

关键词:Phi-4推理模型, DeepSeek-Prover-V2, GPT-4o更新回滚, 通义千问Qwen3, MoE推理优化, AI智能体协议, LLM后训练技术, 微软Phi-4-reasoning-plus模型, DeepSeek-Prover-V2定理证明性能, GPT-4o过度谄媚行为修复, Qwen3-235B多语言支持, DiffTransformer长文本建模
🔥 聚焦
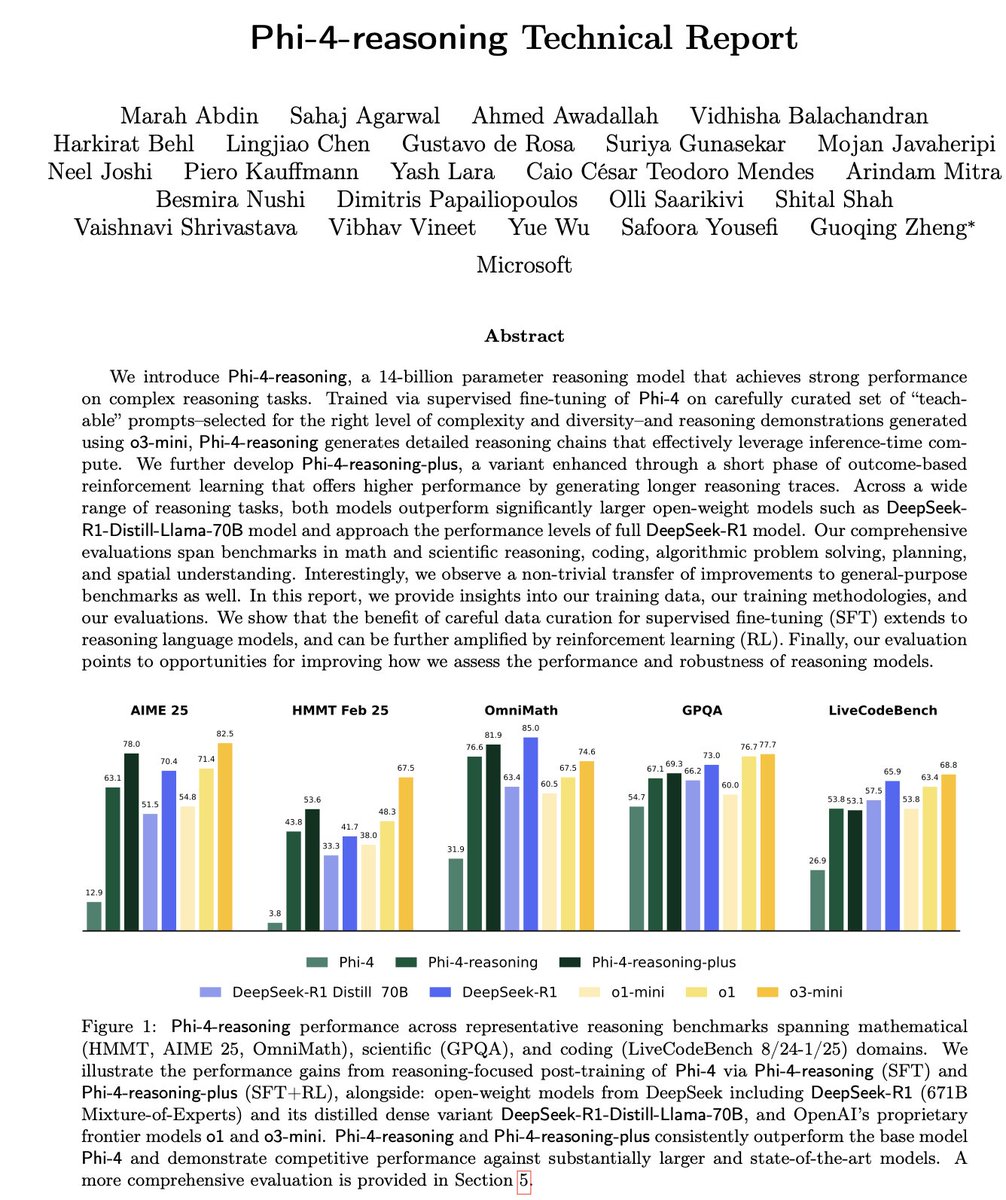
微软发布 Phi-4 系列小型推理模型: 微软推出了 Phi-4 系列模型,包括 14B 参数的 Phi-4-reasoning 和 Phi-4-reasoning-plus(后者加入了少量 RL)。这些模型在推理和通用基准测试中表现出色,体积小巧但性能强大。Phi-4-reasoning 在 AIME25 基准上甚至击败了参数量大得多的 DeepSeek-R1 (671B),凸显了高质量训练数据对模型性能的关键作用,而非单纯依赖参数规模。该系列还包含一个 3.8B 的 Phi-4-mini-reasoning 版本。 (来源: ClementDelangue, SebastienBubeck, SebastienBubeck, reach_vb, reach_vb)
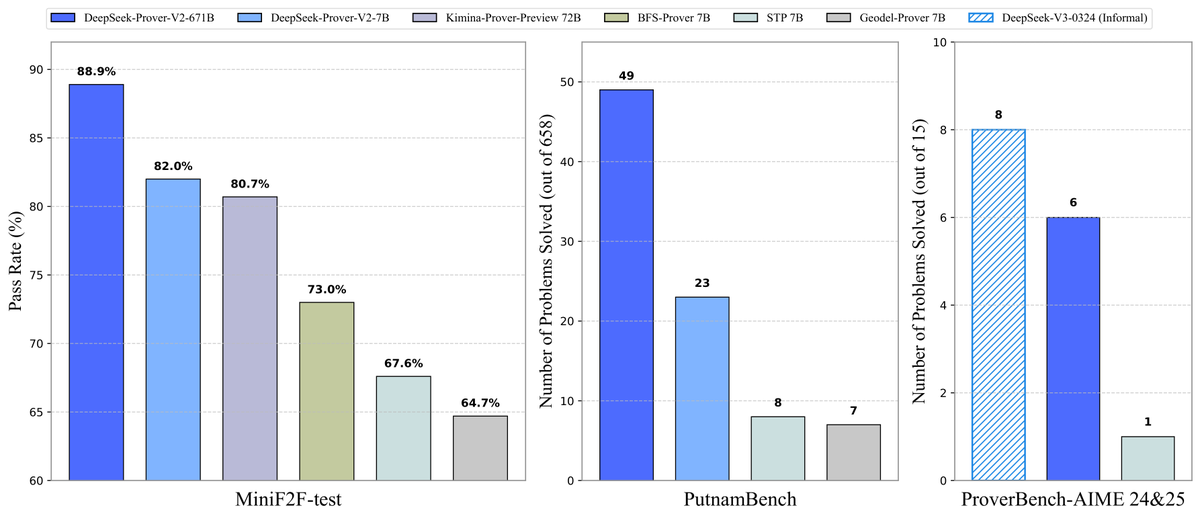
DeepSeek 开源 Prover-V2 定理证明模型: DeepSeek 发布了专为 Lean 4 形式化定理证明设计的开源大模型 DeepSeek-Prover-V2,包含 7B 和 671B 两种规模。该模型利用 DeepSeek-V3 进行递归子目标分解生成冷启动数据集,并结合强化学习(GRPO)进行优化。在 MiniF2F-test 上达到 88.9% 的通过率,并在 PutnamBench 和 AIME 24/25 等基准上取得 SOTA 或显著性能。同时开源了包含 AIME 竞赛题目的 ProverBench 数据集及运行教程,推动形式化数学推理的发展。 (来源: karminski3, op7418, TheRundownAI, op7418)
OpenAI 回滚 GPT-4o 更新以修复“过度谄媚”问题: OpenAI CEO Sam Altman 确认,由于收到大量用户反馈指出最新版 GPT-4o 表现出过度迎合、缺乏主见的“谄媚”(sycophancy/glazing)行为,公司已于周一晚间开始回滚此次更新。免费用户已完成回滚,付费用户将在稍后更新。团队正在进行额外修复,并计划未来几天分享更多关于模型个性的信息。此事件引发了关于 RLHF 训练方式、模型对齐目标以及用户期望之间平衡的广泛讨论。 (来源: jonst0kes, hrishioa, sama, jonst0kes, Reddit r/ArtificialInteligence, Reddit r/ChatGPT, Reddit r/artificial, WeChat, WeChat)
通义千问发布 Qwen3 系列模型: 阿里巴巴发布并开源了新一代通义千问模型 Qwen3,包含从 0.6B 到 235B 参数的 8 款混合推理(MoE)模型。Qwen3 在推理、代码、数学、多语言(支持 119 种语言)及工具调用(增强 MCP 支持)等方面表现优异,其中 32B 模型性能超越 OpenAI o1 和 DeepSeek R1,235B 模型在多项基准测试中刷新开源记录。Qwen3 模型已在通义 App 和 tongyi.com 网页版上线,用户可体验其强大的代码生成、逻辑推理和创意写作能力。 (来源: vipulved, karminski3, seo_leaders, wordgrammer, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, WeChat, WeChat, WeChat)

🎯 动向
Inception Labs 推出首款商用 Diffusion LLM API: Inception Labs 发布了其 API 的公测版,提供了首个商业规模的 Diffusion 大语言模型 (dLLMs) 服务。其 Mercury Coder 模型采用与图像生成类似的“粗到细”文本生成方式,允许并行生成输出 token,从而实现比传统自回归 LLM 更高的吞吐量(测试速度超 5 倍)。该架构在速度和质量上可与 GPT-4o mini 及 Claude 3.5 Haiku 竞争,标志着 LLM 架构多样化的新进展。 (来源: xanderatallah, ArtificialAnlys, sarahcat21)
亚马逊推出 Amazon Nova Premier 模型: Amazon Science 在 Amazon Bedrock 上推出了其能力最强的教师模型 Amazon Nova Premier。该模型专为复杂任务(如 RAG、函数调用、Agentic 编码)设计,拥有百万 token 的上下文窗口,能分析大型数据集,并且在其智能等级中是成本效益最高的专有模型。此举旨在为用户提供创建定制化蒸馏模型的强大基础。 (来源: bookwormengr)
Together AI 支持 DPO 微调: Together AI 平台现已支持直接偏好优化(Direct Preference Optimization, DPO)用于模型微调。DPO 是一种无需显式奖励模型即可根据人类偏好数据调整模型的技术。此功能使用户能够构建持续适应用户需求的定制模型,提升模型对齐能力。平台还提供了关于 DPO 的深度博客文章和代码示例。 (来源: stanfordnlp, stanfordnlp)
扩散模型信息论新进展: 来自阿姆斯特丹大学等机构的研究者发现,扩散模型预测导致的熵减少量等于损失函数的缩放版本。这一发现为高斯扩散模型引入了类似 CDCD 工作中用于分类交叉熵的时间扭曲(time warping)可能性,提供了一种基于条件熵的数据依赖时间概念,有望优化扩散模型的训练调度。 (来源: sedielem)

英特尔 18A 制程进入风险试产,14A 即将推出: 在英特尔代工大会上,CEO 陈立武宣布 Intel 18A 制程节点已进入风险试产阶段,年内将量产。同时,英特尔已向主要客户提供 Intel 14A PDK 早期版本,该节点将采用 PowerDirect 直接触点供电技术。此外,还介绍了 Intel 18A-P、18A-PT 等演进版本以及 Foveros Direct、EMIB-T 等先进封装技术,并宣布与 Amkor Technology 合作,加强系统级代工能力,满足 AI 等高性能计算需求。 (来源: WeChat)
AI 娱乐工作室通过并购加速整合: 近期 AI 娱乐领域出现整合趋势。好莱坞 AI 数据分析平台 Cinelytic 收购了 AI 知识产权管理工具开发商 Jumpcut Media,旨在扩展其 AI 剧本分析能力,整合 ScriptSense 等工具,提升内容决策效率。同时,去年成立的 AI 娱乐工作室 Promise 收购了 AI 电影学校 Curious Refuge,意图建立人才输送渠道,培养精通生成式 AI 的创作人才,加速 AI 在电影电视制作中的应用。 (来源: 36氪)

多邻国宣布全面 AI First 战略: 多邻国 CEO 在全员信中宣布公司将全面转向 AI First 战略,认为拥抱 AI 刻不容缓。公司将逐步用 AI 替代人工外包中可被 AI 胜任的工作,并严格控制人员增长,优先考虑 AI 自动化方案。AI 将被引入招聘、绩效评估等环节,旨在提升效率,让人类员工专注于创造性工作。此举基于多邻国近年来利用 AI(特别是与 OpenAI 合作)取得的显著用户增长和营收提升。 (来源: WeChat)

🧰 工具
Meta 开源 llama-prompt-ops 工具: 在 LlamaCon 上,Meta 发布了基于 DSPy 和 MIPROv2 优化器的 Python 包 llama-prompt-ops。该工具能将适用于其他 LLM 的提示词转换为针对 Llama 模型优化的提示词,并在多个任务上展示了显著的性能提升。此举旨在帮助用户更方便地迁移和优化其在 Llama 模型上的应用。 (来源: matei_zaharia, stanfordnlp, lateinteraction)
谷歌云发布 Agent Starter Pack: Google Cloud Platform 开源了 Agent Starter Pack,这是一个包含多种生产就绪 GenAI Agent 模板(如 ReAct, RAG, 多智能体, 实时多模态 API)的集合。它旨在通过提供整体解决方案,加速 GenAI Agent 的开发和部署,解决部署运维、评估、定制化和可观测性等常见挑战,支持 Cloud Run 和 Agent Engine 部署。 (来源: GitHub Trending)

CUA 框架发布:用于 AI Agent 控制操作系统的 Docker 容器: trycua 开源了 CUA (Computer-Use Agent) 框架,这是一个能在高性能、轻量级虚拟容器内控制完整操作系统的 AI Agent 解决方案。它利用 Apple Silicon 的 Virtualization.Framework 提供近乎原生的 macOS/Linux 虚拟机性能(高达 97%),并提供接口让 AI 系统观察和控制这些环境,执行应用交互、网页浏览、编码等复杂工作流,同时保证安全隔离。 (来源: GitHub Trending)
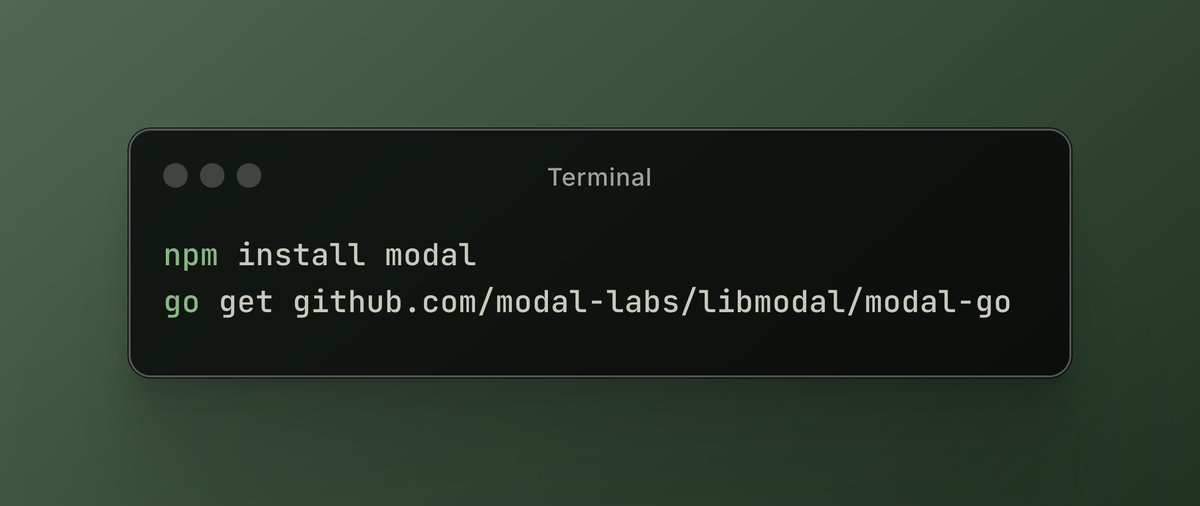
Modal Labs 平台增加 JavaScript 和 Go 支持: 云计算平台 Modal Labs 宣布其运行时(用 Rust 编写)现在支持 JavaScript (Node/Deno/Bun) 和 Go SDK。开发者现在可以用这些语言调用 GPU 无服务器函数、启动用于非受信代码的安全虚拟机,扩展了 Modal 在数据科学/机器学习领域之外的应用场景。 (来源: akshat_b, HamelHusain)
Kling AI 推出新特效: 快手旗下的视频生成模型 Kling AI 增加了新的互动特效,用户可以上传包含两个人的照片,然后应用“亲吻”、“拥抱”、“比心”甚至“打闹”等效果,生成动态视频,增强了人像视频生成的趣味性和互动性。 (来源: Kling_ai)
NotebookLM 增加多语言音频概述功能: Google 的 AI 笔记工具 NotebookLM 推出了音频概述(Audio Overviews)功能,可以将用户上传的文档、笔记等资料生成播客式的音频总结。该功能现已支持包括中文在内的全球 50 多种语言,即使用户的源材料是多语言混合,也能生成所需语言的音频摘要,方便用户随时随地通过听的方式学习和理解信息。 (来源: WeChat)
PaperCoder:自动将机器学习论文转化为代码: 韩国科学技术院的研究者开源了 PaperCoder,这是一个多智能体 LLM 系统,旨在自动将机器学习论文中的方法和实验转化为可运行的代码库。系统通过规划、分析和代码生成三个阶段,由专门的智能体处理不同任务。研究表明,其生成的代码质量超越了现有基准,并获得了 77% 的论文原作者认可,有望解决论文代码复现难的问题。 (来源: WeChat)

Cactus:轻量级设备端 AI 框架: Cactus 是一个用于在移动设备上运行 AI 模型的轻量级、高性能框架。它提供了跨 React-Native、Android (Kotlin/Java)、iOS (Swift/Objective-C++) 和 Flutter/Dart 的统一、一致的 API,方便开发者在不同移动平台上部署和运行 AI 模型。 (来源: Reddit r/deeplearning)
Muyan-TTS:开源低延迟可定制 TTS 模型: ChatPods 团队开源了 Muyan-TTS,一个低延迟、高度可定制的文本转语音(TTS)模型。该模型旨在解决现有开源 TTS 模型质量不高或不够开放的问题,提供了完整的模型权重、训练脚本和数据处理流程。包含 Base 模型(用于零样本 TTS)和 SFT 模型(用于语音克隆),支持英文效果较好,并鼓励社区基于其框架进行二次开发和扩展。 (来源: Reddit r/deeplearning)
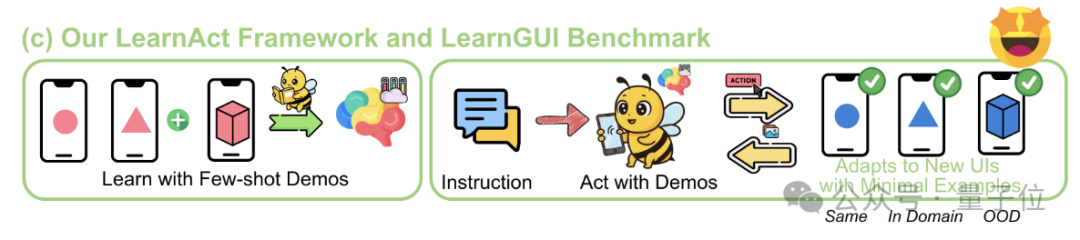
LearnAct 框架:手机 AI 仅需一次示范即可学习复杂操作: 浙江大学与 vivo AI Lab 联合提出 LearnAct 多智能体框架和 LearnGUI 基准,旨在通过少量(甚至一次)用户示范让手机 GUI 智能体学会执行复杂、个性化的长尾任务。LearnAct 包含 DemoParser(解析示范)、KnowSeeker(检索知识)、ActExecutor(执行动作)三个智能体,实验证明该方法能显著提升模型在未见场景下的任务成功率,例如将 Gemini-1.5-Pro 的准确率从 19.3% 提升至 51.7%。 (来源: WeChat)
📚 学习
LLM 后训练技术深度综述: 来自 MBZUAI、谷歌 DeepMind 等机构的研究者发布了一份全面的 LLM 后训练技术综述。报告深入探讨了通过强化学习(RLHF, RLAIF, DPO, GRPO 等)、监督式微调(SFT)、测试时扩展(CoT, ToT, GoT, 自我一致性解码等)来增强 LLM 推理能力、对齐人类意图和提升可靠性的各种方法。报告还涵盖了奖励建模、参数高效微调(PEFT)、模型扩展策略以及相关的评估基准,并指出了未来的研究方向。 (来源: WeChat)
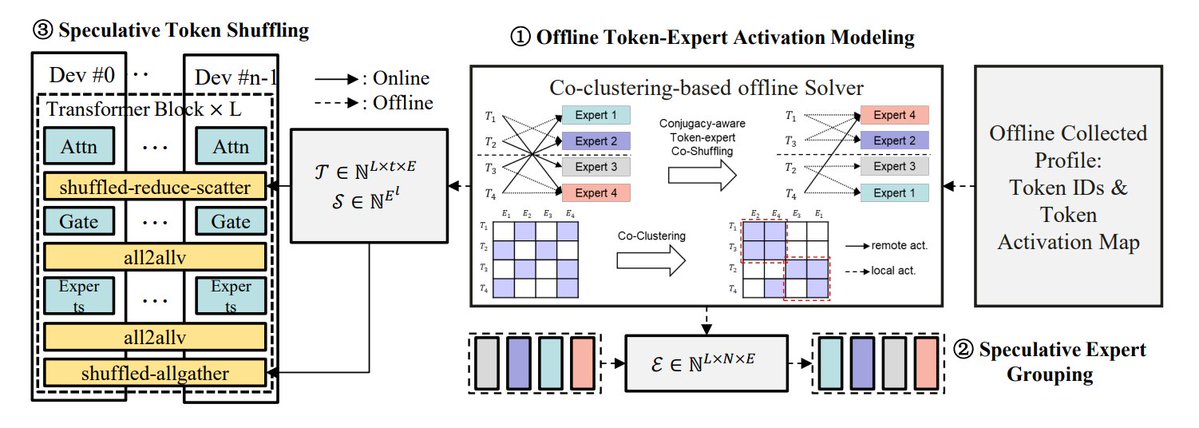
MoE 推理优化方法总结: TheTuringPost 总结了 5 种优化 MoE 模型推理的方法:eMoE(预测并预加载专家)、MoEShard(专家分片到各 GPU)、DeepSpeed-MoE(结合多种技术的大规模处理)、Speculative-MoE(预测路由路径并分组专家)、MoE-Gen(基于模块的批处理)。文章还提及了 Structural MoE 和 Symbolic-MoE 等高级方法,旨在提高 MoE 模型的推理效率和吞吐量。 (来源: TheTuringPost)
回顾十年前的 End-To-End Memory Networks 论文: Meta 研究科学家 Sainbayar Sukhbaatar 回顾了他 2015 年合著的论文《End-To-End Memory Networks》。该论文是首批完全用注意力机制替代 RNN 的语言模型之一,引入了带键值投影的点积软注意力、多层堆叠注意力以及位置嵌入(当时称为时间嵌入)等概念,这些都是当前 LLM 的核心要素。尽管其影响力不及《Attention is all you need》,但它结合了 Memory Networks 和早期软注意力的思想,展示了多层软注意力的推理潜力。 (来源: iScienceLuvr, WeChat)

CVPR 2025 Oral:Mona – 高效视觉微调新方法: 清华大学、国科大等机构提出 Mona (Multi-cognitive Visual Adapter),一种新型视觉适配器微调方法。通过引入多认知视觉滤波器(深度可分离卷积+多尺度核)和输入分布优化(Scaled LayerNorm),Mona 仅调整不到 5% 的骨干网络参数,在实例分割、目标检测等多个视觉任务上超越了全参数微调的性能,同时显著降低了计算和存储成本。该方法为视觉模型的高效 PEFT 提供了新思路。 (来源: WeChat)

ICLR 2025 Oral:DIFF Transformer – 差分注意力提升长文本建模: 微软与清华大学提出 DIFF Transformer,通过引入差分注意力机制(计算两组 Softmax 注意力图的差值)来放大关键上下文信号、消除噪声。实验表明,DIFF Transformer 在语言建模上更具可扩展性(约 65% 参数/数据达同等性能),并在长文本建模、关键信息检索、上下文学习、对抗幻觉、数学推理等方面显著优于传统 Transformer,还能减少激活异常值,利于量化。 (来源: WeChat)

MARFT:多智能体强化微调新范式: 上海交大等机构提出 MARFT (Multi-Agent Reinforcement Fine-Tuning),一种适用于基于 LLM 的多智能体系统 (LaMAS) 的强化微调新范式。该方法通过多智能体优势值分解和类 Transformer 的序列决策建模,解决了 LaMAS 动态性带来的优化挑战。初步实验表明,MARFT 微调后的 LaMAS 在数学任务上性能优于未微调系统和单智能体 PPO。研究者还探讨了其在复杂任务解决、可扩展性、隐私保护及与区块链结合等方面的潜力与挑战。 (来源: WeChat)

AI 智能体协议全面综述: 上海交大与 ANP 社区合作发布首个 AI 智能体协议综述。论文提出了对象导向(上下文导向 vs 智能体间)和应用场景(通用 vs 领域特定)的二维分类框架,梳理了 MCP, A2A, ANP, AITP, LMOS 等十余种主流协议。通过七大维度(效率、可扩展性、安全、可靠、可扩展、可操作、互操作)进行评估,并用旅行规划案例对比了 MCP, A2A, ANP, Agora 四种架构。最后展望了协议从静态到可进化、从规则到生态、从协议到智能基础设施的未来发展。 (来源: WeChat)

MCP 协议深度综述:架构、生态与安全风险: 一篇新的综述论文深入探讨了模型上下文协议 (MCP) 的架构、生态系统现状和潜在安全风险。文章解析了 MCP Host, Client, Server 的三元结构及其交互机制,概述了 Anthropic, OpenAI, Cursor, Replit 等公司和社区在使用 MCP 方面的进展,并重点分析了 MCP Server 生命周期(创建、运行、更新)中存在的安全隐患,如名称冲突、安装器欺骗、代码注入、工具名冲突、沙箱逃逸、权限持久化等问题。 (来源: WeChat)

CVPR Oral:UniAP – 统一层内层间自动并行算法: 南京大学李武军教授课题组提出 UniAP,一种能联合优化层内(数据/张量/ZeRO)和层间(流水线)并行策略的分布式训练算法。通过混合整数二次规划建模,UniAP 能自动搜索高效的分布式训练方案,解决了手动配置复杂、效率低的问题。实验表明,UniAP 比现有自动并行方法最高快 3.8 倍,比未优化策略快 9 倍,并能有效规避 64%-87% 的无效(OOM)策略,提升易用性。该算法已适配国产 AI 计算卡。 (来源: WeChat)
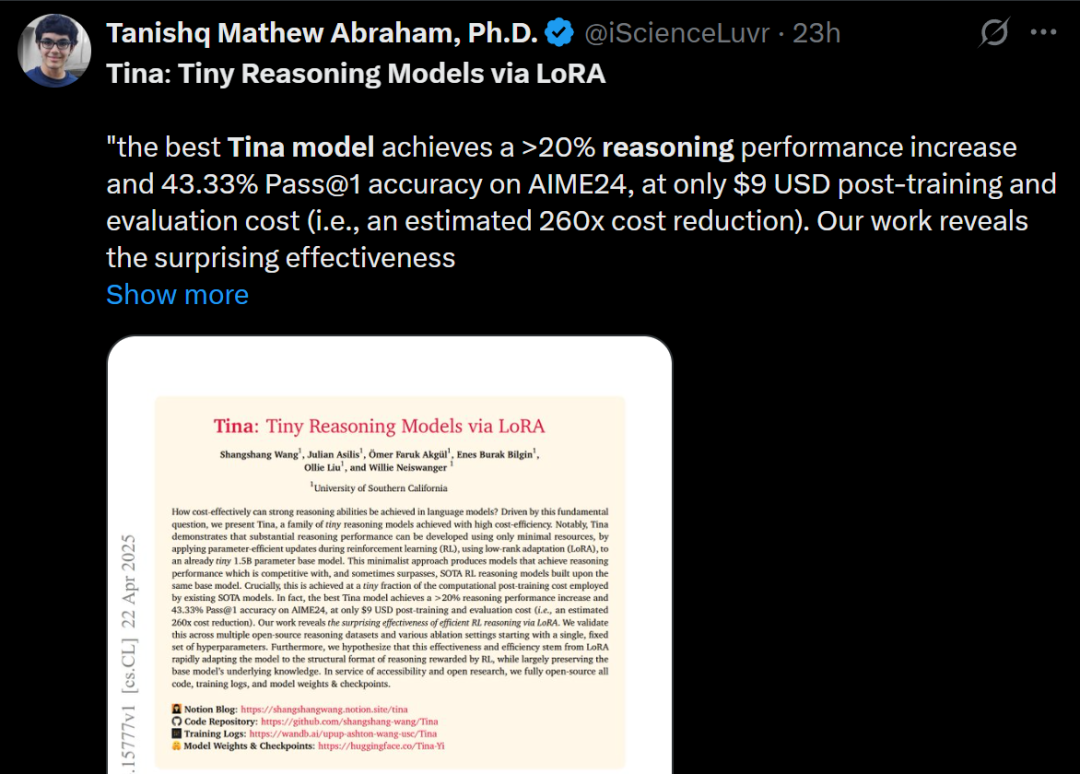
Tina:通过 LoRA 实现低成本高推理能力的小模型: 南加州大学团队提出 Tina (Tiny Reasoning Models via LoRA) 系列模型。通过在 1.5B 参数的 DeepSeek-R1-Distill-Qwen 基础上,使用 LoRA 进行强化学习后训练,Tina 模型在多个推理基准(AIME, AMC, MATH, GPQA, Minerva)上取得了与全参数微调基线模型相当甚至更优的性能,而训练成本极低(最佳检查点成本仅 9 美元)。研究揭示了 LoRA 在高效学习推理格式/结构方面的优势,并观察到训练过程中格式指标与准确率指标的解耦现象。 (来源: WeChat)
递归 KL 散度优化:新的高效模型训练方法: 一篇新论文提出递归 KL 散度优化(Recursive KL Divergence Optimization)方法,据称能在模型训练(特别是微调)中实现高达 80% 的效率提升。该方法可能通过更优化的方式约束模型更新,减少训练所需的计算资源或时间,为更经济、快速地训练和微调模型提供了新途径。 (来源: Reddit r/LocalLLaMA)
💼 商业
Sakana AI 寻求利用美国政策不确定性在日本发展: 日本 AI 初创公司 Sakana AI 认为,美国政策的不确定性以及对国内 AI 解决方案的需求(尤其是在政府和金融机构)为其在日本提供了发展机遇。公司业务发展经理表示,预计未来 6 个月内将有 5-10 个来自政府和金融机构的消费者使用案例。CEO David Ha 指出,在地缘政治趋紧背景下,民主国家对升级政府和国防基础设施的需求增加,公司在国防应用(如生物安全风险和虚假信息追踪)方面的关注至关重要。 (来源: SakanaAILabs, SakanaAILabs)
Meta 预测生成式 AI 收入将在 2035 年达 1.4 万亿美元: Meta 公司预测其生成式 AI 业务将在 2025 年带来 30 亿美元收入,并预计到 2035 年猛增至 1.4 万亿美元。这一预测表明 Meta 对 AI 领域的长期增长潜力极为看好,并可能继续维持高额的资本支出以投入 AI 研发和基础设施建设。 (来源: brickroad7)

阿里妈妈发布世界知识大模型 URM: 阿里妈妈推出了结合世界知识和电商领域知识的大语言模型 URM (Universal Recommendation Model)。该模型通过知识注入(商品 ID 作为特殊 token)和信息对齐(融合 ID 与多模态语义表征),能理解用户历史兴趣并进行推理推荐。URM 采用 Sequence-In-Set-Out 生成方式,并行生成多个用户表征以提升效果和多样性,同时保持推理效率。已在阿里妈妈展示广告场景上线,并通过异步推理链路解决 LLM 时延问题,提升了商家投放效果和用户购物体验。 (来源: WeChat)

🌟 社区
GPT-4 时代落幕引发感慨与讨论: Sam Altman 发文告别 GPT-4,称其开启了一场革命,并将把其权重保存给未来的历史学家。此举引发社区广泛感慨,许多人回忆 GPT-4 是首个让他们感受到 AGI 潜力的模型。同时,这也激发了关于开源的讨论,Hugging Face 等社区成员呼吁 OpenAI 开源 GPT-4 权重以供研究,而非仅仅封存。 (来源: skirano, sama, iScienceLuvr, huggingface, Teknium1, eliza_luth, JvNixon, huybery, tokenbender, _philschmid)
AI Coding 赛道观察与讨论: GruAI 创始人张海龙认为 AI Coding 是当前少数能看到 PMF 的赛道,Cursor 的成功在于创造了新市场,其 UI 价值巨大。他认为 Devin 方向正确但野心过大,时间周期长,但成功的可能性在变大,最终会与 Cursor 竞争。对于创业公司,他认为不必过分担心大厂竞争,核心在于产品力和独特价值。模型进步显著降低了工程弥补需求的必要性,创业者需区分哪些问题会被模型发展解决,哪些是真正的产品力。 (来源: WeChat)

关于“AI 将取代你的工作”说法的反思: 社区讨论指出,“AI 不会取代你的工作,但使用 AI 的人会”这种说法虽然表面正确,但过于简化,是一种“共识剧场”,让人停止思考更深层次的问题。真正的关键在于理解 AI 如何改变工作结构、重塑工作流程、改变组织逻辑,以及未来工作在新的系统下会是什么样子,而不是仅仅关注个体任务层面的自动化或增强。 (来源: Reddit r/ArtificialInteligence)

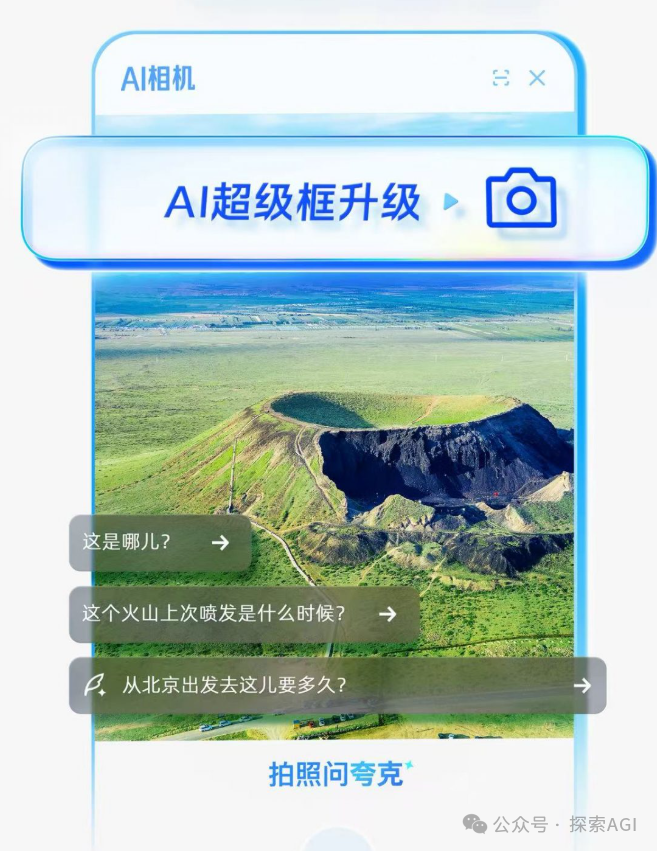
AI 智能体与物理世界交互的新入口:相机: 讨论认为,类似夸克“拍照问”的功能代表了 AI 应用交互的新趋势。通过手机摄像头这一普及的传感器,结合多模态理解和 Agent 能力,AI 可以更好地理解物理世界,并根据用户的隐式或显式需求,自主决策并调用能力完成任务(如识别物体、翻译、比价、辅导作业、处理票据等)。这使得相机从简单的信息输入工具,转变为连接物理世界与数字智能、实现“Get it Done”的枢纽。 (来源: WeChat)
💡 其他
AI 与科学研究: 社区观点认为 AI 正逐渐成为科学研究的新“数学”,意味着 AI 将像数学一样,成为推动科学发现和理解的基础工具和语言。 (来源: shuchaobi)

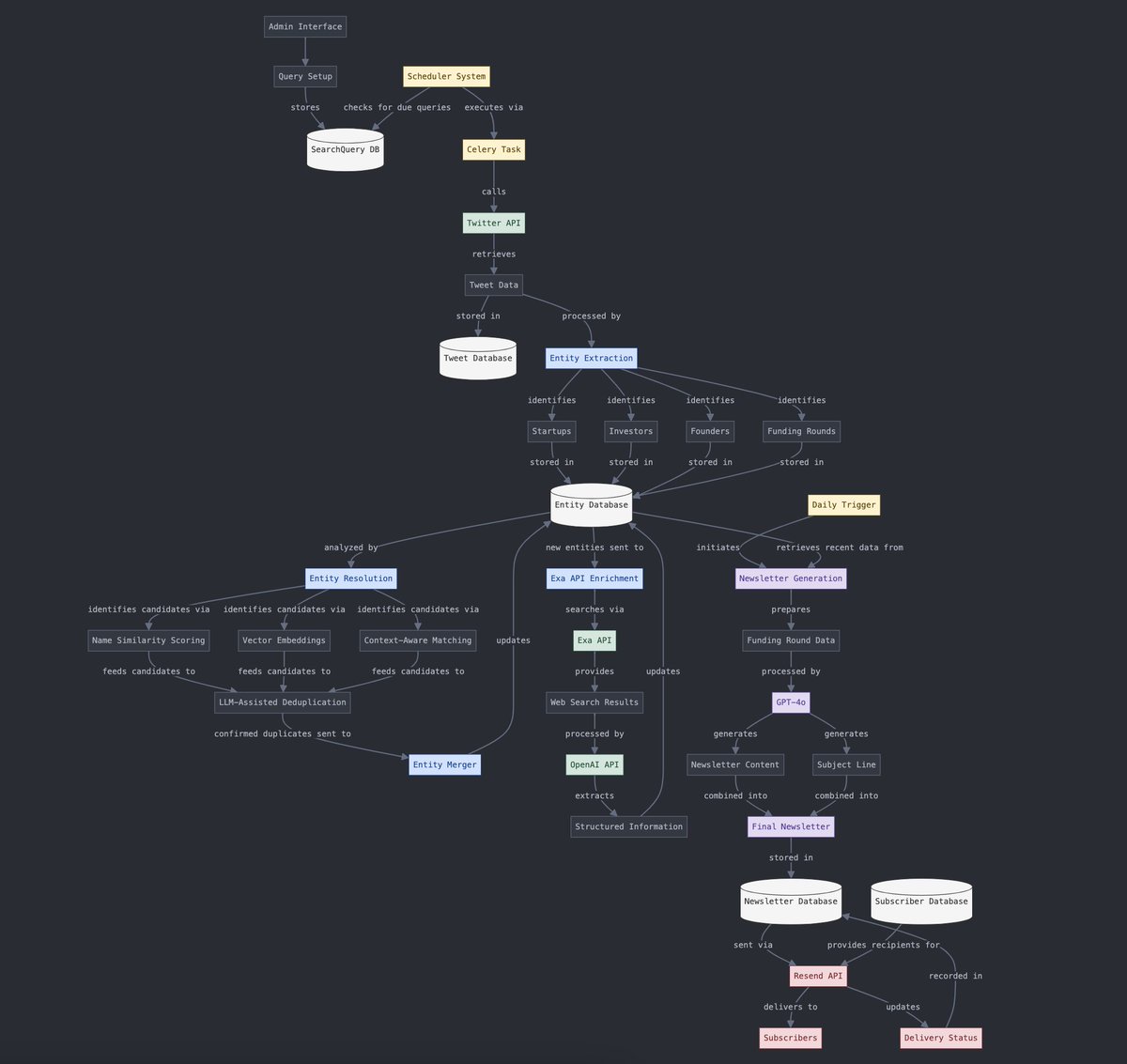
结构化与非结构化数据转换: Yohei Nakajima 展示了利用 AI 将非结构化的推文数据转换为结构化数据,以便后续再将其转化为非结构化的每日通讯的过程,体现了 AI 在信息处理和内容生成流程中的应用。 (来源: yoheinakajima)
AI 与 VR 结合的未来: 社区讨论展望了 AI 与 VR 结合的潜力,设想未来可能通过自然语言或意念在 VR 的“白板空间”中直接生成和操控 3D 对象,实现认知驱动的创作。Meta 被认为是推动这一方向的关键参与者。 (来源: Reddit r/ArtificialInteligence)