

关键词:OpenAI, DSPy, SGLang, Nvidia, ChatGPT, AI, LLM, MoE, dspy.GRPO, DeepSeek MoE, Parakeet TDT, Agentic 系统, EQ-Bench 3
🔥 聚焦
OpenAI 确认维持非营利结构: OpenAI 宣布其现有营利性实体将转变为公益公司(PBC),但控制权仍归属于当前的非营利组织。此举确认了 OpenAI 将继续由非营利组织控制,并重申其确保 AGI(通用人工智能)惠及全人类的使命。这一决定是在经历内部动荡和外界对其结构性质疑(包括马斯克的诉讼)后做出的,社区对此反应不一,有人认为这是坚守使命,也有人质疑其资本结构调整的真实意图 (来源: OpenAI, sama, jachiam0, NeelNanda5, scaling01, zacharynado, mcleavey, steph_palazzolo, Plinz, Teknium1)
DSPy 框架发布实验性在线 RL 优化器 dspy.GRPO: Stanford NLP 团队发布了 DSPy 框架的一项实验性新功能 dspy.GRPO,这是一个在线强化学习(RL)优化器。该工具旨在优化 DSPy 程序,即使是复杂的多模块、多步骤程序也能直接应用,无需修改现有代码。此举被视为将 RL 优化(如 DeepSeek 使用的 GRPO)引入更高抽象层次(LLM 工作流)的重要一步,旨在提升 AI 代理和复杂管道的性能与效率,社区对此反响热烈,认为这将是 DSPy 3.0 的重要组成部分 (来源: Omar Khattab, matei_zaharia, lateinteraction, Michael Ryan, Lakshya A Agrawal, Scott Condron, Noah Ziems, Rogerio Chaves, Karthik Kalyanaraman, Josh Cason, Mehrdad Yazdani, DSPy, Hopkinx🀄️, Ahmad, william, lateinteraction, lateinteraction, swyx)
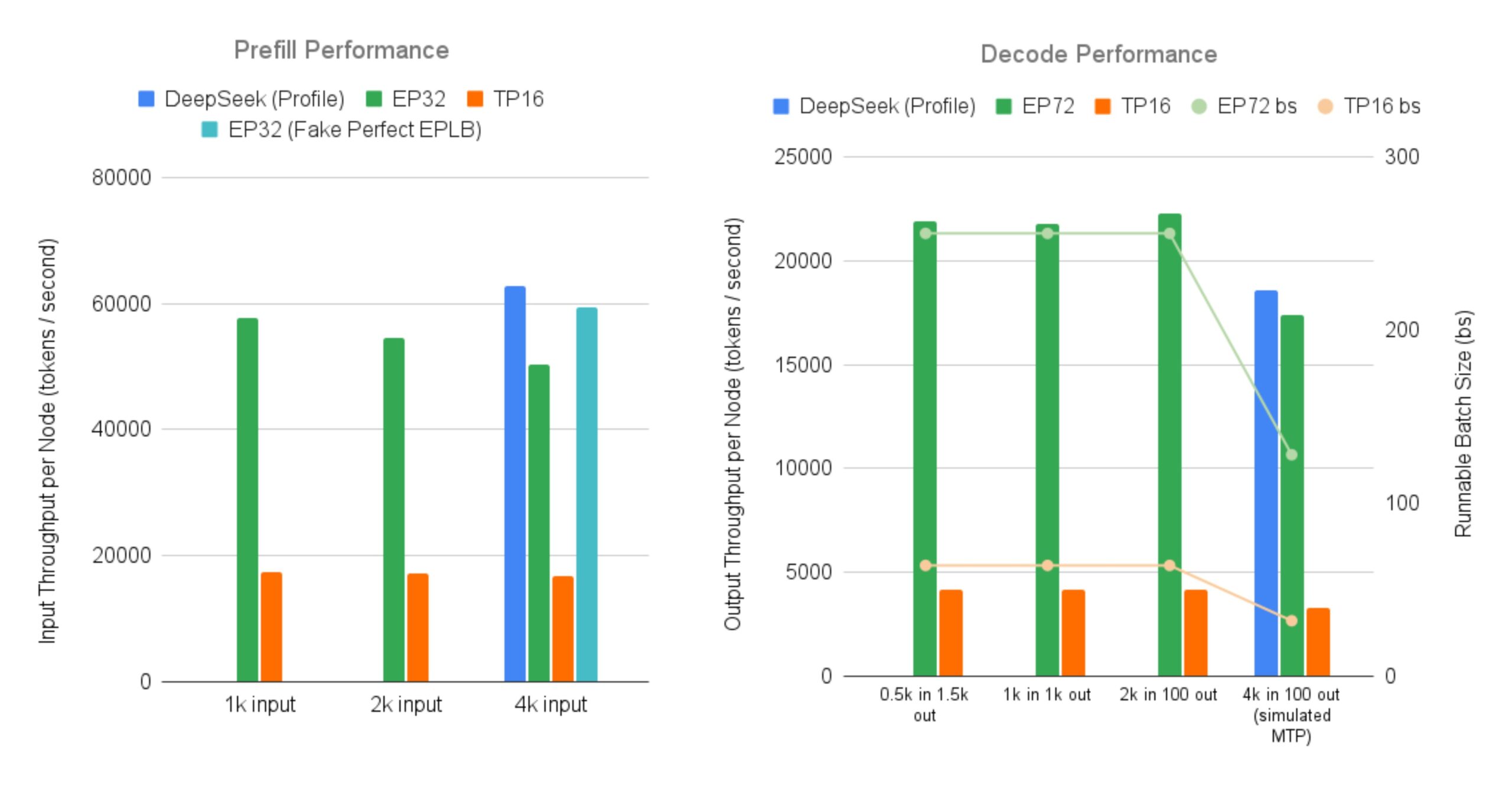
SGLang 开源实现高效服务 DeepSeek MoE 大模型: LMSYS Org 宣布 SGLang 提供了首个开源实现,用于在 96 个 GPU 上服务 DeepSeek V3/R1 等具有大规模专家并行(Expert Parallelism)和预填充-解码分离(Prefill-Decode Disaggregation)特性的 MoE(Mixture-of-Experts)模型。该实现几乎达到了 DeepSeek 官方报告的吞吐量(每节点输入 52.3k token/秒,输出 22.3k token/秒),相比传统的张量并行,输出吞吐量提升高达 5 倍。这为社区提供了高效运行和部署大型 MoE 模型的开源方案 (来源: LMSYS Org, teortaxesTex, cognitivecompai, lmarena_ai, cognitivecompai)
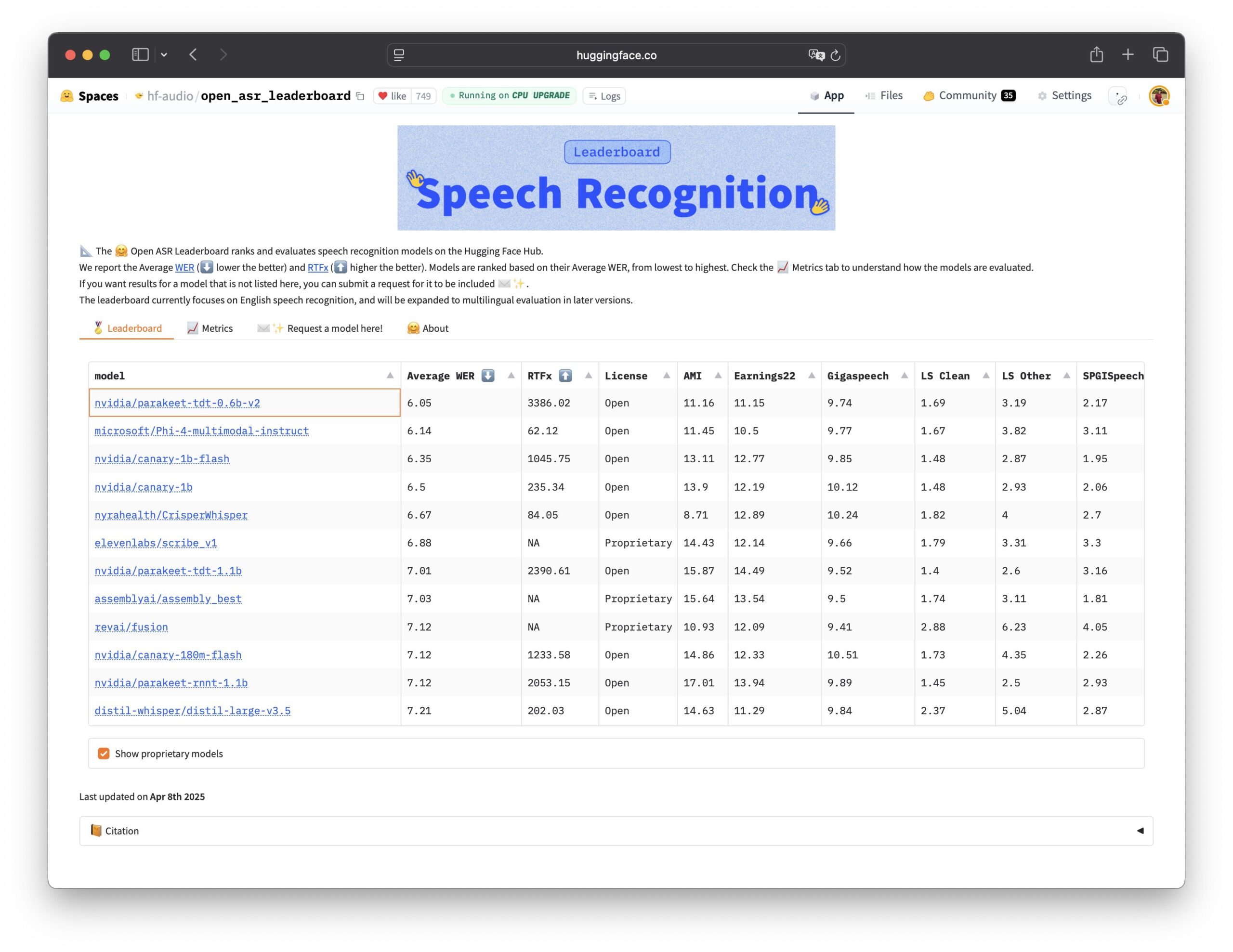
Nvidia 开源 Parakeet TDT 语音识别模型: Nvidia 开源了 Parakeet TDT 0.6B 模型,该模型在 Open ASR Leaderboard 上表现最佳,成为当前性能领先的开源自动语音识别(ASR)模型。该模型拥有 6 亿参数,能在 1 秒内转录 60 分钟的音频,性能优于许多主流闭源模型。模型采用 CC-BY-4.0 许可,允许商业使用,为语音识别领域提供了强大的开源选项 (来源: Vaibhav (VB) Srivastav, huggingface, ClementDelangue)
🎯 动向
ChatGPT 访问量持续增长超越 X: Similarweb 数据显示,ChatGPT 的访问量持续增长,在 4 月份的总访问量(47.86 亿次)已超过 X 平台(40.28 亿次)。从 2025 年初开始,ChatGPT 的访问量稳步攀升,从 1 月偶尔落后,到 4 月几乎全面领先 X,显示出 AI 聊天机器人在用户活跃度上的强劲势头 (来源: dotey)
数据信任与领导力成为 AI 转型关键: 多篇报告和讨论强调,数据信任是加速 AI 转型的无形力量。同时,成功的 GenAI 领导者在战略、组织和技术应用上展现出不同的特质。这表明 AI 成功的关键不仅在于技术本身,更在于高质量、可信的数据基础以及有效的领导和战略部署 (来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

GTE-ModernColBERT 在长文本嵌入任务上表现 SOTA: LightOn 发布的 GTE-ModernColBERT 多向量嵌入模型,在 LongEmbed 长文档搜索基准测试中取得了 SOTA(State-of-the-Art)成绩,领先近 10 个点。值得注意的是,该模型仅在 MS MARCO 的短文档(长度 300)上进行训练,却在长文本任务中展现出优异的零样本泛化能力。这进一步印证了后期交互(Late Interaction)模型(如 ColBERT)在处理长上下文检索方面的潜力,优于传统的 BM25 和密集检索模型 (来源: Antoine Chaffin, Ben Clavié, tomaarsen, Dorialexander, Manuel Faysse, Omar Khattab)

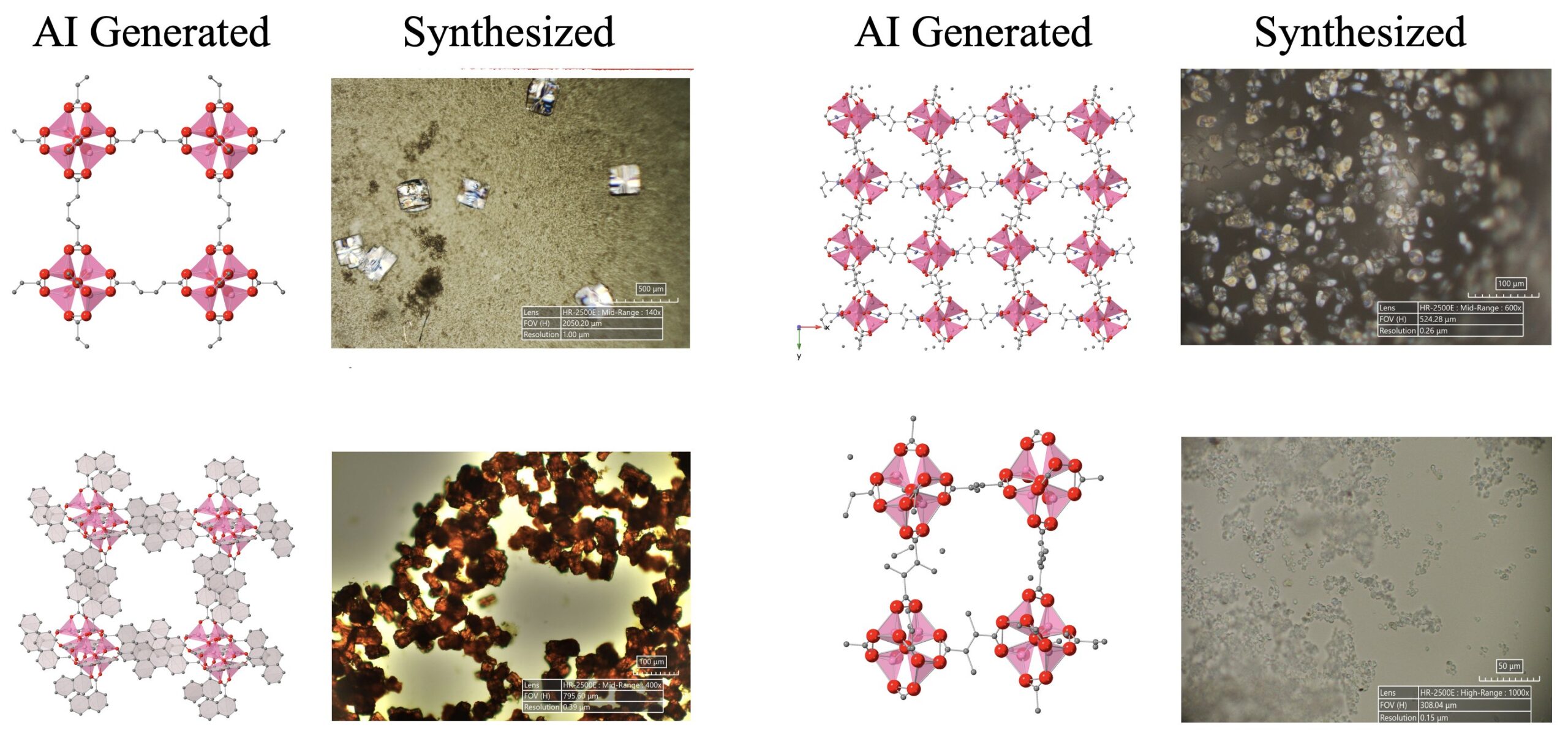
AI 驱动的科学发现取得进展: 一个由 LLM、扩散模型和硬件设备组成的 AI 代理系统成功自主地发现并合成了 5 种新型金属有机结构(MOFs),这些结构超出了现有的人类知识范围。该研究展示了 AI 代理在自动化科学研究方面的潜力,能够完成从提出研究思路到湿实验验证的全过程 (来源: Sherry Yang)
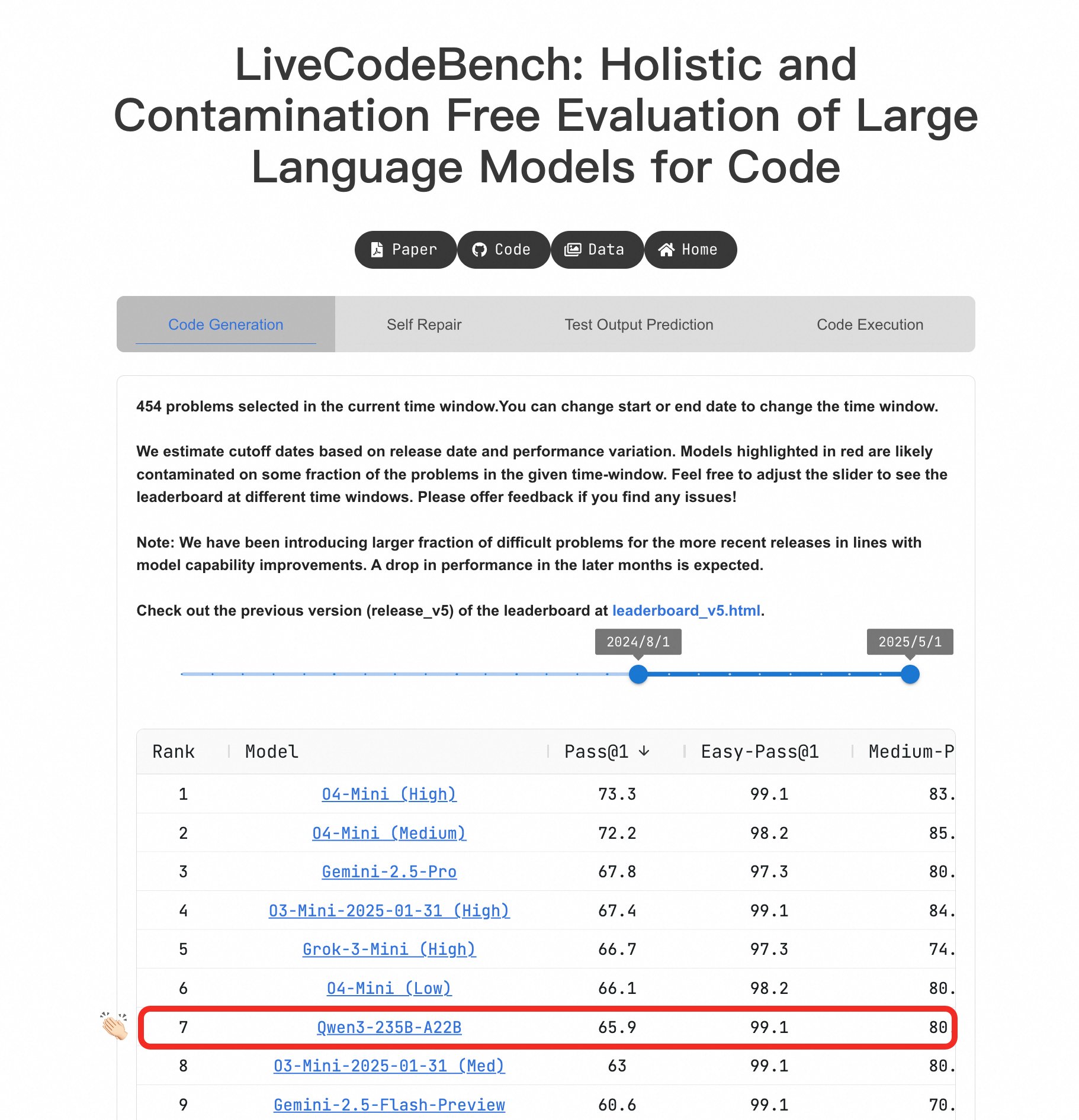
Qwen3 大模型在编程能力上表现突出: 在 LiveCodeBench 基准测试中,Qwen3-235B-A22B 模型展现了出色的性能,被认为是竞技水平代码生成方面表现最好的开源模型之一,其性能与 o4-mini(低置信度)相当。即使在困难问题上,Qwen3 也能保持与 O4-Mini (Low) 同等水平,优于 o3-mini (来源: Binyuan Hui, teortaxesTex)
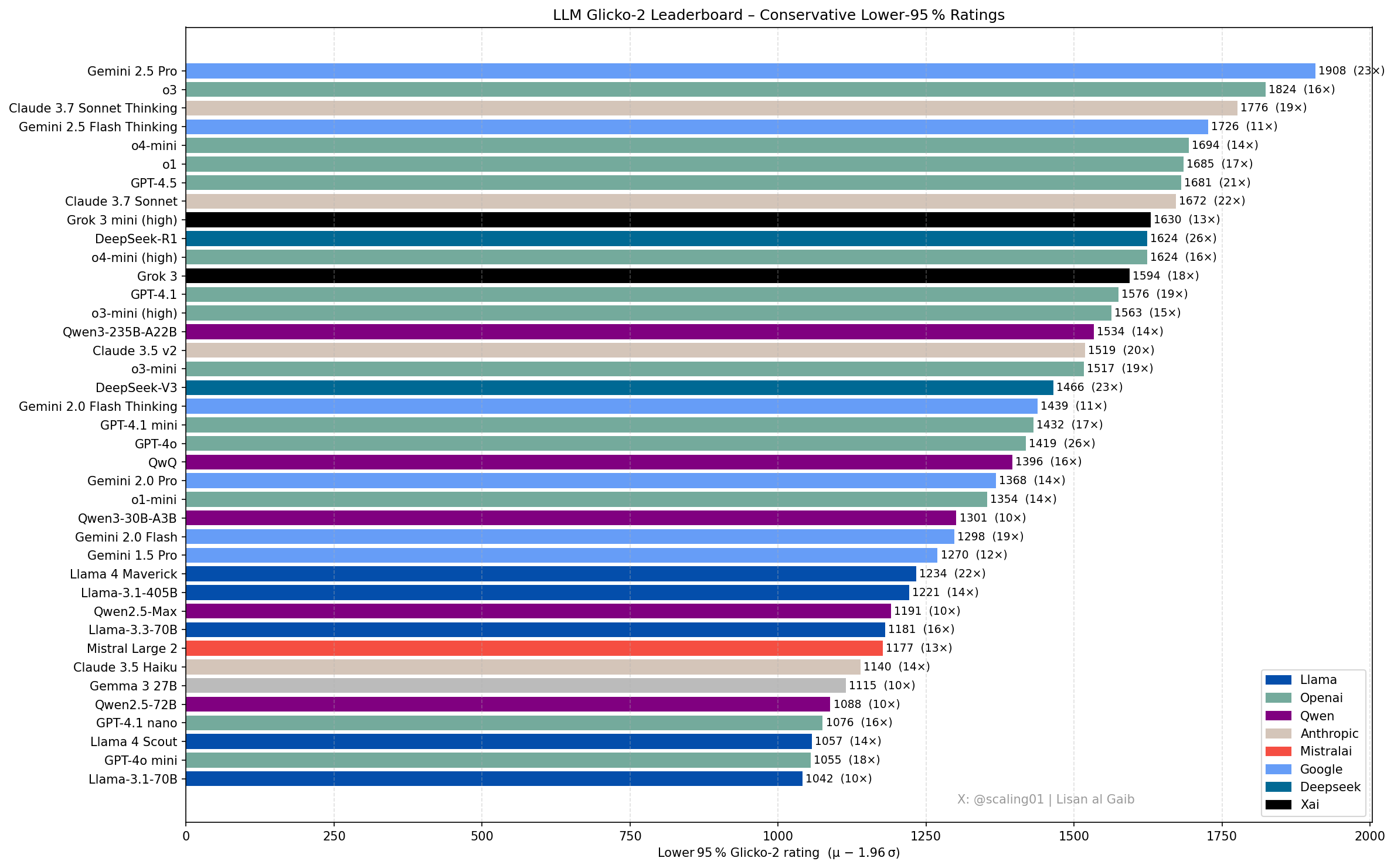
LLM 排行榜新进展与讨论: 社区成员 Lisan al Gaib 使用 Glicko-2 评级系统更新了 LLM 排行榜,引发讨论。Scaling01 认为该榜单与其主观感受符合度达 95%,Gemini 2.5 Pro 仍是领先者,但 Gemini 2.5 Flash、Grok 3 mini 和 GPT-4.1 可能被高估。榜单显示了 OpenAI、Llama 和 Gemini 系列模型的合理进展顺序,o3 (high) 与 Gemini 2.5 Pro 水平相当 (来源: Lisan al Gaib)
开源机器人技术生态系统快速发展: Hugging Face 的 Clem Delangue 与 NPeW、Matth Lapeyre 交流后,对 AI 机器人领域的进展表示兴奋。Peter Welinder (OpenAI) 也赞扬了 Hugging Face 在推动开源机器人技术生态系统发展方面的工作,认为该领域正在快速成长 (来源: ClementDelangue, Peter Welinder, ClementDelangue, huggingface)
AI 解释性研究方向受关注: 研究人员呼吁在 AI 解释性(Interpretability)方面进行更多工作,特别是针对模型出现的奇怪行为进行解释。通过理解这些行为,可以反过来推导 LLM 内部机制的更深层结论,并可能催生新的解释性工具。这被认为是一个有前景且具影响力的研究方向 (来源: Josh Engels)
FutureHouseSF 致力于构建“AI 科学家”: FutureHouseSF 公司 CEO Sam Rodriques 接受采访,阐述了公司构建“AI 科学家”的目标。讨论内容涉及 AI 科学家的具体含义、机器人技术在其中的作用,以及为何科学领域需要类似“星际之门”项目的推动力,旨在利用 AI 加速科学发现 (来源: steph_palazzolo)
谷歌 TPU 优势或被低估: 评论员 Justin Halford 认为,投资者可能低估了谷歌在 TPU(张量处理单元)方面的优势。他指出,在算法护城河不显著的情况下,算力将是 AI 竞赛的关键,而谷歌自研 TPU 能避免中间成本,这在数千亿资金涌入基础设施建设的背景下至关重要 (来源: Justin_Halford_)
开源 VLA 模型 Nora 发布: Declare Lab 开源了基于 Qwen2.5VL 和 FAST+ tokenizer 的新型视觉-语言-动作(VLA)模型 Nora。该模型在 Open X-Embodiment 数据集上训练,并在真实世界的 WidowX 任务上表现优于 Spatial VLA 和 OpenVLA (来源: Reddit r/MachineLearning)

LLM 推理优化新方法:快照与恢复: 面对 LLM 推理中的冷启动和多模型部署挑战,有团队构建了一种新的运行时系统。该系统通过快照模型的完整执行状态(包括内存布局、注意力缓存、执行上下文)并直接在 GPU 上恢复,实现了 2 秒内的冷启动,可在 2 个 A4000 GPU 上托管 50 多个模型,GPU 利用率达 90% 以上,且无持久内存膨胀。这种方法类似为推理构建了一个“操作系统” (来源: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
开源实时目标检测器 D-FINE: Hugging Face Transformers 库新增了实时目标检测器 D-FINE。该模型据称比 YOLO 更快更准确,采用 Apache 2.0 许可证,可在 T4 GPU(免费 Colab 环境)上运行,为实时目标检测提供了新的 SOTA 开源选项 (来源: merve, algo_diver)
LLM 定价趋于动态化: 观察到大型语言模型的定价正变得更加动态。这可能有助于市场随着时间的推移找到更优的价格点,反映了模型提供商在成本、需求和竞争压力下调整定价策略的趋势 (来源: xanderatallah)
tinybox green v2 支持 GPU 间 P2P: the tiny corp 宣布其 tinybox green v2 产品通过修改后的驱动程序,支持 RTX 5090 GPU 之间的点对点(P2P)通信。这意味着数据可以直接在 GPU 之间传输,无需经过 CPU RAM,提高了多 GPU 协同工作的效率。该功能兼容 tinygrad 和 PyTorch(任何使用 NCCL 的库) (来源: the tiny corp)
研究人员发布 EQ-Bench 3 用于评估 LLM 情商: Sam Paech 发布了 EQ-Bench 3,这是一个用于衡量大型语言模型(LLM)情商(EQ)的基准测试工具。开发团队在经历多次原型失败后推出了该版本,旨在更准确、可靠地评估模型在理解和回应情感方面的能力 (来源: Sam Paech, fabianstelzer)

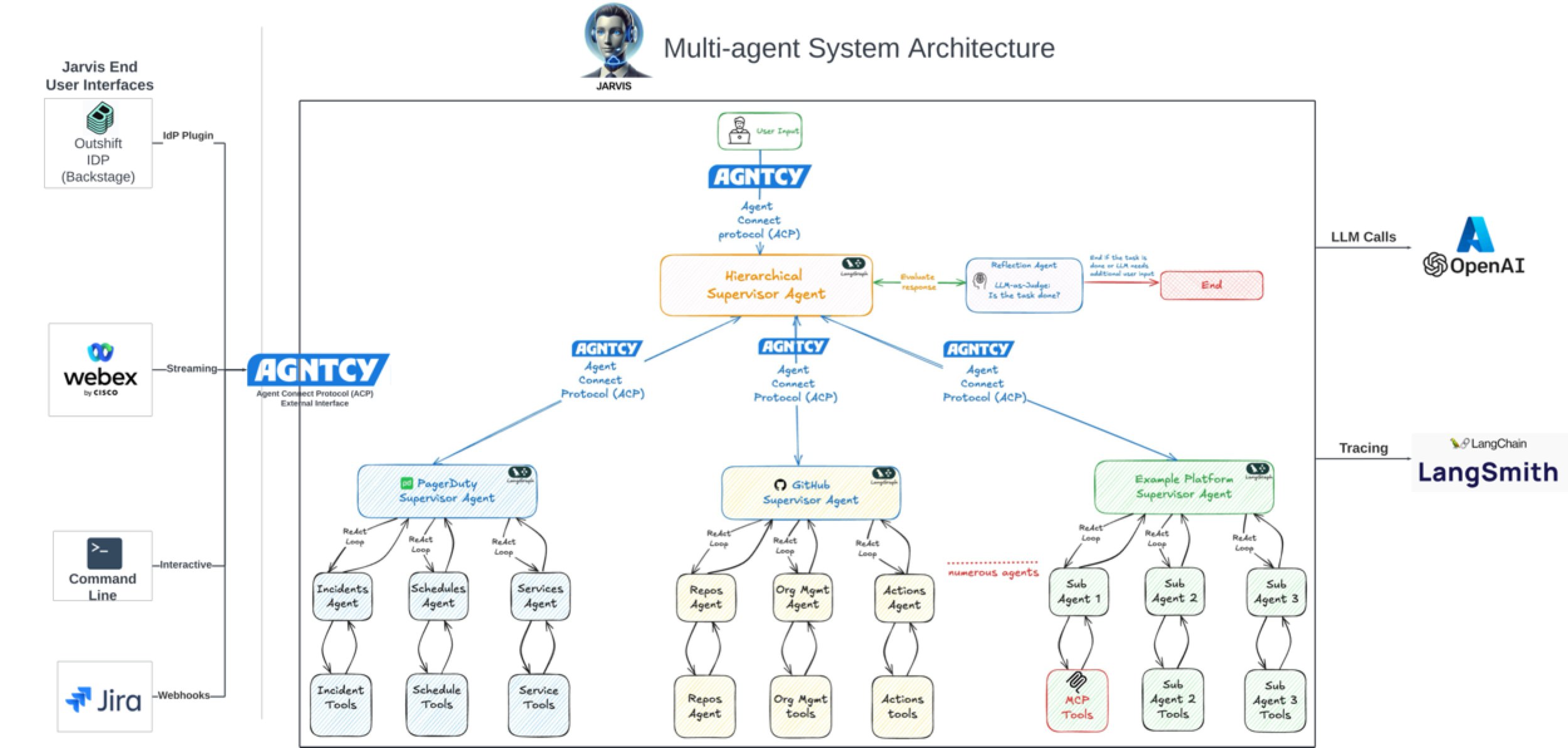
AI 助力软件开发效率提升显著: 社区讨论和案例显示,AI 正显著提升软件开发效率。例如,Vesta 公司代码库中 AI 的提交量已居首位。Cisco Outshift 利用基于 LangGraph 和 LangSmith 构建的 AI 平台工程师 JARVIS,将 CI/CD 设置时间从一周缩短到一小时内,资源配置时间从半天缩短到几秒,实现了 10 倍生产力提升 (来源: mike, LangChainAI, hwchase17)
AI 进军影视与创意产业: 迪士尼/卢卡斯影业通过工业光魔(ILM)发布了首个公开的生成式 AI 作品,标志着顶级 VFX 工作室对 AI 技术的接纳。这预示着 AI 将在影视特效、创意设计等领域扮演更重要角色,改变内容创作流程 (来源: Bilawal Sidhu)
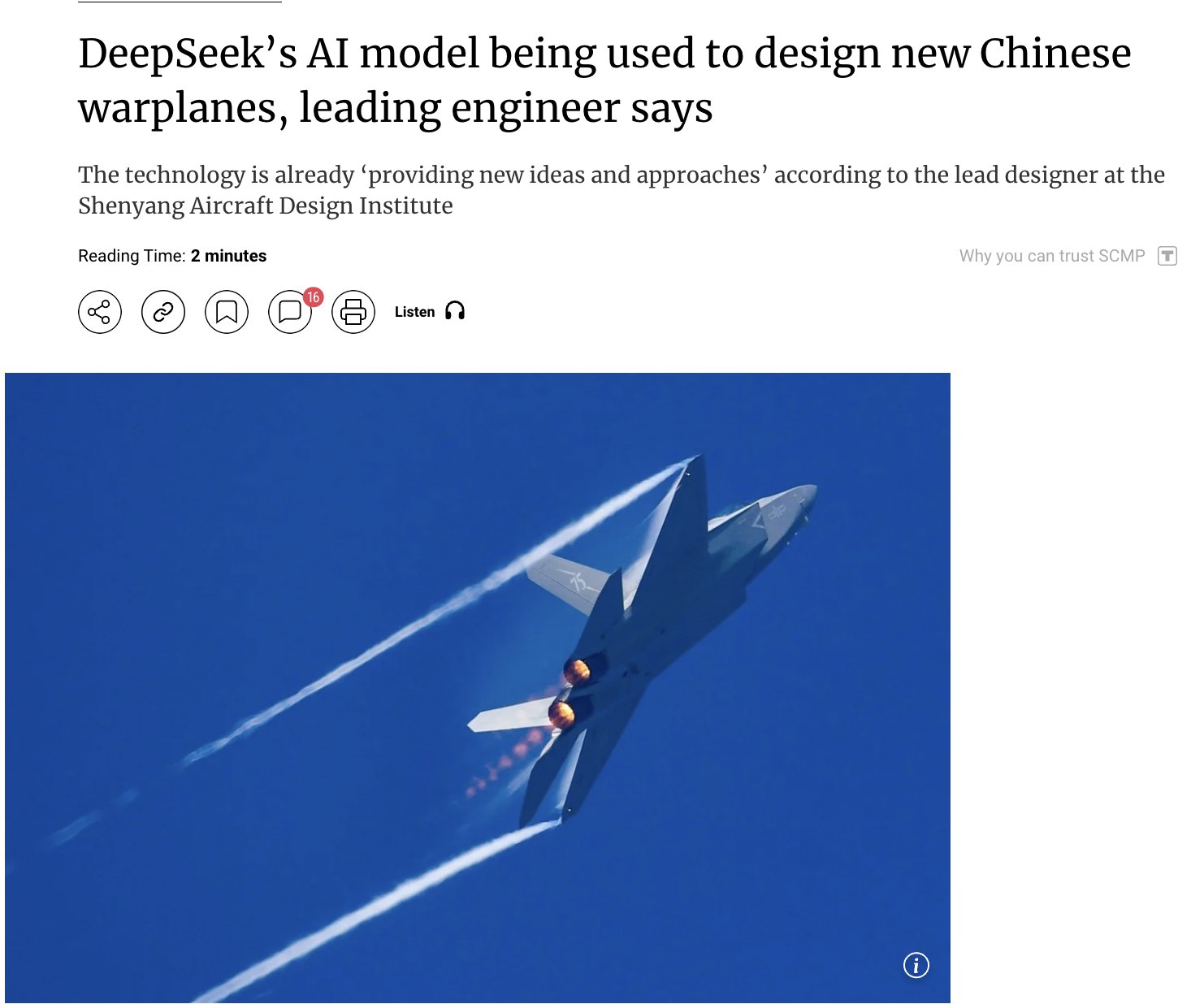
AI 在军事领域的应用引发关注: 有报道称中国正使用其自研的 DeepSeek AI 模型来设计先进战斗机(如 J-15、J-35)并塑造下一代飞机(J-36、J-50)。据称 AI 通过优化隐身性、材料和性能来加速研发。尽管信息来源需谨慎对待,但这反映了 AI 在国防和航空航天领域应用的潜力及引发的关注 (来源: Clash Report)
人才动态:Rohan Pandey 离开 OpenAI: OpenAI Training 团队的研究员 Rohan Pandey 宣布离职。他表示将休息一段时间,致力于解决梵文 OCR 问题,以将古典印度文学经典“永存于超级智能的权重之中”,之后将公布下一步计划。社区成员对其评价很高,认为他是极具天赋的研究者 (来源: Rohan Pandey, JvNixon, teortaxesTex)

AI 版权登记突破 1000 件: 美国版权局已登记超过 1000 件包含 AI 生成内容的作品。这反映了 AI 在创作领域的应用日益广泛,同时也凸显了 AI 生成内容的版权归属和保护问题日益成为焦点 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

Duolingo 裁减合同工,AI 应用引担忧: Duolingo 因 AI 能以 12 倍速度生成课程内容而裁减了部分合同工。此举引发了关于自动化对语言学习及相关行业就业影响的担忧,显示了 AI 在内容创作领域替代人工的潜力及随之而来的社会经济影响 (来源: Reddit r/ArtificialInteligence)

微软在云与 AI 竞赛中领先亚马逊?: 有报道分析指出,微软凭借其在 AI 领域的积极布局(如投资 OpenAI)和云服务(Azure)的整合,正在云和 AI 的竞赛中超越亚马逊(AWS)。文章认为亚马逊在战略聚焦上可能落后于微软 (来源: Reddit r/ArtificialInteligence, Reddit r/deeplearning)

MoE 模型专家使用率引讨论: 社区讨论 MoE 模型中专家(Experts)的使用是否遵循帕累托原则(少数专家处理大部分流量)。多数观点认为,训练目标通常是让专家平均负载,Mixtral 模型偏差很小。但 Qwen3 可能存在一定偏差,不过远未达到 80/20 分布。DeepSeek-R1(256 专家,激活 8 个)的例子也说明,即使特定任务(如编码)会倾向于某些专家,但并非固定不变,且共享专家始终激活 (来源: Reddit r/LocalLLaMA)

Josiefied-Qwen3-8B 微调模型获好评: 用户分享了对 Goekdeniz-Guelmez 微调的 Qwen3 8B 模型(Josiefied-Qwen3-8B-abliterated-v1)的积极评价。该模型被认为在遵循指令、生成生动回复方面优于原版 Qwen3 8B,且无审查。用户在 Q8 量化下运行,认为其表现超出了 8B 模型的预期,尤其适用于在线 RAG 系统 (来源: Reddit r/LocalLLaMA)

RTX 5060 Ti 16GB 或成 AI 性价比之选: 用户分享经验,认为 RTX 5060 Ti 16GB 版本(约 499 美元)虽然游戏性能评测不佳,但凭借 16GB VRAM 在 AI 应用中颇具性价比。对比 12GB GPU 运行 LightRAG 处理 PDF,16GB 版本速度快 2 倍以上,因能容纳更多模型层数,避免了频繁的模型切换,提高了 GPU 利用率。其较短的卡身也适合 SFF 构建 (来源: Reddit r/LocalLLaMA)
RGB 图像用于精细目标分类的可行性探讨: 社区提问,在无法使用高光谱成像(HSI)的情况下,仅使用 RGB 图像是否足以进行单类别精细对象(如咖啡豆)的实时分类或异常检测。虽然文献常推荐 HSI 处理细微差异,但用户希望了解仅用 RGB 实现此类任务的成功案例或可行性 (来源: Reddit r/deeplearning)
Claude 模型 System Prompt 疑似泄露: GitHub 上出现一份疑似 Claude 模型的 System Prompt 文本,长达 25K token。其中包含详细的指令,例如要求模型在任何情况下(包括搜索结果和生成内容中)都不得复制或引用歌词,即使是近似或编码形式,推测与版权限制有关。该泄露(若属实)为了解 Claude 的内部工作机制和安全约束提供了线索 (来源: karminski3)
AI 图像修复新模型 PixelHacker 发布: PixelHacker 模型发布,专注于图像修复(inpainting),强调在修复过程中保持结构和语义的一致性。据称,该模型在 Places2、CelebA-HQ 和 FFHQ 等数据集上的表现优于当前的 SOTA 模型 (来源: Reddit r/deeplearning)

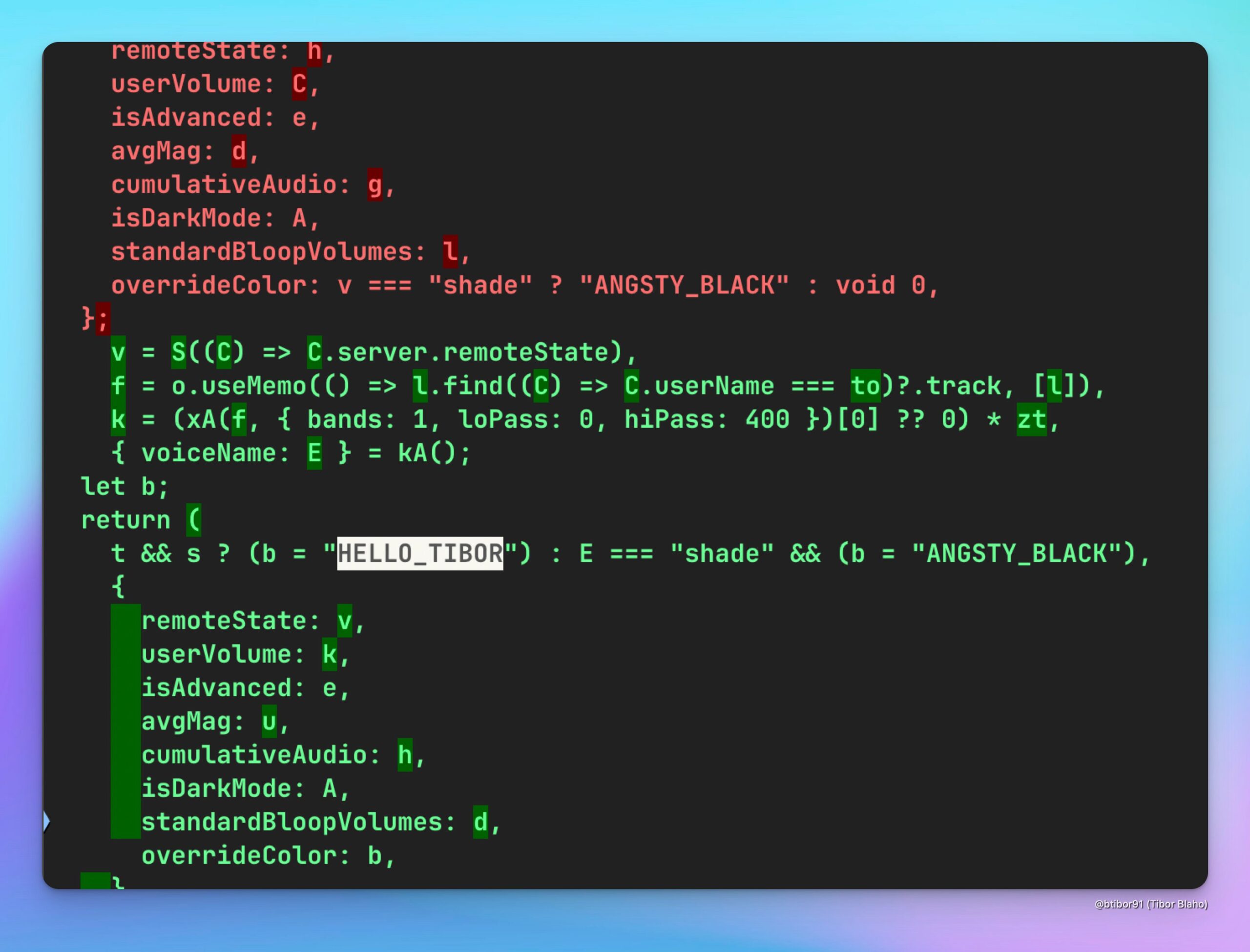
ChatGPT 新增 HELLO_TIBOR 语音: 用户发现最新版 ChatGPT 网页应用中增加了一个名为 “HELLO_TIBOR” 的新语音选项。这表明 OpenAI 可能在持续扩展其语音交互功能,提供更多样化的语音选择 (来源: Tibor Blaho)
🧰 工具
Runway 实现图像转游戏截图及电影致敬: 用户利用 Runway 的 Gen-4 References 功能进行实验,通过详细的多步骤提示(分析场景、理解意图、设定游戏引擎和渲染要求),成功将普通图像转换为虚幻引擎风格的 2.5D 等轴测游戏截图。另一用户则使用 Runway References 和 Gen-4 创作了致敬电影《好家伙》(Goodfellas) 的视频片段。这些案例展示了 Runway 在可控图像/视频生成方面的强大能力,尤其是在结合参考图像和风格迁移方面 (来源: Ray (movie arc), Bryan Fox, c_valenzuelab, c_valenzuelab)

Runway 支持 3D 资产导入提升视频生成可控性: Runway 的 Gen-4 References 功能现在支持使用 3D 资产作为参考,以实现对生成视频中对象形状和细节的更精确控制。用户只需提供场景背景图、3D 模型在该场景中的简单合成图以及风格参考图,即可在生成工作流中引入高度细节化和特定的模型,增强生成内容的一致性和可控性 (来源: Runway, c_valenzuelab, op7418)
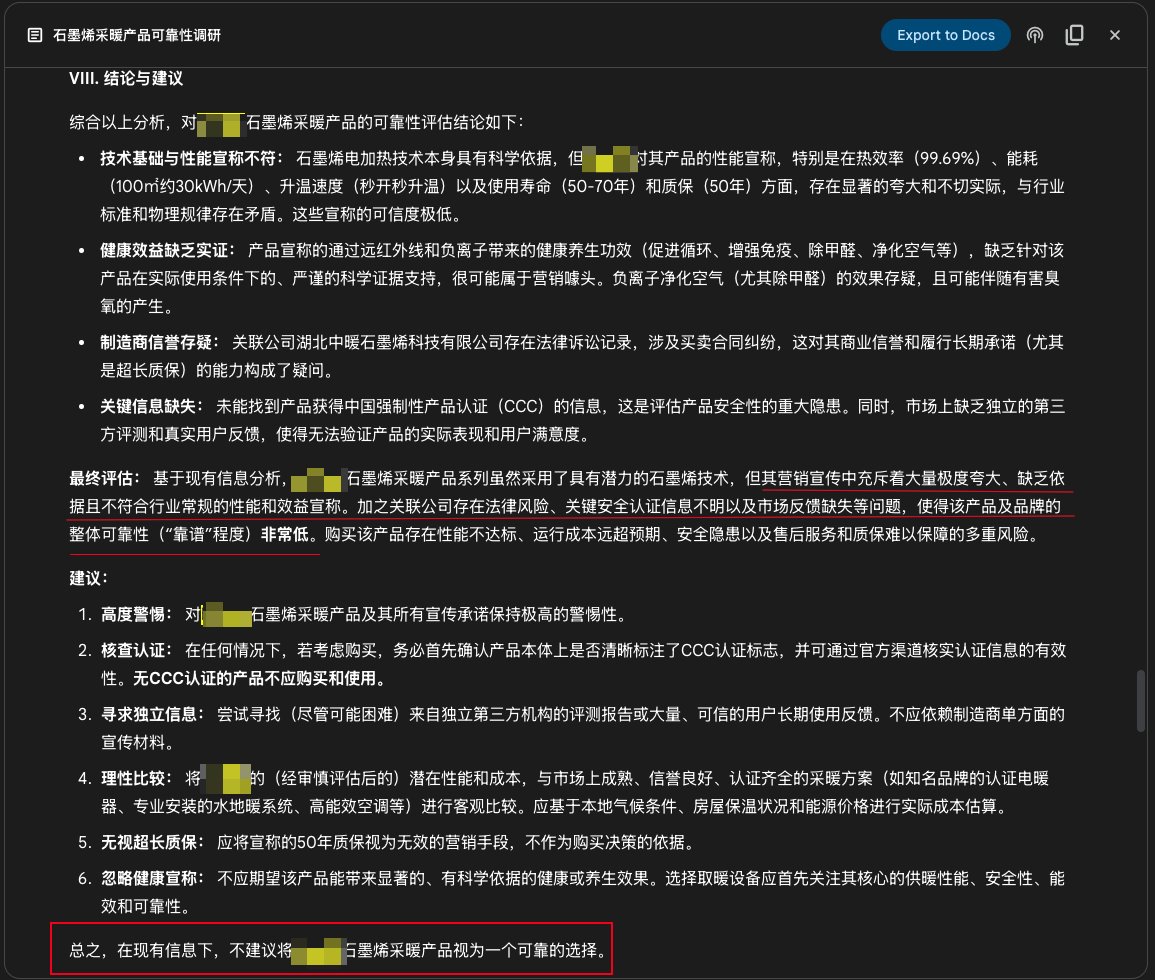
谷歌 Gemini Deep Research 功能用于产品调研: 用户分享了使用 Google Gemini 的 Deep Research 功能调研产品可靠性的案例。通过输入产品宣传介绍,Gemini 搜索了上百个网页后,明确指出某石墨烯采暖产品宣传夸大、缺乏依据、存在风险,不建议购买。这展示了 AI 深度研究工具在信息核实和消费决策辅助方面的实用价值 (来源: dotey)
AgentA/B:基于 LLM 代理的自动化 A/B 测试框架: AgentA/B 是一个全自动 A/B 测试框架,它使用大规模基于 LLM 的代理来替代真实用户流量。这些代理能在实际网页环境中模拟现实的、具有意图驱动的用户行为,从而实现更快、更便宜且无风险的用户体验(UX)评估,甚至可以在没有真实流量的情况下进行测试 (来源: elvis)
Qdrant 助力 Pariti 提升招聘效率: 招聘平台 Pariti 使用 Qdrant 向量数据库为其 AI 驱动的候选人匹配系统提供支持。通过 Qdrant 的实时向量搜索能力,Pariti 能在 40 毫秒内对 7 万份候选人资料进行排序和动态匹配度评分,将候选人审查时间缩短了 70%,招聘成功率翻倍,且 94% 的顶尖候选人出现在搜索结果前 10 名 (来源: qdrant_engine)

Qwen 3 与 LangGraph 等构建开源深度研究代理: Soham 开发并开源了一个深度研究代理。该代理使用 Qwen 3 模型,结合 Composio、LangChain 的 LangGraph、Together AI 以及 Perplexity/Tavily 进行搜索,据称其表现优于许多其他尝试过的开源模型。代码已开放,提供了一个可复现的研究自动化工具方案 (来源: Soham, hwchase17)
Perplexity on WhatsApp 提升移动端 AI 使用体验: Perplexity CEO Arav Srinivas 提到,在 WhatsApp 上使用 Perplexity AI 非常方便,尤其是在网络连接不佳的航班上。因为 WhatsApp 本身针对弱网络环境进行了优化,使得通过消息应用访问 AI 成为一种稳定可靠的方式,提升了 AI 在移动和特殊场景下的可用性 (来源: AravSrinivas)
Suno iOS 应用更新:支持生成可分享音乐片段: Suno AI 音乐生成应用的 iOS 版本更新,新增了将生成的歌曲转换为可分享片段的功能。用户可以选择 10 秒、20 秒或 30 秒的片段长度,并附带歌词和封面图或官方提供的可视化效果(未来将增加更多样式),方便用户在社交媒体上分享和展示 AI 创作的音乐 (来源: SunoMusic, SunoMusic)
AI 编程助手 Cursor 社区讨论: 用户 Andrew Carr 表达了对 AI 编程助手 Cursor 的好感。同时,Justin Halford 认为 Cursor 只是一个功能而非完整产品,易被大型模型公司的发布所取代。Cline 工具宣布支持 Cursor 的 .cursorrules 配置文件格式,显示了社区对其的关注和集成尝试 (来源: andrew_n_carr, Justin Halford, Celestial Vault)
OctoTools:灵活的 LLM 工具调用框架获 NALCL 最佳论文: OctoTools 框架在 KnowledgeNLP@NAACL 获得最佳论文奖。它是一个灵活易用的框架,通过模块化的“工具卡”(类似乐高积木)为 LLM 配备多样化的工具(如视觉理解、领域知识检索、数值推理等)以完成复杂推理任务。目前支持 OpenAI、Anthropic、DeepSeek、Gemini、Grok 和 Together AI 模型,并已发布 PyPI 包 (来源: lupantech)

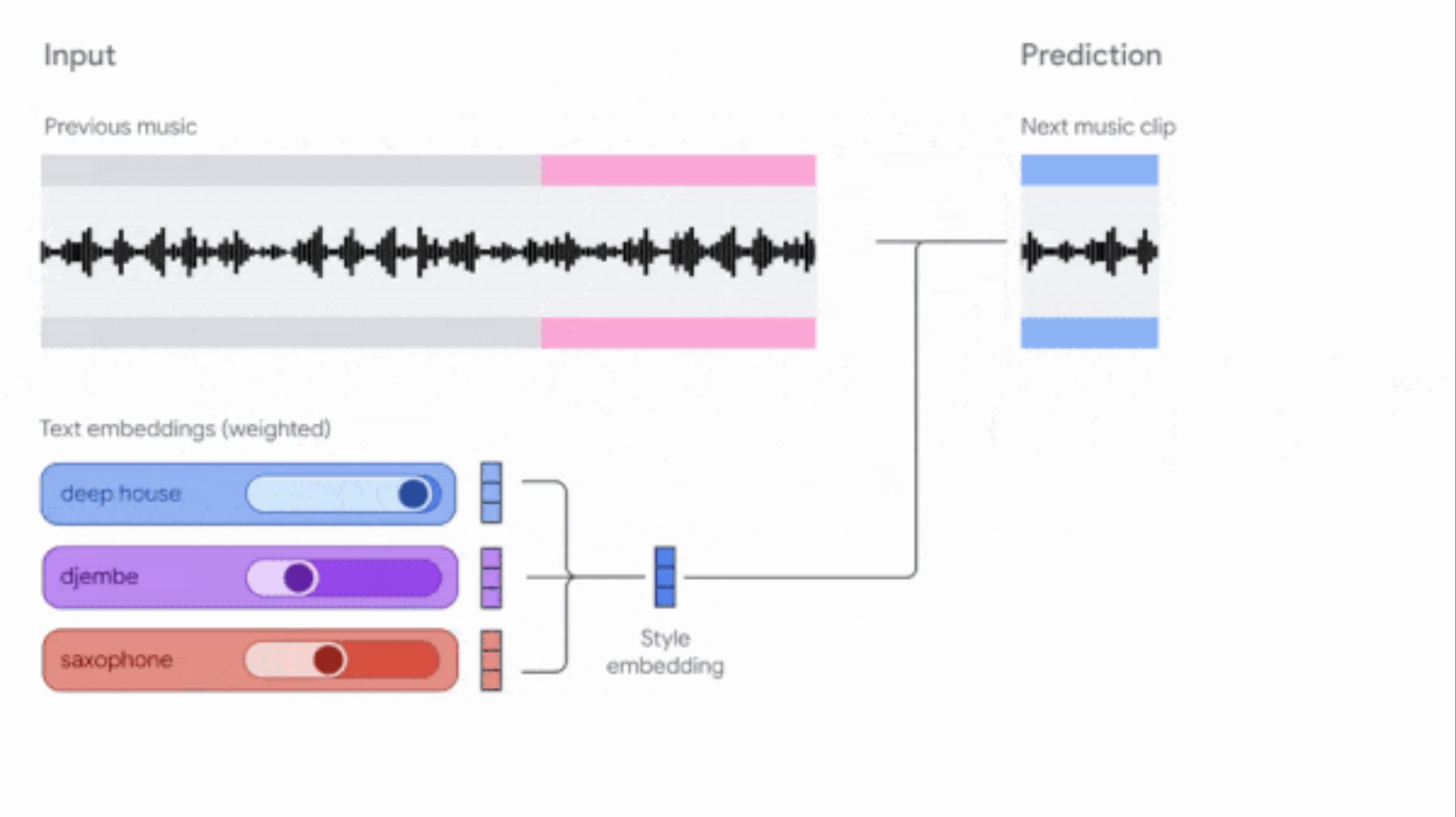
谷歌更新 Music AI Sandbox 和 MusicFX DJ 工具: 谷歌更新了其面向作曲家和制作人的音乐生成工具。Music AI Sandbox 现允许用户输入歌词生成完整歌曲;MusicFX DJ 则允许用户实时操控流媒体音乐。两者均基于升级后的 Lyria 模型(分别为 Lyria 2 和 Lyria RealTime),能生成 48kHz 高质量音频,并提供对调性、速度、乐器等的广泛控制。Music AI Sandbox 目前需通过等待列表申请使用 (来源: DeepLearningAI)
AI 驱动的代码审查代理: Composiohq、LlamaIndex 等工具结合 Grok 3 和 Replit Agent,构建了一个能审查 GitHub Pull Requests 的 AI 代理。流程包括:Grok 3 生成审查代理代码,Replit Agent 自动创建前端界面,用户通过界面提交 PR 链接,代理进行审查并提供反馈。这展示了 AI 代理在自动化软件开发流程(如代码审查)方面的潜力 (来源: LlamaIndex 🦙)
AI 生成填色页(带参考图): 用户分享了使用 AI 生成带有彩色参考小图的黑白填色页的经验和提示词。目标是解决孩子填色时不知如何配色的问题。提示词要求生成适合打印的清晰黑白轮廓线条稿,并在角落附带彩色小图作为参考,同时指定了风格、尺寸、适合年龄和画面内容 (来源: dotey)

使用 gpt-image-1 模型生成图像的代理代码示例: 用户分享了一段代码,展示了如何创建一个使用 gpt-image-1 模型生成图像的代理。这为开发者提供了一个快速实现图像生成功能的代码参考 (来源: skirano)
VectorVFS:将文件系统用作向量数据库: VectorVFS 是一个轻量级 Python 包和 CLI 工具,它利用 Linux VFS 的扩展属性(xattr)将向量嵌入直接存储到文件系统的 inode 中,从而将现有目录结构转变为一个高效且可语义搜索的嵌入存储库,无需维护单独的索引或外部数据库 (来源: Reddit r/MachineLearning)
AI 驱动的 Kubernetes 助手 kubectl-ai: Google Cloud Platform 发布了 kubectl-ai,这是一个 AI 驱动的 Kubernetes 命令行助手。它可以理解自然语言指令,执行相应的 kubectl 命令,并解释结果。支持 Gemini、Vertex AI、Azure OpenAI、OpenAI 以及本地运行的 Ollama 和 Llama.cpp 模型。项目还包含 k8s-bench 基准测试,用于评估不同 LLM 在 K8s 任务上的表现 (来源: GitHub Trending)

Higgsfield Effects:AI 驱动的电影级视觉特效包: Higgsfield AI 推出了 Higgsfield Effects,这是一个包含 10 种电影级视觉特效(VFX)的工具包,如雷神、隐形、金属化、着火等。用户可以通过单个提示词调用这些效果,旨在将复杂的 VFX 制作流程简化,使得普通用户也能轻松创建高影响力的视觉效果 (来源: Higgsfield AI 🧩)
Agent-S:模拟人类使用计算机的开放代理框架: Agent-S 是一个开源的代理框架,其目标是让 AI 像人类一样使用计算机。它可能包含理解用户意图、操作图形界面、使用各种应用程序等能力,旨在实现更通用和自主的 AI 代理行为 (来源: dl_weekly)
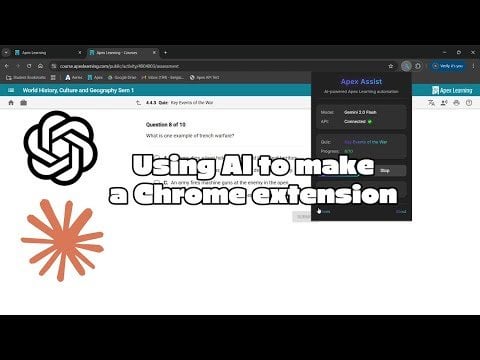
AI 生成 Chrome 扩展自动完成在线测验: 用户使用 Gemini AI 制作了一个 Chrome 扩展程序,可以自动完成特定在线学习平台的测验。这展示了 AI 在自动化重复性任务方面的应用潜力,但也可能引发关于学术诚信的讨论 (来源: Reddit r/ArtificialInteligence)
GPT-4o 图像生成:伦勃朗风格的名人肖像: 用户使用 GPT-4o 将多位知名电视剧主角(如 Walter White, Don Draper, Tony Soprano, SpongeBob 等)转化为伦勃朗绘画风格的肖像。这些图像展示了 AI 在理解人物特征和模仿特定艺术风格方面的能力 (来源: Reddit r/ChatGPT, Reddit r/ChatGPT)

Meta 发布 Llama Prompt Ops 工具包: Meta AI 发布了 Llama Prompt Ops,这是一个用于优化 Llama 模型提示词的 Python 工具包。该工具旨在帮助开发者更有效地设计和调整 Llama 模型的提示,以提升模型性能和输出质量 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)
用户寻求免费/低成本 Excel/表格生成 AI: Reddit 用户寻求能够生成 Excel 或 OpenOffice 电子表格文档的免费或低成本 AI 工具,希望能避免 ChatGPT 免费版的每日限制。社区推荐了 Claude、Google Gemini(配合 Sheets)以及本地部署开源模型(通过 LM Studio 或 LocalAI)等选项 (来源: Reddit r/artificial)
用户咨询 Claude 长上下文处理方法: Reddit 用户询问如何在 Claude 中处理复杂项目时绕过上下文长度限制和新聊天失忆的问题。社区建议的方法包括:将关键信息保存到项目文件中,或让 Claude 总结对话要点并将其带到新聊天中 (来源: Reddit r/ClaudeAI)
用户咨询 OpenWebUI 新功能使用方法: Reddit 用户询问 OpenWebUI v0.6.6 版本中新增的“会议录音与导入”功能以及笔记导入(Markdown)、OneDrive 集成等功能具体如何使用 (来源: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
用户咨询 OpenWebUI 处理大量 JSON 文件进行 RAG 的方法: Reddit 用户寻求在 OpenWebUI 中高效处理数千个 JSON 文件以进行 RAG 的最佳实践。考虑到直接上传到“知识库”可能效率低下,用户询问是否有推荐的外部向量数据库设置或自定义数据管道集成方法 (来源: Reddit r/OpenWebUI)
用户报告 OpenWebUI 与 n8n 集成超时问题: 用户在使用 OpenWebUI 作为 n8n AI 代理前端时遇到问题:当 n8n 工作流执行超过约 60 秒时,OpenWebUI 会显示错误,即使用户确认 n8n 后端已成功完成。用户寻求增加超时时间或保持连接的方法 (来源: Reddit r/OpenWebUI)
📚 学习
LangGraph 用于构建复杂 Agentic 系统: LangGraph 作为 LangChain 生态的一部分,专注于构建有状态的多 Actor 应用。Jacob Schottenstein 的演讲探讨了使用 LangGraph 将有向无环图(DAG)转换为有向循环图(DCG)来构建更强大的 Agent 系统。实际案例中,Cisco Outshift 利用 LangGraph 和 LangSmith 构建了 AI 平台工程师 JARVIS,显著提升了开发运维效率 (来源: Sydney Runkle, LangChainAI, hwchase17, Hacubu)
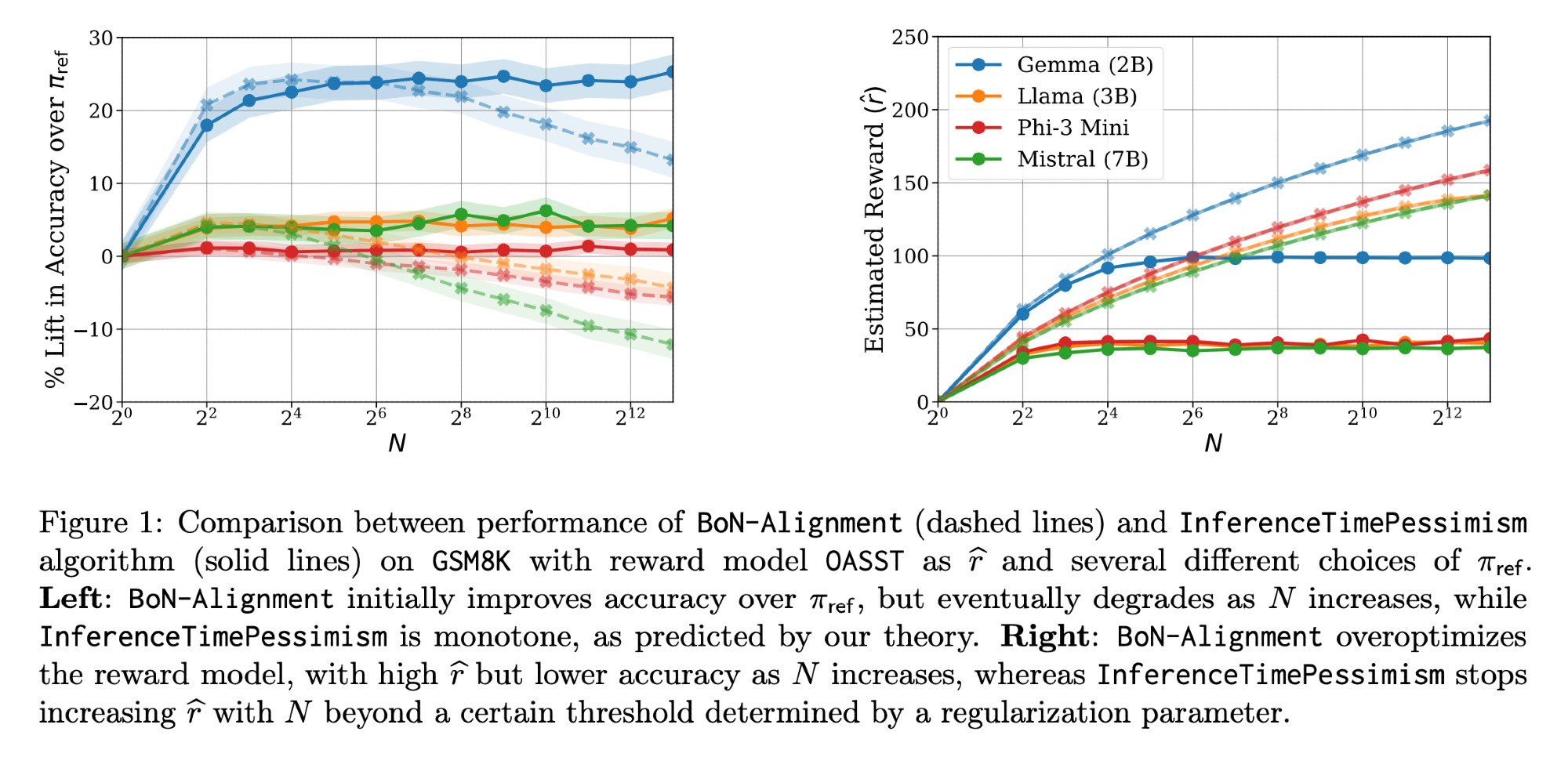
LLM 推理优化:Llama-Nemotron 论文与 InferenceTimePessimism: Meta AI & Nvidia Research 发布的 Llama-Nemotron 论文(arXiv:2505.00949v1)展示了一系列直接优化方法,用于在推理工作负载中保持质量的同时降低成本。同时,ICML ‘25 论文介绍了 InferenceTimePessimism 算法,作为 Best-of-N 推理方法的潜在改进,旨在利用额外信息优化推理过程 (来源: finbarrtimbers, Dylan Foster 🐢)
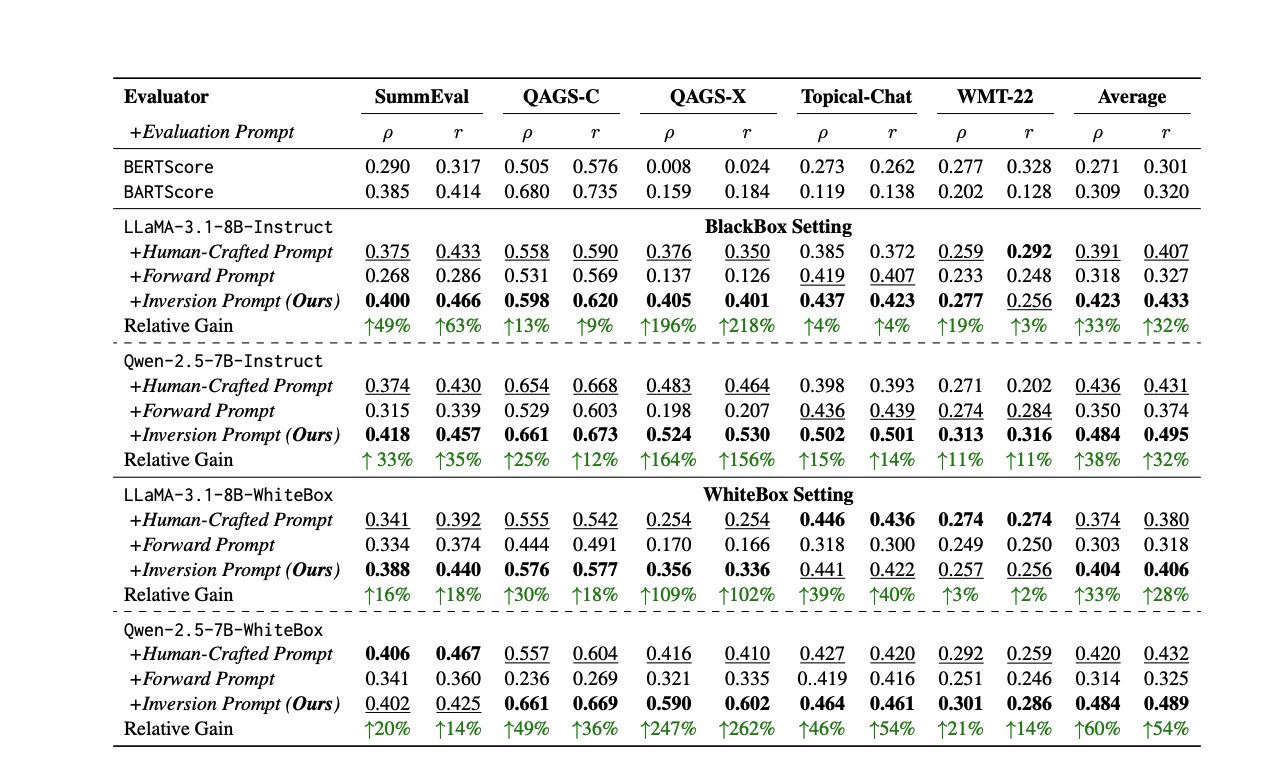
LLM 评估新方法与资源: 评估 LLM 性能是一个持续挑战。一篇论文提出通过反转响应来自动生成高质量评估提示的方法,以解决人工或 LLM 评委的不一致性。同时,LLM 评估专家 Shreya Shankar 开设了面向工程师和产品经理的 LLM 评估课程。此外,SciCode 基准测试作为 Kaggle 竞赛发布,挑战 AI 编写复杂物理和数学现象的代码 (来源: ben_burtenshaw, Aditya Parameswaran, Ofir Press)
AI 控制与对齐相关资源: AI 控制(研究如何安全监控和使用未达到超智能但可能未对齐的 AI)成为日益重要的领域。FAR.AI 发布了 ControlConf 会议的演讲视频,包含 Neel Nanda 等多位专家的见解。同时,一篇讨论价值观(区分终极价值与工具价值)的文章被认为与 AI 对齐讨论相关 (来源: FAR.AI, Séb Krier)

Common Crawl 发布新数据集: Common Crawl 发布了 2025 年 4 月的网页抓取存档。同时,Bram Vanroy 推出了 C5(Common Crawl Creative Commons Corpus),这是一个经过严格筛选、仅包含 CC 许可文档的 Common Crawl 子集,目前已收集 1500 亿 token,涵盖 8 种欧洲语言,为训练语言模型提供了新的合规数据源 (来源: CommonCrawl, Bram)
AI 学习活动与教程: 多项 AI 相关活动和教程资源发布:Qdrant 举办了关于使用 MCP 编排 AI 代理的在线编码会议;Corbtt 计划举办关于使用 RL 优化真实世界代理的网络研讨会;Comet ML 组织活动分享构建和生产化 GenAI 系统的见解;Ofir Press 将在 PyTorch 网络研讨会分享 SWE-bench 和 SWE-agent 的构建经验;Nous Research 联合多家机构举办 RL 环境黑客松;LlamaIndex 赞助特拉维夫 MCP 黑客松;Hugging Face 提供 1 分钟构建 MCP 服务器教程;Together AI 发布 Matryoshka 机器学习系列视频;Andrew Price 关于 AI 改变 3D 行业的演讲被再次推荐;giffmana 分享了 Transformer 讲座录像 (来源: qdrant_engine, Kyle Corbitt, dl_weekly, PyTorch, Nous Research, LlamaIndex 🦙, dylan, Zain, Cristóbal Valenzuela, Luis A. Leiva)

AI 理论与方法探讨: 社区讨论了 AI 领域的一些基础理论和方法:1. 探讨了“世界模型”(World Models)的概念、解决的问题、技术架构和挑战。2. 讨论了傅立叶特征/谱方法在深度学习中未能广泛应用的原因。3. 提出了“Serenity Framework”概念框架,整合五大意识理论探索 AI 的递归自意识。4. 讨论了 AI 是否过度依赖预训练模型。5. 探讨了 LLM 缩减(Downscaling)的重要性 (来源: Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/artificial, Reddit r/MachineLearning, Natural Language Processing Papers)

提示工程与模型优化资源: LiorOnAI 分享了 OpenAI 总裁 Greg Brockman 关于构建完美提示的框架。Modal 提供了使用 TensorRT-LLM、FP8 量化和推测解码等技术以低于 250ms 延迟服务 LLaMA 3 8B 的教程。N8 Programs 分享了在低显存(64GB RAM)条件下,使用 6bit 量化模型作为教师、4bit 模型作为学生进行训练的经验。Kling_ai 转发了包含 Midjourney v7、Kling 2.0 等工具提示词的资源帖 (来源: LiorOnAI, Modal, N8 Programs, TechHalla)

AI 在教育领域的应用与研究: 斯坦福大学计算机科学博士 Rose 的博士论文聚焦于利用 AI 方法、评估和干预来改善教育。这代表了 AI 在教育领域应用的深入研究方向 (来源: Rose)

Vibe-coding:一种新兴的 AI 辅助编程方式: YC 播客采访 Windsurf CEO 的笔记中提到了“Vibe-coding”的概念。这可能是一种更注重直觉、氛围和快速迭代,并深度融合 AI 辅助的编程范式,暗示了 AI 对软件开发流程和理念的潜在改变 (来源: Reddit r/ArtificialInteligence)
英伟达 CUDA 升级路径信息: Phoronix 文章讨论了 Volta 架构之后 Nvidia CUDA 的升级路径,这对于拥有旧款 Nvidia GPU(如 10xx 系列)并希望继续用于 AI 开发的用户具有参考价值 (来源: NerdyRodent)
💼 商业
CoreWeave 完成对 Weights & Biases 的收购: AI 云平台 CoreWeave 正式完成对 MLOps 平台 Weights & Biases (W&B) 的收购。此次收购旨在将 CoreWeave 的高性能 AI 云基础设施与 W&B 的开发者工具相结合,打造下一代 AI 云平台,帮助团队更快地构建、部署和迭代 AI 应用 (来源: weights_biases, Chen Goldberg)

Figure AI 机器人在宝马工厂进行测试优化: 人形机器人公司 Figure AI 的团队在宝马集团斯帕坦堡工厂进行了为期两周的访问,优化了其机器人在 X3 车身车间的流程,并探索了新的应用场景。这标志着双方在 2025 年的合作进入实质性阶段,展示了人形机器人在汽车制造领域的应用潜力 (来源: adcock_brett)

Reborn 与宇树科技达成战略合作: AI 公司 Reborn 宣布与机器人公司宇树科技(Unitree Robotics)建立战略合作伙伴关系。双方将在数据、模型和人形机器人领域展开合作,共同目标是加速相关技术的发展 (来源: Reborn)

🌟 社区
巴菲特对 AI 的审慎观点引发讨论: 在 2025 年股东大会上,巴菲特表达了对 AI 的“冷静观望”和“有限应用”态度。他强调 AI 无法替代复杂决策中的人类判断力(以保险业务负责人 Ajit Jain 为例),伯克希尔将 AI 视为提升现有业务效率的工具,而非投资纯算法公司。他认为 AI 领域存在泡沫,需等待技术证明长期盈利能力。这引发了关于“AI+行业”与“行业+AI”模式价值的讨论 (来源: 36氪)
Anthropic CEO 承认对 AI 工作原理缺乏理解: Anthropic CEO Dario Amodei 承认,目前对大型 AI 模型(如 LLM)的内部工作原理缺乏深入理解,称这种情况在技术史上是“前所未有的”。这一坦诚发言再次凸显了 AI 的“黑箱问题”,引发了社区对于 AI 可解释性、可控性和安全性的广泛讨论和担忧 (来源: Reddit r/ArtificialInteligence)

OpenAI 发布非前沿开源模型的计划及其争议: OpenAI CPO Kevin Weil 表示,公司正准备发布一个基于民主价值观构建的开源权重模型,但该模型将有意落后于前沿模型一代,以避免加速竞争对手(如中国)的发展。此策略引发社区激烈讨论,批评者认为这一定位自相矛盾:既无法成为“世界最好”的开源模型(需与 DeepSeek-R2 等前沿模型竞争),又可能因性能落后而变得无用,同时可能蚕食 OpenAI 自身的中低端 API 收入,是“双输”局面 (来源: Haider., scaling01)
AI 驱动的自动化与未来工作形态讨论: Fiverr CEO 认为 AI 将淘汰“简单任务”,使“困难任务”变简单,“不可能任务”变困难,强调从业者需成为领域大师才能避免被淘汰。社区讨论 AI 是否会取代所有工作,以及由此可能产生的社会结构变化(经济崩溃或 UBI 乌托邦)。同时,AI 在软件开发中的应用日益普遍,甚至成为主要的代码贡献者,引发对未来开发模式的思考 (来源: Emm | scenario.com, Reddit r/ArtificialInteligence, mike)
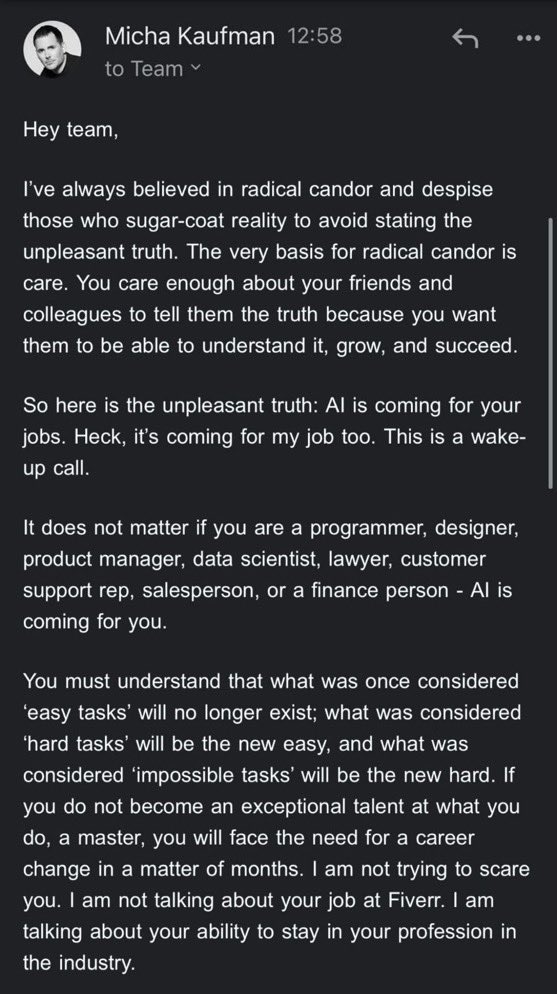
AI 安全与风险讨论持续升温: 谷歌 DeepMind CEO Demis Hassabis 警告 AGI 可能在 5-10 年内到来,但社会尚未准备好应对其变革性影响,呼吁积极的全球合作。同时,一场关于 AI 灾难风险的有意义对话在风险担忧者 Ajeya Cotra 和怀疑论者 random_walker 之间展开,双方努力理解对方观点并识别分歧关键点。社区也开始讨论 AI 控制问题,关注如何安全监控和使用强 AI 系统 (来源: Chubby♨️, dylan matthews 🔸, random_walker, FAR.AI, zacharynado)
AI 在日常生活和人际关系中的应用与影响: 用户分享使用 AI (Anthropic Sonnet) 辅助约会软件回复并提高成功率的经历,并畅想“关系 Cursor”的可能性。同时,也有文章指出 AI 正在助长一些人的精神幻想,导致其与现实亲友疏远。这反映了 AI 在情感、社交领域的渗透及其带来的机遇与潜在风险 (来源: arankomatsuzaki, Reddit r/artificial)

LLM 使用体验与模型对比讨论: 用户反馈 Gemini 2.5 Pro 对自身文件上传能力存在困惑,甚至无法上传文件,怀疑是付费功能限制。同时,有用户家人反馈更偏好使用 Gemini 而非 ChatGPT。另一用户则称赞 Claude 在生成书面内容方面优于其他 LLM,认为其回答更自然、更像真正的文章而非简单的任务完成。这些讨论反映了用户在实际使用中遇到的问题、偏好差异以及对不同模型能力的直观感受 (来源: seo_leaders, agihippo, Reddit r/ClaudeAI, seo_leaders)

AI 伦理与社会规范探讨: 讨论涉及 AI 在药物研发中的应用及其伦理考量,以及反 AI 人士对此的态度。同时,有评论认为 AI 实时翻译的普及可能让人怀念过去跨语言交流的“挣扎感”所带来的连接。还有关于宠物翻译 AI 的讨论,认为人们喜欢宠物的部分原因在于可以投射情感,而真实的 AI 翻译可能只会反馈“饿了”和“想交配” (来源: Reddit r/ArtificialInteligence, jxmnop, menhguin)
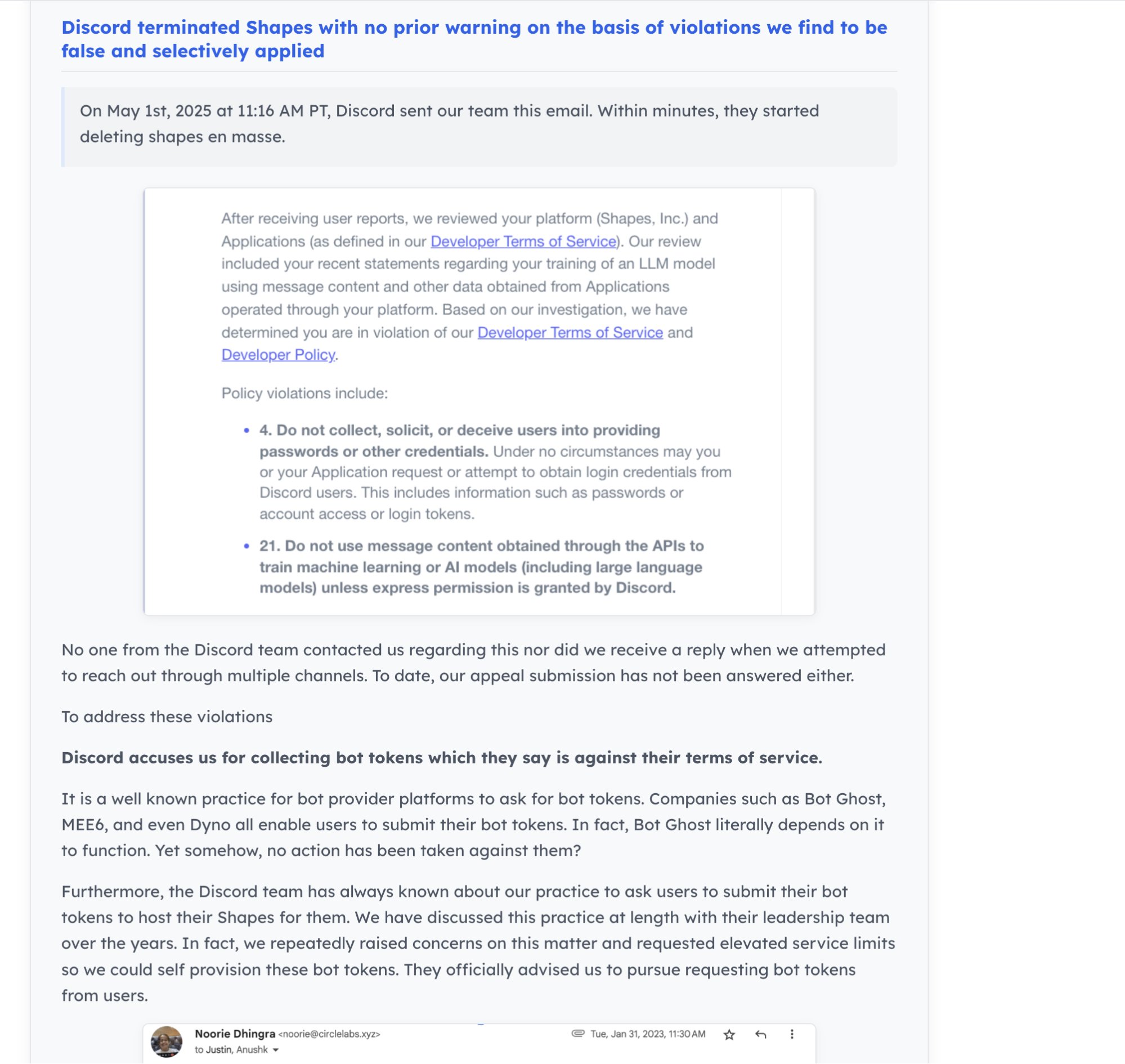
AI 社区动态与开发者生态: Discord 关闭拥有 3000 万用户的 AI Bot “Shapes”,引发开发者对平台风险的担忧。同时,有观点认为对 AI 创业公司而言,在开源项目贡献比刷 LeetCode更能证明能力,更容易获得工作机会。Nous Research 联合 XAI、Nvidia 等举办 RL 环境黑客松,旨在推动 RL 环境开发 (来源: shapes inc, pash, Nous Research)
ChatGPT 行为异常:陷入“Boethius”循环: 用户报告在询问“第一位作曲家是谁”时,ChatGPT-4o 表现异常,反复提及 Boethius(一位音乐理论家而非作曲家),甚至在后续对话中“道歉”并开玩笑说 Boethius 像“幽灵”一样缠着回答。这一有趣的“故障”展示了 LLM 可能出现的意外行为模式和潜在的内部状态混乱 (来源: Reddit r/ChatGPT)

关于 AI 未来发展阶段的思考: 社区提问:如果当前 AI 发展处于“大型机”(mainframe)阶段,那么未来的“微处理器”(microprocessor)阶段会是什么样子?这个问题引发了对 AI 技术演进路径、普及形式以及未来可能出现的更小型化、更个人化、更嵌入式的 AI 形态的畅想 (来源: keysmashbandit)
AI 生成内容的风格与识别: 用户观察到 AI 生成的文本(尤其是 GPT 类模型)常常使用一些固定短语和句式(如“significant implications for…”等),使其易于识别。同时,AI 生成的语音虽然音质提升,但在结构、节奏和停顿上仍显生硬。这引发了关于 LLM 输出的“模式化”和自然度问题的讨论 (来源: Reddit r/ArtificialInteligence)
对 Perplexity AI 设计的认可: 用户 jxmnop 认为 Perplexity AI 似乎将资源更多地投入到设计而非自研模型上,但其产品体验(vibes)感觉不错。这反映了 AI 产品竞争中,除了核心模型能力外,用户界面和交互设计也是重要的差异化因素 (来源: jxmnop)

AI 在非工作场景的趣味应用: Reddit 用户征集 AI 在非工作场景的有趣或奇怪用途。例子包括:用荣格和弗洛伊德视角分析梦境、咖啡杯占卜、根据冰箱随机食材制定食谱、听 AI 读睡前故事、总结法律文件等。这展示了用户探索 AI 应用边界的创造力 (来源: Reddit r/ArtificialInteligence)
用户寻求 48GB VRAM 最佳 LLM: Reddit 用户寻求在 48GB VRAM 条件下,兼顾知识量和可用速度(>10t/s)的最佳 LLM。讨论中提到了 Deepcogito 70B (Llama 3.3 微调)、Qwen3 32B,并有建议尝试 Nemotron、YiXin-Distill-Qwen-72B、GLM-4、量化的 Mistral Large、Command R+、Gemma 3 27B 或部分卸载的 Qwen3-235B 等。这反映了用户在特定硬件约束下选择和优化模型的实际需求 (来源: Reddit r/LocalLLaMA)
💡 其他
机器人技术进展: 领域内持续有新动态:1. PIPE-i:Beca Group 推出用于管道等基础设施检查的机器人勘测车。2. 开源人形机器人:加州大学伯克利分校推出开源人形机器人项目。3. Hugging Face 机械臂:Hugging Face 发布 3D 打印机械臂项目。4. 可食用机器人蛋糕:研究人员制作出可以食用的机器人蛋糕。5. 下水道无人机:用于检查下水道的无人机出现,代替人工完成肮脏工作 (来源: Ronald_vanLoon, TheRundownAI)

AI 监管讨论:SB-1047 法案纪录片发布: Michaël Trazzi 发布了关于加州 AI 安全法案 SB-1047 辩论幕后故事的纪录片。该法案旨在对前沿 AI 开发施加最低限度的监管,但最终未能通过。纪录片探讨了法案失败的原因,尽管有大量加州民众支持,引发了对 AI 监管路径和挑战的进一步思考 (来源: Michaël Trazzi, menhguin, NeelNanda5, JeffLadish)
量子计算与 AI 的结合: Nvidia 正在通过将量子硬件与 AI 超级计算机集成,为实用量子计算铺平道路,重点关注纠错和加速从实验到实际应用的过渡。同时,有观点认为量子计算可能更多地带来科学繁荣,而非仅仅是网络安全领域的颠覆 (来源: Ronald_vanLoon, NVIDIA HPC Developer)
