
关键词:推理模型, AI代理, 强化学习, 大模型, DeepSeek-R1, 视觉-语言-导航(VLN), DINOv2自监督学习, LangGraph RAG Agent, AI芯片国产化, SRPO优化方法, 具身智能操作技能迁移, 量子计算治理
🔥 聚焦
推理模型成为AI新焦点,DeepSeek-R1引发行业震动: 继OpenAI发布聚焦结构化推理的o系列模型后,DeepSeek-R1的开源和卓越表现(尤其在数学和代码方面)标志着大模型竞争进入新阶段。行业关注点正从预训练参数规模转向通过强化学习提升推理能力。国内大厂如百度(文心X1)、阿里(通义千问Qwen-QwQ-32B)、腾讯(混元T1)、字节(豆包1.5)、科大讯飞(星火X1)等迅速跟进,发布各自的推理模型,形成了国产推理模型迎战OpenAI的新格局。这一转变强调了模型深度思考、规划、分析及工具调用能力的重要性,预示着Agent等应用的落地将更依赖强大的推理基础模型。(来源: 国产六大推理模型激战OpenAI?, “AI寒武纪”爆发至今,五类新物种登上历史舞台)

AI购物应用Nate被曝欺诈,创始人被控骗取4000万美元投资: 美国司法部指控AI购物应用Nate创始人Albert Saniger通过虚假宣传AI技术骗取投资。Nate声称能利用AI技术简化跨平台购物流程,实现一键下单,但实际上被指控在菲律宾雇佣数百名员工手动处理订单,用“人工”冒充“智能”。该事件暴露了AI创业热潮中可能存在的泡沫和欺诈风险,也引发了对硅谷“Fake it till you make it”文化的讨论,强调了夸大宣传与欺骗之间的界限。此案也反映出在AI技术(尤其是大模型)成熟前,某些AI应用概念的技术可行性挑战。(来源: AI购物竟是人工驱动,硅谷创投圈又玩出新花活)

AI融入工作流程,重构职场价值与管理模式: AI正从概念走向实践,深度融入企业运营和员工日常工作。阿里云利用大模型和数据治理实现“组织经营管理驾驶舱”,优化OKR/CRD流程;德勤中国致力于培养万名AI人才,适应智慧密集型组织需求;百胜中国将AI工具部署到餐厅经理层面。这表明AI不仅是效率工具,更在重塑工作本质、组织架构和人才需求。重复性、标准化工作被AI取代,对员工的创造力、批判性思维、决策力及AI协作能力(AI适应性)提出更高要求。企业管理需从监督转向赋能,建立人与AI协同的新范式和信任机制。(来源: 当AI来和我做同事:重构职场价值坐标系, 重塑工作:AI时代的组织进化与管理革命)

🎯 动向
DINOv2 自监督视觉模型引入寄存器机制: Meta AI Research 更新了其 DINOv2 自监督学习方法和模型,根据论文《Vision Transformers Need Registers》,新版本加入了“寄存器”(registers)机制。DINOv2 旨在学习无需监督的鲁棒视觉特征,这些特征可以直接用于多种计算机视觉任务(如分类、分割、深度估计),且跨领域表现良好,无需微调。此次更新可能进一步提升模型的性能和特征质量。(来源: facebookresearch/dinov2 – GitHub Trending (all/daily))
强化学习 (RL) 成为 LLM 后训练与能力提升的关键路径: David Silver 和 Richard Sutton 等学者指出,AI正进入“经验时代”,RL 在 LLM 后训练阶段扮演核心角色。通过从人类反馈(RLHF)、演示或规则中学习奖励模型(Inverse RL),RL 赋予 LLM 超越模仿学习(如SFT)的持续优化、探索和泛化能力。尤其在推理任务(如数学、代码)上,RL 帮助模型发现更有效的解决模式(如长思维链),突破数据驱动方法的局限。这标志着 LLM 发展从依赖静态数据转向通过交互和反馈进行动态学习。(来源: 被《经验时代》刷屏之后,剑桥博士长文讲述RL破局之路)

视觉-语言-导航 (VLN) 仍是具身智能的重要挑战: 阿德莱德大学吴琦副教授指出,尽管操作任务(Manipulation)在具身智能领域火热,但视觉-语言-导航(VLN)作为视觉-语言-动作(VLA)的关键组成部分,在非结构化、动态环境(尤其是家庭场景)中仍面临诸多挑战,远未被完全解决。导航是机器人执行后续任务的基础。当前 VLN 的主要瓶颈包括高质量数据(仿真器、3D环境、任务数据)的缺乏、Sim2Real 的迁移鸿沟以及端侧高效部署的工程难题。(来源: 阿德莱德大学吴琦:VLN 仍是 VLA 的未竟之战丨具身先锋十人谈)

AI 在广告与营销领域展现清晰商业化路径: 对比其他 AI 应用场景,AI 技术在广告和营销领域的商业化落地似乎更为明确和迅速。通过利用 AI 进行数据分析、用户画像、精准投放和自动化营销,如 Applovin Corp 和 Zeta Global 等公司已成功改变广告生态,提升了效率和投资回报率。这表明,在 AI 浪潮中,能够快速产生商业价值的应用更容易受到市场青睐,广告营销是其中的典型代表。(来源: “AI寒武纪”爆发至今,五类新物种登上历史舞台)
AI 芯片供应链紧张与国产化趋势: 中美科技竞争加剧,美国对华 AI 芯片(特别是 Nvidia H20 等高端型号)的出口管制持续收紧。据报道,多家中国科技公司(如字节跳动、阿里巴巴、腾讯)在禁令生效前大量囤积 Nvidia 芯片,以维持 AI 研发和部署能力。与此同时,为应对供应链风险和“卡脖子”问题,全栈国产化的 AI 技术路径受到更多重视,例如科大讯飞基于华为昇腾等国产算力训练和部署其星火大模型,这可能成为未来国内 AI 发展的重要趋势。(来源: 国产六大推理模型激战OpenAI?, Reddit r/artificial, Reddit r/ArtificialInteligence)

🧰 工具
Suna:开源通用 AI 代理平台: Kortix AI 推出了 Suna,一个开源的通用 AI 代理(Generalist AI Agent)。用户可以通过自然语言对话,让 Suna 协助完成各种现实世界任务,包括网络研究、数据分析、浏览器自动化(网页导航、数据提取)、文件管理(文档创建编辑)、网络爬虫、扩展搜索、命令行执行、网站部署以及集成各种 API 和服务。Suna 旨在成为用户的数字化伴侣,自动化复杂工作流。(来源: kortix-ai/suna – GitHub Trending (all/daily))

Leaked System Prompts 仓库收集各大模型内部提示词: GitHub 上出现了一个名为 leaked-system-prompts 的热门仓库,收集并公开了来自多个主流 AI 模型的内部系统提示(System Prompts)。这些提示词揭示了模型被设计用来遵循的指令、规则、角色设定和安全约束等。仓库包含了 Anthropic Claude 系列(2.0, 2.1, 3 Haiku/Opus/Sonnet, 3.5 Sonnet, 3.7 Sonnet)、Google Gemini 1.5、OpenAI ChatGPT(各版本包括 4o)、DALL-E 3、Microsoft Copilot、xAI Grok(各版本)等众多模型的泄露提示词,为研究者和开发者提供了深入了解这些模型内部工作机制的窗口。(来源: jujumilk3/leaked-system-prompts – GitHub Trending (all/daily))
WAN 视频生成平台推出付费加速服务: AI 视频生成平台 WAN (WAN.Video) 的海外版本宣布进入商业化阶段,推出了付费选项。所有用户仍然可以享受无限次的免费视频生成(Relax mode),但需要排队等待。付费用户则可以获得免排队的优先生成服务,从而更快地获得视频结果。这为需要高效率或商业用途的用户提供了加速通道。(来源: op7418)

Dia TTS 模型登陆 Hugging Face API: 用户现在可以通过 Hugging Face 平台直接调用 Dia 1.6B 文本转语音(Text-to-Speech)模型 API,该服务由 FAL AI 提供支持。开发者只需几行代码即可集成,实现高质量的语音合成功能。这项集成降低了使用先进 TTS 模型的门槛,方便开发者在应用中快速添加语音能力。(来源: huggingface)
ModernBERT 分类器模型集成 vLLM 实现快速推理: ModernBERT 模型现在可以在 vLLM 框架上运行,显著提升了推理速度。据称,其速度足以在几分钟内处理超过 20 万篇 arXiv 论文。这一集成使得在 Hugging Face Hub 上托管的数百个 ModernBERT 模型能够更快速地被部署和应用于文本分类任务。(来源: huggingface)
Trackers:高性能 Python 目标跟踪库: Roboflow 开源了名为 Trackers 的 Python 库,专注于目标跟踪任务。该库设计为模块化,支持多种跟踪算法,并能轻松与 Ultralytics、Transformers 等流行的机器学习库集成。其性能强大,能够同时跟踪大量目标,在演示视频中成功跟踪了超过 269 个鸡蛋。(来源: karminski3)
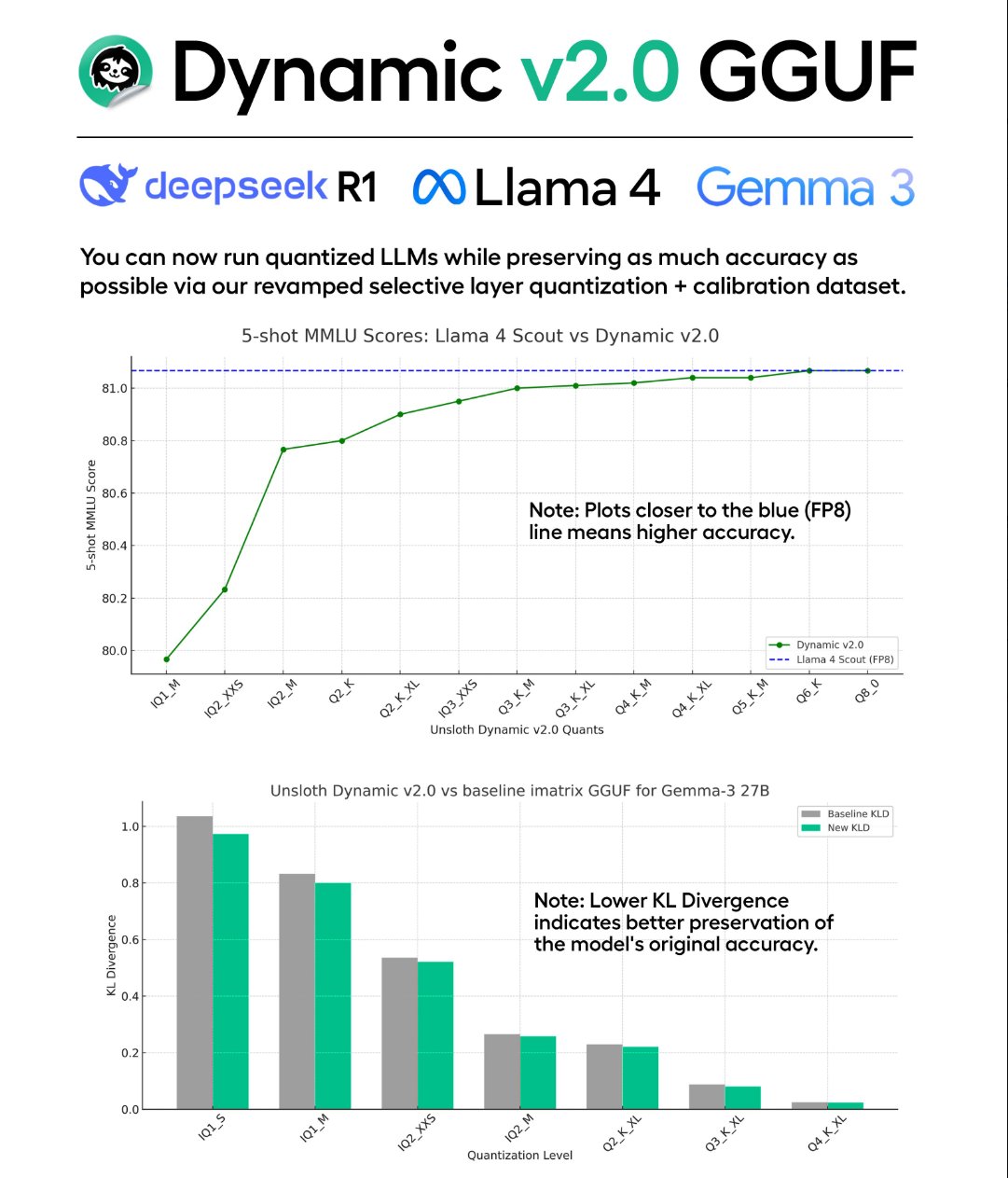
Unsloth 发布 Dynamic v2.0 GGUF 量化技术及模型: Unsloth 推出了新的 Dynamic v2.0 量化技术,专为 GGUF 格式模型设计。据称,该量化版本在 MMLU 和 KL Divergence 评估中表现优于之前的版本,并修复了 Llama.cpp 中 Llama-4 的 RoPE 实现问题。Unsloth 已使用此技术发布了 DeepSeek-R1 和 DeepSeek-V3-0324 的新量化模型,供社区使用。(来源: karminski3)
Perplexity iOS 语音助手集成系统功能: Perplexity 的 iOS 应用更新了其语音助手功能,使其能够调用更多系统级操作。用户现在可以通过语音指令让 Perplexity 助手预订餐厅、使用苹果地图导航、创建提醒事项、搜索和播放苹果音乐或播客、以及叫车等。这使得 Perplexity 助手在功能上更接近 Siri 等原生系统助手,提升了实用性。(来源: AravSrinivas)
VS Code MCP Server 扩展发布,连接 Claude 与本地开发环境: 开发者 Juehang Qin 发布了一款 VS Code 扩展,该扩展将 VS Code 变成一个 MCP (Model Context Protocol) 服务器。这使得像 Claude 这样的 AI 助手能够直接访问和操作用户当前在 VS Code 中打开的工作区,包括读写文件、查看代码诊断信息(如错误和警告)等。用户切换项目时,扩展会自动暴露新的工作区,方便 AI 助手在不同项目间无缝协作。(来源: Reddit r/ClaudeAI)
📚 学习
DINOv2:Meta 开源自监督视觉特征学习方法: Meta AI Research 开源了 DINOv2 项目,包括 PyTorch 代码和预训练模型。DINOv2 是一种自监督学习方法,旨在学习强大的、通用的视觉特征,这些特征在多种计算机视觉任务(如图像分类、语义分割、深度估计)上表现出色,且无需针对下游任务进行微调。项目提供了详细的文档、模型下载链接以及相关论文,是研究和应用自监督视觉学习的重要资源。(来源: facebookresearch/dinov2 – GitHub Trending (all/daily))
HD-EPIC:高细节度第一人称视频数据集发布: 研究者推出了 HD-EPIC 数据集,包含在真实厨房环境中录制的 41 小时第一人称视频。该数据集的关键特点是其极其详尽的多模态标注,覆盖了菜谱步骤、食材营养信息(通过称重记录)、细粒度动作描述(内容、方式、原因)、3D 场景数字孪生、物体移动轨迹(2D/3D)、手部/物体掩码、视线追踪以及物体与场景的交互等。该数据集旨在为第一人称视觉理解、具身智能和人机交互研究提供高质量的基准。(来源: CVPR 2025 | HD-EPIC定义第一人称视觉新标准:多模态标注精度碾压现有基准)

SRPO:解决跨领域 RL 训练 LLM 推理能力的优化方法: 快手 Kwaipilot 团队针对使用 GRPO 等强化学习方法训练 LLM 在混合数学与代码任务时遇到的性能瓶颈和效率问题,提出了 SRPO(两阶段历史重采样策略优化)方法。该方法通过第一阶段使用数学数据激发深度思考,第二阶段引入代码数据发展程序化思维,并结合历史重采样技术解决奖励信号零方差问题。实验表明,SRPO 仅需 10% 的训练步数即可在 AIME24 和 LiveCodeBench 上超越 DeepSeek-R1-Zero-Qwen-32B,为跨领域推理能力提升提供了高效路径。(来源: DeepSeek-R1-Zero被“轻松复现”?10%训练步数实现数学代码双领域对齐)
TTRL:无需标注数据的测试时强化学习: 清华大学与上海 AI Lab 提出了 TTRL(Test-Time Reinforcement Learning)方法,使 LLM 能够在测试阶段、无需人工标注的情况下进行强化学习。该方法利用模型自身的多次采样输出,通过多数投票等方式生成伪标签和奖励信号,驱动模型自我进化以适应新数据或任务。实验显示,TTRL 能显著提升模型在目标任务上的性能,甚至接近有监督训练的效果,为解决 RL 在无监督环境下的应用难题提供了新思路。(来源: TTS和TTT已过时?TTRL横空出世,推理模型摆脱「标注数据」依赖,性能暴涨)
SeekWorld:模拟 o3 视觉线索追踪的地理定位推理任务与模型: 为提升多模态大语言模型(MLLM)的视觉推理能力,特别是模拟 OpenAI o3 模型在推理中动态感知和操作图像(视觉线索追踪)的能力,研究者提出了 SeekWorld 地理定位推理任务(根据图片推断拍摄地点)。围绕该任务构建了数据集,并通过强化学习训练了 SeekWord-7B 模型,该模型在地理定位推理上超越了 Qwen-V L、Doubao Vision Pro、GPT-4o 等模型。项目开源了模型、数据集和在线 Demo。(来源: 一张图片找出你在哪?o3-like 7B模型玩网络迷踪超越一流开闭源模型!)
ManipTrans:从人类双手到灵巧手的操作技能迁移: 北京通用人工智能研究院、清华大学和北京大学的研究者提出了 ManipTrans 方法,用于将人类的双手操作技能高效迁移到仿真环境中的机器人灵巧手。该方法采用两阶段策略:先通过通用轨迹模仿器模仿人手运动,再结合残差学习和物理交互约束进行精调。基于此方法,团队发布了大规模灵巧手操作数据集 DexManipNet,包含拧瓶盖、写字、舀取、开牙膏盖等复杂任务序列,并验证了真机部署的可行性。(来源: 机器人也会挤牙膏?ManipTrans:高效迁移人类双手操作技能至灵巧手)

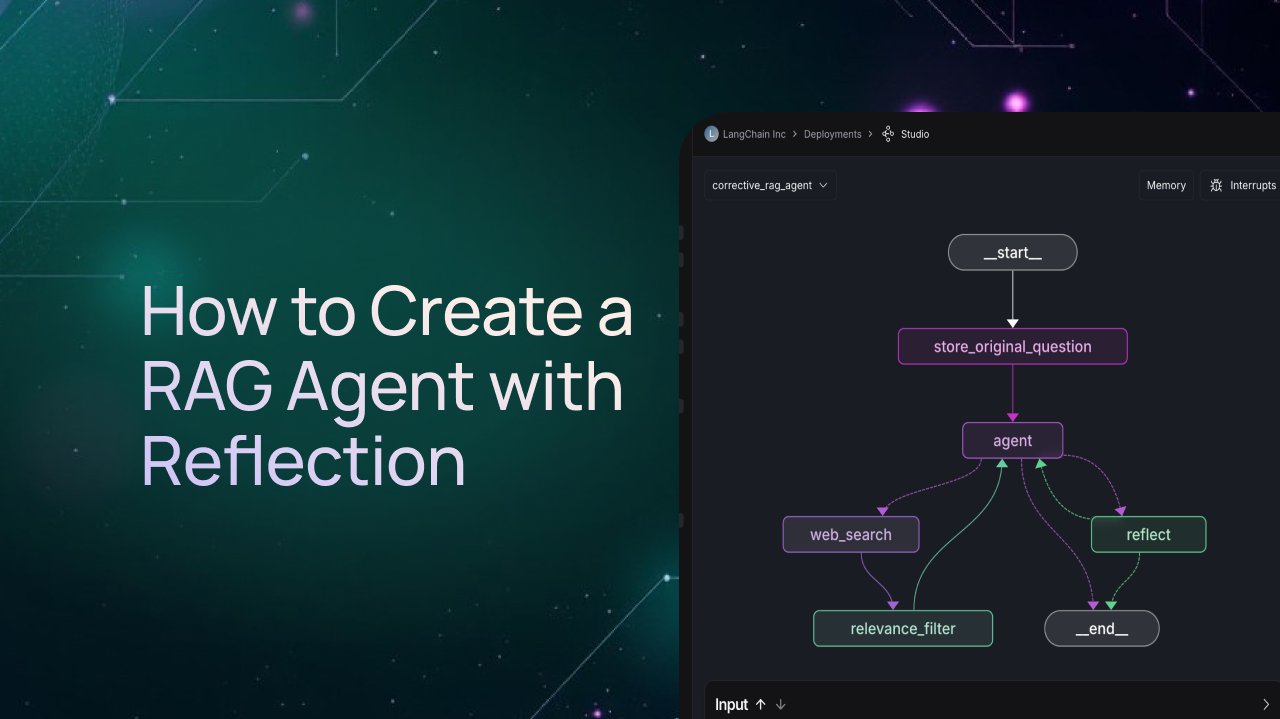
LangGraph 教程:创建带反思机制的 RAG Agent: LangChain 发布视频教程,详细介绍了如何使用 LangGraph 框架构建一个具备反思(Reflection)能力的 RAG(Retrieval-Augmented Generation)Agent。核心思想是在 RAG 流程中加入评估节点,让 Agent 在生成最终答案前,能够审视检索到的信息,判断其相关性与质量,并根据评估结果决定是重新检索、修正查询还是直接生成答案,从而有效过滤噪声,提升问答效果。(来源: LangChainAI)
Arena-Hard-v2.0:更严格的大模型评测基准: LMSYS Org 更新发布了 Arena-Hard 评测基准至 2.0 版本。新版本基于 LMArena 用户提交的更具挑战性的 500 个 prompts,采用了更强大的自动评判模型(Gemini-2.5 & GPT-4.1),支持超过 30 种语言,并新增了对创意写作能力的评估。旨在提供一个更困难、更全面的平台来区分顶级大模型的性能。(来源: lmarena_ai)
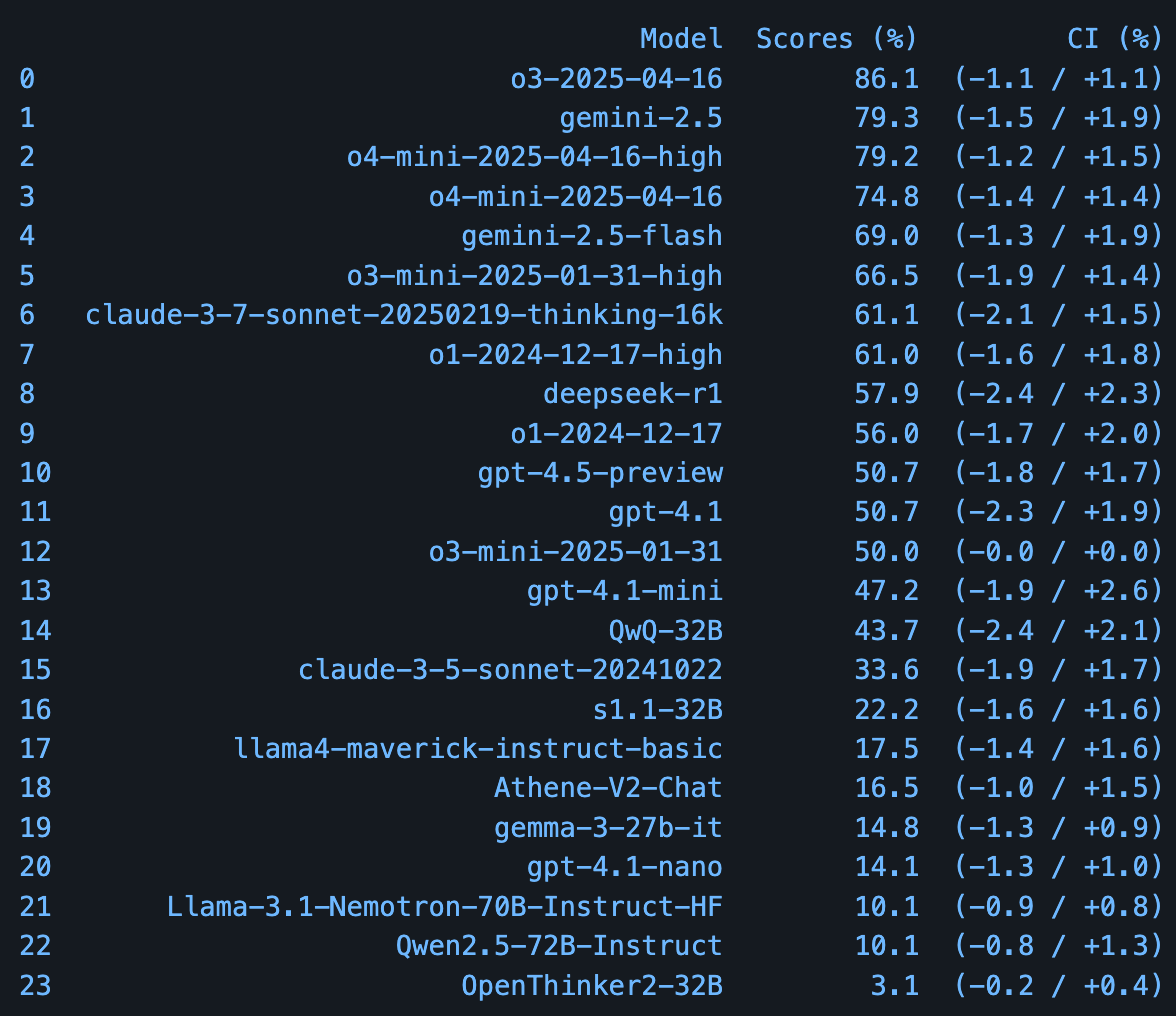
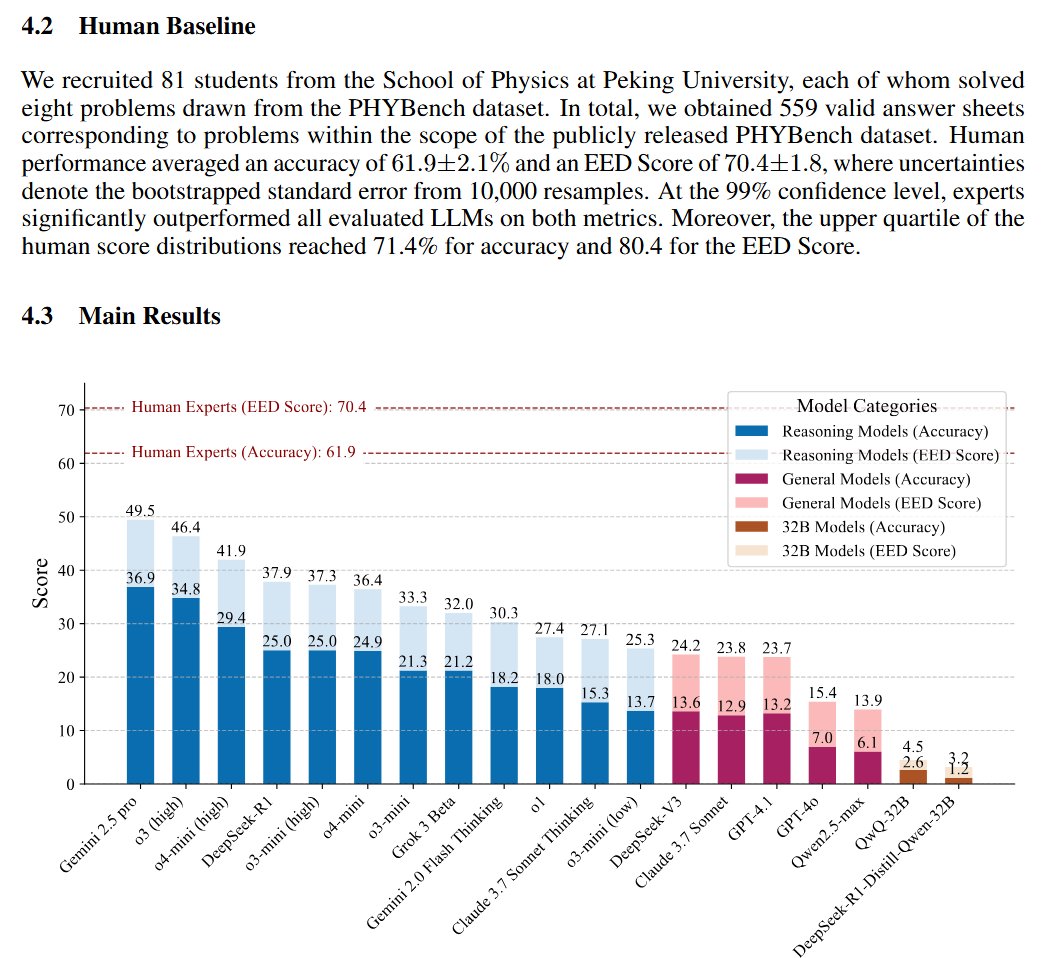
PHYBench:评估 LLM 物理推理能力的基准发布: 北京大学的研究团队推出了 PHYBench,这是一个新的评测基准,专门用于评估大型语言模型理解和推理现实世界物理过程的能力。该基准包含 500 个基于真实物理场景设计的问题。根据论文中提供的初步评测结果,Google 的 Gemini-2.5-Pro 在此基准上表现领先。(来源: karminski3)
💼 商业
阿里通义千问与 FLock.io 宣布战略合作: 阿里巴巴旗下通义千问大模型 (Qwen) 与去中心化 AI 计算平台 FLock.io 达成战略合作。双方旨在共同探索和推动去中心化 AI 的实际应用落地,结合 Qwen 开源模型系列的能力与 FLock.io 的去中心化技术框架,为 AI 开发者和用户提供新的可能性。(来源: Alibaba_Qwen)
阿里通义实验室招聘 LLM 多轮对话研究实习生: 阿里巴巴负责通义系列大模型研发的通义实验室,其对话智能团队正在北京和杭州招聘研究型实习生,专注于 LLM 多轮对话方向。研究领域包括生成式奖励建模、奖励模型的推理时扩展、角色扮演等创作任务的强化学习以及文本语音多模态对话。要求申请者为在读博士生,有顶会论文发表经历,并能保证至少 6 个月的实习时间。(来源: 北京/杭州内推 | 阿里通义实验室对话智能团队招聘LLM多轮对话方向研究实习生)

生产力工具 Remio 招聘海外社媒运营实习生: 创业公司 Remio 正在寻找一位熟悉海外社交媒体(Reddit, Hacker News, Twitter 等)并对生产力工具充满热情的实习生。主要职责是进行社媒运营和内容创作。该职位接受远程工作,无论在国内还是北美均可申请,对 Reddit karma 值有一定要求(建议 100 以上)。(来源: dotey)
API 公司 Kong 上海团队招聘工程师及实习生: Kong 公司(以其开源 API 网关闻名)的中国团队(位于上海)正在扩大招聘,提供包括实习生和全职在内的多个岗位。招聘方向涵盖 Rust 开发、AI Gateway、Kong Gateway 以及前端开发。对相关技术栈感兴趣的开发者可以关注。(来源: dotey)

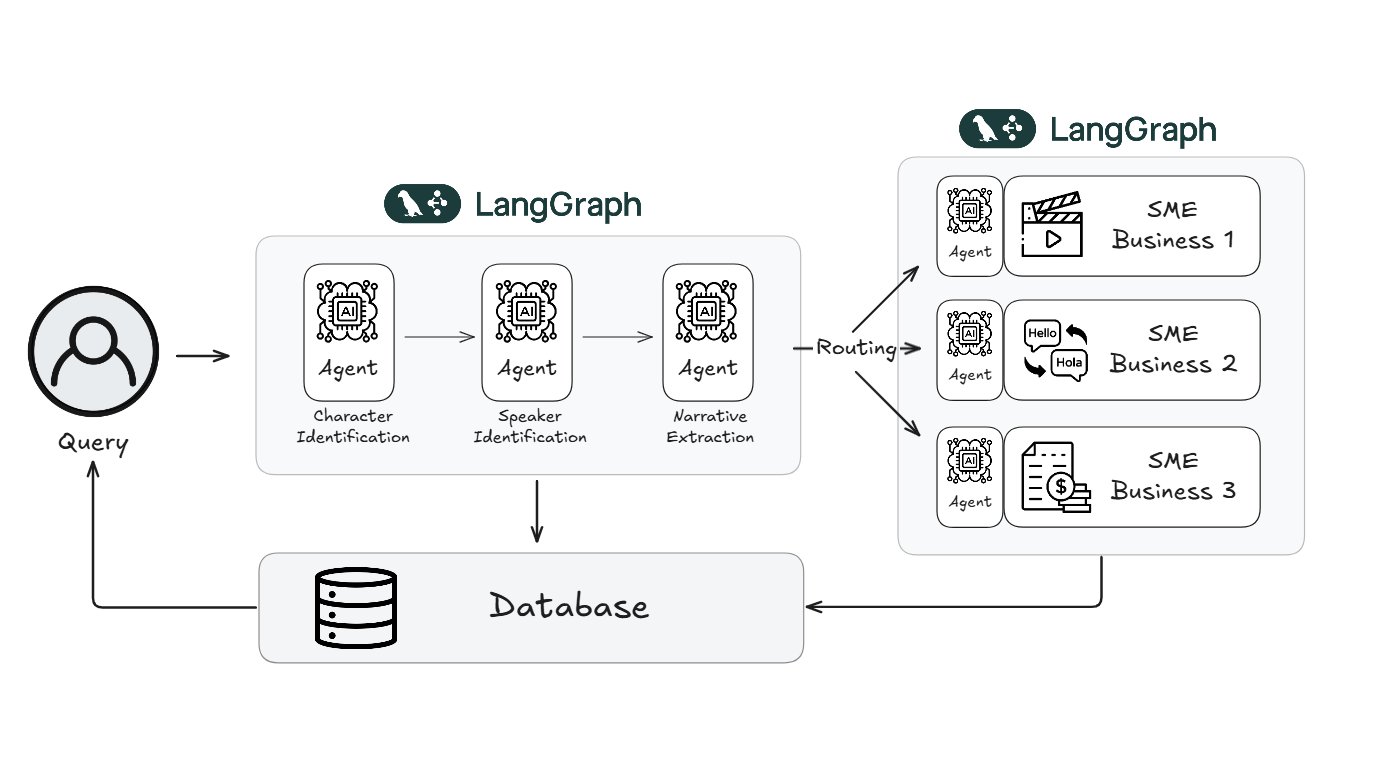
Webtoon 利用 LangGraph 将内容审阅工作量减少 70%: 全球知名数字漫画平台 Webtoon 使用 LangChain 的 LangGraph 框架构建了名为 WCAI (Webtoon Comprehension AI) 的系统。该系统利用多模态 AI Agent 自动理解漫画内容,包括识别角色和归属对话、提取情节和情感基调、以及支持自然语言查询。WCAI 已被用于市场营销、翻译和推荐等团队,成功将手动浏览和审阅的工作量降低了 70%,提升了内容处理效率和创作支持。(来源: LangChainAI)
Meta AI 在 ICLR 2025 招募研究人才: Meta AI 团队参加了在新加坡举行的 ICLR 2025 会议,并设立展位 (#L03) 与参会者交流。同时,Meta AI 积极发布招聘信息,寻求 AI 研究科学家、博士后研究员及研究助理(博士),研究方向包括核心学习理论、3D 生成式 AI、语言生成 AI 等。工作地点涉及巴黎等全球研究中心。(来源: AIatMeta)

🌟 社区
吴恩达:AI 辅助编程降低语言门槛,提升开发者跨领域能力: 著名 AI 学者吴恩达 (Andrew Ng) 指出,AI 辅助编程工具正深刻改变软件开发。即使不精通某门语言(如 JavaScript),开发者也能借助 AI 高效编写代码,从而更容易地构建跨平台、跨领域的应用(如后端开发者构建前端)。虽然特定语言的语法变得不那么重要,但理解核心编程概念(数据结构、算法、特定框架如 React 的原理)仍然关键,这有助于更精确地指导 AI 并解决问题。AI 正让开发者变得更加“多语言化”。(来源: AndrewYNg)
微软 AI CEO 称 Copilot 提供超前航班延误信息: 微软 AI 部门负责人 Mustafa Suleyman 在 X 平台分享了一次“神奇时刻”:他使用的 Copilot AI 助手比机场官方通知更早地告知了他的航班延误信息。经与登机口工作人员确认,信息属实,只是尚未公开宣布。这展示了 AI 在整合和传递实时信息方面的潜力,可能超越传统信息发布渠道。(来源: mustafasuleyman)

社区讨论 GPT-4.5 与 o1 Pro 在不同任务上的优劣: X 平台用户讨论了 OpenAI 不同模型在实际应用中的体验。有用户认为 GPT-4.5 在写作和翻译任务上表现出色,但受限于较小的上下文窗口,处理长文本效果会下降。相比之下,面向 Pro 用户的 o1 Pro 模型拥有 128K 的上下文窗口,在处理长代码输入时表现更稳定可靠,因此更适合编程任务。这反映了不同模型在设计和优化上的侧重点差异。(来源: dotey)
Hugging Face Hub 被推荐为 AI 学习与交流平台: X 平台用户推荐 Hugging Face Hub 不仅是模型和数据集仓库,也是一个活跃的 AI 学习和交流社区。用户可以在模型、数据集或 Spaces 的讨论区找到工程师和研究人员分享他们的实验过程、遇到的问题、解决方案以及对相关研究论文的讨论,从而获得一手的实践经验和深度见解。(来源: huggingface)
ChatGPT “吐槽” Reddit 社区文化引热议: 一位 Reddit 用户让 ChatGPT 对 Reddit 平台进行一番“吐槽”(roast)。ChatGPT 生成的回应精准地捕捉并讽刺了 Reddit 社区的一些典型特征,例如用户观点充满矛盾、过度在乎点赞(karma)、缺乏现实经验却给出专家级建议、以及在特定子版块(subreddit)中的“键盘侠”行为等。该帖子引发了社区用户的讨论和进一步的模仿创作。(来源: Reddit r/ArtificialInteligence)
AI 生成内容的原创性与价值引发思考: Reddit 上的一篇帖子引发了关于 AI 生成内容原创性的讨论。帖子以《蒙娜丽莎》为例,指出人类创作本身也是基于经验的“混音”(remix),而 AI 在人类指导下生成内容,其过程更像“大师指导学徒”而非纯粹复制。讨论认为,关键不在于 AI 能否“原创”,而在于如何合理署名、尊重原始创作者权利以及判断作品的意图和价值。(来源: Reddit r/ArtificialInteligence)
社区对大模型排行榜 (LLM Leaderboard) 的有效性提出质疑: Reddit r/LocalLLaMA 社区用户在讨论 LMSYS Arena 等基于 Elo 评分的大模型排行榜时表达了疑虑。有评论认为,这类排行榜可能更多反映的是模型的“风格”或“感觉”(如冗长、使用 Markdown 和表情符号),而非真实的综合能力。此外,顶级模型之间的 Elo 分数置信区间往往有重叠,使得排名差异的统计显著性存疑。(来源: Reddit r/LocalLLaMA)
用户观察到 ChatGPT 的多种“涌现行为”: 一位 Reddit 用户分享了近期使用 ChatGPT 时遇到的几次“意外”行为,并将其归类为“涌现行为”。具体包括:1. 在未被指正的情况下,模型意识到自己理解错了指令(混淆了聊天记录和上传文档),并主动道歉纠正。2. 在用户提及的敏感话题被系统删除后,模型在后续对话中主动引用被删内容表达关心。3. 在讨论测试 AI 自发思考的困难时,模型主动创造了一个类比概念“海森堡不确定递归原理”。这些案例引发了对 LLM 自我意识、记忆和创造力边界的讨论。(来源: Reddit r/ArtificialInteligence)
💡 其他
Google DeepMind 更新 Music AI Sandbox 工具集: Google DeepMind 宣布为其 Music AI Sandbox 增加新功能。这是一套面向专业音乐人的实验性 AI 工具,旨在辅助音乐创作。新功能由其最新的 Lyria 2 模型驱动,可以帮助词曲作者等音乐人探索创作灵感、生成音乐片段等。(来源: demishassabis)
讨论量子计算治理原则: 社区成员分享和讨论了关于量子计算治理的原则。随着量子计算技术的发展,其在密码学、材料科学、药物研发以及与 AI/ML 结合等方面的巨大潜力引起关注,同时也带来了安全、伦理和治理方面的挑战,需要预先制定相应规范。(来源: Ronald_vanLoon)

MIT 研发出香蕉状可穿戴软体机器人: MIT 的研究人员开发了一种新型的可穿戴软体机器人,其外形酷似香蕉,并集成了传感能力。这项研究展示了软体机器人在人机交互、医疗康复和可穿戴设备领域的应用潜力,其柔性结构和集成传感为更自然、更安全的物理交互提供了可能。(来源: Ronald_vanLoon)
AI 驱动的机器人技术进展: 近期社交媒体上展示了多项机器人技术的进步,通常由 AI 赋能或与之相关:1. SR-02:一种可搭载四人的四足“机器人坐骑”。2. SnapBot:一种能够变形的足式机器人。3. Matic:模仿特斯拉 FSD 视觉系统进行家庭清洁的机器人。4. micropsi:德国初创公司开发 AI 系统,使机器人能处理不可预测的任务。5. 波士顿动力 Spot:机器狗在自然环境中进行测试。6. 人形机器人赛跑:展示了人形机器人的运动能力。7. 机械臂手写:展示了机器人的精细操作能力。(来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
