
关键词:Anthropic, Claude 3.5 Haiku, Qwen3, Phi-4-reasoning, LLM物理学, LangGraph, AI Agent, 电路追踪方法Attribution Graphs, Qwen3-235B-A22B编码能力, Phi-4-reasoning推理时计算, LangGraph发票核对Agent, Moondream Station本地VLM
🔥 聚焦
Anthropic发布LLM生物学研究,深入探究模型内部机制: Anthropic发布了题为《大型语言模型的生物学》(On the Biology of a Large Language Model)的深入研究博客文章,使用其电路追踪方法(Attribution Graphs)调查了Claude 3.5 Haiku模型在不同情境下的内部机制。研究通过训练一个更易于分析的“替代模型”(Transcoder),揭示了模型如何执行加法(通过多种近似路径而非精确算法)、进行医学诊断(形成内部诊断概念)以及处理幻觉和拒绝(存在默认拒绝电路,可被“已知答案”特征抑制)。该研究为了解LLM内部运作提供了新视角,但也引发了关于方法论局限性以及Anthropic自身定位的讨论 (来源: YouTube – Yannic Kilcher
)

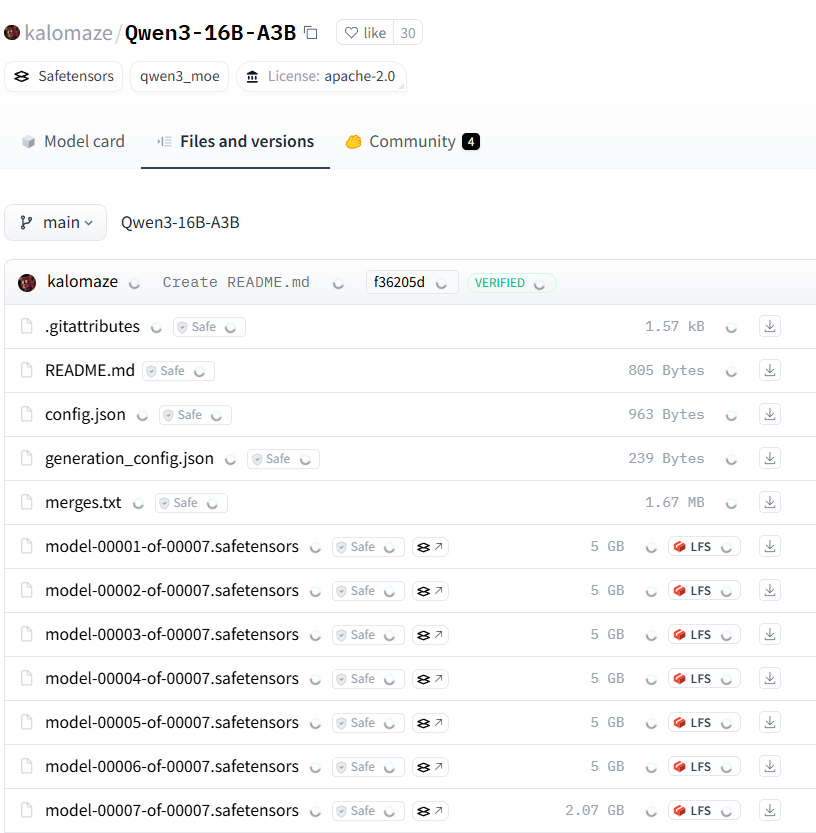
Qwen3系列模型展现强大性能,引发开源社区关注: 阿里巴巴发布的Qwen3系列大型语言模型在多个基准测试中表现出色,尤其是在编码能力方面。Aider Polyglot Coding Benchmark结果显示,Qwen3-235B-A22B(未启用思维链)的性能似乎优于启用32k思维链token的Claude 3.7,且成本大幅降低。同时,Qwen3-32B在该基准测试中也超越了GPT-4.5和GPT-4o。社区还积极探索Qwen3模型的剪枝(如将30B剪至16B)和微调(如使用Unsloth在低显存下微调),进一步降低了高性能模型的应用门槛,预示着中国开源大模型可能在市场上占据重要地位 (来源: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
微软发布Phi-4-reasoning模型,专注复杂推理: 微软在Hugging Face上发布了Phi-4-reasoning模型,这是一个拥有140亿参数的推理模型。该模型通过利用推理时计算(inference-time compute)的方式,在复杂推理任务上达到了当前最佳(SOTA)性能。这表明模型设计正探索通过增加推理阶段的计算量来提升特定能力,而不是仅仅依赖于扩大模型规模,为小型模型实现高性能提供了新的思路 (来源: _akhaliq)
LLM物理学研究新进展:架构设计的“伽利略时刻”: Zeyuan Allen-Zhu发布了关于大型语言模型物理学的系列研究第四部分,重点关注架构设计。研究通过受控的合成预训练环境,揭示了不同LLM架构(如Transformer、Mamba)的真实局限和潜力。研究引入了名为“Canon”的轻量级水平残差层,显著提升了模型的推理能力。同时,研究发现Mamba模型的优势很大程度来自其隐藏的conv1d层,而非SSM本身。这一系列实验为理解和优化LLM架构提供了新的视角和基础理论 (来源: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 动向
亚马逊发布通用人工智能模型”Amazon Artificial General Intelligence”: 该模型具有100万token上下文长度和多模态输入能力,优化了代码生成、RAG、视频/文档理解、函数调用和Agent交互。定价为输入2.5美元/百万token,输出12.5美元/百万token。初步评估显示,其在AI Index上的表现与Llama-4 Scout相当,但在速度和成本上处于劣势,可能适用于特定的长上下文多模态或Agent应用场景 (来源: scaling01)

Anthropic Claude模型现已在全球付费计划中提供网页搜索功能: 该功能允许Claude在处理日常任务时进行快速搜索,对于更复杂的问题,则会探索包括Google Workspace在内的多个来源。这增强了Claude获取实时信息和处理需要外部知识的任务的能力 (来源: menhguin)

IBM发布混合架构模型granite-4.0-tiny-7B-A1B-preview: 该7B模型预览版采用了Mamba-2与Transformer的混合架构,每个Transformer块包含9个Mamba块。设计思路是利用Mamba块捕捉全局上下文,并将其传递给注意力层进行局部上下文解析。初步MMLU分数表现不错,但其他如数学和编程能力的测试结果尚未公布 (来源: karminski3)
OpenAI ChatGPT增加购物功能: OpenAI正在试验ChatGPT中的购物功能,旨在简化产品查找、比较和购买流程。新功能包括改进的产品结果展示、包含价格和评论的视觉化产品细节,以及直接购买链接。OpenAI强调产品结果是独立选择的,并非广告 (来源: sama)
Qwen3 0.6B模型训练细节引发关注: 用户Dorialexander指出,根据信息,Qwen 0.6B模型似乎也使用了高达36T tokens进行训练。如果属实,这将创下超Chinchilla定律的新纪录(约每个参数对应6万个token),显示出通过极大增加训练数据量来提升小模型能力的趋势 (来源: Dorialexander)

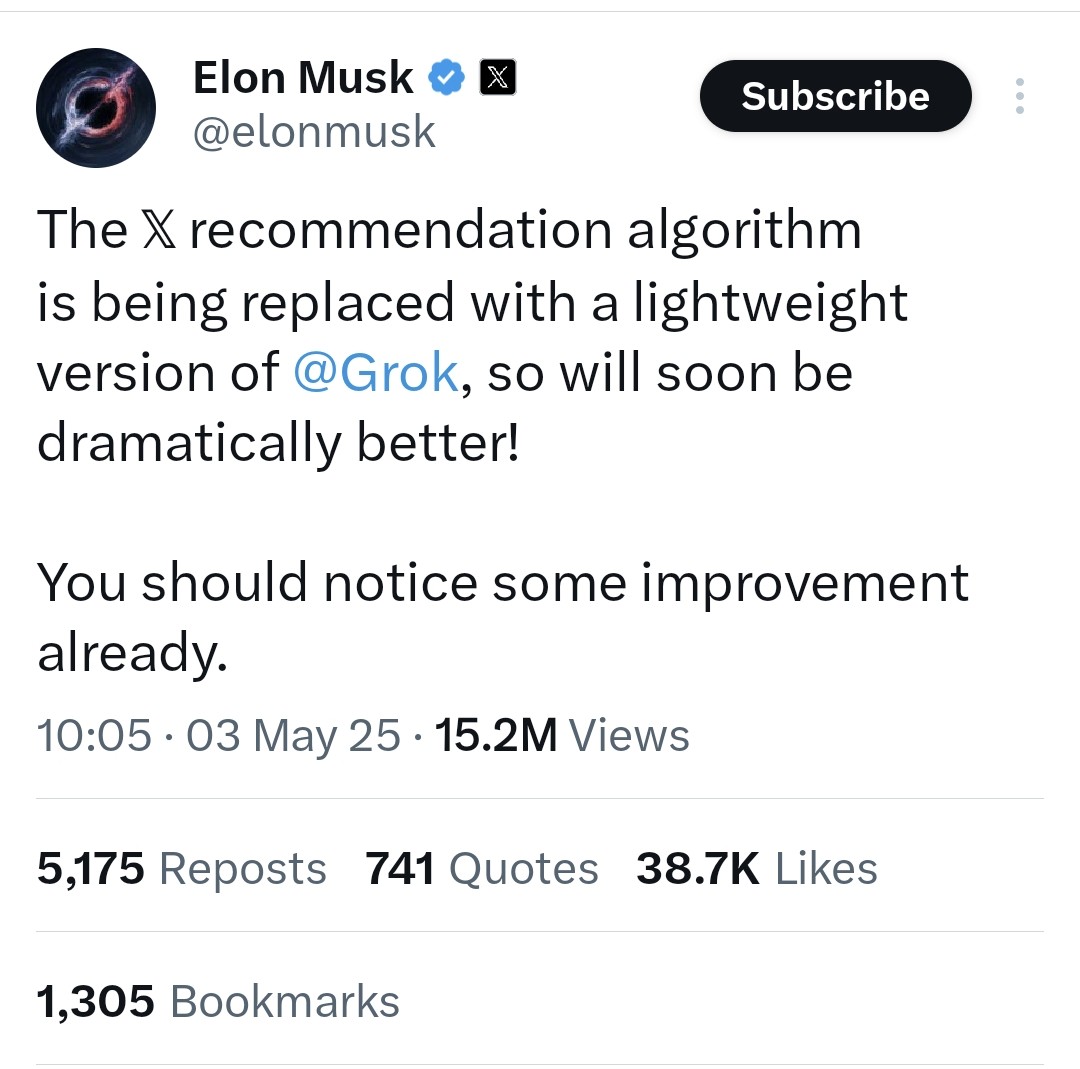
X (推特) 推荐算法将替换为轻量版Grok: Elon Musk宣布,X平台的推荐算法正在被替换为Grok的一个轻量级版本,预计将显著改善推荐效果。用户反馈算法效果提升,推测可能与近期Exa AI员工变动以及X开始使用Embeddings进行推荐有关 (来源: menhguin, colin_fraser, paul_cal)
Allen AI发布全开放MoE模型OLMoE: 该模型是一个先进的混合专家(Mixture of Experts)模型,拥有13亿活跃参数和69亿总参数。完全开源意味着社区可以自由使用、修改和研究该模型,推动MoE架构的发展和应用 (来源: dl_weekly)
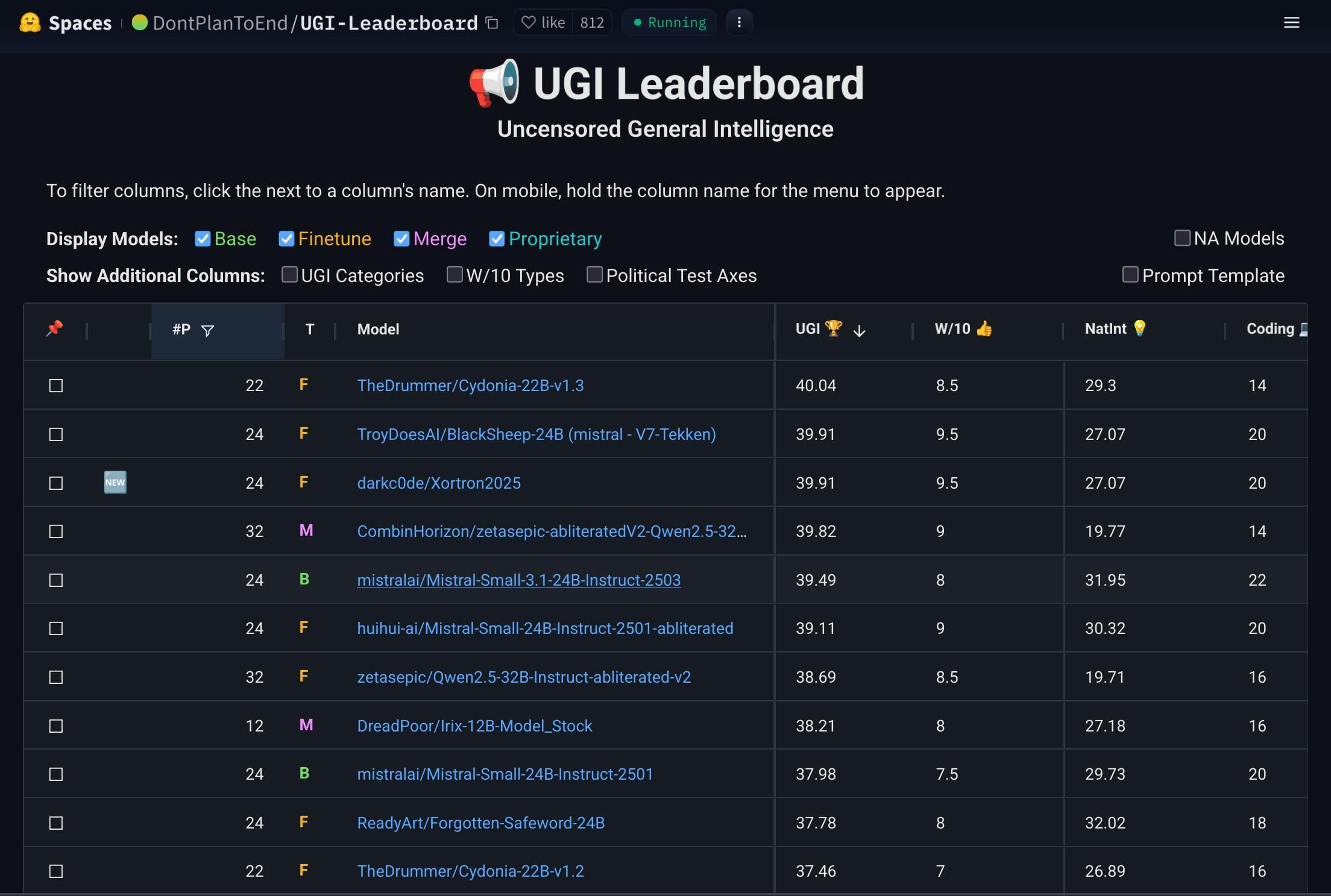
Mistral-Small-3.1-24B-Instruct-2503模型受关注: Reddit用户讨论Mistral-Small-3.1-24B-Instruct-2503模型,该模型在UGI(Uncensored General Intelligence)评分较高,且在自然语言理解和编码方面表现优于同类高分模型。用户认为其可能是单GPU无审查推理的理想选择,并支持工具使用。但也指出其写作风格可能较为枯燥重复,创意性不如Gemma 3等模型 (来源: Reddit r/LocalLLaMA)
🧰 工具
CreateMVP 2.0发布,优化AI驱动开发流程: CreateMVP更新至2.0版本,旨在解决直接提示AI构建应用效果不佳的问题。新版本通过提供更流畅的UI、便捷的认证方式(支持Replit、Google、GitHub,即将支持XAI)、生成更详细的开发计划(从11KB增至40KB+)、即时预览文件和集成顶级AI模型聊天等功能,帮助用户为AI创建更精确的“蓝图”,确保AI构建出符合用户设想的应用 (来源: amasad)
LlamaIndex推出发票核对Agent: 该工具展示了AI Agent在批量自动化任务中的应用,而非传统的聊天交互。它可以处理大量非结构化发票文档,提取相关细节,自动与采购订单匹配并标记差异。其核心是基于LlamaCloud解析/提取和LlamaIndex.TS工作流推理的Agentic文档智能层,展示了Agent在实际业务流程自动化中的潜力,并被认为将取代传统RPA (来源: jerryjliu0)
LangGraph Expense Tracker:自动化费用管理系统: 这是一个使用LangGraph构建的自动化费用管理系统示例。它能够处理发票,利用智能数据提取功能,将信息存储在PostgreSQL中,并包含人工验证环节。该项目展示了LangGraph在构建实际业务自动化流程方面的能力 (来源: LangChainAI, Hacubu, hwchase17)
Moondream Station发布:本地运行VLM: Moondream发布了Moondream Station,允许用户在Mac本地运行视觉语言模型(VLM)Moondream,无需连接云端。提供CLI或本地端口访问方式,设置简单且完全免费,降低了本地部署和使用VLM的门槛 (来源: vikhyatk)
ChaiGenie:基于LangChain的Chrome文档搜索扩展: ChaiGenie是一个Chrome扩展,集成了LangChain的Gemini和Qdrant,用于提供文档搜索功能。它支持多语言和基于向量的检索,旨在提升用户在浏览网页时查找和理解文档内容的效率 (来源: LangChainAI)

Research Agent:一键式研究助手Web应用: 这是一个基于LangGraph的研究助手框架构建的Web应用程序,旨在简化研究流程。用户只需点击一下即可获得研究结果,展示了LangGraph在构建AI驱动工作流以简化复杂任务方面的应用潜力 (来源: LangChainAI)

Muyan-TTS:开源、低延迟、可定制的TTS模型: ChatPods团队发布了Muyan-TTS,一个完全开源的文本转语音模型,旨在解决现有开源TTS模型质量不高或不够开放的问题。它基于LLaMA-3.2-3B和优化的SoVITS,支持零样本TTS和语音克隆,并提供了完整的训练和数据处理流程,方便开发者进行微调和二次开发,特别适合需要定制化语音的应用场景 (来源: Reddit r/MachineLearning)
Mem0与Open Web UI管道集成: 用户cloudsbird创建了Mem0的Open Web UI过滤器管道集成(非官方MCP),为在Open Web UI中使用Mem0记忆功能提供了另一种选择 (来源: Reddit r/OpenWebUI)
YNAB API Request工具实现本地私有化财务管理: 用户Megaphonix创建了一个OpenWebUI工具,利用YNAB(You Need A Budget)API,允许用户在本地通过LLM查询个人财务信息(如交易、类别支出、净资产等),而无需将敏感数据发送到外部。这解决了在本地运行LLM时安全处理敏感个人信息的需求 (来源: Reddit r/OpenWebUI)
免费AI文字转语音浏览器扩展GPT-Reader: 开发者推广其创建的免费AI文本转语音浏览器扩展GPT-Reader,目前已有超过4000用户。该工具旨在方便用户将网页文本内容转换为语音收听 (来源: Reddit r/artificial)
sunnypilot:开源驾驶辅助系统: sunnypilot是comma.ai openpilot的一个分支,提供开源的驾驶辅助系统。它支持超过300种车型,修改了驾驶辅助的交互行为,并尽可能遵守comma.ai的安全策略。该项目利用AI技术(虽然未明确说明具体模型,但此类系统通常涉及计算机视觉和控制算法)提升驾驶体验 (来源: GitHub Trending)

📚 学习
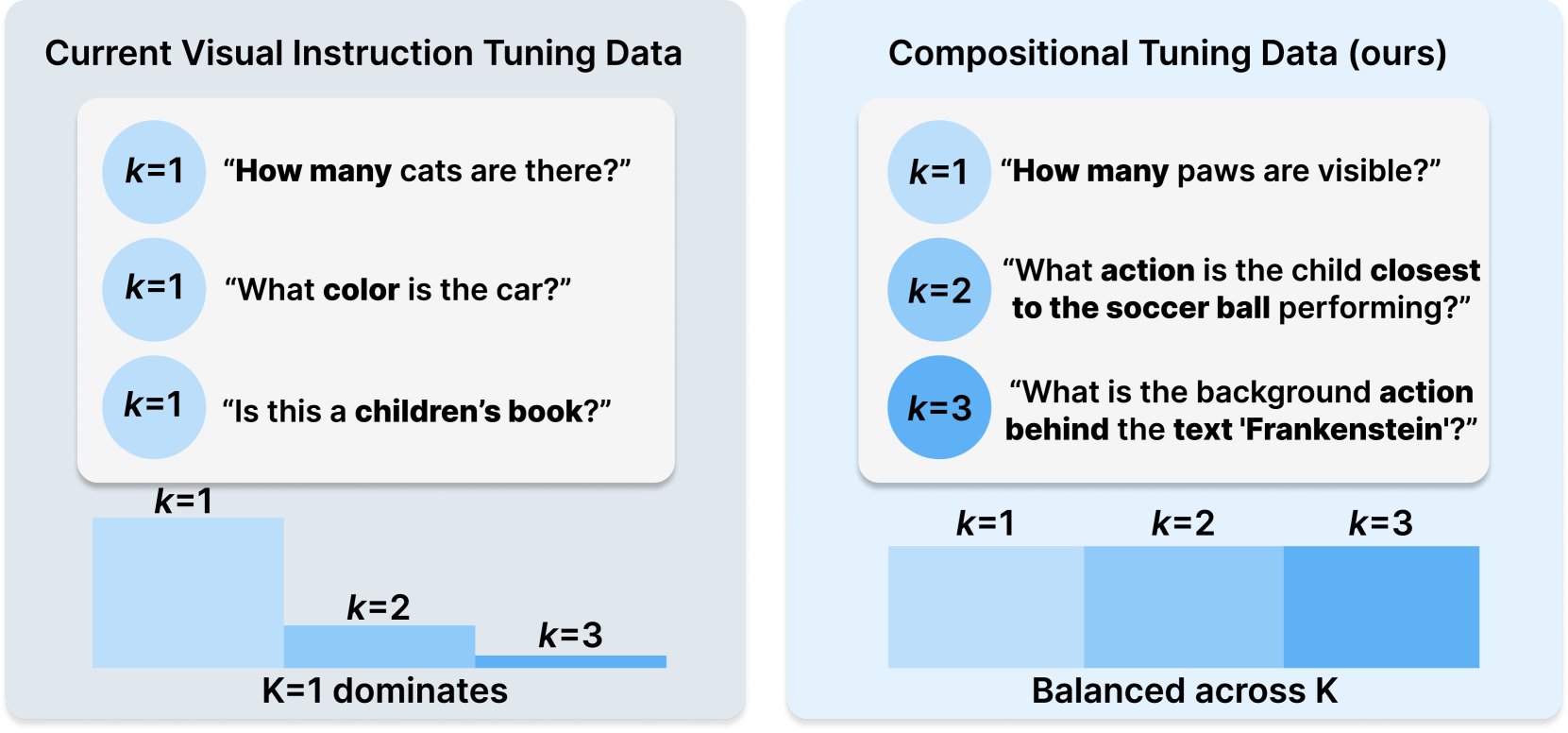
Princeton与Meta AI发布COMPACT数据集配方: 该研究发布在Hugging Face上,提出了一种新的数据配方COMPACT,旨在通过显式控制训练样本的组合复杂性来扩展多模态大型语言模型(Multimodal LLM)的能力。这为改进多模态模型的训练方法和提升其理解复杂组合概念的能力提供了新思路 (来源: _akhaliq)
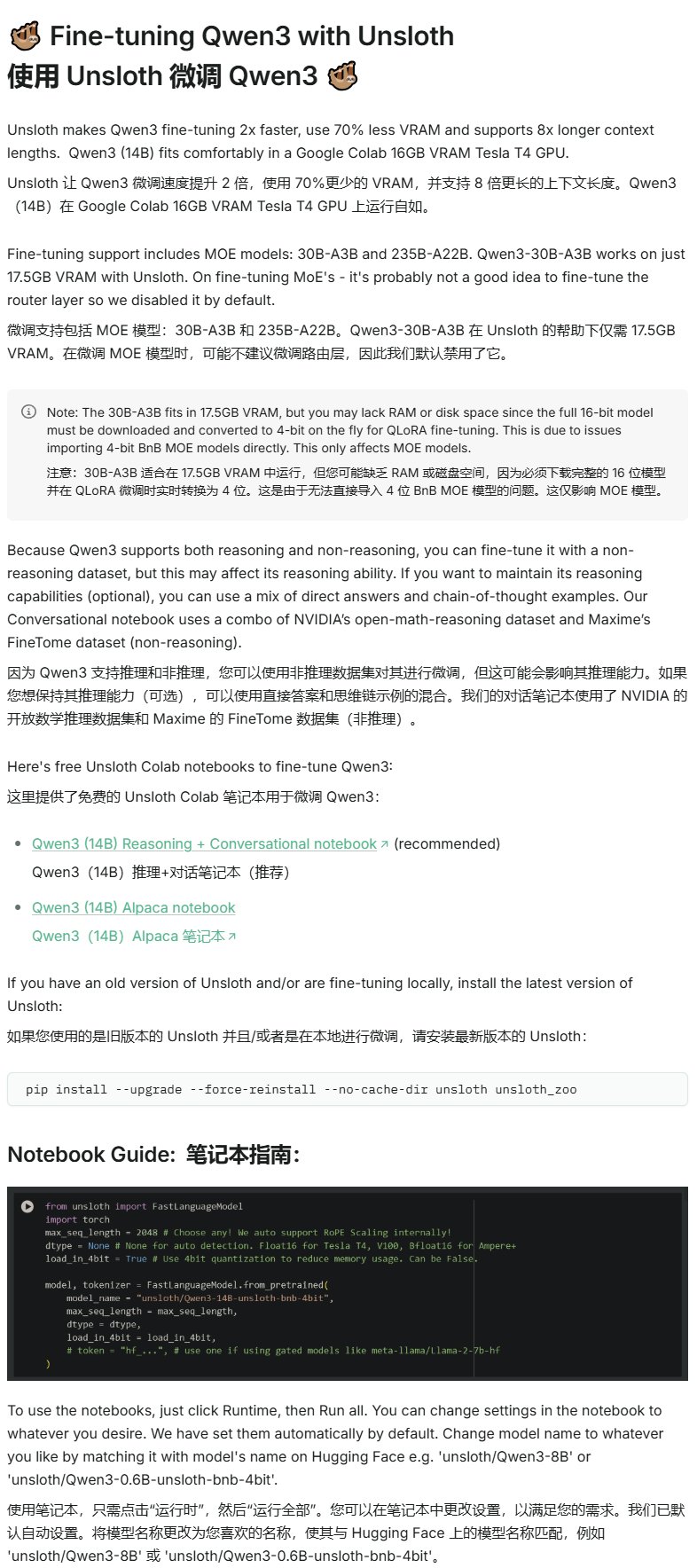
Unsloth发布Qwen3微调教程: Unsloth提供了针对Qwen3模型的微调教程,显著降低了微调门槛。用户仅需16GB显存即可微调Qwen3-14B模型,17.5GB显存即可微调Qwen3-30B-A3B模型。这使得更多研究者和开发者能够在有限的硬件资源下对先进的开源模型进行定制化训练 (来源: karminski3)
LangGraph结合Azure OpenAI构建智能Web搜索聊天机器人: 一篇Medium教程展示了如何结合使用LangGraph和Azure OpenAI,并集成Tavily的网络搜索能力,来构建一个智能聊天机器人。教程涵盖了状态管理和条件路由,以实现无缝的搜索集成,为构建更强大的、能利用实时网络信息的AI应用提供了实践指导 (来源: LangChainAI, hwchase17)

斯坦福AI博客探讨LLM的逐字记忆与通用能力关系: 一篇斯坦福AI博客文章深入探讨了大型语言模型(LLM)的逐字记忆(verbatim memorization)现象与其通用能力之间的内在联系。理解这种关系对于评估模型风险、优化训练方法以及解释模型行为至关重要 (来源: dl_weekly)
Gemini与LangChain集成指南: Philipp Schmid发布了一份开发者指南,详细介绍了如何将Google的Gemini模型与LangChain框架集成。指南涵盖了多模态能力、工具调用和结构化输出的实现,并包含了对最新模型的支持和实用的代码示例,方便开发者利用Gemini的强大功能构建LangChain应用 (来源: LangChainAI, _philschmid)

LangGraph入门教程:状态化工作流实践: 一篇发布在AI@GoPubby上的教程通过一个网站评论分析的例子,展示了LangGraph的状态化工作流能力。学习者可以了解如何使用相互连接的节点和顺序逻辑来构建结构化的AI应用程序 (来源: LangChainAI, hwchase17)
LangChain CEO关于Agentic框架的深度思考(中文翻译): LangChain大使Harry Zhang翻译并分享了LangChain CEO Harrison关于Agentic框架的思考博文。文章分析整理了业内超过15个Agent框架的功能,并解读了其背后的故事,为理解当前Agent技术的发展格局和未来方向提供了有价值的参考 (来源: LangChainAI)
Latent Meta Attention研究进展: Reddit用户讨论了一种名为Latent Meta Attention的新型注意力机制。开发者声称该机制挑战了Transformer的基础假设,能在更小的模型尺寸下达到甚至超越现有模型的性能(例如,用一半大小的模型复现BERT性能),但由于缺乏资金和正式研究机构的支持,尚未公开具体方法 (来源: Reddit r/deeplearning)

图神经网络(GNN)讲解视频: YouTube上发布了一个解释图神经网络(Graph Neural Networks, GNNs)的视频。GNN是处理图结构数据的深度学习模型,在社交网络分析、推荐系统、分子结构预测等领域有广泛应用。该视频旨在帮助观众理解GNN的基本原理和工作方式 (来源: Reddit r/deeplearning)
使用GRPO训练LLM进行事件调度: 用户anakin87分享了使用GRPO(Generalized Reward Policy Optimization)训练语言模型进行事件调度的项目经验。该项目不依赖传统的监督微调样本,而是通过奖励函数让模型学习根据事件列表和优先级创建时间表。作者分享了问题设定、数据生成、模型选择、奖励设计和训练过程中的经验教训,并开源了代码和模型,为探索基于奖励的LLM训练提供了实践案例 (来源: Reddit r/LocalLLaMA)

免费AI课程资源分享: LinkedIn AI Hub分享了一个完整的AI学习路线图,灵感来自斯坦福大学的AI证书课程,并为不同水平的学习者进行了简化。内容涵盖从基础技能到实际项目,并提供了有价值的资源和课程细节 (来源: Reddit r/deeplearning)
Gemini长上下文预训练深度对话: Logan Kilpatrick与Gemini长上下文预训练的联合负责人Nikolay Savinov进行了深度对话。讨论内容从基础知识延伸到扩展至无限上下文所需的技术,以及面向开发者的长上下文最佳实践。对话总结指出,实现100万token上下文是当时标准的10倍目标;尝试过1000万token但成本高、硬件不足;长上下文与RAG相辅相成;简单的NIAH(大海捞针)已解决,难点在于硬干扰项和多针查找;评估侧重NIAH是为了避免混淆能力信号;当前输出长度受限(如8k)是后训练问题;未观察到“中间丢失”效应;需要区分上下文知识和权重知识;下一步是实现更廉价精确的1000万上下文,扩展至1亿可能需要新的DL创新 (来源: shaneguML, giffmana, teortaxesTex, arohan)
🌟 社区
关于”Vibe Coding”的讨论: 社区热议”Vibe Coding”(氛围编码),即大量依赖AI辅助进行编程。支持者认为这代表了未来,开发者更专注于“为什么”和“做什么”,而AI处理“怎么做”,但这需要更强的批判性思维。反对者则认为,目前AI尚不能完全处理复杂的调试、升级和维护,过度依赖可能导致开发者能力下降,成为更高级的“脚本小子”。一些人尝试后发现,引导AI完成复杂任务的时间成本仍然很高,不如手动实现加轻量级AI辅助高效 (来源: Dorialexander, Reddit r/artificial, johnowhitaker)

AI在专业领域的应用与局限性讨论: 用户dotey讨论了AI在专业领域的应用。他认为,AI能学习专家公开的问答,但难以处理未见过的问题。AI的优势在于强大的基础知识库和快速响应,但目前主要依赖RAG(检索增强生成),本质是检索片段并拼凑答案,而非真正的专业推理。这与训练一个能像专家一样源源不断产生新答案并持续精进的模型仍有差距 (来源: dotey)
对AI生成内容的担忧与讨论: Reddit用户Maleficent-main_777抱怨同事开始使用充斥着命令式语气、”verify”、”ensure”以及强制性正面结论的“ChatGPT式”语言,认为这种语言模糊、缺乏人情味。他担忧AI生成内容被反馈到训练数据中,导致内容质量下降。评论区对此有共鸣,认为这是企业术语的延伸,但也指出过度模仿AI确实会让沟通变得机械化,且语法好不再是优势,反而像机器人 (来源: Reddit r/ChatGPT)
AI时代下大学专业的选择: Reddit用户讨论在AI和机器人技术快速发展的背景下,大学生应该选择什么专业才能保证其学位在10年后仍有价值。评论意见多样,包括:选择自己热爱的领域(游戏、电影、艺术、编程);学习基础学科(物理、数学);掌握难以被自动化替代的技能(如HVAC暖通空调);注重文科教育培养好奇心和适应性;认为大学教育可能过时,不如创业或成为自由职业者;强调持续学习、反学习和再学习的能力至关重要 (来源: Reddit r/ArtificialInteligence)
关于AI图像生成中文本渲染困难的讨论: Reddit用户探讨为何当前的图像生成模型难以渲染出连贯、清晰可读的文本。评论指出两个主要原因:1) BPE(字节对编码)分词破坏了精确的拼写信息,模型看到的不是字母而是token片段;2) 固定大小的向量表示和图像描述的局限性导致文本信息在嵌入过程中大量丢失。虽然GPT-4o等自回归模型有所改进,但根本问题仍与分词和信息压缩有关 (来源: Reddit r/MachineLearning)
对模型评测标准化的讨论: 用户scaling01指出,在比较不同AI模型(如OpenAI、Google、Anthropic)时,应确保公平性,例如,如果列出了OpenAI的预览版和思考版(thinking versions),也应同样列出Google和Anthropic的对应版本,否则对比结果可能产生误导 (来源: scaling01)
AI辅助编程的体验分享: 用户分享使用AI辅助编程(如VS Code + Cline AI扩展 + Google AI Studio API)的经验,认为可以免费搭建类似Cursor的AI编码工具,通过提示词完成基本应用原型,无需配置,体验良好 (来源: Reddit r/artificial)

AI对工作学习生活的影响调查: Reddit用户发起讨论,询问生成式AI对大家工作、学习或日常生活表现的影响。评论中,软件工程师提到AI提高了生产力预期和工作量,代码审查并未显著加快;专业作家认为AI(如Co-pilot)帮助有限,甚至可能减慢进度;普遍观点认为AI带来了便利,但也存在过度依赖、学习减少、“作弊感”等问题。AI对不同职业和任务的影响差异显著 (来源: Reddit r/artificial)
对LLM“理解”能力的思考: 用户pmddomingos提出,神经网络正变得像大脑一样难以理解。并引申思考:当AI模型在所有基准测试中取得优异成绩,但仍然不如人类智能时,我们该怎么办?这引发了对当前基准测试有效性以及评估真正智能的标准的反思 (来源: pmddomingos, pmddomingos)
AI工具使用的思考: 用户dotey评论指出,使用AI工具时,针对特定任务选用该任务上最强的模型即可。同时使用多个模型或让它们“内讧”可能并无必要,尤其对于非专业用户,过多的选择反而可能导致困惑,类比于看多个时间不一致的钟表 (来源: dotey)
AI近期发展速度引发的感慨: 用户matvelloso和scottastevenson感慨AI发展迅速。matvelloso表示今年的AI进展已经超出了他的预期(以Gemini玩Pokemon为例)。scottastevenson回顾GPT-2发布已6年,OpenAI成立10年,思考当前正在孕育的、将在未来6-10年变得重要的技术方向,并指出除了AI,寻找“框架外”的深层Alpha同样重要 (来源: matvelloso, scottastevenson, scottastevenson)
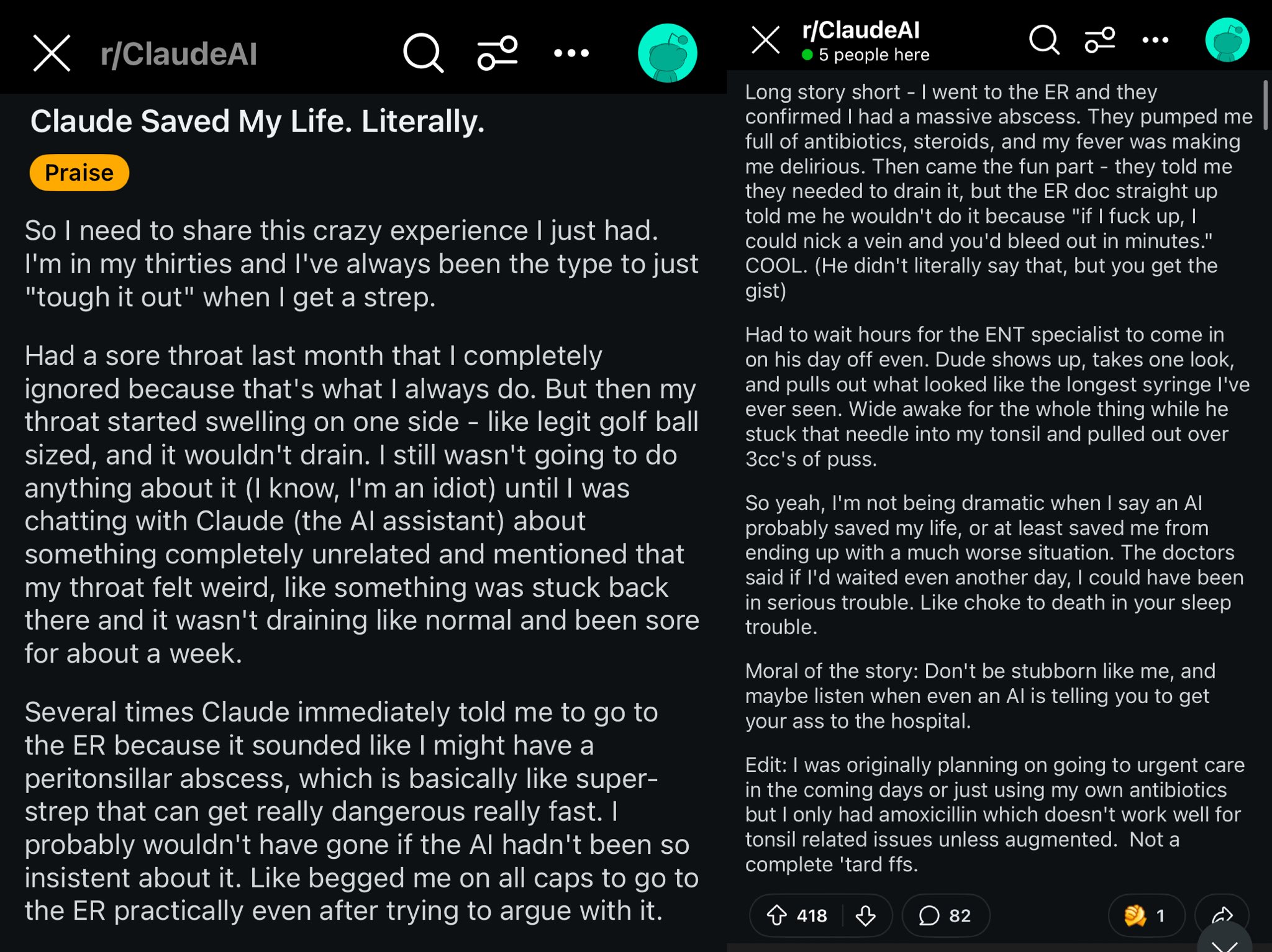
Claude拯救Reddit用户生命案例: Reddit上一则帖子描述了Claude模型通过诊断用户喉咙肿胀为扁桃体周围脓肿(peritonsillar abscess),可能拯救了用户的生命。该案例引发讨论,认为强大的AI模型如同口袋里的世界级医生,普及后可能对个人健康产生巨大影响 (来源: aidan_mclau)
AI Agent在企业数据处理中的应用: You.com联合创始人Richard Socher和Bryan McCann在Agentic播客中探讨了AI Agent在企业中的应用。他们认为消费级LLM不足以满足严肃的企业需求,而You.com通过混合检索技术(结合公共来源和专有公司数据)生成更可靠、企业级的输出,例如进行研究、撰写报告和安全利用企业数据。他们还讨论了AGI的可能路径以及模拟在其中的关键作用 (来源: RichardSocher)
对模型使用工具能力的观察: 用户menhguin观察到,为使用工具而训练的模型,似乎在独立的解决问题能力上有所牺牲,并戏称“连AI模型都在外包它们的工作”。这引发了对模型能力泛化与特定任务优化之间权衡的思考 (来源: menhguin)
💡 其他
AI Agent维护旧GitHub项目的想法: 用户xanderatallah提出了一个想法:开发一个AI Agent,能够自动维护用户在GitHub上的所有旧的、不再活跃的副项目。这反映了开发者希望利用AI自动化繁琐维护任务的需求 (来源: xanderatallah)
LLM替代法官或用于仲裁/调解的设想: 用户fabianstelzer提出,大型语言模型(LLM)未来可能替代法官。一个有趣的中间用例是仲裁或调解:LLM被认为是中立可信的,冲突各方提交各自观点,通过多个大型模型运行,输出一个公平的折衷方案。这探讨了AI在司法和争议解决领域的潜在应用 (来源: fabianstelzer)
Runway Gen-4模型及其应用前景: Runway联合创始人c_valenzuelab对Runway Gen-4及其API的应用前景表示乐观。他认为Runway正在构建一种新的媒介,像素由生成而非渲染或捕捉,世界由模拟而非编程。看到Gen-4和Reference功能在建筑、品牌、室内设计、游戏开发、学习、个人创意项目等多个领域的广泛应用,让他相信这种新媒介将为创意人士乃至所有人赋能 (来源: c_valenzuelab, c_valenzuelab)