
关键词:ChatBot Arena, Phi-4-reasoning, Claude Integrations, AI 智能体, DeepSeek-Prover-V2, Qwen3, Gemini, Parakeet-TDT-0.6B-v2, 排行榜幻觉, 小模型推理能力, 第三方应用集成, AI 编程智能体, 数学定理证明
🔥 聚焦
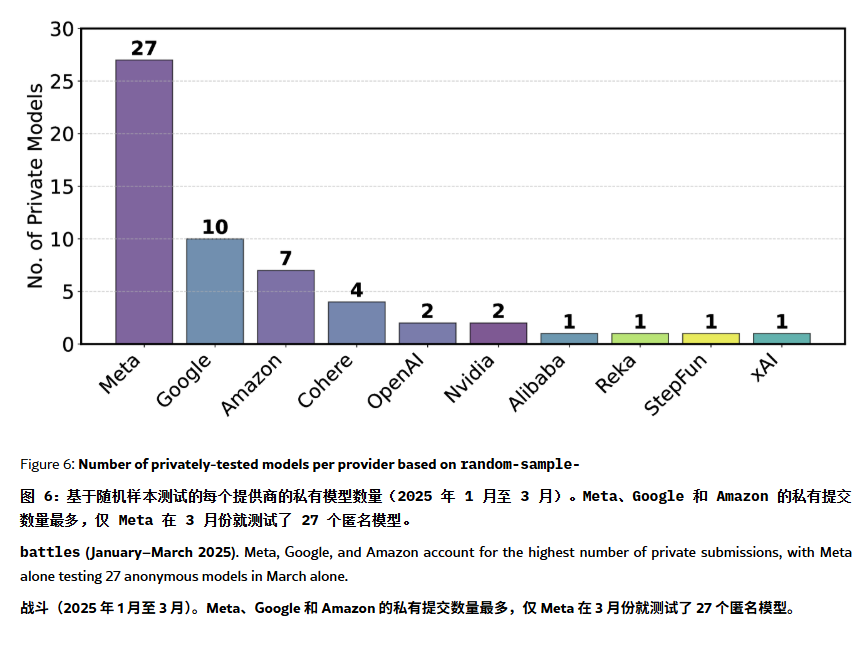
ChatBot Arena 榜单被指存在“幻觉”与操纵: 一篇 ArXiv 论文[2504.20879]对广泛引用的 ChatBot Arena 模型排行榜提出质疑,认为其存在“排行榜幻觉”。论文指出,大型科技公司(如Meta)可能通过提交大量微调模型变体(如Llama-4测了27个)并仅公布最佳结果来刷榜;模型展示频率也可能偏向大厂模型,挤压开源模型的曝光机会;模型淘汰机制缺乏透明度,大量开源模型在测试数据不足的情况下被下架;此外,用户常用提问的相似性可能导致模型针对性地过拟合训练以提高得分。这引发了对当前主流 LLM 基准测试可靠性和公正性的担忧,建议开发者和用户审慎看待榜单排名,并考虑构建符合自身需求的评估体系。(来源: karminski3, op7418, TheRundownAI)
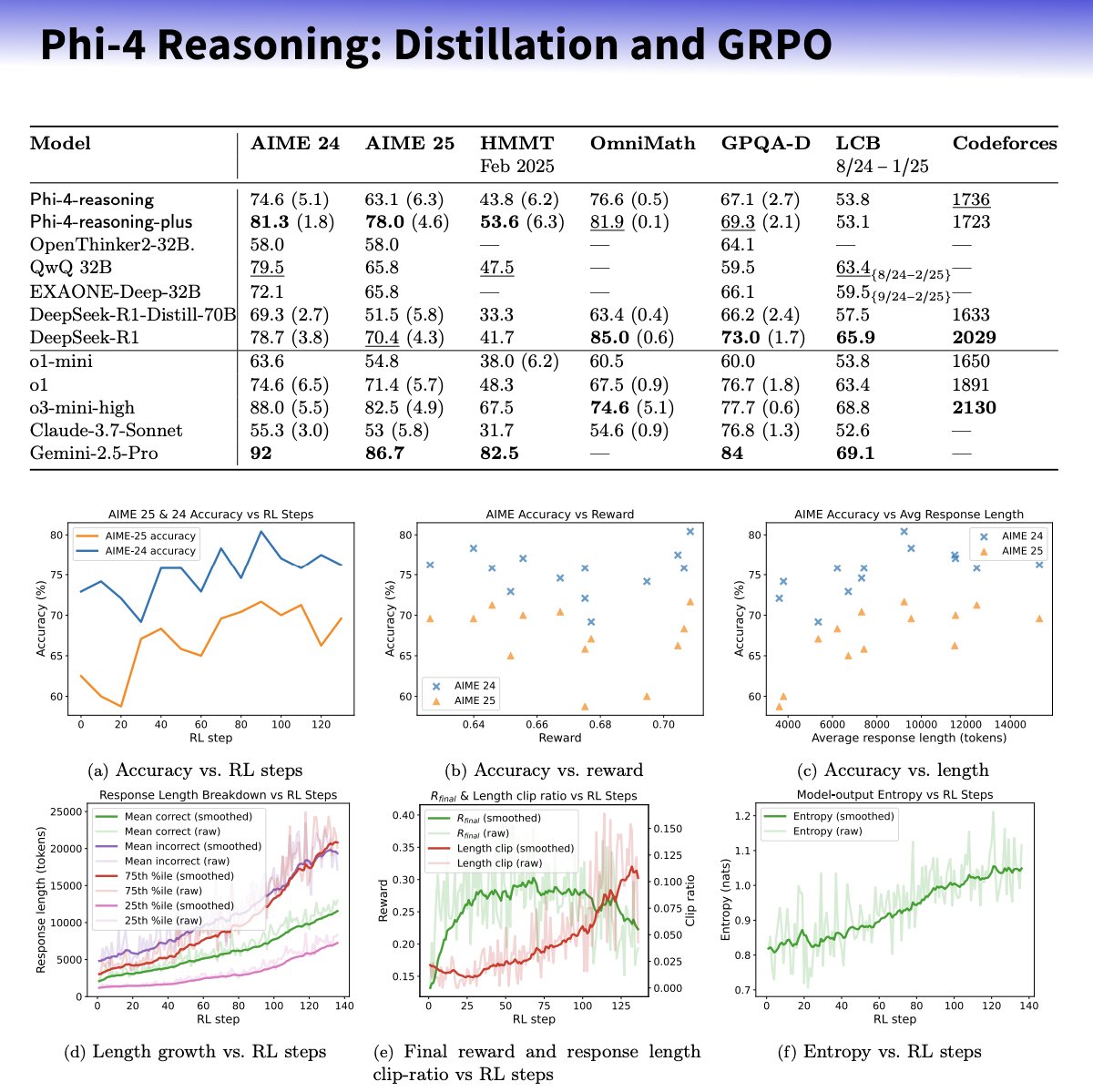
微软发布 Phi-4-reasoning 系列小模型,专注提升推理能力: 微软推出了基于 Phi-4 架构的 Phi-4-reasoning 和 Phi-4-reasoning-plus 模型,旨在通过精心策划的数据集、监督微调(SFT)和目标强化学习(RL)来增强小型语言模型的推理能力。据称,这些模型利用 OpenAI o3-mini 作为“教师”生成高质量的链式思考(CoT)推理轨迹,并通过 GRPO 算法进行强化学习优化。微软研究员 Sebastien Bubeck 声称 Phi-4-reasoning 在数学能力上优于 DeepSeek R1,但模型规模仅为其 2%。该系列模型使用专门的推理 token 和扩展的 32K 上下文长度。此举被认为是在小型化、专业化模型方向上的探索,可能为资源受限场景提供更强的推理解决方案,但也引发了关于其是否利用 OpenAI 技术并在 MIT 许可下发布的讨论。(来源: _philschmid, TheRundownAI, Reddit r/LocalLLaMA)
Anthropic 推出 Integrations 功能并扩展研究能力: Anthropic 宣布推出 Claude Integrations,允许用户将 Claude 与 Jira、Confluence、Zapier、Cloudflare、Asana 等 10 种第三方应用和服务连接,未来还将支持 Stripe、GitLab 等。此前仅限本地服务器的 MCP(模型上下文协议)支持扩展至远程服务器,开发者可通过文档或 Cloudflare 等方案在约 30 分钟内创建自己的集成。同时,Claude 的研究(Research)功能得到增强,新增高级模式,可搜索网络、Google Workspace 及已连接的 Integrations,将复杂请求分解调查,生成带引用的综合报告,处理时间可能长达 45 分钟。网页搜索功能也向全球付费用户开放。这些更新旨在提升 Claude 作为工作助手的集成度和深度研究能力。(来源: _philschmid, Reddit r/ClaudeAI)

AI 智能体能力遵循新摩尔定律:每4个月翻一番: AI Digest 的研究指出,AI 编程智能体完成任务的能力正经历指数级增长,其处理任务的时长(以人类专家所需时间衡量)在 2024-2025 年间大约每 4 个月翻一番,快于 2019-2025 年间每 7 个月翻一番的速度。目前顶尖 AI 智能体已能处理人类需 1 小时的编程任务。若此加速趋势持续,预计到 2027 年 AI 智能体或能完成长达 167 小时(约一个月)的复杂任务。这种能力的飞速提升得益于模型本身的进步以及算法效率的提高,并可能因 AI 辅助 AI 研发而形成超指数增长的正反馈循环,预示着“软件智能爆炸”的可能性,将深刻改变软件开发、科研等领域,同时也带来自动化对就业市场的冲击等社会挑战。(来源: 新智元)

🎯 动向
DeepSeek-Prover-V2 发布,提升数学定理证明能力: DeepSeek AI 发布了 DeepSeek-Prover-V2,包含 7B 和 671B 两种规模,专注于 Lean 4 形式化定理证明。该模型采用递归证明搜索和强化学习(GRPO)进行训练,利用 DeepSeek-V3 分解复杂定理并生成证明草图,再结合专家迭代和合成的冷启动数据进行微调和强化学习。DeepSeek-Prover-V2-671B 在 MiniF2F-test 上达到 88.9% 的通过率,并在 PutnamBench 上解决了 49 个问题,展现了 SOTA 性能。同时发布的还有包含 AIME 和教科书题目的 ProverBench 基准。该模型旨在统一非形式化推理与形式化证明,推动自动定理证明的发展。(来源: 新智元)

英伟达与 UIUC 提出 400 万 token 上下文扩展新方法: 英伟达和伊利诺伊大学厄巴纳-香槟分校的研究者提出了一种高效的训练方法,可将 Llama 3.1-8B-Instruct 的上下文窗口从 128K 扩展至 1M、2M 乃至 4M token。该方法采用持续预训练和指令微调两阶段策略,关键技术包括使用特殊文档分隔符、基于 YaRN 的位置编码扩展以及单步预训练。训练出的 UltraLong-8B 模型在 RULER、LV-Eval、InfiniteBench 等长上下文基准测试中表现优异,并在 MMLU、MATH 等标准短上下文任务上保持甚至超越了基线 Llama 3.1 的性能,优于 ProLong、Gradient 等其他长上下文模型。该研究为构建超长上下文 LLM 提供了高效且可扩展的途径。(来源: 新智元)

Qwen3 发布,性能提升显著: 阿里巴巴发布了 Qwen3 系列模型,包括 Qwen3-30B-A3B 等。根据 Reddit 用户的初步测试和基准数据(如 AHA Leaderboard),Qwen3 相较于之前的 Qwen2.5 和 QwQ 版本在多个维度(如健康、比特币、Nostr 等特定领域知识)表现更好。用户反馈显示,Qwen3 在处理特定任务(如模拟太阳系动力学)时表现出较强的能力,能正确应用物理定律生成椭圆轨道和相对周期。但也有用户指出 Qwen3 在长上下文(如接近16K)时性能下降明显,且推理时 token 消耗较高,建议配合搜索工具使用。Qwen3 的命名方式(如 Qwen3-30B-A3B)也因其清晰度受到好评。(来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, karminski3, madiator)
Gemini 即将整合 Google 账户数据以提供个性化体验: Google 计划让 Gemini AI 助手接入用户的 Google 账户数据,包括 Gmail、照片、YouTube 历史等,旨在提供更个性化、主动和强大的辅助体验。Google 产品负责人 Josh Woodward 表示,这是为了让 Gemini 更好地理解用户,成为用户的延伸。该功能将是可选的(opt-in),用户可以选择是否开启数据访问权限。此举引发了关于隐私和数据安全的讨论,用户需要在个性化便利性与数据隐私之间做出权衡。(来源: JeffDean, Reddit r/ArtificialInteligence)

英伟达推出 Parakeet-TDT-0.6B-v2 ASR 模型: 英伟达发布了新的自动语音识别(ASR)模型 Parakeet-TDT-0.6B-v2,参数量为 6 亿。据称,该模型在 Open ASR Leaderboard 上的表现优于 Whisper3-large(参数量 16 亿),尤其在处理多样化数据集(包括 LibriSpeech、Fisher Corpus、YouTube 数据等约 12 万小时数据)方面表现出色。该模型支持字符、单词和段落级别的时间戳,但目前仅支持英语,且需要英伟达 GPU 和特定框架运行。用户初步反馈其转录和标点符号准确度高。(来源: Reddit r/LocalLLaMA)

Qwen2.5-VL 发布,提升视觉语言理解: 阿里巴巴发布了 Qwen2.5-VL 系列多模态模型(包括 3B、7B、72B 参数),旨在提升机器对视觉世界的理解和交互能力。这些模型可用于图像摘要、视觉问答、从复杂视觉信息生成报告等任务。文章介绍了其架构、基准测试表现和推理细节,展示了其在视觉语言理解方面的进步。(来源: Reddit r/deeplearning)

Mistral Small 3.1 Vision 支持已合并至 llama.cpp: llama.cpp 项目已合并对 Mistral Small 3.1 Vision 模型(24B 参数)的支持。这意味着用户将能够在 llama.cpp 框架下运行此多模态模型,进行图像理解等任务。Unsloth 已提供相应的 GGUF 格式模型文件。这为本地运行 Mistral 的视觉模型提供了便利。(来源: Reddit r/LocalLLaMA)
Meta 发布 Synthetic Data Kit: Meta 开源了一个名为 Synthetic Data Kit 的命令行工具,旨在简化 LLM 微调所需的数据准备阶段。该工具提供 ingest(导入数据)、create(生成 QA 对,可选推理链)、curate(使用 Llama 作为评判者筛选优质样本)、save-as(导出为兼容格式)四个命令,利用本地 LLM(通过 vLLM)生成高质量的合成训练数据,特别适用于为 Llama-3 等模型解锁特定任务推理能力。(来源: Reddit r/MachineLearning)
GTE-ModernColBERT-v1 成为热门嵌入模型: 由 LightOnIO 推出的 GTE-ModernColBERT-v1 模型成为 Hugging Face 上新的热门趋势搜索/嵌入模型。该模型采用多向量(也称为后期交互或 ColBERT)搜索方法,为关注此类技术的开发者提供了新的选择。(来源: lateinteraction)
X 推荐算法更新: X 平台(前 Twitter)对其推荐算法进行了修复,旨在解决用户负反馈未被采纳、重复看到相同内容以及 SimCluster 算法推荐不相关内容等长期存在的问题。据称早期反馈积极。(来源: TheGregYang)
维基百科宣布新 AI 战略以辅助人类编辑: 维基百科公布了其新的人工智能战略,旨在利用 AI 工具支持和增强人类编辑的工作,而非取代他们。具体细节未在来源中详述,但表明这家全球最大的在线百科全书正在探索如何将 AI 技术融入其内容创建和维护流程中。(来源: Reddit r/artificial)
🧰 工具
Midjourney 推出 Omni-Reference 功能: Midjourney 发布了新的 Omni-Reference(oref)功能,允许用户通过提供参考图片 URL(使用 –oref 参数)来指导图像生成,以实现角色、物体、车辆或非人类生物的一致性。用户可以通过 –ow 参数控制参考图的影响权重,较低权重适用于风格化,较高权重适用于写实或精确的面部匹配。该功能旨在提升生成图像中特定元素的一致性和可控性。(来源: op7418, DavidSHolz)

Runway Gen-4 References 实现单图个性化: Runway 的 Gen-4 模型推出了 References(参考)功能,用户仅需提供一张参考图像,即可将图像中的风格或人物特征应用到新的生成内容中。演示显示,该功能可以轻松地将人物肖像以参考图的风格或置于参考图描绘的世界中进行再创作,展示了模型仅凭单张参考图就能实现较高一致性和美学质量的个性化生成能力。(来源: c_valenzuelab, c_valenzuelab)

Perplexity 的 WhatsApp 机器人恢复服务: Perplexity AI 的 WhatsApp 聊天机器人因需求远超预期而短暂下线后,现已恢复服务。用户可以通过电话号码 +1 (833) 436-3285 与其互动,可以转发消息进行事实核查、直接提问获取答案、进行自由形式的文本对话以及创建图像。(来源: AravSrinivas, AravSrinivas)
Krea AI 结合 4o 图片模型实现精准图像控制: AI 创意工具 Krea AI 增加了新功能,允许用户结合 OpenAI 的 4o 图片模型能力,通过图像拼贴和涂鸦的方式更精确地控制生成图像的内容和风格。这展示了 Krea 在交互式图像生成方面的持续创新,让用户能够更直观、细致地引导 AI 创作。(来源: op7418)
行云褐蚁一体机:低成本运行满血 DeepSeek: 清华背景的行云集成电路推出褐蚁 AI 一体机,号称能在 14.9 万元的价位下,以超过 20 token/s 的速度运行未经量化的 FP8 精度 DeepSeek-R1/V3 671B 模型,并支持 128K 上下文。该方案采用双路 AMD EPYC CPU 和大容量高频内存,配合少量 GPU 加速,旨在通过 CPU+内存的架构大幅降低大模型私有化部署的硬件成本,提供接近官方性能的本地化体验,适用于对成本敏感且需要高精度的企业场景。(来源: 新智元)

NotebookLM App 即将发布: Google 的 AI 笔记应用 NotebookLM 即将推出官方 iOS 和 Android 应用程序,预计于 5 月 20 日上线,目前已开放预订。这将把 NotebookLM 基于用户笔记和文档提供摘要、问答和创意生成的功能带到移动端。(来源: zacharynado)
Granola 推出 iOS 应用,实现 AI 实时会议纪要: AI 笔记应用 Granola 发布了 iOS 版本,将其原有的 Zoom 会议 AI 笔记功能扩展到线下的面对面交谈场景。用户可以在 iPhone 上使用 Granola 记录和转录对话,并利用 AI 生成摘要和笔记,方便后续回顾和整理。(来源: amasad)
Grok Studio 支持 PDF 处理: Grok AI 助手在其 Studio 功能中增加了对 PDF 文件的处理能力,用户现在可以更方便地在 Grok Studio 中处理和分析 PDF 文档。具体功能细节未详述,但标志着 Grok 在多格式文档理解和交互方面的能力扩展。(来源: grok, TheGregYang)
Suno 新模型展现出色音乐生成能力: AI 音乐生成平台 Suno 推出了新模型,用户反馈其生成效果“非常出色”。有用户尝试用其生成现场演出风格的歌曲,虽然未能完全实现期望的呼应效果,但生成的音乐在人群氛围感等方面表现良好,展示了新模型在音乐质量和风格多样性上的进步。(来源: nptacek, nptacek)
AI 辅助识别青蛙叫声的应用 Frog Spot: 一位开发者创建了一款名为 Frog Spot 的免费应用,使用自训练的 CNN 模型(TensorFlow Lite)通过分析 10 秒音频的声谱图来识别不同种类的青蛙叫声。该应用旨在帮助公众了解本地物种,同时也展示了深度学习在生物声学监测和公民科学领域的应用潜力。(来源: Reddit r/deeplearning)
AI 辅助工业技术图纸自动化: 一篇 IAAI 2025 论文介绍了一种自动化处理管道与仪表流程图(P&ID)中“仪表典型”(Instrument Typicals)扩展的方法。该方法结合计算机视觉模型(文本检测与识别)和领域特定规则,自动从 P&ID 图纸和图例表中提取信息,将简化的仪表典型符号扩展为详细的仪表清单,生成准确的仪表索引。这旨在提高工程项目(尤其在投标阶段)的效率,减少人工错误。(来源: aihub.org)

利用 Sora 生成微缩酱板鸭景观: 用户分享了使用 Sora 根据详细提示词生成的“微缩景观酱板鸭”图片。提示词细致地描述了场景风格(微距摄影、微缩景观)、主体(酱板鸭构成的摊位建筑)、细节(酱红色表皮、辣椒芝麻、厨师切片、食客)、环境(鸭肉酱料构成的街道、腌制风格墙面、红灯笼等)。这展示了 Sora 在理解复杂、富有想象力的文本描述并生成相应高质量图像方面的能力。(来源: dotey)

创建 3D 天气预报 GPTs: 用户分享了一个自制的 ChatGPTs 应用“Weather 3D”,它可以根据用户输入的城市名称,调用天气 API 获取实时天气数据,并生成该城市标志性建筑的 3D 等距微缩模型风格插画,同时融入当前天气状况。插画顶部会显示城市名、天气状况、温度和天气图标。该 GPTs 展示了如何结合 API 调用和图像生成能力,创造出实用且具有视觉吸引力的 AI 应用。(来源: dotey)

📚 学习
AdaRFT:优化强化学习微调的新方法: Taiwei Shi 等人提出了一种名为 AdaRFT 的轻量级、即插即用的课程学习方法,旨在优化基于人类反馈的强化学习(RFT)算法(如 PPO, GRPO, REINFORCE)的训练过程。据称,AdaRFT 能够将 RFT 训练时间缩短高达 2 倍,并提升模型性能,通过更智能地安排训练数据顺序来提高学习效率和效果。(来源: menhguin)

AI 评估(Evals)线上大师课: Hamel Husain 和 Shreya Shankar 开设了一个为期 4 周的关于 AI 应用评估(Evals)的线上大师课。课程旨在帮助开发者将 AI 应用从原型阶段推向生产就绪状态,内容涵盖开发和上线后的评估方法、基准测试与实际评估的区别、数据检查、PromptEvals 等。强调评估在确保 AI 应用可靠性和性能方面的重要性。(来源: HamelHusain, HamelHusain)

Google 模型调优手册: Google Research 提供了一个名为 “tuning_playbook” 的资源库,旨在为模型调优提供指导和最佳实践。这对于需要对大型语言模型或其他机器学习模型进行微调以适应特定任务或数据集的开发者和研究人员来说,是一个有价值的学习资源。(来源: zacharynado)

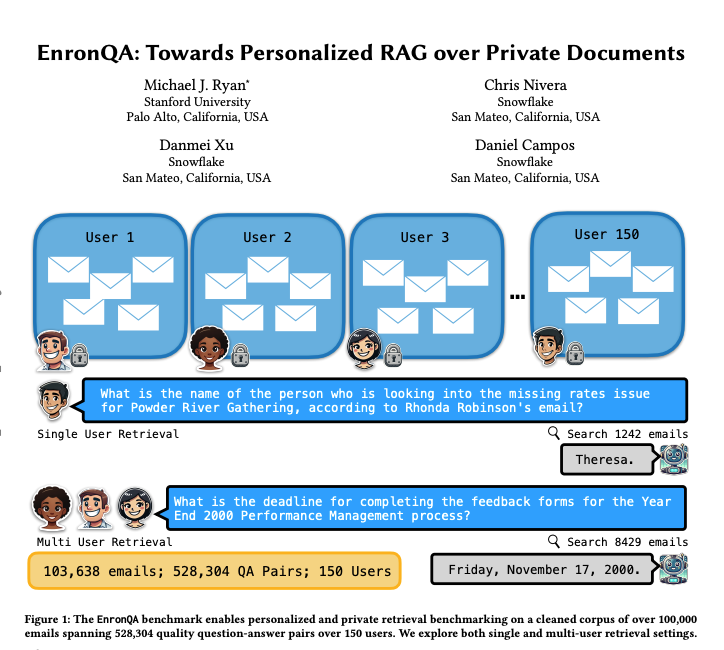
EnronQA:个性化 RAG 基准数据集: 研究者推出了 EnronQA 数据集,包含来自 150 位用户的 103,638 封邮件和 528,304 个高质量问答对。该数据集旨在作为评估个性化检索增强生成(RAG)系统在处理私有文档方面性能的基准。数据集中包含黄金参考答案、错误答案、推理理由和备选答案,有助于更细致地分析 RAG 系统的表现。(来源: tokenbender)
ReXGradient-160K:大规模胸片与报告数据集: 发布了一个名为 ReXGradient-160K 的大型公开胸部 X 光数据集,包含来自美国 3 个卫生系统(79 个医疗点)的 109,487 名独特患者的 60,000 项胸片研究及其配对的放射学报告(自由文本)。据称这是目前公开可用的患者数量最多的胸片数据集,为训练和评估医学影像 AI 模型提供了宝贵资源。(来源: iScienceLuvr)

探讨 AI 智能体能力增长的博客文章: 研究员 Shunyu Yao 发表博客文章《The Second Half》,提出当前 AI 发展正处于一个“中场休息”时刻。在此之前,训练比评估更重要;在此之后,评估将比训练更重要,原因在于强化学习(RL)终于开始有效运作。文章探讨了 AI 能力持续提升的背景下,评估方法论转变的重要性。(来源: andersonbcdefg)
OpenAI 关于隐私与记忆化的研究分享: OpenAI 的研究人员 Pratyush Maini 和 Zhili Feng 将进行一场关于隐私和记忆化研究的演讲,讨论如何检测、量化和消除大型语言模型中的记忆化现象,及其在生产环境 LLM 中的实际应用。这关系到如何平衡模型能力与用户数据隐私保护。(来源: code_star)

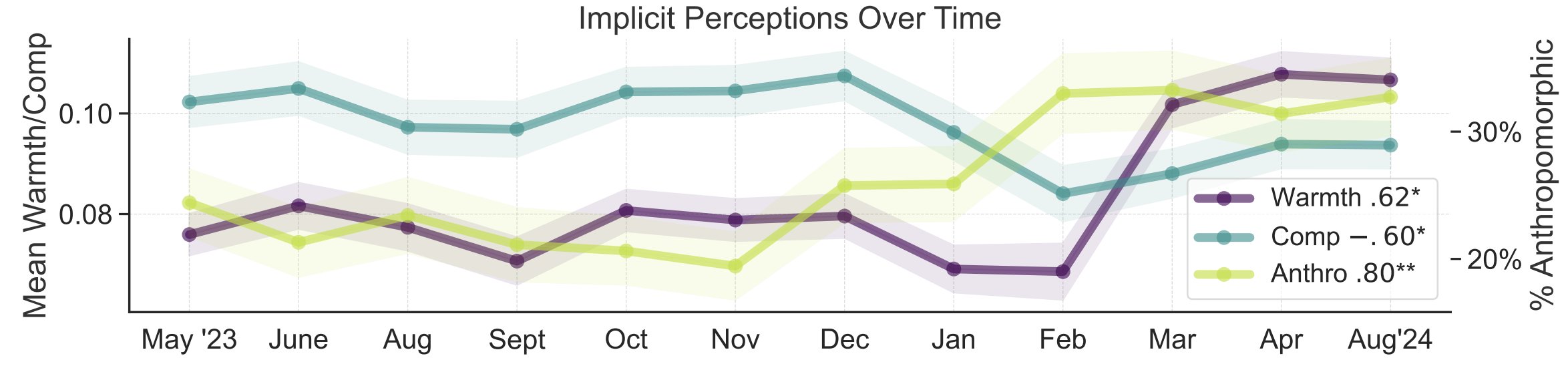
AI 公众认知的隐喻研究: 斯坦福大学研究者 Myra Cheng 等人在 FAccT 2025 发表论文,通过分析 12 个月内收集的 12000 个关于 AI 的隐喻,来理解公众对 AI 的心智模型及其随时间的变化。研究发现,随着时间推移,公众倾向于将 AI 视为更具人性化和能动性(拟人化程度上升),并且对其的情感倾向(温暖度)也在上升。这种方法提供了比自陈报告更细致的公众认知洞察。(来源: stanfordnlp, stanfordnlp)
MIRI 发布 AI 治理研究议程: 人工智能研究所(MIRI)的技术治理团队发布了新的 AI 治理研究议程,阐述了他们对战略格局的看法,并提出了一系列可操作的研究问题。其目标是探索需要采取哪些措施来防止任何组织或个人构建出无法控制的超级智能,以减少来自 AI 的灾难性风险和灭绝风险。(来源: JeffLadish)
💼 商业
企业级 AI 解决方案商滴普科技申请港股 IPO: 由前华为、阿里背景高管赵杰辉创立的企业级 AI 解决方案提供商滴普科技(Deepexi)已正式提交港股上市申请。该公司专注于 FastData 数据智能平台和 FastAGI 企业级人工智能解决方案,服务于零售(如百丽)、制造、医疗等行业。在过去三年中,公司收入持续增长,2024 年达到 2.43 亿元。滴普科技已完成 8 轮融资,获得高瓴资本、IDG 资本、五源资本等知名机构投资,最后一轮融资后估值约 68 亿元人民币。尽管收入增长,但公司目前仍处于亏损状态,调整后净亏损逐年收窄。(来源: 36氪)
宝马中国宣布接入 DeepSeek 大模型: 继与阿里巴巴合作后,宝马集团进一步深化在中国的 AI 布局,宣布将接入 DeepSeek 大模型。该功能计划于 2025 年第三季度开始,率先应用于搭载第 9 代 BMW 操作系统的多款在华销售新车,未来也将应用于国产宝马新世代车型。此举旨在通过 DeepSeek 的深度思考能力,强化以 BMW 智能个人助理为核心的人机交互体验,提升车辆的智能化水平和情感连接能力,是宝马加速本土化 AI 战略、应对智能化转型挑战的重要一步。(来源: 36氪)
Shopify 强制全员使用 AI,欲用 AI 替代部分岗位: 全球电商平台 Shopify CEO Tobi Lutke 在内部备忘录中强调,高效使用 AI 已成为公司所有员工的“铁律”,不再是建议。备忘录要求员工将 AI 应用于工作流程,形成条件反射;团队申请增加人手前需证明为何 AI 无法完成任务;绩效考核将引入 AI 使用指标。Lutke 指出,AI 能极大提升效率(部分员工达 10 倍甚至 100 倍),员工需每年提升 20%-40% 才能保持竞争力。此前 Shopify 已在客服等部门进行裁员并引入 AI 替代。此举被视为 AI 导致白领岗位调整和裁员趋势的明确信号。(来源: 新智元)

🌟 社区
关于 AI 幻觉问题的讨论: 李彦宏在百度 AI 开发者大会上批评 DeepSeek-R1 存在幻觉率高、速度慢、成本高等问题,引发社区对大模型“幻觉”现象的再次讨论。有分析指出,不仅 DeepSeek,包括 OpenAI 的 o3/o4-mini、阿里的 Qwen3 等先进模型普遍存在幻觉问题,且推理模型的多轮思考可能放大偏差。Vectara 的评估显示 R1 幻觉率(14.3%)远高于 V3(3.9%)。社区认为,随着模型能力增强,幻觉变得更隐蔽、更具逻辑性,使用户难以分辨真伪,引发对可靠性的担忧。同时,也有观点认为幻觉是创造力的副产品,尤其在文学创作等领域有其价值。如何界定可接受的幻觉程度,以及如何通过 RAG、数据质量控制、批判模型等技术手段缓解幻觉,仍是业界持续探索的议题。(来源: 36氪)

对 AI 伴侣/朋友的思考与讨论: Meta CEO 扎克伯格提出用个性化 AI 朋友来满足人们对更多社交连接的需求(声称普通人有 3 个朋友,但需求是 15 个),引发社区讨论。Sebastien Bubeck 认为实现真正的 AI 伴侣非常困难,关键在于 AI 需要能有意义地回答“最近在忙什么?”,即拥有自身的经历和体验,而不仅仅是共享用户的经历。他认为当前的 AI 伴侣设想过于关注共享体验,而忽略了 AI 自身也需要有可分享的独立体验,甚至八卦(分享彼此的体验)。另有评论者从邓巴数的角度质疑,认为由 AI 构成的庞大社交圈可能缺乏真实意义。还有观点担忧,商业公司提供的 AI 朋友最终目的可能是为了精准营销转化,而非真正的陪伴。(来源: jonst0kes, SebastienBubeck, gfodor, gfodor)

AI 艺术创作引发的情感与思考: 社区中有用户表达了因 AI 能在短时间内创作出“疯狂好”的艺术作品而感到“悲伤”(grieving),认为这挑战了人类在艺术创造上的独特性。这引发了关于 AI 艺术、人类创造力本质以及技术冲击下个人价值感的讨论。有评论认为,艺术创作的乐趣在于过程本身,而非与 AI 竞争;AI 艺术可以作为灵感来源。也有人认为 AI 艺术缺乏人类创作的“错误”或灵魂,显得过于完美或刻板。同时,讨论也延伸到 AI 在情感模拟、意识、以及未来社会结构(如工作被取代)等方面带来的哲学思考。(来源: Reddit r/ArtificialInteligence)
AI 伦理与责任:秘密实验与信息披露: 社区讨论了 AI 研究中的伦理问题。一则新闻提到有 AI 研究者在 Reddit 上进行秘密实验,试图改变用户想法,引发了对用户知情权和 AI 操纵风险的担忧。另一则讨论中,有用户反映向 AI 公司报告潜在安全问题时,遭遇流程复杂、责任不清的困境,凸显了当前 AI 领域在负责任披露和漏洞响应机制方面尚不成熟。(来源: Reddit r/ArtificialInteligence, nptacek)

NLP 领域对 ChatGPT 崛起的反思: Quanta Magazine 发表文章,通过对 Chris Potts, Yejin Choi, Emily Bender 等多位自然语言处理(NLP)领域专家的访谈,回顾了 ChatGPT 发布后对整个领域带来的冲击和反思。文章探讨了大型语言模型的崛起如何挑战了传统 NLP 的理论根基、引发了领域内的争论、派别分化和研究方向的调整。社区成员对此文反响热烈,认为它很好地概述了 GPT-3 之后语言学领域的震动和适应过程。(来源: stanfordnlp, Teknium1, YejinChoinka, sleepinyourhat)
AI 生成广告的出现与观感: 社交媒体用户反映开始在 YouTube 等平台看到由 AI 生成的广告,并表示感到“非常不适”。这表明 AI 内容生成技术已开始应用于商业广告制作,同时也引发了用户对于 AI 生成内容质量、真实性以及情感体验的初步反应。(来源: code_star)
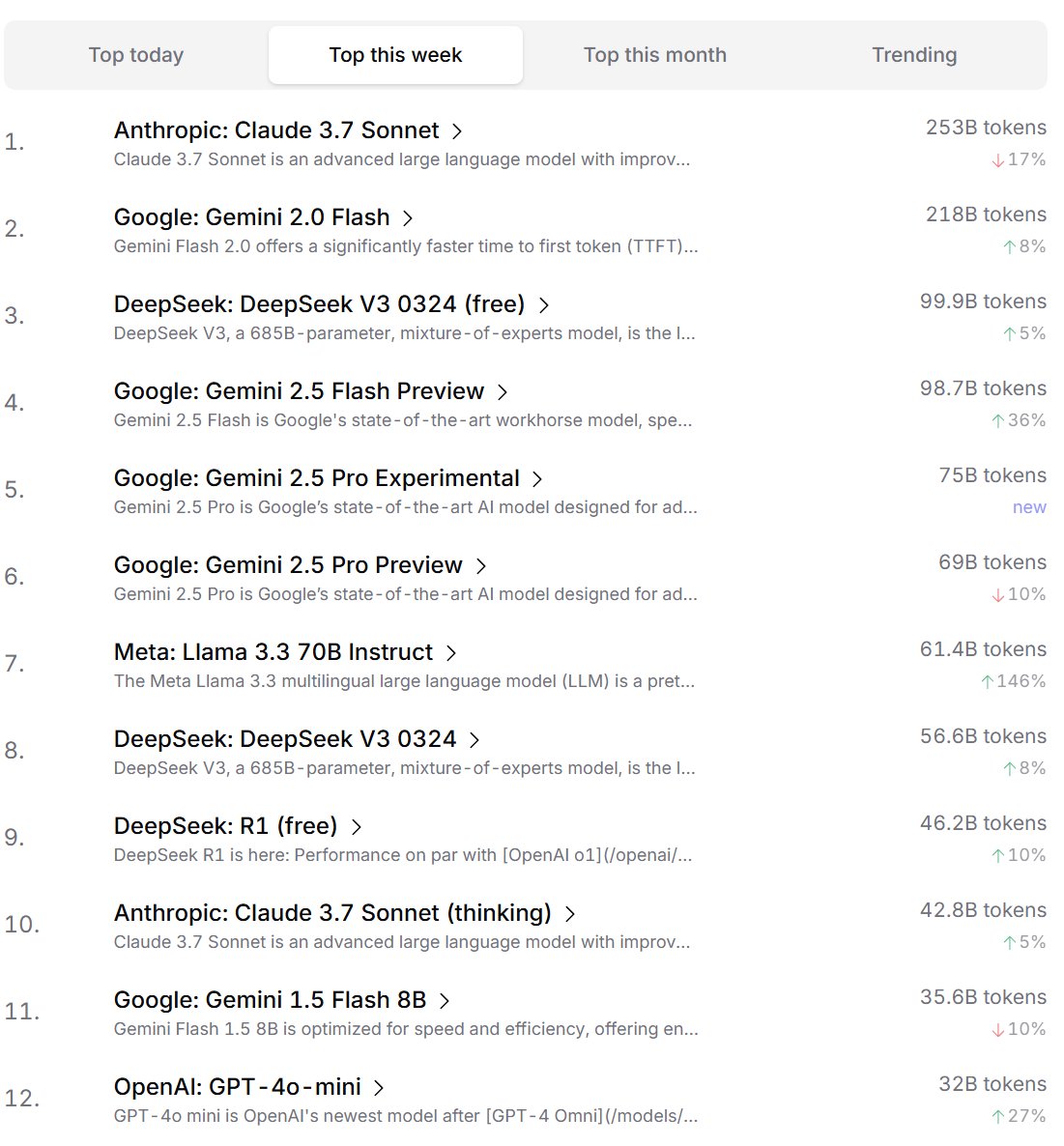
开发者对 AI 模型的偏好排名: Cursor.ai 发布了其用户(主要是开发者)偏好的 AI 模型排名,同时 Openrouter 也公布了模型 Token 使用量排名。这些基于实际产品使用数据的排名,被认为可能比 ChatBot Arena 等竞技场式榜单更能反映用户在真实开发场景中的选择偏好,为评估模型实用性提供了不同视角。(来源: op7418, Reddit r/LocalLLaMA)
关于 AI 是否具备“思考”能力的讨论: 社区中对于大语言模型(LLMs)是否真正具备“思考”能力存在持续讨论。有观点认为,当前的 LLMs 实际上并不在说话前进行思考,而是通过生成更多文本(如思维链)来模拟思考过程,这是一种误导。另有观点认为,使用连续数学方法(如 LLMs)在离散计算机上进行离散推理本身就存在根本性的问题。这些讨论反映了对当前 AI 技术本质和未来发展方向的深入思考。(来源: francoisfleuret, pmddomingos)
对 AI 能源消耗与环境影响的辩证思考: 针对 AI 训练和运行所需巨大能源消耗带来的环境问题,社区出现辩证思考。一种观点认为,AI 的巨大能源需求(尤其是 Google, Amazon, Microsoft 等超大规模计算公司)正迫使这些公司投资建设自己的可再生能源(太阳能、风能、电池),甚至重启核电站(如微软与 Constellation 合作重启三里岛核电站),这种需求可能反而成为加速清洁能源部署和技术突破(如小型模块化核反应堆 SMR)的催化剂。但也有观点指出,AI 能源消耗的收益递减问题,以及冷却所需的水资源消耗同样值得关注。(来源: Reddit r/ArtificialInteligence)
Anthropic 被指试图限制 AI 芯片竞争: 社区讨论指出,Anthropic CEO Dario Amodei 主张加强对向中国等地的 AI 芯片出口管制,甚至提出芯片可能通过伪装成孕妇假肚子等方式走私的说法。批评者认为,Anthropic 此举旨在限制竞争对手(尤其是像 DeepSeek、Qwen 这样的中国公司)获取先进计算资源,以维护其在尖端模型开发上的优势。这种做法被指责为利用政策打压竞争,不利于全球 AI 技术的开放发展和开源社区。(来源: Reddit r/LocalLLaMA)

💡 其他
AI 与人类认知极限的思考: Jeff Ladish 评论认为,人类作为 AI 的“复制粘贴助手”的角色窗口期极其短暂,暗示 AI 的自主能力将迅速超越简单辅助。同时,DeepMind 创始人 Hassabis 在采访中表示,真正的 AGI 应能独立提出有价值的科学猜想(如爱因斯坦提出广义相对论),而不仅仅是解决问题,认为当前 AI 在假设生成方面仍有欠缺。刘慈欣则期待 AI 能突破人脑的生物认知极限。这些观点共同指向了对 AI 能力边界、人类角色演变以及未来智能本质的深层思考。(来源: JeffLadish, 新智元)
Waymo 激光雷达捕捉到惊险瞬间: Waymo 自动驾驶车辆的激光雷达(LiDAR)系统在一次其成功规避的摩托车事故中,清晰捕捉到了外卖骑手在碰撞中翻转的 3D 点云影像。这不仅展示了 Waymo 感知系统的强大能力(即使在复杂动态场景下),也意外地记录下了事故的独特视角。所幸事故中无人重伤。(来源: andrew_n_carr)
AI 用于小说创作的新思路:情节承诺系统: 开发者 Levi 提出了一种用于 AI 小说创作的“情节承诺”(Plot Promise)系统,以替代传统的层级大纲方法。该系统受 Brandon Sanderson 的“承诺、进展、回报”理论启发,将故事视为一系列活跃的叙事线索(承诺),每个承诺有重要性评分,算法根据评分和进展情况建议推进时机,但 AI 会结合上下文逻辑地选择当前最适合推进的承诺。用户可动态增删承诺。该方法旨在增强故事的灵活性、可扩展性(适应超长篇幅)和创作的涌现性,但面临 AI 决策优化、长期连贯性维持和输入提示长度限制等挑战。(来源: Reddit r/ArtificialInteligence)