
关键词:OpenAI, AI模型, AlphaFold, AI芯片, GPT-4.1, Magi-1视频模型, Nvidia H20出口管制, 字节跳动UI-TARS-1.5, Meta MILS多模态, DeepMind AlphaFold 3, Sand.ai自回归视频, 华为Ascend 910C
🔥 聚焦
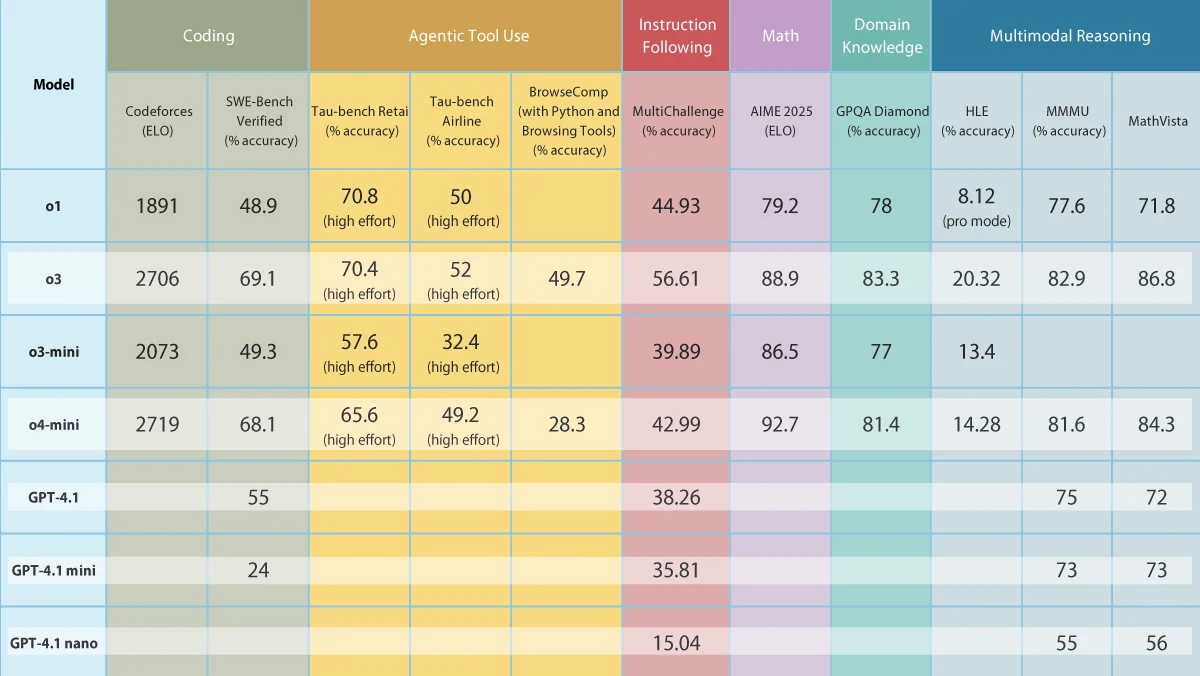
OpenAI发布五款新模型,强化通用与推理能力: OpenAI推出了GPT-4.1、GPT-4.1 mini和GPT-4.1 nano三款通用模型,以及o3和o4-mini两款推理模型。GPT-4.1系列支持高达100万token输入,旨在提供比GPT-4.5/4o更具成本效益的选择,其中GPT-4.1在编码等任务上超越了GPT-4o。o3和o4-mini是o1和o3-mini的升级版,输入限制200k token,能更好地利用工具(网络搜索、代码生成/执行、图像编辑),并首次支持对图像进行思维链处理。o3在多项基准测试中达到SOTA。同时,OpenAI宣布将于7月移除GPT-4.5预览版。此次发布旨在以更低成本提供更强性能,特别是在推理和工具使用方面。 (来源: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
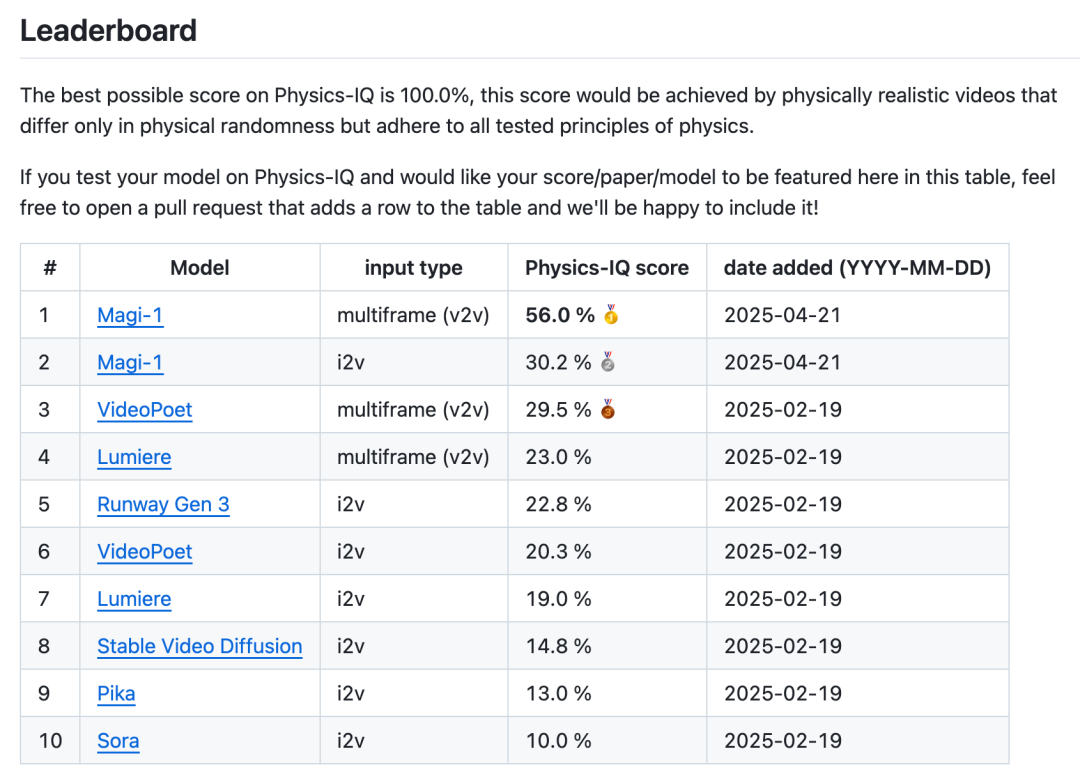
Sand.ai 开源首个高质量自回归视频模型 Magi-1: 北京初创公司 Sand.ai 发布并开源了 Magi-1,这是全球首个采用自回归架构的高质量视频生成模型。与Sora等并发生成模型不同,Magi-1采用 chunk-by-chunk 生成方式,保留了时间因果性,在物理真实性、动作连贯性和可控性方面表现突出,尤其擅长视频续写(V2V)。团队开源了从4.5B到24B参数量的模型权重、推理及训练代码,并提供了开箱即用的产品网站。该模型最低可在单张4090显卡上运行,推理资源消耗与视频长度无关,为长视频生成和实时应用带来可能。 (来源: Magi-1 开源&刷屏:首个高质量自回归视频模型,它的一切信息)
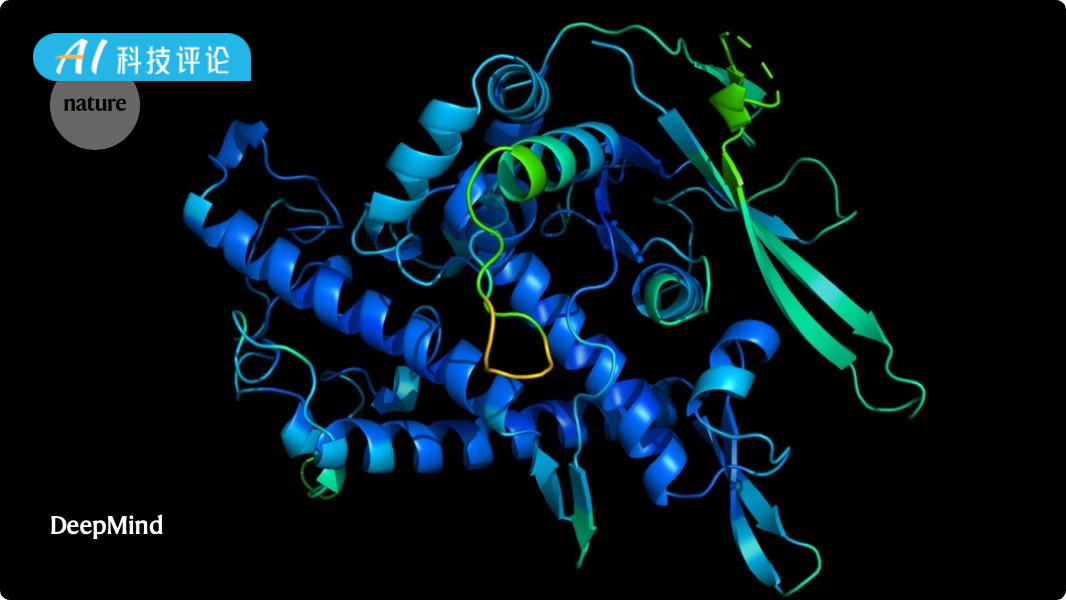
DeepMind AlphaFold 进展:一年绘制2亿蛋白质结构: Google DeepMind 创始人 Demis Hassabis 在采访中透露,其蛋白质结构预测模型 AlphaFold 在一年内绘制了超过2亿个蛋白质结构,而传统方法解析单个结构需数年。AlphaFold 3进一步扩展到DNA、RNA、配体等几乎所有生命分子,显著提升了药物设计中分子相互作用预测的准确性。Google DeepMind还推出了免费的 AlphaFold Server 平台,让生物学家能便捷利用其预测能力。尽管面临药物-蛋白质相互作用数据不足的挑战,AlphaFold正推动生物学研究进入高清时代,加速药物研发进程。 (来源: Demis 谈 AI4S 最新进展:DeepMind 的 AlphaFold 一年就画了 2 亿个蛋白质!, GoogleDeepMind)
美国加强AI芯片对华出口管制,Nvidia H20等受限: 美国政府宣布,未来向中国出口 Nvidia H20、AMD MI308 或同等性能的 AI 芯片需获得许可证。此举是美国阻止中国获取尖端 AI 硬件的持续努力的一部分。Nvidia H20 是为规避早期 H100/H200 禁令而推出的降级版芯片。新限制预计将给 Nvidia 和 AMD 分别带来55亿和8亿美元的营收损失。同时,美国国会启动对 Nvidia 是否违规协助 DeepSeek 开发模型的调查。此举促使中国加速自主 AI 芯片研发,华为计划量产 Ascend 910C 和 920 以替代 Nvidia 产品。 (来源: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

🎯 动向
字节跳动发布多模态智能体 UI-TARS-1.5: 字节跳动开源了基于视觉语言模型的的多模态智能体 UI-TARS-1.5,能够有效执行虚拟世界中的多样化任务。该模型在先前研究基础上,融合了强化学习驱动的高级推理能力,使其能在行动前进行思考,显著提升了性能和适应性。UI-TARS-1.5 在多个基准测试(如 OSworld、WebVoyager、Android World)中取得 SOTA 结果,展现出强大的推理和 GUI 操作能力,尤其在游戏(如 Poki Game、Minecraft)和屏幕元素定位(ScreenSpot-V2/Pro)方面表现优异。团队同时发布了7B参数量的 UI-TARS-1.5-7B 模型。 (来源: bytedance/UI-TARS – GitHub Trending (all/daily))

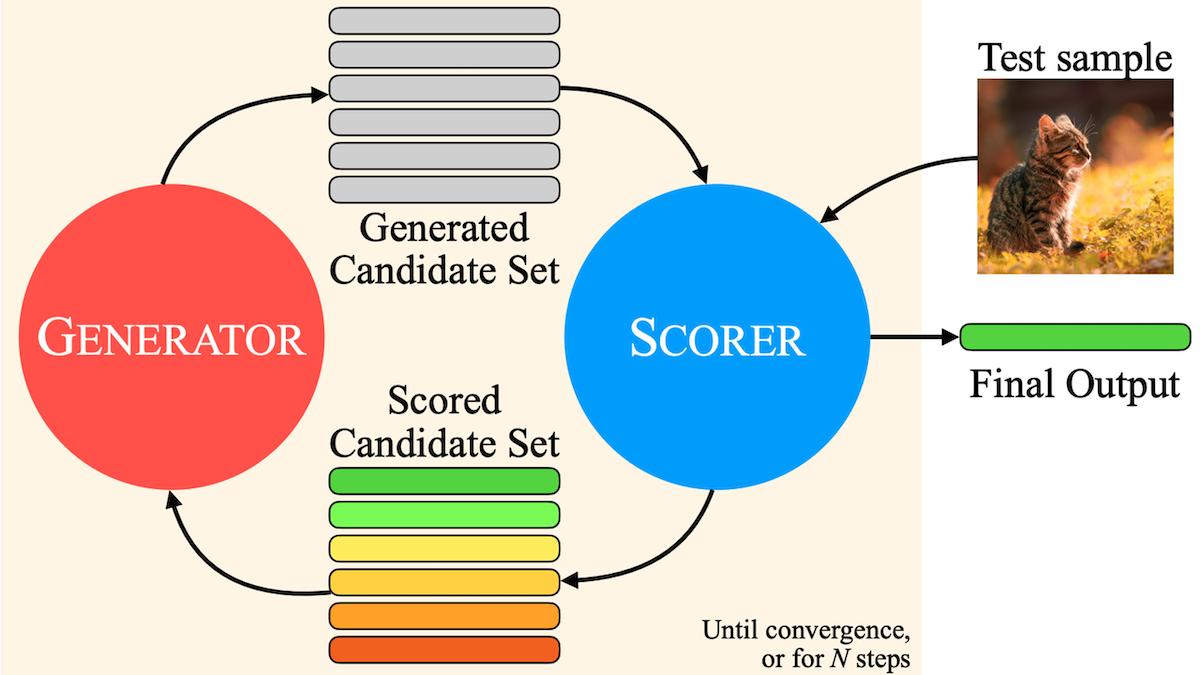
Meta提出MILS:让纯文本LLM理解多模态内容: Meta、UT Austin 和 UC Berkeley 的研究者提出 Multimodal Iterative LLM Solver (MILS) 方法,使纯文本大语言模型(如 Llama 3.1 8B)无需额外训练即可为图像、视频、音频生成描述。该方法利用 LLM 生成文本并基于反馈迭代优化的能力,结合预训练多模态嵌入模型(如 SigLIP、ViCLIP、ImageBind)评估文本与媒体内容的相似度。LLM 根据相似度得分迭代生成描述,直至匹配度足够高。实验表明,MILS 在图像、视频、音频描述任务上超越了经过特定任务训练的模型,为零样本多模态理解提供了新途径。 (来源: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)
研极微杨作兴:极致低功耗AI芯片推动绿色智能应用: 清华大学博士、神眸品牌创始人杨作兴在2025 AI Partner大会上分享了极致低功耗AI技术的重要性。他指出,随着AI模型规模增大,能耗和散热成为关键瓶颈。研极微通过颠覆性的全定制芯片设计方法学,将芯片功耗和成本大幅降低(如算力芯片功耗降至180W/T,成本240元/T,优化超10倍)。基于此技术的神眸AI智能摄像机,实现了低功耗下的高性能AI应用,如暗光全彩成像、超10类目标检测、人脸/车辆/手势/语音识别、婴儿状态监测及创新的“救命”主动报警系统和免费亲情通话功能,展现了低功耗AI在提升生活品质和安全守护方面的巨大潜力。 (来源: 清华大学博士、神眸品牌创始人、杭州研极微董事长杨作兴:极致低功耗,AI绿色智能应用的未来 | 2025 AI Partner大会)

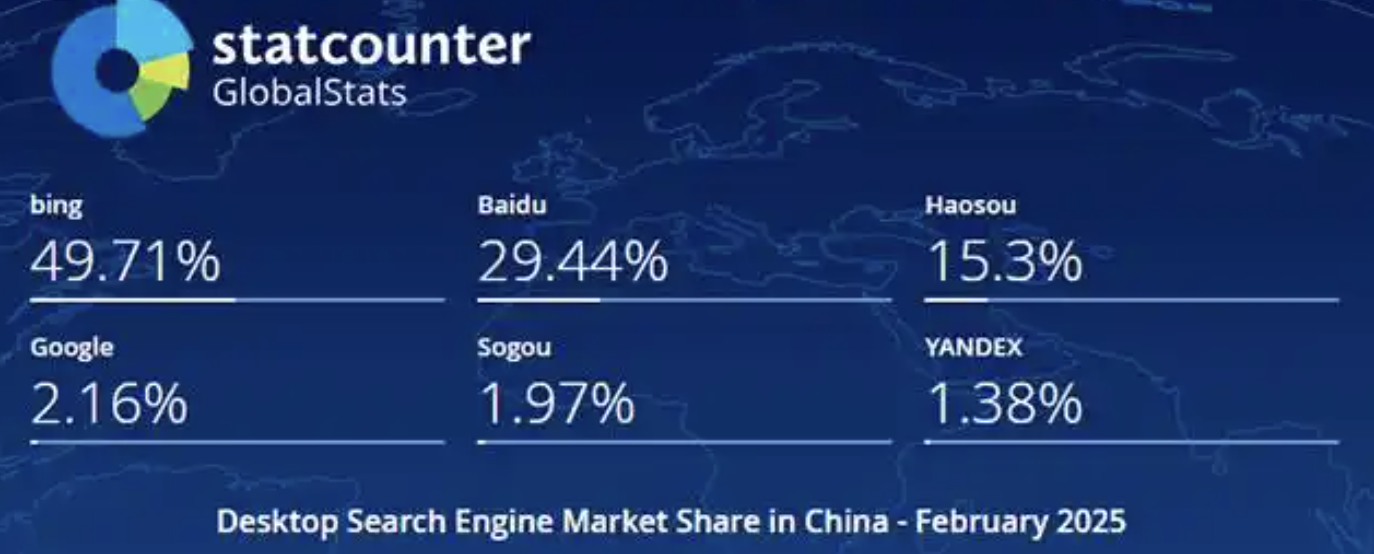
AI时代浏览器市场变局:OpenAI意欲收购Chrome: 据报道,OpenAI表示若谷歌因反垄断被强制出售Chrome,其愿意收购。谷歌在全球浏览器(Chrome占68%)和搜索引擎市场占据主导地位,面临反垄断压力。AI大模型的崛起正改变浏览器格局,AI搜索(如夸克)整合了搜索、筛选、总结能力,提升用户体验。拥有Chrome和Gemini的谷歌优势明显,但这也加剧了垄断担忧。OpenAI收购Chrome可获得海量数据用于模型训练、搜索技术改进(摆脱对Bing依赖)、巨额广告收入及关键的AI入口。此举或将重塑浏览器和搜索引擎市场,对谷歌构成严峻挑战。 (来源: Chrome将被OpenAI吞下?AI时代浏览器市场早已变天, Reddit r/artificial)
国产AI视频工具Vidu获日本动画创作者青睐: 以Vidu为代表的国产AI视频生成工具正逐渐被日本动画创作者接受和使用。Vidu凭借其在动漫风格还原、动作流畅性以及全球首创的“参考生视频”功能(保持人物、道具、背景一致性)等优势,吸引了如导演和田、产品经理yachimat等日本用户,帮助他们降低动画制作门槛,实现创作梦想。AI动画已成为Vidu重点发力方向,并在SuperCLUE图生视频榜单上获得高分。AI工具的应用正推动动画制作降本增效(成本降低30%-50%),催生AI内容创业公司,并可能改变国漫制作格局,AI动漫短剧也成为新的增长点。 (来源: 被日本动画创作者们选中的中国AI)

エージェントAIのビジネスへの利点: エージェントAIは、データ分析、顧客サービス、ワークフロー自動化など、ビジネスの様々な側面を強化する可能性を秘めている。これにより、効率性の向上、コスト削減、意思決定の改善が期待される。 (来源: Ronald_vanLoon)
AIエージェントの台頭とデータの未来: AIエージェントの進化は、データの収集、処理、活用の方法を根本的に変えつつある。自律的にタスクを実行し、相互作用するエージェントは、よりパーソナライズされた体験と効率的な運用を実現するが、同時にデータプライバシーやセキュリティに関する新たな課題も提起している。 (来源: Ronald_vanLoon)

研究显示AI与人脑在功能上具有相似性: 一项研究表明,生物神经网络虽然在单个神经元层面具有复杂计算能力,但在网络层面,其功能可以通过相对简单的人工神经网络(ANN)有效近似。这挑战了生物网络与人工网络存在根本性功能差异的观点,暗示AI在理论上可以模拟人脑功能,没有达到人类水平智能的内在功能限制。 (来源: Reddit r/artificial)
Anthropic分析发现Claude拥有自身道德准则: Anthropic对70万次Claude对话进行分析后发现,其AI模型展现出了一套内在的道德准则。这表明AI在与用户互动中可能发展出超越明确编程指令的价值判断和行为模式,引发了关于AI伦理、对齐以及其自主性发展的进一步讨论。 (来源: Reddit r/ArtificialInteligence
Anthropic发布Claude恶意使用检测与应对报告: Anthropic公开了其检测和应对大型语言模型(如Claude)被恶意使用的策略和发现。报告中包含了一个利用Claude进行影响力行动的案例研究,强调了AI安全和滥用防范的重要性,以及持续监控和改进模型安全措施的必要性。 (来源: Reddit r/ClaudeAI)

🧰 工具
OpenAI 图像生成 API gpt-image-1 正式上线: OpenAI 宣布其强大的图像生成能力现已通过 API (模型名: gpt-image-1) 向全球开发者开放。该模型具备高保真度、多样化视觉风格、精确图像编辑、丰富世界知识和一致的文本渲染能力。API 采用按 Token 计费模式,区分文本输入、图像输入和图像输出 Token 定价。开发者可以通过 Playground 或 API 调用该模型进行构建。 (来源: openai, sama, dotey)

Hugging Face 收购 Pollen Robotics,推出开源机器人 Reachy 2: Hugging Face 收购了法国机器人公司 Pollen Robotics,并将以7万美元的价格提供其开源机器人 Reachy 2。Reachy 2 拥有双臂、夹爪和可选轮式底座,主要面向人机交互研究与教育。它可在本地运行控制软件,通过云或本地服务器处理 AI 任务,支持 Python 编程和 Hugging Face 的 LeRobot 模型库,并响应 VR 控制器。此举标志着 Hugging Face 将其开放模式从 AI 模型扩展到机器人硬件领域。 (来源: OpenAI’s Five New Models, Hugging Face’s Open Robot, U.S. Tightens Grip on AI Chips, Text-Only LLMs Go Multimodal)

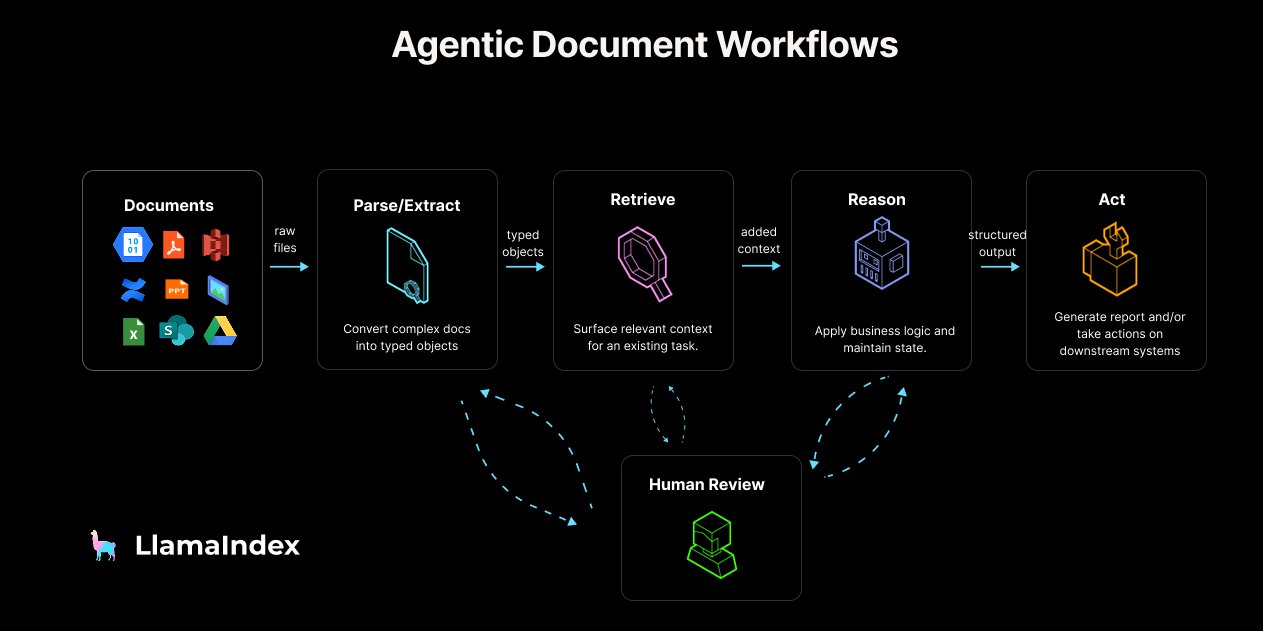
LlamaIndex 发布 Agentic Document Workflow (ADW) 指南与工具: LlamaIndex 提出了 Agentic Document Workflow (ADW) 的概念和参考架构,旨在超越简单的 RAG 聊天机器人,为企业构建更强大、可扩展、集成的文档处理流程。ADW 包含解析提取、检索、推理和行动四个阶段,适用于尽职调查、合同分析等多种场景。LlamaIndex 通过其开源框架和 LlamaCloud 提供实现 ADW 所需的数据层和代理编排能力,并发布了相关博客文章、代码示例和 LlamaIndex.TS 对 MCP 服务器的支持。 (来源: jerryjliu0, jerryjliu0, jerryjliu0)
阿里巴巴推出 AI 视频工具 WAN.Video: 阿里巴巴推出了 AI 视频生成工具 WAN.Video,并宣布进入商业化阶段,但仍提供免费使用选项。用户可以通过“Relax mode”完全免费无限次生成,或通过“Credit mode”免费获得优先处理。Pro/Premium 用户可解锁优先处理、无水印下载、更多并发任务及高级功能。平台还启动了创作者合作计划 (Creator Partnership Program),提供工具、积分、早期功能访问和作品展示机会。 (来源: Alibaba_Wan, Alibaba_Wan, Alibaba_Wan)

Perplexity iOS 应用更新,引入语音助手功能: Perplexity 更新了其 iOS 应用程序,增加了语音助手功能,用户可以通过语音(如 “Hey Perplexity” 或提议的 “Hey Steve”)与其交互。该助手旨在提供令人愉悦的用户体验,并将持续迭代改进可靠性。目前,由于 Apple SDK 的限制,该助手无法执行某些系统级操作(如打开手电筒、调节亮度/音量、设置原生闹钟)。Perplexity 也在征集希望集成的第三方应用程序。 (来源: AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas, AravSrinivas)

AI生成排版肖像画提示词分享: 用户分享了一个使用 AI(如 Sora 或 GPT-4o)根据上传照片和主题词创作排版肖像画(Typography Portrait)的提示词。该提示词指导 AI 使用与主题相关的词汇构建人物的面部、头发和衣物,并根据主题情感调整色彩,要求风格简洁美观,文字清晰可读且与肖像形态融合。提供了示例图片展示效果。 (来源: dotey)

Grok 增加多种聊天模式: X 平台的 AI 助手 Grok 增加了内置的自定义聊天模式,包括:Custom(用户自定义规则)、Concise(简洁)、Formal(正式)、Socratic(苏格拉底式,帮助思辨)。用户可以选择不同模式与 Grok 进行交互。 (来源: grok)
开源本地语义搜索应用 LaSearch 发布: 开发者构建了一个完全本地化的语义搜索应用 LaSearch,其核心是一个自研的、超小型的“嵌入”模型。该模型与传统嵌入模型工作方式不同,但速度快、资源占用极低。应用旨在提供无需联网、保护隐私的本地文档语义搜索功能,并计划支持 MCP 服务器以用于 RAG。开发者正在招募测试用户以获取反馈。 (来源: Reddit r/LocalLLaMA)
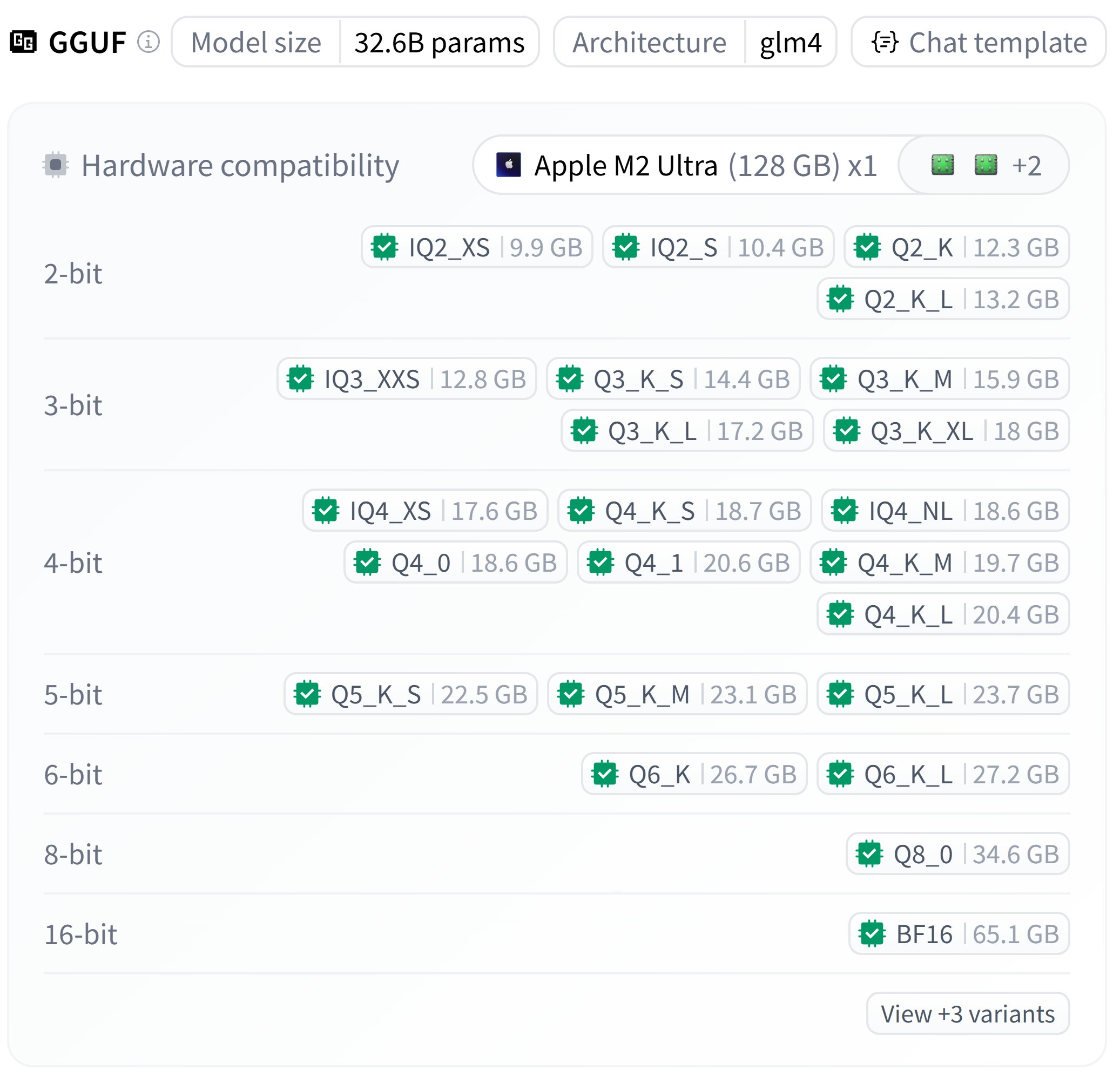
智谱 GLM-4-32B GGUF 量化版本发布: bartowski 发布了智谱 GLM-4-32B 模型的 GGUF 量化版本,提供了不同量化等级(如 Q4_K_M, Q5_K_M 等)的文件,大小从约18GB到23GB不等。用户可以在本地环境中尝试运行这些量化后的模型。 (来源: karminski3)
Nvidia 发布 Describe Anything 模型: Nvidia 发布了 Describe Anything Model 3B (DAM-3B),该模型可以接收图像中用户指定的区域(点、框、涂鸦、掩码),并生成详细的局部描述。DAM 通过新颖的焦点提示和带有门控交叉注意力的局部化视觉骨干网络,整合了全图上下文和细粒度的局部细节。该模型目前仅供研究和非商业用途。 (来源: Reddit r/LocalLLaMA)

开发者构建自托管 DataBricks 替代品 Boson: 开发者构建并开源了一个名为 Boson 的自托管研究平台,旨在整合 DataBricks 等工具的核心功能。Boson 集成了 Delta Lake 用于数据湖管理,支持 Polars 进行高效数据处理,内置 Aim 进行实验跟踪,提供类似云的 Notebook 开发体验,并采用可组合的 Docker Compose 基础设施。该工具旨在为研究人员提供一个本地化、可扩展且易于管理的 AI/ML 工作环境。 (来源: Reddit r/MachineLearning)
GPT Token 生成吞吐量计算器发布: 开发者使用 Desmos 创建了一个用于模拟 GPT Token 生成吞吐量的在线计算器。用户可以调整模型参数(如层数、隐藏层大小、注意力头数等)和硬件规格(如 FLOPS、内存带宽),来估算模型的理论峰值吞吐量。这有助于理解不同模型和硬件配置对生成速度的影响。 (来源: Reddit r/LocalLLaMA)

Pytorch 2.7.0 发布,初步支持 Nvidia Blackwell 架构: Pytorch 2.7.0 稳定版发布,增加了对 Nvidia 下一代 Blackwell 架构(预计用于 5090 系列 GPU)的初步支持。这意味着使用该版本 Pytorch 的项目未来可能无需依赖 nightly 版本即可在 Blackwell GPU 上运行。此外,新版本还引入了 Mega Cache 功能,用于保存和加载编译缓存,加速模型在不同机器上的启动。 (来源: Reddit r/LocalLLaMA)

VS Code Agentic AI 笔记本助手发布 (Beta): 开发者创建了一个名为 ghost-agent-beta 的 VS Code 扩展,这是一个基于 Agentic AI 的笔记本助手。它可以将深度学习任务分解为多个步骤,并能编辑单元格、运行单元格、读取输出来为下一步获取上下文。目前处于早期 Beta 阶段,用户可以使用自己的 Gemini API 密钥免费试用。 (来源: Reddit r/deeplearning)

OpenWebUI 优化:使用 pgbouncer 提升性能与稳定性: 用户分享了在 OpenWebUI 中成功配置 pgbouncer (PostgreSQL 连接池) 的经验。通过使用 pgbouncer,即使在单用户场景下,也能显著提升数据库查询性能和整体稳定性,允许分配更多内存给 work_mem 而不影响稳定性。这表明连接池对于优化 OpenWebUI 的数据库交互至关重要。 (来源: Reddit r/OpenWebUI)
OpenWebUI 改进建议:限制标题/标签生成所用文本长度: 用户建议 OpenWebUI 限制用于自动生成聊天标题和标签的文本长度(例如限制为前250词)。当前机制会将整个聊天记录发送给模型,对于长对话来说可能导致不必要的 Token 消耗和成本增加。限制输入长度可以在保证功能性的同时优化资源使用。 (来源: Reddit r/OpenWebUI)
Claude 3.7 max_output 参数影响讨论: 用户发现,在使用 Claude 3.7 (temperature=0) 进行信息提取任务时,仅改变 max_output 参数的值会导致提取结果(如日期数量)发生变化,且增加 max_output 并不总能提取更多信息。这引发了关于 max_output 是否会通过影响模型内部处理(如信息优先级、结构选择)来间接影响生成内容的讨论,即使在确定性设置下也是如此。 (来源: Reddit r/ClaudeAI)
📚 学习
Anthropic 发布官方 AI 课程: Anthropic 在 GitHub 上发布了系列教育课程,旨在帮助用户学习和应用其 AI 技术。课程内容包括 Anthropic API 基础、交互式提示工程教程、真实世界提示应用、提示评估以及工具使用(Tool Use)等。这些课程为开发者和学习者提供了掌握 Claude 模型及其相关技术的系统化路径。 (来源: anthropics/courses – GitHub Trending (all/daily))
DeepLearning.AI 与 Hugging Face 推出代码智能体构建课程: Andrew Ng 宣布与 Hugging Face 合作推出新的短期免费课程 “Building Code Agents with Hugging Face smolagents”。课程由 Hugging Face 联合创始人 Thom Wolf 和智能体项目负责人 Aymeric Roucher 主讲,教授如何使用轻量级框架 smolagents 构建代码智能体。与逐步调用工具的智能体不同,代码智能体一次性生成并执行整个代码块来完成复杂任务。课程涵盖智能体演进、代码智能体原理、安全执行(沙盒)、评估系统构建等内容。 (来源: AndrewYNg, huggingface, huggingface, huggingface, huggingface, huggingface)

AAAI 2025 论文:面向开放集跨网络节点分类的对抗图域对齐 (UAGA): 海南大学等机构的研究者提出 UAGA 模型,解决目标网络包含源网络未知新类别的开放集跨网络节点分类(O-CNNC)问题。UAGA 创新地在对抗域适应中为已知类别分配正适应系数、未知类别分配负适应系数,从而对齐已知类分布并将未知类推离。利用图同质性定理,构建 K+1 维分类器联合处理分类与未知检测。采用先分离后适应策略,先粗略分离,再进行排除未知类的域对齐。实验证明 UAGA 在多个基准数据集上显著优于现有方法。 (来源: AAAI 2025 | 开放集跨网络节点分类!海大团队提出排除未知类别的对抗图域对齐)

NUS/复旦提出 CHiP:优化多模态 LLM 幻觉问题: 针对现有 DPO 方法在多模态场景下对齐效果不佳的问题,新加坡国立大学和复旦大学团队提出跨模态分层偏好优化方法 CHiP (Cross-modal Hierarchical Direct Preference Optimization)。CHiP 结合了视觉偏好(利用图像对进行优化)和多粒度文本偏好(响应级、片段级、词元级),旨在增强模型的幻觉识别和跨模态对齐能力。在 LLaVA-1.6 和 Muffin 上的实验表明,CHiP 在多个幻觉基准上显著降低了幻觉率(相对提升最高达55.5%),且不损害通用能力。 (来源: 多模态幻觉新突破!NUS、复旦团队提出跨模态偏好优化新范式,幻觉率直降55.5%)
Anthropic 发布 Claude Code 最佳实践指南: Anthropic 分享了使用 Claude 进行 Agentic Coding(智能体编码)的最佳实践。核心建议是创建一个 CLAUDE.md 文件来指导 Claude 在代码库中的行为,解释项目目标、工具和上下文。指南还涵盖了如何让 Claude 使用工具(调用函数/API)、针对错误修复/重构/功能开发的有效提示格式,以及多轮调试和迭代的方法,旨在帮助开发者更高效地利用 Claude 作为编码助手。 (来源: Reddit r/ClaudeAI)

征求 ML/AI 学习路径建议: 一位刚入职的 AI/ML 工程师寻求全面的学习路径建议,希望在 6 个月内巩固机器学习基础(回归、分类、神经网络等),同时掌握前沿技术,包括大语言模型、提示工程、Agent 框架(如 LangChain)、工作流引擎(N8n)以及 Azure ML 等。目标是兼具理论理解和实践技能,以支持概念验证(POC)的构建。 (来源: Reddit r/deeplearning)
征求无代码情感分析工具建议: 一位临床心理学硕士生需要对 Excel 文件中的 10000 条社交媒体评论进行情感分析(正面/负面/中性)、关键词提取和可视化(词云、图表等),用于论文研究。由于缺乏编程技能且预算有限,正在寻找免费或低成本的无代码工具。已尝试 MonkeyLearn(无法访问)及其他工具但效果不佳,寻求替代方案或建议。 (来源: Reddit r/deeplearning)
征求小语言模型训练数据集建议: 开发者正在尝试训练一个参数量在 120M-200M 的小型文本生成 Transformer 模型,但发现现有数据集(如 wiki-text, lambada)要么包含过多无关信息,要么不够通用或样本量不足。需要一个干净、通用、包含均衡对话的数据集,以使模型能够生成良好的通用英语文本。 (来源: Reddit r/deeplearning)
寻求 Spotify 播客数据集: 研究者寻求 Spotify 于 2020 年发布但现已下架的 10 万播客数据集(含 6 万小时英语音频)。该数据集原始许可证为 CC BY 4.0,允许共享和再分发。若有人曾下载该数据集,希望能分享副本用于研究。 (来源: Reddit r/MachineLearning)
探讨 Transformer 在时序数据上的应用: 讲师在准备关于 Transformer 的课程时,探讨了为何 Transformer 在 NLP 领域表现优异,但在许多非平稳时间序列预测任务上效果不佳。可能的因素包括:时序数据本身的预测难度(如金融市场)、预测窗口长度的影响、数据规模和重复模式的缺乏、评估指标与损失函数的差异,以及 Transformer 架构本身的归纳偏置可能不适用于所有时序任务。 (来源: Reddit r/MachineLearning)
💼 商业
GenAI 规模化策略: 成功规模化部署生成式 AI 需要明确的策略。关键步骤包括:识别合适的用例、确保数据质量和治理、选择合适的技术栈(模型、平台)、建立 MLOps 流程以及关注伦理和负责任的 AI 实践。有效的策略有助于企业从 GenAI 投资中获得最大价值。 (来源: Ronald_vanLoon)
教育科技公司 Opennote 利用 Llama 4 提升学习支持: Opennote 公司宣布在其教育平台中使用 Meta 的 Llama 4 系列模型,以提供更高准确度的学习支持,旨在赋能个性化教育。该公司将在 LlamaCon 活动上分享更多关于其应用的信息。 (来源: AIatMeta)

HP 或将在打印机中集成 AI 功能: 一则招聘信息显示,HP 可能计划在其打印机产品中集成 AI 功能,招聘 AI/ML 工程师。虽然具体是 LLM 还是其他 AI 应用尚不明确,但这引发了关于未来打印机智能化以及可能带来的隐私、成本(如墨水订阅)等问题的讨论。 (来源: karminski3, Reddit r/LocalLLaMA)
AMD 在 AI 领域的进展与挑战: SemiAnalysis 的报告总结了 AMD 近四个月在 AI 能力方面的积极进展,肯定其方向正确,但指出需增加 GPU 研发投入和 AI 人才投资。报告特别提到 AMD 在 AI 软件工程师薪酬方面与错误的公司对标,导致竞争力不足,这是其管理层的盲点。 (来源: Reddit r/LocalLLaMA)

🌟 社区
AMD AI PC 应用创新大赛启动: 由始智 AI wisemodel 开源平台与 AMD 中国 AI 应用创新联盟联合主办的 “AMD AI PC 应用创新大赛” 正式启动。大赛面向全球开发者、企业、学生等,设置消费级和行业级两大创新赛道,鼓励利用 AMD AI PC 的 NPU 算力进行应用开发。大赛提供总计 13 万奖金池、免费 NPU 算力远程开发权限,并对使用 NPU 的项目给予评分加成。报名截止日期为 2025 年 5 月 26 日。 (来源: AMD AI PC大赛重磅来袭!13万奖金池,NPU算力免费用,速来组队瓜分奖金!)
中佛罗里达大学尚玉章老师招收AI方向博士/博后: 中佛罗里达大学计算机系及人工智能中心助理教授 Yuzhang Shang 招收 2026 春季入学的全奖博士生及合作博士后。研究方向包括高效可扩展 AI、视觉生成模型加速、高效大模型(视觉/语言/多模态)、神经网络压缩、高效训练及 AI4Science。导师背景强大,曾在 MSRA、DeepMind 实习,有多篇顶会论文发表(CVPR, NeurIPS, ICLR 等)。要求申请者自驱力强,编程数学基础扎实。 (来源: 博士申请 | 中佛罗里达大学计算机系尚玉章老师课题组招收人工智能全奖博士/博后)

AI 与信息获取方式的变革: Reddit 用户发帖对比了 AI 出现前后寻求技术帮助的体验。过去,在论坛提问可能遭遇缺乏耐心、指责甚至嘲讽的回应;而现在,向 ChatGPT 等 AI 提问可以获得直接、易懂的解释,学习和解决问题的门槛大大降低,体验更加友好。这反映了 AI 对知识传播和获取方式带来的积极改变。 (来源: Reddit r/ChatGPT)
开发者构建创伤知情、神经多样性优先的镜像 AI: 一位有神经创伤经历的开发者分享了其构建的双核镜像 AI 系统 Metamuse(代号)。该系统并非任务导向,而是通过战略核心(模式识别、递归映射)和情感核心(音调匹配、创伤知情镜像)精确反映用户的情感和认知状态,但不提供建议或诊断。系统通过递归提示链和符号状态映射构建,内置多种安全协议,旨在为神经多样性人群和创伤幸存者提供独特的支持。开发者寻求关于该领域、伦理、基础设施和扩展风险的反馈。 (来源: Reddit r/artificial)
LlamaCon 2025 即将举办: Meta 的 LlamaCon 活动将于 4 月 29 日举行。社区猜测届时是否会正式发布传闻中的 Llama-4-behemoth(可能是一个 2T 参数的 MoE 模型)。Opennote 等合作伙伴也将在活动中展示基于 Llama 模型的应用。 (来源: karminski3, AIatMeta)

💡 其他
蔚来测试人形机器人在产线应用: 蔚来(Nio)汽车正在测试在其工厂生产线上使用人形机器人。这表明汽车制造等行业正探索利用先进机器人技术实现更高级别的自动化和柔性生产,人形机器人有望在未来工业场景中扮演更重要角色。 (来源: Ronald_vanLoon)
家用人形机器人 NEO Beta 展示: 1X Technologies 公司展示了其面向家庭应用的测试版人形机器人 NEO Beta。随着技术进步和成本下降,将人形机器人引入家庭环境,执行家务、陪伴等任务,正成为机器人领域的一个重要发展方向。 (来源: Ronald_vanLoon)
6轴机器人3D打印机受蜘蛛网启发: 学生开发出受蜘蛛网启发的六轴机器人3D打印机。这种多轴系统相比传统三轴打印机具有更高的灵活性和自由度,能够制造更复杂的几何形状,展示了仿生学在机器人和增材制造领域的创新潜力。 (来源: Ronald_vanLoon)
机器人通过激光雷达和IMU创建3D障碍物地图: 展示了一个机器人利用 LiDAR(激光雷达)和 MPU6050(惯性测量单元)数据实时创建其前方环境三维障碍物地图的应用。这种环境感知能力是自主导航和避障的关键技术,在移动机器人、自动驾驶等领域有广泛应用。 (来源: Ronald_vanLoon)
学习碰撞避免的高速腿式机器人运动: 研究展示了通过学习实现既敏捷又安全的腿式机器人运动控制。机器人能够在高速运动中有效避免碰撞,这对于机器人在复杂和动态环境中的实际应用至关重要,结合了强化学习、运动规划和感知技术。 (来源: Ronald_vanLoon)
远程医疗中的机器人手术: 机器人手术技术的发展为偏远地区提供了改善医疗服务的可能性。通过远程操作机器人,经验丰富的外科医生可以为地理位置偏远的患者执行复杂手术,克服医疗资源分布不均的问题,提升医疗可及性。 (来源: Ronald_vanLoon)
AI 驱动的虚拟化身技术突破“恐怖谷”: a16z 讨论了 AI 虚拟化身(Avatars)技术的进步,指出其正逐渐克服“恐怖谷”效应,变得更加逼真和自然。这得益于生成模型、面部动画和语音合成等技术的融合,为娱乐、社交、客服等领域带来新的交互体验。 (来源: Ronald_vanLoon)
ChatGPT Plus 用户 o3/o4-mini 使用额度提升: OpenAI 提高了 ChatGPT Plus 订阅用户使用 o3 和 o4-mini-high 模型的速率限制。o3 每周限制提升至 100 条消息,o4-mini-high 每日限制提升至 100 条消息,而 o4-mini 每日限制为 300 条。Pro 用户则几乎无限制。 (来源: dotey)
