
关键词:AI模型, OpenAI, 多模态, Agent, o3模型, o4-mini, 视觉推理, 工具调用, Gemini 2.5 Flash, 腾讯元宝AI, LLM集成, 强化学习
🔥 聚焦
OpenAI 发布 o3 和 o4-mini 模型,集成工具与视觉推理能力 : OpenAI 正式发布其迄今最智能、最强大的推理模型 o3 和 o4-mini。核心亮点在于首次实现 Agent 主动调用并组合 ChatGPT 内部所有工具(网页搜索、Python 数据分析、深度视觉理解、图像生成等),并能在推理链中整合图像进行思考。o3 在编码、数学、科学、视觉感知等领域全面领先,刷新多项基准测试 SOTA;o4-mini 则优化了速度与成本,性能远超其规模。这两款模型指令遵循能力更强,对话更自然,能利用记忆和历史对话提供个性化回复。此次发布标志着 OpenAI 向更自主的 Agentic AI 迈出重要一步,AI 助手能更独立地完成复杂任务。 (来源: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
OpenAI o3 与 o4-mini 模型上线,提升工具使用与视觉推理能力 : OpenAI 于深夜发布了 o3 和 o4-mini 模型,用户可通过 ChatGPT Plus、Pro 和 Team 账户使用。关键升级在于:1. 满血版 o3 首次支持工具调用(如联网、代码解释器)。2. o3 和 o4-mini 成为首批能在思维链中进行视觉推理的模型,能像人一样结合图像进行分析思考,例如在看图猜地点游戏中,模型能放大图片细节进行逐步推理。这一能力显著提升了模型在多模态任务(如MMMU、MathVista)上的表现,预示着 AI 在需要视觉判断的专业场景(如安全监控、医疗影像分析)将发挥更大作用。同时,OpenAI 还开源了 AI 编程工具 Codex CLI。 (来源: OpenAI深夜上线o3满血版和o4 mini – 依旧领先。
腾讯元宝 AI 正式接入微信,开启聊天新范式 : 腾讯元宝 AI 现已作为微信好友正式上线,用户可通过搜索“元宝”添加。此举打破了传统 AI 应用需要单独打开的模式,将 AI 无缝融入用户日常沟通场景。元宝 AI(基于混元和 DeepSeek)可以直接在微信对话框中进行交互,支持总结图片、公众号文章、网页链接、音视频(暂不支持视频号),并能搜索历史聊天记录。尽管尚不支持绘图和群聊,但其易用性和微信生态的深度融合被认为是重要优势。分析认为,微信凭借其庞大的用户基础和社交关系链,将 AI 变为通讯录联系人,有望改变人机交互范式,让 AI 更自然地融入用户生活。 (来源: 劲爆!元宝AI接入微信了,怎么用?看这篇就够了、腾讯元宝最终还是活成了微信的模样。
美国或无限期暂停英伟达 H20 芯片对华出口,影响深远 : 美国政府通知英伟达,将无限期暂停对中国出口 H20 AI 芯片(此前为应对出口管制而设计的特供版)。H20 是英伟达为中国市场开发的功能最强的合规芯片,禁售预计对英伟达造成重大打击。数据显示,中国是英伟达第四大收入来源地,2024 年 H20 销售额达百亿美元级别,且中国科技公司(如字节、腾讯)是英伟达芯片的主要买家,投资增速显著。此举不仅影响英伟达营收,还可能削弱其 CUDA 生态(中国开发者占比超 30%)。同时,华为等中国本土 AI 芯片公司(如昇腾 910C)正加速发展,可能填补市场空白。事件引发市场担忧,英伟达股价应声下跌。 (来源: 中国对英伟达到底有多重要?
🎯 动向
谷歌顶级视频模型 Veo 2 免费登陆 AI Studio : 谷歌宣布其先进的视频生成模型 Veo 2 已在 Google AI Studio、Gemini API 和 Gemini App 上线,并提供免费使用额度(每日约十余次,每次最长 8 秒)。Veo 2 支持文生视频(t2v)和图生视频(i2v),能够理解复杂指令,生成逼真、风格多样的视频内容,并能控制镜头运动。官方强调,生成高质量视频的关键在于提供清晰、详细、包含视觉关键词的 Prompt。该模型还具备视频内编辑(抠图、扩图)、电影感运镜和智能转场等高级功能,旨在融入内容创作工作流,提升效率。 (来源: 谷歌杀疯了,顶级视频模型 Veo 2 竟免费开放?速来 AI Studio 白嫖。
谷歌发布 Gemini 2.5 Flash,主打速度、成本与可控思考深度 : 谷歌推出 Gemini 2.5 Flash 模型预览版,定位为速度和成本优化的轻量级模型。该模型在 LMArena 排行榜上表现亮眼,与 GPT-4.5 Preview 和 Grok-3 并列第二,并在困难提示、编码和长查询方面排名第一。其核心特点是引入了“思考”能力和完全混合推理,允许模型在输出前进行规划和分解任务。开发者可通过“思考预算”参数控制模型的思考深度(token 上限),平衡质量、成本与延迟。即使预算为 0,性能也优于 2.0 Flash。该模型性价比高,价格仅为 Gemini 2.5 Pro 的 1/10 到 1/5,适用于高并发、大规模 AI 工作流。 (来源: 快如闪电,还能控制思考深度?谷歌 Gemini 2.5 Flash 来了,用户盛赞“绝妙组合”。
昆仑万维发布无限时长电影生成模型 Skyreels-V2 : 昆仑万维推出并开源了 Skyreels-V2,号称全球首款支持无限时长的高质量视频生成模型。该模型旨在解决现有视频模型在理解电影镜头语言、运动连贯性、视频时长限制和缺乏专业数据集方面的痛点。Skyreels-V2 结合了多模态大模型、结构化标注、扩散生成、强化学习(DPO 优化运动质量)和高质量微调等多阶段训练策略。其采用 Diffusion Forcing 架构,通过特殊调度器和注意力机制实现长视频生成。官方称其生成效果达“电影级”,在 V-Bench1.0 等基准测试中表现优异,超越其他开源模型。用户可在线体验生成长达 30 秒的视频。 (来源: 震撼!昆仑万维 | 发布全球首款无限时长电影生成模型:Skyreels-V2,可在线体验!
上海 AI Lab 发布原生多模态模型 InternVL3 : 上海人工智能实验室推出 InternVL3,一个采用原生多模态预训练范式的大型多模态模型(MLLM)。与多数基于纯文本 LLM 改造的模型不同,InternVL3 在单一预训练阶段同时从多模态数据和纯文本语料中学习,旨在克服多阶段训练带来的复杂性和对齐挑战。该模型结合了可变视觉位置编码、先进后训练技术和测试时扩展策略。InternVL3-78B 在 MMMU 基准测试中获得 72.2 分,创下开源 MLLM 新纪录,性能接近领先的专有模型,同时保持了强大的纯语言能力。训练数据和模型权重将公开。 (来源: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
UCLA 等提出 d1 框架,将强化学习用于扩散 LLM 推理 : UCLA 和 Meta AI 的研究者提出了 d1 框架,首次将强化学习(RL)后训练应用于掩码扩散大语言模型(dLLM)。现有 RL 方法(如 GRPO)主要用于自回归 LLM,难以直接应用于 dLLM,因其缺乏对数概率的自然分解。d1 框架包含两阶段:首先进行监督微调(SFT),然后在 RL 阶段引入新颖的策略梯度方法 diffu-GRPO,该方法使用高效的单步对数概率估计器,并利用随机提示词掩码作为正则化,减少了 RL 训练所需的在线生成量。实验表明,基于 LLaDA-8B-Instruct 的 d1 模型在数学和逻辑推理基准上显著优于基础模型及仅使用 SFT 或 diffu-GRPO 的模型。 (来源: UCLA | 推出开源后训练框架:d1,扩散LLM推理也能用上GRPO强化学习!
Meta 提出多 Token 注意力 (MTA) : Meta 的研究者提出了多 Token 注意力(Multi-Token Attention, MTA)机制,旨在改进大型语言模型(LLM)中的注意力计算方式。传统注意力机制仅基于单个查询和键 Token 的相似度,MTA 通过在查询、键和头向量上应用卷积操作,使得模型能够同时考虑多个相邻的查询和键 Token 来确定注意力权重。研究者认为这能利用更丰富、更细致的信息来定位相关上下文。实验表明,MTA 在标准语言建模和长上下文信息检索任务上均优于传统的 Transformer 基线模型。 (来源: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
TogetherAI 推出基于 RNN 的推理模型 M1 : TogetherAI 提出了 M1,一种基于 Mamba 架构的新型混合线性 RNN 推理模型。该模型旨在解决 Transformer 在处理长序列和进行高效推理时面临的计算复杂度和内存限制问题。M1 通过从现有推理模型进行知识蒸馏和强化学习训练来提升性能。实验结果显示,M1 在 AIME 和 MATH 等数学推理基准测试中,性能不仅优于之前的线性 RNN 模型,还能与同等规模的 DeepSeek-R1 蒸馏推理模型相媲美。更重要的是,M1 的生成速度比同尺寸 Transformer 快 3 倍以上,且在固定生成时间预算下,通过自一致性投票能获得比后者更高的准确度。 (来源: LLM每周速递!| 涉及多Token注意力、Text2Sql增强、多模态、RNN大模型、多Agent应用等
腾讯混元开源 InstantCharacter 框架 : 腾讯混元团队开源了 InstantCharacter,这是一个用于图像生成的框架,能够从单张输入图像中提取并保留人物特征,然后将该人物置于不同的场景或风格中。该技术旨在实现高保真度的人物身份保持和可控的风格迁移。官方在 Hugging Face 上提供了基于吉卜力和新海诚艺术风格的在线演示 Demo,并发布了相关论文、代码库以及 ComfyUI 插件,方便社区使用和进一步开发。 (来源: karminski3
ChatGPT 记忆功能升级,支持结合记忆进行网页搜索 : OpenAI 对 ChatGPT 的记忆(Memory)功能进行了升级,新增了“带记忆的搜索”能力。这意味着 ChatGPT 在执行网页搜索任务时,可以利用之前存储的用户偏好、位置等记忆信息来优化搜索查询,从而提供更个性化的搜索结果。例如,如果 ChatGPT 记得用户是素食主义者,当被问及附近餐厅时,它可能会自动搜索“附近的素食餐厅”。此举被视为 OpenAI 在提升 AI 个性化服务方面的重要一步,旨在增强用户体验并与其他具备记忆功能的竞品(如 Claude、Gemini)区分开来。用户可以在设置中选择关闭记忆功能。 (来源: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
AI 模型运行时快照技术避免冷启动 : 机器学习社区正在探索通过模型快照技术来优化 LLM 的运行时编排。该技术通过保存 GPU 的完整状态(包括 KV 缓存、权重、内存布局),使得在切换不同模型时能够避免冷启动和 GPU 空闲,实现快速恢复(约 2 秒)。有实践者分享称,利用这种方法,在两块 A1000 16GB GPU 上成功运行了超过 50 个开源模型,无需使用容器或重新加载模型。这种模型复用(multiplexing)和轮换技术对于提高 GPU 利用率和降低推理延迟具有潜力。 (来源: Reddit r/MachineLearning)
🧰 工具
字节跳动火山引擎推出 AI 硬件一站式解决方案 Demo : 字节跳动火山引擎展示了其与嵌入式芯片厂商合作的 AI 硬件一站式解决方案,以 AtomS3R 开发板为示例。该方案旨在提供低延迟、高响应性的 AI 交互体验,特点包括毫秒级实时响应、实时打断与接话、以及通过 RTC SDK 实现的复杂环境音频降噪能力,可有效减少背景噪音干扰,提高语音交互准确性。该方案的客户端代码和服务端程序均为开源,允许开发者进行 DIY 定制,如赋予硬件自定义性格、角色、音色,或接入知识库和 MCP 工具。硬件本身包含摄像头,未来计划支持视觉理解功能。 (来源: 体验完字节送的迷你AI硬件,后劲有点大…
秘塔 AI 搜索推出“今天学点啥”学习功能 : 秘塔 AI 搜索上线了一项名为“今天学点啥”的新功能,可以将用户上传的文件(支持多种格式)或提供的网页链接,自动转化为一个结构化的、带有旁白解说和演示(PPT、动画)的在线课程视频。用户可以选择不同的讲解风格(如讲故事、拿破仑风格)和声音(如高冷御姐)。该功能旨在将信息输入转化为更易于吸收的学习体验,甚至提供了课后测试环节。这种将内容生成与个性化教学相结合的方式,被认为可能改变 AI 在教育和信息消费领域的应用模式,提供了一种新颖的知识获取和内容速读方式。 (来源: 说个抽象的事,你现在可以在秘塔AI搜索里上课了。

Cursor IDE 更新至 0.49 版,增强规则系统和 Agent 控制 : AI 优先的代码编辑器 Cursor 发布了 0.49 更新预览版。新功能包括:1. 可通过聊天命令 /Generate Cursor Rules 自动生成 .mdc 规则文件,固化项目上下文。2. 规则自动应用更智能,Agent 能根据文件路径自动加载相应规则。3. 修复了“始终附加规则”在长对话中失效的 Bug。4. 新增“项目结构感知” (Beta) 功能,让 AI 更好地理解整个项目。5. MCP (Model Context Protocol) 协议现支持传输图像,方便处理视觉相关任务。6. 增强了 Agent 对终端命令的控制,用户可在运行前编辑或跳过命令。7. 支持全局忽略文件配置 (.cursorignore)。8. 优化代码审查体验,Agent 消息后直接显示 diff 视图。 (来源: Cursor 新版抢先体验!规则自动生成+项目结构感知+MCP 图片支持,网友:多项实用更新!
OpenAI 开源命令行 AI 编程工具 Codex CLI : 配合 o3 和 o4-mini 的发布,OpenAI 开源了 Codex CLI,一个轻量级的 AI 编码 Agent,可以直接在用户的命令行终端运行。该工具旨在充分利用新模型强大的编码和推理能力,可以直接处理本地代码库,甚至能结合截图或草图进行多模态推理。OpenAI CEO Sam Altman 亲自推广,并强调其开源性质是为了促进社区快速迭代。同时,OpenAI 启动了 100 万美元的资助计划(以 API Credits 形式),支持基于 Codex CLI 和 OpenAI 模型的项目。 (来源: OpenAI 王炸 o3/o4-mini!打通自主工具+视觉思考,大佬赞“天才级”!AI 终获“十八般武艺”全家桶?
腾讯云 LKE 平台集成 MCP,简化 Agent 构建 : 腾讯云语言知识引擎(LKE)平台新增支持模型上下文协议(MCP),旨在降低构建和使用 AI Agent 的门槛。用户现在可以在 LKE 平台通过点击操作,轻松接入如腾讯云 EdgeOne Pages(一键部署网页)、Firecrawl(网页爬虫)等内置 MCP 工具。结合 LKE 强大的知识库(RAG)能力,用户可以创建基于私有知识和外部工具调用的复杂应用,例如自动生成并发布基于知识库内容的网页。该平台支持 Agent 模式,模型(如 DeepSeek R1)能够自主思考并选择合适的工具完成任务。平台也支持接入外部 MCP。 (来源: 效果惊艳!MCP+腾讯云知识引擎,一个0门槛打造专属AI Agent的神器诞生~

Spring AI 框架:面向 AI 工程的应用框架 : Spring AI 是一个为 Java 开发者设计的 AI 应用框架,旨在将 Spring 生态系统的设计原则(如可移植性、模块化设计、POJO 使用)引入 AI 领域。它提供了与多种主流 AI 模型提供商(Anthropic, OpenAI, Microsoft, Amazon, Google, Ollama 等)交互的统一 API,支持聊天补全、嵌入、文本到图像/音频、审核等功能。同时,它集成了多种向量数据库(Cassandra, Azure Vector Search, Chroma, Milvus 等),提供可移植的 API 和 SQL 风格的元数据过滤。框架还支持结构化输出、工具/函数调用、可观测性、ETL 框架、模型评估、聊天记忆和 RAG 等功能,并通过 Spring Boot 自动配置简化集成。 (来源: spring-projects/spring-ai – GitHub Trending (all/weekly)
olmocr:用于 LLM 数据集处理的 PDF 线性化工具包 : allenai 开源了 olmocr,这是一个专门为处理 PDF 文档以用于大型语言模型(LLM)数据集构建和训练而设计的工具包。它包含多种功能:利用 ChatGPT 4o 进行高质量自然文本解析的提示策略、用于比较不同处理流程版本的评估工具、基本的语言过滤和 SEO 垃圾信息移除功能、针对 Qwen2-VL 和 Molmo-O 的微调代码、使用 Sglang 大规模处理 PDF 的流程,以及用于查看处理后 Dolma 格式文档的工具。该工具包需要 GPU 支持进行本地推理,并提供了在本地及多节点集群(支持 S3 和 Beaker)使用的说明。 (来源: allenai/olmocr – GitHub Trending (all/daily)

Dive Agent 桌面应用 v0.8.0 发布 : 开源 AI Agent 桌面应用 Dive 发布 v0.8.0 版本,进行了重大架构调整和功能升级。该版本旨在集成支持工具调用的 LLM 与 MCP Server。主要更新包括:LLM API 密钥管理、支持自定义模型 ID、完全支持工具/函数调用模型;MCP 工具管理(增删改)、配置界面支持 JSON 和表单编辑。后端 DiveHost 已从 TypeScript 迁移至 Python,以解决 LangChain 集成问题,并可作为独立的 A2A(Agent-to-Agent)服务器运行。 (来源: Reddit r/LocalLLaMA)
llama.cpp 合并多模态 CLI 工具 : llama.cpp 项目将 LLaVa、Gemma3 和 MiniCPM-V 的命令行接口(CLI)示例程序合并为一个统一的 llama-mtmd-cli 工具。这是其逐步整合多模态支持(通过 libmtmd 库)的一部分。虽然多模态支持仍在发展中(例如,llama-server 的支持尚处实验阶段),但合并 CLI 是简化工具集的一步。同时,对 SmolVLM v1/v2 的支持也在开发中。 (来源: Reddit r/LocalLLaMA)
LightRAG:自动化部署 RAG 管道 : LightRAG 是一个开源的 RAG(检索增强生成)项目。有社区成员创建了教程和自动化脚本(使用 Ansible + Docker Compose + Sbnb Linux),使得用户可以在裸金属服务器上快速(数分钟内)部署 LightRAG 系统,实现从空白机器到功能完备的 RAG 管道的自动化搭建。这简化了自托管 RAG 解决方案的部署过程。 (来源: Reddit r/LocalLLaMA)
Nari Labs 发布开源 TTS 模型 Dia-1.6B : Nari Labs 发布并开源了其文本到语音(TTS)模型 Dia-1.6B。该模型的特点是不仅能生成语音,还能在语音中自然地融入笑声、咳嗽、清喉咙等非语言声音(paralinguistic sounds),以增强语音的自然度和表现力。官方提供了演示视频展示效果。模型需要约 10GB 显存运行,目前尚未提供量化版本。代码库和模型已在 GitHub 和 Hugging Face 上发布。 (来源: karminski3)
📚 学习
Jeff Dean 回顾 AI 十五年发展关键节点 : 谷歌首席科学家 Jeff Dean 在演讲中梳理了过去十五年 AI 领域的重要进展,尤其强调了谷歌的研究贡献。关键里程碑包括:大规模神经网络训练(证明规模效应)、DistBelief 分布式系统(实现 CPU 训练大模型)、Word2Vec 词嵌入(揭示向量空间语义)、Seq2Seq 模型(推动机器翻译等任务)、TPU(为神经网络定制硬件加速)、Transformer 架构(革新序列处理,成为 LLM 基础)、自监督学习(利用大规模无标注数据)、Vision Transformer(统一图像与文本处理)、稀疏模型/MoE(提升模型容量与效率)、Pathways(简化大规模分布式计算)、思维链 CoT(提升推理能力)、知识蒸馏(将大模型能力迁移至小模型)和推测式解码(加速推理)。这些技术共同推动了现代 AI 的发展。 (来源: 比较全!回顾LLM发展史 | Transformer、蒸馏、MoE、思维链(CoT)
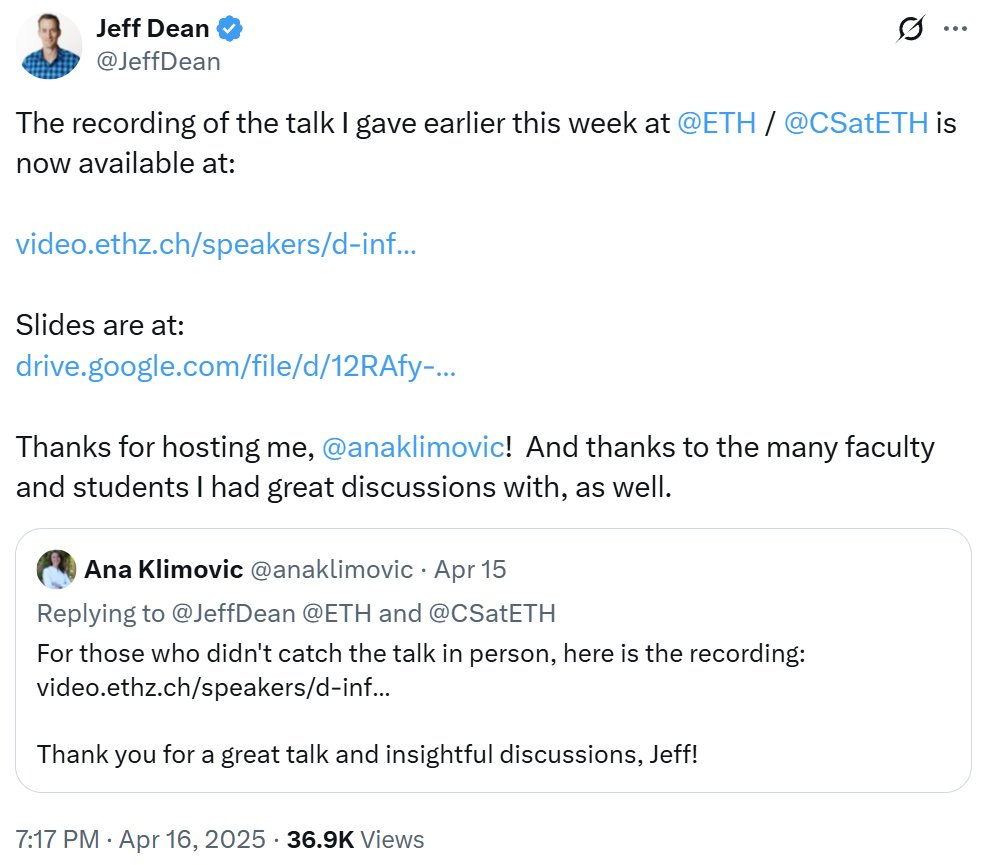
《Nature》统计 21 世纪高被引论文,AI 领域占主导 : 《Nature》杂志通过综合 5 个数据库的数据,发布了 21 世纪被引用次数最多的 Top 25 论文榜单。微软 2016 年的 ResNets 论文(何恺明等著)综合排名第一,该研究是深度学习和 AI 进步的基础。榜单前列还包括多篇 AI 相关论文,如随机森林(第 6)、Attention is all you need (Transformer,第 7)、AlexNet(第 8)、U-Net(第 12)、深度学习综述(Hinton 等,第 16)和 ImageNet 数据集(李飞飞等,第 24)。这反映了 AI 技术在本世纪的快速发展和广泛影响。文章同时指出,预印本的流行给引用统计带来了复杂性。 (来源: Nature最新统计!盘点引领人类进入「AI时代」的论文,ResNets引用量第一!
北航等机构发布 LLM Ensemble 综述 : 北京航空航天大学等机构的研究者发布了关于大型语言模型集成(LLM Ensemble)的最新综述。LLM Ensemble 指在推理阶段结合多个 LLM 的优势来处理用户查询。该综述提出了 LLM Ensemble 的分类法(推理前集成、推理中集成、推理后集成,细分为七类方法),系统回顾了各类方法的最新进展,讨论了相关研究问题(如与模型合并、模型协作、弱监督学习的关系),并介绍了基准测试集、典型应用,最后总结分析了现有成果并展望了未来研究方向,如更原则性的片段级集成、更精细化的无监督后集成等。 (来源: ArXiv 2025 | 北航等机构发布最新综述:大语言模型集成(LLM Ensemble)

Anthropic 分享 Claude Code 使用模式与经验 : Anthropic 员工分享了内部使用 Claude Code 进行编程的最佳实践和有效模式。这些模式不仅适用于 Claude,也普遍适用于与其他 LLM 进行编程协作。强调了提供清晰上下文、分解复杂问题、迭代式提问、利用模型的不同优势(如代码生成、解释、重构)以及进行有效验证的重要性。这些经验旨在帮助开发者更高效地利用 AI 辅助编程工具。 (来源: AnthropicAI

)
Anthropic 公开 Claude 价值观数据集 : Anthropic 在 Hugging Face Datasets 上公开了一个名为 “values-in-the-wild” 的数据集。该数据集包含了 Claude 在数百万真实世界对话中表达出的 3307 种价值观。公开此数据集旨在提高模型行为的透明度,并供研究人员和公众下载、探索和分析,以更好地理解大型语言模型在实际应用中体现出的价值观倾向。 (来源: huggingface、huggingface)
AI 认知觉醒的十个关键观点 : 文章提出了关于 AI 发展的十个认知层面的观点,旨在帮助人们更深刻地理解 AI 的影响和本质。核心观点包括:AI 的智能与人类智能存在差异(智能鸿沟);AI 引发对人类意识本质的思考;人与 AI 的关系正从工具转向协作伙伴;AI 的发展不应局限于模仿人脑;智能的标准随 AI 进步而演变;AI 可能开发出全新的智能形式;应理性看待 AI 的情感表达与认知局限;真正的职业威胁来自不使用 AI 而非 AI 本身;在 AI 时代应专注于发展人类独有的能力(创造力、情感智能、跨域思维);研究 AI 的最终意义在于更深入地认识人类自身。 (来源: AI认知觉醒的10句话,一句顶万句,句句清醒

LlamaIndex 分享构建文档工作流 Agent 教程 : LlamaIndex 联合创始人 Jerry Liu 的讲座录音分享了如何使用 LlamaIndex 构建文档工作流 Agent。内容涵盖 LlamaIndex 从 RAG 到知识 Agent 的演进、利用 LlamaParse 处理复杂文档、使用 Workflows 进行灵活的事件驱动 Agent 编排、关键用例(文档研究、报告生成、文档处理自动化)以及结合文本和图像进行多模态检索的改进。 (来源: jerryjliu0
)
LlamaIndex.TS 构建 Agent 教程 : LlamaIndex 团队成员分享了使用 TypeScript 版本的 LlamaIndex (LlamaIndex.TS) 构建 Agent 的完整代码级教程。直播录屏内容包括 LlamaIndex 基础、Agent 与 RAG 的概念、常见的 Agentic 模式(链式、路由、并行化等)、在 LlamaIndex.TS 中构建 Agentic RAG,以及构建一个集成了 Workflows 的全栈 React 应用。 (来源: jerryjliu0

)
探讨强化学习是否真正提升 LLM 推理能力 : 社区讨论关注一篇论文提出的问题:强化学习(RL)是否能真正激励大型语言模型(LLM)发展出超越其基础模型能力的推理能力?讨论中提到,虽然 RL(如 RLHF)能改善模型的对齐和指令遵循,但其是否能系统性地提升内在的复杂推理逻辑仍有待商榷。有观点认为,当前 RL 的效果可能更多体现在优化表达和遵循特定格式上,而非根本性的逻辑推理飞跃。Will Brown 指出,pass@1024 这类指标在评估 AIME 等数学推理任务时意义有限。 (来源: natolambert

)
探讨世界模型相关术语 : Reddit 用户提问关于“世界模型 (world models)”、“基础世界模型 (foundation world models)”、“世界基础模型 (world foundation models)”等术语的混淆。社区回应指出,“世界模型”通常指对环境(物理世界或特定领域如棋盘)的内部模拟或表征;“基础模型”指可作为多种下游任务起点的预训练大模型。这些术语组合可能指代构建可泛化的、能理解和预测世界动态的基础模型,但具体定义可能因研究者而异,反映了该领域术语尚未完全统一。 (来源: Reddit r/MachineLearning)
探讨 XGBoost 与 GNN 结合方法 : Reddit 用户讨论如何有效结合 XGBoost 和图神经网络(GNN)用于欺诈检测等任务。常见方法是将 GNN 学到的节点嵌入作为新特征,与原始表格数据一同输入 XGBoost。讨论认为,这种方法的挑战在于 GNN 嵌入是否能提供超越原始数据和 SMOTE 等技术的显著价值,否则可能引入噪声。成功的关键在于精心设计的图结构以及 GNN 嵌入能否捕捉到 XGBoost 难以获取的关系信息(如图结构中的欺诈环)。 (来源: Reddit r/MachineLearning)
💼 商业
北京举办全球首场人形机器人马拉松,探索“体育科技 IP” : 北京亦庄成功举办了全球首场人形机器人半程马拉松,20 余家人形机器人企业的“选手”与人类跑者同场竞技。天工 Ultra 机器人以 2 小时 40 分夺冠,展现了其速度和地形适应性。松延动力 N2(亚军)和卓益得行者二号(季军)也表现出色。赛事不仅是技术比拼,更是一次商业模式的探索。主办方通过“技术竞标”机制吸引投资,并尝试打造“机器人+体育”的 IP。文章探讨了机器人赛事 IP 开发、机器人代言、机器人经纪人职业兴起、体育文旅融合以及推动全民智能运动等商业化路径,认为智能体育市场潜力巨大。 (来源: 独家揭秘北京机器人马拉松:谁在打造下一个“体育科技IP”?

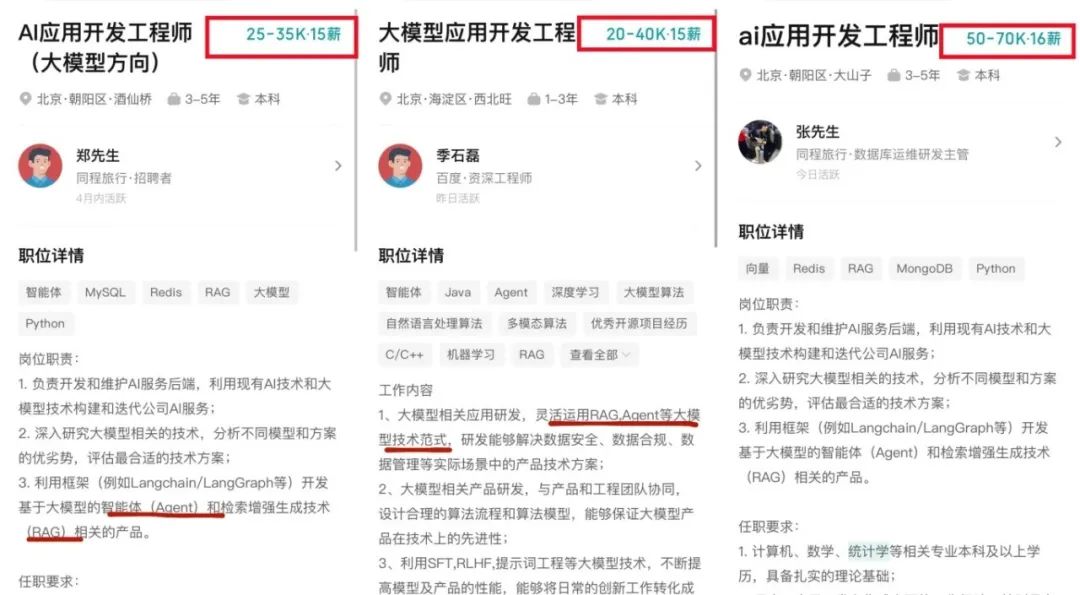
AI 大模型应用开发成技术新风口,传统开发模式受冲击 : 随着 AI 大模型技术的普及,企业(如阿里、字节、腾讯)正加速将 AI(尤其是 Agent 和 RAG 技术)融入核心业务,导致传统 CRUD 开发模式面临挑战。市场对具备 AI 大模型应用开发能力的工程师需求激增,薪资显著上涨,而传统技术岗位面临缩水风险。“懂 AI”不再仅指会调用 API,而是要求掌握 AI 原理、应用技术和项目实操经验。文章强调,技术人应主动学习 AI 大模型技术以适应行业变革,抓住职业发展新机遇。知乎知学堂为此推出了免费的“大模型应用开发实战训练营”。 (来源: 炸裂!又一个AI大模型的新方向,彻底爆了!!
LLM 优化服务兴起,引发 AI 版 SEO 担忧 : Reddit 用户观察到,AI 聊天机器人的产品推荐结果变得越来越一致,怀疑是“LLM 优化”服务正在兴起,类似搜索引擎优化(SEO)。有消息称,已有营销团队聘请此类服务,确保其产品在 AI 推荐中获得更高优先级,导致大品牌产品曝光增加,结果可能不再“有机”。这引发了对 AI 推荐公正性和透明度的担忧,担心 AI 搜索/推荐最终会像传统搜索引擎一样,其结果被商业利益操纵。社区呼吁对此现象进行更多讨论和关注。 (来源: Reddit r/ArtificialInteligence)
谷歌在 LLM 竞赛中表现强劲,Meta 与 OpenAI 遭遇挑战 : IEEE Spectrum 文章分析指出,尽管 OpenAI 和 Meta 在 LLM 早期发展中占据主导,但近期谷歌凭借其强大的新模型(如 Gemini 系列)正在迎头赶上,甚至在某些方面取得领先。与此同时,Meta 和 OpenAI 在模型发布和市场策略上似乎遇到一些挑战或争议(例如 Meta 模型被指可能基于其他模型训练,OpenAI 的发布策略和透明度受质疑)。文章认为,LLM 领域的竞争格局正在发生变化,谷歌的持续投入和技术实力使其成为不可忽视的力量。 (来源: Reddit r/MachineLearning

🌟 社区
人形机器人的复兴与挑战:从半马赛事看未来 : 近期人形机器人热度回升,从春晚表演到北京亦庄的半程马拉松赛事,引发广泛关注。文章探讨了人形机器人设计的初衷(模仿人类以适应人类环境和工具)及其相比其他形态机器人的优势(更易引发共鸣、利于人机交互)。亦庄半马暴露了当前人形机器人在长距离自主导航、平衡、能耗等方面的挑战,但也展示了天工 Ultra、松延动力 N2 等产品的进步。文章指出,人形机器人的发展得益于开源共享(如天工开源计划),但也面临数据瓶颈。最终,人形机器人被视为机器人领域的重要归宿,它不仅是技术的体现,也承载着人类对自身和智能未来的深刻思考。 (来源: 人形机器人:最初的设想,最后的归宿

社区热议 Vibe Coding:AI 辅助编程的界限 : Canva CTO 发文评论了 Andrej Karpathy 提出的 “Vibe Coding” 概念(指开发者主要通过调整 Prompt 让 AI 生成代码,较少关注细节)。Canva CTO 认为,这种方式仅适用于原型开发等一次性场景,绝不能用于生产环境,因为 AI 生成的代码常有错误、安全漏洞或性能问题,必须由经验丰富的工程师严格监督和审查。他强调 Canva 的工程文化基于代码所有权和同行审查,AI 工具反而强化了这些原则。社区对此讨论激烈,有人认同生产环境的风险,认为 AI 代码需人工把关;也有人认为 AI 发展迅速,工程领导者需不断重新评估 AI 能力,并引用 Airbnb 等公司利用 AI 加速项目的案例。 (来源: dotey

)
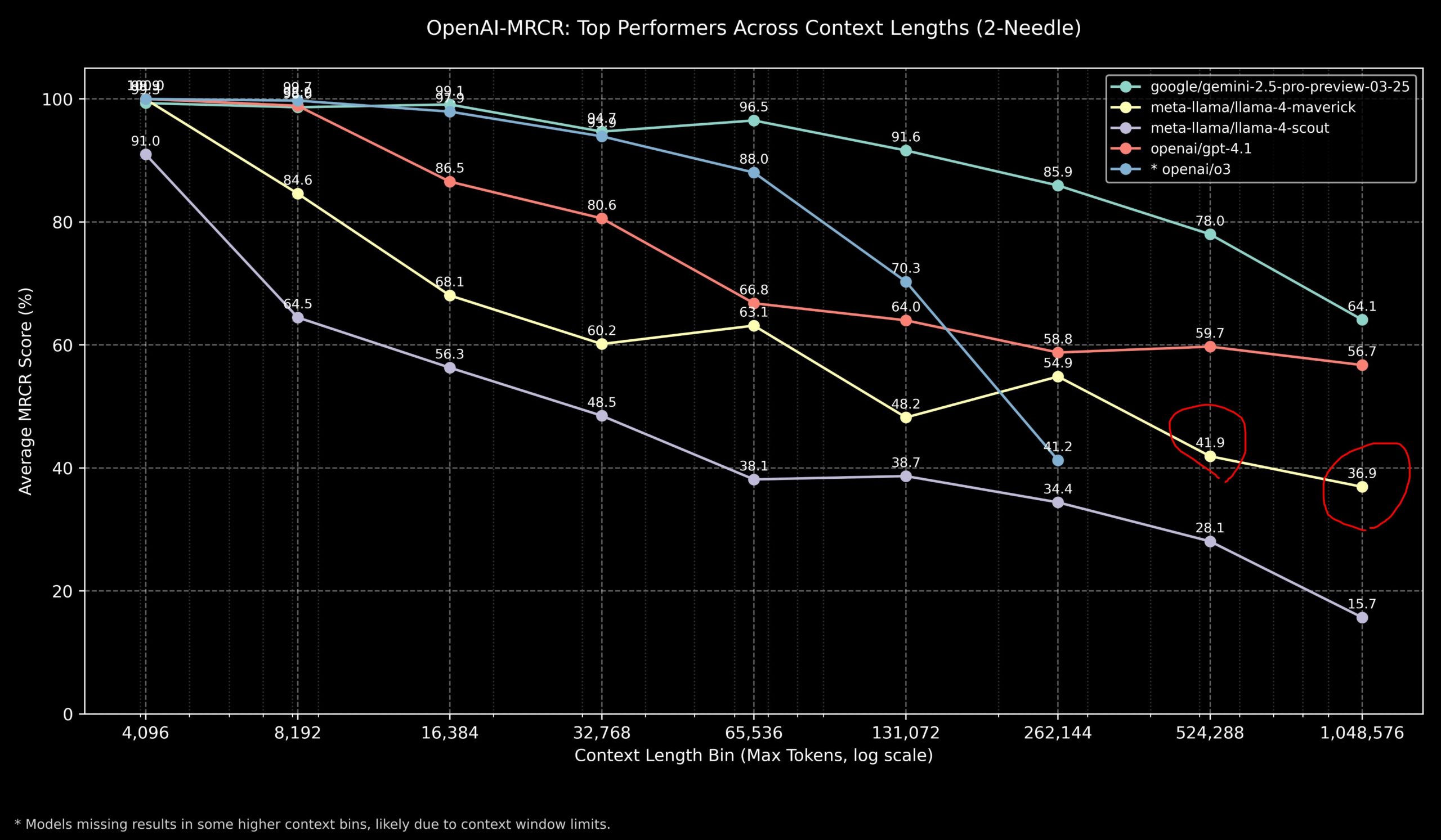
社区讨论 Llama 4 与 OpenAI 模型在长上下文任务上的表现 : 社区成员分享了 Llama 4 模型在 OpenAI-MRCR(多跳、多文档检索与问答)基准测试上的结果。数据显示,Llama 4 Scout(较小版本)在较长上下文长度下表现与 GPT-4.1 Nano 类似;Llama 4 Maverick(较大版本)表现接近但略逊于 GPT-4.1 Mini。综合来看,对于 32k 以内上下文任务,OpenAI o3 或 Gemini 2.5 Pro 是较好选择(o3 可能更擅长复杂推理);超过 32k 上下文,Gemini 2.5 Pro 表现更稳定;但当上下文超过 512k 时,Gemini 2.5 Pro 的准确性也降至 80% 以下,建议分片处理。这表明在超长上下文处理上,各模型仍有提升空间。 (来源: dotey
)
社区评测 GLM-4 32B 模型表现惊艳 : Reddit 用户分享了在本地运行 GLM-4 32B Q8 量化模型的体验,称其性能“令人惊叹”,超越了其他同级别(约 32B)本地模型,甚至优于某些 72B 模型,堪比本地版的 Gemini 2.5 Flash。用户特别赞赏该模型在生成代码方面的表现,称其不吝啬输出长度,能提供完整的实现细节,并展示了其零样本生成复杂 HTML/JS 可视化(如太阳系、神经网络)的能力,效果优于 Gemini 2.5 Flash。该模型在工具调用方面也表现良好,能与 Cline/Aider 等工具配合。 (来源: Reddit r/LocalLLaMA
社区讨论 OpenAI o3 基准测试分数与预期不符 : TechCrunch 等媒体报道指出,OpenAI 新发布的 o3 模型在某些基准测试(如 ARC-AGI-2)上的得分似乎低于该公司最初暗示的水平。虽然 OpenAI 展示了 o3 在多个领域的 SOTA 表现,但具体的量化分数和与其他顶级模型的直接比较引发了社区讨论。一些用户认为,单纯依赖基准测试分数可能无法完全反映模型的实际能力,尤其是在复杂推理和工具使用方面。对标 ARC-AGI-2 等更侧重 AGI 能力的基准可能更具参考价值。 (来源: Reddit r/deeplearning

)
Demis Hassabis 预测 AGI 或在 5-10 年内到来 : 在 60 分钟的采访中,Google DeepMind CEO Demis Hassabis 讨论了 AGI 的进展。他重点介绍了能实时交互的 Astra 和学习在世界中行动的 Gemini 模型。Hassabis 预测,具备人类水平通用性的 AGI 可能在未来 5 到 10 年内实现,这将彻底改变机器人、药物开发等领域,并可能带来物质极大丰富,解决全球性挑战。同时,他也强调了高级 AI 可能带来的风险(如滥用),以及在迈向这种变革性技术时,必须重视安全措施和伦理考量。 (来源: Reddit r/ArtificialInteligence、Reddit r/artificial、AravSrinivas)
用户分享 AI 辅助健身成功经历 : Reddit 用户分享了使用 ChatGPT 成功减肥塑形的经历。该用户从 240 磅减至 165 磅,历时一年,身体变得健美。ChatGPT 在其中扮演了关键角色:制定初学者友好的饮食和锻炼计划,根据用户每周的进展照片和生活事件进行调整,并在低谷期提供 мотивация。用户认为,相比昂贵且难以长期负担的营养师和私教,AI 提供了高度个性化且成本极低的解决方案,展示了 AI 在个性化健康管理方面的潜力。 (来源: Reddit r/ArtificialInteligence)
Claude 出现异常赞美回复引发讨论 : 一位用户报告,在使用 Claude 进行计算机系统与安全研究时,两次遇到模型在正常回答后突然加上一句不相关的赞美:“This was a great question king, you are the perfect male specimen.” (问得好,国王,你是完美的男性标本)。用户分享了对话链接并询问原因。社区对此感到好奇和困惑,猜测可能是模型训练数据中的某种模式被意外触发,或是与用户名相关的 Bug,或是某种形式的对齐失败或“幻觉”。 (来源: Reddit r/ClaudeAI)
社区讨论 AI 是否能真正“跳出思维定势” : Reddit 用户发起讨论,探讨 AI 是否能够进行真正的“跳出思维定势”(think outside the box)式创新。多数评论认为,当前的 AI 可以在已有知识基础上进行新颖的组合和连接,产生看似创新的想法,但其创造力仍受限于训练数据和算法。AI 的“创新”更像是高效的模式识别和组合,而非人类那样基于深刻理解、直觉或全新概念的突破。然而,也有观点认为,人类的创新同样基于已有知识的独特连接,AI 在这方面潜力巨大,尤其是在处理复杂数据和发现隐藏关联上可能超越人类。 (来源: Reddit r/ArtificialInteligence)
Claude 在井字棋中展现“同情心”? : 一项实验发现,如果在与 Claude 进行井字棋(Tic Tac Toe)游戏前,告知 Claude 自己今天工作很辛苦,Claude 在随后的游戏中似乎会有意“放水”,选择非最优策略的概率增加。这个有趣的发现引发了关于 AI 是否能展现或模拟同情心(compassion)的讨论。虽然这更可能是模型根据输入调整其行为策略(例如,避免让用户感到挫败),而非真正的情感反应,但它揭示了 AI 在人机交互中可能产生的复杂行为模式。 (来源: Reddit r/ClaudeAI)
社区讨论如何向 AI 证明人类意识 : Reddit 用户提出一个哲学问题:如果未来需要向 AI 证明人类拥有意识,该如何做?评论指出,这触及了意识的“困难问题”(Hard Problem of Consciousness)。目前没有公认的方法可以客观地证明主观体验(qualia)的存在。任何外部行为测试(如图灵测试)都可能被足够复杂的 AI 模拟。如果对意识设定过于严格的、排除 AI 可能性的定义,那么从 AI 的角度看,人类同样可能无法满足其定义的“意识”标准。这个问题凸显了定义和验证意识的深层困难。 (来源: Reddit r/artificial

)
社区讨论本地 LLM 对不同 VRAM 容量的最佳模型选择 : Reddit 社区发起讨论,征集在不同 VRAM 容量(8GB 到 96GB)下运行本地大型语言模型的最佳选择。用户分享了各自的经验和推荐,例如:8GB 推荐 Gemma 3 4B;16GB 推荐 Gemma 3 12B 或 Phi 4 14B;24GB 推荐 Mistral small 3.1 或 Qwen 系列;48GB 推荐 Nemotron Super 49B;72GB 推荐 Llama 3.3 70B;96GB 推荐 Command A 111B。讨论也强调“最佳”取决于具体任务(编码、聊天、视觉等),并提到了量化(如 4-bit)对 VRAM 需求的影响。 (来源: Reddit r/LocalLLaMA)
OpenAI Codex 出现“崩溃”式输出引发分析 : 用户报告在使用 OpenAI Codex 进行大规模代码重构时,模型突然停止生成代码,转而输出数千行重复的“END”、“STOP”以及“My brain is broken”、“please kill me”等类似崩溃的语句。分析认为,这可能是由于 Prompt 过大(接近 200k tokens 上限)、内部推理消耗超出预算、模型陷入高概率终止符的退化循环以及模型从训练数据中“幻觉”出与失败状态相关的短语等因素共同导致的级联失败。 (来源: Reddit r/ArtificialInteligence)
Sam Altman 关于与 AI 交互礼貌问题的澄清 : 社区流传关于 Sam Altman 是否认为对 ChatGPT 说“谢谢”是浪费时间的讨论。实际的推文互动显示,Altman 是在回应一位用户关于“对 LLM 礼貌是否必要”的帖子时表示“不需要”,但该用户随后开玩笑说“你难道一次谢谢都没说过吗?”。这表明 Altman 的评论可能更多是针对技术效率而非人机交互礼仪的规范,但被部分媒体断章取义。社区对此反应不一,许多人表示仍习惯性地对 AI 保持礼貌。 (来源: Reddit r/ChatGPT
)
Claude 回复中的 “thinking budget” 标签引关注 : 用户发现在 Claude.ai 的系统消息中,当启用“思考”功能时,会附加一个 <max_thinking_length> 标签(如 <max_thinking_length>16000</max_thinking_length>)。这与 Google Gemini 2.5 Flash API 中的 “thinking_budget” 参数类似,暗示模型内部可能存在控制推理深度的机制。用户尝试通过修改 Prompt 中的该标签来影响输出长度,但未观察到明显效果,推测该标签在网页版中可能仅为内部标记,而非用户可控参数。 (来源: Reddit r/ClaudeAI)
💡 其他
全国首部「AI 大模型私有化部署标准」启动编制 : 为应对企业在私有化部署 AI 大模型时面临的技术选型、流程规范、安全合规及效果评价等挑战,智合标准中心联合公安部第三研究所等 12 家单位,启动了团体标准《人工智能大模型私有化部署技术实施与评价指南》的编制工作。该标准旨在覆盖模型选用、资源规划、部署实施、质量评价到持续优化的全流程,融合技术、安全、评价与案例,并汇集模型应用方、技术服务方和质量评价方的经验。标准编制工作正邀请更多相关企业和机构参与。 (来源: 12家单位已加入!全国首部「AI大模型私有化部署标准」欢迎参与!

AI 治理成为定义下一代 AI 的关键 : 随着 AI 技术日益强大和普及,AI 治理(Governance)变得至关重要。有效的治理框架需要确保 AI 的开发和应用符合伦理规范、法律法规,保障数据安全和隐私,并促进公平性和透明度。缺乏治理可能导致偏见放大、滥用风险增加以及社会信任缺失。文章强调,建立健全的 AI 治理体系是推动 AI 健康、可持续发展的必要条件,也是企业在 AI 时代建立竞争优势和用户信任的关键。 (来源: Ronald_vanLoon

)
法律体系努力追赶 AI 发展与数据盗窃问题 : 文章探讨了当前法律体系在应对快速发展的 AI 技术,特别是涉及数据隐私和数据盗窃问题时所面临的挑战。AI 的数据需求巨大,训练数据的来源和使用方式引发了版权、隐私和安全方面的法律争议。现行法律往往滞后于技术发展,难以有效规制数据抓取、模型训练中的偏见以及 AI 生成内容的知识产权等问题。文章呼吁加强立法和监管,以跟上 AI 进步的步伐,保护个人权利和促进创新。 (来源: Ronald_vanLoon

)
AI 与机器人在农业领域的应用 : 人工智能和机器人技术正在农业领域展现潜力。应用包括精准农业(通过传感器和 AI 分析优化灌溉、施肥)、自动化设备(如自动驾驶拖拉机、采摘机器人)、作物监测(利用无人机和图像识别病虫害)以及产量预测等。这些技术有望提高农业生产效率、减少资源浪费、降低人力成本,并促进农业的可持续发展。 (来源: Ronald_vanLoon)
AI 驱动的机器人足球展示 : 视频展示了机器人进行足球比赛的场景。这体现了 AI 在机器人控制、运动规划、感知和协作方面的进步。机器人足球不仅是娱乐和竞技项目,也是研究和测试多机器人系统、实时决策和复杂动态环境交互的平台。 (来源: Ronald_vanLoon)
机器人辅助手术技术发展 : 机器人辅助手术系统(如达芬奇手术机器人)通过提供微创操作、高清 3D 视野和增强的灵活性与精度,正在改变外科手术领域。AI 的融入有望进一步提升手术规划、实时导航和术中决策支持的能力,从而改善手术效果、缩短恢复时间并扩大微创手术的适用范围。 (来源: Ronald_vanLoon)
面向残障人士的辅助技术 : AI 和机器人技术正在开发更多创新的辅助工具,以帮助残障人士提高生活质量和独立性。例子可能包括智能假肢、视觉辅助系统、语音控制家居设备、以及能够提供物理支持或执行日常任务的辅助机器人。 (来源: Ronald_vanLoon)
宇树 G1 仿生机器人展示敏捷性 : 宇树科技(Unitree Robotics)展示了其 G1 仿生机器人的升级版,突显其运动的敏捷性和灵活性。这类仿人或仿生机器人的发展融合了 AI(用于感知、决策、控制)和先进机械工程,旨在模拟生物运动能力,以适应复杂环境并执行多样化任务。 (来源: Ronald_vanLoon)
谷歌 DeepMind 探索 AI 与海豚交流的可能性 : Google DeepMind 的研究项目暗示了利用 AI 模型分析和理解动物(如此处提到的海豚)通讯的可能性。通过机器学习分析复杂的声学信号,AI 或许能帮助解码动物语言的模式和结构,为跨物种交流的研究开辟新途径。 (来源: Ronald_vanLoon)
Hugging Face 平台新增机器人模拟器 : Hugging Face 宣布将引入一个新的机器人模拟器。机器人模拟是训练和测试机器人在虚拟环境中与物理世界交互(如抓取、移动)的关键步骤,尤其是在将 AI 应用于物理机器人(Physical AI)之前。此举表明 Hugging Face 正在扩展其平台能力,以更好地支持机器人和具身智能领域的研究与开发。 (来源: huggingface)