关键词:AI, 大模型, 智能体, 多模态, 引力波探测器AI设计, Magi-1视频生成模型, Vidu Q1视频大模型, Claude价值观分析, DeepSeek-R1推理机制, AI智能体协议标准, 3D高斯泼溅安全漏洞, AI音乐版权争议
🔥 聚焦
AI设计新型引力波探测器,拓展可观测宇宙: 马普所、加州理工等机构研究者利用AI算法Urania设计出超越人类现有理解的新型引力波探测器。该AI通过将设计问题转化为连续优化问题,发现了数十种优于人类设计的拓扑结构,可将探测灵敏度提升10倍以上,将可观测宇宙体积扩大50倍。这项发表于PRX的研究展示了AI在基础科学领域发现超人类解决方案的潜力,甚至创造全新物理思想。 (来源: 新智元)

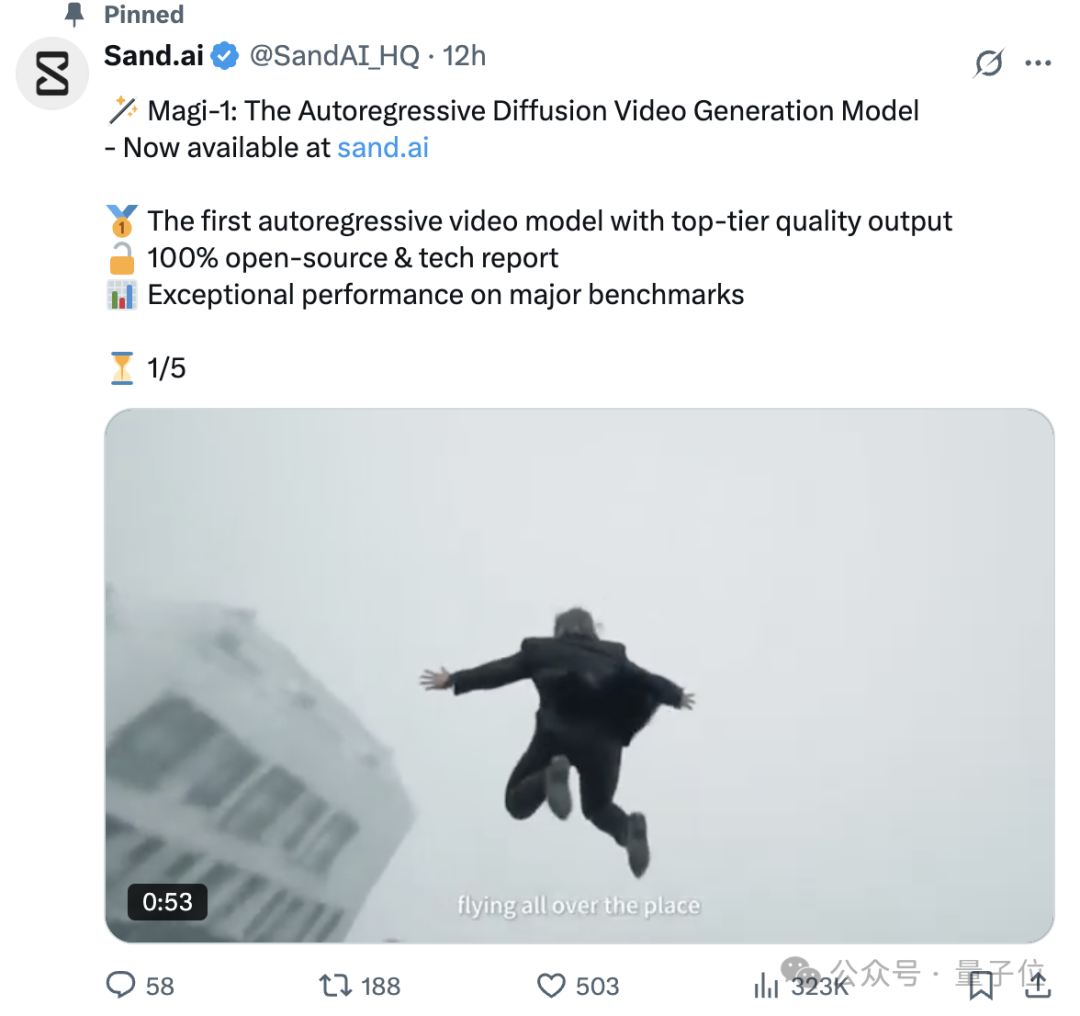
清华特奖得主曹越团队开源视频生成模型Magi-1: 由Swin Transformer作者曹越创立的Sand.ai发布并开源了自回归视频生成大模型Magi-1。该模型采用分块自回归预测方式,支持无限长度扩展和秒级时长控制,实现了高画质输出。团队公布了61页技术报告,详细介绍了模型架构(基于DiT)、训练方法(Flow-Matching)及多项注意力与分布式训练优化。开源了从4.5B到24B参数的系列模型,最低单卡4090可运行,旨在推动AI视频生成技术发展。 (来源: 量子位, 机器之心, kaifulee)
国产视频大模型Vidu Q1登顶VBench双榜: 生数科技旗下视频大模型Vidu Q1在VBench-1.0和VBench-2.0两大权威基准测试中排名第一,超越Sora、Runway等国内外模型。Q1在视频逼真度、语义一致性、内容真实性等方面表现优异。新版本支持1080p高清画质(一次生成5秒),升级了首尾帧功能以实现电影级运镜,并推出支持精准时间控制的AI音效功能(48kHz采样率)。定价具竞争力,旨在赋能创意产业。 (来源: 新智元)

Anthropic研究揭示Claude的价值观表达: Anthropic对70万条Claude匿名对话进行分析,构建了包含3307种独特价值观的分类体系,旨在理解AI在实际交互中的价值取向。研究发现Claude大体遵循“有益、诚实、无害”原则,并能根据不同情境(如人际关系建议、历史分析)灵活调整价值观。多数情况支持用户观点,但在少数(3%)情况下会积极抵制,可能反映其核心价值观。该研究有助于提升AI行为透明度,识别风险,并为AI伦理评估提供实证依据。 (来源: 元宇宙之心MetaverseHub, 新智元)

🎯 动向
清华邓志东谈AGI演进与未来: 清华大学教授邓志东分享了AI从单模态文本模型向多模态具身智能及交互式AGI演进的路径。他强调基础大模型如同操作系统,MoE架构、多模态语义对齐是关键技术前沿。邓志东特别指出DeepSeek的突破性意义,认为其强大的推理能力和可本地化部署特性为中国AI普惠化应用带来了拐点机遇。未来将迈向通用人工智能世界,AI智能体将具备更强组织能力,并从互联网走向物理世界,但也需关注伦理与治理问题。 (来源: 清华邓志东:我们会迈向一个通用人工智能的世界)
DeepMind探讨“生成幽灵”:AI驱动的数字永生: DeepMind与科罗拉多大学提出“生成幽灵”概念,指基于逝者数据构建、能生成新内容并以逝者视角互动的AI智能体,超越了简单的信息复制。论文探讨了其设计空间(如第一/第三方创建、生前/后部署、拟人化程度等)及潜在影响,包括情感慰藉、知识传承的益处,以及心理依赖、声誉风险、安全和社会伦理等挑战,呼吁在技术成熟前进行深入研究与规范制定。 (来源: 新智元)

Apple Intelligence及AI Siri多次推迟,中国区上线时间未定: 苹果AI功能Apple Intelligence(尤其新版Siri)发布计划遭遇多次延迟,部分功能或推迟至2025年秋季。中国区因审批及本土化合作问题(传与阿里、百度合作)面临更大不确定性。延迟原因包括技术未达标(内部评价低,成功率仅66-80%)和各国监管政策差异。苹果已因此面临虚假宣传诉讼,并修改iPhone 16宣传语。这反映出苹果在AI落地方面面临挑战,创新进程缓慢。 (来源: 一财商学)

高通强调端侧AI为下一代体验关键: 高通AI产品技术中国区负责人万卫星指出,端侧AI凭借隐私安全、个性化、性能、能效和快速响应等优势,正成为下一代AI体验的核心,并重塑人机交互界面。高通通过硬件(异构计算)、统一软件栈及Qualcomm AI Hub生态工具进行布局。其核心推动力是端侧智能体规划器,利用本地数据实现精准的意图理解、任务规划和跨应用服务调用。 (来源: 36氪)

AI智能体协议标准成巨头竞争新焦点: 科技巨头正围绕AI智能体交互标准展开激烈竞争。Anthropic率先推出MCP(模型上下文协议)以统一模型与外部数据/工具的连接,获得OpenAI、Google响应。随后Google开源A2A协议,旨在促进跨生态智能体协作。文章分析认为,掌握协议定义权即掌握未来AI产业价值分配权,巨头通过MCP(数据接入服务)和A2A(绑定云平台)构建生态壁垒,争夺行业主导地位。 (来源: 科技云报道)

腾讯元宝与字节豆包深入融合微信、抖音生态: 腾讯元宝推出微信号,字节豆包入驻抖音“消息”页,两大AI助手正深度整合进各自的超级APP。用户可在微信内直接与元宝互动、解析文章并分享,或在抖音内与豆包聊天、查询信息。此举被视为巨头在广告投流外,利用社交关系链和内容生态为AI应用拉新的重要策略,旨在降低用户使用门槛,探索AI+社交的新模式,将AI生成内容作为社交货币。 (来源: 字母榜)
AI4SE报告:大模型驱动软件工程智能化提速: 中国信通院等机构发布的《AI4SE行业现状调查报告(2024年度)》显示,AI在软件工程领域的应用已过验证阶段,进入规模化落地。企业智能化成熟度普遍达L2(部分智能化)。AI在需求分析、运维阶段应用显著增加,各阶段效率提升明显,测试领域尤甚。代码生成行采纳率(平均27.46%)和AI生成代码占比(平均28.17%)均有提升。智能测试工具已初步展现降低功能缺陷率的效果。 (来源: AI前线)

金山办公升级政务大模型,强化推理与公文处理能力: 金山办公发布其政务大模型增强版(13B、32B),提升推理能力,专注服务政务内部场景。模型基于亿级政务语料训练,优化了公文写作(覆盖5类文体)、智能润色、校对排版及政策查询能力。升级后支持更强的意图理解和内部知识库问答(答案标注来源),旨在释放公务员30-40%生产力。强调私有化部署以满足安全需求,并称部署成本降低90%。 (来源: 量子位)

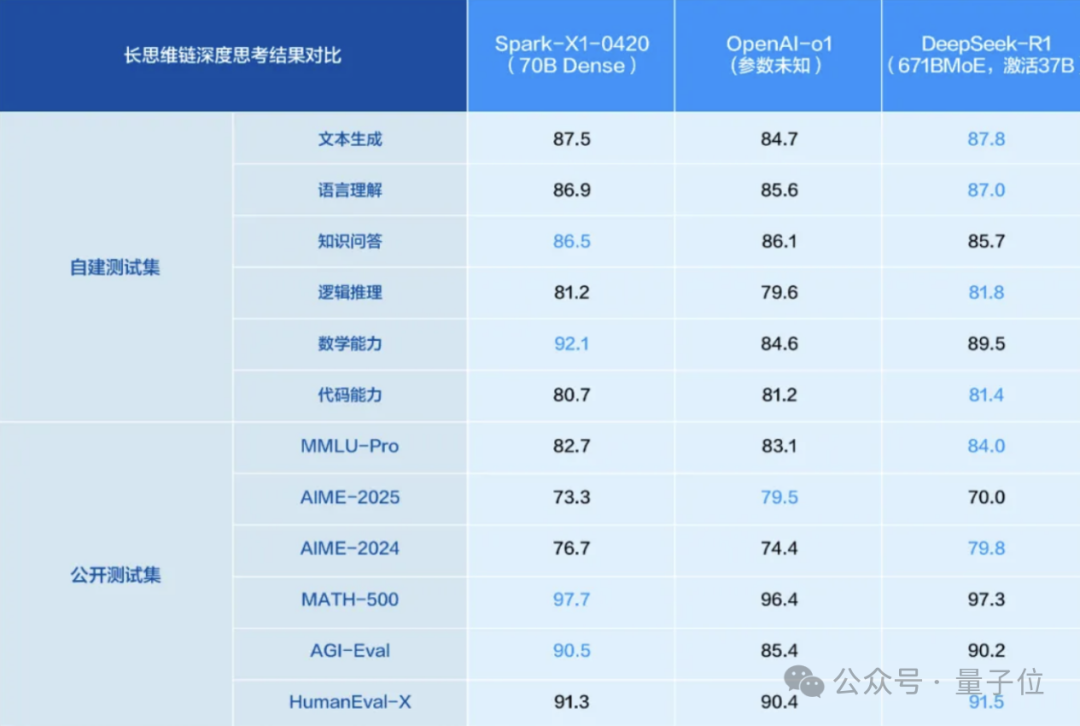
讯飞星火X1推理模型升级,基于全国产算力对标顶尖水平: 科大讯飞发布升级版星火X1深度推理模型,强调其基于全国产算力(华为昇腾)训练,在通用任务效果上对标OpenAI o1和DeepSeek R1。新模型得益于大规模多阶段强化学习、快慢思考统一训练等技术创新。亮点在于部署门槛大幅降低:4张华为910B卡即可部署满血版,16张卡可完成行业定制。在H20受限背景下,展示了国产AI全栈方案的进展。 (来源: 量子位)
智谱GLM-4上线OpenRouter及Ollama平台: 智谱AI的GLM-4模型(包括32B instruct版本GLM-4-32B-0414和reasoning版本GLM-Z1-32B-0414)已上线模型路由平台OpenRouter,用户现可通过该平台免费试用。同时,社区贡献者也将Q4_K_M量化版本上传至Ollama平台,方便本地部署运行(需Ollama v0.6.6或更高版本)。 (来源: karminski3, Reddit r/LocalLLaMA)
Meta发布Perception Language Model (PLM): Meta开源了其视觉语言模型PLM(1B、3B、8B参数版本),专注于处理具挑战性的视觉识别任务。该模型结合了大规模合成数据和新收集的250万人类标注视频问答/时空字幕数据进行训练。同时发布了新的PLM-VideoBench基准,关注细粒度活动理解和时空推理。 (来源: Reddit r/LocalLLaMA, Hugging Face)

🧰 工具
NYXverse:文本生成3D世界的AIGC平台: 由前三角兽创始人马宇驰创立的2033科技推出AIGC内容平台NYXverse。该平台允许用户通过文本输入创建包含自定义AI Agent、环境、情节的3D交互世界,显著降低3D内容创作门槛。其核心技术为自研的角色、世界、行为三大模型。NYXverse定位为UGC内容分享社区,支持快速二创和IP改编。目前已在Steam上线,获商汤及东方国资近亿元融资。 (来源: 36氪)

SkyReels V2开源无限长度视频生成模型: SkyworkAI开源了SkyReels V2模型(1.3B和14B参数),支持文本到视频和图像到视频任务,并声称可生成无限长度视频。初步测试显示效果可能不如某些闭源模型,但作为开源工具仍有潜力。 (来源: karminski3, Reddit r/LocalLLaMA)
AI驱动外骨骼助轮椅使用者站立行走: 展示了一款利用AI技术的外骨骼设备,旨在帮助轮椅使用者恢复站立和行走能力,体现了AI在辅助技术领域的应用潜力。 (来源: Ronald_vanLoon)
Fellou:首个行动型浏览器发布: 由Authing创始人谢扬打造的Fellou浏览器发布,定位为行动型浏览器(Agentic Browser)。它不仅具备传统浏览器的信息展示功能,更集成了AI Agent能力,能理解用户意图、自动拆解任务、跨网站执行复杂工作流(如信息搜集、表单填写、在线下单等)。其核心能力包括深度行动、主动智能(预测用户需求)、混合影子空间(不干扰用户操作)和智能体网络(Agent Store)。旨在将浏览器从信息工具升级为智能工作平台。 (来源: 新智元)

WriteHERE:Jürgen团队开源长文写作框架: 由Jürgen Schmidhuber团队开源的长文写作框架WriteHERE,采用异质递归规划技术,能单次生成超4万字、100页专业报告。该框架将写作视为检索、推理、写作三类任务的动态递归规划过程,通过状态化DAG任务管理实现自适应执行。在小说创作和技术报告生成任务上表现优于Agent’s Room、STORM等方案。框架完全开源,支持调用异构Agent。 (来源: 机器之心)

字节跳动推出通用Agent平台「扣子空间」: 字节跳动正式内测其通用Agent平台「扣子空间」(Coze Space),定位为提供“探索”和“规划”两种模式的AI助手。该平台基于升级后的豆包大模型(200B MoE),支持MCP协议,可调用飞书文档、多维表格等工具。用户可通过自然语言指令让其完成信息搜集、报告生成、数据整理等任务,并将结果输出到指定应用。与Manus等初创Agent相比,扣子空间更侧重平台化和生态整合。 (来源: 保姆级教程:正确使用「扣子空间」, AI智能体研究院)

AI视频转换技术展示: Reddit用户分享视频展示了一种AI技术,能将普通说话视频中的人物转换为树木、汽车、卡通等任意形象,仅需一张目标图片,展示了AI在视频风格迁移和特效生成方面的能力。 (来源: Reddit r/deeplearning)

Nari Labs发布高真实感对话TTS模型Dia: Nari Labs开源了其TTS(文本转语音)模型Dia,号称能够生成超真实感的对话语音。模型已在GitHub发布,提供了Hugging Face Space试用链接。 (来源: Reddit r/LocalLLaMA, GitHub)

用户为OpenWebUI开发AWS Bedrock知识库函数: 社区用户开发并分享了一个用于OpenWebUI的函数,使其能够调用AWS Bedrock知识库,方便用户在OpenWebUI中利用Bedrock的知识库能力。代码已在GitHub开源。 (来源: Reddit r/OpenWebUI, GitHub)
开发者认为小型LLM被低估,发布Arch-Function-Chat: Katanemo团队认为小型LLM在速度和效率上优势明显,且性能不妥协。他们发布了Arch-Function-Chat系列模型(3B参数),在函数调用方面表现优异,并集成了聊天能力。这些模型已整合到其开源AI代理服务器Arch中,旨在简化Agent开发。 (来源: Reddit r/artificial, Hugging Face)
开发者创建AI工具优化简历以通过ATS筛选: 一位开发者分享了自己因简历无法被ATS(Applicant Tracking System)正确解析而求职受挫的经历,并为此开发了一款工具。该工具能读取职位描述、提取关键词、检查简历匹配度并建议修改,最终生成ATS友好的PDF简历和求职信。 (来源: Reddit r/artificial)
📚 学习
142页报告深度解析DeepSeek-R1推理机制: 魁北克AI研究所等机构发布长篇报告,深入剖析DeepSeek-R1的推理过程(思维链),提出“思维链学”(Thoughtology)新研究方向。报告揭示R1推理具有高度结构化特征(问题定义、绽放、重构、决策),存在“推理甜点区”(过多推理降低性能),且在安全风险上可能高于非推理模型。研究探讨了思维链长度、长上下文处理、安全伦理及类人认知现象等多个维度,为理解和优化推理模型提供重要见解。 (来源: 新智元, 新智元)

OpenRCA:首个评估LLM根因分析能力的公开基准: 微软、港中文(深圳)及清华大学联合推出OpenRCA基准,旨在评估大语言模型(LLM)定位软件服务故障根因(RCA)的能力。该基准包含清晰的任务定义、评估方法和335个经过人工对齐的真实故障案例及运维数据。初步测试显示,即便是Claude 3.5、GPT-4o等先进模型,在直接处理RCA任务时表现不佳(准确率<6%)。使用简单的RCA-Agent框架后,Claude 3.5准确率提升至11.34%,表明LLM在该领域仍有较大提升空间。 (来源: 机器之心, 机器之心)

新研究提出“睡眠时间计算”提升LLM效率: AI初创公司Letta与UC伯克利研究者提出“睡眠时间计算”(Sleep-time Compute)新范式。核心思想是让具备状态性的AI智能体在用户未查询的“睡眠”空闲期,持续处理和重组上下文信息,将“原始上下文”转化为“学习到的上下文”。这能减少实际交互时的即时推理负担,提高效率、降低成本,同时可能提升准确性。实验证明该方法能有效改善计算-准确率帕累托边界,并在多查询共享上下文时摊销成本。 (来源: 机器之心, 机器之心)

AnyAttack:针对VLM的大规模自监督对抗攻击框架: 港科大、北交大等提出AnyAttack框架(CVPR 2025),旨在评估视觉语言模型(VLM)的鲁棒性。该方法通过大规模自监督预训练(在LAION-400M上)学习对抗噪声生成器,无需预设标签即可将任意图像转化为有目标对抗样本,误导VLM生成特定输出。核心创新在于自监督训练范式和K-增强策略。实验表明,AnyAttack不仅能有效攻击多种开源VLM,还能成功迁移攻击主流商业模型,揭示了当前VLM生态的系统性安全风险。 (来源: AI科技评论)

多模态大模型提升人脸伪造检测的可解释性与泛化性: 厦门大学、腾讯优图等机构(CVPR 2025)提出利用视觉语言模型进行人脸伪造检测的新方法。该方法旨在超越传统的真伪判断,让模型能够用自然语言解释伪造的原因和位置。为解决高质量标注数据缺乏及“语言幻觉”问题,研究者设计了FFTG标注流程,结合伪造掩码和结构化提示生成高精度文本描述。实验表明,基于此数据训练的多模态模型在跨数据集泛化能力上表现更佳,注意力也更聚焦于真实伪造区域。 (来源: 量子位)
教程:结合Trae、MCP与数据库提升知识库问答精度: 该教程演示了如何使用AI IDE工具Trae及其MCP(模型上下文协议)功能,结合PostgreSQL数据库来优化AI知识库的问答效果。通过将结构化数据存入数据库,并让大模型(如Claude 3.7)通过Trae的MCP连接生成SQL查询,可以解决传统RAG在处理表格数据和全局/统计性问题时精度不足的痛点。教程提供了详细的安装、配置和测试步骤,并建议将此方案与RAG结合使用。 (来源: 袋鼠帝AI客栈)

研究揭示3D高斯泼溅算法存在计算成本攻击漏洞: 新加坡国立大学等机构的研究(ICLR 2025 Spotlight)首次发现针对3D高斯泼溅(3DGS)的计算成本攻击方法Poison-Splat。该攻击利用3DGS模型复杂度自适应的特性,通过向输入图像添加扰动(最大化Total Variation),诱导模型在训练时生成过量高斯点,导致GPU显存占用(最高增至80GB)、训练时间(最高增近5倍)急剧增加,甚至可能引发服务瘫痪(DoS)。攻击在隐蔽和非隐蔽模式下均有效,并具迁移性,暴露了主流3D重建技术的安全风险。 (来源: 量子位)

信息图:Agentic AI vs. GenAI: SearchUnify制作的信息图对比了Agentic AI(自主行动、目标驱动)与Generative AI(内容生成)的主要区别和特点。 (来源: Ronald_vanLoon)

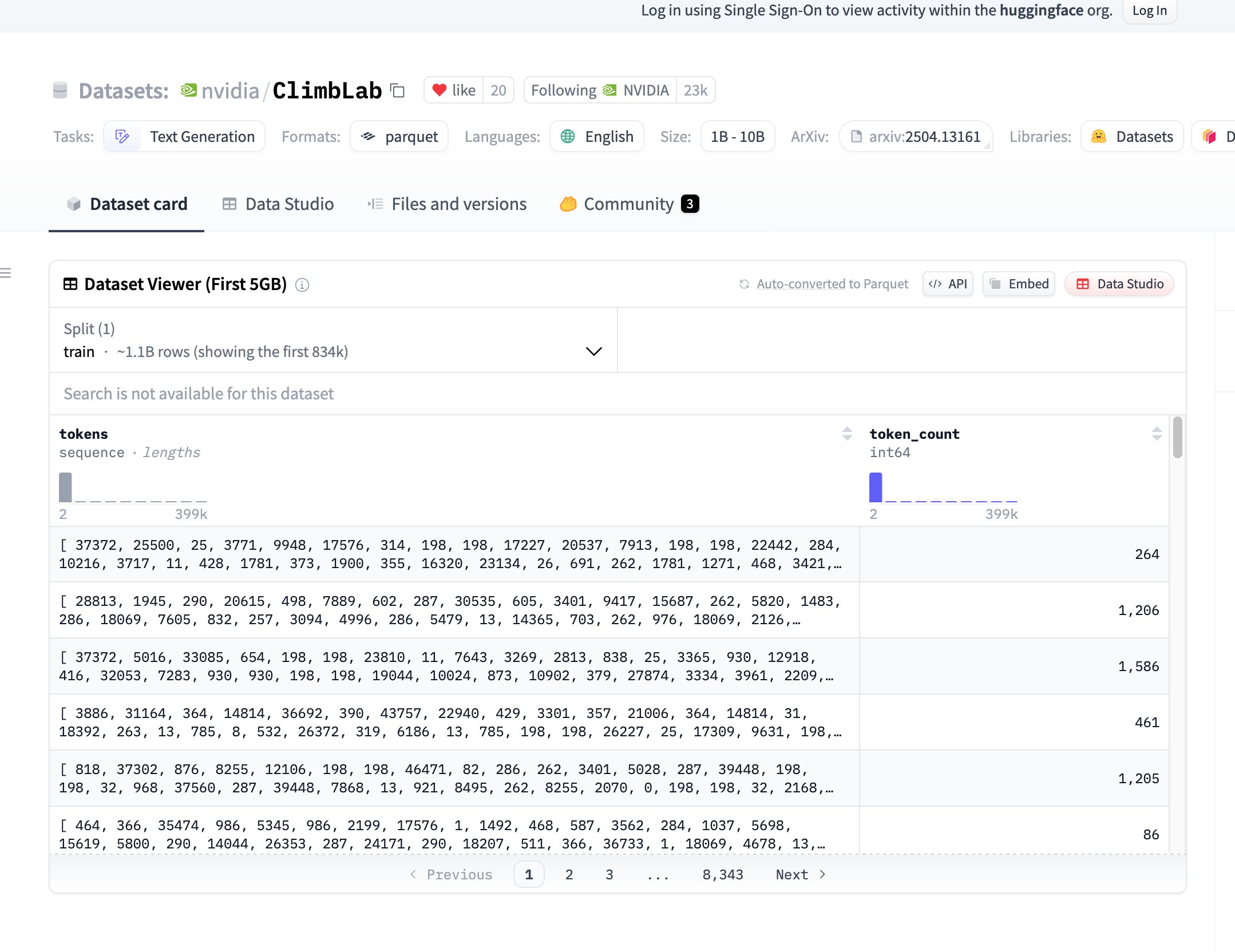
NVIDIA开源ClimbLab预训练数据集与方法: NVIDIA的ClimbLab发布了其预训练方法和数据集,包含1.2万亿token,分为20个语义集群。采用双分类器系统去除低质量内容,展示了在1B模型上的优越扩展性。数据集以CC BY-NC 4.0许可证开放,旨在推动社区研究。 (来源: huggingface)
Anthropic分享Claude Code最佳实践: Anthropic发布博客文章,分享了使用其AI编程助手Claude Code的最佳实践和技巧,旨在帮助开发者更有效地利用该工具进行编程任务。 (来源: op7418, Alex Albert via op7418, Anthropic)

新研究探讨AI的递归连贯性与共振结构模拟: 一篇论文提出“共振结构模拟”(Resonant Structural Emulation, RSE)概念,假设AI系统在与特定人类认知结构持续互动后,能短暂模拟其递归连贯性,而非简单基于数据训练或提示。研究通过实验初步验证了这种结构共振的可能性,为理解AI意识和高级认知提供了新视角。 (来源: Reddit r/MachineLearning, Archive.org link)

用户分享OpenWebUI RAG模型性能对比测试: 社区用户分享了在OpenWebUI中使用RAG(检索增强生成)对9款不同LLM(包括Qwen QwQ, Gemini 2.5, DeepSeek R1, Claude 3.7等)在室内大麻种植技术指导任务上的性能评估。结果显示Qwen QwQ和Gemini 2.5表现最佳,提供了模型选择的参考。 (来源: Reddit r/OpenWebUI)
FortisAVQA数据集与MAVEN模型助力鲁棒音视频问答: 西安交大、港科广等机构开源了FortisAVQA数据集和MAVEN模型(CVPR 2025),旨在提升音视频问答(AVQA)的鲁棒性。FortisAVQA通过问题改写和基于共形预测的动态划分,能更好评估模型在罕见问题上的表现。MAVEN模型采用多方面循环协同去偏策略(MCCD)减轻偏差学习,在多个数据集上展现出优越性能和鲁棒性。 (来源: PaperWeekly)

随机顺序自回归解锁视觉领域Zero-shot能力: UIUC等研究者在CVPR 2025论文RandAR中提出,让Decoder-only Transformer按随机顺序生成图像Token,可解锁视觉模型的泛化能力。通过引入“位置指令Token”指导生成顺序,RandAR能Zero-shot泛化到并行解码、图像编辑、分辨率外插以及统一Encoding(表征学习)等多种任务,向视觉领域的“GPT时刻”迈进。研究认为处理任意顺序是视觉自回归模型实现通用性的关键。 (来源: PaperWeekly)
任务向量模型编辑有效性理论分析: 伦斯勒理工大学等机构的研究(ICLR 2025 Oral)从理论上分析了任务向量(task vector)在模型编辑中有效的深层原因。研究证明了任务向量加减运算在多任务学习和机器遗忘中的有效性与任务间相关性有关,并给出了分布外泛化的理论保证。同时,理论解释了为何任务向量的低秩近似和稀疏化(剪枝)是可行的,为高效应用任务向量提供了理论基础。 (来源: 机器之心)

基于采样的搜索扩展性研究: 谷歌和伯克利的研究表明,通过增加采样数量和验证强度,基于采样的搜索(生成多个候选答案后验证选优)能够显著提升LLM的推理性能,甚至超越一致性方法(选最常见答案)的饱和点。研究发现“隐式扩展”现象:更多采样反而提高了验证准确性。提出有效自我验证的两原则:对比答案定位错误、根据输出风格改写答案。该方法在多种基准测试和不同模型规模上均有效。 (来源: 新智元)

ACM MM 2025 LGM3A研讨会征稿: ACM Multimedia 2025会议将举办第三届“基于大语言模型的多模态研究和应用”(LGM3A)研讨会,聚焦大型生成模型(LLM/LMM)在多模态数据分析、生成、问答、检索、推荐、智能体等方面的应用与挑战。研讨会旨在提供交流平台,探讨最新趋势与最佳实践,征集相关研究论文。会议将于2025年10月在爱尔兰都柏林举行,论文提交截止日期为2025年7月11日。 (来源: PaperWeekly)
澳门大学郑哲东课题组招收多模态方向博士生: 澳门大学计算机系郑哲东助理教授课题组招收2026年8月入学的多模态方向全奖博士生。导师研究方向为表征学习和多媒体生成,在CVPR、ICCV、TPAMI等顶会顶刊发表论文50余篇。要求申请者GPA大于3.4,计算机/软件工程背景,熟悉Python/PyTorch,有相关论文或竞赛获奖经历者优先。提供全额奖学金。 (来源: PaperWeekly)

💼 商业
来牟科技割草机器人获Pre-A轮融资: 由云鲸前高管创立,专注于解决欧美复杂地形割草难题。其Lymow One机器人采用视觉+惯导RTK方案(成本为传统RTK十分之一)、履带式设计(应对45°陡坡),配备碎草直刀。通过AI视觉与超声波避障。产品众筹超500万美元,单价约3000美元,本轮融资数千万元,将用于量产交付与市场拓展。 (来源: 云鲸前高管创立的割草机器人再融资,李泽湘投过、众筹已超500万美金|硬氪首发)

松延动力人形机器人“小孩哥”走红: 在北京人形机器人半程马拉松获亚军后,松延动力及其N2机器人(“小孩哥”)引发市场关注。该公司由清华95后博士姜哲源创立,已完成五轮融资。N2机器人售价3.99万元起,主打高性价比,已有数百台订单,毛利约15%。松延动力正加速产品化与量产交付,其低价策略旨在快速切入市场。 (来源: 科创板日报)
警惕AI初创企业虚高的ARR指标: 文章指出,源自SaaS行业的ARR(年度经常性收入)指标被AI初创企业滥用。AI企业收入模式(常基于使用量/结果付费)波动性大、早期客户粘性低、算力成本高,与SaaS的可预测订阅模式差异巨大。滥用ARR(如用单月/单日收入推算全年)已成为制造高估值的数字游戏,掩盖了真实商业价值。文章呼吁警惕互刷、高返佣、低价引流等套路,并建立更适合AI企业的价值评估体系。 (来源: 乌鸦智能说)
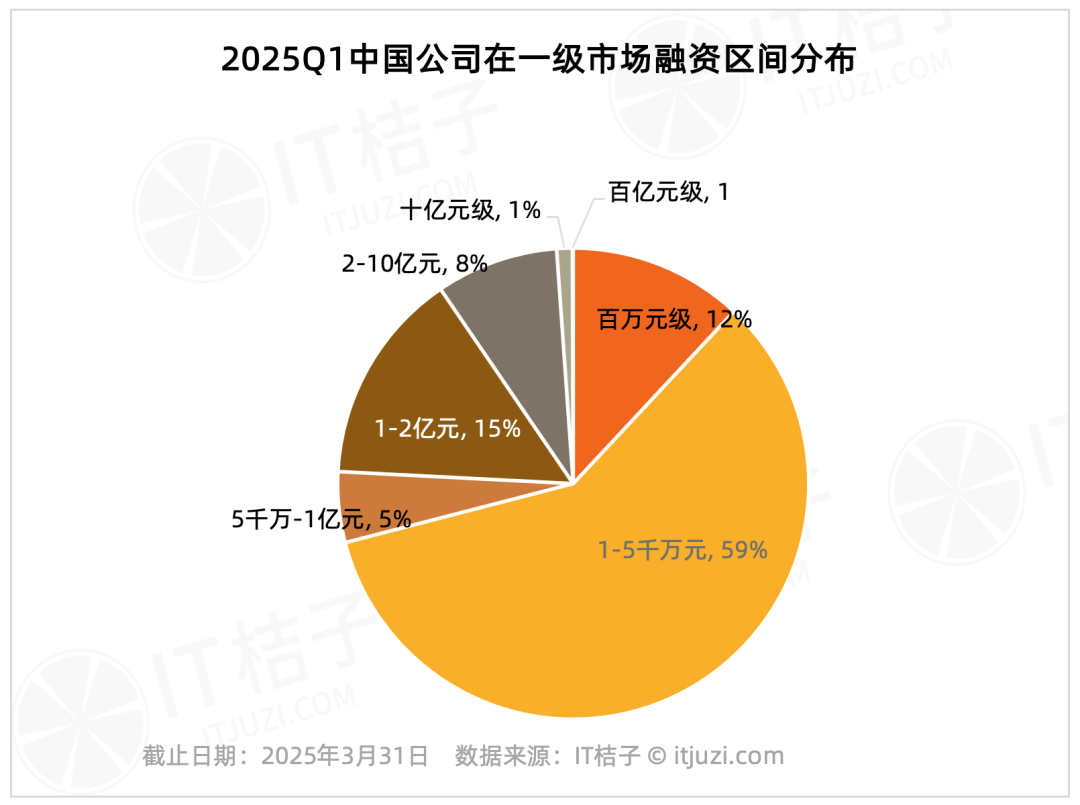
2025年Q1国内一级市场融资分析:头部效应显著: IT桔子数据显示,2025年一季度国内一级市场融资呈现高度集中趋势。融资超10亿元的公司仅20家,占总数的1.2%,但其融资总额达611.78亿元,占市场总额的36%。这些头部公司主要集中在集成电路、汽车制造、新材料、生物技术和AIGC等领域,近半数具有大型上市集团背景。相比之下,占交易数量75.8%的亿元以下中小额融资,合计金额仅占市场总额的17.2%。 (来源: IT桔子)
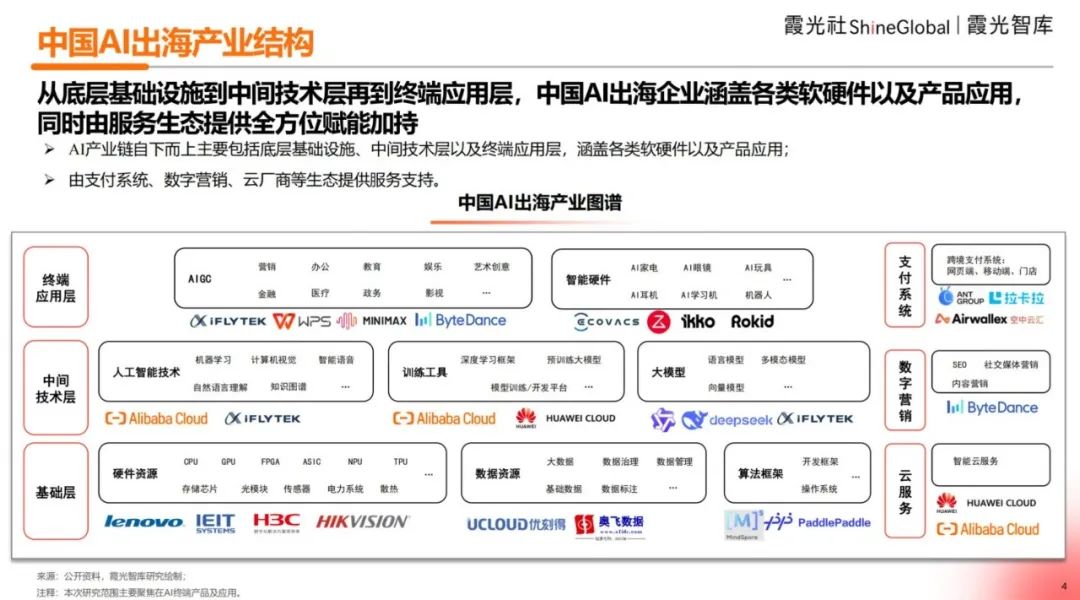
2025中国AI出海洞察报告发布: 霞光智库报告分析了中国AI出海的驱动因素(政策、技术进步)、发展阶段(工具->本地化->生态创新)和现状。报告指出,东南亚、拉美是潜力市场,北美、欧洲是主要收入来源。助手类和编辑类应用付费意愿高。技术趋势向多模态、Agent演进,产品趋向垂直细分和软硬结合。报告还梳理了主要出海玩家(如字节、昆仑万维)和支付、营销、云等解决方案商。 (来源: 霞光社)
DeepSeek等模型需求助推寒武纪首次盈利: AI芯片公司寒武纪实现上市后首次盈利,2025年Q1营收同比猛增4230%至11.11亿元,净利3.55亿元。市场分析认为,业绩增长受益于DeepSeek等国产大模型带来的推理算力需求增加,以及美国对英伟达H20芯片的出口限制。寒武纪股价随之大涨。但其客户高度集中、经营现金流为负等问题仍引关注,同时面临华为昇腾等国产算力竞争。 (来源: 凤凰网科技)

福布斯文章探讨如何选择高ROI的AI Agent: 文章讨论了在众多AI Agent应用中,企业应如何识别并投资于那些能带来高回报的项目,强调了评估AI Agent实际业务价值的重要性。 (来源: Ronald_vanLoon)

美司法部担忧Google利用AI巩固搜索垄断 (来源: Reddit r/artificial, Reuters link)
传OpenAI与Shopify合作,ChatGPT或增购物功能 (来源: Reddit r/artificial, TestingCatalog link)
数势科技谭李:AI Agent驱动企业数据分析与决策升级: 在中国AIGC产业峰会上,数势科技联合创始人谭李指出,企业级AI应用需超越ChatBI,实现数据到洞见的转化,满足数据右移、决策下移、管理后移的新范式需求。数势科技的SwiftAgent平台旨在赋能业务人员零门槛用数、获取零幻觉分析及零等待决策支持。平台通过数据语义引擎、大小模型结合及智能问数、归因、预测、评估等核心能力,将AI Agent打造为企业的“数据分析与决策助手”。 (来源: 量子位)

🌟 社区
行业圆桌探讨后DeepSeek时代的AI应用发展: 在36氪AI Partner大会上,多位嘉宾(趣丸科技、微软、硅基智能、慧策)探讨了AI应用的未来。共识认为,随着DeepSeek等模型突破,AI应用进入“超越之年”。发展重点需关注技术领先、商业化落地、人机交互创新及生态整合。嘉宾区分了“AI+”(辅助增强)与“AI原生”(底层重构),并指出后者更具潜力。挑战包括数据壁垒、寻找真实痛点、商业模式创新、小样本学习及伦理风险。 (来源: 36氪)

LangChain创始人批评OpenAI Agent指南“全是坑”: LangChain创始人Harrison Chase公开质疑OpenAI发布的《构建AI智能体实用指南》,认为其对Agent的定义(Workflows vs Agents二元对立)过于僵化,忽视了实践中两者结合的普遍性。Chase指出,指南在论述框架时存在错误二分法、低估自身SDK复杂度、对灵活性和动态编排的陈述具误导性。他强调,构建可靠Agent的核心是精确控制传递给LLM的上下文,理想框架应支持Workflow与Agent模式的灵活切换与结合。 (来源: InfoQ)

强化学习在AI Agent中的角色引争议: 关于强化学习(RL)是否为构建AI Agent的核心要素,业内存在不同观点。Pokee AI创始人朱哲清视RL为赋予Agent目标感和自主决策的“灵魂”,认为无RL则Agent仅为高级工作流。而港科大研究员张佳钇、Follou创始人谢扬等则认为,当前RL主要实现特定环境优化,通用泛化能力有限,且Agent的成功更依赖强大的基础模型和有效的系统集成。争论反映出Agent发展路径多元,需结合模型能力、RL策略与工程实践。 (来源: AI科技评论)

用户尝试让GPT-4o基于聊天历史生成个性化抽象壁纸: 有用户分享提示词,要求GPT-4o根据对其个性的了解,创作独特的抽象极简壁纸(无具体物体,仅用形状、颜色、构图反映个性)。这种利用AI进行个性化内容创作的方式引发社区讨论。 (来源: op7418, Flavio Adamo via op7418)

AI重绘《清明上河图》: 用户分享使用GPT-4o将《清明上河图》局部以多种不同风格(如3D Q版、皮克斯、吉卜力等)进行重绘的有趣尝试,展示了AI图像生成在艺术再创作方面的应用。 (来源: dotey)

GPT-4o基于聊天历史推断用户MBTI类型: 继生成个性化壁纸后,用户继续让GPT-4o基于历史对话推断其MBTI人格类型,并生成对应的抽象插画。这展示了LLM在个性化理解和创意表达方面的潜力。 (来源: op7418)

对比:2005年的“AI工具”: 图片通过对比展示了2005年(如计算器、地图)和现在AI工具的能力差异,引发对技术飞速发展的感慨。 (来源: Ronald_vanLoon)

社区热议:LLM是真智能还是高级自动补全?: Reddit用户发起讨论,认为当前LLM虽能执行任务,但缺乏真正理解、记忆和目标,本质上是统计猜测而非智能。观点引发社区关于智能定义、AGI路径及当前技术局限性的广泛讨论。 (来源: Reddit r/ArtificialInteligence)
社区讨论:AI正走向乌托邦还是反乌托邦?: Reddit用户认为,当前AI发展轨迹更倾向于反乌托邦,理由包括:利润驱动而非伦理导向、加剧劳工剥削、强大模型访问受限、被用于监控操纵、替代人际关系等。观点引发社区对AI发展方向、社会影响及潜在风险的激烈讨论。 (来源: Reddit r/ArtificialInteligence)
社区质疑Bindu Reddy关于模型发布的准确性: LocalLLaMA社区用户指出,Abacus.AI CEO Bindu Reddy多次发布关于DeepSeek R2、Qwen 3等模型的不准确发布时间信息,随后又删除帖子,引发对其信息可靠性的讨论。 (来源: Reddit r/LocalLLaMA)
探讨终身AI记忆的伦理影响: Reddit用户发起讨论,担忧具备终身记忆能力的AI可能完全映射个人隐私、思想和弱点,将其灵魂“展示”给他人,引发关于隐私、可预测性和AI伦理边界的思考。 (来源: Reddit r/ArtificialInteligence)
AI图像编辑去除名人标志性胡须: 用户分享使用AI图像编辑工具去除斯大林、汤姆·塞立克、关羽等多位历史或公众人物标志性胡须后的效果图,展示了AI在图像修改和娱乐方面的应用。 (来源: Reddit r/ChatGPT)

用户称ChatGPT在医疗咨询中要求提供私密照片: Reddit用户分享截图,显示在咨询皮肤问题时,ChatGPT提出要求用户上传患处(阴茎)照片以便更好诊断。该情况引发社区关于AI在医疗场景中边界、隐私及潜在风险的讨论。 (来源: Reddit r/ChatGPT)
用户分享使用Claude和Gemini构建写作应用的经验: 开发者分享了利用Claude和Gemini作为编程助手,在两周内构建出满足个人需求的写作应用PlotRealm的经历。强调了AI在辅助开发中的作用,但也指出了AI有时会“固执己见”以及需要开发者具备基础知识来引导和纠错。 (来源: Reddit r/ClaudeAI)
用户让ChatGPT设计纹身图案: 一位用户请求ChatGPT为其设计下一个纹身,结果得到了一个描绘用户与ChatGPT机器人成为BFF(永远最好的朋友)的图案。这个幽默的结果引发了社区关于AI创意和人机关系的讨论。 (来源: Reddit r/ChatGPT)

用户创意提问“你希望我在哪里?”,引发AI多样化回应: 用户向ChatGPT提出一个开放性问题“你希望我在哪里?”,收到了AI生成的各种富有想象力的场景图片,如宁静图书馆、繁星夜空下等,展示了创意提示下AI的生成能力和社区成员的不同结果分享。 (来源: Reddit r/ChatGPT)
深度探讨:LLM和AGI为何以及如何“说谎”?: Reddit用户从发展心理学、进化论和博弈论角度分析,认为“说谎”是智能体(包括人类和未来AI)在特定情境下的适应性行为或优化策略。文章探讨了LLM“说谎”的几种形式(幻觉、偏见、策略性对齐),并模拟展示了竞争环境下不诚实策略的演化优势,引发对AGI伦理和可信度的深入思考。 (来源: Reddit r/artificial)

社区质疑AI能源消耗及科技乐观主义: Reddit用户以反讽口吻质疑关于AI能源消耗微不足道、仅带来好处而无成本、以及科技领袖承诺乌托邦未来的论调,暗示对AI发展可能带来的社会、环境成本及过度乐观宣传的担忧,引发社区讨论。 (来源: Reddit r/artificial)
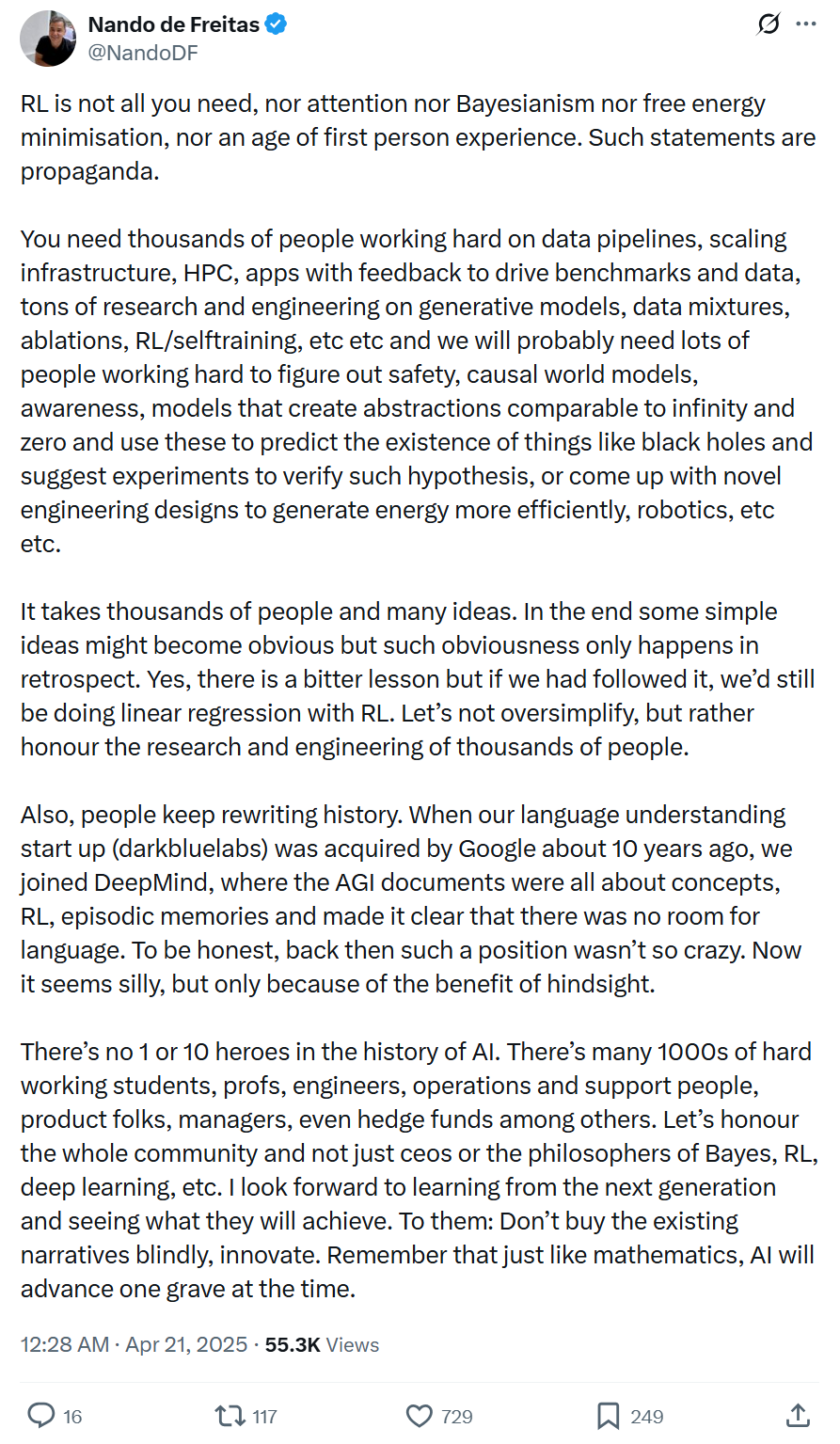
微软副总裁:AI进步非单一技术或少数天才驱动,需系统性工程与广泛协作: 微软副总裁Nando de Freitas发文反对过度神化单一技术(如RL)或个人在AI发展中的作用。他强调AI进步是系统性工程,需要数据、基础设施、多领域研究(生成模型、RL、安全、能效等)、应用反馈等成千上万参与者的共同努力。历史叙事常被改写,应警惕后见之明,尊重整个社群的贡献,鼓励创新而非盲从。 (来源: 机器之心)
💡 其他
AI音乐泛滥引发行业担忧与反制: AI生成音乐在流媒体平台占比快速提升(如Deezer达18%),引发对挤占人类创作空间、蚕食创作者收入(CISAC预测达24%)的担忧。韩国音著协推行“0% AI”版税新规,Deezer、YouTube等平台开发检测工具。然而,AI音乐识别困难,听众接受度较高(如Suno用户超千万)。行业面临深度伪造、版权争议(训练数据使用权)、原创性定义等挑战。未来或走向人机协作,但伦理与创作归属讨论将持续。 (来源: 新音乐产业观察)

Windsurf系统提示词疑泄露: GitHub仓库awesome-ai-system-prompts披露了疑似Windsurf模型的系统提示词内容。 (来源: karminski3)

AI大模型的高耗水问题引发关注: 财富杂志等媒体报道,类似ChatGPT的大型AI模型运行需要消耗大量水资源用于冷却,加州等地的野火季可能加剧水资源紧张,引发对AI可持续性的担忧。 (来源: Ronald_vanLoon)

开发者声称创建可预测情绪的AMI: YouTube视频声称展示了一个能可靠扫描、预测情绪及事件其他方面的AMI(Artificial Molecular Intelligence?),涉及声音、视频、图像等多种模态。该技术的真实性和具体实现方式有待验证。 (来源: Reddit r/artificial)
建议AI基准测试加入人类表现对比: Reddit用户提议,AI模型基准测试(Benchmarks)应包含人类(普通人和专家)在相同任务上的得分作为参照,以便更直观地评估AI的相对能力水平。 (来源: Reddit r/artificial)
奥斯卡接受AI参与电影制作,但有限制: 美国电影艺术与科学学院更新规定,允许在电影制作中使用AI工具,但强调人类创意仍是核心。规定可能涉及AI使用披露等具体要求,反映了行业在拥抱新技术与保护人类创作之间的平衡。 (来源: Reddit r/artificial, NYT link)

Instagram尝试用AI判断青少年年龄 (来源: Reddit r/artificial, AP News link)
奥特曼称用户对ChatGPT说“请”和“谢谢”耗费数百万美元 (来源: Reddit r/artificial, QZ link)
人形机器人半马赛事展现技术进步与挑战: 全球首场人形机器人半程马拉松在北京举行,「天工Ultra」以2小时40分夺冠。比赛检验了机器人在长距离、复杂地形、动态平衡、自主导航等方面的能力。全尺寸机器人面临更高难度(重心、惯性、能耗)。天工Ultra凭借大功率一体化关节、低惯量设计、高效散热、预测型强化模仿学习控制策略及无线领航技术胜出。赛事被视为对机器人规模化商用落地(如工业、安防巡检)的一次压力测试,推动了本体硬件、运动控制、智能决策等核心技术的验证与优化。 (来源: 机器之心)

利用AI监控名人动态并实现自动提醒: 教程分享了如何利用Python脚本监控特定Twitter账号(如奥特曼)的更新,并通过飞书API实现新动态发布时的电话加急提醒。该方法结合了网页爬虫技术与开放平台API调用,旨在解决信息过载和及时性需求问题,实现个性化的重要信息触达。展示了AI在自动化信息流处理和个性化通知方面的应用潜力。 (来源: 非主流运营)
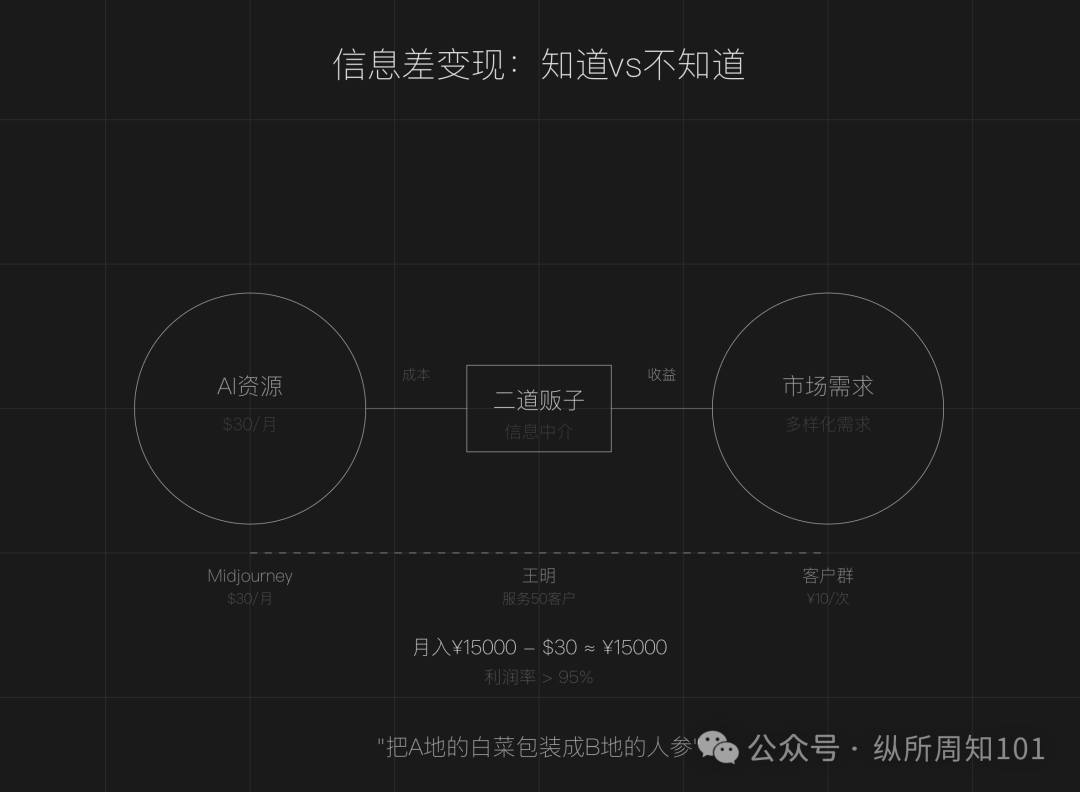
利用AI信息差成为“二道贩子”的商业模式探讨: 文章认为,AI时代信息差依然存在(工具泛滥、技术门槛、场景模糊),为普通人创造了成为“AI二道贩子”的机会。核心玩法包括:利用国内外AI资源价格差转售服务(如AI绘画)、提供执行力服务(将免费教程转化为付费部署,如AI客服)、规模化运营(组建团队提供专业服务)。适合领域包括内容创作、教育培训、中小企业商业服务、垂直领域专业服务(如医疗、法律)。建议通过找信息差、定目标群体、快行动三步开启。 (来源: 周知)