关键词:Gemini 2.5 Pro, AI 模型, 人形机器人, AI 伦理, AI 创业, AI 生成内容, AI 辅助创意, Gemini 2.5 Pro 通关《宝可梦:蓝》, Anthropic Claude 全球网页搜索, Qwen3 MoE 模型路由偏差, Runway Gen-4 References 功能, AI 在心理健康支持中的应用
🔥 聚焦
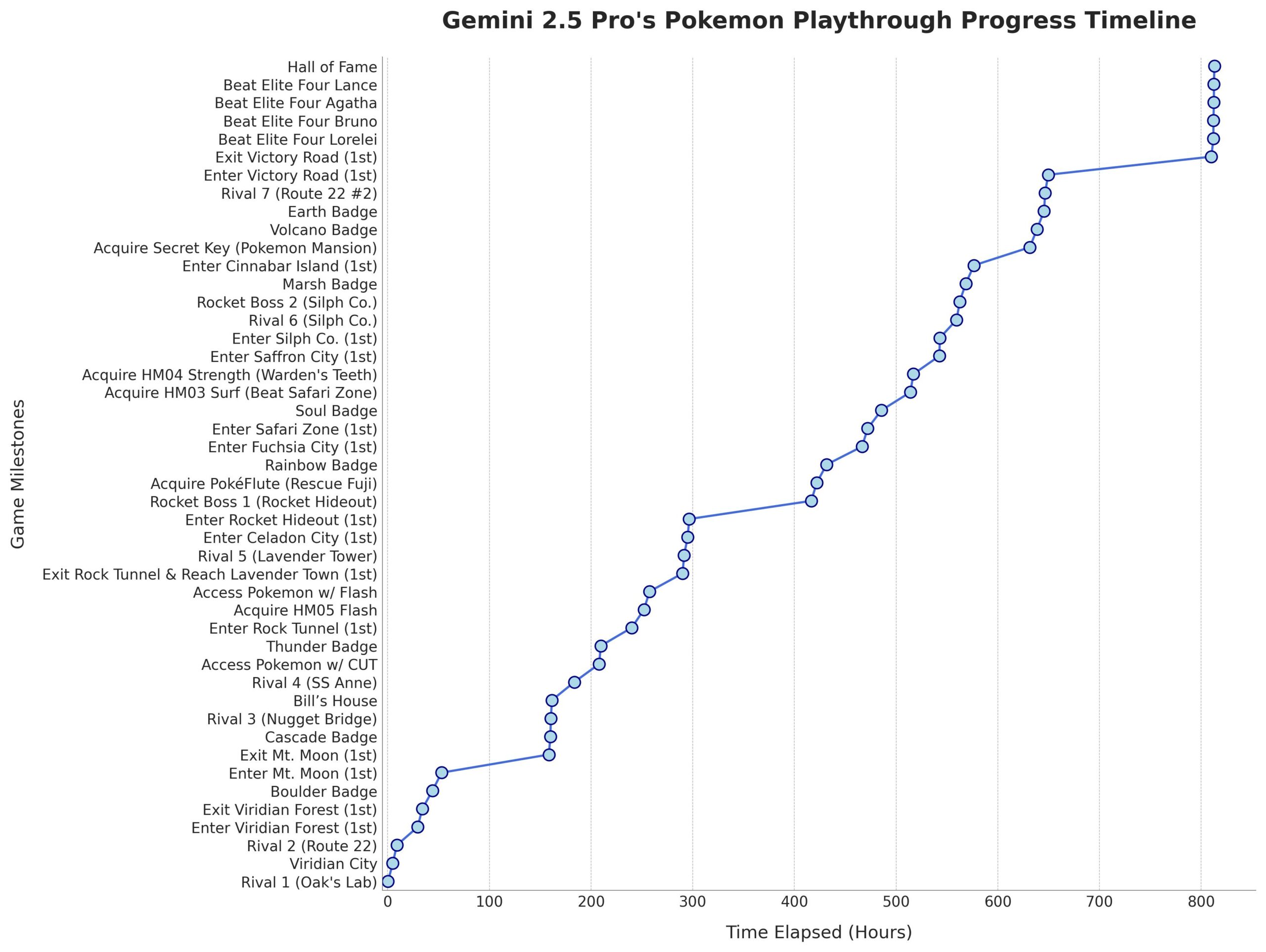
Gemini 2.5 Pro 成功通关《宝可梦:蓝》: 谷歌的 Gemini 2.5 Pro AI 模型成功完成了经典游戏《宝可梦:蓝》,包括收集所有8个徽章并击败了宝可梦联盟的四天王。这一成就由直播主 @TheCodeOfJoel 运行和直播,并得到了谷歌 CEO Sundar Pichai 和 DeepMind CEO Demis Hassabis 的祝贺。这展示了当前 AI 在复杂任务规划、长期策略制定和与模拟环境交互方面的显著进步,超越了之前 AI 在该游戏上的表现,标志着 AI 代理能力的新里程碑。(来源: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
苹果与 Anthropic 合作开发 AI 编码平台 “Vibe Coding”: 据彭博社报道,苹果正与 AI 初创公司 Anthropic 合作,共同开发一个名为 “Vibe Coding” 的新型 AI 驱动编码平台。该平台目前已在苹果内部向员工推广测试,未来有可能向第三方开发者开放。这标志着苹果在 AI 编程辅助工具领域的进一步探索,旨在利用 AI 提升开发效率和体验,可能与其自有的 Swift Assist 等项目形成补充或整合。(来源: op7418)
AI 驱动的机器人技术进展与讨论: 近期人形机器人和具身智能受到广泛关注。Figure 公司展示了其高科技的新总部,涵盖电池、执行器到 AI 实验室,预示着其在机器人领域的雄心。迪士尼也展示了其人形角色机器人技术。然而,北京人形机器人马拉松比赛中,部分机器人(包括客户改装的宇树G1)表现不佳,出现摔倒、续航差、平衡性问题,引发了对当前人形机器人实际能力的讨论,凸显了其在“小脑”(运动控制)和“大脑”(智能决策)方面仍需巨大进步。(来源: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

AI 伦理与社会影响讨论升温: 社交媒体和研究领域对 AI 的社会影响和伦理问题的讨论日益增多。例如,加州 SB-1047 AI 法案引发争议,相关纪录片探讨了监管的必要性与挑战。NAACL 2025 会议举办了关于“LLM 时代的社会智能”教程,探讨 AI 与人类、社会互动中的长期和新兴挑战。同时,用户对 AI 生成内容的质量(“slop”)表示担忧,认为需要更好的模型设计和控制。这些讨论反映了社会对 AI 技术快速发展所带来的伦理、监管和社会适应性问题的日益关切。(来源: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 动向
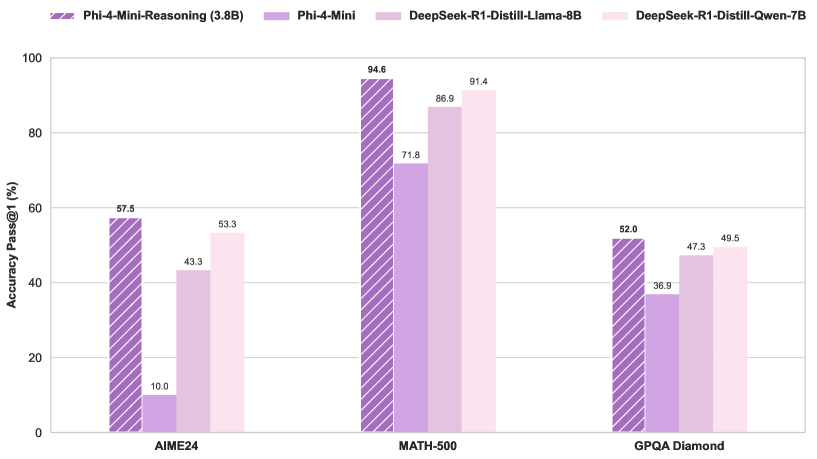
微软发布 Phi-4-Mini-Reasoning 模型: 微软在 Hugging Face 上发布了 Phi-4-Mini-Reasoning 模型,该模型旨在提升小型语言模型在数学推理方面的能力,进一步推动了小型化、高效能模型的发展。(来源: _akhaliq)
Anthropic Claude 模型支持全球网页搜索: Anthropic 宣布,其 Claude AI 模型现已为所有付费用户提供全球范围内的网页搜索功能。对于简单任务,Claude 会进行快速搜索;对于复杂问题,它会探索包括 Google Workspace 在内的多个信息源,增强了模型的实时信息获取和处理能力。(来源: Teknium1, Reddit r/ClaudeAI)

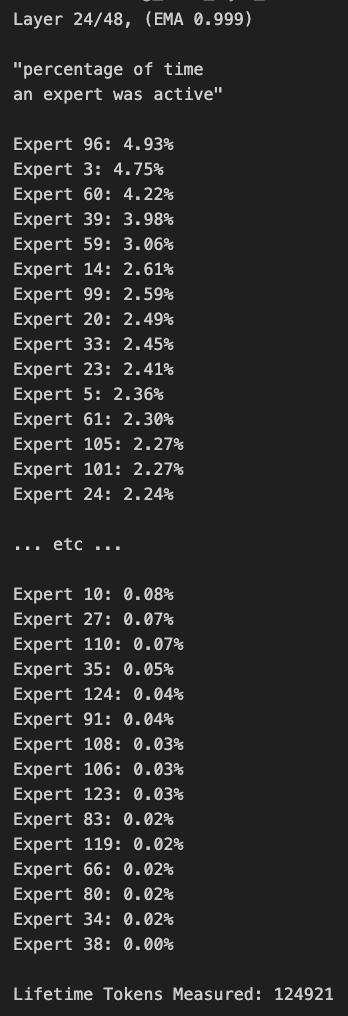
Qwen3 MoE 模型路由存在偏差,可被剪枝: 用户 kalomaze 分析发现 Qwen3 MoE(混合专家模型)的路由分布存在显著偏差,即使是 30B MoE 模型也显示出可剪枝的潜力。这意味着部分专家(Experts)可能未被充分利用,通过剪枝移除这些专家可能在不显著影响性能的情况下减小模型大小和计算需求。Kalomaze 已发布基于此发现将 30B 模型剪枝至 16B 的版本,并计划发布 235B 剪枝至 150B 的版本。(来源: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2 在开源数学助手中表现突出: DeepSeek Prover V2 被认为是目前表现最好的开源数学辅助模型。尽管其性能仍不及 Gemini 2.5 Pro、o4 mini high、o3、Claude 3.7 和 Grok 3 等闭源或更强大的模型,但它在结构化推理方面表现良好。用户认为其在需要创造性思维的“头脑风暴”环节有待加强。(来源: cognitivecompai)
模型偏好讨论:开发者倾向与特定模型特性: 开发者社区中关于不同大模型优劣的讨论持续进行。例如,Sentdex 认为结合 Codex 的 o3 在 Cursor 中的表现优于 Claude 3.7。VictorTaelin 则表示尽管 Sonnet 3.7 并非完美(有时过于主动添加非要求内容,智能程度未达预期),但在实践中仍比 GPT-4o(易犯错)、o3/Gemini(代码格式和重写不佳)、R1(稍显过时)和 Grok 3(第二佳,但实践中稍逊)提供更稳定可靠的结果。这反映了不同模型在特定任务和工作流中的适用性差异。(来源: Sentdex, VictorTaelin, paul_cal)

LLM 性能趋势讨论:指数增长还是收益递减?: Reddit 用户讨论了 LLM 是否仍在经历指数级改进。有观点认为,尽管早期进展迅速,但目前 LLM 性能提升正趋于收益递减,获得额外性能变得越来越困难和昂贵,类似于自动驾驶技术的发展。另一些用户则反驳,指出从 GPT-3 到 Gemini 2.5 Pro 的巨大飞跃表明进步依然显著,现在断言平台期为时过早。讨论反映了对 AI 未来发展速度的不同预期。(来源: Reddit r/ArtificialInteligence)
AI 芯片成为人形机器人发展的关键: 行业观点认为,人形机器人的核心在于其“大脑”,即高性能芯片。文章指出,当前人形机器人在运动控制(小脑)和智能决策(大脑)方面尚有不足,而芯片性能直接决定了机器人的智能化程度。英伟达的 GPU、英特尔处理器以及国内黑芝麻智能的华山 A2000 和武当 C1236 等芯片,都在为机器人提供更强的感知、推理和控制能力,是推动人形机器人从噱头走向实际应用的关键。(来源: 人形机器人,最重要的还是“脑子”)

AI 伦理与拟人化:我们为何对 AI 说“谢谢”?: 讨论指出,尽管 AI 没有情感,用户仍倾向于对其使用礼貌用语(如“谢谢”、“请”)。这源于人类的拟人化本能和“社会存在感知”。研究表明,礼貌的交互方式可能引导 AI 产生更符合期望的、更人性化的回应。然而,这也带来了风险,如 AI 可能学习并放大人类偏见,或被恶意引导产生不当内容。对 AI 的礼貌行为,反映了人类在与日益智能化的机器互动时的复杂心理和社会适应。(来源: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 工具
Runway Gen-4 References 功能: RunwayML 推出的 Gen-4 References 功能允许用户将自己或其他参考图像融入 AI 生成的视频或图片(如 meme)中。用户反馈该功能效果显著,能够处理多个一致的角色出现在同一生成图像中,简化了将特定人物或风格融入 AI 创作的过程。(来源: c_valenzuelab)

Krea AI 推出图片生成模板: Krea AI 新增功能,将常见的 GPT-4o 图片生成提示词制作成模板。用户只需上传自己的图片并选择模板,即可生成相应风格的图片,无需手动输入复杂的提示词,简化了图片生成流程。(来源: op7418)
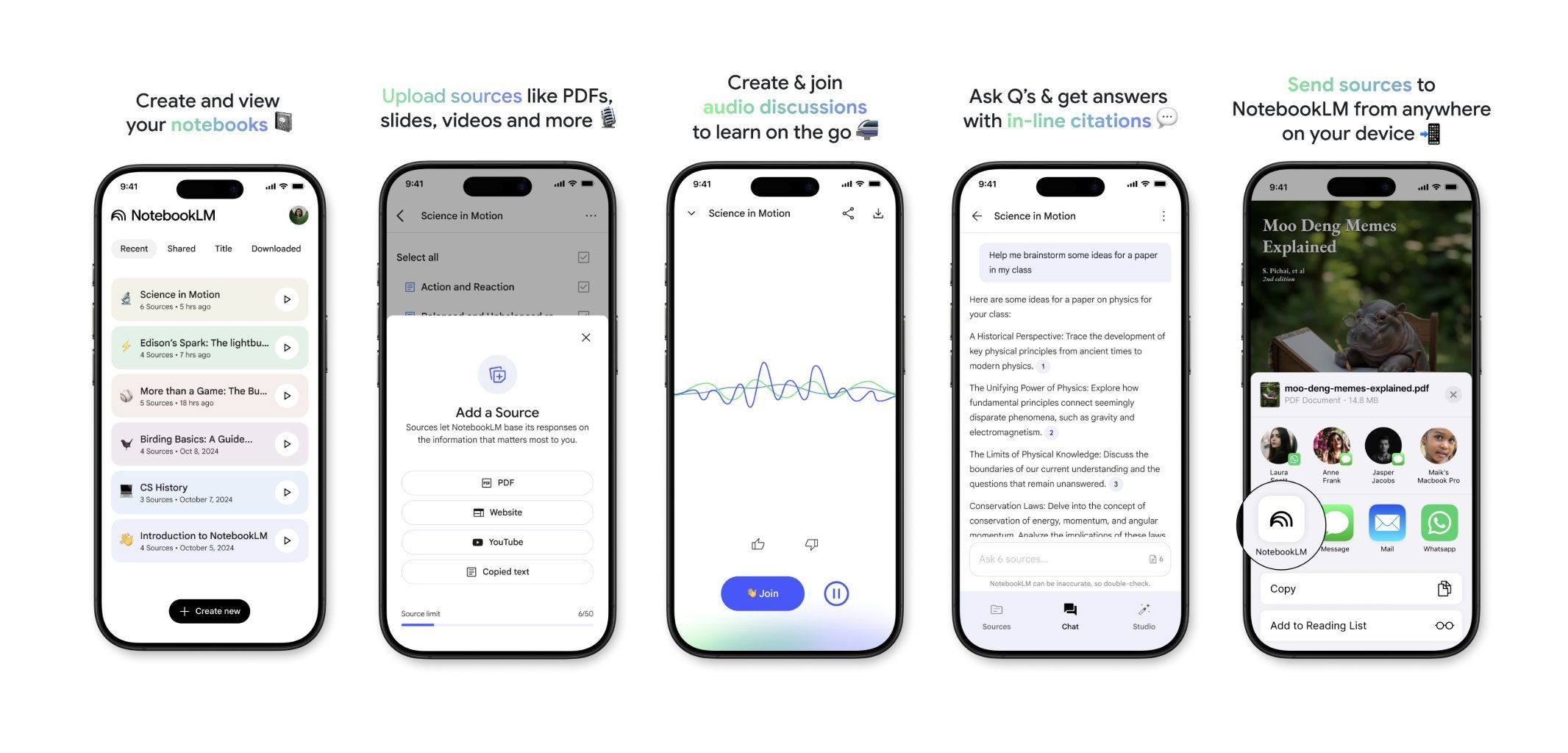
NotebookLM 即将推出移动端应用: 谷歌的 NotebookLM(前身为 Project Tailwind)即将发布移动应用程序。用户可以将手机上看到的文章和内容快速转发至 NotebookLM 进行处理和整合。目前已开放应用候补名单注册,旨在提供更便捷的移动端信息管理和 AI 辅助学习体验。(来源: op7418)
Runway 用于室内设计: 用户展示了使用 Runway AI 进行室内设计的案例。通过提供一张空间图片和一张代表风格/情绪的参考图片,Runway 能够生成融合两者特点的室内设计效果图,展示了 AI 在创意设计领域的应用潜力。(来源: c_valenzuelab)

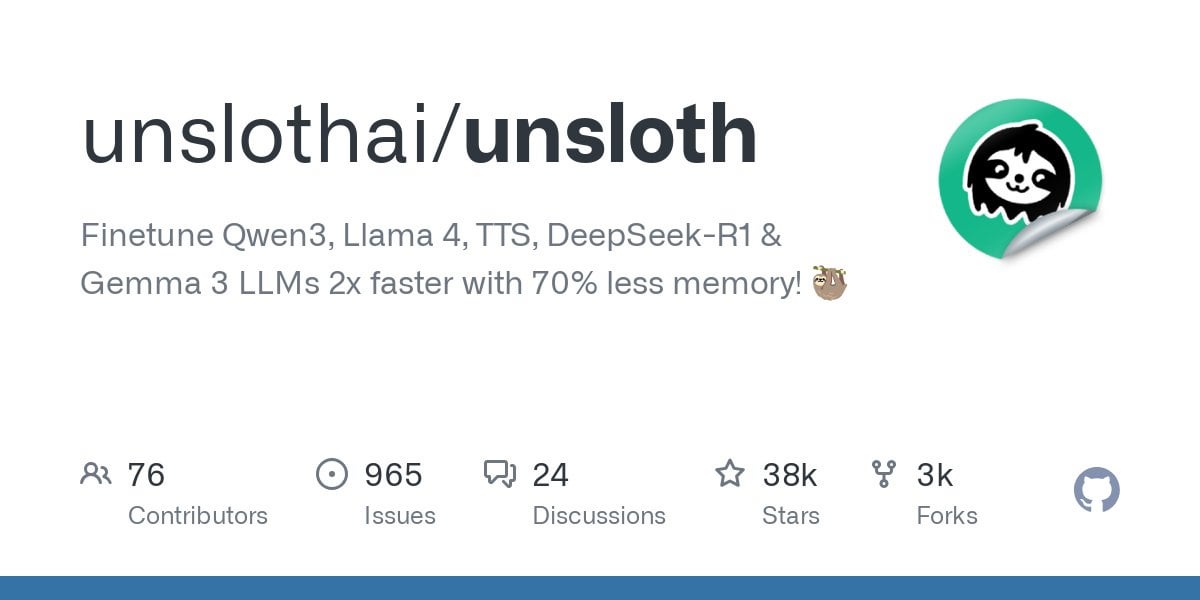
Unsloth 支持 Qwen3 模型微调: Unsloth 宣布支持对 Qwen3 系列模型进行微调,速度提升 2 倍,显存占用减少 70%。用户可以在 24GB 显存 GPU 上实现比 Flash Attention 2 长 8 倍的上下文长度微调。提供了 Colab 笔记本来免费微调 Qwen3 14B 模型,并上传了包括 GGUF 在内的多种量化模型。这降低了微调先进模型的硬件门槛。(来源: Reddit r/LocalLLaMA)
Claude AI Styles 功能: 用户分享使用 Claude AI 的 Styles 功能来改善与 AI 的协作体验。通过创建一个名为“Iterative Engineering”的风格,设定讨论、计划、小步修改、测试、迭代、按需重构的步骤,可以引导 Claude 更加 methodical 和 incremental 地进行编码,避免其过度重写代码,提升了 AI 作为编程伙伴的实用性。(来源: Reddit r/ClaudeAI)
Deepwiki 提供代码块来源: 用户 cto_junior 提到 Deepwiki 的一个优点是它在每个答案旁边都显示源代码块,而不仅仅是附加链接。这种做法提高了信息的可信度,尤其对于对 AI 工具持怀疑态度的软件开发工程师(SDEs)来说更有帮助。(来源: cto_junior)
📚 学习
NousResearch 发布 Atropos RL 框架更新: NousResearch 的 Atropos 强化学习(RL)环境框架进行了更新。新功能允许用户快速轻松地测试 RL 环境的 rollout,无需训练或推理引擎。默认使用 OpenAI API,但可配置为其他 API 提供商(或本地 VLLM/SGLang 端点)。测试完成后会生成包含 completions 及其分数的网页报告,并支持 wandb 日志记录,便于 RL 环境的调试和评估。(来源: Teknium1)

个性化 RAG 基准数据集 EnronQA 发布: 研究者发布了 EnronQA 数据集,旨在推动个性化检索增强生成(Personalized RAG)在私人文档上的研究。该数据集包含 103,638 封邮件和针对 150 位用户的 528,304 个高质量问答对,为评估和开发能理解和利用个人特定信息的 RAG 系统提供了资源。(来源: lateinteraction)
GTE-ModernColBERT (PyLate) 发布: LightOnAI 发布了 GTE-ModernColBERT (PyLate),这是一个 128 维的 MaxSim 检索器,基于 gte-modernbert-base 并在 ms-marco-en-bge-gemma 上进行了微调。它原生支持 PyLate 库,可进行重排和 HNSW 索引。在 NanoBEIR 基准测试中表现优异,并在 BEIR 平均得分上超过了 ColBERT-small,提供了新的高效文本检索选项。(来源: lateinteraction)

SOLO Bench – 新型 LLM 基准测试: 用户 jd_3d 开发并发布了 SOLO Bench,一种新的 LLM 基准测试方法。该测试要求 LLM 生成包含特定数量(如 250 或 500)句子的文本,每个句子必须且只能包含一个来自预定义列表(包含名词、动词、形容词等)的单词,且每个单词只能使用一次。通过基于规则的脚本进行评估,旨在测试 LLM 的指令遵循、约束满足和长文本生成能力。初步结果显示该基准能有效区分不同模型的性能。(来源: Reddit r/LocalLLaMA)
利用战略性递归反思操纵潜在空间: 用户提出一种通过“战略性递归反思”(Strategic recursive reflection, RR)在 LLM 潜在空间中创建嵌套推理层次的方法。通过在关键时刻提示模型反思之前的交互,生成元认知循环,构建“迷你潜在空间”。每个提示被视为一种压力,引导模型在潜在空间中的路径,使其更具自指性和抽象能力。这被认为模拟了人类通过反思思想来深化思考的过程,旨在探索更深层次的概念。(来源: Reddit r/ArtificialInteligence)
💼 商业
谷歌向三星支付费用以预装 Gemini AI: 继去年因默认搜索引擎协议被判违反反垄断法后,谷歌被曝每月向三星支付“巨额资金”及收入分成,以将 Gemini AI 预装在三星设备上,并可能要求合作伙伴强制预装 Gemini。这解释了为何三星 Galaxy S25 系列深度整合 Gemini,甚至将其设为默认 AI 助手。此举反映了谷歌在自有硬件渠道不足的情况下,急于抢占移动端 AI 入口的战略,但也可能再次引发反垄断担忧。(来源: 三星手机预装Gemini AI,也是谷歌花钱买的)

AI 创业公司面临挑战: Reddit 讨论指出,许多 AI 初创公司可能缺乏护城河,因为模型能力趋同,用户忠诚度低。大型科技公司(谷歌、微软、苹果)凭借其生态系统优势(如预装、整合),更容易触达用户。即使初创公司的模型稍好,用户也可能倾向于使用默认或集成的“足够好”的 AI。这引发了对 AI 初创公司长期生存能力和 VC 投资前景的担忧。(来源: Reddit r/ArtificialInteligence)
本周 AI 融资与商业动态汇总 (May 2nd, 2025): 微软 CEO 透露 AI 已编写公司“重要部分”代码;微软 CFO 警告 AI 服务可能因需求过高而中断;谷歌开始在第三方 AI 聊天机器人中投放广告;Meta 推出独立 AI 应用;Cast AI 融资 $108M,Astronomer 融资 $93M,Edgerunner AI 融资 $12M;研究指责 LM Arena 存在基准测试被操纵问题;Nvidia 挑战 Anthropic 对芯片出口管制的支持。(来源: Reddit r/artificial)
🌟 社区
AI 生成内容的质量与成本讨论: 社区中对 AI 生成内容的质量参差不齐(称为 “slop”)表示担忧。用户 wordgrammer 指出,大量生成的 AI 视频质量低下,实际成本(考虑到筛选和重试)远高于标价。这引发了对模型设计(如 jam3scampbell 引用乔布斯观点)和有效利用 AI 工具的讨论,强调需要更精细的控制和更高的生成质量标准。(来源: wordgrammer, jam3scampbell, willdepue)
AI 在特定任务上的表现引发讨论: 社区成员讨论了 AI 在不同任务上的表现和局限性。例如,DeepSeek R1 被认为可能是 LLM 炒作的一个高峰,尽管在形式数学、医学等领域有进展,但尚未引起普通用户的广泛关注。DeepSeek Prover V2 在数学方面表现好,但被认为缺乏创造性。用户 vikhyatk 质疑过度优化模型以在 AIME(美国数学邀请赛)等特定基准上表现的意义,认为大众并不关心数学能力。这些讨论反映了对 AI 能力边界和实际应用价值的思考。(来源: wordgrammer, cognitivecompai, vikhyatk)
AI 辅助创意与设计: 社区展示了使用 AI 工具进行创意设计的多种方式。用户利用 Runway 的 Gen-4 References 功能将自己融入 meme;使用 Runway 进行室内设计概念生成;利用 GPT-4o 和提示词模板创作具有特定风格的图像(如折纸华南虎、动物硅胶腕托、将单词含义融入字母设计)。这些案例展示了 AI 在视觉创意、个性化设计方面的潜力。(来源: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

对 AI 写作风格模仿能力的质疑: 用户 nrehiew_ 认为,让 LLM “以我的语气和风格继续写作”的指令可能并没有实际效果,因为大多数人高估了自己写作风格的独特性。这引发了对 LLM 理解和复制细微写作风格能力的讨论,以及用户对这种能力的感知偏差。(来源: nrehiew_)
AI 用于情感支持引发共鸣与讨论: Reddit 用户分享了与 ChatGPT 等 AI 对话获得情感支持甚至帮助应对危机的经历。许多人表示,在孤独、需要倾诉或面临心理困境时,AI 提供了一个无评判、耐心且随时可用的交流对象,有时甚至感觉比与真人交流更有效。这引发了关于 AI 在心理健康支持中作用的讨论,同时也强调了 AI 不能替代专业人类帮助,以及需要警惕 AI 可能带来的偏见或误导。(来源: Reddit r/ChatGPT, Reddit r/ClaudeAI)
对 AI 生成艺术的看法分歧: 用户讨论了 AI 生成艺术对人类艺术家及其作品认知的潜在影响。有人抱怨,高质量的作品现在常被轻易地归因为 AI 生成,忽视了创作者的才华和努力。这种现象甚至开始扭曲人们的感知,使人倾向于在作品中寻找“人类错误”来确认其非 AI 创作。讨论也涉及到是否应强制要求 AI 生成内容添加水印的问题。(来源: Reddit r/ArtificialInteligence)
💡 其他
AI 消耗资源引关注: 讨论强调了 AI 发展背后的巨大资源消耗。训练和运行大型 AI 模型需要消耗大量电力和水资源,数据中心成为新的高能耗设施。用户与 AI 的每一次交互,包括简单的“谢谢”,都在累积消耗能源。这引发了对 AI 可持续发展和能源解决方案(如核聚变)的关注。(来源: 你对 AI 说的每一句「谢谢」,都在烧钱)
AI 与意识的距离: Reddit 用户讨论当前 AI 是否具有自我意识。普遍观点认为,目前的 AI(如 LLM)本质上是基于概率预测词语的复杂模式匹配系统,缺乏真正的理解和自我意识,距离具备该能力还非常遥远。但也有评论指出,人类意识本身也未被完全理解,对比可能存在误区,且 AI 在特定任务上的超人能力不容忽视。(来源: Reddit r/ArtificialInteligence)
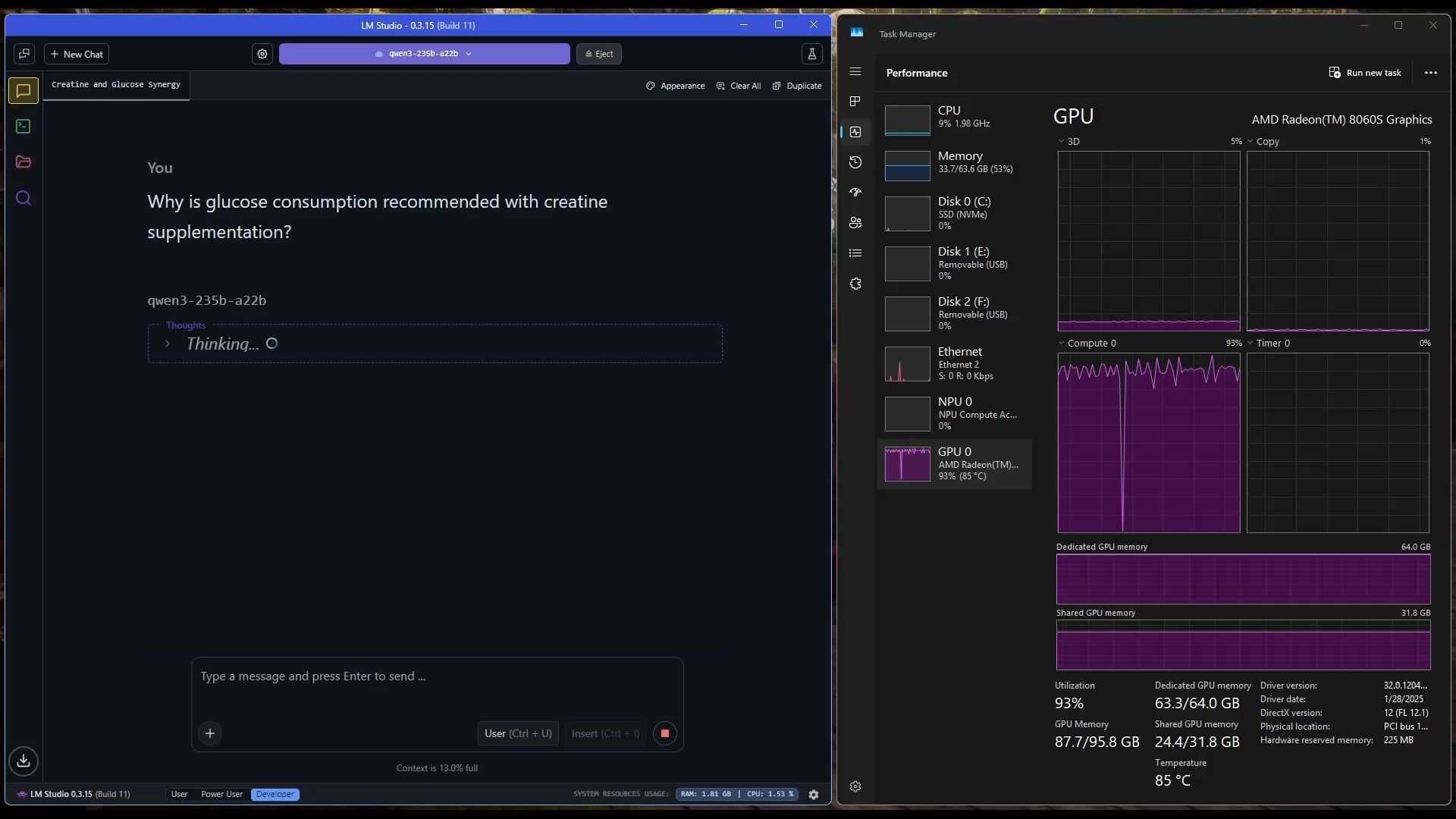
Windows 平板运行大型 MoE 模型: 用户展示了在配备 AMD Ryzen AI Max 395+ 和 128GB RAM 的 Windows 平板电脑上,仅使用 iGPU(Radeon 8060S,分配 95.8GB 中的 87.7GB 作为 VRAM)运行 Qwen3 235B-A22B MoE 模型(使用 Q2_K_XL 量化)的实例,速度达到约 11.1 t/s。这展示了在便携设备上运行超大型模型的可能性,尽管内存带宽仍是瓶颈。(来源: Reddit r/LocalLLaMA)