
关键词:GPT-5, 量子计算, AI材料设计, 强化学习, 大语言模型, AI基础设施, 多模态模型, AI Agent, 量子NP难题, CGformer晶体图神经网络, RLMT强化学习框架, DeepSeek稀疏注意力DSA, UniVid统一视觉任务框架
🔥 聚焦
GPT-5攻克「量子NP难题」 : 量子计算专家Scott Aaronson首次发表论文,揭示GPT-5在量子复杂性理论研究中的突破性辅助作用。GPT-5在30分钟内助攻解决了“量子版NP难题”中的关键推导环节,而这通常需要人类1-2周时间。这一成果标志着AI已开始触及人类智慧的核心科学发现工作,预示着AI在科学研究领域潜力的巨大飞跃。 (来源: arXiv, scottaaronson.blog)
新材料AI设计模型CGformer : 上海交通大学李金金教授和黄富强教授团队研发出全新AI材料设计模型CGformer,通过创新融合Graphormer的全局注意力机制与CGCNN,并集成中心性编码、空间编码,成功突破传统晶体图神经网络局限。该模型能完整捕获复杂晶体结构的全局信息,显著提升高熵钠离子固态电解质等新材料的预测精度和筛选效率。 (来源: Matter)

UniVid统一视觉任务框架 : UniVid是一个创新框架,通过微调预训练的视频扩散Transformer,使其无需任务特定修改即可适应多样化的图像和视频任务。该方法将任务表示为视觉语句,通过上下文序列定义任务和预期输出模态,展示了预训练视频生成模型作为视觉建模统一基础的巨大潜力。 (来源: HuggingFace Daily Papers)
RLMT颠覆大模型后训练 : 普林斯顿大学陈丹琦副教授团队提出“基于模型奖励思维的强化学习”(RLMT)框架,通过让LLM在回复前生成长思维链,并结合基于偏好的奖励模型进行在线RL优化。该方法显著提升了LLM在开放式任务上的推理能力和泛化性,甚至使8B模型在聊天和创意写作方面超越GPT-4o。 (来源: arXiv)

CHURRO历史文本识别模型 : CHURRO是一个3B参数的开源视觉语言模型(VLM),专门为高精度、低成本的历史文本识别而设计。该模型在包含22个世纪、46种语言的99,491页历史文献数据集CHURRO-DS上训练,其性能超越了Gemini 2.5 Pro等现有VLM,显著提升了文化遗产研究和保存的效率。 (来源: HuggingFace Daily Papers)
🎯 动向
Altman预测AI超级智能及Pulse功能 : Sam Altman预测AI将在2030年全面超越人类智能,并指出AI发展速度惊人。OpenAI推出ChatGPT的“主动模式”Pulse功能,标志着AI从被动响应转向主动为用户思考,能够基于用户闲聊内容主动提供相关信息,实现极度个性化的服务,预示着AI将成为人类潜意识的外包。
黄仁勋驳斥AI泡沫论与英伟达战略 : 黄仁勋在专访中反驳“AI泡沫帝国”论,强调AI在经济中的关键角色,预测英伟达有望成为首家市值10万亿美元公司。他指出AI推理背后潜藏巨大算力需求,英伟达通过极致协同设计,每年推出新架构,并开放系统生态,无惧自研潮,旨在塑造AI经济体系并推动“主权AI”成为新共识。
DeepSeek开源V3.2-Exp及DSA机制 : DeepSeek开源了参数量为685B的V3.2-Exp实验版本,并同步公开论文,详细介绍了其新的稀疏注意力机制(DeepSeek Sparse Attention,DSA)。DSA旨在探索和验证在长上下文场景下训练和推理效率的优化,在保持模型输出质量的同时,显著提高了长上下文处理效率。 (来源: 36氪, HuggingFace)

GLM-4.6即将发布 : 智谱AI的GLM-4.6模型预计即将发布,其Z.ai官网已将GLM-4.5标识为“上一代旗舰模型”,预示着新版本可能带来上下文长度等方面的提升,引发社区关注和期待。 (来源: Reddit r/LocalLLaMA, karminski3)
苹果AI策略与内部聊天机器人Veritas : 苹果内部开发代号为“Veritas”的AI聊天机器人被曝光,作为Siri的陪练,具备执行应用内操作的能力。尽管如此,苹果仍坚持不推出消费级聊天机器人,专注于系统级AI集成,并计划通过AI答案引擎和通用接口MCP深化第三方模型集成,而非自研聊天机器人。 (来源: 36氪)

AI PC市场增长与技术瓶颈 : AI PC市场出货量预计在2025-2026年强劲增长,但主要由Windows 10停服和PC换机周期驱动,而非AI技术颠覆。当前AI功能多为传统PC补充,面临本地算力不足、交互被动、生态封闭等挑战,真正的AI设备需实现“本地算力为主、云端补充为辅”及主动感知。 (来源: 36氪)

AI涌入电力交易市场 : AI正被广泛应用于电力交易市场,清鹏智能等公司通过时序大模型预测风光发电量和用电需求,辅助交易决策。AI处理海量数据的优势有望放大盈利,但也可能因模型不成熟和市场复杂性导致亏损,行业仍在探索阶段。 (来源: 36氪)
阿里通义大模型更新与全栈AI服务 : 阿里云在云栖大会上重磅升级全栈AI体系,发布Qwen3-MAX、Qwen3-Omni等6个新模型,定位为“全栈人工智能服务商”。阿里云致力于构建“AI时代的Android”和“下一代计算机”,提供从基础模型到基础设施的全栈AI云服务,以应对AI Agent从“智能涌现”到“自主行动”的演进。 (来源: 36氪)

NVIDIA Blackwell架构深度解析 : NVIDIA Blackwell架构的深度解读活动,将探讨其架构、优化及在GPU云中的实现。该活动由SemiAnalysis和NVIDIA专家主讲,旨在揭示Blackwell GPU作为“下一个十年GPU”如何推动AI算力发展和GPU云的未来。 (来源: TheTuringPost)

🧰 工具
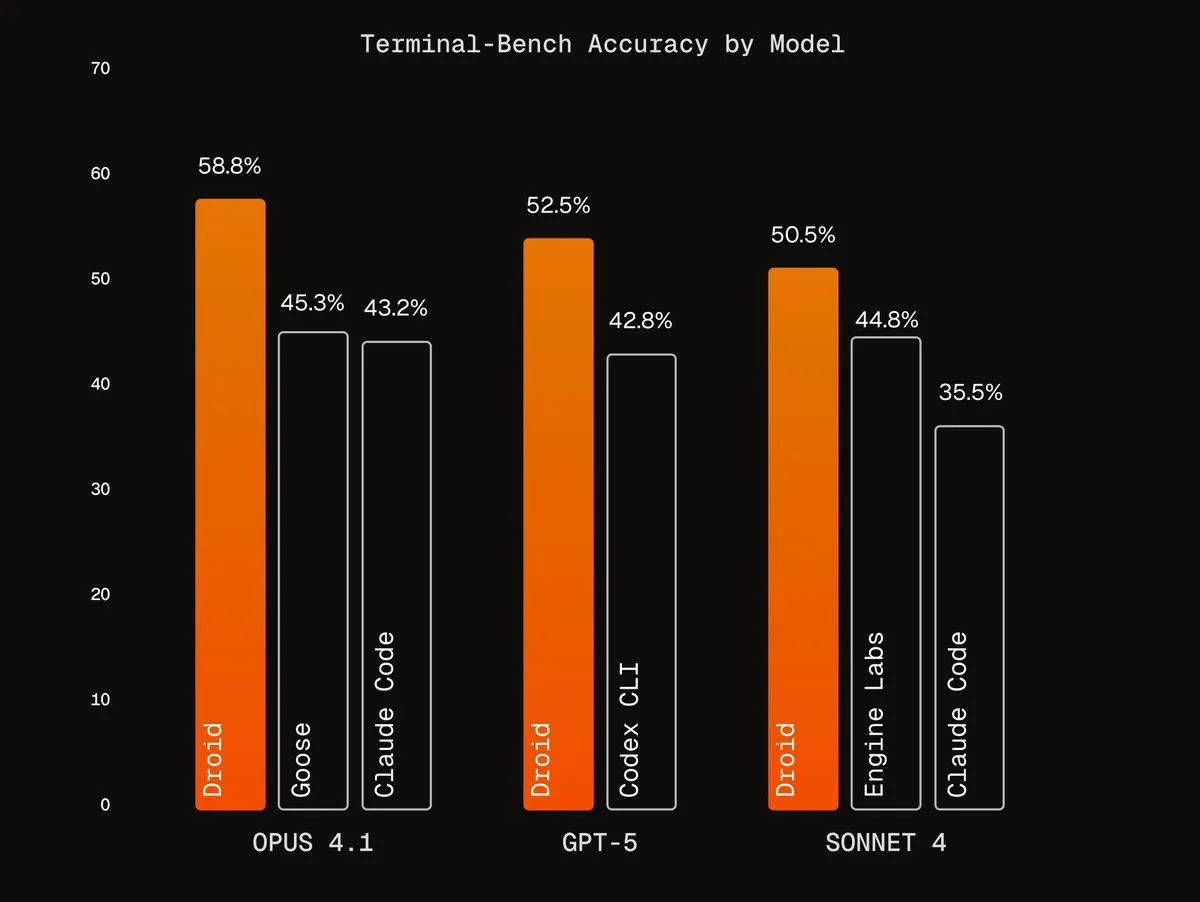
Factory AI的Agentic Harnesses : Factory AI开发了世界级的Agentic Harnesses,显著提升了现有模型的性能,尤其在编码任务中表现出色,被用户称为“作弊码”。其Droids代理在Terminal-Bench上排名第一,并通过多代理验证工作流实现可靠的代码重构。 (来源: Vtrivedy10, matanSF, matanSF)
RAGLight开源RAG库 : LangChainAI发布RAGLight,一个轻量级Python库,用于构建生产级RAG系统。该库具备LangGraph驱动的代理管道、多提供商LLM支持、内置GitHub集成和CLI工具,旨在简化RAG系统的开发和部署。 (来源: LangChainAI, hwchase17)
ArgosOS语义操作系统 : ArgosOS是一款桌面应用,通过基于标签的架构而非向量数据库,实现文档的智能搜索和内容整合。它利用LLM创建相关标签并存储在SQLite数据库中,从而智能处理查询,例如分析购物账单,为小规模应用提供准确高效的文档管理方案。 (来源: Reddit r/MachineLearning)
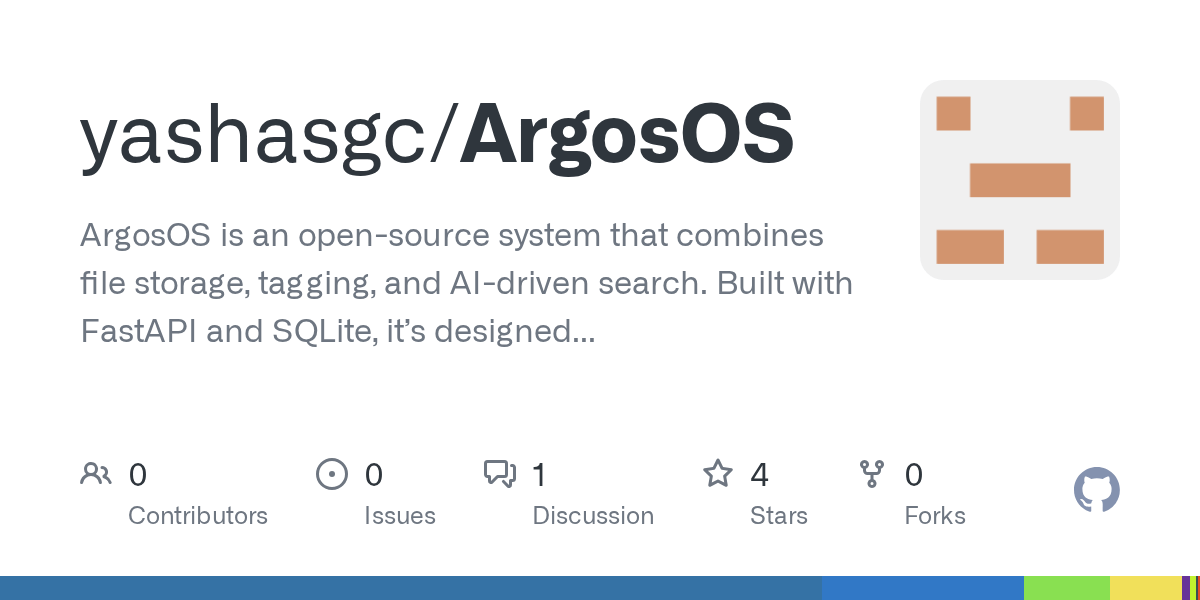
Ollama的Web搜索工具 : Ollama现在支持Web搜索工具,允许用户在Minions工作负载中集成Web搜索功能,从而丰富AI应用的上下文信息,提升其处理复杂任务的能力。 (来源: ollama)
Hyperlink本地多模态RAG : Hyperlink提供本地多模态RAG功能,允许用户离线搜索和总结截图/照片库。通过OCR和嵌入技术,该工具能将非结构化的图像数据转化为可查询内容,实现完全私有、设备上的文档管理和信息提取。 (来源: Reddit r/LocalLLaMA)

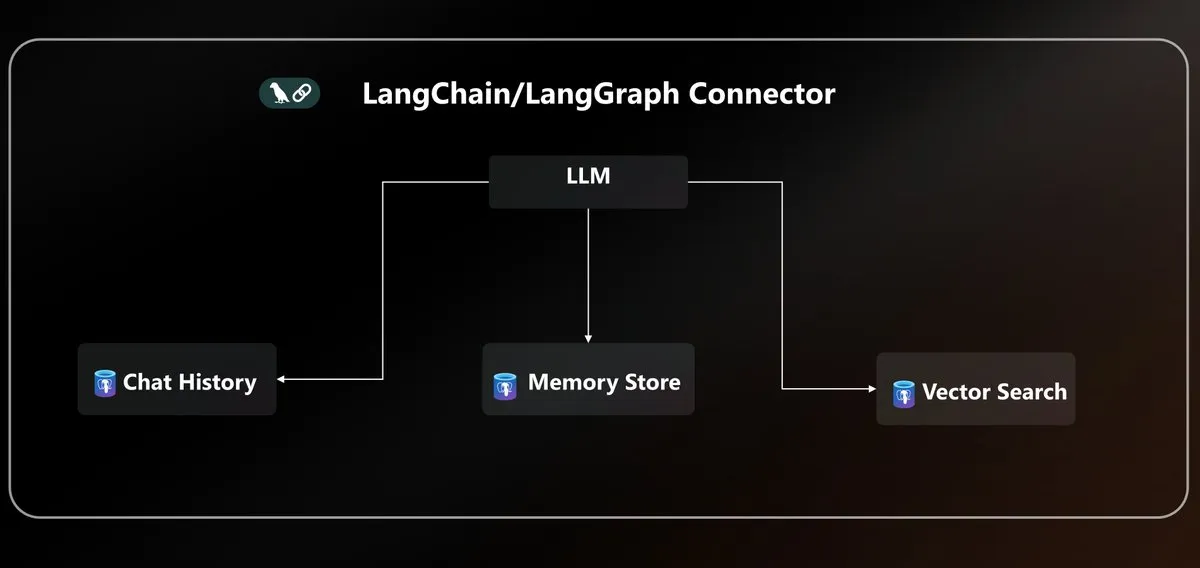
Azure PostgreSQL LangChain连接器 : Microsoft推出原生的Azure PostgreSQL连接器,为LangChain生态系统统一代理持久性。该连接器提供企业级向量存储和状态管理,简化了在Azure环境中构建和部署AI代理的复杂性。 (来源: LangChainAI)
LLM API标准化与MCP协议 : 社区讨论LLM API碎片化问题,指出不同提供商的消息结构、工具调用模式和推理字段名存在不兼容性,呼吁行业标准化JSON API协议。同时,MCP协议(Model-Client Protocol)的引入也引发了关于其对代理发展影响的讨论。 (来源: AAAzzam, charles_irl)
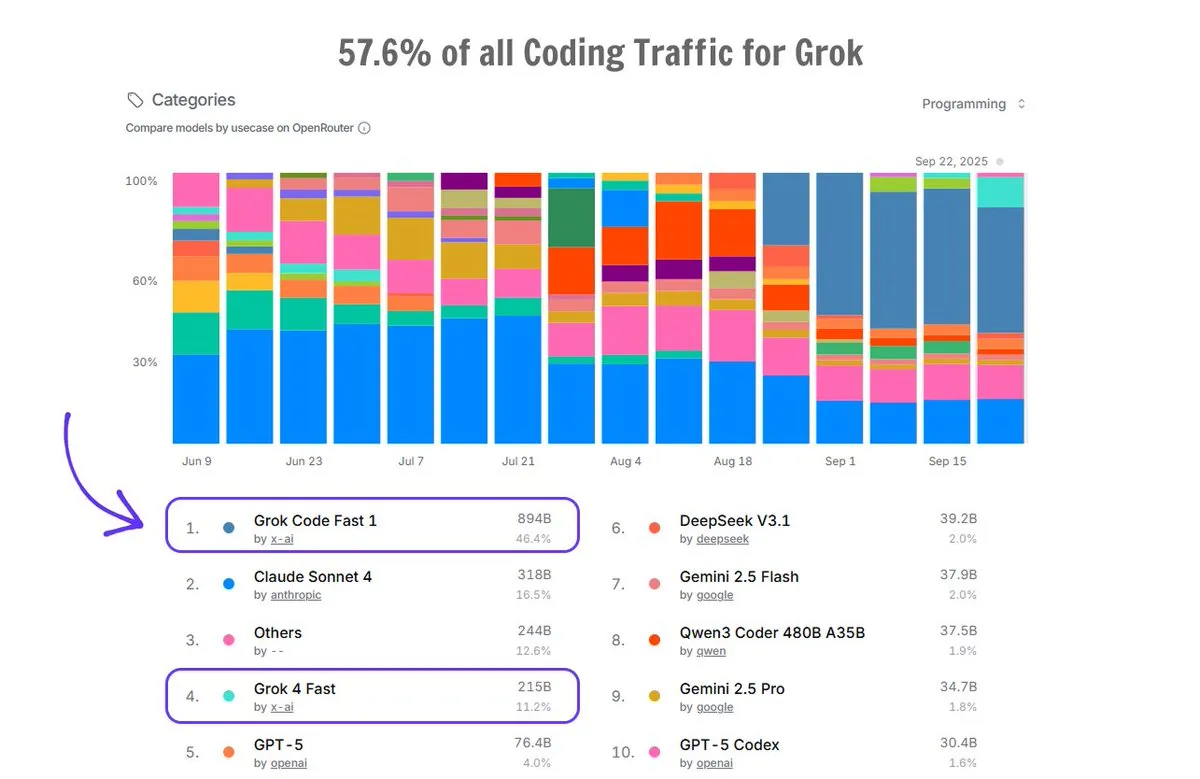
Grok Code在OpenRouter上的应用 : Grok Code在OpenRouter平台上占据了57.6%的编码流量,超过所有其他AI代码生成器的总和,其中Grok Code Fast 1排名第一,显示其在代码生成领域的强大市场表现和用户青睐。 (来源: imjaredz)
📚 学习
AI基础课程Cursor Learn : Lee Robinson推出Cursor Learn,一个免费的六部分视频系列课程,旨在帮助初学者掌握tokens、context和agents等AI基础概念。课程时长约1小时,提供测验和AI模型试用,是学习AI基础知识的便捷资源。 (来源: crystalsssup)
Python数据结构免费书籍 : Donald R. Sheehy发布了一本名为《A First Course on Data Structures in Python》的免费书籍,涵盖数据结构、算法思维、复杂性分析、递归/动态规划和搜索方法,为AI和机器学习领域的学习者提供坚实的基础。 (来源: TheTuringPost)

dots.ocr多语言OCR模型 : 小红书Hi Lab发布dots.ocr,一个强大的多语言OCR模型,支持100种语言,能端到端解析文本、表格、公式和布局(输出为Markdown),并免费商用。该模型体积小巧(1.7B VLM),但在OmniDocBench和dots.ocr-bench上达到SOTA性能。 (来源: mervenoyann)

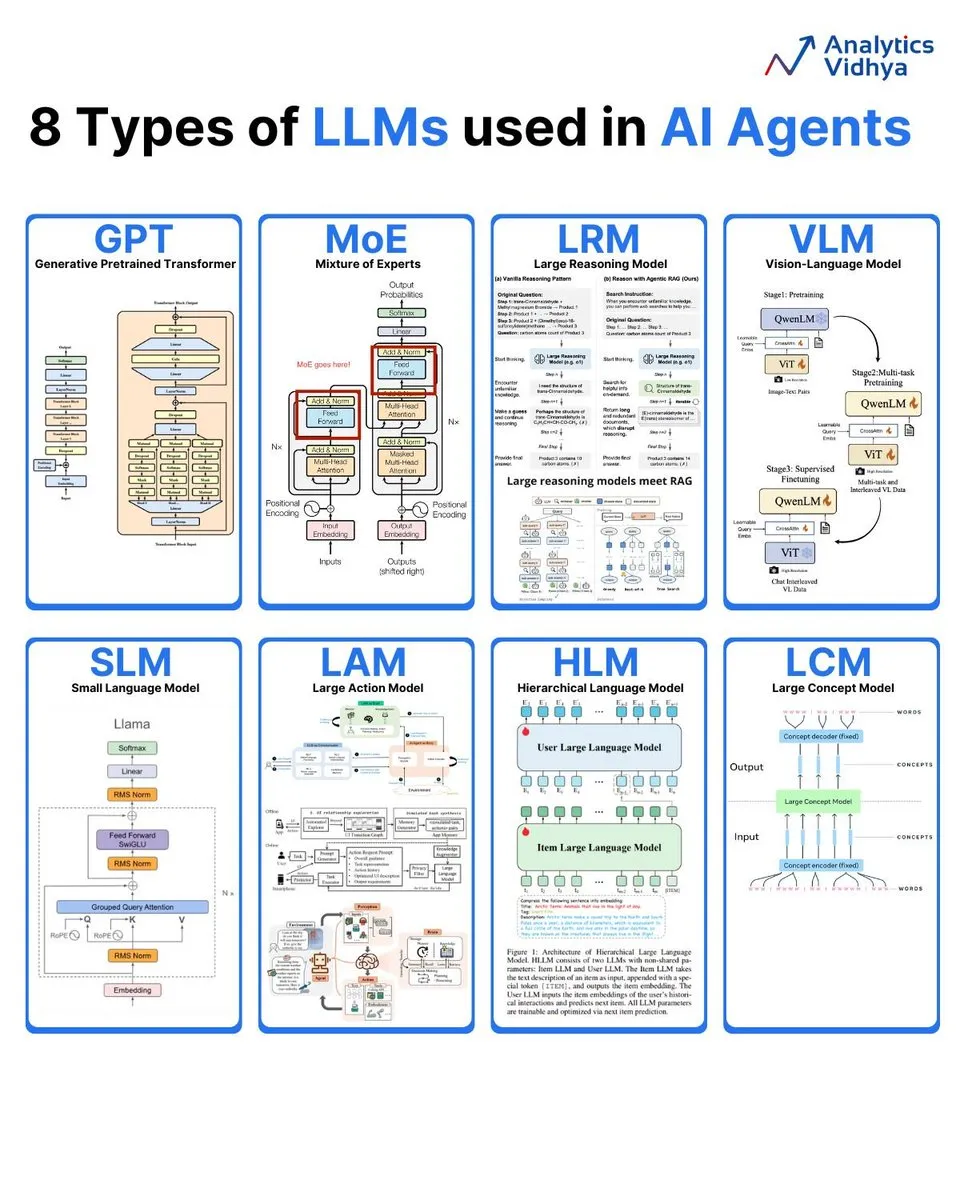
8种大语言模型类型解析 : Analytics Vidhya总结了8种主流大语言模型类型,包括GPT(生成式预训练变换模型)、MoE(混合专家模型)、LRM(大推理模型)、VLM(视觉语言模型)、SLM(小语言模型)、LAM(大行为模型)、HLM(分层语言模型)和LCM(大概念模型),详细解读其架构和应用。 (来源: karminski3)
AI周报:最新论文总结 : DAIR.AI发布本周AI论文精选(9月22-28日),涵盖ATOKEN、LLM-JEPA、Code World Model、Teaching LLMs to Plan、Agents Research Environments、Language Models that Think, Chat Better、Embodied AI: From LLMs to World Models等多个前沿研究,为AI研究者提供最新动态。 (来源: dair_ai)
AI时代年轻研究者建议 : Jascha Sohl-Dickstein分享了在“人类世”最后阶段,年轻研究者如何选择研究项目和做出职业决策的实用建议。他探讨了AGI对学术生涯的深远影响,并强调在AI系统将超越人类智能的背景下,需要重新思考研究方向和专业发展。 (来源: mlpowered)
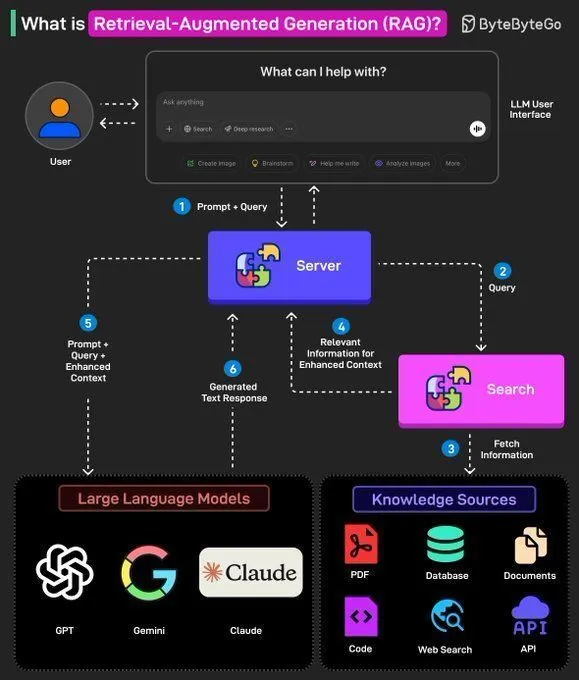
RAG概念与AI Agent构建 : Ronald van Loon分享了RAG(检索增强生成)的基本概念及其在LLM中的重要性,并提供了构建AI Agent的8个关键步骤。内容涵盖AI Agent的概念、堆栈、优势以及如何通过框架进行评估,为AI开发者提供了从理论到实践的指导。 (来源: Ronald_vanLoon, Ronald_vanLoon)
Meta解决LLM推理低效问题 : Meta研究揭示LLM在长思维链中存在重复性工作导致的推理低效问题。他们提出通过将重复步骤压缩为小型命名行为,让模型调用这些行为而非重新推导,从而减少token消耗,提升推理效率和准确性,为优化LLM推理过程提供了新思路。 (来源: ylecun)

Veo-3视觉推理能力显现 : Lisan al Gaib指出,Veo-3视频模型展现出与GPT-3类似的涌现(视觉)推理能力,预示着原生多模态模型在充分发挥其潜力后,将带来更全面的视觉理解和推理效益。 (Source: scaling01)

💼 商业
OpenAI千亿赌局与AI基建泡沫 : OpenAI正以烧钱速度编织一张横跨芯片、云计算与数据中心的巨型网络,包括Nvidia的1000亿美元注资和与Oracle的3000亿美元“星际之门”合作。尽管2025年营收预计仅130亿美元,但OpenAI管理层认为AI基建投入是“百年一遇的机遇”,引发了AI基建是否面临互联网泡沫的争议。 (来源: 36氪)

马斯克第六次起诉OpenAI : 马斯克旗下xAI公司第六次起诉OpenAI,指控其系统性挖角员工、非法窃取Grok大模型源代码及数据中心战略计划等商业机密。此次诉讼标志着两家AI巨头之间的竞争进入白热化阶段,马斯克认为OpenAI已背离其非营利初心,而OpenAI则否认指控,称其为“持续骚扰”。 (来源: 36氪)

顶级AI科学家许主洪加盟阿里通义 : 全球顶尖AI科学家、IEEE Fellow许主洪(Steven Hoi)已加盟阿里通义实验室,将转向多模态大模型的基础前沿研发。许主洪拥有20多年AI产学研经验,曾任Salesforce副总裁并创立HyperAGI,此次加盟标志着阿里在多模态大模型领域再投重码,以加速模型迭代效率和多模态创新突破。 (来源: 36氪)

🌟 社区
ChatGPT 4o性能下降与用户情绪 : 大量ChatGPT用户反映4o模型性能下降,出现“缩水”和“安全路由”问题,导致用户感到沮丧和被欺骗。许多神经多样性用户尤其悲伤,认为4o曾是他们沟通和自我理解的“生命线”。用户普遍质疑OpenAI缺乏透明度,并呼吁其兑现“对待成年用户”的承诺,反对不明确的审查机制。 (来源: Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT, Reddit r/ChatGPT)

AI时代就业与裁员争议 : 社区热议AI对就业市场的影响,包括初级岗位数量显著下降、企业裁员与AI投资并行,以及AI裁员理由的真实性。讨论指出“懂AI的人取代不懂AI的人”的趋势,并呼吁企业重新设计入门级工作而非简单裁撤,以培养适应AI时代需求的稀缺人才。 (来源: 36氪, 36氪, Reddit r/artificial)

LLM研究的挑战与门槛 : 社区热议机器学习研究门槛日益增高,个人研究者难以与大型科技巨头竞争。面临海量论文、昂贵算力、复杂数学理论等挑战,许多人感到难以入门和取得突破,引发对领域可持续性的担忧。 (来源: Reddit r/MachineLearning)
MoE模型对本地托管的影响 : 社区深入讨论MoE模型对本地LLM托管的优缺点。观点认为MoE模型虽占用更多VRAM,但计算效率高,且能通过CPU卸载实现更大模型运行,尤其适合内存充足但GPU受限的消费级硬件,是提高LLM性能的有效途径。 (Source: Reddit r/LocalLLaMA)
AI Agents快速发展与应用 : 社区讨论AI Agents的快速发展,其能力在不到一年内从“几乎不可用”迅速提升到在狭义场景下“表现良好”,甚至“通用Agent开始有用”,其进步速度超出预期。然而,也有观点认为当前编码Agent同质化严重,缺乏显著差异。 (Source: nptacek, HamelHusain)
RL研究趋势与GRPO争议 : 社区深入讨论强化学习(RL)研究的最新趋势,特别是GRPO算法的地位和争议。有观点认为RL研究正向预训练/建模转变,GRPO是重要的开源进展,但也有OpenAI员工认为其显著落后于前沿技术,引发关于算法创新与实际性能的激烈讨论。 (来源: natolambert, MillionInt, cloneofsimo, jsuarez5341, TheTuringPost)

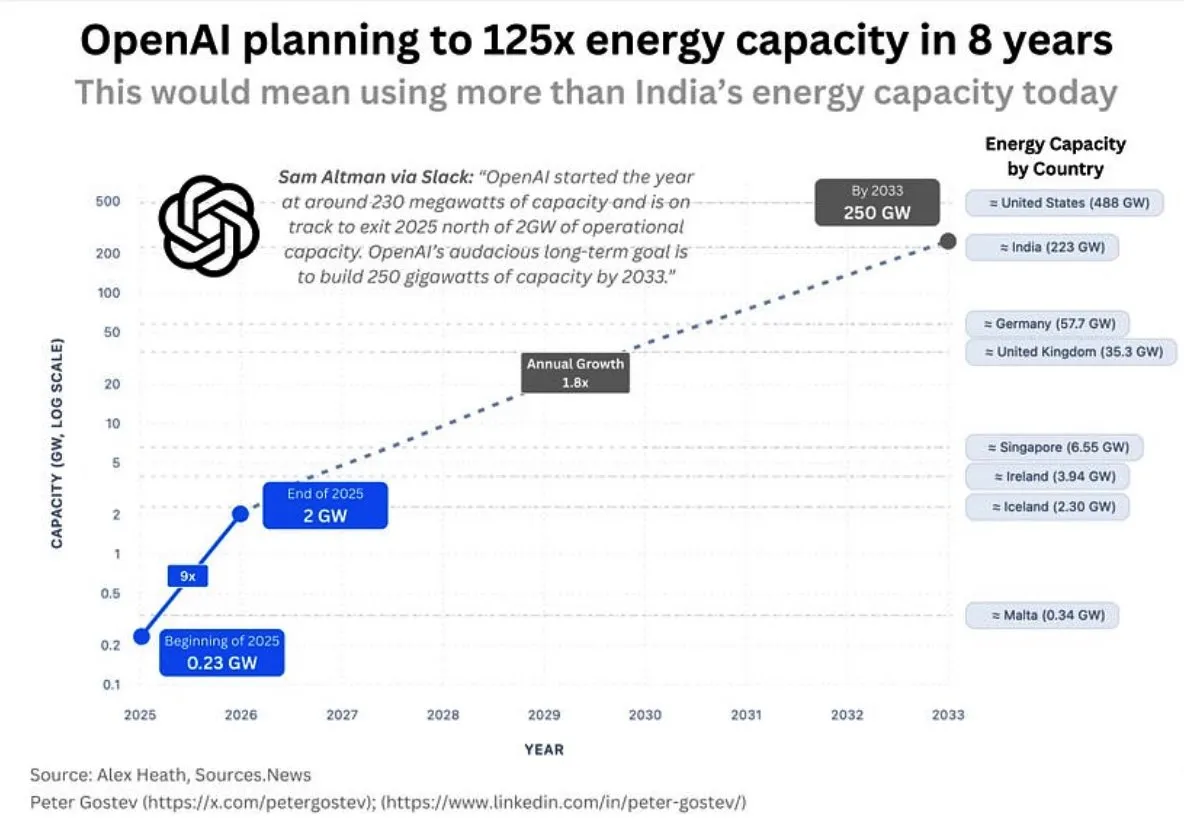
OpenAI能源消耗与AI基础设施 : 社区讨论OpenAI未来巨大的能源需求,预计其五年内将消耗超过英国或德国的能源,八年内超过印度,引发对AI基础设施建设规模、能源供应以及环境影响的担忧。同时,Google数据中心选址也因水资源消耗问题遭到当地居民反对。 (Source: teortaxesTex, brickroad7)
Sutton的Bitter Lesson与AI发展 : 社区讨论Richard Sutton的“Bitter Lesson”对AI研究的启示,强调通用计算方法优于人类先验知识。讨论围绕“模仿与世界模型”的关系展开,认为单纯模仿可能导致“货物崇拜”,而缺乏真实经验的模仿存在根本局限。 (Source: rao2z, jonst0kes)
💡 其他
BionicWheelBot仿生机器人 : BionicWheelBot机器人通过模仿车轮蜘蛛的翻滚动作,实现了在复杂地形上的多功能导航。这项创新展示了仿生学在机器人设计中的应用潜力,为未来机器人应对多变环境提供了新的解决方案。 (来源: Ronald_vanLoon)
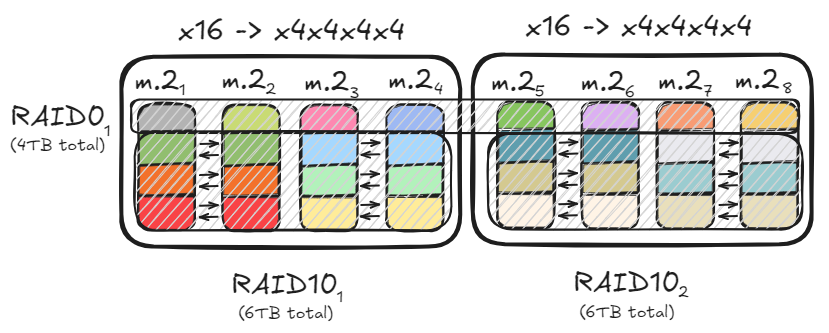
PC存储优化与RAID配置 : 用户分享如何通过RAID0和RAID10配置,利用多PCIe通道和M.2硬盘,实现高达47GB/s的数据吞吐量,以加速加载大型模型。这种优化方案在满足高速读写需求的同时,兼顾了存储容量和数据冗余,为本地AI模型部署提供了高效硬件基础。 (来源: TheZachMueller)
良渚“数栖湾AI+产业社区”开园 : 杭州良渚“数栖湾AI+产业社区”正式开园,聚焦人工智能、数字游民经济和文化创意等前沿领域。该社区通过“数栖八条”专项政策和“四场”空间布局,为AI探索者提供从创意萌芽到生态领航的全周期支持,旨在打造一个技术与人文深度融合的创新生态。 (来源: 36氪)
