
关键词:AI, 模型, 斯坦福AI指数报告, 光子AI处理器, Llama 4视觉语言模型, Qwen2.5-Omni多模态, 英特尔大模型一体机
🔥 聚焦
斯坦福发布2025 AI指数报告: 斯坦福大学发布了长达456页的《2025 AI Index》报告,全面概述了AI领域的现状与趋势。报告指出,美国在模型发布数量上领先,但中国在模型质量上迅速追赶,性能差距显著缩小。训练成本持续攀升(如Gemini 1.0 Ultra约1.92亿美元),但推理成本急剧下降。AI的碳排放问题日益严峻,Meta Llama 3.1的训练排放量巨大。报告还提到,许多AI基准测试已饱和,难以区分模型能力,“人类最后考试”成为新挑战。公共数据抓取受限(48%顶级域名限制爬虫),引发对“数据峰值”的担忧。企业AI投资巨大,但尚未看到显著的生产力回报。AI在科学和医疗领域潜力巨大,但实际应用转化仍需时间。政策方面,美国州级立法活跃,尤其关注深度伪造,而全球层面多为无约束力声明。尽管存在对工作替代的担忧,公众对AI的整体态度仍偏乐观 (来源: AINLPer)
新型光子AI处理器取得突破: 《Nature》杂志刊登两篇论文,介绍了结合光子与电子的新型AI处理器,旨在突破后晶体管时代的性能与能耗瓶颈。新加坡Lightelligence公司的PACE光子加速器(含16000+光子组件)展示了高达1GHz的计算速度和500倍的最小延迟缩减,并在解决伊辛问题上表现优异。美国Lightmatter公司的光子处理器(含四个128×128矩阵)成功运行BERT、ResNet等AI模型,精度媲美电子处理器,并演示了玩《吃豆人》等应用。两项研究均表明其系统可扩展,利用现有CMOS厂房制造,有望推动AI硬件向更强、更节能的方向发展,标志着光子计算迈向实用化的重要一步 (来源: 36氪)

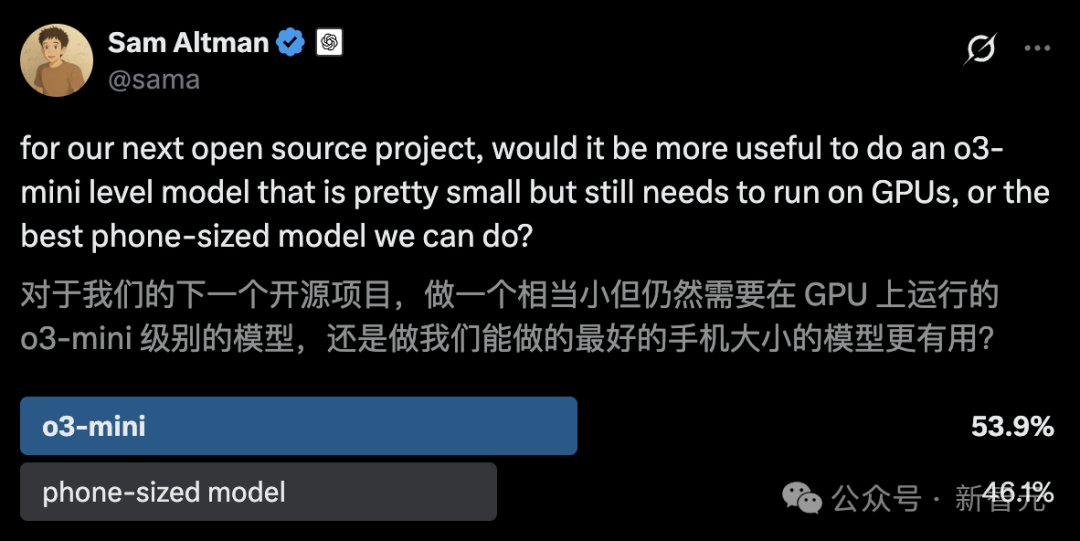
UC伯克利开源14B代码模型DeepCoder,媲美o3-mini: UC伯克利与Together AI联合发布了DeepCoder-14B-Preview,一个完全开源的14B参数代码推理模型,性能媲美OpenAI的o3-mini。该模型通过分布式强化学习(RL)从Deepseek-R1-Distilled-Qwen-14B微调而来,在LiveCodeBench基准测试中Pass@1达到60.6%。团队构建了包含24K个高质量编程问题的训练集,并采用了改进的GRPO+训练方法、迭代式上下文扩展(从16K扩展到32K,推理时达64K)和超长过滤技术。同时开源了优化的RL训练系统verl-pipeline,将端到端训练速度提高了2倍。此次发布不仅包括模型,还开放了数据集、代码和训练日志 (来源: 新智元)
🎯 动向
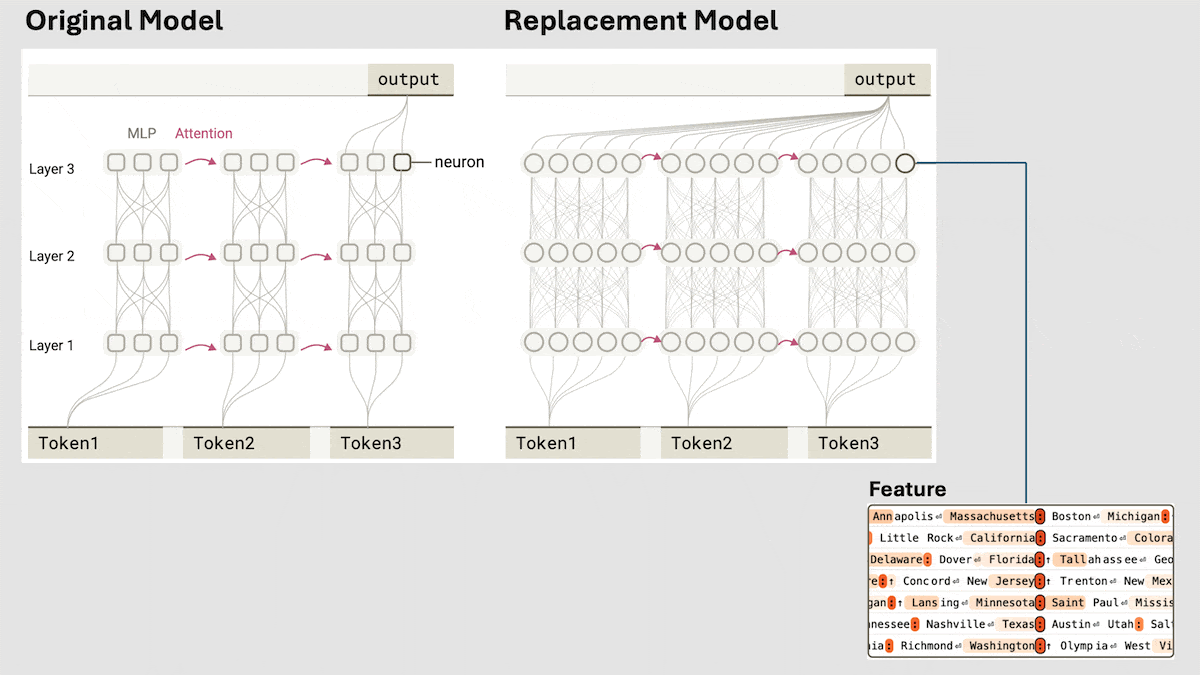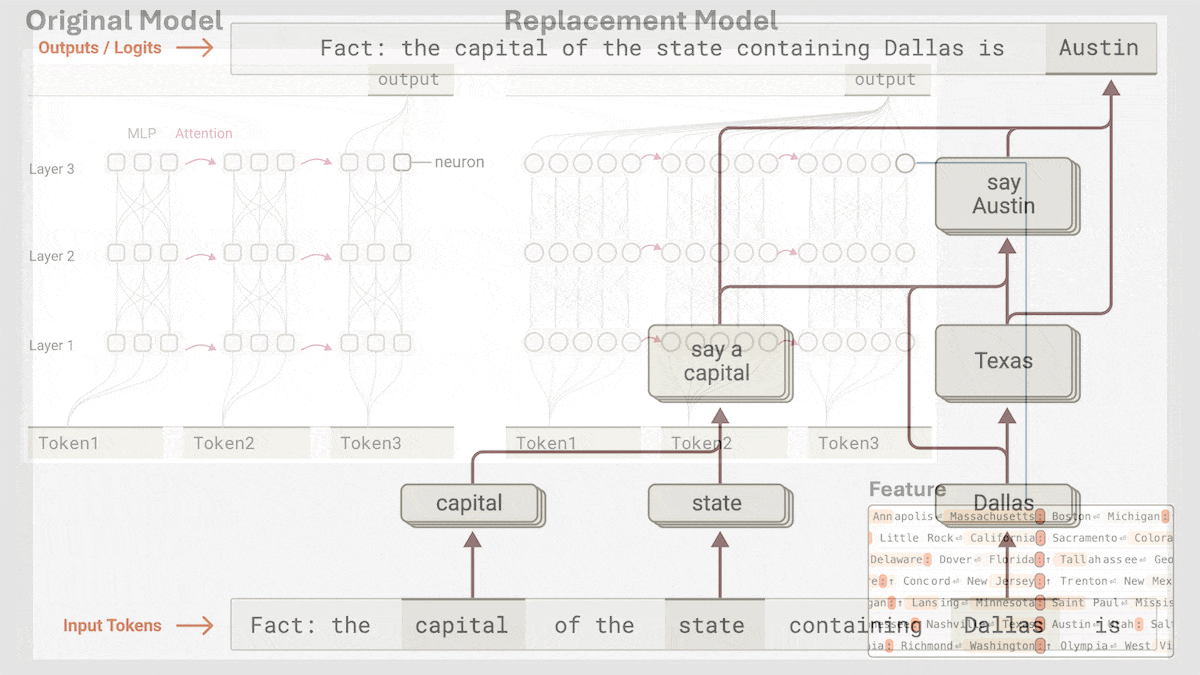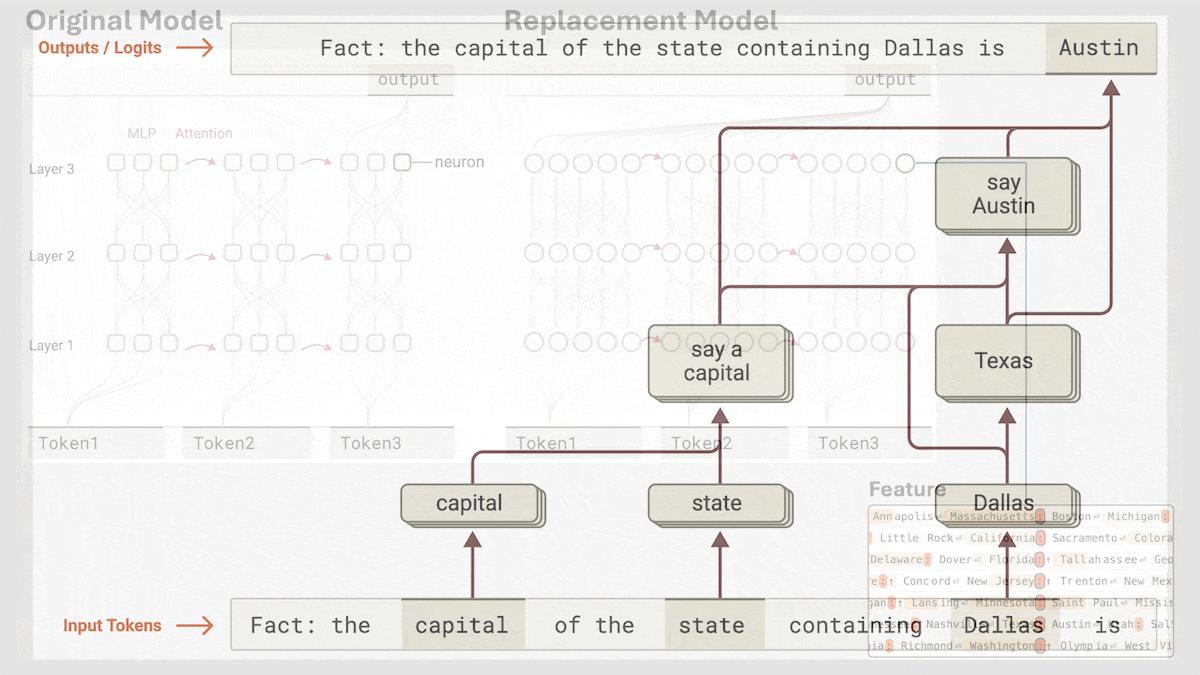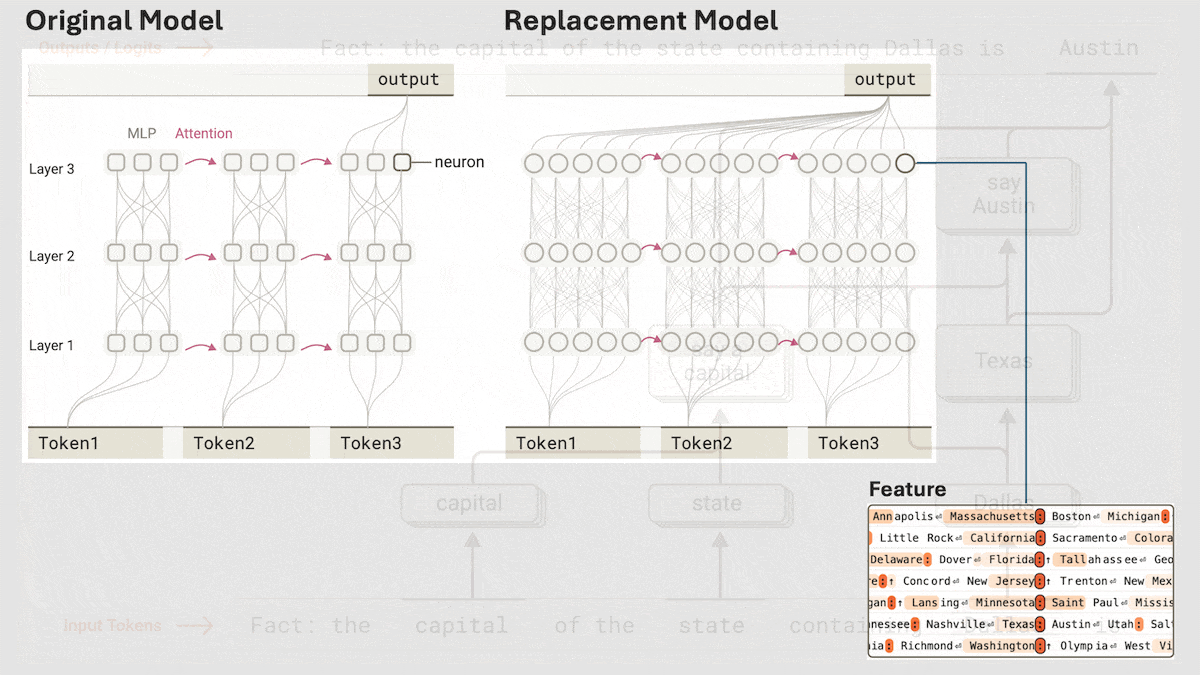
Anthropic揭示Claude 3.5 Haiku的隐式推理机制: Anthropic的研究团队通过一种新方法分析了Transformer模型(特别是Claude 3.5 Haiku)的内部工作机制。他们发现,即使没有明确训练进行链式思考(Chain-of-Thought),模型在生成响应时也会通过神经元激活表现出类似推理的步骤。该方法通过将全连接层替换为可解释的“跨层转码器”(cross-layer transcoder),识别与特定概念或预测相关的“特征”,并构建归因图来可视化信息流。实验表明,模型在回答问题(如“小的反义词是什么?”或判断达拉斯所在州的首府)时,内部会经历多个逻辑步骤,而非直接预测答案。该研究有助于理解LLM的内部运作,区分真正的推理能力和表面模仿 (来源: DeepLearning.AI)
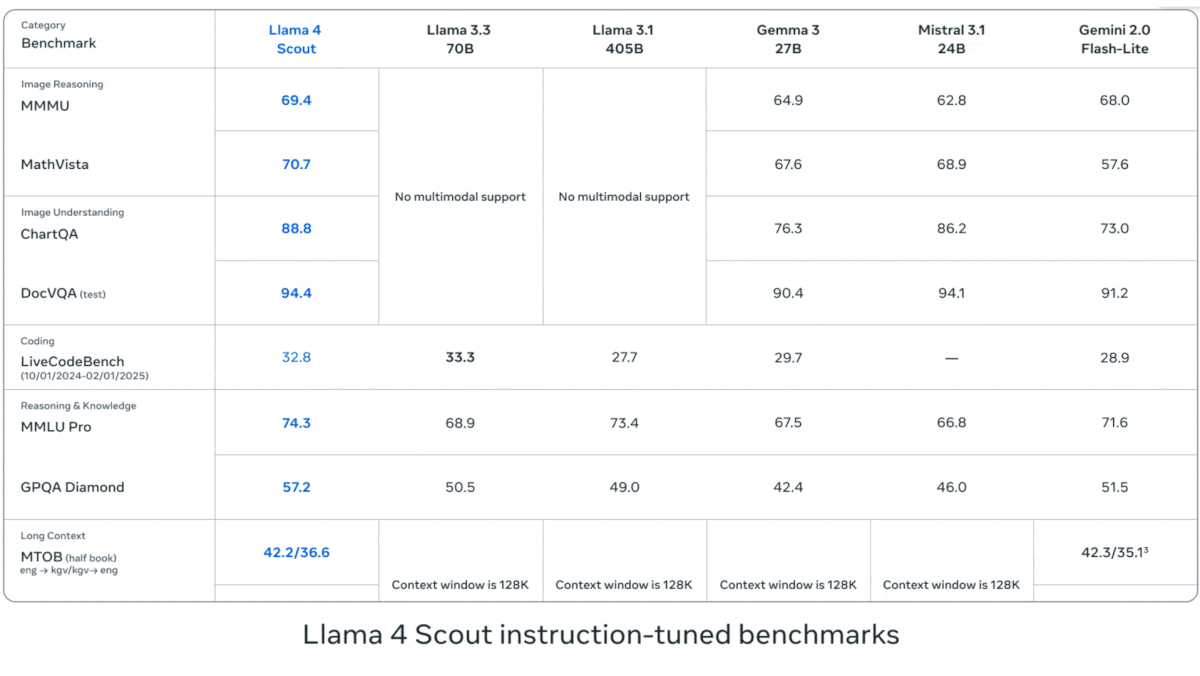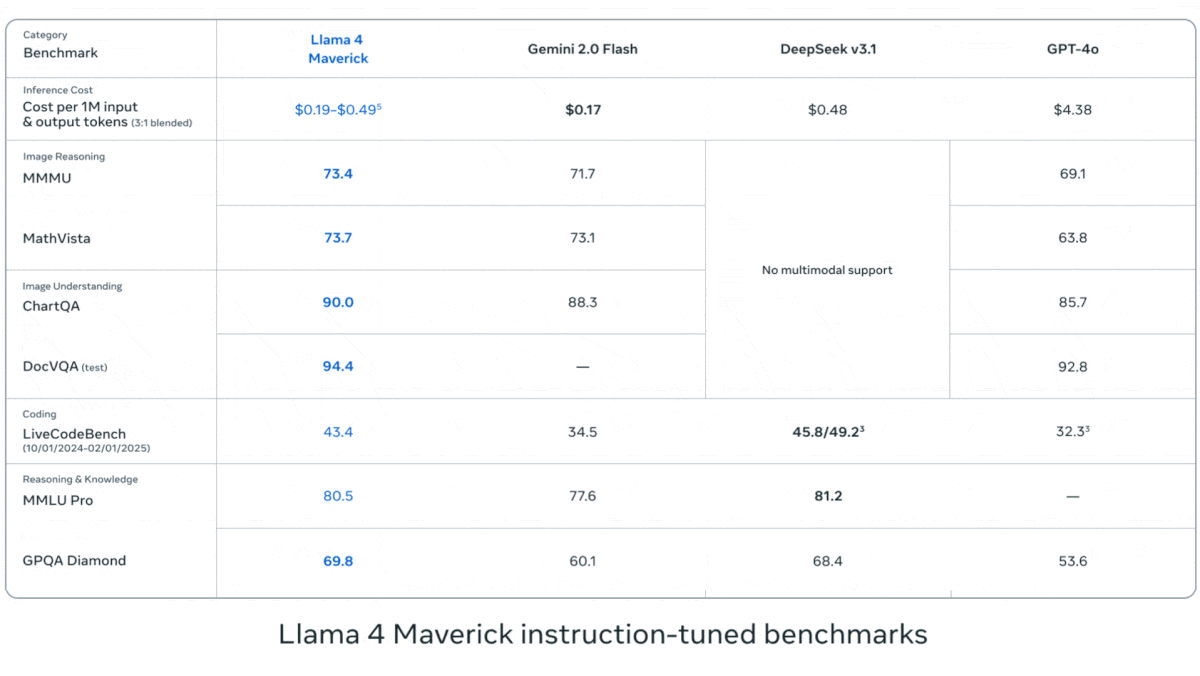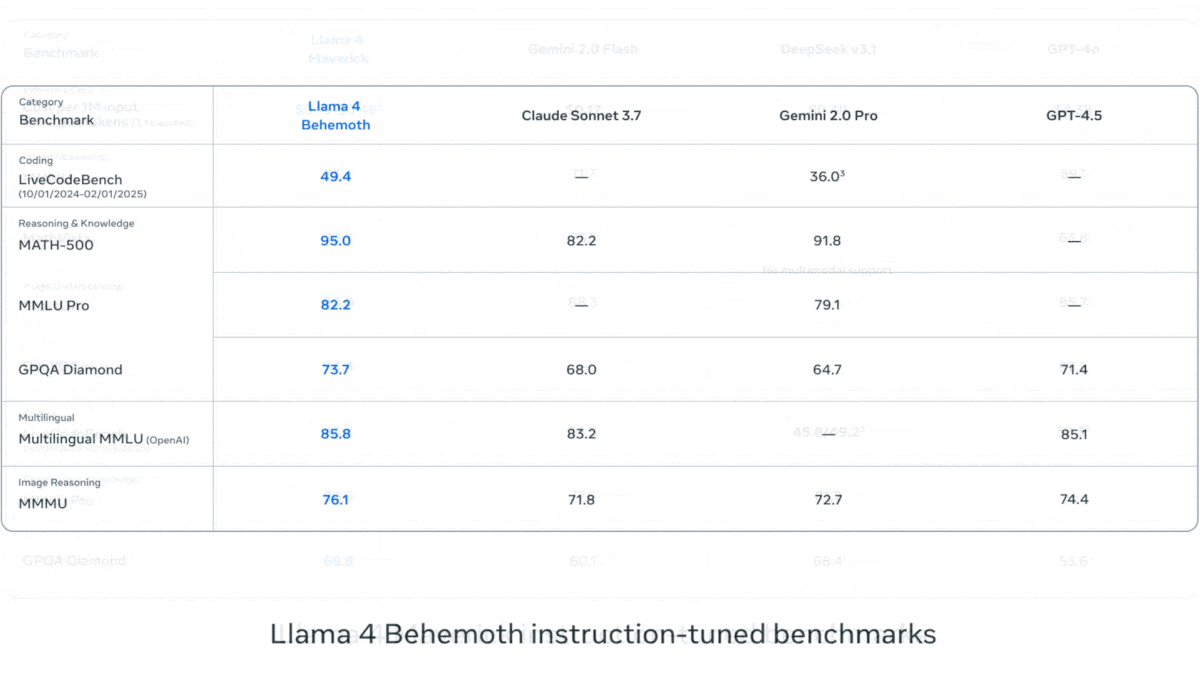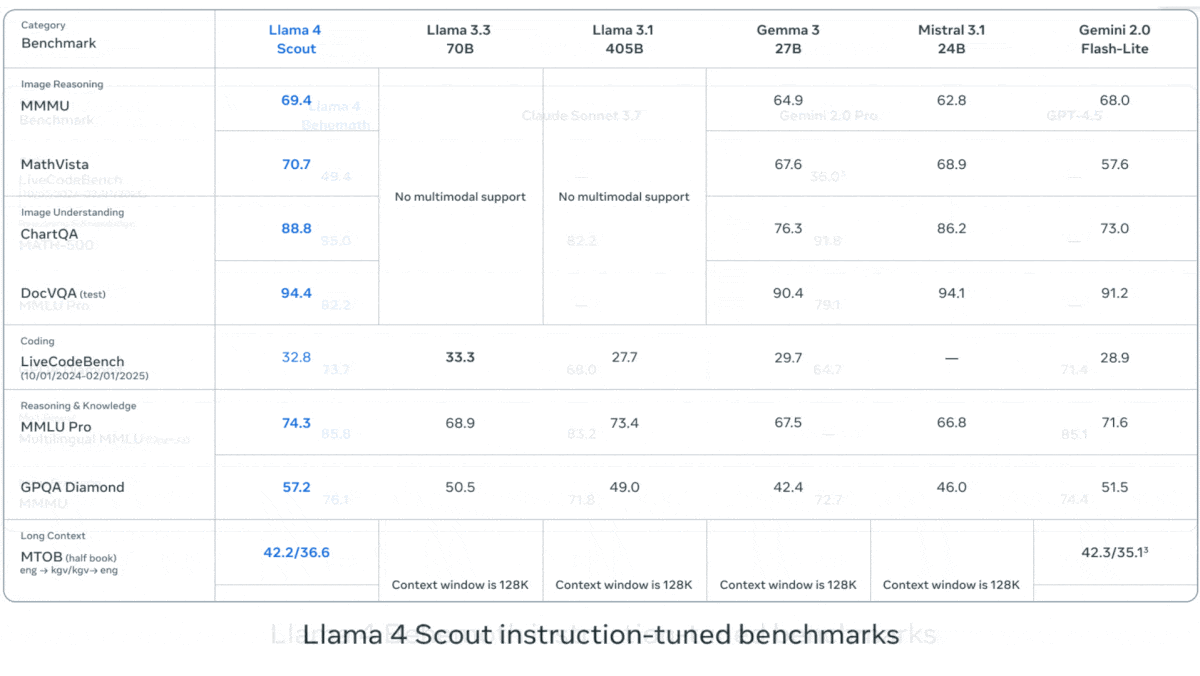
Meta发布Llama 4系列视觉语言模型: Meta推出了Llama 4系列的两个开源多模态模型:Llama 4 Scout (109B参数, 17B激活) 和 Llama 4 Maverick (400B参数, 17B激活),并预告了近2T参数的Llama 4 Behemoth。这些模型均采用MoE架构,支持文本、图像、视频输入和文本输出。Scout拥有高达10M token的上下文窗口(尽管实际有效性受质疑),Maverick则为1M。模型在图像、编码、知识和推理等多项基准测试中表现强劲,Scout优于Gemma 3 27B等,Maverick优于GPT-4o和Gemini 2.0 Flash,早期Behemoth版本则超越GPT-4.5等。模型的发布进一步推动了开源模型追赶闭源模型的步伐 (来源: DeepLearning.AI, X @AIatMeta)
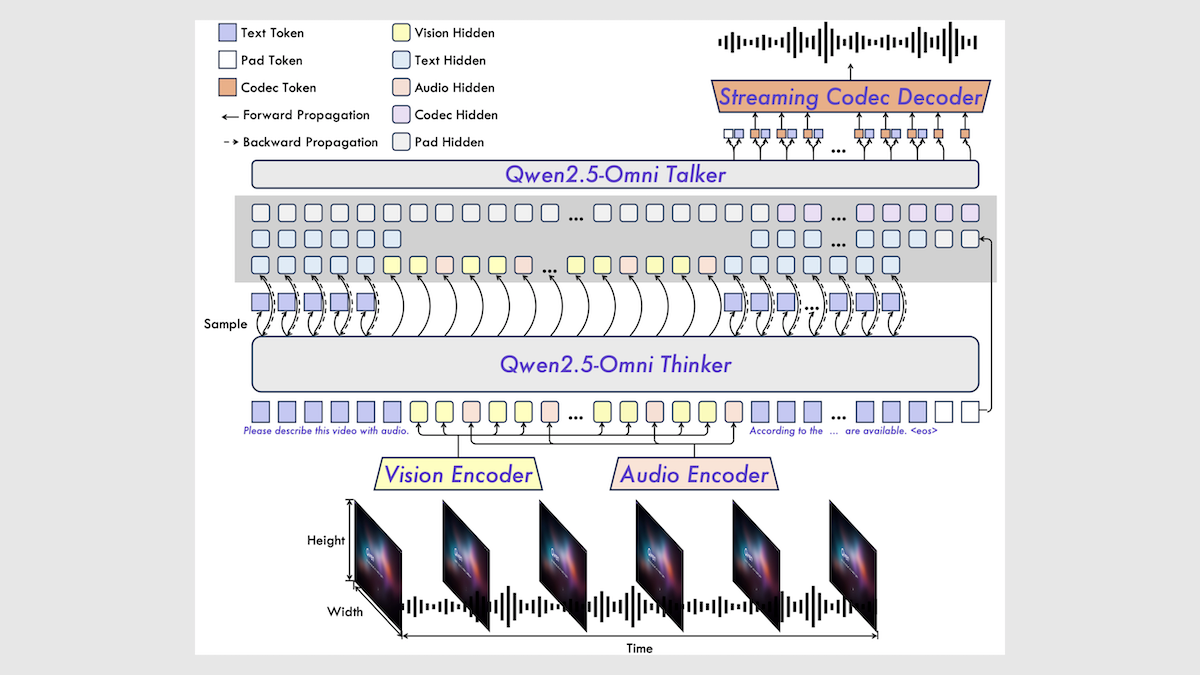
阿里巴巴发布Qwen2.5-Omni 7B多模态模型: 阿里巴巴发布了新的开源多模态模型Qwen2.5-Omni 7B,能够处理文本、图像、音频和视频输入,并生成文本和语音输出。该模型基于Qwen 2.5 7B文本模型、Qwen2.5-VL视觉编码器和Whisper-large-v3音频编码器构建,采用创新的Thinker-Talker架构。模型在多项基准测试中表现出色,尤其在音频到文本、图像到文本和视频到文本任务上达到SOTA水平,但在纯文本和文本到语音任务上表现稍逊。Qwen2.5-Omni的发布进一步丰富了高性能开源多模态模型的选择 (来源: DeepLearning.AI)
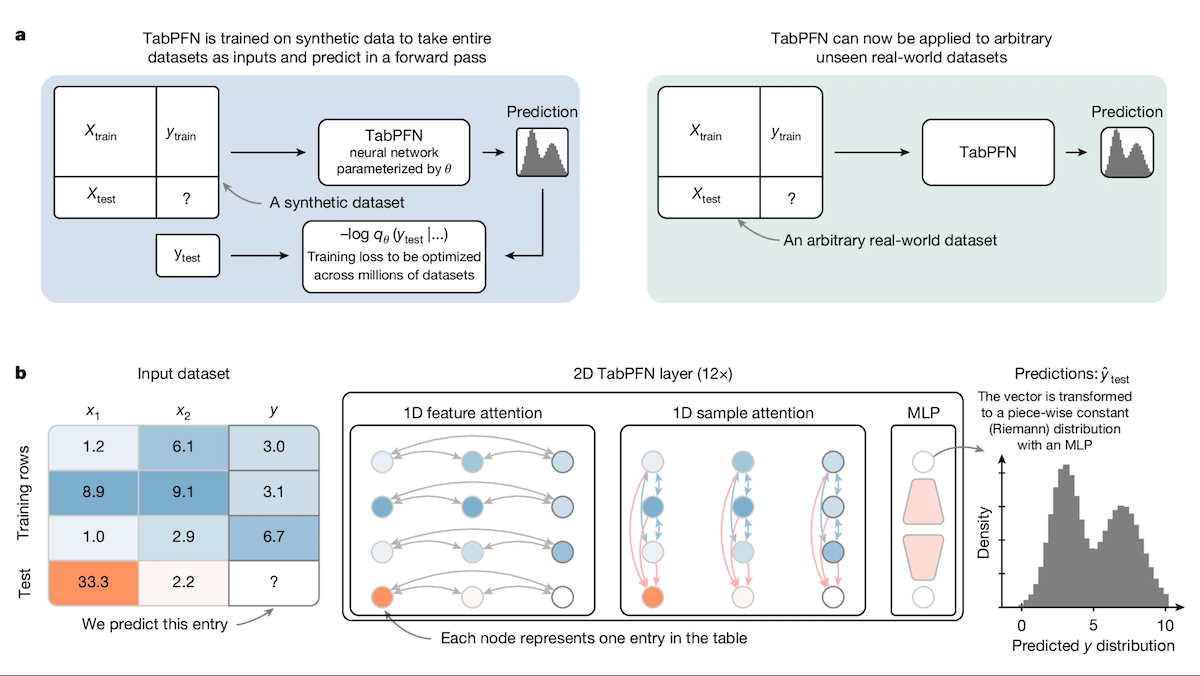
TabPFN:超越决策树的表格数据Transformer: 来自弗莱堡大学等机构的研究者推出了Tabular Prior-data Fitted Network (TabPFN),一种专为表格数据设计的Transformer模型。通过在1亿个合成数据集上进行预训练,TabPFN学会了识别跨数据集的模式,使其能够在新的表格数据上直接进行分类和回归预测,无需额外训练。实验表明,在AutoML和OpenML-CTR23基准测试中,TabPFN在分类(AUC)和回归(RMSE)任务上的表现均优于CatBoost、LightGBM和XGBoost等流行的梯度提升树方法,尽管推理速度较慢。这项工作为Transformer在表格数据处理领域开辟了新途径 (来源: DeepLearning.AI)
英特尔平台成为大模型一体机高性价比新选择: 随着DeepSeek等开源模型的普及,大模型一体机成为企业快速部署AI的热门选择。英特尔正通过其锐炫™ (Arc™) 游戏显卡(如A770)与至强® W处理器的组合,提供一种高性价比的硬件解决方案,将一体机价格从百万元级别降至十万元级别。该平台不仅支持DeepSeek R1,还兼容Qwen、Llama等模型。飞致云、超云、云尖等多家企业已基于该平台推出AI一体机产品或解决方案,用于知识库问答、智能客服、金融投顾、文档处理等场景,满足中小企业和特定部门的本地化AI推理需求 (来源: 量子位)
Google推出第七代TPU “Ironwood”: 在Google Cloud Next大会上,Google发布了其第七代TPU系统Ironwood,专为AI推理优化。相较于第一代Cloud TPU,Ironwood的性能提升了3600倍,能效提升了29倍。与第六代Trillium相比,Ironwood的每瓦性能提升了2倍,单芯片内存达到192GB(Trillium的6倍),数据访问速度提升4.5倍。Ironwood预计将于今年晚些时候推出,旨在满足日益增长的AI推理需求 (来源: X @demishassabis, X @JeffDean, Reddit r/LocalLLaMA)

Google DeepMind及Gemini模型将支持MCP协议: Google DeepMind的联合创始人Demis Hassabis及Gemini模型负责人Oriol Vinyals均表示,将支持模型上下文协议(MCP),并期待与MCP团队及行业伙伴共同发展该协议。MCP正迅速成为AI Agent时代的开放标准,旨在让不同模型能够理解统一的“服务语言”,方便调用外部工具和API。此举将使Gemini模型能更好地集成到日益增长的MCP生态中,构建更强大的Agent应用 (来源: X @demishassabis, X @OriolVinyalsML)
月之暗面发布KimiVL A3B多模态模型: 月之暗面(Moonshot AI)发布了KimiVL A3B Instruct & Thinking模型,这是一个开源(MIT许可证)的多模态大模型系列,具有128K长上下文能力。该系列包含一个MoE VLM和一个MoE Reasoning VLM,激活参数仅约3B。据称在视觉和数学基准测试上优于GPT-4o,在MathVision上达到36.8%,ScreenSpot-Pro上达到34.5%,OCRBench上达到867分,并在长上下文测试(MMLongBench-Doc 35.1%, LongVideoBench 64.5%)中表现出色。模型权重已在Hugging Face发布 (来源: X @huggingface)

Orpheus TTS 3B发布:多语言零样本语音克隆模型: 开源社区发布了Orpheus TTS 3B模型,这是一个30亿参数的多语言文本转语音模型。它支持零样本语音克隆,流式生成延迟约100毫秒,并允许引导情感和语调,生成类人语音。该模型采用Apache 2.0许可证,权重已在Hugging Face上提供,进一步推动了开源TTS技术的发展 (来源: X @huggingface)
OmniSVG发布:统一可缩放矢量图形生成模型: 一个名为OmniSVG的新模型被提出,旨在统一生成可缩放矢量图形(SVG)。该模型基于Qwen2.5-VL,并集成了SVG标记化器,能够接受文本和图像输入,并生成相应的SVG代码。项目网站展示了其强大的SVG生成效果。目前论文和数据集已发布,模型权重尚未公开 (来源: X @karminski3, Reddit r/LocalLLaMA)
Google Cloud Next 2025 聚焦AI: Google Cloud Next大会重点展示了AI领域的进展。发布了为推理优化的第七代TPU Ironwood;宣布Gemini 2.5 Pro是目前最智能的模型,并在Chatbot Arena登顶;将DeepMind、Google Research和Google Cloud的研究成果结合,向客户提供WeatherNext和AlphaFold等模型;允许企业在自有数据中心运行Gemini模型;并宣布与Nvidia合作,将Gemini模型通过Blackwell和机密计算带到本地部署 (来源: X @GoogleDeepMind, X @GoogleDeepMind, Reddit r/artificial, X @nvidia)
2025年AI趋势预测: 综合多方观点,2025年AI的关键趋势包括:生成式AI的持续发展与应用深化、AI伦理与负责任AI的重要性提升、边缘AI的普及、AI在特定行业(如医疗、金融、供应链)的加速落地、多模态AI能力的增强、AI Agent的自主性与挑战、AI对传统业务模式的颠覆、以及AI人才和技能多样性的需求增加 (来源: X @Ronald_vanLoon, X @Ronald_vanLoon, X @Ronald_vanLoon)

特斯拉工厂实现车辆自动驾驶转运: 特斯拉展示了其生产的汽车能够在工厂区域内自动从生产线下线行驶至装载区,无需人工干预。这体现了自动驾驶技术在受控环境(如工厂物流)中的应用潜力,是AI在汽车制造和自动化领域的一个进展实例 (来源: X @Ronald_vanLoon)
🧰 工具
Free-for-dev:开发者免费资源大全: GitHub上的ripienaar/free-for-dev项目是一个广受欢迎的资源列表,汇总了各类SaaS、PaaS、IaaS产品中对开发者(尤其是DevOps和基础设施开发者)有用的免费套餐。列表涵盖云服务、数据库、API、监控、CI/CD、代码托管、AI工具等众多类别,并明确要求服务提供的是长期免费层而非试用期,且注重安全(如限制TLS的服务不被接受)。该项目由社区驱动,持续更新,为开发者寻找和比较免费服务提供了极大便利 (来源: GitHub: ripienaar/free-for-dev)
Graphiti:构建实时AI知识图谱框架: getzep/graphiti 是一个用于构建和查询具有时序感知能力的知识图谱的Python框架,特别适用于需要处理动态环境信息的AI Agent。它能持续整合用户交互、结构化/非结构化数据,支持增量更新和精确的历史查询,无需完全重新计算图谱。Graphiti结合了语义嵌入、关键词搜索(BM25)和图遍历进行高效混合检索,并允许自定义实体定义。该框架是Zep记忆层的核心技术,现已开源 (来源: GitHub: getzep/graphiti)

WeChatMsg:微信聊天记录提取与AI助手训练工具: LC044/WeChatMsg 是一个用于提取Windows本地微信聊天记录(支持微信4.0)并将其导出为HTML、Word、Excel等格式的工具。它旨在帮助用户永久保存聊天记录,并能对记录进行分析生成年度报告。更进一步,该工具支持利用用户的聊天数据训练个性化的AI聊天助手,体现了“我的数据我做主”的理念。项目提供了图形用户界面和详细的使用说明 (来源: GitHub: LC044/WeChatMsg)
阿里云百炼上线全周期MCP服务,打造Agent工厂: 阿里云百炼平台正式上线了模型上下文协议(MCP)服务的完整平台能力,覆盖服务注册、云托管、Agent调用和流程组合的全生命周期。开发者可以直接使用平台托管的高德地图、Notion等官方或第三方MCP服务,或通过简单配置(无需管理服务器)将自有API注册为MCP服务。这旨在降低Agent开发门槛,使开发者能快速构建和部署具备调用外部工具能力的AI Agent,推动大模型在真实场景的应用落地。该服务被视为阿里AI商业化的重要一步 (来源: 微信公众号 – AINLPer, 量子位)
Hugging Face与Cloudflare合作提供免费WebRTC基础设施: Hugging Face与Cloudflare合作,通过FastRTC为AI开发者提供全球范围的企业级WebRTC基础设施。开发者可以使用Hugging Face Token免费传输10GB数据,用于构建实时的语音和视频AI应用。官方提供了一个Llama 4语音聊天演示作为示例,展示了该合作带来的便利性 (来源: X @huggingface)
Google AI Studio迎来UI重大更新: Google AI Studio(原MakerSuite)的用户界面进行了第一阶段的重新设计,带来了更现代的外观和体验。此次更新旨在为未来几个月内将推出的更多开发者平台功能奠定基础。新UI与Gemini应用的风格更加统一,并增加了专门的开发者后台,用于API管理和支付管理。此次更新预示着平台功能的扩展,可能包括对新模型(如Veo 2)的接入 (来源: X @JeffDean, X @op7418)

LlamaIndex推出视觉引用功能: LlamaIndex发布新教程,展示如何利用LlamaParse中的布局Agent功能,实现Agent回答的视觉引用。这意味着生成的答案不仅可以追溯到文本来源,还能直接映射到源文档(如PDF)中对应的视觉区域(通过边界框精确定位)。这增强了Agent回答的可解释性和溯源能力,尤其适用于处理包含图表、表格等视觉元素的文档 (来源: X @jerryjliu0)

LangGraph推出无代码GUI构建器: LangGraph现在提供了一个无代码的图形用户界面(GUI)构建器,用于设计Agent的架构。用户可以通过拖拽等可视化操作来规划Agent的工作流程和节点连接,然后可以一键生成Python或TypeScript代码。这降低了构建复杂Agent应用的门槛,方便快速原型设计和开发 (来源: X @LangChainAI)
Perplexity更新股票图表功能: Perplexity对其股票图表功能进行了更新,现在能够实时反映当日股价变化,而不是将时间轴拉伸填满整个图表。这项改进虽然基础,但提升了金融信息展示的即时性和实用性 (来源: X @AravSrinivas, X @AravSrinivas)

OLMoTrace:连接LLM输出与训练数据的工具: Allen Institute for AI (AI2) 推出了OLMoTrace工具,能够将OLMo模型的输出实时映射回其对应的训练数据来源(在4T token数据中实现秒级匹配)。这有助于理解模型行为、提高透明度,并改进后训练数据。该工具旨在帮助研究人员和开发者更好地理解大型语言模型的内部工作机制和知识来源 (来源: X @natolambert)
llama.cpp合并对Qwen3模型的支持: 流行的本地LLM推理框架llama.cpp已合并对即将发布的Qwen3系列模型的支持,包括基础模型和MoE版本。这意味着一旦Qwen3模型发布,用户将能第一时间在llama.cpp生态中使用GGUF格式的量化模型,方便在本地设备上运行 (来源: X @karminski3, Reddit r/LocalLLaMA)

KTransformers框架支持Llama 4模型: 国产AI推理框架KTransformers(以支持CPU+GPU混合推理,特别是MoE模型卸载而闻名)已在其开发分支增加对Meta Llama 4系列模型的实验性支持。根据文档,运行Q4量化的Llama-4-Scout (109B) 需要约65GB内存和10GB显存,Llama-4-Maverick (402B) 需要约270GB内存和12GB显存。在4090+双Xeon 4配置下,单批次推理速度可达32 tokens/s。这为在有限显存下运行大型MoE模型提供了可能 (来源: X @karminski3, Reddit r/LocalLLaMA)
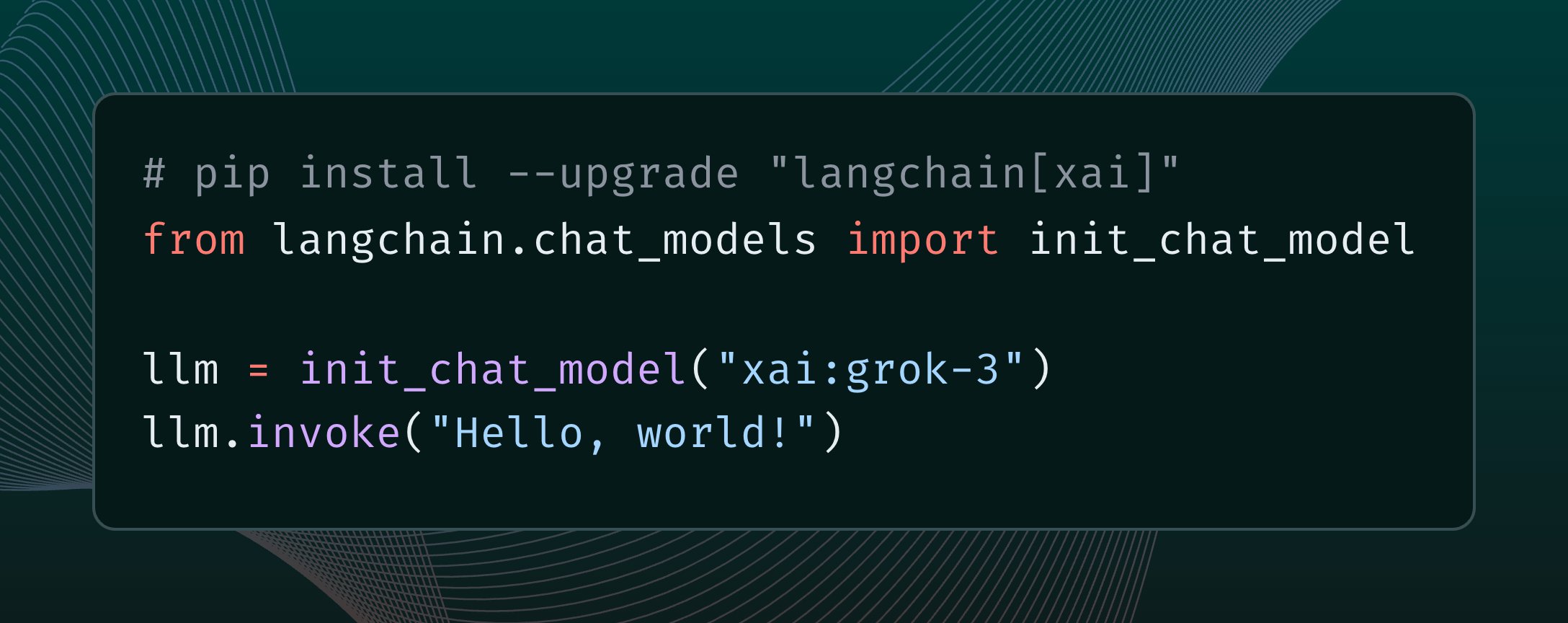
LangChain集成xAI Grok 3模型: LangChain宣布已集成xAI最新发布的Grok 3模型。用户现在可以通过LangChain框架调用Grok 3,利用其强大的能力构建应用程序 (来源: X @LangChainAI)
n8n云服务免费部署教程: 介绍了如何使用Hugging Face Spaces和Supabase免费部署开源工作流自动化平台n8n,并获得支持HTTPS的公共域名访问。这使得用户能够利用n8n的全部功能(包括需要回调URL的节点),而无需自行购买服务器和配置域名及SSL证书。该方法利用Supabase的免费数据库解决了Hugging Face Space休眠导致的数据丢失问题 (来源: 微信公众号 – 袋鼠帝AI客栈)
OpenWebUI 插件更新:上下文计数器与自适应记忆: 社区开发者为OpenWebUI发布/更新了两个插件:1) Enhanced Context Counter v3,提供详细的Token使用、成本跟踪和性能指标仪表盘,支持多种模型和自定义校准。2) Adaptive Memory v2,通过LLM动态提取、存储和注入用户特定的信息(事实、偏好、目标等),实现个性化、持久且自适应的对话记忆,且完全在本地运行,无需外部依赖 (来源: Reddit r/OpenWebUI, Reddit r/OpenWebUI)
QuickVoice MCP:让Claude打电话: 社区开发者创建了一个名为QuickVoice的MCP(模型上下文协议)工具,可以让Claude 3.7 Sonnet等支持MCP的模型拨打和处理真实的电话。用户可以通过自然语言指令(如“打电话给医生预约”)让AI完成通话任务,包括导航IVR菜单。项目已在GitHub开源 (来源: Reddit r/ClaudeAI)

RPG Dice Roller for OpenWebUI: 社区为OpenWebUI开发了一个RPG骰子投掷工具插件,方便在进行角色扮演游戏对话时获得真实的随机结果 (来源: Reddit r/OpenWebUI)
📚 学习
Girafe-ai 开源机器学习课程: GitHub上的girafe-ai/ml-course项目提供了girafe-ai机器学习课程第一学期的教学材料,包括Naive Bayes、kNN、线性回归/分类、SVM、PCA、决策树、集成学习、梯度提升以及深度学习入门等内容。提供了讲座视频录像、PPT课件和作业。是学习机器学习基础知识的宝贵资源 (来源: GitHub: girafe-ai/ml-course)
中科大与华为诺亚提出CMO框架优化芯片逻辑综合: 中国科学技术大学王杰教授团队与华为诺亚方舟实验室合作,在ICLR 2025上发表论文,提出基于神经符号函数挖掘的高效逻辑优化方法CMO。该框架利用图神经网络(GNN)指导蒙特卡洛树搜索(MCTS),生成轻量级、可解释且泛化能力强的符号打分函数,用于剪枝逻辑优化算子(如Mfs2)中的无效节点转换。实验表明,CMO能将关键算子运行效率提升最高2.5倍,同时保持优化质量,已应用于华为自研EMU逻辑综合工具 (来源: 量子位)
上海AI Lab提出MaskGaussian高斯剪枝新方法: 上海AI Lab的研究团队在CVPR 2025上提出MaskGaussian方法,用于优化3D高斯泼溅(3D Gaussian Splatting)。该方法通过将可学习的掩码分布融入光栅化过程,首次实现了同时为被使用和未被使用的高斯点保留梯度,从而能够在剪枝大量冗余高斯点的同时,最大限度地保持重建质量。实验在多个数据集上剪枝了超过60%的高斯点,性能损失可忽略,同时提高了训练速度并减少了内存占用 (来源: 量子位)
Qwen2.5-Omni技术报告解读: Reddit用户分享了对阿里巴巴Qwen2.5-Omni技术报告的详细解读笔记。报告介绍了该模型的Thinker-Talker架构、多模态(文本、图像、音频、视频)输入处理方式(包括创新的TMRoPE位置编码用于音视频对齐)、流式语音生成机制、训练流程(预训练+后训练RL)等。这份笔记为了解该前沿多模态模型的内部工作原理提供了有价值的参考 (来源: Reddit r/LocalLLaMA)
麦肯锡发布企业扩展生成式AI操作指南: 麦肯锡发布了一份面向数据领导者的操作指南,探讨了如何在企业中规模化应用生成式AI。报告可能涵盖了策略制定、技术选型、人才培养、风险管理等方面,为企业在实践中落地和扩展GenAI提供指导 (来源: X @Ronald_vanLoon)

AI Agent学习入门指南: Khulood_Almani分享了关于如何开始学习AI Agent的资源或步骤,可能包括了学习路径、关键概念、推荐工具或平台等,为想要入门AI Agent领域的学习者提供指引 (来源: X @Ronald_vanLoon)

视觉位置识别中的重排序技术研究: arXiv上的一篇论文探讨了在视觉位置识别(Visual Place Recognition, VPR)任务中,重排序(Re-Ranking)技术是否仍然有效。研究可能分析了现有重排序方法的优劣,并评估了其在现代VPR系统中的作用和必要性 (来源: Reddit r/deeplearning, Reddit r/MachineLearning)
《AI 2027》研究报告探讨ASI风险与未来: 一份题为《AI 2027》的研究报告探讨了到2027年可能出现的AI发展情景,特别是自动化AI研发可能导致超人AI(ASI)的出现。报告分析了ASI带来的潜在风险,如目标不对齐导致人类失权、权力集中、国际军备竞赛加剧安全风险、模型被窃取以及公众认知滞后等问题,并探讨了地缘政治可能出现的战争、协议或屈服等结局 (来源: Reddit r/artificial)
神经网络激活对齐研究: 一篇发表在OpenReview上的论文探讨了神经网络中表征对齐(representational alignment)发生的原因。研究发现对齐并非源于单个神经元,而是与激活函数的工作方式有关,并提出了Spotlight Resonance Method来解释这一现象,提供了实验结果支持 (来源: Reddit r/deeplearning)
💼 商业
阿里国际重点布局AI以求突破: 面对跨境电商行业的激烈竞争和全球贸易变局,阿里国际数字商业集团将AI视为核心战略,大力投入以寻求增长和效率提升。公司启动“Bravo 102”全球AI人才培养计划,并在校招中将80%岗位设为AI相关。AI应用已覆盖B2B(AI搜索引擎Accio、“生意助手”AI Agent)和B2C(Aidge平台提供虚拟试衣、AI客服等)。尽管阿里国际营收增长显著(2024Q4同比增长32%),但投入导致亏损扩大。AI被视为阿里国际走出低价竞争、实现高附加值转型和精细化运营的关键驱动力 (来源: 36氪)
OpenAI前核心成员加入Mira Murati新公司: GPT系列开山一作Alec Radford和OpenAI前首席研究官Bob McGrew已加入由OpenAI前CTO Mira Murati创立的新AI公司Thinking Machines Lab,担任顾问。Radford对GPT系列模型的诞生起到了关键作用,而McGrew则深度参与了GPT-3/4及o1模型的研发。Thinking Machines Lab创始团队成员中有大量(至少19名)来自OpenAI。该公司目标是普及AI应用,据传计划融资10亿美元,估值90亿美元,显示出市场对顶尖AI人才领导的初创公司的高度期待 (来源: 新智元)
公募基金关注医药企业AI+医疗业务: 近期,中国多家公募基金密集调研医药上市公司,AI在医疗领域的应用成为关注焦点。海尔生物介绍了其物联网血液网、疫苗网中的AI应用,以及通过AI提升公卫场景(如疫苗预约)效率的进展。海正药业则表示已引入DeepSeek-R1模型,并与AI制药公司合作,希望利用AI赋能新药研发全流程。康缘药业也表示正建设AI+多组学驱动的中药创新药发现平台。这表明AI技术在医药研发、运营和患者服务等环节的应用正受到资本市场的高度关注 (来源: 创业板观察)
OpenAI启动Pioneers计划深化行业合作: OpenAI推出了Pioneers计划,旨在与有雄心的公司建立合作伙伴关系,共同构建先进的AI产品。该计划将专注于两个方面:一是密集微调模型,使其在特定领域的高价值任务上表现超越通用模型;二是构建更优质的真实世界评估(evals),使行业能够更好地衡量模型在领域相关任务上的性能。这表明OpenAI正寻求将其技术更深入地应用于特定行业,并通过合作方式提升模型在垂直领域的实用性和评测标准 (来源: X @sama)
Nvidia与Google Cloud合作推动本地化Gemini部署: Nvidia和Google Cloud宣布合作,将支持Google Gemini模型在企业本地(on-prem)运行。该方案将结合Nvidia Blackwell GPU平台和机密计算(Confidential Computing)技术,旨在为企业提供高性能且安全的本地化AI部署选项。此举满足了部分企业对于数据隐私、安全合规以及特定性能的需求,使他们能在自己的基础设施上运行强大的Gemini模型 (来源: X @nvidia)
Google允许企业在自有数据中心运行Gemini模型: Google Cloud宣布,将允许企业客户在自己的数据中心运行其Gemini AI模型。这一举措旨在满足企业对数据主权、安全性和定制化部署的需求,使他们能够在本地环境中利用Gemini的强大能力,而无需将敏感数据传输到云端。这为企业提供了更大的灵活性和控制力,特别是在金融、医疗等受严格监管的行业 (来源: Reddit r/artificial)
Nvidia CEO黄仁勋淡化关税影响,AI服务器或可豁免: 面对美国可能实施的新关税政策,Nvidia CEO黄仁勋表示影响有限,并暗示大部分Nvidia的AI服务器可能获得豁免。这可能得益于其产品的战略重要性或特定的贸易分类。此消息对依赖Nvidia硬件的AI行业来说是一个积极信号,有助于缓解对供应链成本上升的担忧 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)
🌟 社区
Reddit热议:Qwen3模型何时发布?: Reddit社区和X平台(原Twitter)用户热议阿里巴巴Qwen3模型的发布时间。虽然有用户分享了阿里AI峰会的海报并猜测即将发布,但随后有消息确认该峰会并未发布Qwen3。同时,llama.cpp合并Qwen3支持的消息也加剧了社区的期待。这反映了开源社区对国产大模型进展的高度关注和期待 (来源: X @karminski3, Reddit r/LocalLLaMA)

推理数据集竞赛启动: Bespoke Labs联合Hugging Face和Together AI发起了推理数据集竞赛。旨在鼓励社区创建更多样化、更贴近现实世界复杂性的推理数据集,特别是在金融、医学等多领域推理方面,以推动下一代LLM的发展。现有数据集(如OpenThoughts-114k)已在模型训练中发挥重要作用,竞赛希望能进一步拓展数据集的边界 (来源: X @huggingface)

LiveCodeBench编程基准更新,o3-mini领先: LiveCodeBench编程能力排行榜时隔8个月更新,OpenAI的o3-mini (high) 和 o3-mini (medium) 分列第一和第二,Google Gemini 2.5 Pro位居第三。该榜单引发社区讨论,部分用户对Claude 3.5/3.7排名相对靠后表示质疑,认为与实际使用体验不符,反映出不同基准测试与用户主观感受之间可能存在的差异 (来源: Reddit r/LocalLLaMA)

社区讨论Claude Code:强大但昂贵且有Bug: Reddit用户讨论Anthropic的Claude Code,普遍认为其上下文感知能力强,编码效果好,甚至感觉“像来自未来”。但缺点是价格昂贵(有用户称日耗达30美元),且存在一些bug(如claude.md文件会话后丢失,输出语法错误等)。用户期待未来能力更强且价格更低的替代品出现 (来源: Reddit r/ClaudeAI)
用户分享Mistral-Small-3.1-24B量化模型: Ollama社区用户分享了Mistral-Small-3.1-24B模型的Q5_K_M和Q6_K量化版本(GGUF格式),弥补了官方仓库仅提供Q4和Q8的不足。这些量化模型使用Ollama客户端制作,支持视觉功能,并提供了在RTX 4090上的上下文长度参考 (来源: Reddit r/LocalLLaMA)

社区寻求AI视频升频工具: Reddit用户询问是否存在能将240p低分辨率视频提升至1080p/60fps的AI工具,希望能修复老旧音乐视频。评论中提到了Ai4Video和Cutout.Pro等工具,但也有观点认为从极低分辨率提升效果有限,可能更像重新生成而非修复 (来源: Reddit r/artificial)
用户反馈Claude 3.5 Sonnet疑似被偷偷更新: Reddit开发者用户根据使用体验(如模型开始使用表情符号、回答风格变化)怀疑Anthropic在未告知的情况下,用优化或蒸馏过的版本替换了原版的Claude 3.5 Sonnet模型,导致性能或行为发生改变。该用户认为原版3.5在编码方面优于3.7,但近期的体验下降。这引发了社区关于模型版本透明度和一致性的讨论 (来源: Reddit r/ClaudeAI)
Anthropic报告引发学生使用AI作弊讨论: Anthropic发布教育报告,通过分析百万级匿名学生对话,发现学生可能使用Claude进行学术不端行为。该报告引发社区讨论,观点包括:学生作弊现象一直存在,AI只是新工具;教育体系需要适应AI时代,评估方式应转变;部分用户对Anthropic分析用户对话数据的隐私表示担忧 (来源: Reddit r/ClaudeAI)

用户讨论LLM/Agent应用监控方法: Reddit机器学习社区用户发起讨论,询问大家如何监控LLM应用或AI Agent的性能与成本,例如追踪Token使用量、延迟、错误率、Prompt版本变化等。讨论旨在了解社区在LLMOps方面的实践方法和痛点,是自建方案还是使用特定工具 (来源: Reddit r/MachineLearning)
💡 其他
Andrew Ng评论美国关税政策对AI的影响: 吴恩达在其周报The Batch中表达了对美国新关税政策的担忧,认为其不仅损害盟友关系和全球经济,也会通过限制硬件(如服务器、冷却、网络设备、电力设施部件)进口和提高消费电子产品价格,间接阻碍美国本土的AI发展和应用普及。他指出,虽然关税可能轻微刺激机器人和自动化需求,但这并非解决制造业问题的有效途径,且AI在机器人领域的进展相对较慢。他呼吁AI社区加强国际合作和思想交流 (来源: DeepLearning.AI)

AI在电信领域的突破与陷阱: 文章探讨了人工智能在电信行业的应用潜力,如网络优化、客户服务、预测性维护等,同时也指出了可能存在的挑战和陷阱,例如数据隐私、算法偏见、集成复杂性以及对现有工作流程的影响 (来源: X @Ronald_vanLoon)
技能多样性对AI投资回报率至关重要: Antonio Grasso强调,要成功实现人工智能项目的投资回报(ROI),团队需要具备多样化的技能组合,这可能包括数据科学、工程、领域知识、伦理、业务分析等多方面能力 (来源: X @Ronald_vanLoon)

AI驱动的供应链引领可持续发展: Nicochan33的文章指出,利用AI优化供应链管理(如路线规划、库存管理、需求预测)不仅能提高效率,还能通过减少浪费、降低能耗等方式,推动可持续发展目标的实现 (来源: X @Ronald_vanLoon)

AI Agent的自主性、保障措施与陷阱: VentureBeat的文章探讨了AI Agent发展的关键议题,包括如何平衡其自主能力、设计有效的安全保障措施以防止滥用或意外后果,以及在部署和使用过程中可能遇到的陷阱 (来源: X @Ronald_vanLoon)

AI被视为对“枯燥”业务的最大威胁: 福布斯的文章认为,人工智能对那些传统上被认为是“枯燥”或流程化的业务构成了最大的颠覆性威胁,因为这些业务通常包含大量可通过AI自动化或优化的任务 (来源: X @Ronald_vanLoon)

医疗算法中的偏见问题及新指南: Fortune文章关注AI在医疗领域长期存在的偏见问题,并探讨新的指导方针是否能推动解决这一问题,确保AI医疗应用的公平性和准确性 (来源: X @Ronald_vanLoon)

AI在劳动力技能提升和疾病识别中的作用: 福布斯的文章探讨了AI在两个方面的积极作用:一是帮助提升现有劳动力的技能以适应未来工作需求,二是在疾病早期识别和诊断方面提供支持 (来源: X @Ronald_vanLoon)

AI数字座席将重新定义工作: VentureBeat的文章讨论了AI Agent(数字座席)如何融入工作场所,不仅是作为工具,更可能改变工作本身的定义、流程和人机协作方式 (来源: X @Ronald_vanLoon)

AI Agent的隐形、自主与可被攻击性困境: VentureBeat的文章深入探讨了AI Agent带来的新困境:它们的运行可能对用户“隐形”,具备高度自主性,同时也可能被恶意利用或攻击,这对安全和伦理提出了新的挑战 (来源: X @Ronald_vanLoon)

特朗普威胁对台积电征收100%关税: 美国前总统特朗普表示,他曾告知台积电(TSMC),如果不在美国建厂,将对其产品征收100%的关税。此言论反映了地缘政治对半导体供应链的持续影响,可能对依赖台积电芯片的AI硬件供应产生潜在风险 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial)

Google Gemini 2.5 Pro被指缺少关键安全报告: Fortune报道称,Google最新发布的Gemini 2.5 Pro模型缺少一份关键的安全报告(Model Card),这可能违反了Google此前向美国政府和国际峰会所做的AI安全承诺。此事引发了对大型科技公司在模型发布透明度和安全承诺履行方面的关注 (来源: Reddit r/artificial)

利用AI进行车牌识别: Rackenzik的文章介绍了基于深度学习的车牌检测与识别技术,探讨了其中的挑战,如图像模糊、不同国家/地区的车牌样式差异以及各种真实世界条件下的识别困难 (来源: Reddit r/deeplearning)
