
关键词:GPT-4.5, 大模型, GPT-4.5训练细节, 华为盘古Ultra性能, RLHF对推理能力影响, 人类学习上限4GB研究, 开源数学数据集MegaMath
🔥 聚焦
OpenAI揭秘GPT-4.5训练细节与挑战: OpenAI CEO萨姆·阿尔特曼与GPT-4.5核心技术团队对谈,披露了模型研发细节。项目启动于两年前,动用近乎全员,耗时超预期。训练中遭遇10万卡集群故障、隐藏bug等“灾难性问题”,暴露了基础设施瓶颈,但也促使技术栈升级,如今仅需5-10人即可复刻GPT-4级模型。团队认为,未来性能提升的关键在于数据效率而非算力,需开发新算法从同量数据中学到更多。系统架构正转向多集群,未来或涉千万级GPU协作,对容错性提出更高要求。对谈还涉及Scaling Law、机器学习与系统协同设计、无监督学习本质等,展现了OpenAI在推动前沿大模型研发中的思考与实践 (来源: 36氪)

华为发布昇腾原生135B稠密大模型盘古Ultra: 华为盘古团队发布了基于国产昇腾NPU训练的135B参数稠密通用语言大模型Pangu Ultra。该模型采用94层Transformer结构,并引入Depth-scaled sandwich-norm (DSSN) 和 TinyInit 初始化技术解决超深模型训练稳定性问题,在13.2T高质量数据上实现了无loss突刺的稳定训练。系统层面,通过混合并行、算子融合、子序列切分等优化,在8192卡昇腾集群上将算力利用率(MFU)提升至50%以上。评测显示,Pangu Ultra在多个基准上超越Llama 405B、Mistral Large 2等稠密模型,并能与DeepSeek-R1等更大规模MoE模型竞争,证明了基于国产算力研发顶尖大模型的可行性 (来源: 机器之心)

研究质疑强化学习对LLM推理能力提升的显著性: 图宾根大学与剑桥大学的研究者对近期宣称强化学习(RL)能显著提升语言模型推理能力的说法提出质疑。通过对常用推理基准(如AIME24)的严格调查,研究发现结果存在高度不稳定性,仅改变随机种子就可能导致得分大幅波动。在标准化评估下,RL带来的性能提升远小于原始报告,且常不具统计显著性,甚至弱于监督微调(SFT)的效果,泛化能力也较差。研究指出采样差异、解码配置、评估框架和硬件异构性是导致不稳定的主要原因,并呼吁采用更严格、可重复的评估标准来冷静看待和衡量模型推理能力的真实进展 (来源: 机器之心)

奥特曼TED演讲:将推强大开源模型,认为ChatGPT非AGI: OpenAI CEO奥特曼在TED大会表示,正开发一款强大的开源模型,性能将超越现有所有开源模型,直接回应DeepSeek等竞争者。他强调ChatGPT用户量持续疯长,新记忆功能将提升个性化体验。他认为AI将在科学发现和软件开发(效率提升巨大)领域迎来突破,但当前模型如ChatGPT尚不具备自我持续学习和跨领域泛化能力,并非AGI。他还讨论了GPT-4o的创意能力引发的版权和“风格权”问题,并重申了OpenAI对模型安全的信心及风险控制机制 (来源: 新智元)

研究称人类一生学习上限约4GB,引脑机接口和AI发展热议: Cell旗下期刊Neuron发表加州理工学院研究,估算人类大脑信息处理速度约为每秒10比特,远低于感官系统每秒10亿比特的数据收集速率。基于此,研究推断人类一生(假设100年不间断学习不遗忘)知识积累上限约为4GB,远小于大模型参数存储能力(如7B模型可存140亿比特)。研究认为该瓶颈源于中枢神经系统的串行处理机制,并预测机器智能超越人类只是时间问题。该研究还对马斯克Neuralink提出质疑,认为其无法突破大脑基本结构限制,不如优化现有通信方式。此研究引发了对人类认知极限、AI发展潜力及脑机接口方向的广泛讨论 (来源: 量子位)

🎯 动向
GPT-4即将退役,GPT-4.1及神秘新模型或将登场: OpenAI宣布将于4月30日起在ChatGPT中用GPT-4o完全取代两年前发布的GPT-4,后者仍可通过API使用。同时,社区和代码泄露表明,OpenAI可能即将发布一系列新模型,包括GPT-4.1(及其mini/nano版本)、满血版o3推理模型以及新的o4系列(如o4-mini)。一款名为Optimus Alpha的神秘模型已在OpenRouter上线,表现优异(尤其编程),支持百万上下文,被广泛猜测为OpenAI即将发布的新模型之一(可能是GPT-4.1或o4-mini),其与OpenAI模型存在诸多相似之处(如特定bug)。这预示着OpenAI模型迭代速度加快,正积极巩固其技术领先地位 (来源: source、source)

阿里Qwen3大模型蓄势待发: 消息称阿里巴巴预计在近期发布Qwen3大模型,研发团队确认模型已进入最后准备阶段,但具体发布时间未定。据悉,Qwen3是阿里2025年上半年的重要模型产品,其研发在Qwen2.5之后启动。受DeepSeek-R1等竞品模型的影响,阿里云基础模型团队将策略重心进一步向提升模型的推理能力倾斜,显示出大模型竞争格局下对特定能力的战略聚焦 (来源: InfoQ)

Kimi开放平台降价并开源轻量级视觉模型: 月之暗面旗下Kimi开放平台宣布下调模型推理服务和上下文缓存的价格,旨在通过技术优化降低用户成本。同时,Kimi开源了两款基于MoE架构的轻量级视觉语言模型Kimi-VL和Kimi-VL-Thinking,支持128K上下文,激活参数仅约30亿,据称在多模态推理能力上显著优于10倍参数量的大模型,旨在推动小型高效多模态模型的发展与应用 (来源: InfoQ)
谷歌发布Agent互操作协议A2A及多款AI新品: 在Google Cloud Next ’25大会上,谷歌联合超50家伙伴推出开放协议Agent2Agent (A2A),旨在实现不同公司、平台开发的AI智能体之间的互操作与协作。同时发布了Gemini 2.5 Flash(高效版旗舰模型)、Lyria(文生音乐)、Veo 2(视频创作)、Imagen 3(图像生成)、Chirp 3(自定义语音)等多款AI模型及应用,并推出第七代TPU芯片Ironwood,专为推理优化。此系列发布体现了谷歌在AI基础设施、模型、平台和智能体方面的全面布局与开放策略 (来源: InfoQ)
字节跳动发布200B参数推理模型Seed-Thinking-v1.5: 字节跳动豆包团队发布技术报告,介绍其拥有200B总参数的MoE推理模型Seed-Thinking-v1.5。该模型每次激活20B参数,在多个基准测试中表现优异,据称超越了拥有671B总参数的DeepSeek-R1。社区猜测这可能是当前字节豆包App中“深度思考”模式所使用的模型,显示了字节在高效推理模型研发上的进展 (来源: InfoQ)
Midjourney发布V7模型,提升图像质量与生成效率: AI图像生成工具Midjourney发布了新模型V7(alpha版)。新版本改进了图像生成的连贯性和一致性,尤其在手部、身体部位及物体细节上表现更佳,并能生成更逼真丰富的纹理。V7引入了Draft Mode,以一半费用实现十倍渲染速度,适用于快速迭代探索。同时提供turbo(更快但更贵)和relax(更慢但更便宜)两种生成模式,满足不同用户需求 (来源: InfoQ)
亚马逊推出AI语音模型Nova Sonic: 亚马逊发布了新一代原生处理语音的生成式AI模型Nova Sonic。据称,该模型在速度、语音识别和对话质量等关键指标上可与OpenAI和谷歌的顶尖语音模型媲美。Nova Sonic通过亚马逊Bedrock开发者平台提供,采用新的双向流式API接入,且价格比GPT-4o便宜约80%,旨在为企业级AI应用提供高性价比的自然语音交互能力 (来源: InfoQ)
苹果国行版iPhone AI功能或年中上线,整合百度与阿里技术: 报道称苹果计划在2025年中期前为中国市场的iPhone(可能在iOS 18.5)引入Apple Intelligence服务。该功能将利用百度文心大模型提供智能能力,并整合阿里巴巴的审查引擎以符合内容监管要求。苹果并未与百度或阿里签署独占协议,显示其在关键市场采取本地化合作策略以快速部署AI功能 (来源: InfoQ)
🧰 工具
火山引擎发布企业数据智能体Data Agent: 火山引擎推出企业级数据智能体Data Agent。该工具利用大模型的推理、分析和工具调用能力,旨在深度理解企业业务需求,自动化执行如撰写深度研究报告、设计营销活动等复杂数据分析与应用任务,提升企业数据利用效率和决策水平 (来源: InfoQ)
GPT-4o图像生成新风格受关注: 社交媒体用户展示了利用GPT-4o图像生成功能创作的新风格,例如将Windows 2000复古界面元素与角色图片结合,生成独特的拼贴画效果。用户分享了提示词技巧,如利用垫图引导、结合风格与内容描述,引发了社区对探索GPT-4o创意潜力的兴趣 (来源: source、source)

📚 学习
最大开源数学预训练数据集MegaMath发布: LLM360推出MegaMath,一个包含3710亿tokens的开源数学推理预训练数据集,规模超越DeepSeek-Math Corpus。数据集覆盖数学密集型网页(279B)、数学相关代码(28B)和高质量合成数据(64B)。团队通过精细化的数据处理流程,包括HTML结构优化、两段式抽取、LLM辅助筛选与精炼等,确保了数据的规模、质量与多样性。在Llama-3.2模型上的预训练验证显示,使用MegaMath能在GSM8K、MATH等基准上带来15-20%的绝对提升,为开源社区提供了强大的数学推理能力训练基础 (来源: 机器之心)

Nabla-GFlowNet:平衡扩散模型微调的多样性与效率: 港中文(深圳)等机构研究者提出Nabla-GFlowNet,一种基于生成流网络(GFlowNet)的扩散模型奖励微调新方法。该方法旨在解决传统强化学习微调收敛慢和直接奖励优化易过拟合、损失多样性的问题。通过推导新的流平衡条件(Nabla-DB)并设计特定损失函数和对数流梯度参数化,Nabla-GFlowNet能在保持生成样本多样性的同时,高效地将模型向奖励函数(如美学评分、指令跟随)对齐。在Stable Diffusion上的实验证明了其相较于DDPO、ReFL、DRaFT等方法的优势 (来源: 机器之心)
Llama.cpp 修复 Llama 4 相关问题: llama.cpp 项目合并了两个针对 Llama 4 模型的修复,涉及 RoPE(旋转位置嵌入)和错误的范数(norms)计算。这些修复旨在提高模型输出质量,但用户可能需要重新下载使用修复后转换工具生成的 GGUF 模型文件才能生效 (来源: source)
💼 商业
英伟达完成对Lepton AI的收购: 据报道,英伟达已收购由前阿里副总裁贾扬清创立的AI基础设施初创公司Lepton AI,交易价值或达数亿美元。Lepton AI主要业务是出租英伟达GPU服务器并提供软件帮助企业构建和管理AI应用。贾扬清及其联合创始人白俊杰等约20名员工已加入英伟达。此举被视为英伟达拓展云服务和企业软件市场,应对AWS、谷歌云等自研芯片竞争的战略部署 (来源: InfoQ)
美国科技界弥漫焦虑情绪,AI冲击就业市场: 报道指出,美国科技行业正经历岗位减少、薪酬缩水和求职周期延长的困境。大规模裁员、企业(如Salesforce、Meta、Google)利用AI替代人力或暂停招聘(尤其工程和初级岗位)加剧了从业者的职业焦虑。数据显示,报告薪资下降和从管理岗转向个人贡献者岗位的人数比例上升。AI正重塑就业市场,迫使求职者拓宽视野至非科技行业或转向创业。专家建议关注“七巨头”之外的就业机会,并掌握AI工具以提升竞争力 (来源: InfoQ)

传OpenAI拟收购Altman与Jony Ive合作的AI硬件公司: 消息称OpenAI正讨论以不低于5亿美元收购由其CEO奥特曼与前苹果设计总监Jony Ive合作创立的AI公司io Products。该公司旨在开发由AI驱动的个人设备,可能的形态包括无屏“手机”或家用设备。io Products由工程师团队构建设备,OpenAI提供技术,Ive工作室负责设计,Altman深度参与。若收购完成,将整合该硬件团队进入OpenAI,加速其在AI硬件领域的布局 (来源: InfoQ)
前OpenAI CTO初创公司再挖角老东家: 前OpenAI CTO Mira Murati创办的AI公司“思维机器实验室”吸引了两位前OpenAI关键人物加入顾问团队:前首席研究官Bob McGrew和前研究员Alec Radford。Radford是GPT系列核心技术论文的主笔。此次招募进一步加强了该初创公司的技术实力,也反映了AI领域激烈的人才竞争 (来源: InfoQ)
百川智能调整业务重心,聚焦医疗领域: 百川智能创始人王小川在公司成立两周年之际发布全员信,重申公司将专注医疗领域,发展百小应、AI儿科、AI全科和精准医疗等应用服务。他强调需减少多余动作,组织架构将更扁平化。此前,公司被曝金融行业B端组裁撤,商业合伙人邓江离职,另有数位联合创始人离职或即将离职,显示公司正经历战略聚焦与组织调整 (来源: InfoQ)
阿里云启动AI生态伙伴“繁花”计划: 阿里云发布“繁花”计划,旨在支持AI生态伙伴。该计划将根据伙伴产品成熟度,提供云资源、算力支持、产品打包、商业化规划及全生命周期服务。同时,阿里云推出AI应用与服务市场,意在构建繁荣的AI生态,加速AI技术与应用的落地 (来源: InfoQ)
酷狗音乐与DeepSeek达成深度合作: 酷狗音乐宣布与AI公司DeepSeek合作,将推出一系列AI创新功能。包括利用多模态分析生成个性化听歌报告、AI每日推荐、智能搜索、AI歌单管理、AI生成动态封面以及具备角色设定的“AI评论官”等,旨在通过AI技术提升用户音乐体验和社区互动 (来源: InfoQ)
传谷歌为留AI人才采用“激进”竞业禁止协议: 报道称谷歌旗下DeepMind为阻止人才流向竞争对手,对部分英国员工实施为期一年的竞业禁止协议。期间员工无需工作但仍领取薪水(带薪休假),但这让一些研究人员感到被边缘化,无法参与快速发展的行业进程。此举在美国或受FTC禁止,但在伦敦总部适用,引发了关于人才竞争和限制创新的讨论 (来源: InfoQ)
OpenAI前员工提交法律文件支持马斯克诉讼: 12名OpenAI前员工提交法律文件,支持马斯克对OpenAI提起的诉讼。他们认为OpenAI的重组计划(转向营利性结构)可能从根本上违反公司最初的非营利使命,而这一使命是吸引他们加入的关键因素。OpenAI回应称,即使结构变化,其使命也不会改变 (来源: InfoQ)
🌟 社区
Anthropic研究揭示AI在高等教育中的应用模式与挑战: Anthropic分析了Claude.ai平台上百万条匿名学生对话,发现理工科(尤其计算机专业)学生是AI早期使用者。学生与AI交互模式包括直接解决问题、直接生成内容、协作解决问题和协作生成内容四种,占比相当。AI主要用于创造(如编程、写练习题)和分析(如解释概念)等高阶认知任务。研究也揭示了潜在的学术不端行为(如获取答案、规避抄袭检测),引发对学术诚信、批判性思维培养及评估方式的担忧 (来源: 新智元)

GPT-4o图像生成引领新潮流:从吉卜力风到AI名流卡牌: GPT-4o强大的图像生成能力在社交媒体上持续引发创作热潮。继“吉卜力风全家福”爆红(背后推手为亚马逊前工程师Grant Slatton)后,用户又开始创作AI领域名人的“魔法风云会”风格卡牌(如奥特曼被设定为“AGI霸主”),以及个性化的塔罗牌。这些案例展示了AI在艺术风格模仿和创意生成方面的潜力,但也引发了关于原创性、版权、审美价值以及AI对设计师职业影响的讨论 (来源: 新智元)

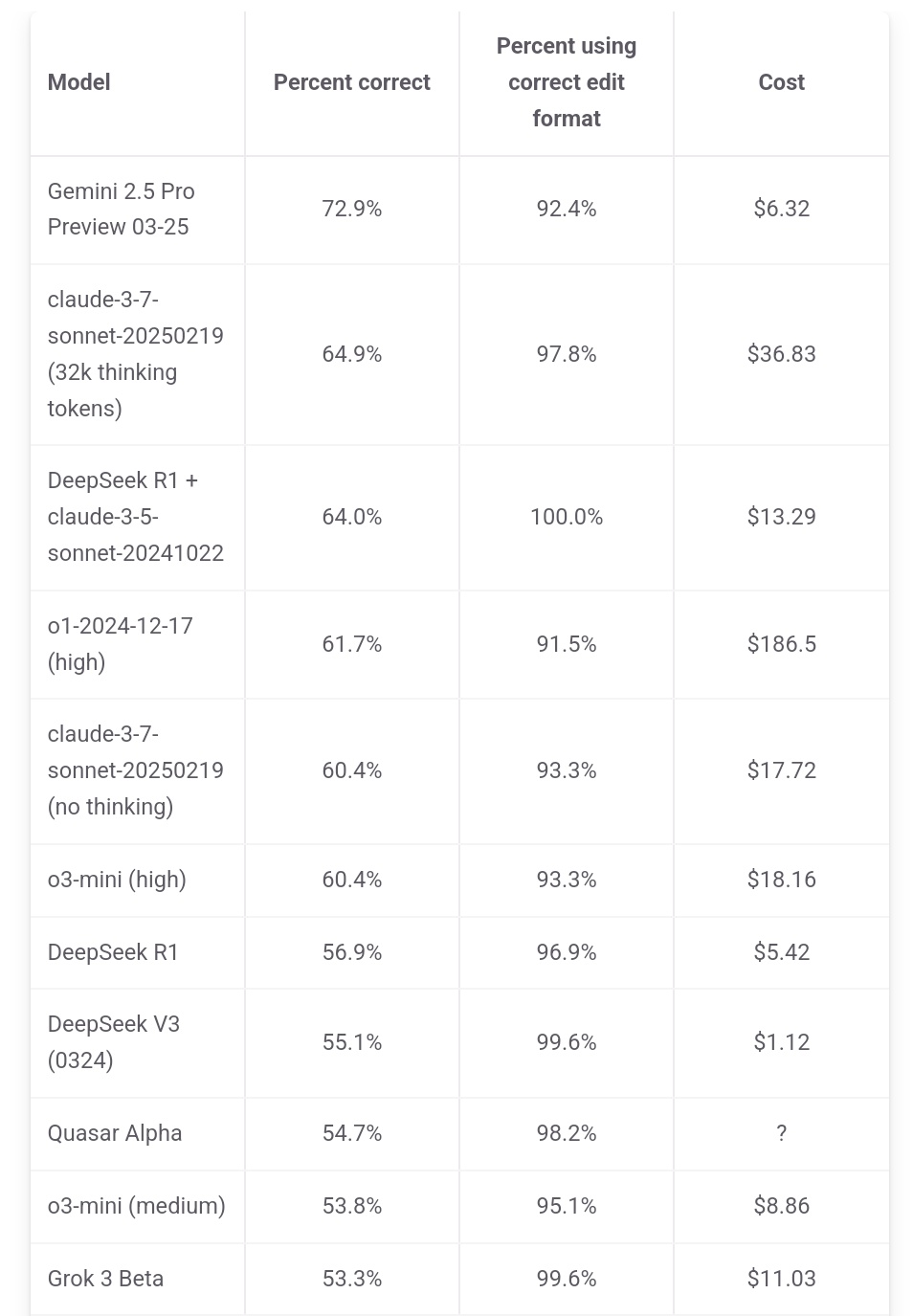
Jeff Dean强调Gemini 2.5 Pro成本优势: 谷歌AI负责人Jeff Dean转发aider.chat的排行榜数据,并指出Gemini 2.5 Pro在Polyglot编程基准测试中不仅性能领先,成本(6美元)也显著低于除DeepSeek外的其他Top 10模型,强调了其性价比优势。部分竞品模型成本高达Gemini 2.5 Pro的2倍、3倍甚至30倍 (来源: JeffDean)
Reddit热议AI对就业市场的冲击,尤其是入门级岗位: Reddit论坛一篇帖子引发热议,发帖人(一名CIS硕士在读生)表达了对AI取代入门级非体力工作(特别是软件工程、数据分析、IT支持)的深切担忧,认为“AI不会抢工作”的说法忽视了新毕业生的困境。他指出大公司已在缩减校招,未来就业市场可能严峻。评论区对此观点分歧,有人认同危机,有人认为这是技术变革常态,需适应新角色(如管理AI团队),也有人质疑“90%岗位消失”的说法,认为经济周期和不同国家情况差异很大,且AI目前能力仍有限 (来源: source)
Claude用户抱怨性能下降和限制收紧: Reddit ClaudeAI板块出现集中讨论,多位用户(包括Pro用户)反映近期遇到更严格的使用限制(quota),即使是常规操作也频繁达到上限。有用户认为Anthropic在暗中收紧额度,并对此表示不满,认为这会迫使用户流向竞品。此外,有用户反馈Claude的“个性”似乎发生变化,变得更“冷漠”、“机械”,失去了早期版本的哲学和诗意感,导致部分用户取消订阅 (来源: source、source、source、source)
ChatGPT图像生成引发趣味与讨论: Reddit用户分享使用ChatGPT进行图像生成的各种尝试和结果。有人要求将狗“变形”成人,结果生成了类似“兽人/福瑞”的形象,引发关于提示词理解和潜在偏见的讨论。另一用户要求将自己画成多重宇宙版本的彩色玻璃窗,效果惊艳。还有用户要求生成关于AI的隐喻图像,或询问AI的“噩梦”,展示了AI图像生成在创意表达和抽象概念可视化方面的能力与局限 (来源: source、source、source、source、source)

社区讨论LLM模型选择与使用策略: Reddit LocalLLaMA板块有用户提议每月进行一次模型使用讨论,分享各自在不同场景(编码、写作、研究等)下使用的最佳模型(开源及闭源)及其原因。评论区用户分享了当前使用的模型组合,如Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo等,并提及特定用途(如工具调用、分类、角色扮演),反映了用户根据任务需求选择和组合不同模型的实践趋势 (来源: source)
💡 其他
中国AIGC产业峰会即将举办: 第三届中国AIGC产业峰会将于4月16日在北京举行。峰会将汇聚来自百度、华为、微软亚研院、亚马逊云科技、面壁智能、生数科技等企业的20余位行业领袖,探讨AI技术突破(算力、大模型)、行业应用(教育、文娱、科研、企业服务)、生态构建(安全可控、落地挑战)等议题。峰会还将发布AIGC企业/产品榜单及中国AIGC应用全景图谱 (来源: 量子位)

斯坦福报告:中美顶尖AI模型性能差距缩小至0.3%: 斯坦福大学发布的2025年AI指数报告显示,中美顶级AI模型在性能上的差距已从2023年的20%显著缩小至0.3%。尽管美国在知名模型数量(40 vs 15)和行业主导企业方面仍领先,但中国模型追赶速度加快。报告还指出,顶级模型之间的性能差距也在缩小,从2024年的12%降至5%,趋同化现象明显 (来源: InfoQ)