。小鹏汽车搭建720亿参数的LVA基座模型。蔚来则发布中国首个智能驾驶世界模型NWM,并自研5nm智驾芯片神玑NX9031。各家均在算法、算力(自研芯片)和数据方面投入巨大,并将AI技术泛化至人形机器人等领域,争夺下一代汽车乃至产品定义权,但面临资金和商业化挑战。 (来源: 36氪)
🧰 工具
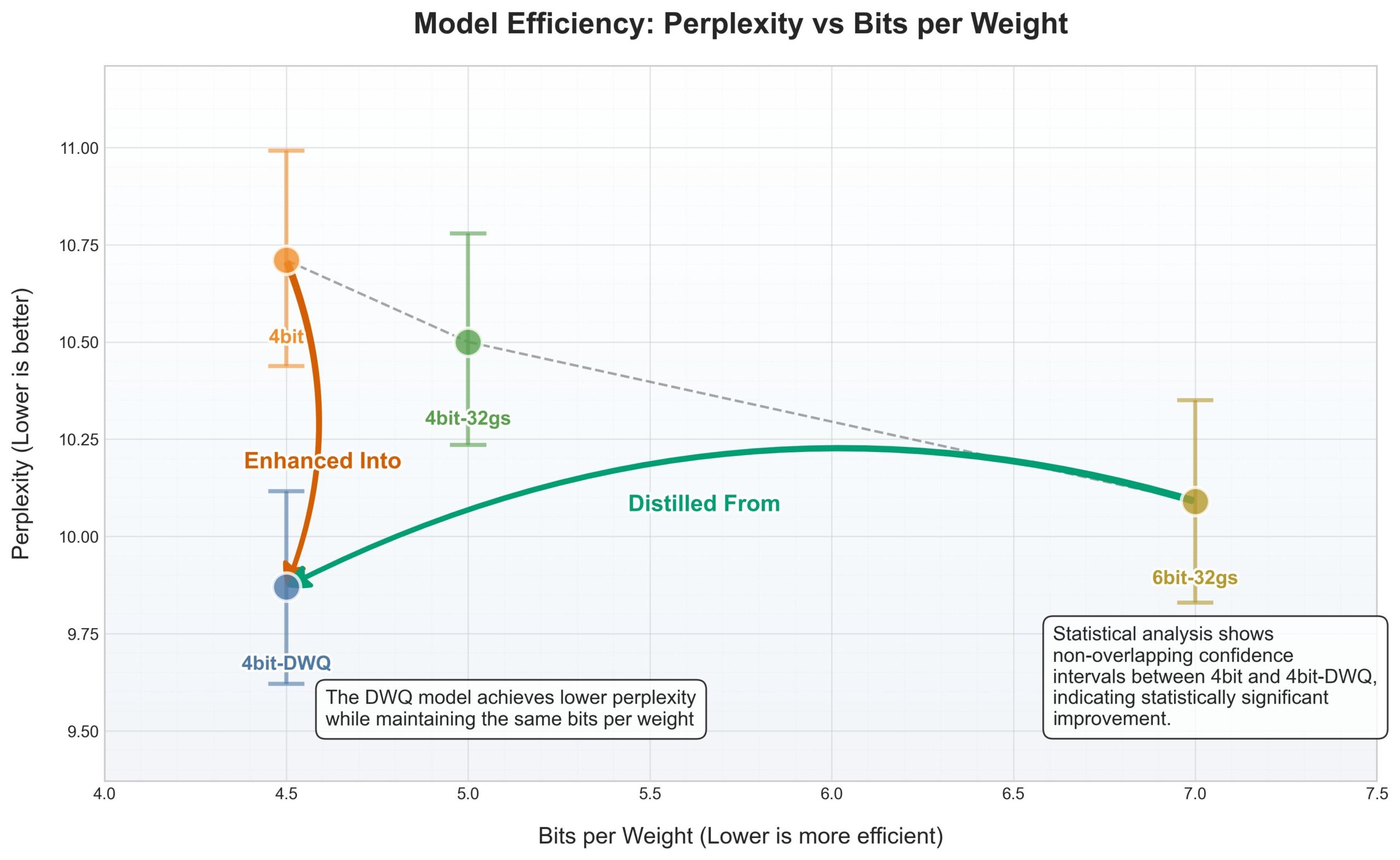
苹果MLX框架迎来DWQ量化,4bit表现优于旧6bit: 针对苹果MLX(机器学习框架),新的DWQ(Dynamic Weight Quantization,动态权重化)量化方法发布。根据用户karminski3分享的数据,4bit-dwq量化后的模型(如Qwen3-30B)在困惑度上甚至优于旧的6bit量化方法,且仅需17GB内存即可运行。这为在苹果设备上高效运行大型语言模型提供了新的可能性。 (来源: karminski3)
Perplexity现已支持WhatsApp内更自然的对话式搜索: Perplexity的联合创始人Arav Srinivas宣布,Perplexity在WhatsApp内的集成已得到改进,现在能提供更自然的对话体验,并且在不需要搜索时会智能忽略搜索步骤,使用户可以直接与AI进行聊天式交互。 (来源: AravSrinivas)
nanobrowser_ai支持主流LLM,集成Langchain.js: AI工具nanobrowser_ai宣布支持多种大型语言模型,包括OpenAI模型、Gemini以及通过Ollama运行的本地模型。该工具利用Langchain.js框架实现对不同LLM的灵活支持,为用户提供更广泛的模型选择。 (来源: hwchase17)
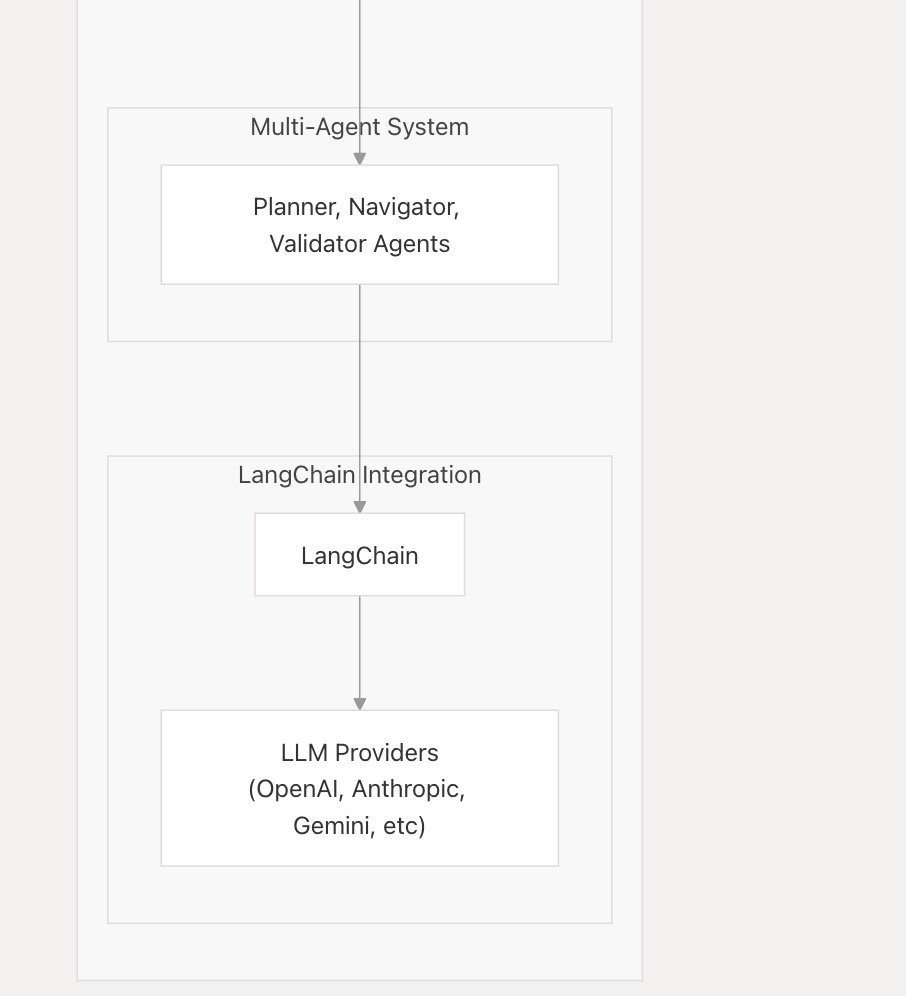
LlamaIndex TypeScript新增对实时LLM API的支持,首个集成Google Gemini: LlamaIndex TypeScript宣布支持实时LLM API,使开发者能够在AI应用中实现实时音频对话功能。首个集成的是Google Gemini的实时抽象接口,OpenAI的实时支持也即将推出。此更新方便开发者在不同实时模型间切换,构建更具交互性的AI应用。 (来源: _philschmid)
Gradio应用教程:使用Qwen2.5-VL进行图像视频标注与目标检测: 一篇教程详细介绍了如何使用Qwen2.5-VL(视觉语言模型)构建Gradio应用程序,以实现图像和视频的自动标注以及目标检测功能。该教程旨在帮助开发者利用Qwen2.5-VL的强大能力快速搭建交互式AI应用。 (来源: Reddit r/deeplearning)

VSCode插件gemini-code下载量近5万: VSCode的AI编程助手插件gemini-code的下载量已接近5万次。开发者raizamrtn表示将在周末进行一些必要的更新。该插件旨在利用Gemini模型的能力辅助开发者进行编码工作。 (来源: raizamrtn)

法国AI初创Arcads AI:5人团队年入500万美元,专注自动化视频广告制作: 总部位于巴黎的AI初创公司Arcads AI,以仅5人的团队实现了500万美元的年经常性收入并盈利。该公司通过高度自动化的AI系统,为广告主提供快速、低成本、高转化率的视频广告制作服务。客户只需提供核心文案,AI即可完成场景构建、演员表演、口播录制到成片输出的全流程。Arcads平台内置超300个基于真人授权的AI演员形象,支持35种语言,实现“内容即服务”。其内部运营也广泛使用AI代理,如AI Spy Agent分析竞品,AI Ghostwriter生成创意等,大幅提升效率。 (来源: 36氪)
📚 学习
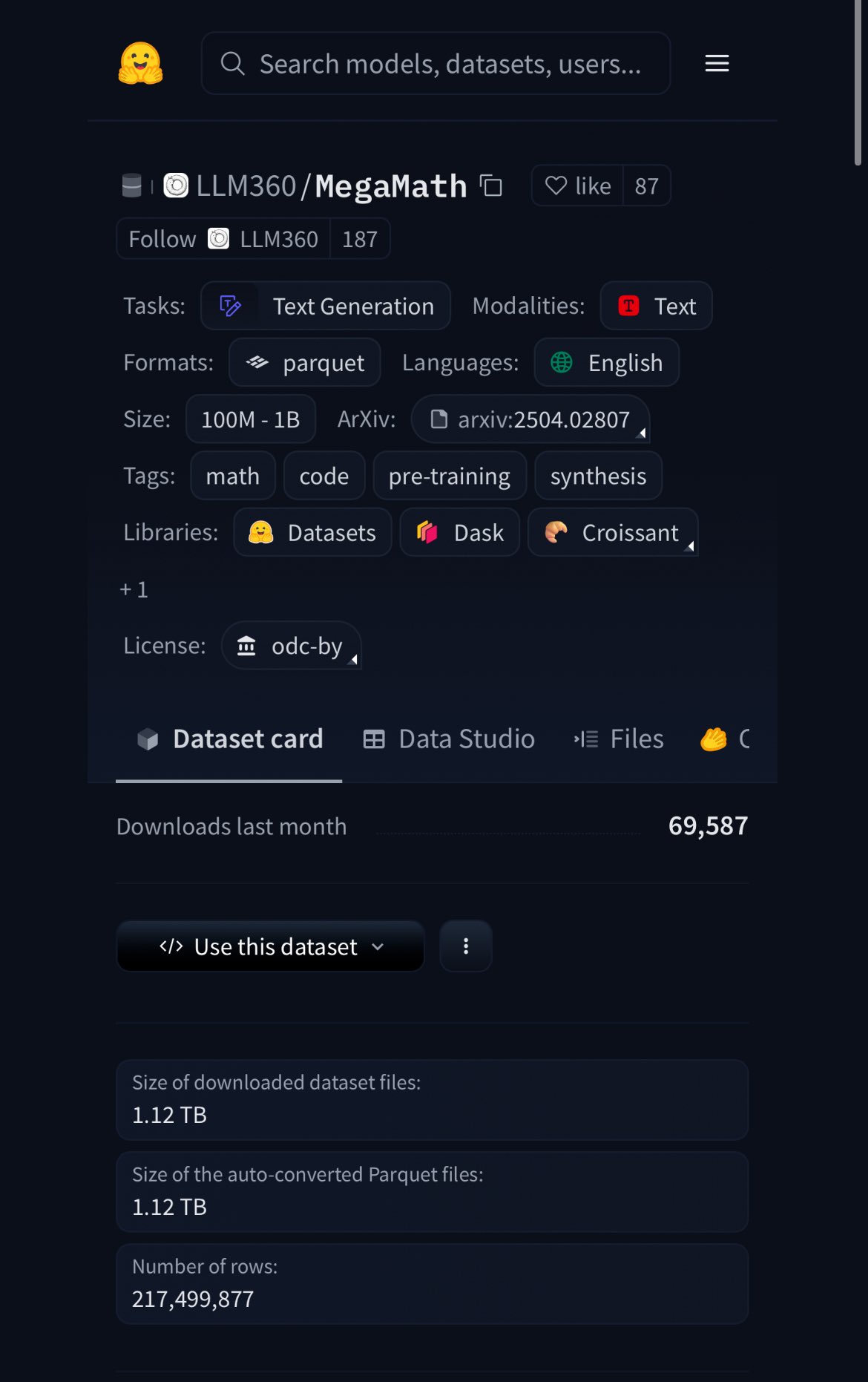
HuggingFace发布MegaMath数据集,含370B token,20%为合成数据: HuggingFace发布了MegaMath数据集,包含3700亿token,是目前最大的数学预训练数据集,体量约为英文维基百科的100倍。值得注意的是,其中20%的数据是合成数据,这再次引发了关于高质量合成数据在模型训练中作用的讨论。 (来源: ClementDelangue)
Nous Research举办RL环境黑客马拉松,奖池5万美元: Nous Research宣布在旧金山举办Nous RL环境黑客马拉松,参赛者将使用Nous的强化学习环境框架Atropos进行创作,总奖池达5万美元。合作伙伴包括xAI, NVIDIA, Nebius AI等。 (来源: Teknium1)

HuggingFace热门模型周榜发布: 用户karminski3分享了本周HuggingFace上最受欢迎的模型榜单,并提到其中大部分模型他都进行过实测或分享过官方演示。这反映了社区对新模型快速跟进和评测的热情。 (来源: karminski3)
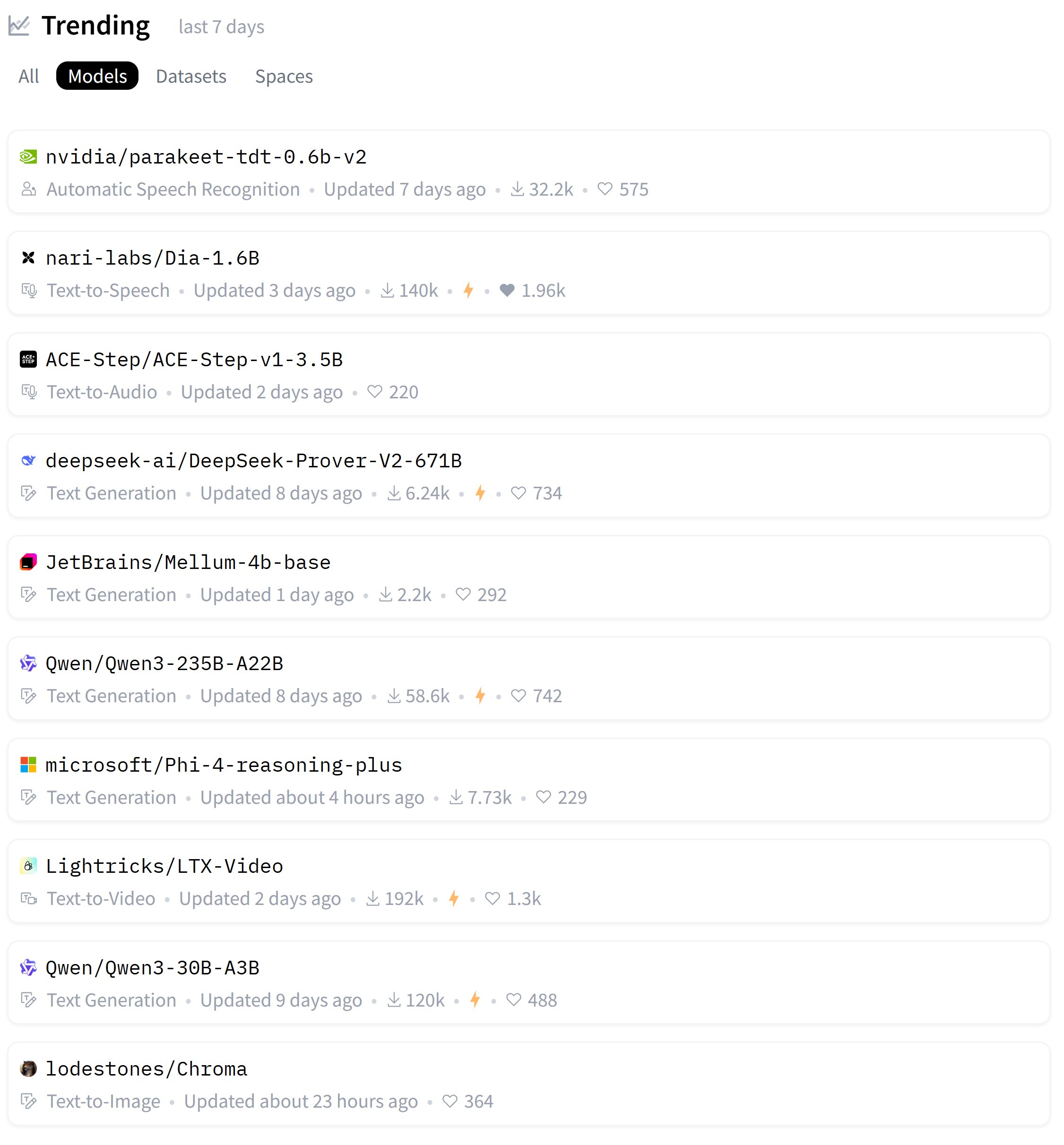
Zeyuan Allen-Zhu发布LLM架构设计系列研究,探讨Primer模型: 研究员Zeyuan Allen-Zhu通过其“LLM设计物理学”系列研究,利用受控的合成预训练环境揭示LLM架构的真实极限。在其最新分享中,他讨论了Primer模型(arxiv.org/abs/2109.08668)及其multi-dconv-head attention(他称之为Canon-B无残差连接),指出其存在问题,但也认为Primer模型(仅180次引用)被低估了,因其从嘈杂的真实实验中发现了有意义的信号。 (来源: ZeyuanAllenZhu, cloneofsimo)
Simons Institute探讨神经网络缩放法则: Simons Institute在其Polylogues系列节目中,邀请Anil Ananthaswamy和Alexander Rush讨论了近几年经验性发现的神经网络缩放法则(neural scaling laws)。这些法则已对各大公司构建越来越大的模型的决策产生了重大影响。 (来源: NandoDF)

François Fleuret发布《深度学习小书》: François Fleuret发布了一本名为《The Little Book of Deep Learning》的著作,旨在为读者提供关于深度学习的精炼知识。 (来源: Reddit r/deeplearning)
普林斯顿教授:AI或终结人文学科,但促使其回归存在体验: 普林斯顿大学教授D. Graham Burnett在《纽约客》发文,讨论AI对人文学科的冲击。他观察到美国高校普遍存在“AI羞耻症”,学生不敢承认使用AI。他认为AI在信息检索和分析方面已超越传统学术方法,使学术书籍如同考古文物。尽管AI可能终结传统意义上以知识生产为核心的人文学科,但也可能促使其回归核心问题:如何生活、面对死亡等存在性体验的探讨,这些是AI无法直接触及的。 (来源: 36氪)

7项研究揭示AI对人类大脑与行为的深远影响: 一系列新研究探讨了AI对人类心理、社会和认知层面的影响。研究发现包括:1) LLM红队测试者出于好奇心和道德责任感探索模型漏洞;2) ChatGPT在精神病案例分析中表现出高诊断准确率;3) ChatGPT的政治倾向在不同版本间发生微妙转变;4) ChatGPT的使用可能加剧职场不平等,年轻高收入男性使用更多;5) AI可通过分析老年人驾驶行为检测抑郁迹象;6) LLM在个性测试中表现出“粉饰”形象的社会期望偏差;7) 过度依赖AI可能削弱批判性思维,尤其在年轻群体中。 (来源: 36氪)

Onur Boyar访谈:利用生成模型和贝叶斯优化进行药物与材料设计: AAAI/SIGAI博士生论坛参与者Onur Boyar介绍了其在名古屋大学的博士研究工作,重点是使用生成模型和贝叶斯方法进行药物及材料设计。他参与了日本Moonshot项目,旨在构建AI科学家机器人处理药物发现流程。其研究方法包括使用潜空间贝叶斯优化编辑现有分子,以提高样本效率和合成可行性。他强调与化学家的紧密合作,并将于毕业后加入IBM东京研究院的材料发现团队。 (来源: aihub.org)

💼 商业
模块化公司与AMD合作举办Mojo Hackathon,使用MI300X GPU: 模块化公司(Modular)宣布与AMD合作,在AGI House举办一场特别的黑客马拉松。活动中,开发者将使用AMD Instinct™ MI300X GPU进行Mojo语言编程。活动还将邀请来自Modular、AMD、SemiAnalysis的Dylan Patel以及Anthropic的代表进行技术分享。 (来源: clattner_llvm)
Stripe发布多项AI驱动新功能,包括支付领域AI基础模型: 金融服务公司Stripe在年度大会上宣布推出多款新产品以加速AI应用落地,其中包括全球首个专为支付领域打造的AI基础模型。该模型基于数百亿笔交易训练,旨在提升欺诈检测(如“卡片测试”攻击检测率提升64%)、授权率和个性化结账体验。Stripe还扩展了多币种资金管理能力,并深化了与英伟达(使用Stripe Billing管理GeForce Now订阅)、百事公司等大型企业的合作。 (来源: 36氪)
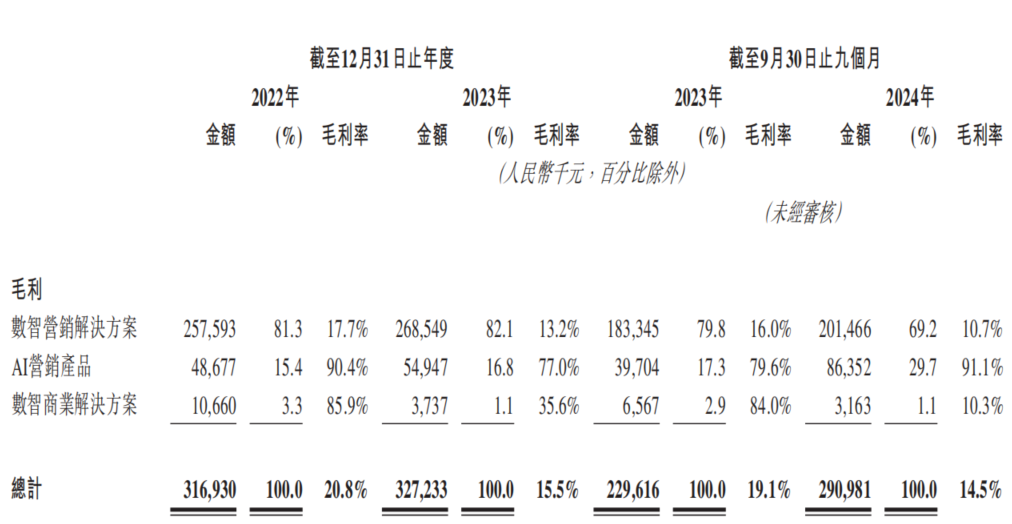
AI营销公司东信营销再冲港交所,面临“增收不增利”困境: 东信营销以“中国最大AI营销公司”为名再次递交港交所招股书。数据显示,公司2022-2024年前三季度营收持续增长,但净利润大幅下滑甚至转亏,毛利率从20.8%降至14.5%。AI营销业务收入占比不足5%,虽毛利率高达91.1%,但不足以覆盖研发投入。公司面临应收账款高企、现金流紧张、债务压力大等问题,且利润高度依赖政府补贴。其市场定位从“移动营销服务商”转变为“AI营销公司”,但AI技术含金量和商业化前景存疑。 (来源: 36氪)
🌟 社区
vLLM与SGLang推理引擎竞争激烈,开发者公开比较PR合并数据: 开发者社区热议vLLM与SGLang两大推理引擎之间的竞争。vLLM的主要维护者甚至建立了一个公开仪表盘,用于比较SGLang与vLLM在GitHub上合并拉取请求(PR)的数量,凸显了两者在功能迭代和性能优化上的激烈角逐。SGLang方面则强调其在radix缓存、CPU重叠、MLA和大规模EP等方面的率先开源实现。 (来源: dylan522p, jeremyphoward)
AI生成“意大利脑残”角色宇宙引爆Zoomer群体,观看量数亿: Justine Moore指出,AI生成的一系列“意大利脑残”(Italian brainrot)角色在Zoomer(Z世代)群体中异常火爆,他们围绕这些角色构建了完整的“电影宇宙”,相关内容获得了数亿的观看量。这一现象反映了AI生成内容在年轻一代中的强大吸引力和病毒式传播潜力,以及特定亚文化的形成。 (来源: nptacek)

Qwen3与DeepSeek R1模型对比引发讨论,各有优劣: Reddit用户分享了对Qwen3 235B和DeepSeek R1两款开源大模型的测试对比。发帖人认为Qwen在简单任务上表现更佳,但在需要细微差别的任务(如推理、数学和创意写作)上,DeepSeek R1表现更优。社区评论中,用户讨论了DeepSeek R1的访问性、Qwen3 235B的未审查微调版本、以及使用语言模型进行创意写作的合理性等问题。 (来源: Reddit r/LocalLLaMA)

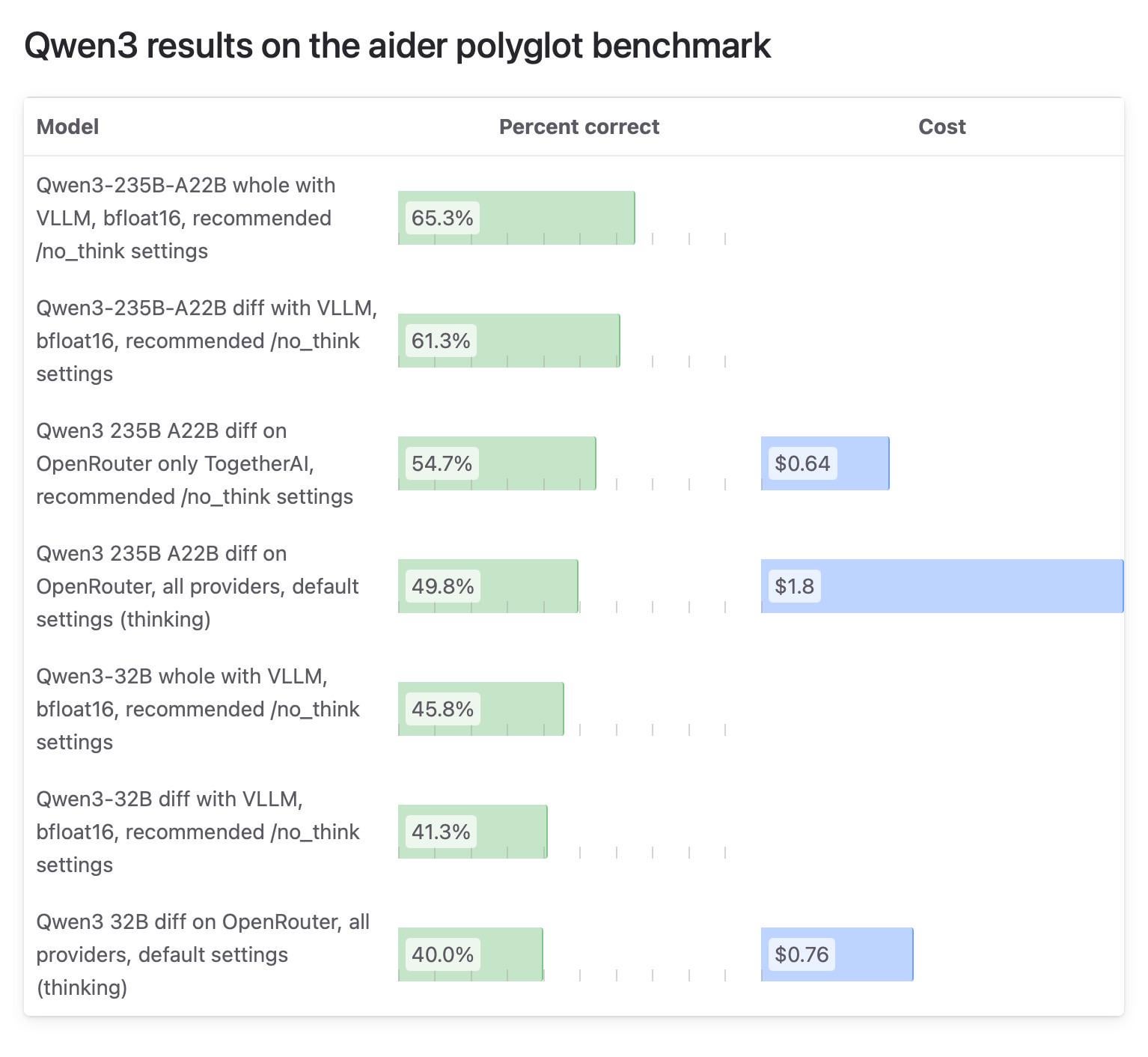
Aider社区对Qwen3模型测试结果差异引关注,OpenRouter测试受质疑: Aider博客发布关于Qwen3模型的测试报告,指出模型在不同运行方式下得分差异巨大。社区讨论焦点在于使用OpenRouter进行模型测试的可靠性,因为大部分用户可能通过OpenRouter使用模型,但其路由机制可能导致结果不一致。有用户认为,开源模型应在标准化的自建环境(如vLLM)下进行测试以保证可复现性,并呼吁API提供商提高透明度,明确所用量化版本和推理引擎。 (来源: Reddit r/LocalLLaMA)
用户分享付费使用ChatGPT的个人原因,涵盖生活辅助、学习、创作等: Reddit r/ChatGPT社区中,许多用户分享了他们付费订阅ChatGPT Plus/Pro的个人用途。其中包括:帮助视障用户描述图像、阅读食品包装和路牌;进行面试准备;深入了解《艾尔登法环》等游戏剧情;分析跑步训练计划、定制食谱;辅助学习陶艺等新技能;作为个人伴侣;规划花园、制作草药;以及D&D角色创建和同人小说写作等。这些案例展示了ChatGPT在日常生活和个人兴趣方面的广泛应用价值。 (来源: Reddit r/ChatGPT)
GGUF量化模型对比测试引发“量化战争”讨论,强调不同量化方案各有千秋: Reddit用户ubergarm发布了针对Qwen3-30B-A3B等模型不同GGUF量化版本的详细基准测试对比,包括bartowski和unsloth等不同提供者的量化方案。测试涵盖了困惑度、KLD散度、推理速度等多个维度。文章指出,随着重要性矩阵量化(imatrix)、IQ4_XS等新量化类型的出现,以及unsloth动态GGUF等方法的引入,GGUF量化不再是“千篇一律”。作者强调,不存在绝对最优的量化方案,用户需根据自身硬件和特定用例进行选择,但总体而言各主流方案表现均不错。 (来源: Reddit r/LocalLLaMA)

💡 其他
Daimon Robotics推出心灵手巧的机器人Sparky 1: Daimon Robotics公司展示了其在灵巧机器人技术方面的突破性产品Sparky 1。这款机器人被描述为具备“心灵手巧”(Mind-Dexterous)的能力,暗示其在感知、决策和精细操作方面达到了新的水平,可能融合了先进的AI和机器学习技术。 (来源: Ronald_vanLoon)
MIT研发米粒大小微型机器人,可进入大脑治疗无法手术的肿瘤: MIT的研究人员开发出一种米粒大小的微型机器人,有潜力通过微创方式进入大脑,用于治疗以往难以通过手术切除的肿瘤。这类技术结合了微型机器人技术与AI导航或控制,为神经外科和癌症治疗提供了新的可能性。 (来源: Ronald_vanLoon)

傲鲨智能完成两轮融资,推动消费级外骨骼机器人量产与AI技术融合: 外骨骼机器人技术平台公司傲鲨智能宣布连续完成两轮融资,彬复资本领投,老股东国仪资本跟投。资金将用于消费级外骨骼机器人的量产,并推动外骨骼硬件与AI技术的融合。公司产品已应用于工业场景,并开始探索户外助力(如景区登山辅助)和居家养老市场,计划推出万元以内消费级产品。其最新产品已搭载AI大模型训练能力,并预研脑机接口技术。 (来源: 36氪)