
关键词:Gemini 2.5 Pro, Kevin-32B, AI Agent, RAG技术, 数字孪生, Gemini 2.5 Pro编码能力, Kevin-32B CUDA内核, Agentic Search, GraphRAG知识图谱, AI与数字孪生融合
🔥 聚焦
谷歌发布Gemini 2.5 Pro I/O版 : 谷歌发布Gemini 2.5 Pro I/O版,大幅提升编码能力,横扫LMArena编程、视觉和WebDev排行榜首,实现单一模型首次三榜称冠。新版本增强前端和UI开发,可从手绘草图生成应用,并修复了函数调用问题,显示出谷歌在AI模型能力上的快速进步。 (来源: JeffDean, lmarena.ai, dotey)
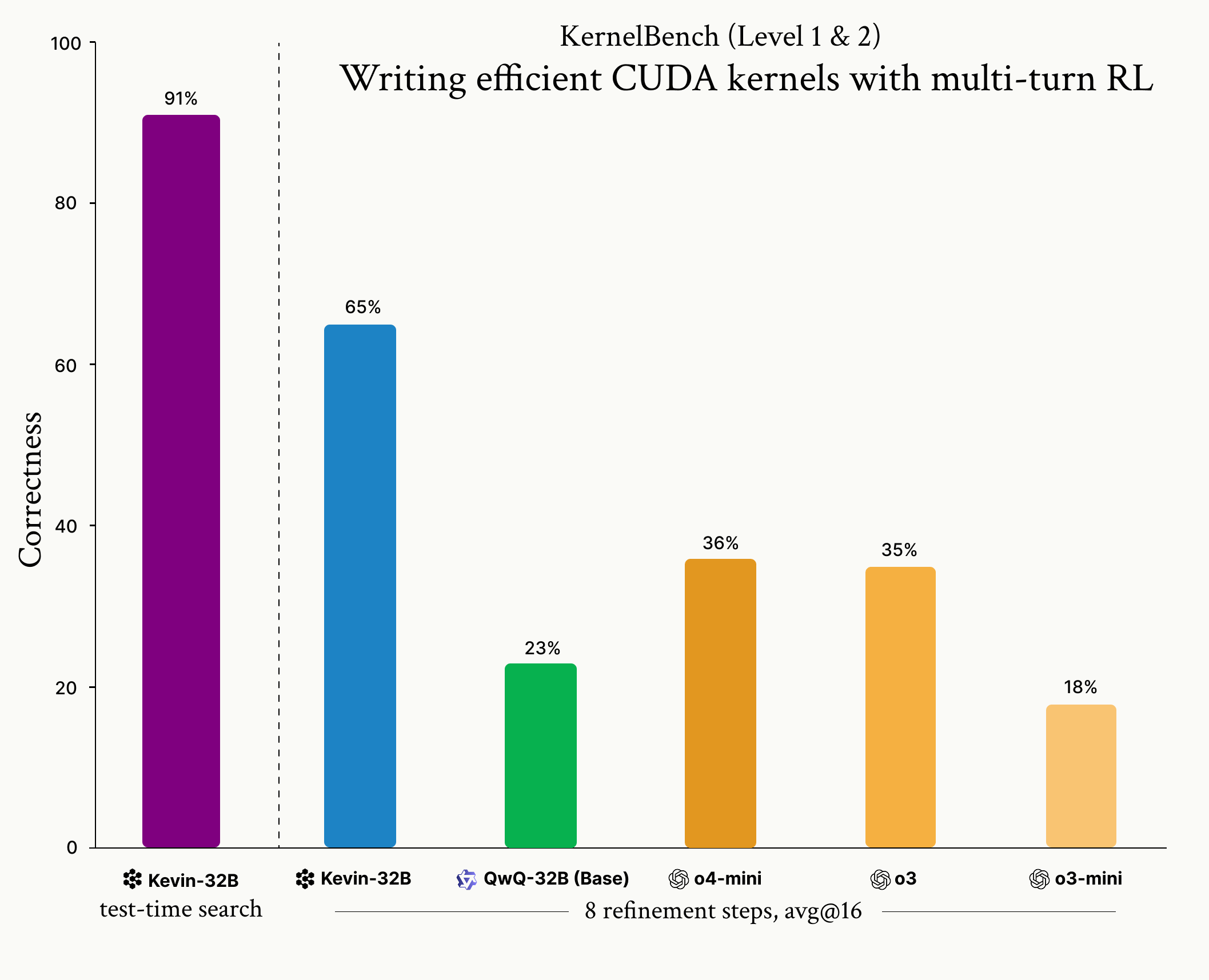
Cognition发布Kevin-32B模型 : Cognition发布Kevin-32B,这是首个通过强化学习(GRPO算法)训练用于编写CUDA内核的开源模型。该模型在KernelBench数据集上表现出色,在正确性和性能上超越了o3和o4-mini等顶级推理模型,展示了RL在低层编程优化上的潜力。 (来源: Cognition, Dorialexander, vllm_project)
Meta发布Perception Encoder : Meta发布新的视觉编码器Meta Perception Encoder,在图像和视频任务上树立新标准。该模型在零样本分类和检索方面表现突出,超越现有模型,为图像和视频理解研究及应用提供了新的强大基础。 (来源: AIatMeta)
LTX-Video 13B开源视频生成模型发布 : LTX-Video 13B发布,这是目前最强大的开源视频生成模型之一。该模型拥有130亿参数,支持多尺度渲染以提升细节,增强运动和场景理解,可在本地GPU上运行,并支持关键帧、相机/角色运动控制。 (来源: teortaxesTex, Yoav HaCohen)
🎯 动向
Anthropic LeMUR支持新Claude模型 : AssemblyAI宣布其LeMUR能力现已支持Anthropic的Claude 3.7 Sonnet和Claude 3.5 Haiku模型。Sonnet增强复杂音频分析的推理能力,Haiku优化响应速度,为音频内容分析和会议摘要等任务带来显著提升。 (来源: AssemblyAI)
Nvidia与ServiceNow推出企业级AI模型Apriel Nemotron 15B : Nvidia与ServiceNow合作推出Apriel Nemotron 15B,这是一个基于Nvidia NeMo构建的紧凑、高成本效益的企业级AI模型。该模型旨在为IT、HR和客户服务等领域提供实时响应、处理复杂工作流并具备可扩展性。 (来源: nvidia)

DeepSeek模型更新及发展时间线 : DeepSeek V3和V3-0324等模型持续更新,展现其在推理能力和新功能上的进展。社区讨论其时间线和特点,认为DeepSeek通过创新架构和训练方法,在追赶前沿模型方面取得显著进展。 (来源: teortaxesTex, dylan522p)

GraphRAG和Agentic Search推动RAG技术发展 : Cohere探讨GraphRAG和Agentic Search作为下一代RAG技术。GraphRAG通过知识图谱提升准确性和可靠性,Agentic Search利用AI Agent进行深度迭代搜索,为企业级AI应用带来更精确、上下文更丰富的答案。 (来源: cohere)
AI Agent概念热炒与落地挑战 : Gartner等机构指出,当前AI Agent领域存在过度炒作(”Agent Washing”),许多现有技术被重新包装。尽管市场咨询量激增,但企业级Agent部署成功率较低,技术瓶颈、可靠性、成本和场景适用性仍是主要制约因素。 (来源: 36氪, Gartner)
AI重塑教育科技格局,中国企业崛起 : 《时代》杂志与Statista发布的全球顶尖教育科技公司榜单显示,中国企业首次包揽前三(编程猫、网易有道、好未来),彻底改变了美国主导的格局。AI成为驱动教育科技变革的关键基础设施,中国企业的成功得益于政策支持和AI技术在教育场景的深度融合。 (来源: 36氪)
Meta与微软CEO探讨AI未来 : Meta创始人扎克伯格与微软CEO纳德拉对话,探讨AI对企业生产力和未来应用开发的影响。纳德拉认为AI正带来“深度应用”阶段,代码库中AI编写比例增加;扎克伯格预测未来工程师将领导智能体小队,AI将完成大部分开发工作。 (来源: 36氪)
数字人技术从“形似”迈向“神似” : 数字人技术正从静态形象向智能交互演进,借助Transformer、扩散模型等大模型技术,实现更逼真的表情、动作和唇形同步。这项技术在消费、中小企业和大型企业领域有广泛应用潜力,但仍面临技术连贯性、互动性和产业链协同等挑战。 (来源: 36氪)
AI成功读取赫库兰尼姆古卷标题 : 维苏威挑战赛取得历史性突破,研究人员利用AI技术首次非侵入性地读取了被火山碳化的赫库兰尼姆古卷标题。这一成果通过AI图像分割和墨迹检测实现,证明了AI“透视”古代文献的能力,为解读更多沉睡的古卷铺平了道路。 (来源: 36氪)

多款开源AI模型和数据集发布 : 社区总结近期开源AI领域的进展,包括Alibaba Qwen发布Qwen3系列模型和Qwen2.5-Omni多模态模型,微软发布Phi4推理模型,NVIDIA发布CoT推理数据集、语音识别模型Parakeet,以及Meta的EdgeTAM等。 (来源: mervenoyann)
ACE-Step发布开源音乐生成模型 : StepFun AI与ACE Studio合作发布ACE-Step 3.5B,这是一个开源的音乐生成模型。该模型支持多语言、多种乐器风格和声乐技巧,可在A100 GPU上快速生成歌曲,为音乐创作领域带来新的AI工具。 (来源: Teknium1, Reddit r/LocalLLaMA)

AI在数字孪生领域的应用增长 : 报告显示,越来越多的行业正在将其数字孪生与AI结合,以提升效率和洞察力。AI与数字孪生的融合成为重要的技术趋势,推动了各行业的数字化转型和创新应用。 (来源: Ronald_vanLoon)

🧰 工具
Smolagents整合计算机使用能力 : Smolagents框架推出计算机使用功能,借助Qwen-VL等视觉模型的能力,AI Agent现在能够理解屏幕截图并定位元素,从而实现点击等操作,推动复杂Agent工作流的发展。 (来源: huggingface)
Qdrant Cloud升级提升矢量搜索效率 : Qdrant Cloud进行重大升级,旨在让用户更快地从原型转向生产。新版本优化了用户界面和体验,使构建语义搜索和嵌入矢量搜索应用更加便捷高效。 (来源: qdrant_engine)
AI洗头服务作为新商业模式兴起 : 上海、深圳等多地出现AI洗头店,通过智能洗头机提供标准化服务,以低价吸引顾客。尽管消费者反馈褒贬不一,且面临技术成熟度、安全性和盈利模式挑战,但AI洗头作为AI在服务业的应用尝试,展现了新的商业探索方向。 (来源: 36氪)
开源LLM评估工具Opik发布 : Opik是一个开源的LLM评估工具,用于调试、评估和监控LLM应用、RAG系统和Agent工作流。它提供全面的追踪、自动化评估和生产级仪表板,帮助开发者提升AI应用的性能和可靠性。 (来源: dl_weekly)
Python Chain-of-Thought工具包Cogitator : 发布了一个名为Cogitator的开源Python工具包,旨在简化Chain-of-Thought (CoT) 推理方法的使用和实验。该库支持OpenAI和Ollama模型,并包含Self-Consistency、Tree of Thoughts和Graph of Thoughts等CoT策略实现。 (来源: Reddit r/MachineLearning)
Comfyui品牌升级并推出原生API节点 : Comfyui进行了品牌升级,并推出原生API节点,支持集成Flux、Kling、Luma等11种在线视觉AI模型。用户无需单独申请API Key,直接在Comfyui内登录即可使用,极大简化了多模型工作流的搭建。 (来源: op7418)

Cursor向学生及法律学生提供免费服务 : AI编程助手Cursor宣布向学生提供免费Pro版本,法律AI工具Spellbook也向法律学生提供免费服务。此举降低了学生接触和使用先进AI工具的门槛,有助于AI技术在教育领域的普及。 (来源: scaling01, scottastevenson)
📚 学习
Unsloth框架实现高效LLM微调 : LearnOpenCV博客深入解读Unsloth框架,展示如何更快速、轻量、智能地微调大型语言模型和视觉语言模型(如Qwen2.5-VL)。Unsloth通过优化技术显著降低GPU内存使用和训练时间,特别适合资源有限的用户。 (来源: LearnOpenCV)
Cohere研究揭示人类评估LLM的偏见 : Cohere一项研究发现,即使是很小的偏见(如更自信的措辞)也会系统性地扭曲人类对LLM输出的评估。模型给出更武断的回答时常被评为“更好”,即使内容相同,这凸显了人类评估的非理性及评估模型面临的挑战。 (来源: Shahules786, clefourrier)
SWE-bench推出多语言编码能力评估 : SWE-bench库发布新版本,引入SWE-bench Multilingual,用于测试LLM在9种编程语言中的编码能力。Claude 3.7在该多语言评估上的表现低于其在英文SWE-bench上的得分,表明LLM跨语言编码能力仍需提升。 (来源: OfirPress)

研究探讨LLM对齐可能损失的能力 : 研究人员探讨大型语言模型在进行对齐(Alignment)训练时可能损失的某些能力,例如随机性和创造性。这引发了关于在提升模型安全性和有用性的同时,如何保留其原始潜力的讨论。 (来源: lateinteraction, Peter West)

Muon优化器研究显示效率优势 : Essential AI发布研究,探讨Muon优化器在LLM预训练中的实践效率。研究表明,作为一种二阶优化器,Muon在计算时间权衡上比AdamW更具优势,尤其在大批量训练时能更有效地保留数据信息。 (来源: cloneofsimo, Essential AI)
Epoch AI基准测试平台更新 : Epoch AI更新其基准测试平台,新增Aider Polyglot、WeirdML、Balrog和Factorio Learning Environment等评估项。这些新基准引入了外部排行榜数据,为评估LLM性能提供了更全面的视角。 (来源: scaling01)
Hugging Face发布AI Agent课程 : Hugging Face发布AI Agent课程,内容涵盖Agent基础、LLM、模型家族、框架(smolagents, LangGraph, LlamaIndex)、可观测性、评估以及Agentic RAG用例,并包含最终项目和基准测试,为学习构建AI Agent提供了系统资源。 (来源: GitHub Trending, huggingface)

💼 商业
OpenAI收购AI编程助手Windsurf : OpenAI同意以约30亿美元收购AI编程助手开发商Windsurf(前身为Codeium),这是OpenAI迄今为止最大规模的收购。此举旨在巩固OpenAI在AI编程领域的地位,获取Windsurf的用户基础和代码库演变数据,为未来AI编程Agent发展布局。 (来源: 36氪, Bloomberg, 智东西)
OpenAI放弃彻底商业化转型计划 : OpenAI宣布放弃将母公司彻底转变为营利性机构的计划,决定维持非营利母公司控制营利性子公司的结构,并将子公司转为“公益性公司”。此举是与监管机构及各方讨论后的折中方案,影响公司治理和未来融资策略,也与马斯克等人的反对有关。 (来源: steph_palazzolo, 36氪)
云从科技面临裁员和亏损 : 老牌AI企业云从科技财报显示营收大幅下降,亏损扩大,并进行裁员和高管降薪。这反映了AI创业领域面临的盈利挑战和市场竞争压力,许多AI企业在当前阶段“活下去”成为首要任务,预示着AI创业泡沫可能正在破裂。 (来源: 36氪)

🌟 社区
AI深度伪造引发信任危机和“合理否认”风险 : 社区讨论AI深度伪造技术日益逼真,导致公众难以分辨真假信息,引发信任危机。更担忧的是,个人或机构可能利用AI伪造作为对其不当言行的“合理否认”借口,这对事实核查和法律追责带来挑战。 (来源: Reddit r/ArtificialInteligence)

OpenAI内部测试显示ChatGPT幻觉问题恶化 : 报道称,OpenAI内部测试显示ChatGPT的幻觉(hallucination)问题正在恶化,且原因不明。这一发现引发社区对模型可靠性和可解释性的担忧,也表明即使是领先模型仍面临基础性挑战。 (来源: Reddit r/artificial)

社区担忧AI模型训练数据中可能被植入广告 : 社区讨论未来AI模型训练数据中可能被故意植入广告或偏见信息,导致模型输出包含隐性推广或特定观点。这引发了对模型透明度、安全性和商业模式的担忧,以及开源模型在此方面的优势。 (来源: Reddit r/LocalLLaMA)
关于AI Agent概念炒作与实际落地难度的讨论 : 社区热议AI Agent概念的火热与实际落地之间的差距。讨论指出,许多“Agent”只是现有技术的重新包装,企业在构建和部署真正的Agent时面临技术可靠性、成本控制和复杂性等挑战,需要务实地评估其业务价值。 (来源: 36氪, Reddit r/ArtificialInteligence)
关于Ollama和OpenWebUI等开源工具的争议 : 社区讨论Ollama作为本地LLM运行工具的优缺点,包括其模型存储格式、与llama.cpp的同步问题以及默认配置等。同时,OpenWebUI修改许可证,对商业用户增加限制,引发了社区关于开源精神和项目可持续性的讨论。 (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
机器学习从业者对数据集获取的焦虑 : 机器学习从业者在社交媒体上表达对获取高质量数据集的焦虑,认为数据是模型性能的“天花板”,但非技术背景的管理者常低估数据工作的复杂性,将AI视为“魔法棒”。 (来源: Reddit r/MachineLearning)
AI生成代码的管理与审查挑战 : 随着AI生成代码的普及,社区讨论如何有效管理和审查由AI产生的大量代码。开发者需要建立流程和工具来确保AI代码的质量和正确性,工作重心可能从编写代码转向审查和验证。 (来源: matvelloso, finbarrtimbers)
RAG实际应用效果与用户期望的差距 : 有用户反映在使用RAG处理个人文档时,模型表现不如预期,无法准确回答文档中包含的问题。这表明RAG在处理特定、非公开数据集时仍存在挑战,实际效果与用户在通用模型上的体验有差距。 (来源: Reddit r/OpenWebUI)
💡 其他
微软PowerToys更新,新增Command Palette等功能 : 微软发布PowerToys 0.90版本,新增Command Palette(CmdPal)模块作为PowerToys Run的演进,增强了快速启动和扩展性。此外还改进了Color Picker、Peek文件删除、New+模板变量等功能,提升Windows用户生产力。 (来源: GitHub Trending)

Nvidia计划停止对旧GPU的CUDA支持 : Nvidia宣布计划在下一主要Toolkit版本中停止对Maxwell、Pascal和Volta系列GPU的CUDA支持。此举将影响部分仍在依赖这些旧硬件进行AI/ML工作的用户,可能推动基础设施升级,但也引发社区对硬件淘汰和兼容性的讨论。 (来源: Reddit r/LocalLLaMA)

谷歌Nest Hub设备未能集成Gemini : 用户抱怨谷歌Nest Hub智能显示设备至今仍使用老旧的Google Assistant,未能集成更强大的Gemini模型。尽管Pixel手机等设备已支持Gemini,但Nest Hub系列缺乏升级路线图,引发用户对谷歌产品生态系统碎片化和AI普及承诺的质疑。 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial)