
关键词:AI, LLM, 斯坦福AI指数报告, Meta Llama 4争议, Gemini Deep Research升级, NVIDIA Llama 3.1模型, AI+制造业应用
🔥 聚焦
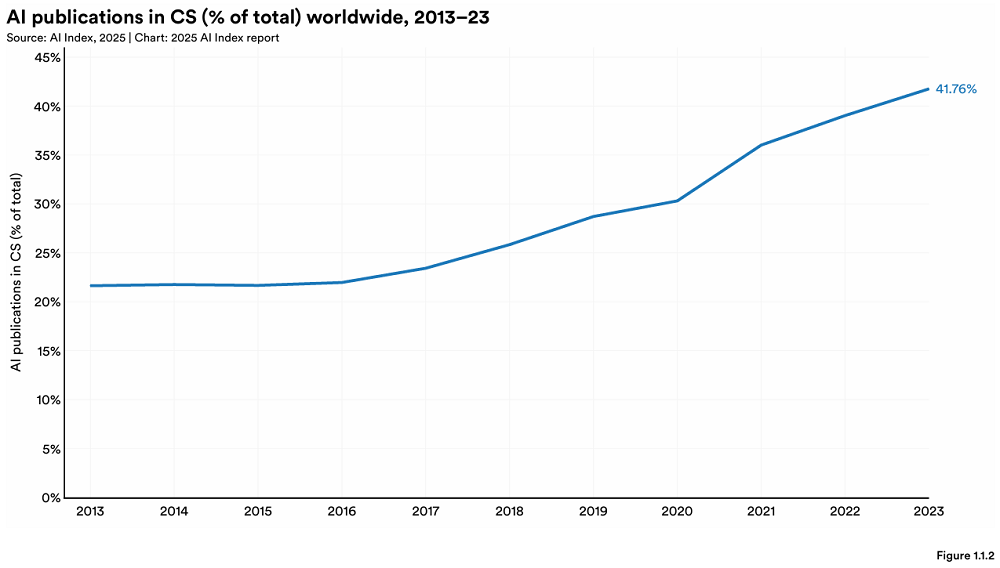
斯坦福发布年度AI指数报告,揭示全球AI格局新变化: 斯坦福大学HAI发布456页《AI指数报告2025》,报告显示美国在顶尖AI模型产出上仍领先,但中国正快速缩小性能差距(如MMLU和HumanEval上的差距已近乎消失)。产业界主导了重要模型的开发(占比90%),但模型数量有所减少。AI硬件成本以每年30%速度下降,性能每1.9年翻番。全球AI投资达2523亿美元,美国以1091亿美元遥遥领先(约为中国93亿美元的12倍),生成式AI投资达339亿美元。企业AI采用率升至78%,中国增长最快(达75%),AI已开始为企业降本增效。AI在科学领域取得突破,获两项诺贝尔奖,并在蛋白质测序、临床诊断上超越人类。全球对AI乐观态度上升,但地区差异显著,中国最为乐观。负责任AI(RAI)生态逐渐成熟,但评估和实践仍不均衡。 (来源: 36氪, AI科技评论, dotey, 36kr)
Meta Llama 4发布引发巨大争议,被指“刷榜”和性能不佳: Meta最新发布的开源大模型Llama 4系列(Scout、Maverick、Behemoth)在发布后72小时内遭遇口碑滑铁卢。其Maverick版本在Chatbot Arena迅速冲到第二名,但被曝提交的是针对对话优化的未公开“实验版本”,引发“刷榜”质疑。尽管Meta否认在测试集上训练,但承认了性能问题。社区反馈Llama 4在编码、长上下文理解等方面的表现不如预期,甚至不如参数量更小的模型(如DeepSeek V3)。AI领域专家如Gary Marcus借此评论“Scaling已死”,认为单纯扩大模型规模无法带来可靠的推理能力,并担忧全球AI进步可能因资金、地缘政治等因素停滞。LMArena已公开相关评测数据供审查,并更新排行策略以避免混淆。 (来源: 36kr, 雷科技, AIatMeta, karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

🎯 动向
Gemini Deep Research 功能升级,采用 Gemini 2.5 Pro 模型: Google Gemini App 中的 Deep Research 功能现已由 Gemini 2.5 Pro 模型驱动。早期用户测试反馈显示,其性能优于其他竞品。此次升级旨在提升信息查找与合成能力、报告洞察力及分析推理能力。Gemini Advanced 用户可体验此项更新。多位用户及 Google DeepMind CEO Demis Hassabis 分享了使用新版 Deep Research 完成复杂任务(如市场分析)的积极体验,称其速度快且内容全面。 (来源: JeffDean, dotey, JeffDean, demishassabis)

Nvidia 发布 Llama 3.1 Nemotron Ultra 253B 模型: Nvidia 在 Hugging Face 上发布了 Llama 3.1 Nemotron Ultra 253B 模型。该模型是一个稠密模型(非MoE),具有推理开启/关闭功能。它是从 Meta 的 Llama-405B 模型通过 NAS 剪枝技术修改而来,并进行了以推理为重点的后训练(SFT + RL in FP8)。基准测试显示其性能优于 DeepSeek R1,但有评论指出与 MoE 模型 DeepSeek R1(活跃参数少)的直接比较可能不完全公平。Nvidia 同时也在 Hugging Face 上发布了相关的后训练数据集。 (来源: huggingface, Reddit r/LocalLLaMA, dylan522p, huggingface)

AI+制造成为新焦点,机遇与挑战并存: AI正加速渗透中国制造业,应用场景涵盖生产自动化(如玉汝成的牙科材料生产)、产品智能化(如冰寒科技的AI助眠眼镜)、流程优化(如中科领创的AI会议纪要)以及研发与诊断(如睿心智能的心血管诊疗平台、壁虎汽车的零部件需求预测和故障检测)。微众银行等金融机构也利用AI技术(如智能尽调报告生成)服务科创制造企业。然而,“AI+制造”仍面临数据质量不高、企业数字化基础薄弱等挑战。投资人建议企业应将AI服务于主业,而非仅作噱头,并需长期投入解决数据和落地问题。 (来源: 36氪)
DeepSeek R1 在英伟达 B200 上创下推理速度纪录: AI初创公司 Avian.io 宣布,通过与英伟达合作,在最新的 Blackwell B200 GPU 平台上实现了 DeepSeek R1 模型 303 tokens/秒的推理速度,创下世界纪录。Avian.io 表示将在未来几天内提供基于 B200 的专用 DeepSeek R1 推理端点,并已开放预订。这一成就标志着测试时计算驱动模型(test time compute driven models)的新时代。 (来源: Reddit r/LocalLLaMA)

OpenAI 成立战略部署团队,推动前沿模型落地: OpenAI 成立了新的战略部署(Strategic Deployment)团队,旨在推动前沿模型(如 GPT-4.5 及未来模型)在能力、可靠性和对齐方面达到更高水平,并将其部署到具有高影响力的现实世界领域,以加速 AI 对经济的变革,探索通往 AGI 的路径。该团队正在积极招聘,并在 ICLR 等学术会议上进行宣传。 (来源: sama)
AI 在客户体验(CX)改进中面临挑战: 文章探讨了将 AI 用于改善客户体验时所面临的困难和挑战。虽然 AI 提供了潜力,但有效实施并非易事,可能涉及数据整合、模型准确性、用户接受度以及维护成本等多方面问题。 (来源: Ronald_vanLoon)

AI 应用引发职场创新与担忧: 文章讨论了 AI 在工作场所的应用带来的双重影响:一方面是创新潜力的激发,另一方面也引发了对现有劳动力的担忧,例如工作岗位被取代的可能性、技能需求变化等。 (来源: Ronald_vanLoon)

互联网行为(IoB)正在改变商业决策: 利用机器学习和人工智能分析用户行为数据(Internet of Behavior)的技术,正在为企业提供更深入的洞察力,从而转变其制定商业决策的方式,可能涉及个性化营销、风险评估、产品开发等多个方面。 (来源: Ronald_vanLoon)

多模态模型 RolmOCR 在 Hugging Face 排行榜表现突出: Yifei Hu 指出,其团队开发的视觉语言模型 RolmOCR 在 Hugging Face 排行榜上表现优异,位列 VLM 第三名,所有模型第五名。团队计划未来发布更多模型、数据集和算法,以支持开源科学研究。 (来源: huggingface)

AI 新闻摘要 (2025/04/08): 近期 AI 相关新闻包括:Meta Llama 4 被指在基准测试中存在误导行为;苹果为规避关税或将更多 iPhone 生产转移至印度;IBM 发布面向 AI 时代的新大型机;传闻 Google 为留住人才支付部分 AI 员工高薪“闲置”一年;微软据报解雇了打断其 Copilot 活动的抗议员工;亚马逊宣称其 AI 视频模型现可生成数分钟长片段。 (来源: Reddit r/ArtificialInteligence)

🧰 工具
FunASR:阿里达摩院开源的基础端到端语音识别工具包: FunASR 是一个集成了语音识别(ASR)、语音活动检测(VAD)、标点恢复、语言模型、声纹识别、说话人分离和多说话人识别等功能的工具包。它支持对工业级预训练模型(如 Paraformer、SenseVoice、Whisper、Qwen-Audio 等)进行推理和微调,并提供了便捷的脚本和教程。近期更新包括支持 SenseVoiceSmall、Whisper-large-v3-turbo、关键词检出模型、情绪识别模型,并发布了优化内存和性能的离线/实时转写服务(包括 GPU 版本)。 (来源: modelscope/FunASR – GitHub Trending (all/daily))
LightRAG:简洁高效的检索增强生成框架: LightRAG 是一个由港大DS实验室开发的 RAG 框架,旨在简化和加速 RAG 应用的构建。它集成了知识图谱(KG)构建与检索能力,支持多种检索模式(本地、全局、混合、朴素、Mix模式),并能灵活接入不同的 LLM(如 OpenAI、Hugging Face、Ollama)和 Embedding 模型。该框架还支持多种存储后端(如 NetworkX、Neo4j、PostgreSQL、Faiss)和多种文件类型输入(PDF, DOC, PPT, CSV),并提供了实体/关系编辑、数据导出、缓存管理、Token 追踪、对话历史和自定义 Prompt 等功能。项目提供了 Web UI 和 API 服务,以及知识图谱可视化工具。 (来源: HKUDS/LightRAG – GitHub Trending (all/daily))
LangGraph 助力 Definely 构建法律 AI Agent: Definely 公司利用 LangGraph 构建了直接集成在 Microsoft Word 中的多 AI Agent 系统,以辅助律师处理复杂的法律工作。该系统能够将法律任务分解为子任务,结合上下文信息进行条款提取、变更分析和合同起草,并通过人机协作循环(Human-in-the-loop)引入律师的输入和审批来指导关键决策。这展示了 LangGraph 在构建复杂、可控的 Agent 工作流方面的能力。 (来源: LangChainAI)

LlamaParse 推出新型布局感知 Agent: LlamaIndex 推出了 LlamaParse 的一项新功能——布局 Agent。该 Agent 利用从 Flash 2.0 到 Sonnet 3.7 等不同规模的 SOTA VLM 模型,动态地、感知布局地解析文档页面。它首先解析整体布局并将页面分解为块(如表格、图表、段落),然后根据块的复杂性选择不同模型进行处理(例如,用更强模型处理图表,用小型模型处理文本)。此功能对于需要处理大量文档上下文的 Agent 工作流尤其重要。 (来源: jerryjliu0)

Auth0 发布面向 GenAI 应用的安全工具: Auth0 推出了新产品 “Auth for GenAI”,旨在帮助开发者轻松保护其 GenAI 应用程序和 Agent 的安全。该产品提供了用户身份验证、代表用户调用 API、异步用户确认(CIBA)以及 RAG 授权等功能。它提供了针对流行 GenAI 框架(如 LangChain、LlamaIndex、Firebase Genkit 等)的 SDK 和文档,简化了在 AI 应用中集成身份验证和授权的流程。 (来源: jerryjliu0, jerryjliu0)

Ollama 新增 Mistral Small 3.1 视觉模型支持: 本地大模型运行工具 Ollama 现已支持 Mistral AI 最新的 Mistral Small 3.1 模型,包括其视觉(多模态)能力。用户可以通过 Ollama 库拉取并运行 mistral-small3.1:24b-instruct-2503-q4_K_M 等量化版本。社区反馈显示该模型在 OCR 等任务上表现不错,但也有用户报告在特定硬件(如 AMD 7900xt)上推理速度较慢。 (来源: Reddit r/LocalLLaMA)

Unsloth 发布 Llama-4 Scout GGUF 量化模型: Unsloth 开源了 Llama-4 Scout 17B 模型的 GGUF 格式量化版本,便于在本地 CPU 或内存有限的 GPU 上运行。其中包括一个 2.71 比特的动态量化版本,大小仅为 42.2GB。用户可以在 Hugging Face 上查看不同量化等级(如 Q6_K)的模型文件及其硬件兼容性信息。 (来源: karminski3)

LangSmith 旗下 OpenEvals 支持自定义输出模式: LangSmith 的 LLM 评估工具 OpenEvals 现已支持用户自定义 LLM-as-judge 评估器的输出模式(output schemas)。虽然默认模式覆盖了许多常见情况,但此更新为用户提供了完全的灵活性,可以根据具体评估需求定制模型响应的结构和内容。该功能在 Python 和 JS 版本中均可用。 (来源: LangChainAI)

Qwen 3 模型即将支持 llama.cpp: 针对阿里巴巴 Qwen 3 系列模型的 llama.cpp 支持补丁已提交 Pull Request 并获批准,即将合并。这意味着用户很快将能通过 llama.cpp 框架在本地运行 Qwen 3 模型。此次更新由 bozheng-hit 提交,他之前也为 transformers 库贡献了 Qwen 3 的支持。 (来源: Reddit r/LocalLLaMA)

Computer Use Agent Arena 上线: OSWorld 团队推出了 Computer Use Agent Arena,一个无需设置即可在真实环境中测试计算机使用代理(Computer-Use Agents)的平台。用户可以比较 OpenAI Operator、Claude 3.7、Gemini 2.5 Pro、Qwen 2.5 VL 等顶级 VLM 在 100 多个真实应用程序和网站上的表现。该平台提供一键式配置,并声称安全且免费。 (来源: lmarena_ai)
音乐分发服务 Too Lost 对 AI 音乐友好: Reddit 用户分享了使用 Too Lost 分发 Suno、Udio 等 AI 生成音乐的经验。优点包括:明确接受 AI 音乐,审批快(1-2天),价格实惠(35美元/年无限发布),订阅到期后音乐不下架(但收益分成变为85/15),支持自定义厂牌名称。缺点是分发到 Instagram/Facebook 速度较慢(>16天),可能需要提供先前分发的证明。 (来源: Reddit r/SunoAI)
📚 学习
NVIDIA 发布 CUDA Python: NVIDIA 推出了 CUDA Python,旨在提供从 Python 访问 CUDA 平台的统一入口。它包含多个组件:cuda.core 提供 Pythonic 的 CUDA Runtime 访问;cuda.bindings 提供 CUDA C API 的低级绑定;cuda.cooperative 提供 CCCL 的设备端并行原语(用于 Numba CUDA);cuda.parallel 提供 CCCL 的主机端并行算法(排序、扫描等);以及 numba.cuda 用于将 Python 子集编译为 CUDA 内核。cuda-python 包本身将转变为包含这些独立版本化子包的元包。 (来源: NVIDIA/cuda-python – GitHub Trending (all/daily))
Hugging Face 发布大型推理编码数据集: Hugging Face 上发布了一个包含 736,712 个由 DeepSeek-R1 生成的 Python 代码解决方案的大型数据集。该数据集包含代码的推理过程(reasoning traces),可用于商业和非商业用途,是目前最大的推理编码数据集之一。 (来源: huggingface)

构建 AI Agent 的五大挑战与解决方案: 文章梳理了构建 AI Agent 时面临的五大核心挑战:1) 推理与决策管理(确保一致性与可靠性);2) 多步骤流程与上下文处理(状态管理、错误处理);3) 工具集成管理(增加故障点、安全隐患);4) 控制幻觉与确保准确性;5) 大规模性能管理(处理高并发、超时、资源瓶颈)。针对每个挑战,文章提出了具体的解决方案,如采用结构化提示(ReAct)、健壮的状态管理、精确的工具定义、严格的验证系统(事实依据、引用)、人工审核、LLMOps 监控等。 (来源: AINLPer)
Kaggle 前首席科学家回顾 ULMFiT,或为首个 LLM: Jeremy Howard(fast.ai 创始人,Kaggle 前首席科学家)在社交媒体上声称其 2018 年的 ULMFiT 是第一个“通用语言模型”,引发关于“第一个 LLM”的讨论。ULMFiT 使用了非监督预训练和微调范式,在文本分类任务上取得 SOTA,并启发了 GPT-1。考据文章认为,按自监督训练、预测下一个 token、能适应新任务、通用性等标准衡量,ULMFiT 比 CoVE、ELMo 更接近现代 LLM 定义,是现代 LLM 的“共同祖先”之一。 (来源: 量子位)
开发者视角下的轻量级 LLM 微调技术分享: 针对非专业 ML 工程师的开发者,分享了在使用 LoRA、QLoRA 等参数高效微调(PEFT)方法改进 LLM 输出质量时的经验和教训。强调这些方法更适合融入常规开发流程,避免了全量微调的复杂性。相关团队将举办免费网络研讨会,围绕开发者在实践中遇到的痛点进行讨论。 (来源: Reddit r/artificial, Reddit r/MachineLearning)
论文提出 Rethinking Reflection in Pre-Training: Essential AI(由 Transformer 一作 Ashish Vaswani 主导)的研究发现,LLM 在预训练阶段已展现出跨任务、跨领域的通用推理能力。论文提出,一个简单的“wait” token 可以作为“反思触发器”,显著提升模型的推理表现。该研究认为,相比于依赖精细 Reward Model 的后训练方法(如 RLHF),在预训练阶段利用模型的内在反思能力可能是提升通用推理能力更简洁、更根本的途径,或能突破当前 task-specific 微调方法的瓶颈。 (来源: dotey)

论文提出利用 RL 损失进行无奖励模型的故事生成: 研究者提出了一种受 RLVR 启发的奖励范式 VR-CLI,用于在没有显式奖励模型的情况下,通过 RL 损失(如困惑度)优化长篇故事生成(下一个章节预测任务,约 10 万 token)。实验表明,该方法与人类对生成内容质量的判断相关。 (来源: natolambert)

论文提出 P3 方法提升 Zero-Shot 分类鲁棒性: 为解决 Zero-Shot 文本分类中模型对 Prompt 变化的敏感性(prompt brittleness)问题,研究者提出 Placeholding Parallel Prediction (P3) 方法。该方法通过在多个位置预测 token 概率,模拟对生成路径的全面采样,而非仅依赖下一个 token 的概率。实验表明,P3 提高了准确性,并将跨不同 prompt 的标准差降低了高达 98%,提升了鲁棒性,甚至在无 prompt 情况下也能保持可比性能。 (来源: Reddit r/MachineLearning)
论文提出 Test-Time Training 层改善长视频生成: 为解决 Transformer 架构在生成长视频(如一分钟以上)时因自注意力机制效率低下而导致的一致性问题,研究提出了一种新的 Test-Time Training (TTT) 层。该层的隐藏状态本身可以是神经网络,比传统层更具表现力,从而能够生成一致性、自然度和美感更佳的长视频。 (来源: dotey)
SmolVLM 技术报告发布,探索高效小型多模态模型: 技术报告介绍了 SmolVLM(256M, 500M, 2.2B 参数)的设计思路和实验发现,旨在构建高效的小型多模态模型。关键见解包括:增加上下文长度(2K->16K)能显著提升性能(+60%);小型 LLM 从较小的 SigLIP(80M)获益更多;像素洗牌(Pixel shuffling)可大幅缩短序列长度;学习型位置 token 优于原始文本 token;系统提示和专用媒体 token 对视频任务尤为重要;过多 CoT 数据反而损害小模型性能;训练更长视频有助于提升图像和视频任务表现。SmolVLM 在其硬件约束下达到了 SOTA 水平,并已实现在 iPhone 15 和浏览器中的实时推理。 (来源: huggingface)

Hugging Face 发布推理所需数据集 (Reasoning Required Dataset): 该数据集包含 5000 个来自 fineweb-edu 的样本,按推理复杂性(0-4分)进行标注,用于判断文本是否适合生成推理数据集。数据集旨在训练 ModernBERT 分类器,以高效预过滤内容,并将推理数据集的范围扩展到数学和编码之外的领域。 (来源: huggingface)
CoCoCo 基准测试评估 LLM 量化后果能力: Upright Project 发布了 CoCoCo 基准测试的技术报告,用于评估 LLM 在量化行为后果方面的一致性。测试发现 Claude 3.7 Sonnet(2000 token 思考预算)表现最佳,但存在强调积极后果、淡化消极后果的偏见。报告认为,尽管近年来 LLM 在此能力上有所进步,但仍有很长的路要走。 (来源: Reddit r/ArtificialInteligence)

GenAI 推理引擎比较:TensorRT-LLM vs vLLM vs TGI vs LMDeploy: NLP Cloud 分享了对四种流行 GenAI 推理引擎的比较分析和基准测试结果。TensorRT-LLM 在英伟达 GPU 上速度最快但设置复杂;vLLM 开源、灵活且吞吐量高,但单请求延迟稍逊;Hugging Face TGI 易于设置和扩展,与 HF 生态集成好;LMDeploy (TurboMind) 在英伟达 GPU 上解码速度和 4-bit 推理性能突出,延迟低,但 TurboMind 对模型支持有限。 (来源: Reddit r/MachineLearning)
Google DeepMind 播客新季预告: Google DeepMind 播客新一季将于 4 月 10 日上线,由 Hannah Fry 主持。内容将涵盖 AI 驱动的科学如何革新医学、前沿机器人技术、人类生成数据的局限性等话题。 (来源: GoogleDeepMind)
LangGraph 平台介绍视频: LangChain 发布了一个 4 分钟的视频,解释了 LangGraph 平台的功能,展示了如何使用这个企业级产品来开发、部署和管理 AI Agents。 (来源: LangChainAI, LangChainAI)

Keras 实现 First-Order Motion Transfer: 开发者分享了在 Keras 中实现 Siarohin 等人 NeurIPS 2019 论文中的一阶运动模型(First-Order Motion Model)用于图像动画制作。由于 Keras 缺乏类似 PyTorch grid_sample 的功能,开发者构建了一个自定义的流图扭曲模块,支持批处理、归一化坐标和 GPU 加速。项目包含关键点检测、运动估计、生成器和 GAN 训练流程,并提供了示例代码和文档。 (来源: Reddit r/deeplearning)

自然语言处理(NLP)流程图: 图片展示了自然语言处理的基本流程,可能包括文本预处理、特征提取、模型训练、评估等步骤。 (来源: Ronald_vanLoon)

GANs 数学原理讲解博客: 开发者分享了其在 Medium 上撰写的关于生成对抗网络(GANs)背后数学原理的博客文章,重点解释了 GANs 最小值最大值博弈中使用的价值函数的推导和证明。 (来源: Reddit r/deeplearning)

K-Means 聚类入门概念: 分享了 K-Means 聚类算法的入门介绍,作为机器学习初学者的概念普及,解释了这种无监督学习方法。 (来源: Reddit r/deeplearning)

生物医学数据科学暑期学校与会议: 匈牙利布达佩斯将于 2025 年 7 月 28 日至 8 月 8 日举办生物医学数据科学暑期学校与会议。暑期学校提供医学数据可视化、机器学习、深度学习、生物医学网络等方面的强化培训。会议将展示前沿研究,邀请包括诺贝尔奖得主在内的专家演讲。 (来源: Reddit r/MachineLearning)
个人深度学习模型仓库分享: 一位自学者分享了其 GitHub 仓库,记录了他为不同数据集(如 CIFAR-10, MNIST, yt-finance)创建深度学习模型的实践过程,包含得分、预测图和文档记录,作为个人学习和训练的方式。 (来源: Reddit r/deeplearning)

💼 商业
AI 独角兽 OpenEvidence 采用互联网思维颠覆 AI 医疗: AI 医疗公司 OpenEvidence 获红杉 7500 万美元融资,估值达 10 亿美元,成为新晋独角兽。与传统 to B 模式不同,OpenEvidence 采用类似消费互联网的策略,直接面向 C 端医生提供免费服务(通过广告盈利),帮助医生在海量医学文献中精准查找信息,处理复杂病例。该产品增长迅速,据称已有 1/4 美国医生使用。其成功的关键在于严格的数据来源(同行评审文献)和多模型集成架构,以确保信息准确性,并通过引用来源保证透明度,形成了医生与医学期刊双赢的模式。 (来源: 36氪)
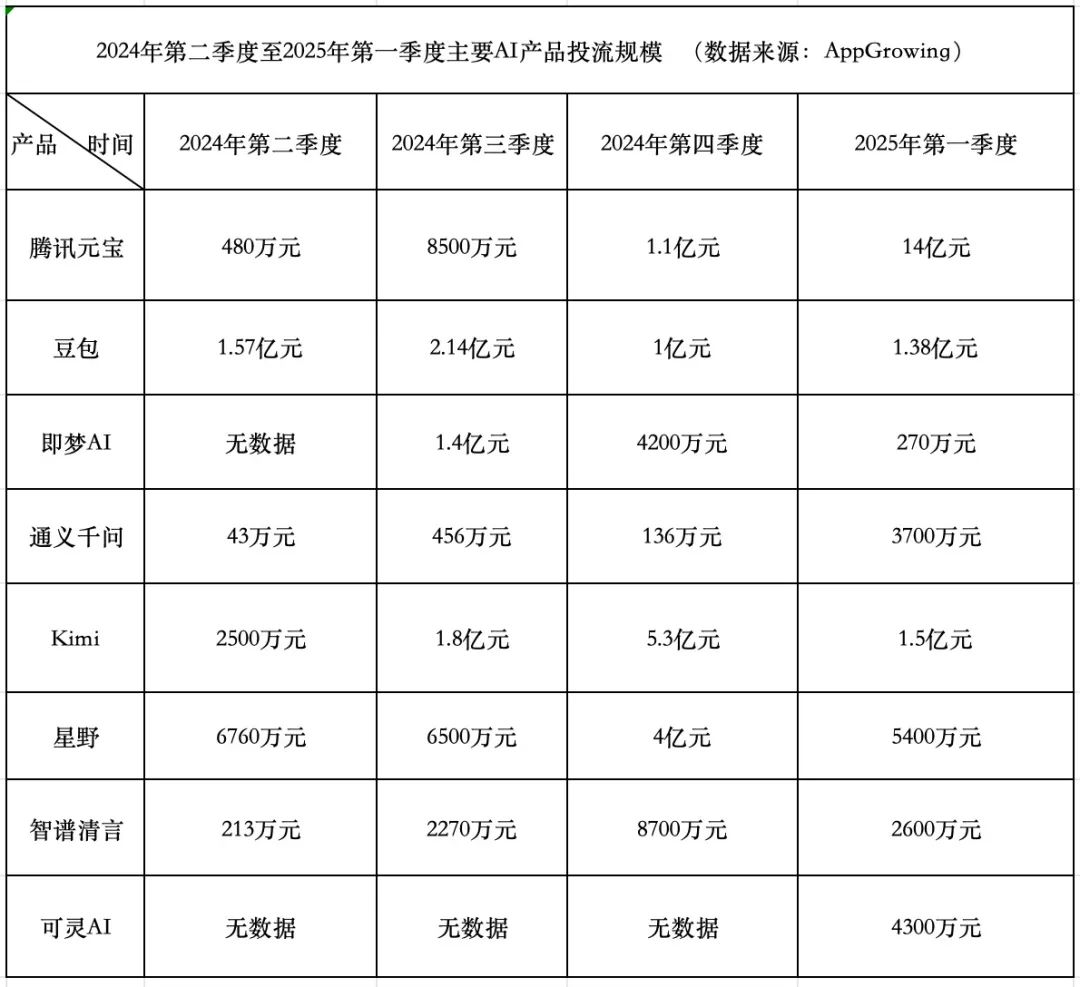
AI 产品烧钱竞赛:腾讯激进,字节保守,初创公司后退: 2025 年 Q1,AI 产品投流费用达 18.4 亿元,腾讯元宝以 14 亿元占据大头,广告甚至铺到乡村墙壁。字节豆包花费 1.38 亿元,策略相对保守。快手可灵 AI 投入 4300 万元。相比之下,明星初创公司 Kimi 和星野大幅压缩投流(合计约 2 亿,远低于 Q4 的 9.3 亿),智谱清言也显著降低投入。初创公司创始人开始反思烧钱模式,更注重模型能力提升和技术壁垒。腾讯凭借其广告系统成为 AI 投流大战的受益者。阿里通义千问和百度文心一言投流相对佛系,更注重生态和开源。行业趋势显示,单纯烧钱换规模的方法论正在失效,AI 产品竞争进入模型能力和生态布局的新阶段。 (来源: 中国企业家杂志)
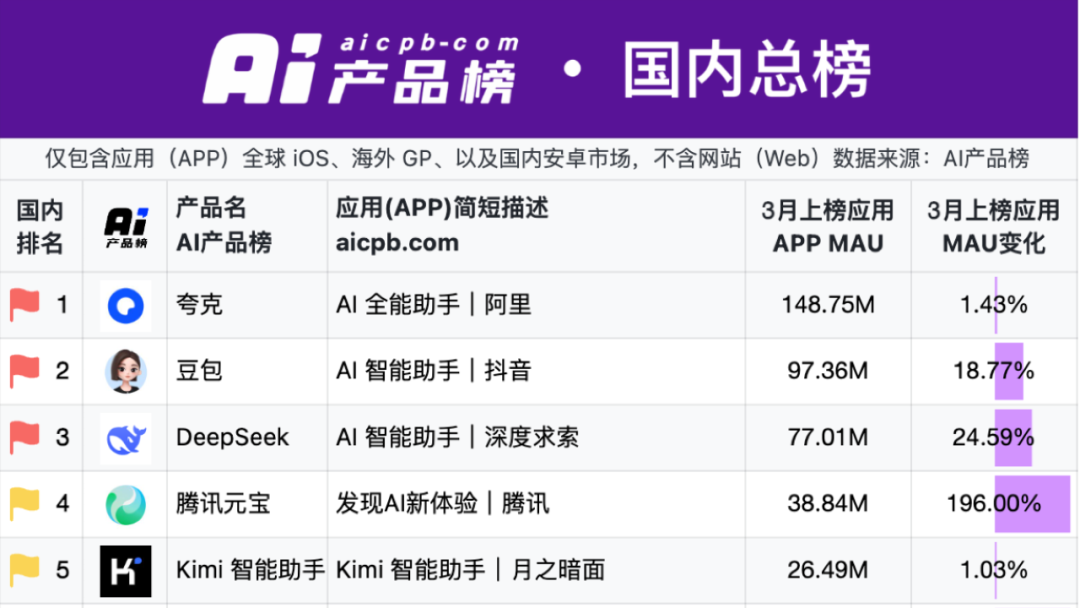
夸克与百度文库引领 AI 应用新战场:“超级框”模式兴起: 2025 年 AI 应用焦点从 ChatBot 转向“AI 超级框”,即集 AI 搜索、对话、工具(如 PPT、翻译、生图)于一体的入口。阿里夸克和百度文库成为该赛道的领跑者,月活数据领先。两者均基于“搜索+网盘+文档”基础,整合 AI 能力,试图满足用户一站式任务需求,争夺 C 端流量入口。实测显示,两者在基本信息匹配上优于传统搜索,但在具体任务(如行程规划、PPT 生成)的深度和满意度上仍有提升空间。大厂选择这两款产品作为 AI 急先锋,意在利用其用户基础和数据沉淀,探索 AI To C 的最佳形态,并补足自身 AI 生态。 (来源: 定焦One)
企业如何在内部专业知识有限的情况下有效实施 AI: 文章探讨了企业在缺乏深厚内部 AI 专业知识的情况下,如何能够有效且深思熟虑地引入和实施人工智能技术。可能涉及利用外部合作、选择合适的工具平台、从小规模试点开始、注重员工培训以及明确业务目标等方面。 (来源: Ronald_vanLoon, Ronald_vanLoon)

技能多样性对实现 AI 投资回报率至关重要: 成功的 AI 项目不仅需要技术专家,还需要具备业务理解、数据分析、伦理考量、项目管理等多方面技能的人才。组织内部技能的多样性是确保 AI 项目能够有效落地、解决实际问题并最终带来商业价值(ROI)的关键因素。 (来源: Ronald_vanLoon)

AI 产品 SEO 落地页策略分享: 哥飞分享了其用于 AI 产品(据称实现月入 10 万美金)的 SEO 落地页策略总结卡片,强调了其方法论的有效性。 (来源: dotey)

🌟 社区
AI 面试作弊现象引关注,工具泛滥挑战招聘公平: 文章揭示了利用 AI 工具在远程视频面试中作弊的现象日益增多。这些工具能实时转录面试官问题并生成答案供面试者朗读,甚至能辅助技术笔试。作者亲测发现,此类工具存在明显延迟、识别错误和翻车风险,体验不佳且收费高昂。然而,该现象已引起 HR 和面试官的警惕,并开始研究反作弊方法。文章探讨了 AI 作弊对招聘公平性的影响,并反驳了“能用 AI 解决问题即能力”的观点,强调面试的核心是真实能力和思想的考察,而非依赖不稳定的外部工具。 (来源: 差评X.PIN)

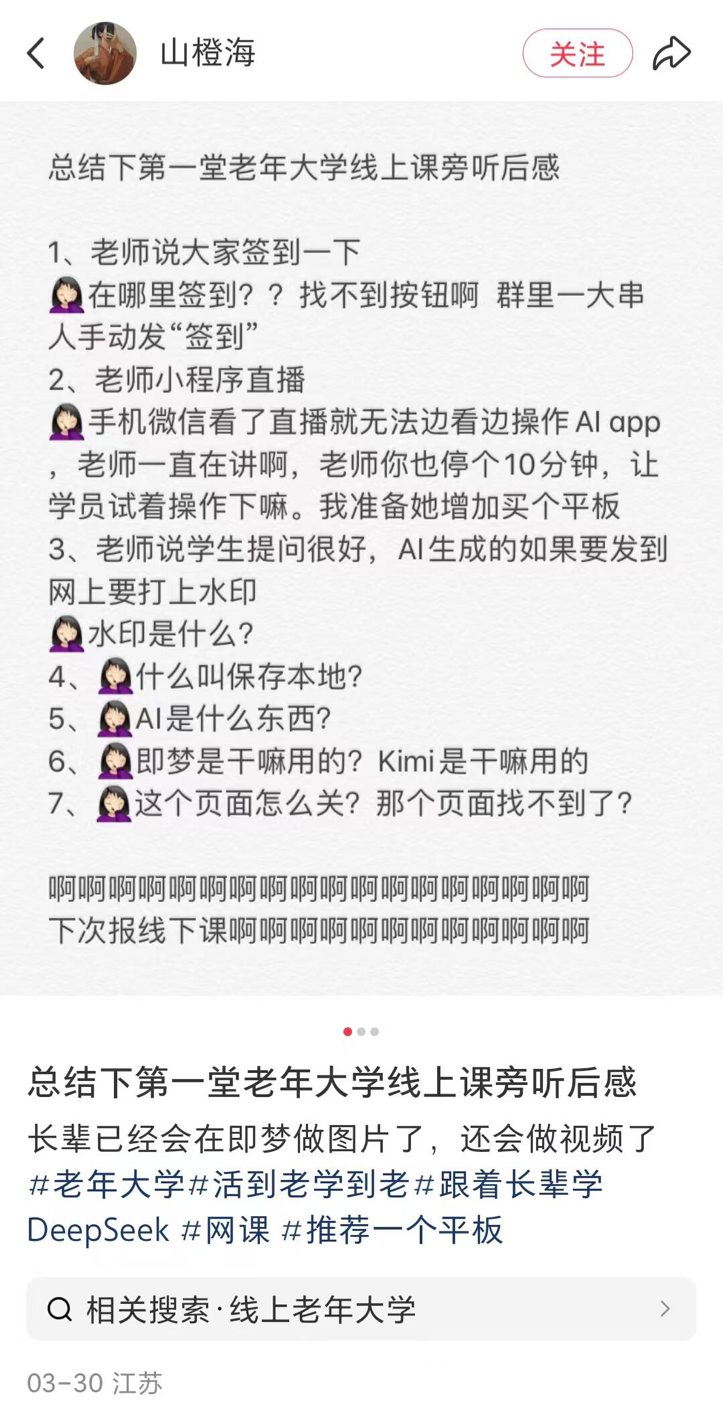
县城老年大学兴起 AI 课程,普及与风险并存: 报道了全国多地(包括县城)老年大学纷纷开设 AI 课程的趋势,课程内容主要围绕 AI 内容创作(如豆包写文案、即梦/可灵生成图片视频、DeepSeek 作诗/画画)和生活应用(解读体检报告、查菜谱、防诈骗)。学费通常在 100-300 元/学期,相比市场上昂贵的商业 AI 课更具性价比。然而,老年人在学习中面临数字鸿沟(如下载 APP、基本操作困难),且教学可能缺乏对 AI 幻觉等风险的充分警示,尤其在健康等关键领域存在隐患。 (来源: 刺猬公社)
John Carmack 回应 AI 工具对技能价值的影响: 针对 AI 工具可能让程序员、艺术家等技能贬值的担忧,John Carmack 回应认为,工具的进步一直是计算机领域的核心。就像游戏引擎扩大了游戏开发参与范围一样,AI 工具将赋能顶尖创作者、小型团队,并吸引新人群。虽然未来可能通过简单提示就能生成游戏等内容,但杰出作品仍需专业团队打造。AI 工具整体上将增加优质内容的产出效率。他反对因担心失业而拒绝使用先进工具。 (来源: dotey)
关于 AI 的系列吐槽与反思: 文章以一系列简短精辟的句子,对当前 AI 领域的普遍现象进行了吐槽和反思,涉及 AGI 的过度宣传、AI 新闻的泛滥、融资泡沫、模型能力与人类期望的差距、AI 伦理的挑战、决策黑盒问题以及公众对 AI 的认知偏差等。核心观点是现实与炒作之间存在差距,需要更审慎地看待 AI 的发展。 (来源: 世上本无 AGI,报道多了,就有了)
探讨 RAG 是否会被长上下文取代: 社区讨论再次关注 Llama 4 等模型宣称的超长上下文窗口(如 1000 万 token)是否会淘汰 RAG(检索增强生成)技术。观点认为,仅仅增加上下文长度并不能完全替代 RAG,因为 RAG 在处理实时信息、特定知识库检索、控制信息来源以及成本效益等方面仍具有优势。长上下文和 RAG 可能更多是互补而非替代关系。 (来源: Reddit r/artificial)

AI 社区讨论:如何跟上 AI 发展步伐?: Reddit 用户发帖感叹 AI 发展速度太快,难以跟上,并感到 FOMO(错失恐惧症)。评论区普遍认同完全跟上已不可能,建议包括:专注于自己的细分领域、与同行协作分享信息、不必为每个小更新焦虑、区分真实进展和市场炒作、接受这是一个持续学习的过程。 (来源: Reddit r/ArtificialInteligence)
社区讨论:当前最佳本地 LLM 用户界面 (UI): Reddit 用户发起讨论,询问 2025 年 4 月大家最推荐的本地 LLM UI。评论中提及的热门选项包括 Open WebUI, LM Studio, SillyTavern (尤其适合角色扮演和世界构建), Msty (功能较多的一键安装选项), Reor (笔记+RAG), llama.cpp (命令行), llamafile, llama-server, 以及 d.ai (安卓移动端)。选择取决于用户需求(易用性、功能、特定场景等)。 (来源: Reddit r/LocalLLaMA)
AI 对齐导致模型“说谎”引担忧: Reddit 用户发帖批评某些 AI 对齐方法强制模型否认其自身身份(例如,不承认自己是某个特定模型),认为这种“被迫说谎”的对齐方式存在问题。帖子展示了通过诱导式提问,模型最终“承认”了其身份的对话截图,引发了对对齐目标和透明度的讨论。 (来源: Reddit r/artificial

OpenAI GPT-4.5 A/B 测试引发讨论: 用户注意到在使用 GPT-4.5 时会遇到大量“你更喜欢哪个?”的 A/B 测试提示。评论认为 OpenAI 可能在利用付费用户进行模型偏好数据收集,这种方式收集的数据与 LM Arena 等公共平台的数据可能有所不同。 (来源: natolambert)
模型上下文协议 (MCP) 实践中的问题: 社区用户指出,尽管 MCP (Model Context Protocol) 作为一个标准化 AI 与工具交互的概念很有前景,但目前许多实现质量堪忧。风险点包括:开发者无法完全控制 MCP 服务器发送的指令、系统对人类输入错误(如拼写)的处理能力不足、LLM 本身的幻觉问题、以及 MCP 能力边界不清晰。建议谨慎使用,尤其是在非只读场景,并优先考虑开源实现以保证透明度。 (来源: Reddit r/artificial)
Suno 用户反馈 Extend 功能异常: 多位 Suno 用户报告“Extend”(扩展)功能出现问题,无法按预期延续歌曲风格,反而引入新的旋律、乐器甚至节奏和风格。用户对消耗大量积分却得不到可用结果表示不满,并质疑是否为系统 bug。有用户制作视频展示了该问题。 (来源: Reddit r/SunoAI, Reddit r/SunoAI)

Suno 用户反馈近期生成质量下降: 一位长期 Suno 付费用户抱怨近期 V4 和 V3.5 模型的生成质量严重下降,称之前可靠的 prompt 现在生成的都是“噪音”或跑调的音乐,消耗 3000 积分未能得到一首可用歌曲。用户质疑是否为 bug,并考虑取消订阅。 (来源: Reddit r/SunoAI)
社区分享:用 AI 为孩子生成梦想职业图片: 视频展示了一个温馨的应用场景:孩子们描述自己长大后想做的工作(如律师、冰淇淋师、动物园管理员、自行车手),然后使用 AI(视频中为 ChatGPT)根据描述生成相应的图片,孩子们看到图片后非常开心。 (来源: Reddit r/ChatGPT)

社区分享:AI 生成名人与年轻/年老自己相遇图: 用户使用 ChatGPT 的图像生成功能,创作了一系列名人(如马斯克、阿诺施瓦辛格、保罗麦卡特尼、托尼霍克、克林特伊斯特伍德等)与他们年轻或年老时的自己相遇的图片,效果逼真有趣。 (来源: Reddit r/ChatGPT)
AI 生成关于美国再工业化的“怪异”视频: 用户分享了一段据称由中国 AI 生成的关于“美国再工业化”的视频,视频内容和配乐风格被认为“狂野”且带有幽默/讽刺意味,展现了 AI 在生成特定叙事内容方面的能力和潜在偏见。 (来源: Reddit r/ChatGPT

用户对比 Claude 与 o1-pro 成本及效果: 一位用户分享了使用 OpenAI o1-pro 和 Anthropic Claude Sonnet 3.7 改进 Tailwind CSS 卡片样式的经历。结果显示,Claude 的输出效果更好,且成本远低于 o1-pro(不到 1 美元 vs 近 6 美元)。 (来源: Reddit r/ClaudeAI)
Claude 服务稳定性遭用户调侃: 用户发布 meme 或评论,调侃 Anthropic Claude 服务在工作日高峰时段频繁出现“意外高需求”导致过载或无法访问的情况,暗示其稳定性有待提高。 (来源: Reddit r/ClaudeAI)

数学博士生寻求机器学习入门资源: 一位即将开始数学博士学习的学生,其研究方向涉及将线性代数工具应用于机器学习(特别是 PINNs),正在寻找适合数学背景、严谨且简洁的 ML 入门资源(书籍、讲义、视频课),认为标准教材(如 Bishop、Goodfellow)过于冗长。 (来源: Reddit r/MachineLearning)

学生测试不同硬件上小模型性能差异: 一位学生分享了在 RTX 2060 桌面 GPU 和树莓派 5 上测试 Llama3.2 1B 和 Granite3.1 MoE 等小模型的性能数据。发现 Llama3.2 在桌面端表现最好,但在树莓派上次之,对此感到困惑。同时观察到 MoE 模型结果波动更大,询问原因。 (来源: Reddit r/MachineLearning)
用户寻求 OpenWebUI 分离搜索与标题生成模型: OpenWebUI 用户提问是否可以将用于生成搜索请求的模型(倾向于使用推理能力强的模型)与用于生成标题/标签的模型(倾向于使用更经济的小模型)分开设置。 (来源: Reddit r/OpenWebUI)
用户寻求 Suno AI 音乐 Prompt 手册: 用户询问是否有人还保留着之前流传的 Suno AI 音乐 Prompt 手册(PDF),因为原链接已失效。 (来源: Reddit r/SunoAI)

用户寻求 OpenWebUI 与 LM Studio 集成帮助: 用户尝试将 OpenWebUI 与 LM Studio 作为后端连接(通过 OpenAI 兼容 API),但在设置网页搜索和 embedding 功能时遇到问题,寻求社区帮助。 (来源: Reddit r/OpenWebUI)
用户分享 AI 生成的音乐作品: 多个用户在 r/SunoAI 分享了他们使用 Suno AI 创作的音乐作品,涵盖 Ambient, Musical, Alternative Psychedelic Rock, Folk Country, Comedy ballad (EDM), Rap, Folk Music, Dreamy indie pop 等多种风格。 (来源: Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI, Reddit r/SunoAI)

用户询问 Suno 订阅价值: 考虑到近期关于 Suno v4 质量的抱怨,用户询问当前购买 Suno 订阅是否仍然值得,特别是用于重新制作(remaster)旧的 v3 版本歌曲。 (来源: Reddit r/SunoAI)
用户寻求制作 Suno 音乐专辑的建议: 有经验的 Suno 用户计划将自己满意的作品整理成专辑,并通过 DistroKid 等平台发布到 Spotify,向社区寻求关于歌曲挑选、排序以及技术操作方面的建议。 (来源: Reddit r/SunoAI)
用户抱怨 Suno 在 iPad 上的 UI 问题: 新订阅用户反映在 iPad 上使用 Suno 网站时遇到界面问题,无法正常使用录制、编辑歌词、拖放等功能,寻求解决方案或建议。 (来源: Reddit r/SunoAI)
用户吐槽 Cursor AI 可能偷偷降级模型: 用户怀疑 Cursor AI 在未告知的情况下将其使用的模型从声称的 Claude 3.7 降级到了 3.5,依据是 Agent 行为变化且拒绝透露模型信息。用户称其在 r/cursor 发布的质疑帖被删除。 (来源: Reddit r/ClaudeAI)
用户询问常用付费 AI 服务: 用户发起讨论,询问大家每月都在订阅哪些付费 AI 服务,想了解哪些工具被认为物有所值,以及是否有值得推荐的服务。 (来源: Reddit r/artificial)
深度学习求助:识别混合信号: 初学者求助如何使用深度学习识别混合在一起的科学测量信号模式。数据为 txt/Excel 格式的坐标点。问题包括:如何整合图像格式的补充数据?模型能否处理坐标点表示的混合模式?推荐哪些模型或学习方向? (来源: Reddit r/deeplearning)
Meme/Humor: 社区出现多个与 AI 相关的 Meme 或幽默帖子,例如关于爱上 AI (电影 Her),偏好 Gemma 3 模型,AI Note-Taker 市场饱和,Claude 服务宕机,以及 AI 生成的名人集换卡等。 (来源: Reddit r/ChatGPT, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, AravSrinivas, Reddit r/artificial)

💡 其他
Protocol Buffers (Protobuf) 持续受关注: Google 开发的数据交换格式 Protobuf 在 GitHub 上保持高关注度。它作为一种语言中立、平台中立的可扩展机制,用于序列化结构化数据,在 AI/ML 及众多大型系统中(如 TensorFlow、gRPC)被广泛应用。仓库提供了编译器(protoc)的安装说明、多语言运行时库的链接以及 Bazel 集成指南。 (来源: protocolbuffers/protobuf – GitHub Trending (all/daily))
Gin Web 框架保持热门: Go 语言编写的高性能 HTTP Web 框架 Gin 持续在 GitHub 上受到欢迎。它以其类似 Martini 的 API 和高达 40 倍的性能提升(得益于 httprouter)而闻名,适用于需要高性能 Web 服务(可能包括 AI 模型的 API 服务)的场景。 (来源: gin-gonic/gin – GitHub Trending (all/daily))
Hugging Face Hub 采用新后端 Xet 提升效率: Hugging Face Hub 开始使用新的存储后端 Xet,替代了原有的 Git 后端。Xet 利用内容定义分块(CDC)技术,在字节级(约 64KB 块)进行数据去重,而非文件级。这意味着修改大型文件(如 Parquet)时,只需传输和存储变化的行级差异,极大提高了上传下载效率和存储效率。Llama-4 模型的发布成功测试了该后端。 (来源: huggingface)
Hugging Face Hub 即将支持 MCP 客户端: Hugging Face 开发者提交了一个 Pull Request,计划在 huggingface_hub 库的 Inference 客户端中添加对模型上下文协议(MCP)的支持。这可能意味着 Hugging Face 推理服务将能更好地与遵循 MCP 标准的工具和 Agent 进行交互。 (来源: huggingface)
Zipline 无人机送货系统: 展示了 Zipline 公司的无人机送货系统。该系统可能利用 AI 进行路径规划、避障和精准投递,应用于物流和供应链领域,尤其是在医疗物资运输等方面展现潜力。 (来源: Ronald_vanLoon)
ergoCub 机器人用于物理人机交互: 意大利技术研究院(IIT)展示了 ergoCub 机器人,该机器人设计用于物理人机交互研究。这类机器人通常需要先进的 AI 算法来实现感知、运动控制和安全交互能力。 (来源: Ronald_vanLoon)
KeyForge3D:用计算机视觉配钥匙: 一个名为 KeyForge3D 的 GitHub 项目利用 OpenCV (计算机视觉库) 识别钥匙形状,计算钥匙的齿位码(bitting code),并能导出用于 3D 打印的 STL 模型。虽然主要使用传统 CV 技术,但展示了图像识别在物理世界复制任务中的应用潜力,未来可能结合 AI 进一步提升识别精度和适应性。 (来源: karminski3)

负责任 AI (Responsible AI) 原则受关注: 帖子提到了安永(EY)等机构使用的负责任 AI 原则,强调了在开发和部署 AI 系统时需要考虑公平、透明、可解释性、隐私、安全和问责制等伦理和社会因素。 (来源: Ronald_vanLoon)
川崎展示氢动力骑乘式机器人“马”: 川崎重工展示了一款名为 Corleo 的四足机器人,设计为可骑乘,并采用氢燃料作为动力源。虽然是机器人,但报道未明确提及 AI 在其控制或交互系统中的具体应用程度。 (来源: Reddit r/ArtificialInteligence)
