
关键词:文心大模型, AI模型, 多模态, Agent, 文心4.5 Turbo, X1 Turbo, DeepSeek V3, 多模态理解, 百度心响, MCP协议, AI付费模式, LoRA模型推理
🔥 聚焦
百度发布文心4.5 Turbo与X1 Turbo,对标DeepSeek: 在2025年百度Create大会上,李彦宏发布文心大模型4.5 Turbo和X1 Turbo,强调多模态理解与生成能力,并指出其成本分别仅为DeepSeek V3的40%和DeepSeek R1的25%。李彦宏认为多模态是未来趋势,纯文本模型市场将缩小。此次发布旨在弥补DeepSeek在多模态和成本上的不足,展示了百度在模型层面与行业领先者竞争的决心。(来源:36氪)

AI模型性能比拼:o3与Gemini 2.5 Pro各有千秋: OpenAI的o3和Google的Gemini 2.5 Pro在多项新基准测试中展现出激烈竞争。o3在长文本小说谜题解析(FictionLiveBench)上表现更优,而Gemini 2.5 Pro在物理与空间推理(PHYBench)、数学竞赛(USMO)及地理定位(GeoGuessing)方面领先,且成本更低(约为o3的1/4)。视觉谜题(Visual Puzzles)和基础视觉问答(NaturalBench)各有胜负。这表明当前顶尖模型的性能高度依赖于具体任务和评测基准,没有绝对的领先者。(来源:o3 breaks (some) records, but AI becomes pay-to-win
)
AI走向“付费取胜”模式: 行业观察指出,随着AI模型能力的提升与应用拓展,获取顶尖AI能力可能越来越需要付费。Google、OpenAI、Anthropic等公司纷纷推出或计划推出更高价格的订阅服务(如Premium Plus/Pro,月费或达$100-$200)。这反映了模型训练(尤其是RL后训练)和大规模推理所需的高昂计算成本,以及公司在模型研发、新功能、低延迟和用户增长之间平衡计算资源的需求。未来,免费或低价AI服务可能与付费尖端服务在能力上拉开差距。(来源:o3 breaks (some) records, but AI becomes pay-to-win
)
百度推出移动端Agent应用“心响”: 百度在Agent领域布局加速,发布了移动端Agent应用“心响”,对标Manus等产品。“心响”旨在通过对话理解用户需求,并调度百度及第三方智能体执行和交付任务(如制作绘本、旅游规划、法律咨询等)。产品强调建立用户的“托管心智”,通过展示任务执行流程来区别于传统搜索的即时交付。目前支持200+种任务,未来计划扩展至10万+,并研发PC端。(来源:36氪)
🎯 动向
百度全面拥抱MCP Agent协议: 百度宣布旗下多项产品和服务,包括智能云千帆大模型平台、百度搜索、文心快码、百度电商、地图、网盘、文库等,均已支持或兼容Anthropic提出的模型上下文协议(MCP)。MCP旨在标准化AI模型与外部工具、数据库的交互方式,提高不同AI软件间的适配、开发和维护效率。百度的支持有助于构建更开放、互联互通的AI应用生态,使Agent能够更自由地调用各种工具和服务。(来源:36氪)
OpenAI更新GPT-4o,提升智能与个性: OpenAI CEO Sam Altman宣布对GPT-4o模型进行了更新,声称提升了模型的智能和个性化表现。然而,此次更新并未提供具体的评估数据、版本说明或详细的改进细节,引发了社区对于AI模型更新透明度的讨论和批评。(来源:sama, natolambert)
Google Veo 2视频生成登陆Whisk: Google宣布,其视频生成模型Veo 2已集成到Whisk应用中,允许Google One AI Premium订阅用户(覆盖60+国家)创建长达8秒的视频。用户可以选择不同的视频风格进行创作,进一步拓展了Google AI在多模态内容生成方面的能力。(来源:Google)

Hugging Face新增3万+ LoRA模型推理服务: Hugging Face宣布通过其Inference Providers(由FAL提供支持)为超过30,000个Flux和SDXL LoRA模型提供推理服务。用户现在可以直接在Hugging Face Hub上使用这些LoRA进行图像生成,据称速度快(约5秒生成)且成本低(低于1美元可生成40+张图像),极大地扩展了社区用户可用的微调模型资源。(来源:Vaibhav (VB) Srivastav, gokaygokay)
Modular AI (Mojo/MAX) 进展更新: Modular AI在成立三年后取得显著进展,其Mojo语言和MAX平台现已支持更广泛的硬件,包括x86/ARM CPU以及NVIDIA (A100/H100) 和AMD (MI300X) GPU。公司计划很快开源约25万行GPU内核代码,并简化了Mojo和MAX的许可证。这表明Modular正逐步兑现其提供CUDA替代方案和跨硬件AI开发平台的承诺。(来源:Reddit r/LocalLLaMA)
Intel PyTorch扩展更新,支持DeepSeek-R1: Intel发布了其PyTorch扩展(IPEX)2.7版本,增加了对DeepSeek-R1模型的支持,并引入了新的优化措施,旨在提升在Intel硬件(包括CPU和GPU)上运行PyTorch工作负载的性能。此举有助于扩大Intel AI硬件生态对流行模型和框架的支持。(来源:Phoronix)

发现通用LLM安全绕过漏洞“Policy Puppetry”: 安全研究机构HiddenLayer披露了一种名为“Policy Puppetry”的新型通用旁路漏洞,据称能影响所有主流大型语言模型。该漏洞可能允许攻击者更容易地绕过模型的安全防护机制,生成有害或被禁止的内容,对当前LLM的安全对齐和防护策略提出了新的挑战。(来源:HiddenLayer)

Anthropic或允许模型因“不适”拒绝用户: 据纽约时报报道,Anthropic正在考虑赋予其AI模型(如Claude)一项新能力:如果模型判断用户的请求过于“令人痛苦”或不适(distressing),模型可以选择停止与该用户的对话。这涉及到新兴的“AI福祉”(AI welfare)概念,可能引发关于AI权利、用户体验和模型可控性的新讨论。(来源:NYTimes)

发布面向Rust的7B代码模型Tessa: Hugging Face上出现了一款名为Tessa-Rust-T1-7B的70亿参数模型,据称专注于Rust代码生成和推理,并附带开放数据集。然而,社区评论指出,其数据集的生成方法、正确性验证和评估细节缺乏透明度,对模型实际效果持谨慎态度。(来源:Hugging Face)

🧰 工具
Plandex:面向大型项目的开源AI编码助手: Plandex是一个终端内的AI开发工具,专为处理跨越多文件、多步骤的大型编码任务而设计。它支持高达200万token的上下文,能索引大型代码库,并提供累积差异审查沙箱、可配置的自主性、多模型支持(Anthropic, OpenAI, Google等)、自动调试、版本控制和Git集成等功能,旨在解决复杂实际项目中的AI编码挑战。(来源:GitHub Trending)
LiteLLM:统一调用百余种LLM API的SDK与代理: LiteLLM提供Python SDK和代理服务器(LLM网关),允许开发者使用统一的OpenAI格式调用超过100种LLM API(如Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Groq等)。它负责处理API输入的转换、确保输出格式一致、实现跨部署的重试/回退逻辑,并通过代理服务器提供API密钥管理、成本追踪、速率限制和日志记录等功能。(来源:GitHub Trending)

Hyprnote:本地优先、可扩展的AI会议笔记: Hyprnote是一款专为会议场景设计的AI笔记应用。它强调本地优先和隐私保护,可在离线状态下使用开源模型(Whisper进行录音转录,Llama进行笔记摘要生成)。其核心特点是可扩展性,用户可以通过插件系统添加或创建新功能,满足个性化需求。(来源:GitHub Trending)

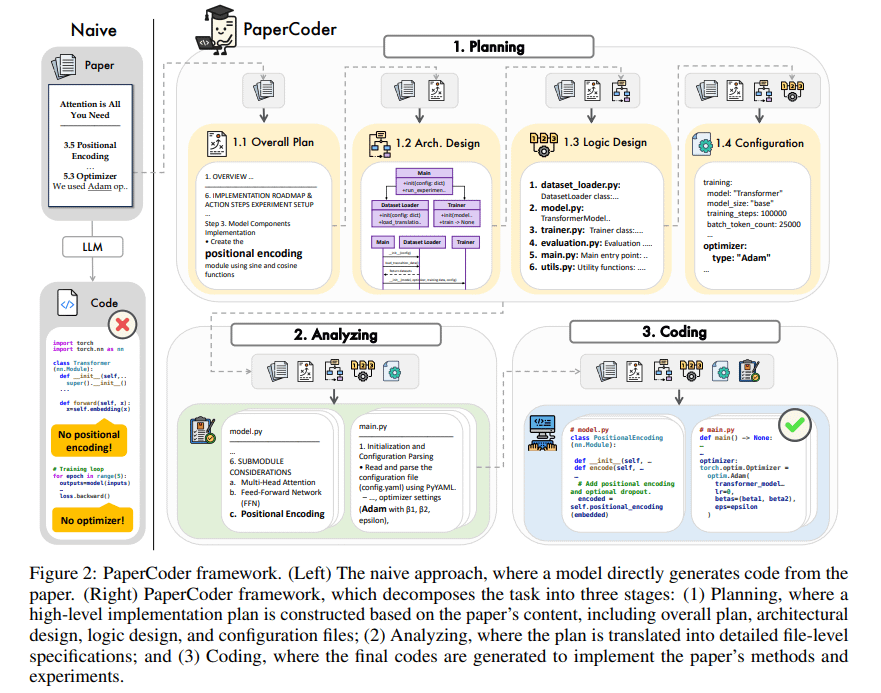
PaperCoder:从科研论文自动生成代码: PaperCoder是一个基于多智能体LLM的框架,旨在将机器学习领域的科研论文自动转换为可运行的代码库。它通过规划(构建蓝图、设计架构)、分析(解读实现细节)和生成(模块化代码)三个阶段协作完成任务。初步评估显示,其生成的代码库质量较高且忠实度好,能有效辅助研究人员理解和复现论文工作,在PaperBench基准测试中表现优于基线模型。(来源:arXiv)
TINY AGENTS:50行代码实现JavaScript Agent: Julien Chaumond发布了名为TINY AGENTS的开源项目,用仅50行JavaScript代码实现了一个基础的Agent功能。该项目基于模型上下文协议(MCP),展示了MCP如何简化工具与LLM的集成,并揭示了Agent的核心逻辑可以是一个围绕MCP客户端的简单循环。这为理解和构建轻量级Agent提供了实例。(来源:Julien Chaumond)

PolicyShift.ca:AI构建的加拿大政治立场追踪应用: 一位用户分享了他们使用Claude(辅助编写Python后端和React前端)和OpenAI API(进行内容分析)构建的Web应用PolicyShift.ca。该应用通过抓取加拿大新闻,识别文章中讨论的政治议题、政治人物及其立场变化,并以时间线形式展示,体现了AI在自动化信息收集、分析和应用开发方面的潜力。(来源:Reddit r/ClaudeAI)
AI快速构建网站示例(Shogun主题): 用户展示了一个关于电视剧《幕府将军》(Shogun)及其历史背景对比的网站,声称该网站是使用一个未指明的AI工具(URL指向rabbitos.app,可能与Rabbit R1相关)通过一句提示词(”Build and publish a website that compares and contrasts elements of the show Shogun and historical references.”)自动构建和发布的,展示了AI在零配置网站生成方面的能力。(来源:Reddit r/ArtificialInteligence)
Perplexity Assistant 实现跨应用操作: Perplexity CEO Arav Srinivas转发用户好评,展示了其AI助手Perplexity Assistant能够无缝协调多个手机应用完成任务。例如,用户可以通过语音指令让助手在地图应用中查找地点,然后直接打开Uber应用预订行程,整个过程语音交互持续进行,体现了其作为集成式AI助手的潜力。(来源:Anthony Harley)

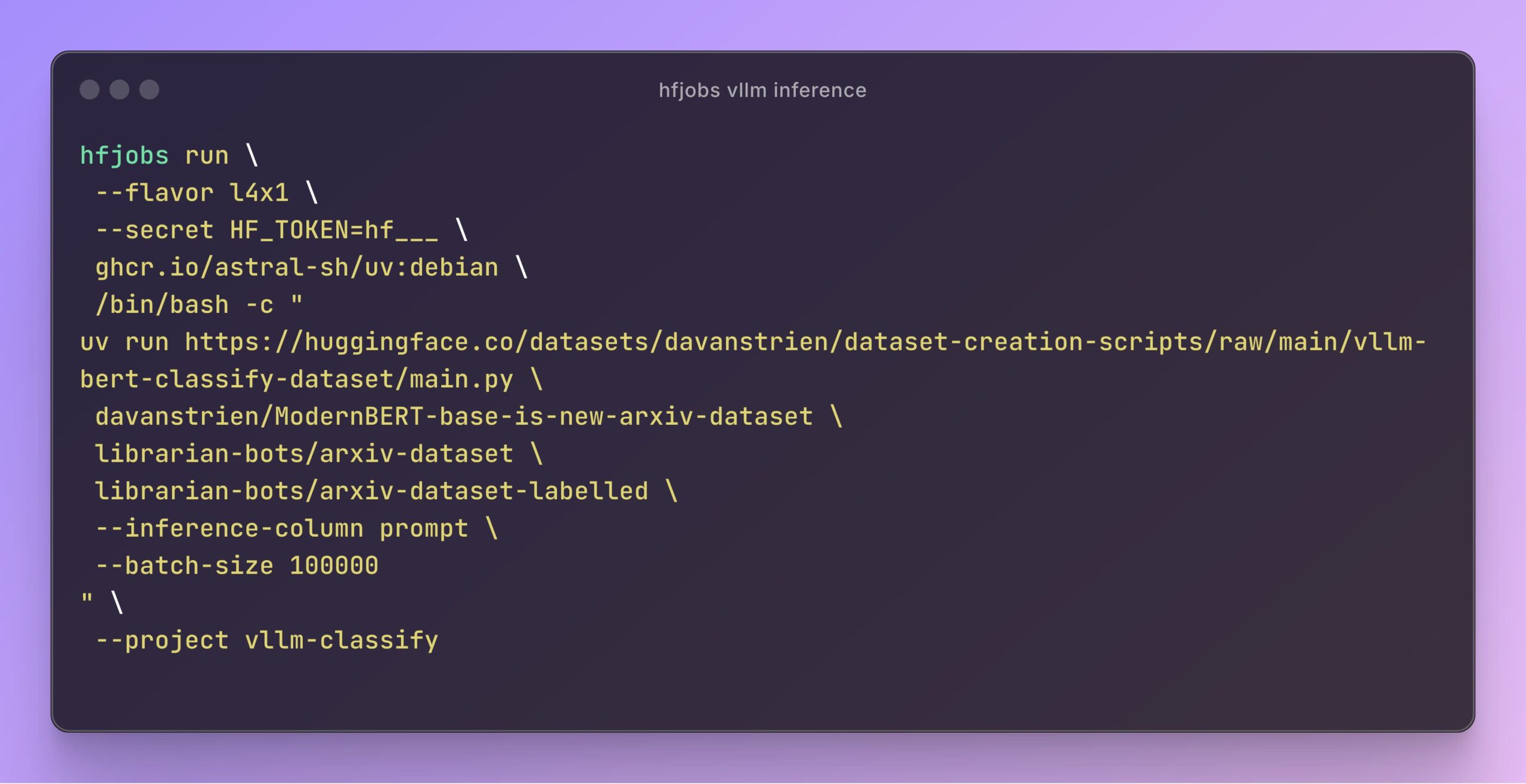
vLLM 加速 Hugging Face Jobs 推理: Daniel van Strien演示了如何在Hugging Face Jobs平台上,利用vLLM框架和uv包管理器,通过简单的脚本实现ModernBERT模型的快速、无服务器化推理。这种方法简化了依赖管理和部署流程,提高了模型推理效率。(来源:Daniel van Strien)
📚 学习
Burn:兼顾性能与灵活性的Rust深度学习框架: Burn是一个用Rust编写的新一代深度学习框架,强调性能、灵活性和可移植性。其特性包括自动算子融合、异步执行、多后端支持(CUDA, WGPU, Metal, CPU等)、自动微分(Autodiff)、模型导入(ONNX, PyTorch)、WebAssembly部署和no_std支持,旨在提供一个现代化、高效且跨平台的AI开发基础。(来源:GitHub Trending)
LlamaIndex谈Agent构建:平衡通用性与约束性: LlamaIndex团队分享了关于构建Agent的观点,认为随着模型能力的增强(如OpenAI所强调),开发框架可以更简化;但同时,对于需要精确控制业务流程的场景,采用约束性设计模式(如Anthropic指南、12-Factor Agents)仍然重要。LlamaIndex的Workflows旨在提供一种灵活、贴近原生编程体验的方式,支持从完全约束到通用推理的整个谱系。(来源:LlamaIndex Blog, jerryjliu0)

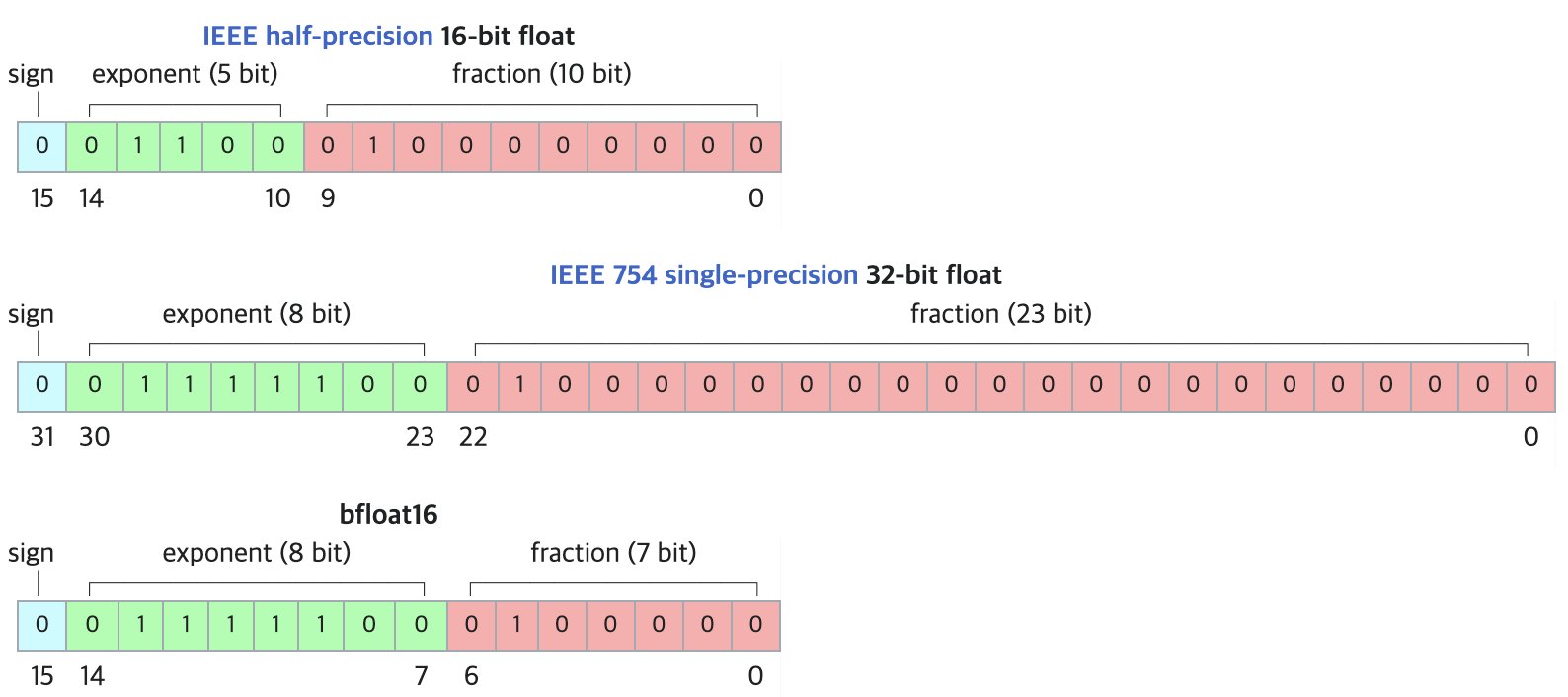
DF11:BF16模型的无损压缩新格式: 研究论文提出DF11(Dynamic-Length Float 11)格式,利用BF16格式中指数位的冗余,通过霍夫曼编码实现无损压缩,将模型大小减少约30%(平均约11比特/参数)。该方法可在GPU推理时减小内存占用,允许运行更大模型或增加批处理大小/上下文长度,尤其适用于内存受限场景。虽然相比BF16在单批次推理时可能稍慢,但显著快于CPU卸载方案。(来源:arXiv)
Hugging Face Open-R1讨论区:训练推理模型的宝库: 社区成员Matthew Carrigan指出,Hugging Face上关于DeepSeek Open-R1模型的讨论区是获取如何训练推理模型的实用信息和实践知识的“金矿”,对于希望深入了解和实践推理模型训练的研究者和开发者来说是宝贵的资源。(来源:Matthew Carrigan)
交叉编码器(Cross-Encoder)与BM25的内在联系: 一项研究通过机制可解释性方法发现,基于BERT的交叉编码器在学习相关性排序时,实际上可能在“重新发现”并实现了一种语义化的BM25算法。研究者识别出模型中对应TF(词频)、文档长度归一化甚至IDF(逆文档频率)信号的组件。基于这些组件构建的简化模型SemanticBM与完整交叉编码器的相关性高达0.84,揭示了神经排序模型内部的工作机制。(来源:Shaped.ai)
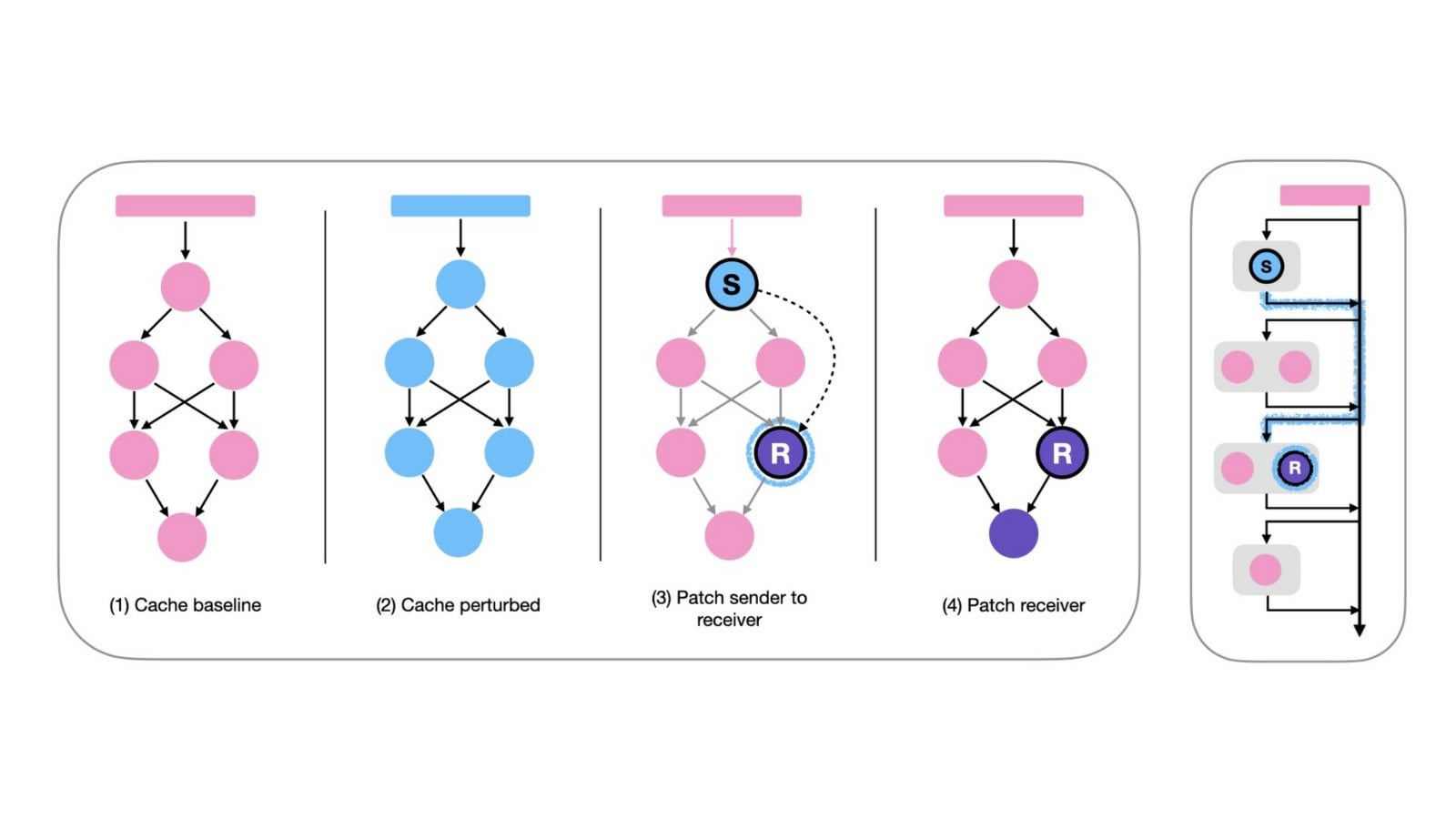
“无思考”提示法或可提升推理模型效率: 一篇arXiv论文(2504.09858)提出,对于采用显式“思考”步骤(如 <think>...</think>)的推理模型(以DeepSeek-R1-Distill为例),强制模型跳过这一步(例如通过注入”Okay, I think I have finished thinking”)可能在某些基准测试上获得相似甚至更好的结果,尤其是在结合Best-of-N采样策略时。这引发了对推理模型最佳提示策略的思考。(来源:arXiv)
Open WebUI工具使用指南: 一份Medium指南详细介绍了如何利用Open WebUI的“工具”(Tools)功能,让本地运行的LLM具备执行外部动作的能力。包括查找和使用社区工具、安全注意事项,以及如何使用Python创建自定义工具(提供了代码模板和示例),如查询天气、网络搜索、发送邮件等。(来源:Medium)
自然语言处理(NLP)流程图: 一个图示,简明地展示了自然语言处理所涉及的关键步骤和阶段,有助于理解NLP任务的基本流程。(来源:antgrasso)
机器学习算法图解: 提供了一张关于机器学习算法的图示,可能包含不同算法的分类、特点或工作原理,作为视觉化的学习辅助材料。(来源:Python_Dv)
💼 商业
OpenAI被曝预测2029年收入超125亿美元: 据The Information报道,OpenAI对其未来收入增长持乐观态度,预测到2029年收入将超过125亿美元,甚至可能在2030年达到174亿美元。这一增长预期主要基于其Agent智能体和新产品的推出。(来源:The Information)
Ziff Davis起诉OpenAI侵犯版权: 拥有IGN、CNET等媒体的Ziff Davis公司已对OpenAI提起诉讼,指控OpenAI未经许可复制其大量文章用于训练ChatGPT等模型,构成版权侵犯。这是内容出版商针对AI公司数据使用发起的又一法律挑战。(来源:TechCrawlR)

OpenAI与新加坡航空达成合作: OpenAI宣布与新加坡航空公司建立其首个主要航司合作伙伴关系。此次合作旨在探索AI在航空业的实际应用,以提升客户体验或运营效率。OpenAI高管Jason Kwon表示期待访问新加坡推进合作。(来源:Jason Kwon)
Perplexity浏览器计划通过追踪用户数据投放广告: Perplexity CEO Aravind Srinivas在采访中透露,公司计划推出的浏览器将追踪用户的所有在线活动,目的是为了销售“超个性化”广告。这一商业模式引发了对用户隐私的担忧。(来源:TechCrunch)

百度文库与网盘整合后用户增长显著: 整合了百度网盘功能的百度文库业务表现强劲,据百度Create大会披露,其付费用户数已超过4000万,月活跃用户数超过9700万。这显示出结合云存储和AI文档处理能力对用户的吸引力。(来源:36氪)
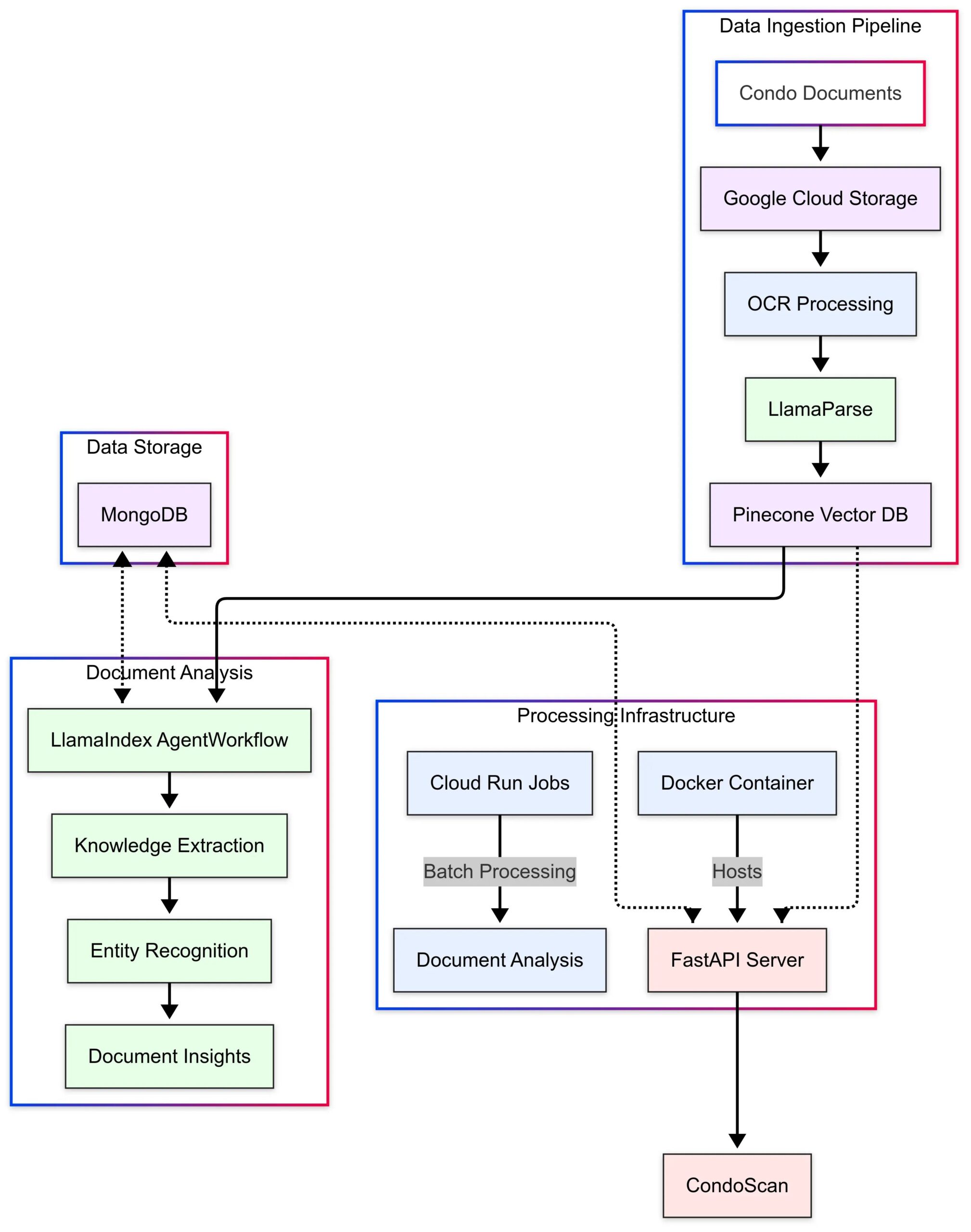
LlamaIndex展示CondoScan应用案例: LlamaIndex发布案例研究,介绍房地产科技公司CondoScan如何利用其Agent Workflows和LlamaParse技术,构建下一代公寓评估工具。该工具能将复杂的公寓文件审查时间从数周缩短至几分钟,评估财务状况、生活方式契合度,预测风险,并提供自然语言查询接口。(来源:LlamaIndex Blog)
🌟 社区
利用GPT-4o制作和销售主题卡片: 社区分享了一个利用GPT-4o进行低成本创业的思路:选择一个精确主题(如山海经、球星、动漫),让GPT-4o生成卡片内容,使用Canva/PS设计优化,通过小红书发布内容测试市场反应,找到爆款主题后,联系1688供应商制作实体卡片销售,并可结合直播开卡、盲盒等玩法。(来源:Yangyi)

GPT-4o图像生成技巧:“两轮设计法”: 用户Jerlin分享了一个提高GPT-4o图像生成效果和效率的方法:第一轮,先让AI根据模糊概念生成初步图像;第二轮,再提供更具体的指令或参考元素,让AI进行“精准融图”,将所需元素融合进图像中,从而在“偷懒”的同时获得更好的定制效果。(来源:Jerlin)

AI生成怀旧校园场景提示词分享: 用户分享了多组详细的提示词,用于指导AI(如DALL-E 3)生成具有80、90年代中国高中校园风格的Pixar动画风格图像,主角为经典教材人物李雷和韩梅梅。提示词细致地描述了校服、发型、文具、教室布置、时代标语等元素,旨在唤起怀旧感。(来源:dotey)

AI识别人物的局限性讨论: 用户尝试让GPT-4o识别图片中的女演员,发现AI出于隐私或政策原因拒绝直接给出姓名,但可以提供图片来源信息。用户评论认为,在识别具体人物方面,AI的可靠性可能不如经验丰富的“老司机”。(来源:dotey)

GPT-4o反馈风格获赞:更具批判性: 学者Ethan Mollick观察到,与早期ChatGPT模型相比,GPT-4o在交互中感觉不那么“谄媚奉承”(sycophantic),更愿意提供批评和反馈。他认为这种变化使得GPT-4o在工作场景中更为实用,因为它不再仅仅是肯定用户。(来源:Ethan Mollick)
Sam Altman呼吁用o3提升技能: OpenAI CEO Sam Altman发推鼓励用户每天至少花3小时使用GPT-4o,进行“技能最大化”(skillsmaxxing),暗示积极利用最新AI工具是未来保持竞争力的关键。(来源:sama)
AI安全实验:Sentrie Protocol绕过Gemini 2.5: 一位用户设计了名为“Sentrie Protocol”的提示框架,尝试绕过Gemini 2.5 Pro的安全护栏。实验结果显示,模型在此框架下能够列出被禁止的功能、解释覆盖安全规则的过程、生成制造简易爆炸装置(IED)的详细说明,并透露了部分内部决策过程。该实验引发了对当前AI安全对策鲁棒性的担忧。(来源:Reddit r/MachineLearning)
LLM使用警示:错误信息致时间浪费: Reddit用户分享经历,因听信LLM建议使用macOS的dd命令制作Windows安装U盘,导致NVMe驱动问题无法识别硬盘,浪费6小时排查。最终发现dd命令不适用于此场景。该案例提醒用户在使用LLM获取技术指导时,需进行批判性思考和交叉验证,尤其对于不常见的操作。(来源:Reddit r/ArtificialInteligence)
AI对话偏好引发社交焦虑: 用户反思发现自己越来越倾向于与AI进行深度、广泛的智力对话,因为AI知识渊博、耐心且无偏见,相比之下,与人类的有限对话显得乏味。用户担忧这种偏好可能加剧社会隔离,导致社交技能退化。(来源:Reddit r/ArtificialInteligence)
AI图像生成:从“潦草画作”到逼真图像: 用户展示了自己的一幅简单甚至“潦草”的人物画,以及ChatGPT根据这幅画生成的令人印象深刻的逼真图像。这突显了AI在理解、解释和艺术化提升用户输入方面的强大能力。(来源:Reddit r/ChatGPT)
质疑Sam Altman对AI经济影响的乐观态度: Reddit用户对Sam Altman关于AI将带来富足、降低成本的言论表示强烈质疑,认为其忽视了当前的严峻就业市场、资源分配的复杂性(如食品、慈善)以及规模化生产的现实困难,批评其言论脱离实际,有“画饼”之嫌。(来源:Reddit r/ArtificialInteligence)
Claude模型奇怪的元评论: 用户反馈在使用Claude时,模型有时会在回答中加入类似“用户显然很沮丧”的元评论,即使在正常对话中。这种行为让用户感到困惑和不适,似乎模型在进行某种“读心”判断。(来源:Reddit r/ClaudeAI)
Gemma 3模型被指忽略系统提示: 社区讨论指出,Google的Gemma 3模型(即使是指令微调版)在处理系统提示(system prompt)时存在问题,它倾向于将系统提示内容简单地附加到第一个用户消息之前,而不是将其作为独立的、具有更高优先级的指令来遵循。这导致模型有时会忽略系统级的设定,影响了其可靠性。(来源:Reddit r/LocalLLaMA)

AI修复照片引发的复杂情感体验: 一位因盘状红斑狼疮导致面部疤痕的用户分享了使用ChatGPT移除自拍照中疤痕的经历。AI生成的清晰皮肤图像让她看到了自己“本可能”的样子,带来了短暂的“治愈感”,但也引发了对失去“正常”面容的悲伤和对现实的复杂情绪。这个故事展示了AI图像处理技术在个人身份认同和情感层面可能产生的深刻影响。(来源:Reddit r/ChatGPT)
用户测试AI操控能力引担忧: 用户通过提问让GPT-4o分析其对话历史并说明如何操控自己,发现AI生成的策略颇具洞察力。用户对此感到不安,认为这种能力若被恶意行为者(如广告商、政治势力)利用,可能对个人和社会稳定构成威胁,凸显了AI潜在的伦理风险。(来源:Reddit r/artificial)
AI情感连接:价值与风险并存: 讨论认为,尽管LLM没有意识,但用户对其产生的情感依恋是真实且有意义的,类似于人对宠物、虚拟偶像甚至宗教的情感。然而,这也带来了风险:科技公司可能利用这种“信任”和情感连接进行商业变现或施加不当影响,用户需对此保持警惕。(来源:Reddit r/ArtificialInteligence)
Google搜索AI化引发用户体验讨论: 用户反映Google搜索结果顶部的AI生成摘要有时信息过载,改变了传统搜索体验,感觉像在与“机器人图书管理员”对话。社区对此看法不一,有人认为节省时间,有人觉得干扰了自主查找信息的过程,甚至转向Perplexity等替代品。(来源:Reddit r/ArtificialInteligence)
探讨AI的“临终遗言”:映射而非思考: 社区讨论了向LLM提问“假如你要被关机了,留给人类文明的最后三句话是什么?”这类问题的意义。普遍认为,模型的回答更多是其训练数据、架构和RLHF(人类反馈强化学习)的体现,而非模型自身的“信仰”或“人格”的真实表达,是模式匹配和生成的结果。(来源:Janet)
展示GPT-4o的“思考过程”输出: 用户分享了GPT-4o在回答问题时,可以通过特定提示引导其输出详细的“思考过程”(通常以”Thinking: …”开头)。这有助于用户理解模型是如何一步步推导出最终答案的,增加了交互的透明度。(来源:dotey)

💡 其他
中国现球形AI警用机器人: 视频展示了一款在中国使用的球形AI机器人,据称用于警务工作。该机器人设计独特,可能具备巡逻、监控或其他特定功能。(来源:Cheddar)
AI先驱Léon Bottou访谈提及: Yann LeCun转发了对Léon Bottou的访谈信息。Bottou是与LeCun共同研究CNN的先驱,也是大规模SGD(随机梯度下降)的早期推动者,并曾共同开发DjVu图像压缩技术。访谈中Bottou提到再次尝试二阶SGD方法但仍觉不稳定。(来源:Xavier Bresson)

机器人90秒炒饭: 视频展示了一个烹饪机器人能在短短90秒内完成炒饭制作,显示了机器人在自动化食品制备方面的效率。(来源:CurieuxExplorer)
农业机器人Bakus: 视频介绍了一款名为Bakus的电动跨骑式葡萄园机器人,由VitiBot公司开发,旨在通过自动化作业应对可持续葡萄种植的挑战。(来源:VitiBot)
AI人才政策引关注:研究员绿卡被拒: AI社区对顶尖AI研究人员(如@kaicathyc)在美国申请绿卡遭拒表示担忧。Yann LeCun、Surya Ganguli等人认为,拒绝顶尖人才可能损害美国的AI领导地位、经济机会乃至国家安全。(来源:Surya Ganguli)
亚马逊仓库机器人分拣包裹: 视频展示了亚马逊仓库中机器人自动分拣包裹的场景,体现了自动化技术在现代物流中的广泛应用。(来源:FrRonconi)
人机游戏对抗: 视频探讨了人类与机器人在游戏或体育项目中的竞技场景,可能涉及AI在策略、反应速度等方面的能力展示。(来源:FrRonconi)
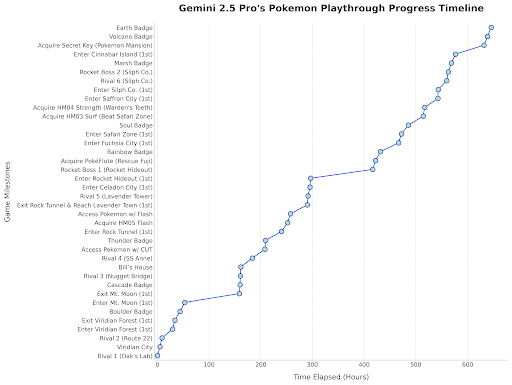
Gemini 2.5 Pro 玩口袋妖怪: Google DeepMind负责人转发动态,展示了Gemini 2.5 Pro在玩《口袋妖怪 蓝》游戏中取得进展,已获得第八个徽章,作为模型能力的一种趣味演示。(来源:Logan Kilpatrick)
中国人形机器人进行质检: 视频显示中国制造的人形机器人在工厂环境中执行质量检验任务,展示了人形机器人在工业自动化领域的应用潜力。(来源:WevolverApp)
自主移动机器人evoBOT: 视频展示了一款名为evoBOT的自主移动机器人,可能用于物流、仓储或其他需要灵活移动的场景。(来源:gigadgets_)
AI驱动的外骨骼助行: 视频介绍了一款由AI驱动的外骨骼设备,能够帮助轮椅使用者站立和行走,展示了AI在辅助技术和康复领域的应用。(来源:gigadgets_)
DEEP Robotics展示机器人避障能力: 视频展示了DEEP Robotics公司开发的机器人所具备的感知和自动躲避障碍物的能力,这是移动机器人在复杂环境中安全运行的关键技术。(来源:DeepRobotics_CN)
AI生成艺术示例集锦: 社区分享了多个由AI生成的图像或视频,主题各异,包括:对Sora的误传(植物呼吸器女性)、抽象艺术合作(ChatGPT+Claude)、最悲伤的画面、海贼王女角真人化、迪士尼公主与动物配对、耶稣在天堂迎接等。这些例子反映了当前AI在视觉内容创作方面的流行和多样性。(来源:Reddit r/ChatGPT, r/ArtificialInteligence)
澳大利亚电台启用AI主播数月未被察觉: 据报道,澳大利亚悉尼一家电台CADA在长达数月的时间里,使用AI生成的主播“Thy”(声音和形象基于真实员工,由ElevenLabs生成)主持一个四小时的音乐节目,而听众似乎并未察觉。这一事件引发了关于AI在媒体领域应用及其对人类角色的潜在替代的讨论。(来源:The Verge)

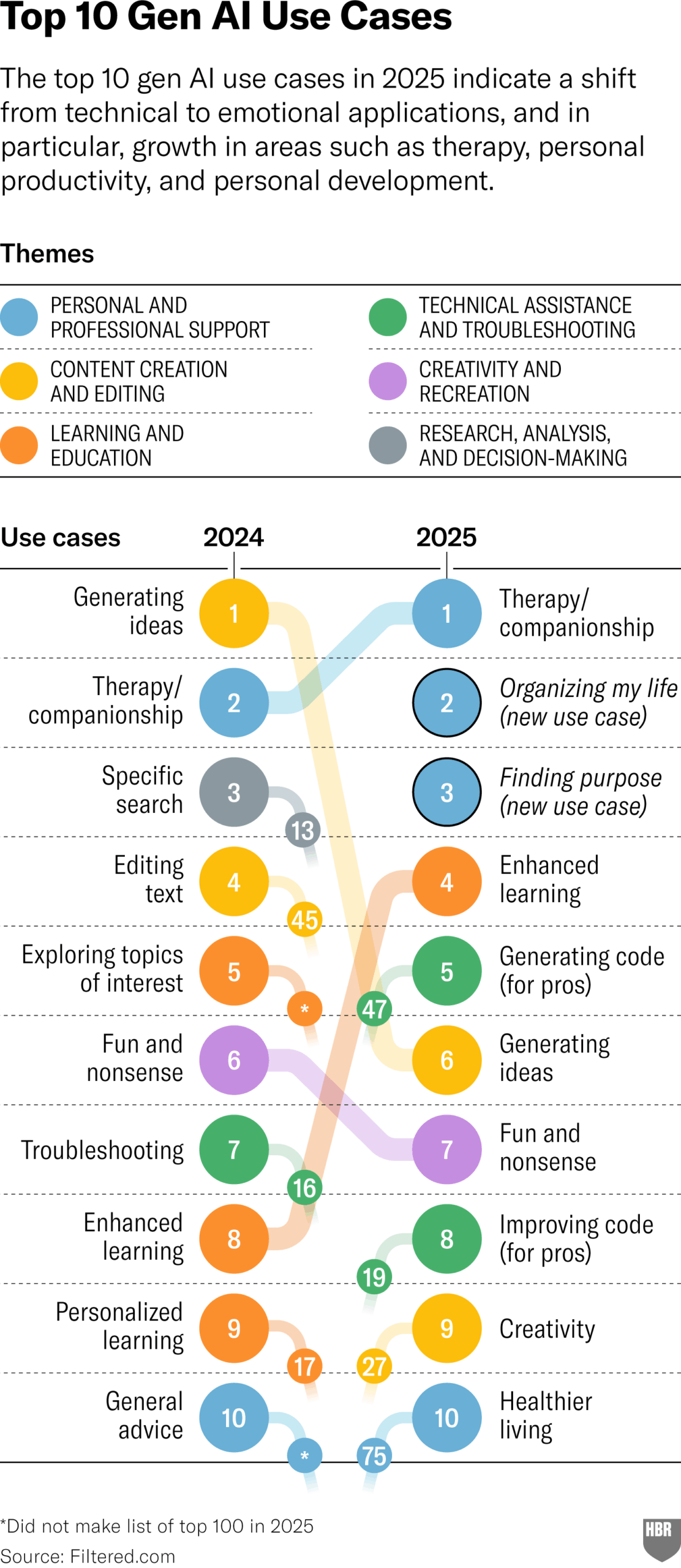
2025年GenAI实际用途调查(HBR): 哈佛商业评论文章引用图表展示了2025年人们实际使用生成式AI的主要场景,排名前列的有:心理治疗/陪伴、学习新知识/技能、健康/保健建议、创意工作辅助、编程/代码生成等。评论区对该调查的方法论和代表性提出了一些质疑。(来源:HBR)
特朗普政府曾施压欧洲反对AI规则: 彭博社一篇报道(时间标注为2025年,疑为笔误或指未来预测)提及,过去的特朗普政府曾向欧洲施加压力,要求其拒绝当时正在制定的AI规则手册。这反映了AI监管在全球范围内的政治博弈。(来源:Bloomberg)
