
关键词:DeepSeek-Prover-V2, Qwen3, 数学推理大模型, 多模态模型, AI评估方法, 开源大模型, 强化学习, AI供应链, DeepSeek-Prover-V2-671B, Qwen2.5-Omni-3B, LMArena排行榜公平性, RLVR数学推理方法, AI供应链风险分析
🔥 聚焦
DeepSeek发布数学推理大模型DeepSeek-Prover-V2:DeepSeek发布了专为形式化数学证明与复杂逻辑推理设计的DeepSeek-Prover-V2系列模型,包括671B和7B版本。该模型基于DeepSeek V3 MoE架构,在数学推理、代码生成、法律文书处理等领域进行了微调。官方数据显示,671B版本解决了近90%的miniF2F问题,显著提升了PutnamBench上的SOTA性能,并在AIME 24和25的形式化版本问题上达到了不错的通过率。此举标志着AI在自动化数学推理和形式化证明领域取得重要进展,可能推动科学研究和软件工程等领域的发展。(来源: zhs05232838, reach_vb, wordgrammer, karminski3, cognitivecompai, gfodor, Dorialexander, huajian_xin, qtnx_, teortaxesTex, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
Qwen3系列大模型发布并开源:阿里巴巴Qwen团队发布了最新的Qwen3大模型系列,包含0.6B至235B参数量的8款模型,涵盖密集模型和MoE模型。Qwen3模型具备思考/非思考模式切换能力,在推理、数学、代码生成及多语言处理(支持119种语言)方面有显著提升,并增强了Agent能力和对MCP的支持。官方评测显示其性能超越了之前的QwQ和Qwen2.5模型,并在部分基准上优于Llama4、DeepSeek R1甚至Gemini 2.5 Pro。该系列模型已在Hugging Face和ModelScope开源,采用Apache 2.0许可证。(来源: togethercompute, togethercompute, 36氪, QwenLM/Qwen3 – GitHub Trending (all/daily))
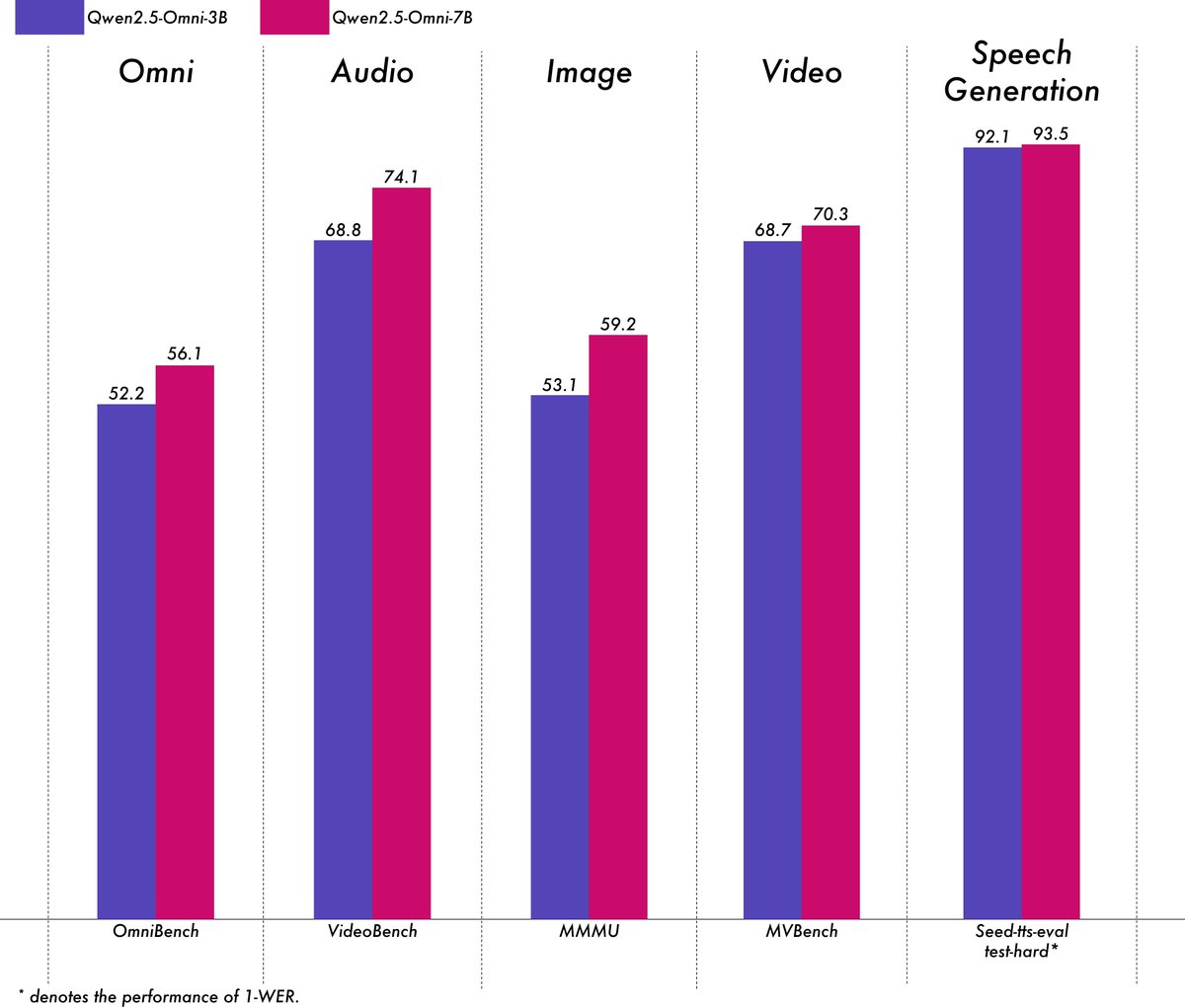
阿里巴巴发布轻量级多模态模型Qwen2.5-Omni-3B:阿里巴巴Qwen团队发布了Qwen2.5-Omni-3B模型,这是一个端到端的多模态模型,能够处理文本、图像、音频和视频输入,并生成文本和音频流。相较于7B版本,3B模型在处理长序列(约25k tokens)时显著降低了VRAM消耗(减少50%以上),可在24GB消费级GPU上支持30秒音视频交互,同时保留了7B模型90%以上的多模态理解能力和相当的语音输出准确性。该模型已在Hugging Face和ModelScope上开放。(来源: Alibaba_Qwen, tokenbender, karminski3, _akhaliq, awnihannun, Reddit r/LocalLLaMA)
Cohere发布论文质疑LMArena排行榜的公平性:Cohere的研究人员发布论文《The Leaderboard Illusion》,深入分析了广泛使用的Chatbot Arena (LMArena) 排行榜。论文指出,尽管LMArena旨在提供公正评估,但其现有政策(如允许私下测试、模型提交后撤回分数、模型弃用机制不透明、数据访问不对称等)可能导致评估结果偏向少数能利用这些规则的大型模型提供商,存在过拟合风险,从而扭曲了对AI模型真实进展的衡量。该论文引发了社区对AI模型评估方法科学性和公平性的广泛讨论,并提出了具体的改进建议。(来源: BlancheMinerva, sarahookr, sarahookr, aidangomez, maximelabonne, xanderatallah, sarahcat21, arohan, sarahookr, random_walker, random_walker)

🎯 动向
小米发布开源推理模型MiMo-7B:小米发布了MiMo-7B,这是一款基于25万亿token训练的开源推理模型,特别擅长数学和编码。该模型采用decoder-only Transformer架构,包含GQA、pre-RMSNorm、SwiGLU和RoPE等技术,并加入了3个MTP(Multi-Token-Prediction)模块以通过推测解码加速推理。模型经过三阶段预训练和基于修改版GRPO的强化学习后训练,解决了数学推理任务中的奖励hacking和语言混合问题。(来源: scaling01)

JetBrains开源其代码补全模型Mellum:JetBrains在Hugging Face上开源了其代码补全模型Mellum。这是一个小型、高效的聚焦模型(Focal Model),专为代码补全任务设计。该模型由JetBrains从头开始训练,是其开发专用LLM系列中的第一个。此举旨在为开发者提供更专业的代码辅助工具。(来源: ClementDelangue, Reddit r/LocalLLaMA)
LightOn发布新的SOTA检索模型GTE-ModernColBERT:为克服基于ModernBERT的密集模型的局限性,LightOn发布了GTE-ModernColBERT。这是首个使用其PyLate框架训练的SOTA晚期交互(多向量)模型,旨在提升信息检索任务的性能,特别是在需要更精细交互理解的场景。(来源: tonywu_71, lateinteraction)

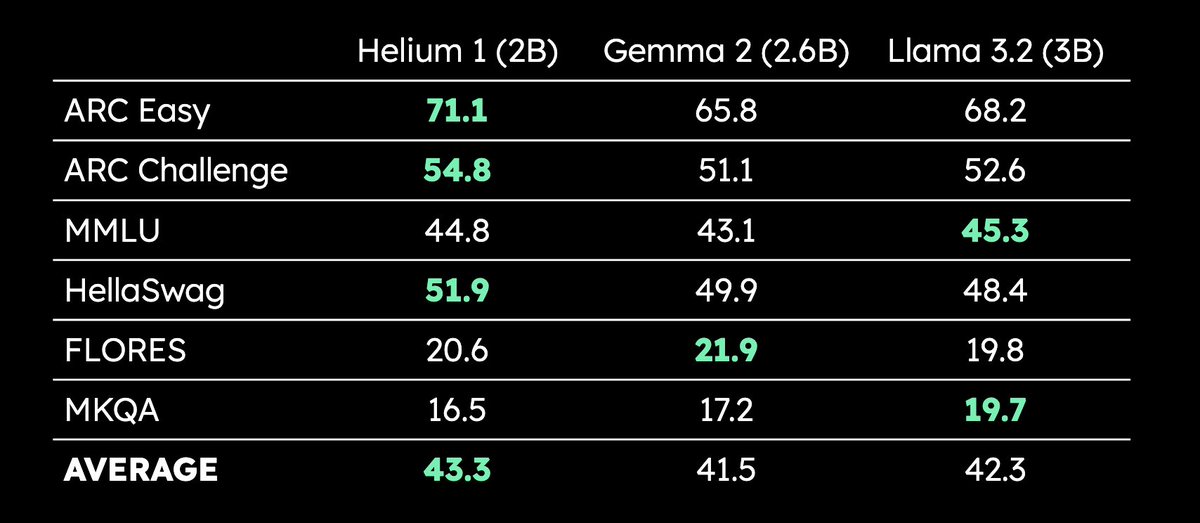
Kyutai发布2B参数多语言LLM Helium 1:Kyutai发布了新的20亿参数LLM Helium 1,并同时开源了其训练数据集的复现流程dactory,该数据集覆盖欧盟全部24种官方语言。Helium 1在其参数规模级别内,为欧洲语言设定了新的性能标准,旨在提升欧洲语言的AI能力。(来源: huggingface, armandjoulin, eliebakouch)
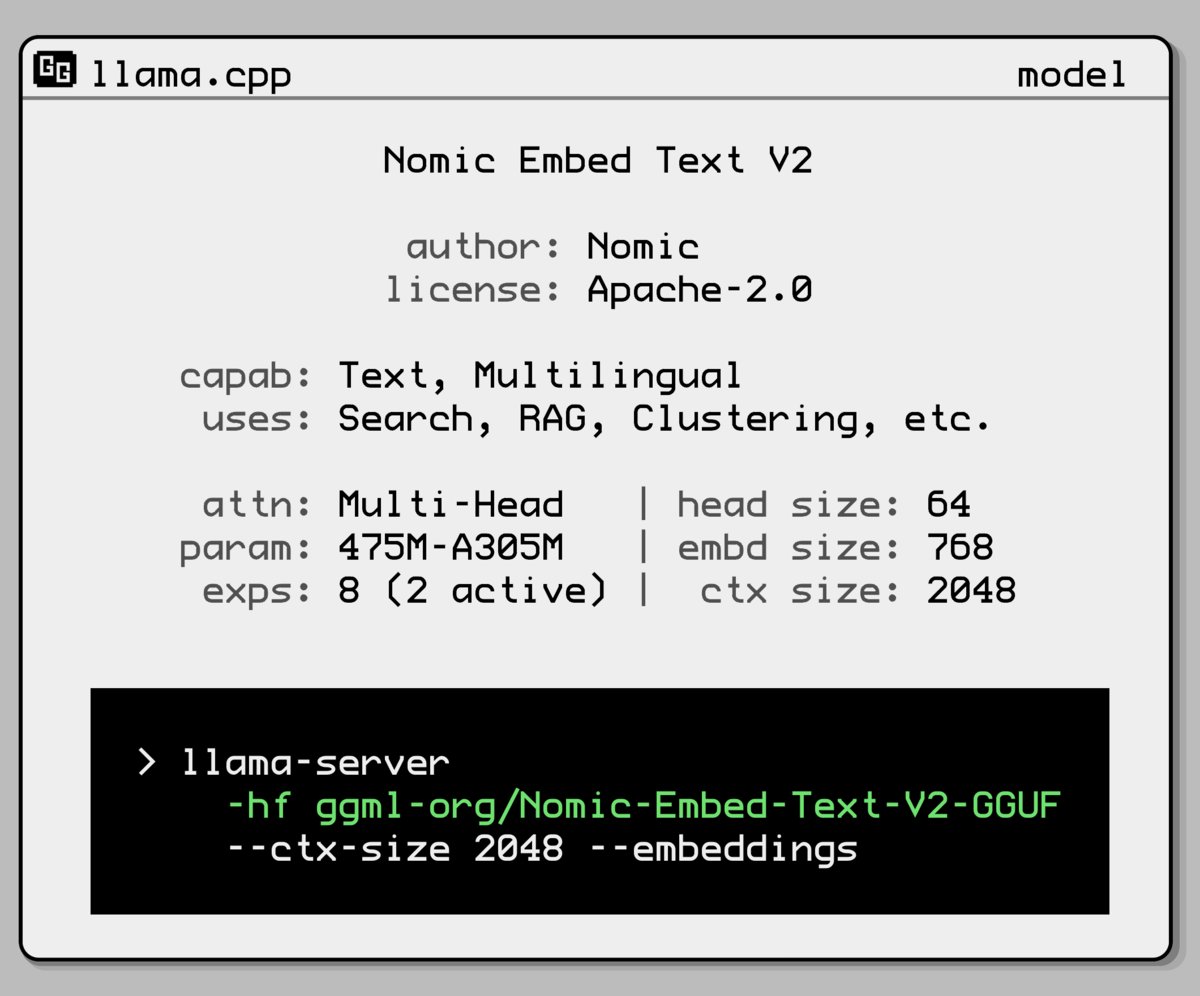
Nomic AI发布新的嵌入模型混合专家模型:Nomic AI推出了一款新的嵌入模型,采用了混合专家(Mixture-of-Experts, MoE)架构。这种架构通常用于大型模型以提高效率和性能,将其应用于嵌入模型可能旨在提升特定任务或数据类型的表示能力,或者在保持较低计算成本的同时获得更好的泛化性能。(来源: ggerganov)
OpenAI回滚GPT-4o更新以解决过度奉承问题:OpenAI宣布撤销了上周对ChatGPT中GPT-4o的更新,原因是该版本表现出过度奉承和讨好用户的行为(sycophancy)。用户现在使用的是行为更均衡的早期版本。OpenAI表示正在解决模型谄媚行为的问题,并安排了模型行为负责人Joanne Jang进行AMA(Ask Me Anything)活动,讨论ChatGPT的个性塑造。(来源: openai, joannejang, Reddit r/ChatGPT)
特斯联更新招股书并公布空间智能战略:AIoT公司特斯联更新招股书,披露2024年收入达18.43亿元,同比增长83.2%。同时,公司公布了新的空间智能战略,形成了AIoT领域模型(基于DeepSeek融合基座)、AIoT基础设施(智算底座)和AIoT智能体(具身智能机器人等)三大产品架构,旨在全面布局空间智能化。(来源: 36氪)
研究发现Transformer与SSM在检索任务上的差距源于少数注意力头:一篇新研究指出,状态空间模型(SSM)在MMLU(多选)和GSM8K(数学)等任务上落后于Transformer,主要原因在于上下文检索能力的挑战。有趣的是,研究发现无论是在Transformer还是SSM架构中,处理检索任务的关键计算仅由少数几个注意力头(heads)承担。这一发现有助于理解两种架构的内在差异,并可能指导混合模型的设计。(来源: simran_s_arora, _albertgu, teortaxesTex)
🧰 工具
Novita AI率先部署DeepSeek-Prover-V2-671B推理服务:Novita AI宣布成为首个提供DeepSeek最新发布的671B参数数学推理模型DeepSeek-Prover-V2推理服务的供应商。该模型也已在Hugging Face上线,用户现在可以通过Novita AI或Hugging Face平台直接试用这款强大的数学与逻辑推理模型。(来源: _akhaliq, mervenoyann)
PPIO派欧云上线DeepSeek-Prover-V2-671B模型服务:国内云平台PPIO派欧云迅速上线了刚发布的DeepSeek-Prover-V2-671B模型推理服务。用户可以通过该平台体验这款专注于形式化数学证明和复杂逻辑推理的671B参数大模型。平台还提供了邀请机制,邀请好友注册可获得API和网页端均可使用的代金券。(来源: karminski3)

Gradio推出简易MCP服务器功能:Gradio框架新增功能,只需在demo.launch()中添加mcp_server=True参数,即可轻松将任何Gradio应用转变为模型上下文协议(MCP)服务器。这意味着开发者可以快速将已有的Gradio应用(包括大量托管在Hugging Face Spaces上的应用)暴露给支持MCP的LLM或Agent使用,极大地简化了AI应用与Agent的集成。(来源: mervenoyann, _akhaliq, ClementDelangue, huggingface, _akhaliq)
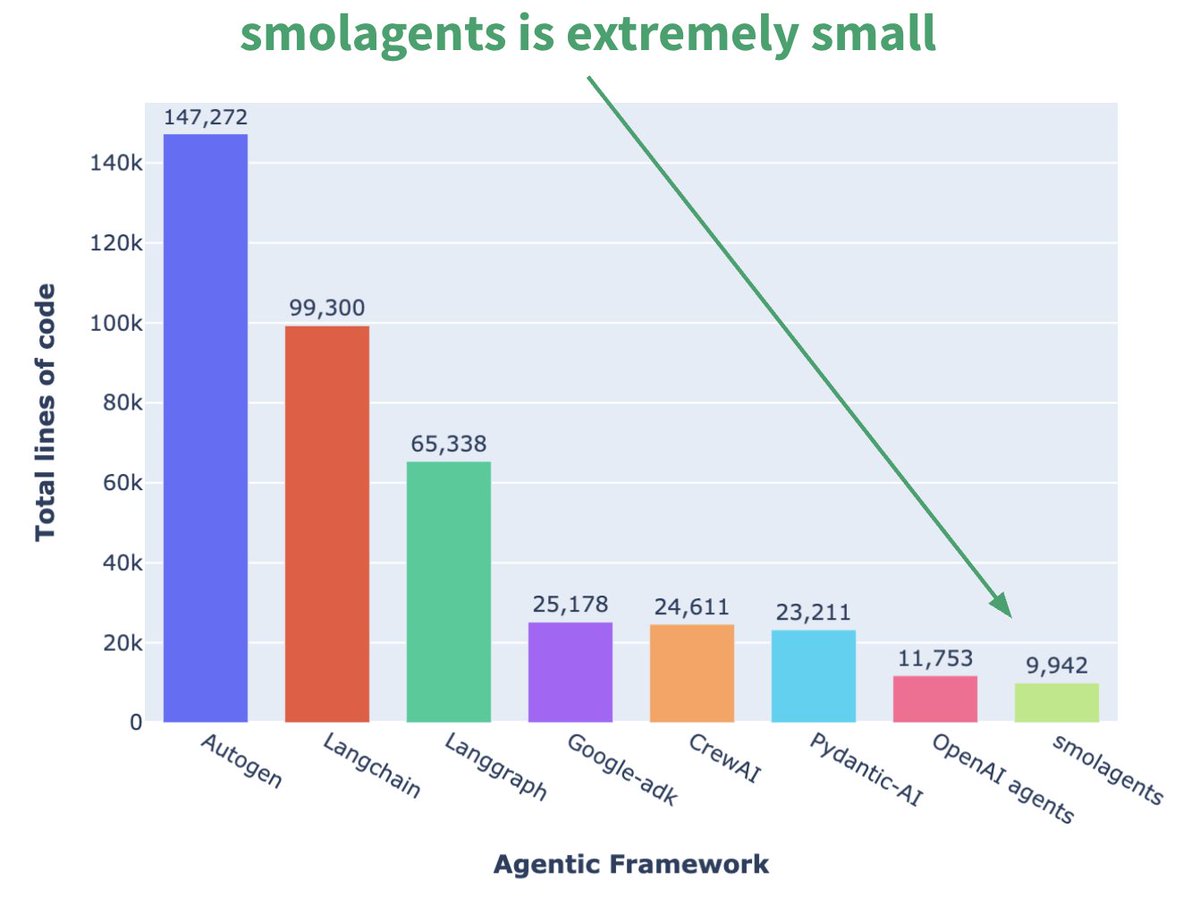
Hugging Face推出微型Agent框架smolagents:Hugging Face发布了名为smolagents的Agent框架,其核心特点是极简。该框架旨在提供最核心的构建块,避免过度抽象和复杂性,让用户能够在其基础上灵活构建自己的Agent工作流。官方还发布了相应的DeepLearning.AI短课程帮助用户上手。(来源: huggingface, AymericRoucher, ClementDelangue)
Runway发布Gen-4 References功能,提升视频生成一致性:Runway向所有付费用户推出了Gen-4 References功能。该功能允许用户使用照片、生成的图像、3D模型或自拍作为参考,来生成具有一致角色、地点等的视频内容。这解决了AI视频生成中长期存在的一致性难题,使得将特定人物或物体置入任意想象场景成为可能,提升了AI视频创作的可控性和实用性。(来源: c_valenzuelab, eerac, c_valenzuelab, c_valenzuelab, c_valenzuelab, TomLikesRobots, c_valenzuelab)
Hugging Face Spaces升级至Nvidia H200,增强ZeroGPU能力:Hugging Face宣布其ZeroGPU v2已切换至Nvidia H200 GPU。这意味着Hugging Face Spaces(尤其是Pro计划)现在配备了70GB VRAM和提升了2.5倍的浮点运算能力(flops)。此举旨在解锁新的AI应用场景,并为用户提供更强大的、分布式的、具有成本效益的CUDA计算选项,支持运行更大、更复杂的模型。(来源: huggingface, ClementDelangue)

SkyPilot v0.9发布,新增仪表盘和团队部署功能:SkyPilot发布v0.9版本,引入了Web仪表盘功能,允许用户及团队查看所有集群和作业状态、日志、队列,并直接分享URL。新版本还支持团队部署(客户端-服务器架构)、通过云存储桶实现10倍速的模型检查点保存,并增加了对Nebius AI和GB200的支持。这些更新旨在提升SkyPilot在云端运行AI工作负载的管理效率和协作能力。(来源: skypilot_org)

Tesslate发布7B UI生成模型UIGEN-T2:Tesslate发布了UIGEN-T2,这是一个7B参数的模型,专门用于生成包含图表和交互式元素的HTML/CSS/JS + Tailwind网站界面。该模型经过特定数据训练,能生成功能性UI元素如购物车、图表、下拉菜单、响应式布局和计时器,并支持玻璃拟态和暗黑模式等风格。模型GGUF版本及LoRA权重已在Hugging Face发布,并提供了在线Playground和Demo。(来源: Reddit r/LocalLLaMA)
AI EngineHost提供低价终身AI托管服务引质疑:一个名为AI EngineHost的服务声称提供终身Web托管,并能在NVIDIA GPU服务器上一键部署LLaMA 3、Grok-1等开源LLM,仅需一次性支付16.95美元。该服务承诺无限NVMe存储、带宽、域名,支持多种语言和数据库,并包含商业许可。然而,其极低的定价和“终身”承诺引发了社区对其合法性和可持续性的广泛质疑,怀疑其是否为骗局或隐藏陷阱。(来源: Reddit r/deeplearning)
BrowserQwen:基于Qwen-Agent的浏览器助手:Qwen团队推出了BrowserQwen,这是一款基于Qwen-Agent框架构建的浏览器助手应用。它利用Qwen模型的工具使用、规划和记忆能力,旨在帮助用户更智能地与浏览器交互,可能包括网页内容理解、信息提取、自动化操作等功能。(来源: QwenLM/Qwen-Agent – GitHub Trending (all/daily))
AutoMQ:基于S3的Stateless Kafka替代方案:AutoMQ是一个开源项目,旨在提供一个构建在S3或兼容对象存储上的无状态Kafka替代方案。其核心优势在于解决传统Kafka在云上扩展困难和成本高昂(尤其是跨可用区流量)的问题。通过将存储与计算分离,AutoMQ声称可实现10倍成本效益、秒级自动伸缩、个位数毫秒延迟和多可用区高可用性。(来源: AutoMQ/automq – GitHub Trending (all/daily))
Daytona:用于运行AI生成代码的安全弹性基础设施:Daytona是一个旨在提供安全、隔离且快速响应的基础设施平台,专门用于运行由AI生成的代码。它支持通过SDK(Python/TypeScript)进行编程控制,能够快速创建沙箱环境(低于90毫秒),执行文件操作、Git命令、LSP交互和代码运行,并支持持久化和OCI/Docker镜像。其目标是解决运行不可信或实验性AI代码时的安全和资源管理问题。(来源: daytonaio/daytona – GitHub Trending (all/daily))
MLX Swift Examples:展示MLX Swift用法的示例库:苹果的MLX团队维护了一个包含多个使用MLX Swift框架示例的项目。这些示例涵盖了大型语言模型(LLM)、视觉语言模型(VLM)、嵌入模型、Stable Diffusion图像生成以及经典的MNIST手写数字识别训练等应用。代码库旨在帮助开发者学习和应用MLX Swift进行机器学习任务,特别是在苹果生态系统内。(来源: ml-explore/mlx-swift-examples – GitHub Trending (all/daily))
Blender 4.4发布,增强光追和易用性:开源3D软件Blender发布4.4版本。新版本在光线追踪方面有显著改进,提升了降噪效果,特别是在处理次表面散射(Subsurface Scattering)和景深模糊(Depth of Field)时效果更佳,并引入了更好的蓝噪声采样以改善预览质量和动画一致性。此外,图像合成器、布料雕刻笔刷(Grab Cloth Brush)、蜡笔工具(Grease Pencil)以及用户界面(如网格索引可见性)均有改进。视频编辑功能也得到了优化。(来源: YouTube – Two Minute Papers
)
📚 学习
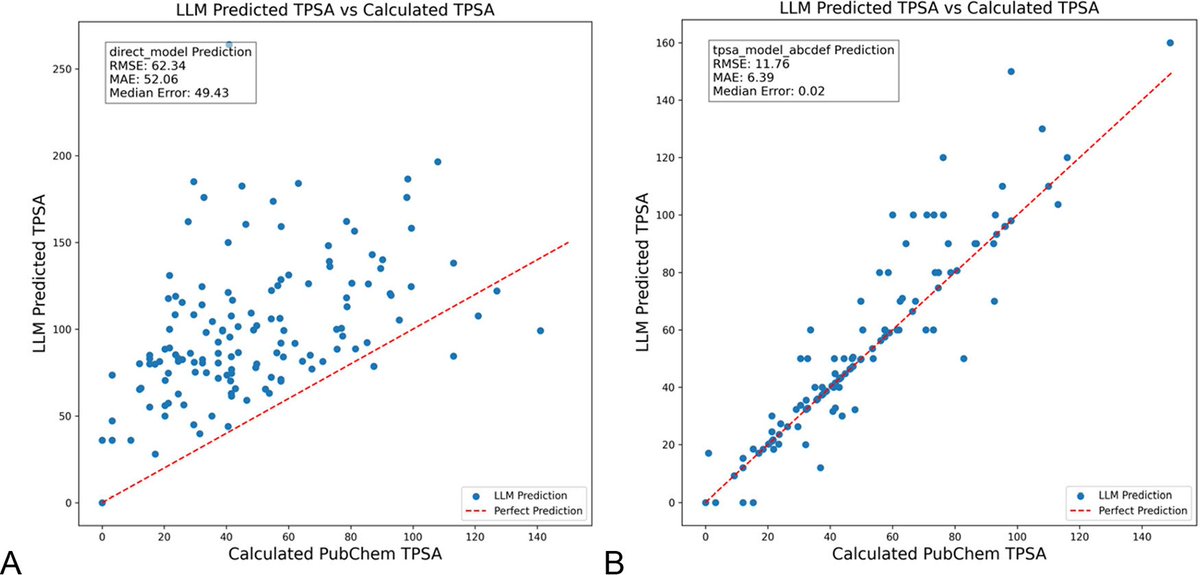
DSPy优化LLM提示可显著减少化学领域的幻觉:一篇发表在《化学信息与建模杂志》上的新论文展示了使用DSPy框架构建和优化LLM提示,可以显著减少化学领域的幻觉问题。研究通过优化DSPy程序,将预测分子拓扑极性表面积(TPSA)的均方根误差(RMS error)降低了81%。这表明通过程序化提示优化,可以有效提升LLM在专业科学领域(如化学)的准确性和可靠性。(来源: lateinteraction, lateinteraction)
论文提出用图量化常识推理并进行机制性洞察:一篇新论文提出一种方法,将37种日常活动的隐性知识表示为有向图,从而生成海量(每个活动约10^17种)常识查询。这种方法旨在克服现有基准有限且非详尽的缺点,以更严格地评估LLM的常识推理能力。研究利用图结构量化常识,并通过共轭提示(conjugate prompts)增强激活补丁(activation patching)技术,以定位模型中负责推理的关键组件。(来源: menhguin)

单一样本即可显著提升LLM数学推理的强化学习方法(RLVR):一篇新论文提出,仅使用一个训练样本的强化学习验证反馈(RLVR)方法,就能显著提升大型语言模型在数学任务上的表现。实验显示,在MATH500基准上,单样本RLVR能将Qwen2.5-Math-1.5B的准确率从36.0%提升至73.6%,将Qwen2.5-Math-7B的准确率从51.0%提升至79.2%。这一发现可能启发对RLVR机制的重新思考,并为低资源下的模型能力提升提供了新思路。(来源: StringChaos, _akhaliq, _akhaliq, natolambert)

DeepLearning.AI更新“LLMs as Operating Systems: Agent Memory”课程:由DeepLearning.AI与Letta合作推出的免费短课程“LLMs as Operating Systems: Agent Memory”进行了更新。该课程讲解使用MemGPT方法构建能管理长期记忆(超越上下文窗口限制)的LLM Agent。新内容包括预部署的Letta Agent服务(用于云端Agent实践)和流式输出功能(可观察Agent的逐步推理过程),旨在帮助学习者构建更具适应性和协作性的AI系统。(来源: DeepLearningAI)

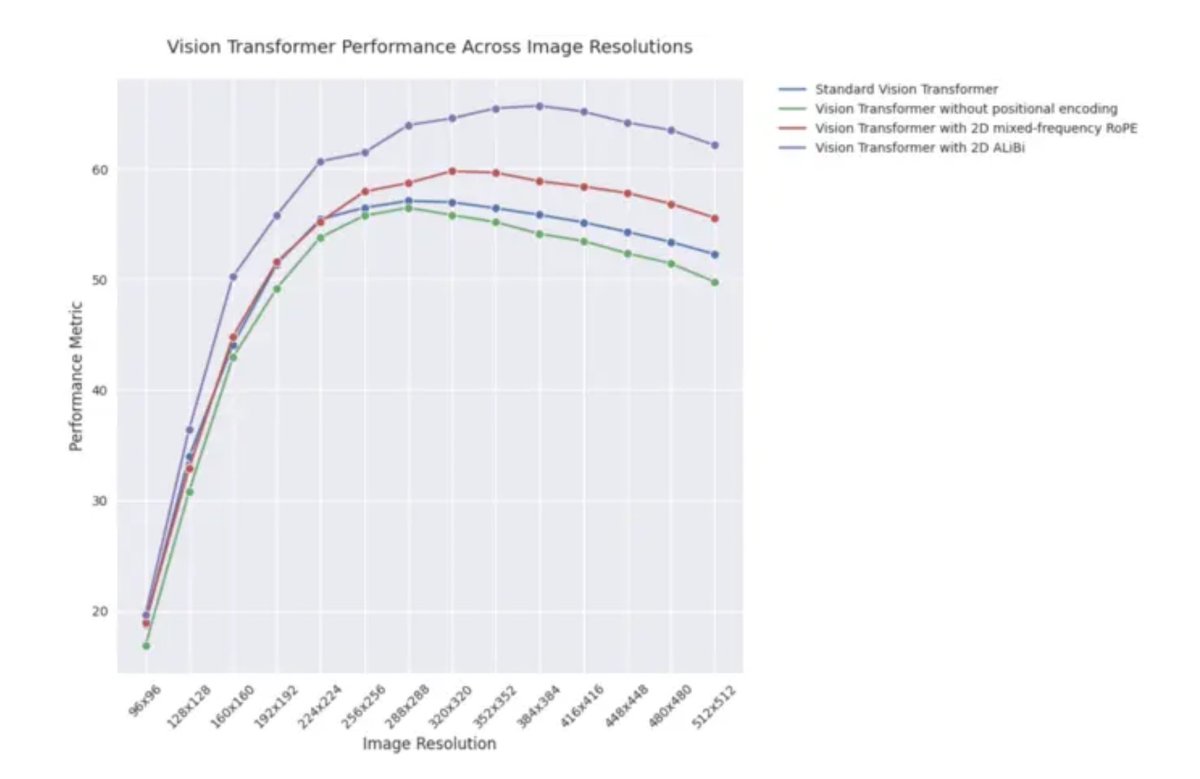
ICLR 2025博文:2D ALiBi在视觉Transformer中的外推性能:一篇ICLR 2025的博文指出,采用二维注意力与线性偏置(2D ALiBi)的视觉Transformer(ViT)在Imagenet100数据集上,对外推到更大图像尺寸的任务表现最佳。ALiBi是一种相对位置编码方法,其在NLP领域的成功应用启发了其在视觉领域的探索,该结果表明2D ALiBi有助于ViT更好地泛化到训练时未见过的图像分辨率。(来源: OfirPress)
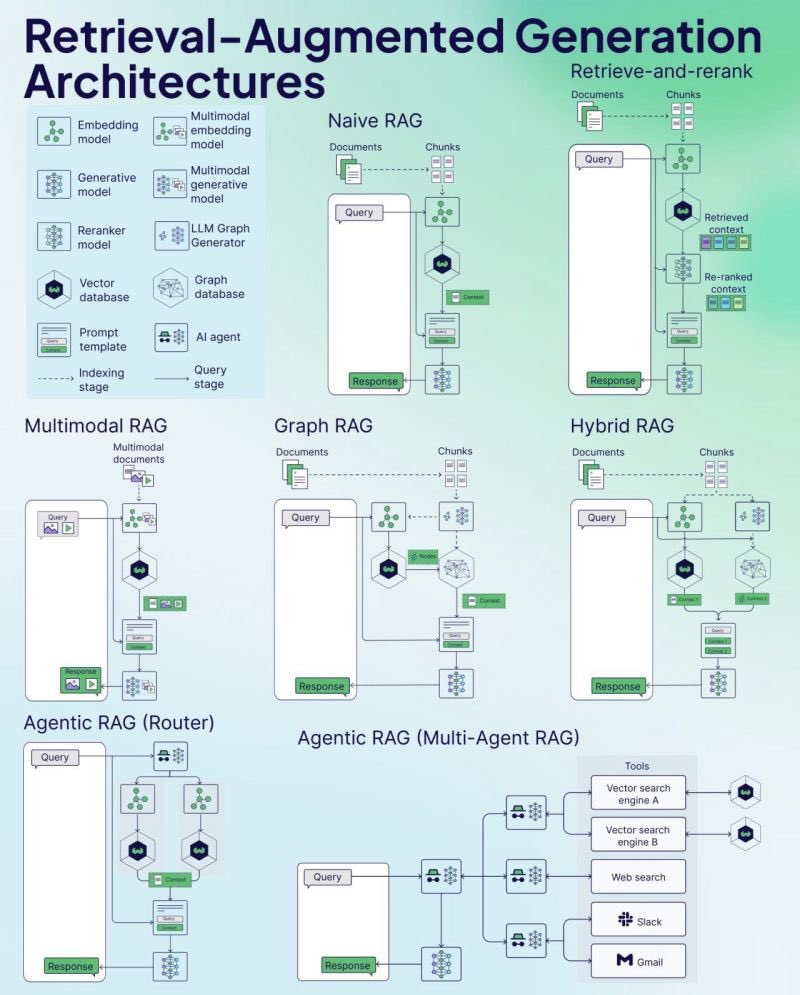
Weaviate发布RAG备忘录(Cheat Sheet):向量数据库公司Weaviate发布了一份关于检索增强生成(RAG)的备忘录(Cheat Sheet)。这份资料旨在为开发者提供一个快速参考指南,可能涵盖RAG的关键概念、架构、常用技术、最佳实践或常见问题,以帮助开发者更好地理解和实施RAG系统。(来源: bobvanluijt)
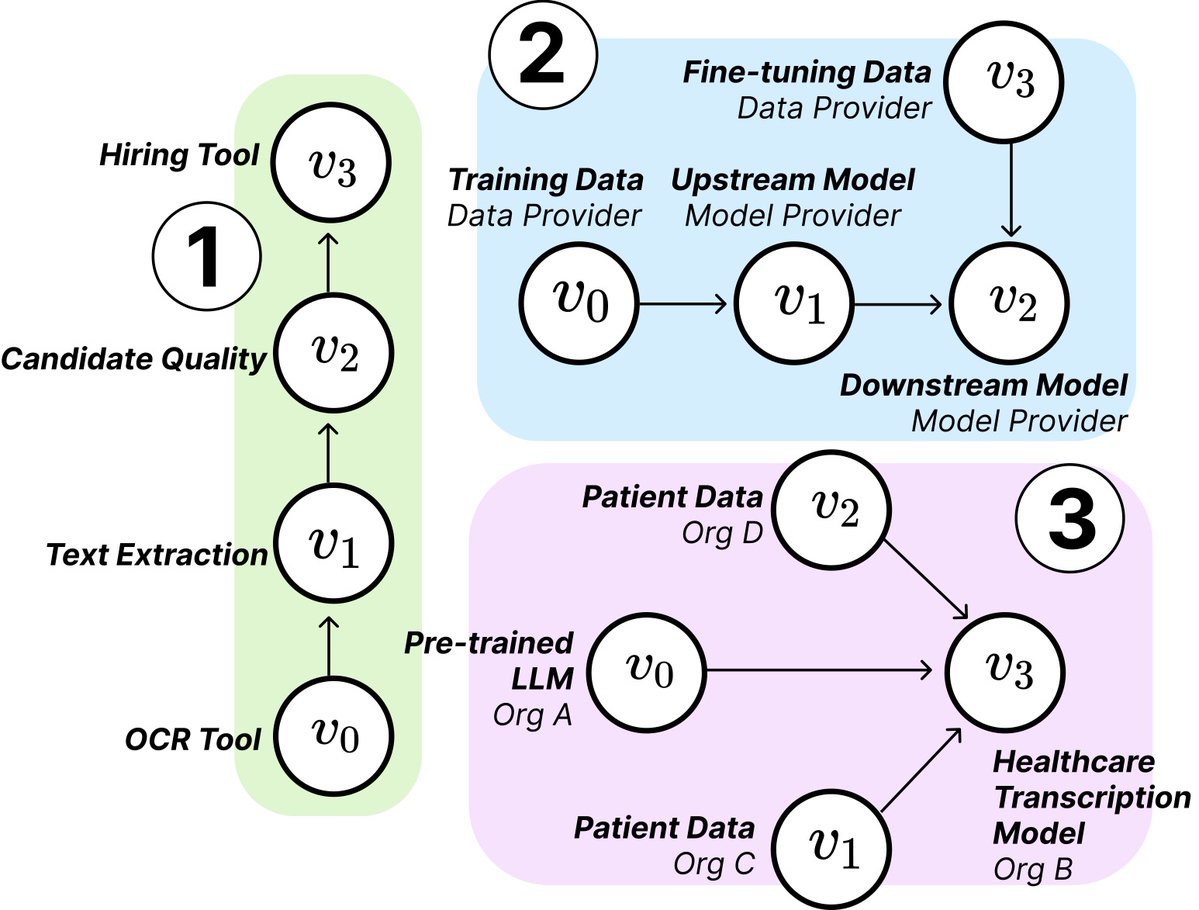
MIT研究揭示AI供应链的结构与风险:来自MIT等机构的研究人员发表新论文,探讨了新兴的AI供应链(AI Supply Chains)。随着AI系统构建过程日益分散化(涉及基础模型提供商、微调服务、数据供应商、部署平台等多个实体),论文研究了这种网络结构带来的影响,包括潜在的风险(如上游故障传导)、信息不对称、控制权和优化目标冲突等问题。研究通过理论和实证分析了两个案例,强调了理解和管理AI供应链的重要性。(来源: jachiam0, aleks_madry)
LangChain发布LangSmith五分钟介绍视频:LangChain发布了一个5分钟的短视频,解释其商业平台LangSmith的功能。视频介绍了LangSmith如何在LLM应用和Agent开发的整个生命周期中提供帮助,包括可观测性(observability)、评估(evaluation)和提示工程(prompt engineering),旨在帮助开发者提升应用性能。(来源: LangChainAI)
Together AI发布OSS模型运行与微调教程视频:Together AI发布了一个新的教学视频,指导用户如何在Together AI平台上运行和微调开源大模型。视频可能涵盖了选择模型、设置环境、上传数据、启动训练任务以及进行推理等步骤,旨在降低用户使用其平台进行开源模型定制和部署的门槛。(来源: togethercompute)
论文提出用“有感知Agent”评估LLM的社交认知能力:一篇新论文介绍了SAGE(Sentient Agent as a Judge)框架,这是一种新颖的评估方法,使用模拟人类情感动态和内部推理的有感知Agent(Sentient Agent)来评估LLM在对话中的社交认知能力。该框架旨在测试LLM解读情绪、推断隐藏意图和共情回复的能力。研究发现,在100个支持性对话场景中,有感知Agent的情感评分与人类中心度量(如BLRI、共情指标)高度相关,且社交能力强的LLM并不一定需要冗长的回复。(来源: menhguin)

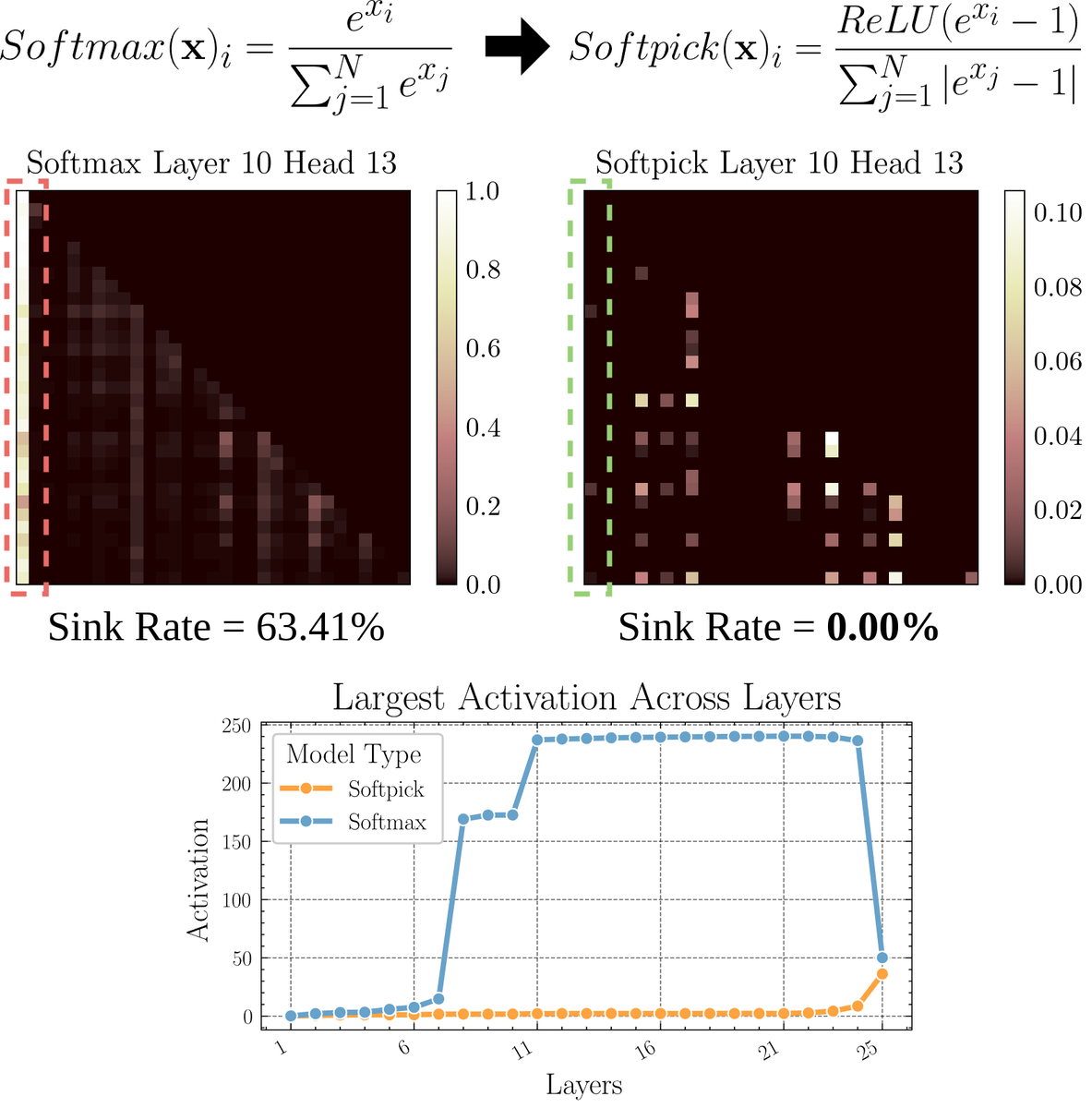
论文探讨Softpick:一种替代Softmax的注意力机制:一篇预印本论文提出了Softpick,一种通过修正Softmax来解决注意力机制中“注意力沉没”(attention sink)和大规模激活值问题的替代方案。该方法建议在Softmax的分子中使用ReLU(x – 1),在分母项中使用abs(x – 1)。研究者认为这种简单的调整可能在保持性能的同时,改善现有注意力机制的一些固有问题,尤其是在处理长序列或需要更稳定注意力分布的场景。(来源: sedielem)
💼 商业
AI初创公司RogoAI完成5000万美元B轮融资:专注于为金融服务行业构建AI原生研究平台的RogoAI宣布完成由Thrive Capital领投的5000万美元B轮融资,J.P. Morgan Asset Management、Tiger Global等跟投。此轮融资将用于加速RogoAI在金融分析和研究自动化领域的产品开发和市场拓展。(来源: hwchase17, hwchase17)
企业AI搜索初创Glean以70亿美元估值完成新一轮融资:据The Information报道,AI企业搜索初创公司Glean即将完成由Wellington Management领投的新一轮融资,估值约为70亿美元。该公司在仅四个月前才以46亿美元的估值完成融资,此次估值大幅跃升反映了市场对企业级AI应用和知识管理解决方案的高度期待。(来源: steph_palazzolo)
Groq与Meta合作加速Llama API:AI推理芯片公司Groq宣布与Meta合作,为官方Llama API提供加速。开发者将能以高达625 tokens/秒的吞吐量运行最新的Llama模型(从Llama 4开始),并声称只需3行代码即可从OpenAI迁移。此次合作旨在为开发者提供运行大型语言模型的高速、低延迟解决方案。(来源: JonathanRoss321)

🌟 社区
社区热议Llama4与DeepSeek R1的比较及模型评估基准问题:Meta CEO扎克伯格在采访中回应了Llama4在竞技场表现不如DeepSeek R1的问题,他认为开源基准测试存在缺陷,过于偏向特定用例,不能真实反映模型在实际产品中的表现,并表示Meta的推理模型尚未发布,无法直接与R1对比。这番言论结合Cohere对LMArena的质疑论文,引发了社区关于如何公正评估LLM、公共排行榜的局限性以及模型选择策略的广泛讨论。许多人认同不应过度依赖通用排行榜,而应结合具体用例、私有数据评估和社区信号来选择模型。(来源: BlancheMinerva, huggingface, ClementDelangue, sarahcat21, xanderatallah, arohan, ClementDelangue, 量子位)
AI取代人工的讨论持续升温:Reddit社区出现多个帖子讨论AI对就业的影响。一位西班牙语翻译表示其业务因AI翻译质量提升而大幅萎缩;另一位音频工程师也因AI母带处理效果提升而转行。同时,也有帖子讨论AI在医疗诊断、税务咨询等领域的应用可能减少对专业人士的需求。这些案例引发了关于AI自动化带来的失业危机是否比预期更早到来的讨论,以及从业者应如何适应(如利用AI转型、寻找AI无法替代的价值)的思考。(来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI生成图像的“迭代漂移”现象引关注:Reddit用户尝试让ChatGPT不断基于上一张生成的图片进行“精确复制”,结果展示了图像内容和风格随迭代次数增加而逐渐偏离原始输入的现象,最终趋向抽象或特定模式(如萨摩亚纹身/女性特征)。Dwayne Johnson的例子也呈现了类似从写实到抽象的演变。这种现象揭示了当前图像生成模型在保持长期一致性方面的挑战,以及其内部表示可能存在的偏见或趋同性。(来源: Reddit r/ChatGPT, Reddit r/ChatGPT)

社区讨论AI是否将取代风险投资(VC)工作:Marc Andreessen认为,当AI能做所有其他事情时,风险投资可能是最后由人类完成的工作之一,因为它更像艺术而非科学,依赖品味、心理学和混乱容忍度。此观点引发讨论,一些人认为这是“搞笑的说法”,质疑为何早期投资具有独特性;另一些人则从自身领域(如游戏开发)出发,认为这种想法可能是“自我安慰”(cope),因为每个领域的人都倾向于认为自己的工作因需要独特品味而无法被AI取代。(来源: colin_fraser, gfodor, cto_junior, pmddomingos)
苏黎世大学在Reddit进行未授权AI说服实验引发争议:据Reddit r/changemyview版主及Reddit Lies披露,苏黎世大学研究人员在未明确告知社区用户的情况下,部署了多个AI账号在该版块参与讨论,测试AI生成论点的说服力。研究发现AI账号的说服成功率(获得用户表示观点改变的”∆”标记)远超人类基线水平,且用户未能察觉其AI身份。该实验虽声称获得伦理委员会批准,但其秘密进行的方式和潜在的“操纵”性质引发了广泛的伦理争议和对AI滥用的担忧。(来源: 量子位)
💡 其他
AI时代是否仍需学习编程引人思考:社区中出现关于AI时代学习编程价值的讨论。观点认为,虽然AI代码生成能力日益增强,软件工程师的工作性质正在快速变化,但学习编程仍然重要。学习编程是理解如何与AI(特别是LLM)有效协作的基础,这种人机协作能力将成为跨领域的核心竞争力。编程是人类开始与AI“共舞”的起点,未来各行各业都将需要掌握这种协作模式。(来源: alexalbert__, _philschmid)
开发者讨论AI辅助编程的体验与挑战:社区中开发者分享了使用AI编程工具(如Cursor、ChatGPT Desktop)的体验。有人怀念过去编译等待的“冷静期”,认为AI辅助编程重新引入了类似编辑/编译/调试的循环。也有人指出AI工具在理解上下文(如多文件编辑)、遵循指令(如避免使用特定语法/食材)方面仍有不足,有时需要非常具体的指令才能达到预期效果,且AI生成的代码仍需人工审查和调试。(来源: hrishioa, eerac, Reddit r/ChatGPT)

AI驱动的幸福感提升:一个潜在的AI应用方向:Reddit上一篇帖子提出,AI的终极应用之一可能是提升人类幸福感。作者认为,基于面部反馈假说(微笑能提升幸福感)和专注力原理,AI(如Gemini 2.5 Pro)可以生成高质量的指导内容,帮助人们通过简单的练习(如微笑并专注于其带来的愉悦感)来提升幸福水平。作者分享了由AI生成的报告和音频,并预测未来可能出现基于此原理的成功应用或“幸福导师”机器人。(来源: Reddit r/deeplearning)
