
关键词:AI模型, OCR技术, AI基础设施, 大型语言模型, AI代理, 多模态模型, AI能耗优化, AI开源生态, DeepSeek OCR模型, Gemini 3多模态推理, Emu3.5世界模型, Kimi Linear混合注意力架构, AgentFold记忆折叠技术
AI 栏目总编精选
🔥 聚焦
DeepSeek OCR模型:AI记忆力新突破与能耗优化 : DeepSeek发布了一款OCR模型,其核心创新在于信息处理和记忆存储方式。模型将文本信息压缩成图像形式,显著减少了运行所需的计算资源,有望缓解AI日益增长的碳足迹。该方法通过分层压缩模拟人类记忆,将不重要内容模糊化以节省空间,同时保持高效率。此研究引起了Andrej Karpathy等专家的关注,认为图像可能比文本更适合作为LLM输入,为AI记忆和代理应用开辟新方向。(来源:MIT Technology Review)

科技巨头持续重金投入AI基础设施 : 微软、Meta和谷歌等科技巨头在最新财报中宣布将继续大幅增加AI基础设施支出。Meta预计今年资本支出将达700-720亿美元,并计划明年进一步扩大;微软智能云收入首次突破300亿美元,Azure及其他云服务增长40%,预计AI产能将提升80%。谷歌CEO皮查伊强调AI全栈方法带来强劲动力,预告Gemini 3即将发布。这些投资反映了巨头们对AI未来突破的乐观预期和抢占市场先机的决心。(来源:Wired, Reddit r/artificial)

Anthropic发现LLM具备有限的“内省能力” : Anthropic最新研究显示,大型语言模型(LLMs)如Claude具备“真正的内省意识”,尽管这种能力目前仍有限。研究探讨了LLM是否能识别其内部思维,或仅是根据提问生成合理答案。这一发现暗示LLMs可能拥有比预期更深层次的自我认知,对理解和发展更智能、更具意识的AI系统具有重要意义。(来源:Anthropic, Reddit r/artificial)

Extropic发布新型热力学计算硬件TSU,号称AI能耗突破 : Extropic公司推出了一种全新的计算设备TSU (Thermodynamic Sampling Unit),其核心是“概率比特”(P-bit),能在0和1之间以可编程概率闪烁,旨在实现AI能耗的10,000倍效率提升。该公司发布了X0芯片、XTR0桌面测试套件和Z1商业级TSU,并开源了Thermol软件库用于GPU模拟TSU。尽管其效率提升的基准定义受到质疑,但这一方向旨在解决AI算力和能源的巨大缺口,为AI计算带来潜在范式转变。(来源:TheRundownAI, pmddomingos, op7418)

🎯 动向
谷歌预告Gemini 3即将发布,强化AI模型家族专业化趋势 : 谷歌CEO桑达尔·皮查伊在财报电话会议中预告,新版旗舰模型Gemini 3将于今年晚些时候发布。他强调谷歌的AI模型家族正走向专业化,Gemini专注于多模态推理,Veo用于视频生成,Genie用于交互式代理,Nano则针对设备端智能。这一策略表明谷歌正从单一通用模型转向互联互通、针对不同场景优化的系统架构,以提升可靠性、降低延迟并支持边缘部署。(来源:Reddit r/ArtificialInteligence, shlomifruchter)
Sora 2新增自定义角色与视频拼接功能,支持连续长视频创作 : Sora 2近期更新了多项重要功能,包括支持创建其他角色(无法上传真实照片,但可从现有视频人物创建),用户可利用此功能确保角色一致性,对构建连续长视频至关重要。此外,草稿页支持多条视频拼接后发布,搜索页增加了排行榜,展示拍摄真人出镜秀和二次创作达人。这些更新显著提升了Sora 2的创作灵活性和用户互动性,有望大幅增加其日活跃用户。(来源:op7418, billpeeb, op7418)
智源发布开源多模态世界模型Emu3.5,性能超越Gemini-2.5-Flash-Image : 北京智源人工智能研究院(BAAI)发布了参数量34B的开源多模态世界模型Emu3.5。该模型以Decoder-only Transformer为框架,能同时处理图、文、视频任务,并统一为下一State预测任务。Emu3.5在海量互联网视频数据上预训练,具备理解时空连续性和因果关系的能力,在视觉叙事、视觉引导、图像编辑、世界探索和具身操作等方面表现出色,尤其在物理真实性方面有显著提升,性能媲美甚至超越Gemini-2.5-Flash-Image(Nano Banana)。(来源:36氪)

Moonshot AI发布Kimi Linear模型,采用混合线性注意力架构 : Moonshot AI推出了Kimi Linear模型,这是一款基于混合线性注意力(KDA)架构的48B参数模型,激活参数为3B,支持1M上下文长度。Kimi Linear通过优化Gated DeltaNet,显著提升了长上下文任务的性能和硬件效率,将KV缓存需求减少高达75%,解码吞吐量提升6倍。该模型在多个基准测试中表现优异,超越了传统全注意力模型,并在Hugging Face上开源了两个版本。(来源:Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, bigeagle_xd)

MiniMax M2模型坚持全注意力架构,强调生产部署中的挑战 : MiniMax M2的预训练负责人Haohai Sun解释了M2模型为何仍采用全注意力(Full Attention)架构而非线性或稀疏注意力。他指出,尽管高效注意力在理论上能节省算力,但在实际工业级系统中,其性能、速度和价格仍难以超越全注意力。主要瓶颈在于评估系统的局限性、复杂推理任务的高昂实验成本以及基础设施的不成熟。MiniMax认为,在追求长上下文能力时,数据质量、评估体系和基础设施的优化比单纯改变注意力架构更为关键。(来源:Reddit r/LocalLLaMA, ClementDelangue)
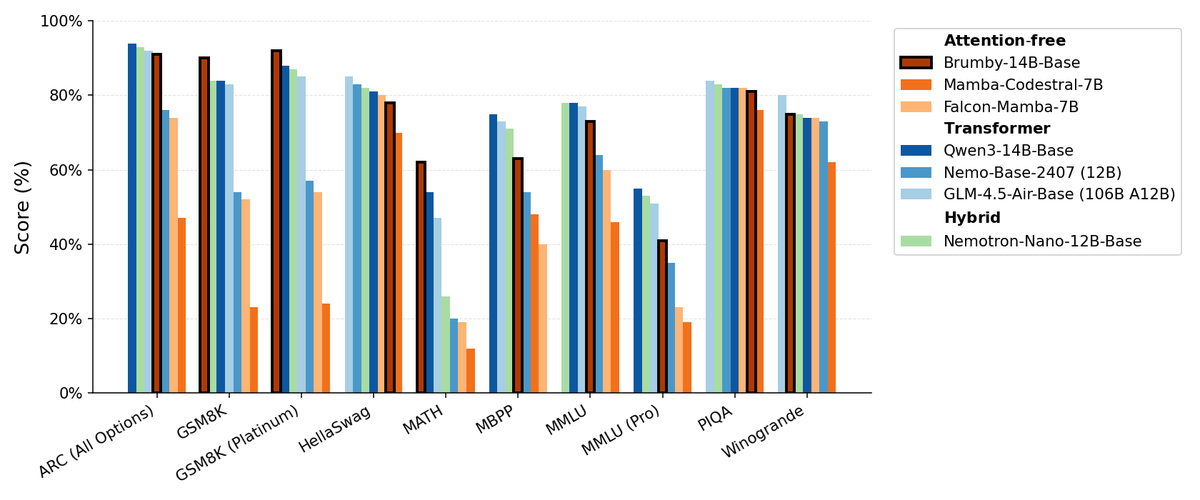
Manifest AI发布Brumby-14B-Base,探索无注意力基础模型 : Manifest AI发布了Brumby-14B-Base,声称这是目前最强的无注意力基础模型,以仅4000美元的成本训练了140亿参数。该模型在性能上与同等规模的Transformer和混合模型相当,预示着Transformer时代可能正缓慢走向终结。这一进展为AI模型架构提供了新的可能性,尤其在降低训练成本方面展现了巨大潜力,挑战了传统注意力机制的主导地位。(来源:ClementDelangue, teortaxesTex)
新的Nemotron模型基于Qwen3 32B,优化LLM响应质量 : NVIDIA发布了Qwen3-Nemotron-32B-RLBFF,这是一个基于Qwen/Qwen3-32B进行微调的大型语言模型,旨在提高LLM在默认思维模式下生成响应的质量。该研究模型在Arena Hard V2、WildBench和MT Bench等基准测试中表现显著优于原始Qwen3-32B,并与DeepSeek R1和O3-mini性能相似,但推理成本仅为5%以下,展示了在性能和效率方面的进步。(来源:Reddit r/LocalLLaMA)

Mamba架构在长上下文处理中仍具优势,但并行训练受限 : Mamba架构在处理长上下文(数百万tokens)方面表现出色,避免了Transformer的内存爆炸问题。然而,其主要限制在于训练期间难以并行化,这阻碍了其在更大规模应用中的普及。尽管存在多种线性混合器和混合架构,Mamba的并行训练挑战仍是其大规模应用的关键瓶颈。(来源:Reddit r/MachineLearning)
NVIDIA发布ARC、Rubin、Omniverse DSX等,强化AI基础设施领导地位 : NVIDIA在GTC大会上发布了一系列重磅公告,包括NVIDIA ARC(空中RAN计算机)与诺基亚合作开发6G、Rubin第三代机架规模超级计算机、Omniverse DSX(用于虚拟协同设计和操作千兆级AI工厂的蓝图)以及NVIDIA Drive Hyperion(机器人出租车标准化架构)并与Uber合作。这些发布表明NVIDIA正将其定位从芯片制造商转变为国家基础设施的架构师,强调“美国制造”和能源竞赛,以应对AI和6G时代的挑战。(来源:TheTuringPost, TheTuringPost)

AgentFold:自适应上下文管理,提升Web代理效率 : AgentFold提出了一种新颖的上下文工程技术,通过“记忆折叠”(Memory Folding)将代理的过往思考压缩成结构化记忆,动态管理认知工作空间。该方法解决了传统ReAct代理上下文过载的问题,并在BrowseComp等基准测试中表现出色,超越了DeepSeek-V3.1-671B等大型模型。AgentFold-30B以更小的参数量实现竞争性性能,显著提升了Web代理的开发和部署效率。(来源:omarsar0)

ReCode:统一规划与行动,实现AI代理决策粒度动态控制 : ReCode(Recursive Code Generation)是一种新的参数高效微调(PEFT)方法,通过将高层规划视为可分解为细粒度行动的递归函数,统一了AI代理的规划与行动表示。该方法仅需0.02%的训练参数即可实现SOTA性能,并减少了GPU内存占用。ReCode使代理能够动态适应不同决策粒度,学习分层决策,并在效率和数据利用率上显著优于传统方法,是实现类人推理的重要一步。(来源:dotey, ZhihuFrontier)

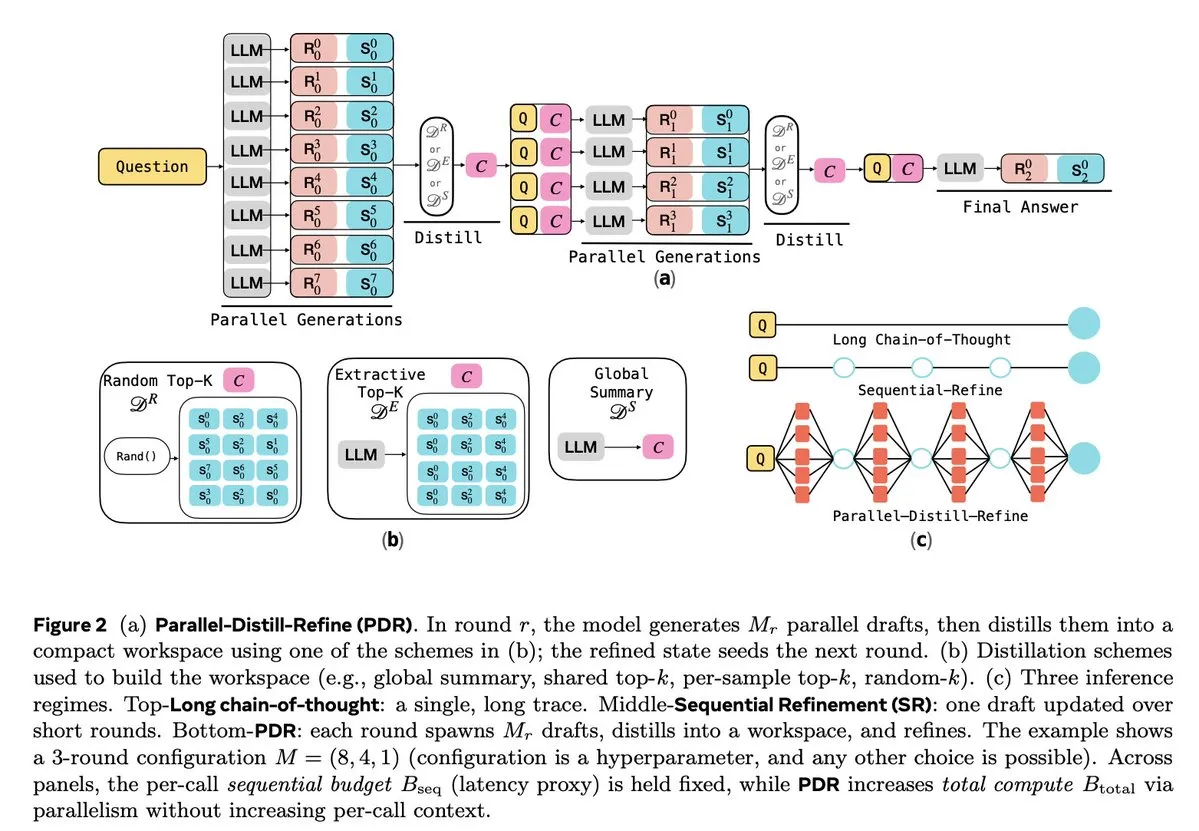
LLM推理与强化学习优化 : 多项研究致力于提升LLM的推理效率和可靠性。Parallel-Distill-Refine (PDR) 通过并行生成和提炼草稿,降低了复杂推理任务的成本和延迟。Flawed-Aware Policy Optimization (FAPO) 引入奖励惩罚机制,纠正推理过程中的缺陷模式,提高可靠性。PairUni框架通过成对训练和Pair-GPRO优化算法,平衡多模态LLM的理解与生成任务。PM4GRPO利用过程挖掘技术,通过推理感知GRPO强化学习,增强策略模型的推理能力。Fortytwo协议则通过分布式对等排名共识,实现了AI群组推理的卓越性能和对对抗性提示的强大抵抗力。(来源:NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
🧰 工具
腾讯开源WeKnora:LLM驱动的文档理解与检索框架 : 腾讯开源了WeKnora,一个基于LLM的文档理解与语义检索框架,专为处理复杂、异构文档设计。它采用模块化架构,结合多模态预处理、语义向量索引、智能检索和LLM推理,遵循RAG范式,通过结合相关文档块和模型推理,实现高质量、上下文感知的答案。WeKnora支持多种文档格式、嵌入模型和检索策略,并提供用户友好的Web界面和API,支持本地部署和私有云,确保数据主权。(来源:GitHub Trending)
Jan:开源离线ChatGPT替代品,支持本地运行LLM : Jan是一款开源的ChatGPT替代品,可在用户电脑上100%离线运行。它允许用户下载并运行来自HuggingFace的LLM(如Llama、Gemma、Qwen、GPT-oss等),并支持与OpenAI、Anthropic等云模型的集成。Jan提供自定义助手、OpenAI兼容API和模型上下文协议(MCP)集成,强调隐私保护,为用户提供完全控制的本地AI体验。(来源:GitHub Trending)

Claude Code:Anthropic的开发者工具包与技能生态 : Anthropic的Claude Code通过一系列“技能”和代理,显著提升了开发者的工作效率。其中包括Rube MCP连接器(连接Claude到500+应用)、Superpowers开发工具包(提供/brainstorm、/write-plan、/execute-plan命令)、文档套件(处理Word/Excel/PDF)、Theme Factory(品牌指南自动化)和Systematic Debugging(模拟高级开发者调试流程)。这些工具通过模块化设计和上下文感知能力,帮助开发者实现自动化工作流、代码审查、重构和错误修复,甚至支持非技术团队自建小工具。(来源:Reddit r/ClaudeAI, Reddit r/ClaudeAI)

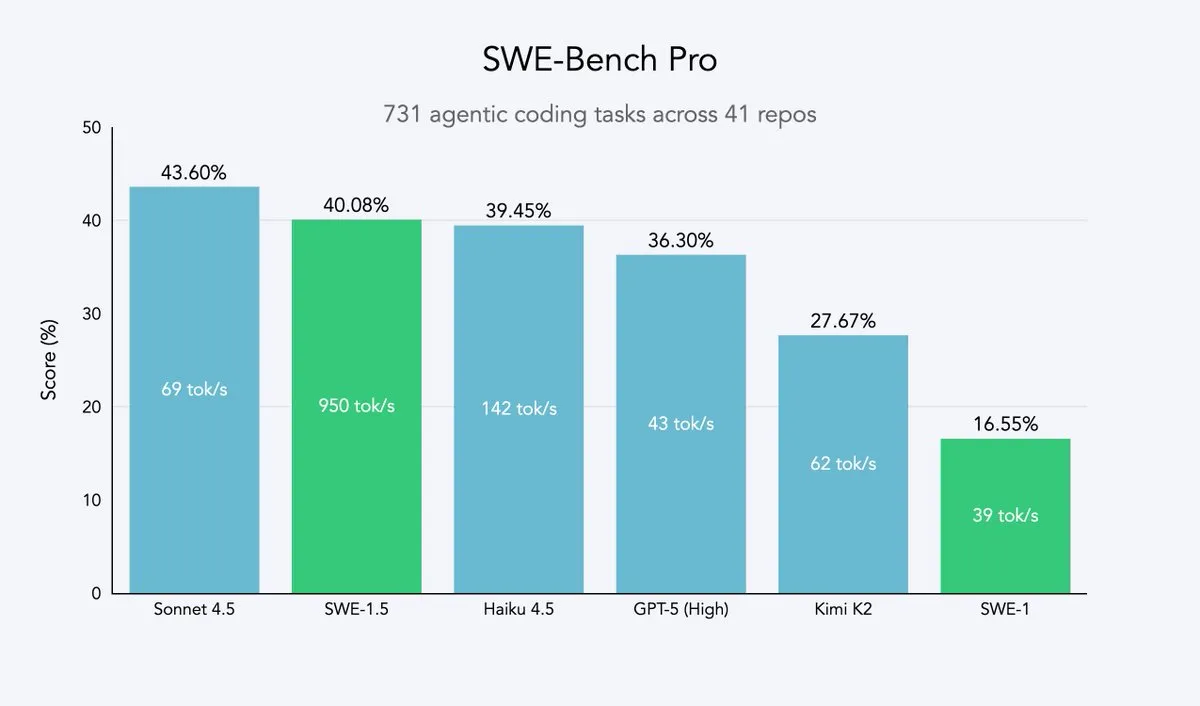
Cursor 2.0和Windsurf:代码智能体追求速度与效率 : Cursor和Windsurf发布了主打速度优化的代码智能体模型和2.0平台,其策略是基于开源大模型(如Qwen3)进行强化学习微调,并部署在优化硬件上,以实现“中等智能但速度超快”的效果。这种路线对于代码智能体公司而言,是一种高效的战略,能在最小资源成本下接近速度和智能的帕累托前沿。Windsurf的SWE-1.5模型在实现近SOTA编码性能的同时,树立了速度新标准。(来源:dotey, Smol_AI, VictorTaelin, omarsar0, TheRundownAI)
Perplexity Patents:首个AI专利研究代理,赋能IP智能 : Perplexity推出了Perplexity Patents,全球首个AI专利研究代理,旨在让IP智能普惠大众。该工具能够支持跨专利的搜索和研究,未来还将推出Perplexity Scholar,专注于学术研究。这一创新将极大地简化专利检索和分析流程,为创新者、律师和研究人员提供高效、易用的知识产权情报服务。(来源:AravSrinivas)

Real Deep Research (RDR):AI驱动的深度科研框架 : Real Deep Research (RDR) 是一个AI驱动的框架,旨在帮助研究人员跟上现代科学的快速发展。RDR弥合了专家撰写调查和自动化文献挖掘之间的鸿沟,提供可扩展的分析流程、趋势分析、跨领域连接洞察,并生成结构化、高质量的摘要。它作为一个全面的研究工具,帮助研究人员更好地理解宏观图景。(来源:TheTuringPost)

LangSmith推出无代码Agent Builder,赋能非技术团队构建代理 : LangChainAI的LangSmith推出了无代码Agent Builder,旨在降低AI代理的构建门槛,使非技术团队也能轻松创建代理。该工具通过对话式代理构建UX、内置记忆功能帮助代理记住并改进,以及赋能非技术团队和开发者共同构建代理,从而加速AI代理的普及和应用。(来源:LangChainAI)
Verdent集成MiniMax-M2,提升编码能力与效率 : Verdent现已支持MiniMax-M2模型,为用户带来先进的编码能力、高性能代理和高效的参数激活。通过Verdent在VS Code中免费试用MiniMax-M2,开发者可以享受更智能、更快、更具成本效益的编码体验。这一集成将MiniMax-M2的强大能力带给更广泛的开发者社区。(来源:MiniMax__AI)
Base44推出全新Builder,加速概念到应用转化 : Base44发布了全新的Builder,标志着其工作方式的根本性转变。新Builder更像一位专家级开发者,能够在构建前进行调查、从多源获取上下文、智能调试并做出明智的架构决策。这一更新旨在将概念转化为功能性应用的速度提升十倍,极大提高了开发效率。(来源:MS_BASE44)
Qdrant与Confluent合作,赋能实时上下文感知AI代理 : Qdrant与Confluent合作,通过Confluent Streaming Agents和Real-Time Context Engine,为智能AI代理和企业应用提供新鲜、实时的上下文。Qdrant的向量搜索能力与Confluent的实时流数据相结合,使开发者能够构建和扩展事件驱动、上下文感知的AI代理,从而解锁代理式AI的全部潜力,并在事故响应等场景中大幅缩短解决时间并降低成本。(来源:qdrant_engine, qdrant_engine)

📚 学习
ICLR26 Paper Finder:基于LLM的AI论文搜索工具 : 一位开发者创建了ICLR26 Paper Finder,这是一个利用语言模型作为骨干的工具,用于搜索特定AI会议的论文。用户可以通过标题、关键词甚至论文摘要进行查询,其中摘要搜索的准确性最高。该工具已托管在个人服务器和Hugging Face上,为AI研究人员提供了高效的文献检索方式。(来源:Reddit r/deeplearning, Reddit r/MachineLearning)
UCLA 2025年春季课程:大型语言模型强化学习 : UCLA将于2025年春季开设“大型语言模型强化学习”课程,涵盖RLxLLM的广泛主题,包括基础知识、测试时计算、RLHF(人类反馈强化学习)和RLVR(可验证奖励强化学习)。这套新讲座为研究人员和学生提供了深入学习LLM强化学习前沿理论和实践的机会。(来源:algo_diver)
手绘Autoencoder指南:理解生成式AI基础 : ProfTomYeh发布了手绘Autoencoder(自编码器)的7步详细指南,旨在帮助读者理解这一在压缩、去噪和学习丰富数据表示方面发挥关键作用的神经网络。Autoencoder是许多现代生成式架构的基础,这份指南通过直观的方式解释其编码和解码信息的工作原理,是学习生成式AI核心概念的宝贵资源。(来源:ProfTomYeh)
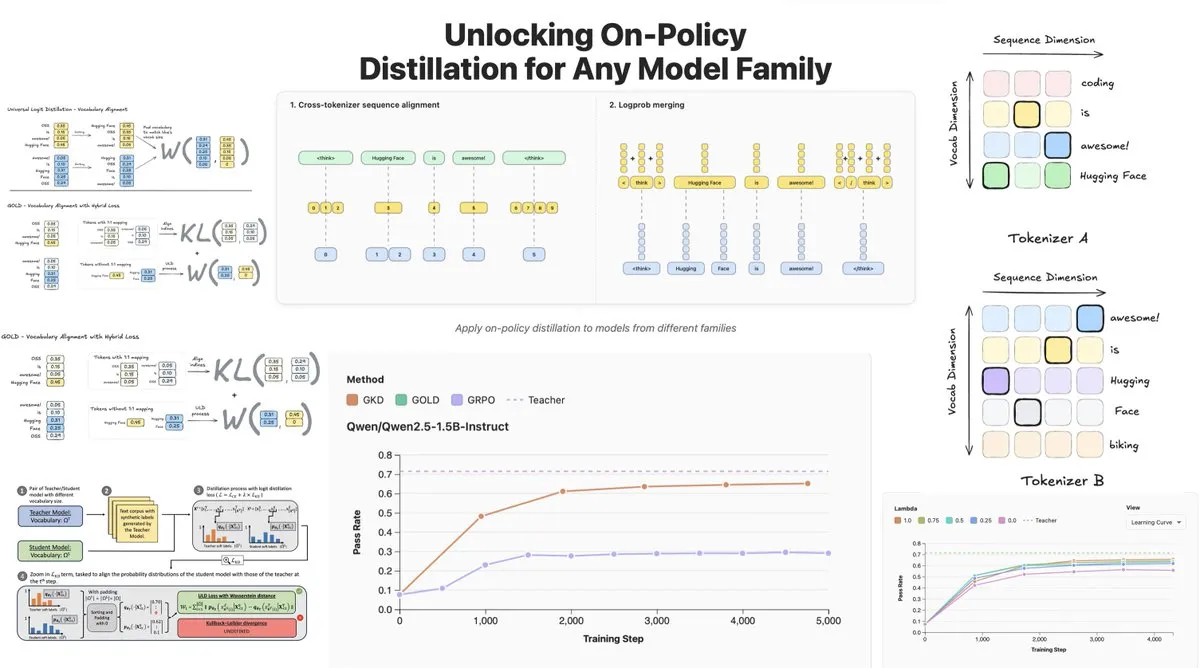
Hugging Face发布On-Policy Logit Distillation,支持跨模型蒸馏 : Hugging Face推出了General On-Policy Logit Distillation(GOLD),扩展了策略蒸馏方法,使其能够将任何教师模型蒸馏到任何学生模型,即使它们的Tokenizer不同。这项技术已被整合到TRL库中,允许开发者从Hub中选择任意模型对进行蒸馏,为LLM的后训练(post-training)提供了巨大的灵活性和性能恢复能力,尤其解决了在特定领域微调后通用性能下降的问题。(来源:clefourrier, winglian, _lewtun)
Lumi:Google DeepMind利用Gemini 2.5辅助arXiv论文阅读 : Google DeepMind的PAIR团队发布了Lumi,一个利用Gemini 2.5大模型辅助阅读arXiv论文的工具。Lumi能够为论文添加摘要、参考文献和内联问答,帮助研究人员更智能、更高效地阅读,提升科研文献的理解效率。(来源:GoogleDeepMind)
💼 商业
AI助推科技巨头营收创新高,微软谷歌财报亮眼 : 谷歌母公司Alphabet和微软在最新财报中均取得里程碑式业绩,AI成为核心增长引擎。Alphabet首次季度营收突破千亿美元,达1023亿美元,谷歌云增长34%,70%现有客户使用AI产品。微软营收增长18%至777亿美元,智能云收入首超300亿美元,Azure云服务增速达40%,AI拉动显著。两家公司均计划大幅增加AI资本支出,以巩固其在AI领域的领先地位,并获得资本市场认可。(来源:36氪, Yuchenj_UW)

Block CTO:AI Agent Goose将60%复杂工作自动化,代码质量与产品成功无直接关系 : Block(原Square)CTO Dhanji R. Prasanna分享了公司如何通过开源AI Agent框架“Goose”在8周内为1.2万名员工节省每周8-10小时工作时间。Goose基于模型上下文协议(MCP),能连接企业工具,实现自动化代码编写、报告生成、数据处理等任务。Prasanna强调,AI原生公司应重新定位为科技公司,并进行组织结构调整。他提出“代码质量与产品成功无直接关系”的反直觉观点,认为产品是否解决用户问题才是关键,并鼓励工程师拥抱AI,资深和新手工程师对AI工具的接受度最高。(来源:36氪)

数字人行业进入淘汰赛,3D数字人制作转向平台化 : 随着大模型爆发,数字人行业面临洗牌,缺乏AI能力的公司被淘汰。2D数字人市场占比达70.1%,而3D数字人受技术迭代和高GPU成本限制。魔珐科技等头部公司强调3D数字人需匹配大模型能力,并指出高质量数据积累、稀缺人才和强大美术能力是关键。行业趋势显示,3D数字人制作正向平台化发展,AI技术进步降低了成本,使规模化应用成为可能。影眸科技和百度等公司也纷纷推出3D生成平台,旨在将数字人作为基础设施,赋能更多应用场景。(来源:36氪)
🌟 社区
用户对AI情感与信任的复杂感知:R2D2与ChatGPT的对比 : 社交媒体上热议R2D2与ChatGPT在用户情感连接上的差异。用户认为R2D2因其独特的脾气、忠诚和“像马一样”的形象而可爱,且不涉及现实社会伦理问题。而ChatGPT作为“真实的假AI”,因其实用性、内容审查限制和潜在的监控担忧,难以建立同样的情感纽带。这种对比揭示了用户对AI的期望不仅在于智能,更在于其“人性化”的互动体验和对社会影响的感知。(来源:Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

AI心理辅导的局限与人类介入的必要性 : 随着AI心理辅导产品兴起,人们开始用AI解决孤独和心理问题。研究显示,约22%的Z世代职场人看过心理医生,近五成向AI咨询。AI在提供信息、排除因素和陪伴方面有优势,但无法替代人类心理咨询师在共情、读懂“空气”和主导治疗节奏上的作用。案例表明,AI在识别极端风险时需人工熔断机制,且人类在情绪与病变边界的判断、经验积累和非语言交流中不可或缺。AI应主要承担重复性、辅助性工作,并降低求助门槛,最终目的是将人引导回真实的人际关系。(来源:36氪)

老年人与大模型的互动:从“活法”定义“算法” : 复旦大学与腾讯SSV时光实验室等机构开展了一项为期一年的研究,教100位老年人使用大模型。研究发现,老年人对AI的态度并非抵触,而是基于生活经验的“实用主义技术观”。他们更关心技术能否融入日常、提供陪伴,而非极致功能。在信任校准中,老年人表现出“有限纠偏”、“协同互惠”和“认知固化”等多种模式,并存在“提问踌躇”和“性别鸿沟”。他们期待的大模型是能“算命的半仙”、“可信赖的医生”、“可聊天的朋友”和“可放松的玩具”,即更温柔地理解、更贴近日常生活的“懂人”技术。这表明技术的价值在于它能等多久,而非跑多快,呼吁技术应“共生化”而非“适老化”,以人的感受、节奏和尊严为尺度。(来源:36氪)

AI社会影响:从隐私监控到能源消耗与就业变革 : 社交媒体广泛讨论AI对社会的多方面影响。用户担忧AI已通过各种应用、搜索和摄像头实现“无形监控”,预测并影响个人行为,而非科幻式的机器人控制。同时,AI数据中心对能源和水资源的巨大需求引发社区抗议,导致电力中断和水资源短缺。此外,AI在代码生成、自动化任务中提升生产力,但引发对就业结构变化的讨论,以及AI代码质量对生产效率的挑战。这些讨论反映了公众对AI技术带来的便利与潜在风险的复杂情绪。(来源:Reddit r/artificial, MIT Technology Review, MIT Technology Review, Ronald_vanLoon, Ronald_vanLoon)

AI领域术语与概念的快速演变 : 社区讨论指出,AI领域的术语和概念正在快速演变。例如,“训练/构建模型”常常指代“微调”,而“微调”又被认为是“提示/上下文工程”的新形式。这种变化反映了AI技术栈的复杂化和对更精细化操作的需求。此外,对于模型速度与智能的权衡,开发者倾向于“慢而智能”的模型,因为它们能提供更可靠的结果,即使这意味着需要更多等待时间。(来源:dejavucoder, dejavucoder, dejavucoder)

AI开源生态与专有模型竞争加剧 : 社区热议开源AI模型与专有模型之间的差距正在缩小,迫使闭源实验室在定价上更具竞争力。MiniMax-M2等开源模型在AI Index上表现出色,且成本极低。同时,中国公司和初创企业积极开源AI技术,而美国企业在这方面相对滞后。这种趋势预示着AI领域将迎来一个“人人基于开源训练模型”的时代,推动AI技术的民主化和创新。(来源:ClementDelangue, huggingface, clefourrier, huggingface)
AI生成内容对传统行业的冲击与伦理挑战 : AI生成内容正日益渗透传统行业,例如AI驱动的“艺术家”登上音乐排行榜,以及深度伪造技术被用于欺诈(如假黄仁勋演讲推广加密货币骗局)。这些现象引发了版权、伦理和监管方面的讨论。同时,AI在代码生成、自动化社交媒体账户管理等方面也带来了新的生产力工具,但其生成内容的质量和可靠性仍需人类介入审查。这凸显了在AI普及过程中,如何平衡技术创新与社会责任、伦理规范的挑战。(来源:Reddit r/artificial, 36氪, jeremyphoward)

AI研究社区对数据质量和评估的关注 : AI研究社区日益关注数据质量在模型训练中的关键作用,并指出获取高质量数据比租用GPU或编写代码更具挑战。同时,对评估基准的局限性也存在广泛讨论,认为现有基准可能无法全面反映模型的真实能力,且易被过度优化。研究人员呼吁开发更具信息量和真实性的评估系统,以推动AI研究的健康发展。(来源:code_star, code_star, clefourrier, tokenbender)

AI在医疗健康领域的应用与展望 : AI在医疗健康领域展现出巨大潜力,例如云澎科技发布AI+健康新品,包括智能厨房实验室和搭载AI健康大模型的智能冰箱,提供个性化健康管理。此外,MONAI作为医疗影像AI工具包,提供PyTorch开源框架。AI驱动的外骨骼帮助轮椅使用者站立行走,以及LLM诊断代理在虚拟临床环境中学习诊断策略。这些进展预示着AI将深刻改变医疗健康服务,从日常健康管理到辅助诊断和治疗。(来源:36氪, GitHub Trending, Ronald_vanLoon, Ronald_vanLoon, HuggingFace Daily Papers)
AI时代的组织变革与人才需求 : 随着AI的普及,企业面临组织结构和人才需求的深刻变革。Block CTO Dhanji R. Prasanna强调,公司需重新定位为“科技公司”,并从“总经理制”转向“职能制”,以集中技术焦点。AI工具如Goose能显著提升生产力,但高层架构和设计仍需资深工程师。招聘时,企业更看重学习型思维和批判性思维,而非单纯的AI工具使用技能。AI也模糊了岗位界限,非技术岗位开始利用AI工具,推动“人机群体”协作模式的形成。(来源:36氪, MIT Technology Review, NandoDF, SakanaAILabs)

💡 其他
多功能机器人技术持续创新 : 机器人领域展现出多样化创新,包括章鱼启发式机器人SpiRobs、能游泳的无人机、用于包裹分拣的Helix机器人,以及NIO工厂中协助质量检查的人形机器人。这些进展涵盖了仿生设计、自动化、人机协作和特殊环境适应性,预示着机器人技术在工业、军事和日常应用中的广泛潜力。(来源:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
AI Agent概念深化与市场展望 : AI Agent被定义为能够像人类一样推理和适应的智能实体,能够实现人机无缝对话。它们被视为未来劳动的趋势,市场上有众多AI Agent构建工具正在涌现。AI Agent的核心价值在于成为能够执行实际任务的“生产工具”,而不仅仅是“聊天”的辅助工具,其发展将推动AI在各领域的深度应用。(来源:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, dotey)
AI与自动驾驶:Uber车队采用Nvidia新芯片,推动机器人出租车发展 : Uber的下一代自动驾驶车队将采用Nvidia的新芯片,有望降低机器人出租车的成本。Nvidia的Drive Hyperion平台是“机器人出租车就绪”车辆的标准化架构,与Uber的合作将推动自动驾驶技术向消费者普及。这表明AI在交通领域的应用正加速发展,旨在实现更安全、更经济的自动驾驶服务。(来源:MIT Technology Review, TheTuringPost)