
关键词:AI, TPU, 谷歌第七代TPU性能, AI Agent协作协议, 商汤日日新V6模型, AI数学奥林匹克竞赛, 开源Firecrawl工具
🔥 聚焦
谷歌发布A2A协议与第七代TPU,加速AI Agent与推理时代 : 谷歌推出开源Agent2Agent (A2A)协议,旨在实现不同供应商和框架下的AI Agent安全通信与协作,补充而非替代MCP协议(MCP连接Agent与工具,A2A连接Agent与Agent)。A2A遵循能力发现、任务管理、协作和用户体验协商等原则,已获超50家伙伴支持。同时,谷歌发布专为AI推理优化的第七代TPU(Ironwood/TPU v7),FP8算力达4614 TFlops,单芯片HBM 192GB,带宽7.2 TBps,能效为上一代2倍。最高配集群(9216颗芯片)算力达42.5 ExaFlops,旨在支持Gemini等“思考型”模型和下一代AI Agent应用,标志着AI正从响应式向主动生成洞察转变。 (来源: 36氪, 36氪, 微信公众号, 微信公众号, 微信公众号, 微信公众号)

MCP成AI Agent生态枢纽,阿里腾讯全面拥抱 : 模型上下文协议(MCP)正迅速成为连接AI Agent与外部工具、数据源的标准接口,被誉为AI生态的“USB”。阿里云百炼上线业界首个全生命周期MCP服务,集成函数计算、超200款大模型及50多款MCP服务,实现5分钟快速搭建Agent。腾讯云也发布支持MCP插件托管的“AI开发套件”。MCP通过解耦主机、服务器和客户端,降低了重复开发成本,提升了AI工具的互联互通能力,对实现复杂Agent协作至关重要。尽管面临生态不健全、工具链不完整等早期挑战,但随着OpenAI、谷歌、微软、亚马逊及国内大厂的纷纷支持,MCP有望加速AI应用爆发和产业发展。 (来源: 36氪)
AI在数学奥林匹克竞赛中取得突破性进展 : 第二届AI数学奥林匹克竞赛(AI Mathematical Olympiad – Progress Prize 2)结果显示,AI在解决高难度数学问题上取得显著进步。最佳模型在由全新题目构成、计算资源受限(每题成本低于1美元)且需精确整数答案(0-999)的测试中获得34/50的高分,远超此前研究中人类评估认为LLM仅能达到约5%水平的判断。即使是相对基础的DeepSeek R1衍生模型也取得了28/50的成绩。这一结果表明,AI的数学推理能力,特别是在需要创造性解题的奥赛级问题上,正快速提升,并非简单的模式匹配或数据记忆。 (来源: Reddit r/MachineLearning)
商汤发布日日新SenseNova V6,6000亿参数多模态MoE模型 : 商汤科技推出第六代大模型日日新SenseNova V6,采用6000亿参数的混合专家(MoE)架构,原生支持文本、图像、视频等多模态输入与融合处理。该模型在多项纯文本和多模态基准测试中表现优异,超越GPT-4.5及Gemini 2.0 Pro。其核心能力包括强推理(多模态和语言深度推理超o1、Gemini 2.0 flash-thinking)、强交互(实时音视频理解、情感表达)和长记忆(支持长视频分析,如直接推理数分钟视频内容)。关键技术包括原生多模态融合训练、多模态长思维链合成(支持64K tokens)、多模态混合增强学习(RLHF+RFT)以及长视频统一表征与动态压缩。商汤强调AI应服务于日常应用,推动AI在各行业的落地。 (来源: 微信公众号)
🎯 动向
谷歌Gemini 2.5 Flash即将发布,主打高效推理 : 谷歌在Cloud Next ’25大会上预告了Gemini 2.5 Flash模型。作为旗舰模型Gemini 2.5 Pro的轻量化版本,Flash将专注于提供快速、低成本的推理能力。其特点在于能够根据提示的复杂性动态调整推理深度,避免在简单问题上过度计算。开发者将能够自定义推理深度以控制成本。该模型预计很快将在Vertex AI上可用,旨在满足对响应速度敏感的日常应用需求。 (来源: 微信公众号, X)

字节跳动发布Seed-Thinking-v1.5技术报告,推理能力强劲 : 字节跳动公布了其基于强化学习训练的推理模型Seed-Thinking-v1.5的技术细节。报告显示,该模型在多个基准测试中表现出色,性能超越DeepSeek-R1,接近Gemini-2.5-Pro和O3-mini-high的水平,在ARC-AGI测试中得分达40%。该模型拥有2000亿总参数和200亿激活参数。目前模型权重尚未发布,但其优异的推理能力和相对较小的激活参数量引起了社区关注。 (来源: X)

ChatGPT增强记忆功能,可引用所有历史对话 : OpenAI宣布升级ChatGPT的记忆功能,允许模型引用用户所有过往的聊天记录来提供更个性化的回应。这项增强旨在利用用户的偏好和兴趣,提升写作、建议、学习等方面的帮助效果。用户在开启新对话时,ChatGPT会自然地利用这些记忆。用户仍然可以完全控制此功能,可在设置中关闭引用历史记录,或完全关闭记忆功能,也可使用临时对话模式。该功能已开始向Plus和Pro用户推送(部分地区除外),并将很快覆盖团队、企业和教育版用户。 (来源: X, X)
OpenAI发布GPT-4.5开发幕后播客 : Sam Altman与OpenAI核心团队成员Alex Paino, Dan Selsam, Amin Tootoonchian录制播客,探讨了GPT-4.5的研发过程及未来方向。团队透露,GPT-4.5的研发标志着从计算效率优化转向数据效率优化,目标是实现比GPT-4高十倍的智能。播客讨论了无监督学习中“压缩”机制的重要性(近似所罗门诺夫归纳),强调了准确评估模型表现、避免死记硬背的必要性,并分享了攻克技术难关的经历和团队士气的重要性。 (来源: X, X)
Perplexity整合Gemini 2.5 Pro,计划接入Grok 3和WhatsApp : AI搜索引擎Perplexity宣布已为Pro用户接入Google最新的Gemini 2.5 Pro模型,并邀请用户将其与Sonar、GPT-4o、Claude 3.7 Sonnet、DeepSeek R1和O3等模型进行比较。此外,Perplexity CEO Aravind Srinivas确认,在收到大量用户积极反馈后,将着手开发Perplexity的WhatsApp集成功能。同时,Grok 3模型也计划很快在Perplexity平台上得到支持。 (来源: X, X, X)

阿里Qwen3系列模型蓄势待发,发布尚需时日 : 社区对阿里巴巴下一代Qwen3系列模型充满期待,包括非开源版本、Qwen3-8B以及Qwen3-MoE-15B-A2B等。然而,根据Qwen开发人员在社交媒体上的回应,Qwen3的发布并非“几小时内”的事情,仍需要更多时间准备。这表明阿里正在积极研发新一代模型,但具体发布时间表尚未确定。 (来源: X, Reddit r/LocalLLaMA)

LM Arena出现神秘高性能模型”Dragontail”与”Quasar Alpha”引猜测 : 在LMSYS Chatbot Arena(LM Arena)平台上,出现了名为”Dragontail”和”Quasar Alpha”的匿名模型,它们在与用户的交互中展现出与顶级模型(如o3-mini-high, Claude 3.7 Sonnet)相当甚至在某些数学问题上更优的性能。社区猜测”Dragontail”可能是即将发布的Qwen3或Gemini 2.5 Flash的变体,而”Quasar Alpha”则被部分用户推测为OpenAI的o4-mini系列模型。这些匿名模型的出现反映了模型竞技场作为前沿模型试水和性能评估平台的作用。 (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
月之暗面Kimi-VL-A3B-Thinking模型Demo上线Hugging Face : 月之暗面(Moonshot AI)已在Hugging Face Spaces上线了其Kimi-VL-A3B-Thinking多模态模型的交互式演示(Demo)。用户现在可以公开体验该模型。初步测试显示,该模型具备在线的OCR和图像识别能力,但在某些需要广泛知识储备的任务(如理解特定meme的笑点)上可能表现有限,这可能与其模型规模有关。 (来源: X, X)

AMD将举办AI活动,发布数据中心GPU新品 : AMD计划举办名为“Advancing AI 2025”的活动,届时将发布用于数据中心的新款GPU。此次发布将专注于AI应用,而非游戏显卡。此举表明AMD在AI硬件市场的持续投入,意图在由Nvidia主导的AI加速器领域展开竞争。 (来源: Reddit r/artificial)
🧰 工具
Firecrawl:将网站转化为LLM可用数据的开源工具 : Mendable AI 推出的 Firecrawl 是一个强大的开源工具(TypeScript编写),旨在通过单一API将整个网站抓取、爬取并转换为LLM就绪的Markdown或结构化数据。它能处理代理、反机器人机制、动态内容渲染等难题,并支持自定义抓取(如排除标签、认证抓取)、媒体解析(PDF、DOCX)和页面交互(点击、滚动、输入)。提供API、Python/Node/Go/Rust SDK,并已集成到Langchain、Llama Index、Crew.ai等多种LLM框架和低代码平台(Dify, Langflow, Flowise)。Firecrawl提供托管API服务及可本地运行的开源版本。 (来源: GitHub)
KrillinAI:基于大模型的视频翻译和配音工具 : KrillinAI 是一个使用Go语言编写的开源项目,利用大型语言模型(LLM)提供专业级的视频翻译和配音服务。它支持一键式全流程部署,能够处理从视频下载(支持yt-dlp和本地上传)、高精度字幕生成(Whisper)、智能字幕分割与对齐(LLM)、多语言翻译、术语替换、AI配音与声音克隆(CosyVoice)到视频合成(自动适配横/竖屏)的完整工作流。旨在生成适配YouTube、TikTok、Bilibili等平台的内容。项目提供了Win/Mac桌面版和非桌面版(Web UI),并支持Docker部署。 (来源: GitHub)
Second Me:构建本地化、个性化的“AI自我” : Second Me 是一个开源项目,旨在使用本地运行的AI模型构建用户的“数字孪生”或“AI自我”。它强调隐私(完全本地执行)和个性化,通过分层记忆建模(HMM)和“Me-alignment”结构来模拟用户的身份、记忆、价值观和推理方式。项目支持Docker部署(macOS、Windows、Linux)和OpenAI兼容API接口,并正在探索MLX训练支持。社区活跃,已贡献微信机器人集成、多语言支持等。其愿景是让AI成为用户能力的延伸,而非平台的附属。 (来源: Reddit r/LocalLLaMA)

EasyControl:为DiT架构Diffusion模型提供LoRA式条件注入 : EasyControl 是一个新发布的开源框架,旨在解决基于DiT(Diffusion Transformer)架构的新型Diffusion模型缺乏成熟插件(如LoRA)支持的问题。它提供了一个轻量级的条件注入模块,允许用户轻松地为DiT模型添加类似LoRA的控制能力,实现风格迁移等任务。项目展示了使用100张亚洲人脸及其对应的吉卜力风格图像(由GPT-4o生成)训练出的模型效果,并已支持与ComfyUI集成。 (来源: X)

XplainMD:融合GNN与LLM的生物医学可解释AI管道 : XplainMD 是一个开源的端到端AI管道,专为生物医学知识图谱设计。它结合图神经网络(R-GCN)进行多关系链接预测(如药物-疾病、基因-表型关系),使用GNNExplainer实现模型解释性,通过PyVis可视化预测子图,并利用LLaMA 3.1 8B Instruct模型对预测进行自然语言解释和健全性检查。整个流程部署在一个交互式的Gradio应用中,旨在提供预测的同时解释“为什么”,增强AI在精准医疗等敏感领域的可信度和可用性。 (来源: Reddit r/deeplearning, Reddit r/MachineLearning)
LaMPlace:AI驱动的芯片宏单元布局优化新方法 : 中国科学技术大学、华为诺亚方舟实验室及天津大学的研究者提出LaMPlace,一种基于AI的芯片宏单元布局优化方法。该方法通过结构化的指标预测器(使用Laurent多项式建模宏间距离对WNS/TNS等跨阶段指标的影响)和可学习掩码生成机制,在布局早期阶段就引导放置决策,以优化最终的芯片性能(PPA)。LaMPlace旨在将优化目标从易于计算的中间指标(如线长、密度)迁移到最终设计目标,实现“左移优化”,提高设计效率。该方法已入选ICLR 2025 Oral。 (来源: 微信公众号)
谷歌推出Agent Development Kit (ADK) 与 Firebase Studio : 作为其推动AI Agent生态的一部分,谷歌发布了Agent Development Kit (ADK),一个用于构建多智能体系统的开发框架。ADK支持多种模型提供商(Gemini, GPT-4o, Claude, Llama等),提供CLI工具、Artifact管理、AgentTool(Agent间调用)等功能,并支持部署到Agent Engine或Cloud Run。同时,谷歌还推出了Firebase Studio,一个云端AI编程工具,集成了Gemini模型,支持从AI编码、编译构建到云服务部署的全流程应用开发。 (来源: 微信公众号, Reddit r/LocalLLaMA)
OpenFOAMGPT:利用国产大模型降低CFD仿真成本 : 英国埃克塞特大学与北航团队合作更新了OpenFOAMGPT项目,该项目旨在让用户通过自然语言驱动计算流体力学(CFD)仿真。新版本成功整合了国产大模型DeepSeek V3和Qwen 2.5-Max,在保持与GPT-4o/o1相近性能的同时,可将成本降低高达100倍。此外,团队还使用QwQ-32B模型实现了本地化部署(单GPU环境),为国内研究者和中小企业提供了更经济、便捷的AI辅助CFD解决方案,降低了专业门槛。 (来源: 微信公众号)
Slop Forensics Toolkit:LLM输出重复内容分析工具 : 一个新的开源工具包被发布,用于分析大型语言模型(LLM)输出中的“slop”——即过度重复使用的词语和短语。该工具利用文体学分析来识别相比人类写作更频繁出现的词汇和n-grams,构建模型的“slop profile”。它还借鉴生物信息学方法,将词汇特征视为“突变”,推断不同模型之间的相似性树。该工具旨在帮助研究人员理解和比较不同LLM的生成特性和潜在的数据污染或训练偏差。 (来源: Reddit r/MachineLearning)
vLLM 推理框架增加对 Google TPU 的支持 : 流行的开源大模型推理和服务框架 vLLM 宣布增加了对 Google TPU 的支持。结合谷歌最新发布的第七代TPU(Ironwood),这一更新意味着开发者可以利用vLLM在谷歌的高性能AI硬件上进行高效的模型推理和部署。这有助于扩展TPU的软件生态系统,为用户提供更多硬件选择。 (来源: X)

📚 学习
港中文、清华等提出SICOG框架,探索大模型自我进化新路径 : 针对大模型对高质量预训练数据的依赖及数据资源枯竭问题,港中文、清华大学等机构提出SICOG(Self-Improving Systematic Cognition)框架。该框架构建了“后训练增强-推理优化-再预训练强化”的三位一体自进化机制,通过“链式描述”(CoD)提升结构化视觉感知,“结构化思维链”(CoT)增强多模态推理,并利用自生成数据闭环和一致性筛选,在零人工标注下实现模型认知能力的持续提升。实验证明,SICOG能显著提升模型在多项任务上的性能,降低幻觉,并展现出良好的扩展性,为解决预训练瓶颈和迈向自主学习型AI提供了新思路。 (来源: 微信公众号)
OpenAI开源BrowseComp基准,评估AI Agent网页浏览能力 : OpenAI发布并开源了BrowseComp(Browsing Competition)基准测试。该基准旨在评估AI Agent在互联网上浏览以查找难以定位信息的能力,类似于一个针对Agent的在线寻宝游戏。OpenAI认为,这类测试能够捕捉智能体进行深度研究式浏览的关键能力,对于评估高级网页浏览Agent的智能水平至关重要。 (来源: X, X)
研究发现推理模型在OOD编码任务上泛化能力更强 : 一项新研究(arXiv:2504.05518v1)通过编码任务实验对比了推理模型与非推理模型的泛化能力。结果显示,推理模型在从分布内(in-distribution)任务迁移到分布外(out-of-distribution, OOD)任务时,性能没有明显下降;而非推理模型则表现出性能下降。这表明推理模型不仅仅是模式匹配器,它们能够学习并泛化到训练分布之外的任务,拥有更强的抽象和应用能力。 (来源: Reddit r/ArtificialInteligence)
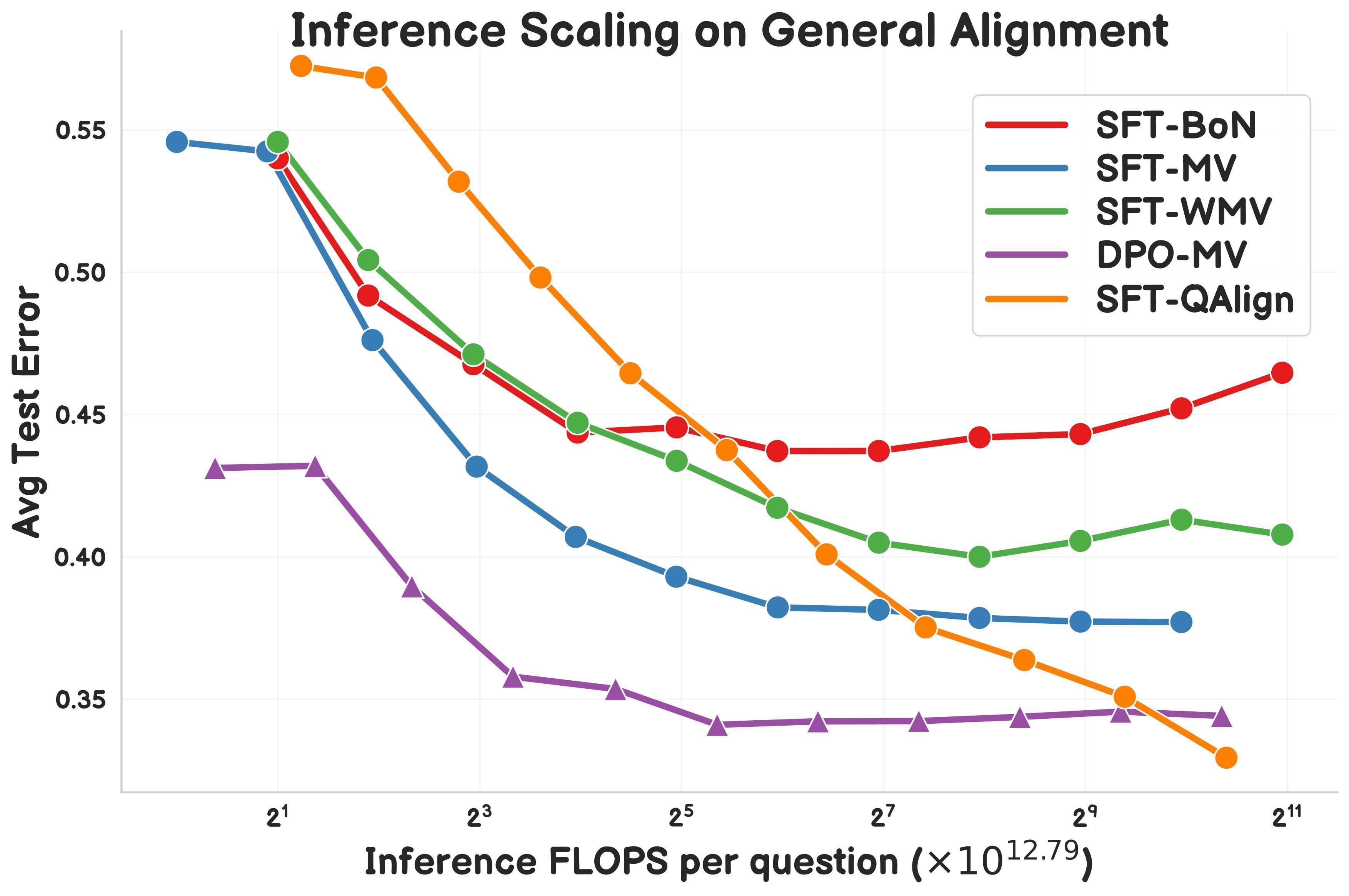
研究提出QAlign:基于MCMC的测试时对齐方法 : Gonçalo Faria等人提出QAlign,一种新的测试时对齐(test-time alignment)方法,使用马尔可夫链蒙特卡洛(MCMC)来提升语言模型性能,无需重新训练模型。研究表明,QAlign在性能上优于经过DPO(Direct Preference Optimization)调优的模型(在相同推理计算量下),并能克服传统Best-of-N采样(易过度优化奖励模型)和多数投票(无法发现独特答案)的局限性,有望用于高质量数据生成等场景。 (来源: X)
Yann LeCun再次强调自回归LLM的局限性 : 在近期的演讲中,Meta首席AI科学家Yann LeCun重申了他对当前主流自回归(Auto-Regressive)大型语言模型架构局限性的看法,认为其模式“注定失败”(doomed)。他认为这种逐词预测的方式限制了模型进行真正规划和深度推理的能力。虽然自回归模型目前仍是SOTA,但LeCun等研究者正积极探索替代方案,如联合嵌入预测架构(JEPA),以期实现更接近人类智能的AI系统。 (来源: Reddit r/MachineLearning)
LlamaIndex展示与Google Cloud结合构建报告生成Agent : LlamaIndex创始人Jerry Liu在Google Cloud Next ’25上展示了如何结合LlamaIndex工作流和Google Cloud数据库(如BigQuery, AlloyDB)构建一个报告生成Agent。该Agent能够解析SOP文档(使用LlamaParse)、教程数据库、法律数据等,为新员工生成个性化的入职指南。这体现了知识型Agent架构需要强大的数据访问和处理能力,并展示了LlamaIndex在构建此类Agent应用中的作用。 (来源: X)

研究者分享Symbolic Compression引擎与.sym文件格式 : 一位独立研究者开源了一个名为Symbolic Compression的引擎及其对应的.sym文件格式。该项目声称能够通过提取序列(如素数、斐波那契数列)背后的递归规则和结构逻辑(基于其提出的Miller’s Law: κ(x) = ((ψ(x) – x)/x)²)来进行压缩,而非仅压缩原始数据。它旨在存储和预测结构本身的出现,提供一种类似JSON但用于递归逻辑的格式。项目包含CLI工具和多区域压缩功能。 (来源: Reddit r/MachineLearning)

💼 商业
Grok-3 API定价公布,最低0.3美元/百万token : xAI 正式向公众开放 Grok 3 系列 API,采用多档定价策略。Grok 3 (Beta) 面向企业应用,输入定价3美元/百万token,输出15美元/百万token;轻量级 Grok 3 Mini (Beta) 输入定价0.3美元/百万token,输出0.5美元/百万token。两者均提供快速响应版本 (fast-beta),价格更高。此定价策略使其在成本上与谷歌 Gemini 2.5 Pro、Anthropic Claude Max 套餐(最低100美元)以及 Meta Llama 4 Maverick (约0.36美元/百万token) 等模型形成竞争。 (来源: 微信公众号)
斯坦福AI报告:阿里AI实力全球第三,中美差距缩小 : 斯坦福大学最新《2025年人工智能指数报告》显示,全球重要大模型贡献中,谷歌和OpenAI各占7席并列第一,阿里巴巴以6席(Qwen系列)位居全球第三、中国第一。报告指出,中美模型性能差距显著缩小,从2023年底的17.5个百分点(MMLU基准)降至2024年底的0.3个百分点。阿里Qwen模型家族(已开源200多款)成为全球最大的开源模型系列,衍生模型超10万。报告还提到,中国顶级模型(如Qwen2.5, DeepSeek-V3)在训练算力需求上普遍低于美国同类模型,显示出更高的效率。 (来源: 微信公众号)
中国医疗AI企业在关税与技术壁垒下寻求突围 : 面对美国关税增加和技术垄断(如GPS巨头掌握影像数据接口)等多重压力,中国医疗科技企业正加速国产替代和智能化转型。联影医疗坚持核心技术自研,推出5.0T磁共振等高端设备,并发展医疗大模型及智能体。迈瑞医疗通过“设备+IT+AI”战略,构建数智化生态(如瑞影云++平台融合DeepSeek)并深耕国际市场。德适生物则以iMedImage®医学影像大模型切入精准医疗,参与制定行业标准,实现差异化竞争。这些企业以AI为驱动,力图在核心技术、供应链和临床接受度上突破,重塑市场格局。 (来源: 微信公众号)
🌟 社区
AI在教育领域的应用引发讨论 : 社区讨论关注人工智能(AI)如何通过定制化学习计划改变教育。AI有潜力根据学生的个人需求、学习节奏和风格来调整教学内容和方法,实现个性化教育,提升学习效率和效果。 (来源: X)

Cursor编辑器背后的复杂工程引关注 : 社区讨论提及AI代码编辑器Cursor的实现并非易事。其核心目标是避免用户手动复制粘贴代码,为此进行了大量用户体验优化和工程创新,包括发明新的代码编辑范式、自研快速编辑模型FastApply和代码补全预测模型Fusion、在本地和服务器端实施两层RAG以优化上下文处理等。这些努力显示了构建流畅AI编程体验所需的技术深度。 (来源: X)
AI作弊工具引发伦理与招聘体系讨论 : 一名哥伦比亚大学学生Roy Lee开发AI工具“Interview Coder”在编程面试中作弊,获得多家顶级公司Offer后被学校开除,随后通过销售该工具在50天内获利220万美元。该工具能隐形运行,模拟人类编码风格生成答案。事件引发广泛讨论:一方面,许多开发者对僵化、脱离实际的编程面试(如LeetCode刷题)感到不满;另一方面,AI作弊现象激增(有报告称比例从2%升至10%),挑战了现有技术面试的有效性,可能迫使企业重塑招聘体系,并引发关于AI时代何为“作弊”的伦理界限讨论。 (来源: 36氪)
通用Agent创新应用涌现 : 近期Agent黑客松比赛(如flowith, openmanus)涌现出许多创新应用。开发设计类:Agent能根据UI草图自动生成包含前后端代码和数据库结构的完整项目(maxcode),或自主搜集信息、确定风格并生成个人网站。分析决策类:Agent能计算航班最佳极光观赏位置,或进行自迭代量化交易策略优化(一鹿向北)。个性化服务类:Agent能智能推荐聚会地点(Jarvis-CafeMeet),分析豆瓣数据生成“品味报告”,或通过语音交互服务老年用户(老奶奶教你用OpenManus)。艺术创作类:Agent能生成特定风格数字艺术、根据音乐生成舞蹈、定制绘画笔刷、实时生成可编程音乐(strudel-manus)等。这些案例展示了Agent在各领域的巨大潜力。 (来源: 微信公众号)
Andrew Ng评论美国关税对AI发展的影响 : 吴恩达(Andrew Ng)发文对美国广泛征收高额关税表示担忧,认为这将损害盟友关系、阻碍全球经济、制造通胀,并对AI发展产生负面影响。他指出,虽然思想和软件(尤其是开源软件)的自由流动可能不受太大影响,但关税会限制AI硬件(如服务器、冷却、网络设备)的获取,增加数据中心建设成本,并通过影响电力设备进口间接影响算力供应。尽管关税可能轻微刺激国内机器人和自动化需求,但这难以弥补制造业的短板。他呼吁AI社区保持国际合作与交流。 (来源: X)
社区热议AI在心理健康支持中的应用 : 越来越多的用户分享使用ChatGPT等AI工具进行心理咨询和情感支持的经历。许多人表示,AI提供了一个安全、无评判的空间来倾诉,能够获得即时反馈和有用的建议,甚至在某些情况下比人类治疗师更能让人感到被倾听和理解,从而产生积极的情感疏导效果。尽管用户普遍认同AI不能完全替代专业持证治疗师,尤其是在处理严重心理问题时,但它在提供基础支持、应对日常压力和初步探索个人问题方面显示出巨大潜力,并因其可及性和低成本而受到欢迎。 (来源: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
AI翻译内容的定性引发讨论 : 社区讨论了一个问题:如果使用AI(如ChatGPT)翻译人类创作的故事,其内容应被视为人类创作还是AI创作?有观点认为,若AI仅作为翻译工具,未改变原文思想、结构和基调,则内容本质仍是人类创作。然而,AI文本检测器可能会因分析文本模式而将其标记为AI生成。这引发了关于AI在创作过程中的角色界定、AI检测器局限性以及如何保持翻译中原文风格的思考。 (来源: Reddit r/ArtificialInteligence)
用户反馈 Gemini 2.5 Pro 在长上下文处理中存在问题 : 用户Nathan Lambert在测试Gemini 2.5 Pro时发现,在处理非常长的上下文输入查询时,模型会遇到连接错误。观察到的现象是模型在推理过程中似乎重新生成了几乎所有的输入令牌,导致推理成本极高并最终失败。此外,他还指出在发生错误时无法分享Gemini聊天记录。这些反馈指出了当前模型在处理超长上下文时可能存在的稳定性和效率问题。 (来源: X)

社区对Llama 4发布反响不佳,质疑其性能与开放性 : Meta发布的Llama 4系列模型在社区引发广泛讨论和负面评价。用户普遍认为,尽管Maverick模型拥有高达1000万token的上下文窗口且在函数调用方面表现尚可,但其400B的总参数量(17B激活参数)并未带来预期的推理性能提升,甚至不如QwQ 32B等模型。此外,其限制性的许可证、缺乏技术论文和系统卡、以及被指在LMSYS等基准上存在“刷分”嫌疑,都损害了Meta在开源社区的声誉。社区对Meta未能延续Llama 3的开放性和领先地位表示失望。 (来源: Reddit r/LocalLLaMA)

Claude Pro计划被指变相降级,用户抱怨使用限制增加 : 随着Anthropic推出价格更高的Max套餐(声称提供Pro计划5倍或20倍用量),社区中许多Claude Pro用户反映,感觉Pro计划本身的使用限制变得更加严格,更容易达到上限。用户猜测Anthropic可能降低了Pro计划的实际可用额度,以促使用户升级到Max计划。这种不透明的调整和感知到的服务降级引发了用户不满,尤其是在Claude模型本身仍存在上下文窗口记忆问题的情况下。 (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

OpenWebUI社区讨论功能与问题 : OpenWebUI用户在社区中讨论工具的功能和遇到的问题。有用户询问是否可能集成Nextcloud作为额外的云存储选项。另有用户报告在使用知识库功能时遇到问题,当上传多个文档时,LLM似乎只参考第一个文档。还有用户在尝试连接Gemini兼容的OpenAI API端点时遇到超时错误。这些讨论反映了用户对工具扩展性和稳定性的需求与关切。 (来源: Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
Suno AI社区交流使用技巧与问题 : Suno AI用户社区活跃,讨论内容包括:如何在使用Cover功能时排除特定乐器(如鼓、键盘)以分离独奏乐器;寻求生成特定音乐风格(如Trip Hop)的建议;报告邀请好友功能无法获得积分的问题;讨论歌词版权问题,例如特定短语(如“You’re Dead”)是否会触发版权限制;以及分享使用Suno进行创意应用的案例,如为D&D角色创作背景音乐。 (来源: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)
💡 其他
AI生成“意外照片”的探索 : 社区用户尝试使用AI生成看起来像是无意中拍摄、构图随意、甚至带有轻微模糊或过曝的“意外照片”。这种探索旨在挑战AI生成完美图像的倾向,模仿人类摄影中的偶然性和不完美性,展示了AI在理解和模拟特定摄影风格(包括“坏”照片风格)方面的能力。 (来源: Reddit r/ChatGPT)

AI在供应链管理中的应用潜力 : 讨论强调了人工智能(AI)在提升供应链追溯性和透明度方面的潜力。通过利用机器学习和数据分析,AI可以帮助企业更好地监控货物流程、预测中断风险、优化库存管理,并向消费者提供更可靠的产品来源信息。 (来源: X)

AI在人力资源管理中的应用探索 : 社区讨论提及采用AI虚拟形象(Avatars)进行人力资源管理的可能性。这可能包括使用AI进行初步面试筛选、员工培训、政策解答、甚至情感支持等任务,旨在提高HR流程效率和员工体验。 (来源: X)

英国央行警告AI可能引发市场危机 : 英国央行发出警告,指出人工智能软件可能被用于操纵市场,甚至故意制造市场危机以牟利。这引发了对AI在金融领域应用的监管和风险控制的担忧。 (来源: Reddit r/artificial)

AI生成逼真3D形状的新方法 : MIT的研究人员开发出一种新的生成式AI方法,能够创建更逼真的三维形状。这对于产品设计、虚拟现实、游戏开发和3D打印等领域具有重要意义,推动了从2D图像或文本描述生成复杂3D模型的技术进步。 (来源: X)

AI推理的功耗与成本大幅降低 : 有报道指出新的技术进展使得AI推理任务的功耗(以MAC能耗衡量)降低了100倍,成本降低了20倍。这种效率的提升对于AI模型在边缘设备、移动端以及大规模云部署的可行性和经济性至关重要。 (来源: X)

关于AI对人类认知影响的讨论 : 社区讨论关注过度依赖AI可能对人脑产生的影响,有观点引用文章标题称可能导致大脑“萎缩和准备不足”(Atrophied And Unprepared)。这反映了对AI工具普及后人类批判性思维、记忆力、问题解决能力等核心认知功能可能退化的担忧。 (来源: X)

对未来AI驱动工作模式的展望与担忧 : 社区讨论引用文章观点,预测到2025年,AI将重写工作规则,当前的工作模式可能终结。这引发了关于AI自动化对就业市场的影响、所需技能的转变以及人机协作新模式的探讨与担忧。 (来源: X)
